Git
Formateur: Fabio Ginja
Premiers pas
Fonctionnement
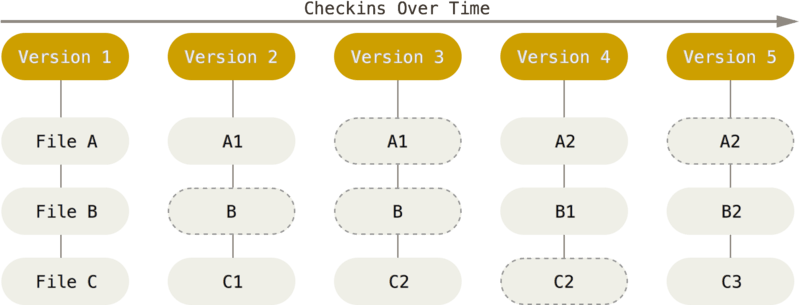
Git pense ses données comme un instantané du contenu de notre espace de travail puis enregistre une référence à cet instantané.Pour être efficace, si les fichiers n’ont pas changé, Git ne stocke pas le fichier à nouveau, juste une référence vers le fichier original qu’il a déjà enregistré.
Opérations et Checksum
Presque toutes les opérations sont locales. On peut donc utiliser git sans jamais avoir besoin de se connecter au réseau, et même de continuer à travailler sur un dépôt dans le train, ou l'avion, et de mettre ensuite à jour (sur un réseau distant) le travail qu'on a effectué sans problème.
Git gère l'intégrité par une somme de contrôle (checksum). Ceci est une signature unique et permet de sécuriser notre travail. En effet, il est impossible de modifier le contenu d'un fichier ou d'un répertoire sans que Git ne s'en aperçoive.
Voici à quoi ressemble une empreinte SHA-1:
24b9da6552252987aa493b52f8696cd6d3b00373La quasi-totalité des actions d’entre elles ne font qu’ajouter des données dans la base de données de Git. Il est très difficile de réaliser des actions qui ne soient pas réversibles.
Les trois états
Git gère trois états dans lesquels les fichiers peuvent résider : validé, modifié et indexé.
- Validé signifie que les données sont stockées en sécurité dans votre base de données locale.
- Modifié signifie que vous avez modifié le fichier mais qu’il n’a pas encore été validé en base.
- Indexé signifie que vous avez marqué un fichier modifié dans sa version actuelle pour qu’il fasse partie du prochain instantané du projet.
Installation
Sur linux (Debian), on peut essayer:
$ apt-get install git-allOu suivre le lien: https://git-scm.com/download/linux
Sur macOS, on pourra installer Xcode Comand Line Tools ou essayer:
$ git --versionOu suivre le lien: http://git-scm.com/download/mac
Sur windows, suivre le lien: http://git-scm.com/download/win
Une fois git installé, on pourra exécuté git config afin de renseigner notre identité:
$ git config --global user.name "John Doe"
$ git config --global user.email johndoe@example.comOn pourra également préciser une autre configuration pour un projet particulier grâce au drapeau (flag) --local:
$ git config --local user.name "Jane"Paramétrage
On va également pouvoir configurer notre éditeur par défaut avec la commande:
$ git config --global core.editor [editeur]
$ git config --global core.editor vimSi on souhaite voir la liste de notre configuration actuelle, on pourra écrire:
$ git config --list
user.name=John Doe
user.email=johndoe@example.com
color.status=auto
color.branch=auto
color.interactive=auto
color.diff=autoOu accéder à une valeur en particulier avec:
$ git config core.editorOu accéder au manuel d'aide de git config:
$ git config --helpLes bases de Git
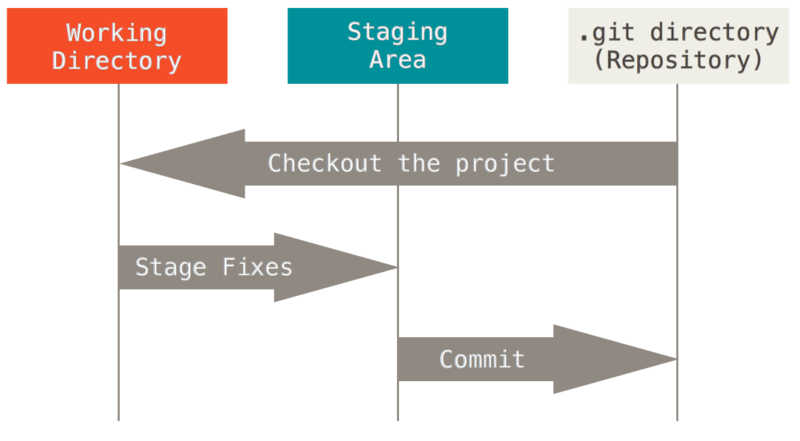
Les bases - Création du Dépôt
Pour créer un dépôt Git, il faudra naviguer dans le répertoire voulu et lancer la commande suivante:
$ git initPour commencer le versioning il faudra ensuite ajouter ces fichiers à l'index (avec git add) puis les valider, ce qui a pour effet de basculer les instantanés des fichiers de l’index dans la base de données du répertoire Git (.git).
Si on souhaite cependant cloner un dépôt existant, il faudra écrire:
$ git clone [url] [nomDeProjet]
$ git clone https://github.com/libgit2/libgit2Cela aura pour conséquence de créer le répertoire .git contenant tout les fichiers nécessaires au dépôt.
$ git add [nom-du-fichier]
$ git commitLes bases - Status
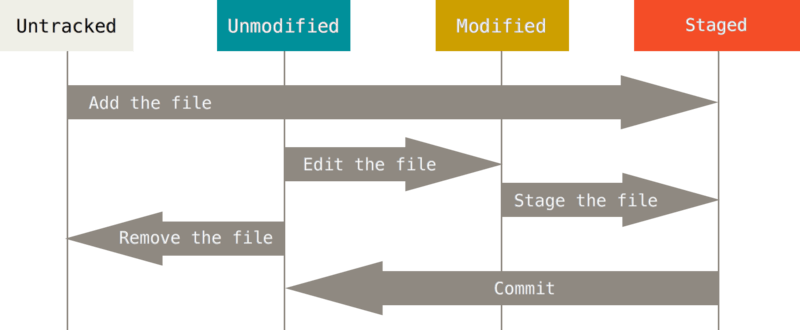
Après la création du dépôt, le statut d'un fichier est untracked (non suivi).
On peut ajouter un fichier (avec git add) pour la prochaine validation. Ce fichier est alors staged (suivi).
Après un git commit, le fichier passe alors au statut unmodified.
Si on modifie un fichier, il passe alors au statut modified et ce jusqu'au prochain git add où il sera staged.
Les bases - Status (2)
Si on fait une modification de fichier après la commande git add, sans faire de commit, alors il faudra de nouveau exécuter git add (cette commande prend un instantané).
On peut voir le statut de notre branche grâce à la commande git status:
$ git status
$ git status -sAvec le flag -s, on peut voir le statut court
Signification des caractères:
? : nouveaux fichiers non suivis
A : nouveau et indexés
M : modifiés
Colonne de gauche : état de l'index
Colonne de droite : état du dossier de travail
Les bases - .gitignore
Pour ignorer des fichiers afin qu'ils ne soient pas dans notre zone d'index, il sera plus commode de créer un fichier nommé ".gitignore". Ce fichier signalera quel fichier il faudra exclure du suivi. Pour le remplir, on peut voir l'exemple suivant:
*.[oa] -> ignore les fichiers terminant par .o ou .a
# commentaire
test/ -> répertoire
!fichier -> inclure malgré les autres règles
doc/**/*.txt -> ignorer tous les fichiers .txt sous le répertoire doc/
# ignorer uniquement le fichier TODO à la racine du projet
/TODOOn peut utiliser les RegEx dans ce fichier pour une gestion plus sensible des fichiers/dossiers à exclure. Lien de la documentation: https://git-scm.com/docs/gitignore
Les bases - Diff
La commande git diff permet de voir les modifications qui ont été apportés depuis le dernier commit mais pas encore indexés.
$ git diffUne fois les modifications indexés, celles-ci ne sont plus visible lors de la commande git diff.
Si on souhaite afficher ces dernières, il faudra utiliser le flag --staged:
$ git diff --stagedLes bases - Commit
La commande git commit a pour effet de basculer les instantanés des fichiers de l’index dans la base de données du répertoire Git (.git).
Il est possible de commenter un commit avec le flag -m, suivi d'un descriptif du travail accompli dans le commentaire:
$ git commit
$ git commit -m "Fix HTTP Status on Error"$ git commit -a
$ git commit -a -m "Add new Route - POST /comments"On peut également placer automatiquement tout fichier déjà en suivi de version dans la zone d'index (ce qui nous évite la commande git add) grâce au flag -a.
Il est possible de cumuler les flag.
Les bases - Effacement
Pour effacer un fichier, on utilisera la commande git rm - Cela effacera le fichier de la zone d'index ET de la zone de travail.
$ git rm fichier.txt
$ git rm -f fichier.txt -> forcer l'effacement du fichierSi on souhaite conserver le fichier dans sa zone de travail mais le supprimer de l'index (ex: oublie dans le gitignore) il faudra exécuter:
$ git rm --cached fichier.txt
$ git rm \*.txt -> il faut échapper le caractère *Si on on a supprimer un fichier par erreur, il est toujours possible de le récupérer:
$ git reset HEAD -> Pour le désindexer
$ git checkout -- [nom-du-fichier] -> Pour annuler le changement sur le fichier désindexéLes bases - Déplacement
Si on souhaite renommer un fichier indexé, on pourra le faire grâce à la commande git mv:
$ git mv nom_origine nom_cible
$ git mv LISEZMOI.txt LISEZMOIIl faut avoir en tête que cela est équivalent à déplacer le fichier, à supprimer le fichier précédement indexé, puis ajouter la nouvelle copie à l'index:
$ mv LISEZMOI.txt LISEZMOI
$ git rm LISEZMOI.txt
$ git add LISEZMOILes bases - Visualiser l'historique
La commance git log nous permet de visualiser l'historique des validations
$ git log
$ git log --oneline -> logs sur une seule ligne
$ git log -p -> différences entre chaque validation
$ git log [nomDeFichier] -> recherche les commits concernant ce fichier
$ git log -p -2 -> différences entre chaque validation - limite la sortie aux deux entrées les plus récentes
$ git log --stat -> avec stats
$ git log --pretty=format:"%h - %an, %ar : %s" -> affichage différent
$ git log --since=2.weeks
$ git log --before="2020-10-01"
$ git log --author='John Doe'Liens pour plus d'info concernant l'affichage:
Les bases - Annuler des actions
La commande git commit --amend nous permet de rajouter un fichier qu'on a oublier d'inclure. On aura alors qu'un seul commit.
$ git commit -m 'validation initiale'
$ git add [nomDuFichier]
$ git commit --amendSi on a ajouté un fichier par erreur, on peut le désindexer grâce à la commande git reset HEAD.
$ git reset HEAD [nomDuFichier]Si l'on souhaite annulé les changements appliqués à un fichier depuis le dernier commit, on peut le réinitialiser comme suit:
$ git checkout -- [nomDuFichier]⚠️ Attention, c’est donc un des rares cas d’utilisation de Git où des erreurs de manipulation peuvent entraîner des pertes définitives de données.
Les bases - Travailler avec les dépôts distants
Les dépôts distants sont des versions de votre projet qui sont hébergées sur Internet ou le réseau d’entreprise.
$ git clone https://github.com/user/some-project
$ cd some-project
$ git remote
origin
$ git remote -v
origin https://github.com/user/some-project (fetch)
origin https://github.com/user/some-project (push)Pour ajouter un nouveau dépôt distant, on peut faire:
$ git remote add [nomcourt] [url]Pour récupérer les fichiers depuis un dépôt distant, on peut utiliser:
$ git fetch [nomcourt]Et si l'on souhaite fusionner le contenu avec notre répertoire courant, il faudra faire:
$ git merge
Ou alors utiliser
$ git pull [url]Les bases - Travailler avec les dépôts distants (2)
Afin de mettre en ligne le travail effectué, il faudra utiliser la commande git push. Cependant cela n'est possible qu'après un git clone et si on dispose des droits nécessaires.
git push [nom-distant] [nom-de-branche]
$ git push origin masterIl est également possible de renommer des dépôts distants:
$ git remote rename [nomActuel] [nomModifié]Ou encore, de le supprimer:
$ git remote rm [nomCourt]
$ git remote
originSi entre temps un autre push a été fait sur la branche, il faudra d'abord effectuer un git pull.
Les bases - Tags
Il est possible d’étiqueter un certain état dans l’historique comme important. Cela est notamment fait pour donner des numéros de versions à nos commit. Pour voir les étiquette, on fera:
$ git tag
v1.3Pour étiqueter un commit passé:
$ git tag v1.2 9fceb02Et pour créer un étiquette:
$ git tag v1.4
$ git tag -a v1.4 -m 'ma version 1.4'Par défaut, git ne push pas les étiquettes sur le serveur. Pour le faire, il faudra écrire:
$ git push origin [nom-du-tag]Il est aussi possible de rechercher un commit avec son étiquette:
$ git show v1.2
// Ou plusieurs commits
$ git tag -l 'v1.8.5*'Les bases - Alias
Il n'y a pas d'autocomplétion avec git, en revanche, il est possible de créer des alias pour éviter d'avoir à taper l'intégralité de la commande. Pour créer un alias, il faudra écrire:
$ git config --global alias.[nom-de-l'alias] [commande]
$ git config --global alias.co checkout
$ git co 9fceb02 -> sera équivalent à: git checkout 9fceb02Pour afficher le dernier commit:
$ git config --global alias.last 'log -1 HEAD'
$ git lastAlias pour désindexer un fichier:
$ git config --global alias.unstage 'reset HEAD --'
$ git unstage fileAVous pouvez créer autant d'alias que vous souhaitez.
Les branches avec Git
Branches - Définition
Créer une branche signifie diverger de la ligne principale de développement et continuer à travailler sans impacter cette ligne.
Pour créer une nouvelle branche, il suffira d'écrire:
$ git branch [nom-de-la-branche]
$ git branch develop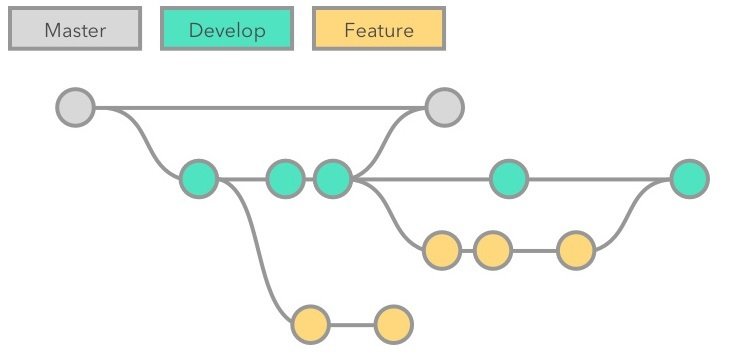
Cela aura pour effet de créer un nouveau pointeur appelé develop qui pointera vers le dernier commit de la branche master.
Branches - Définition (2)
Comment git sait sur quelle branche on se trouve? Grâce au pointeur HEAD qui pointe sur la branche sur laquelle on se trouve.
On peut voir sur quelle branche on se trouve grâce à git log avec le flag --decorate:
$ git log --oneline --decorate
f30ab (HEAD -> master, testing) add feature #32 - ability to add new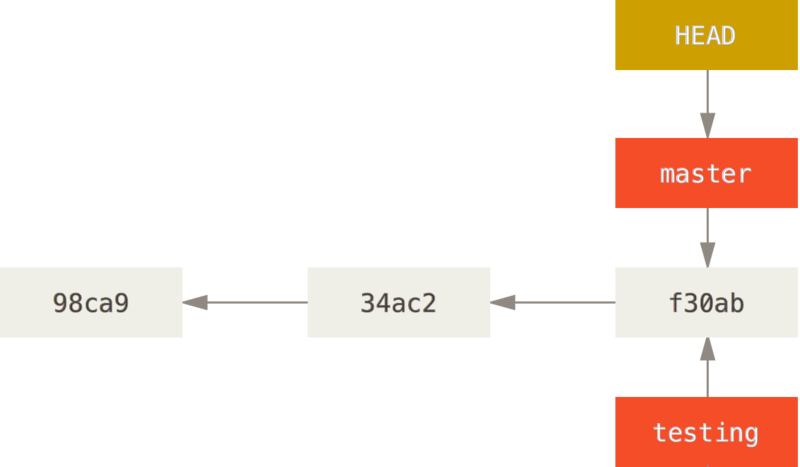
Basculer entre les branches
Pour basculer sur une branche existante, il suffit de lancer la commande git checkout.
$ git checkout [nom-de-la-branche]
$ git checkout testing
Switched to branch 'testing'Désormais, chaque commit sur cette branche fera avancer testing tandis que master pointera vers le même commit (f30ab).
Après avoir changé de branche, HEAD pointe désormais sur la nouvelle branche (testing).
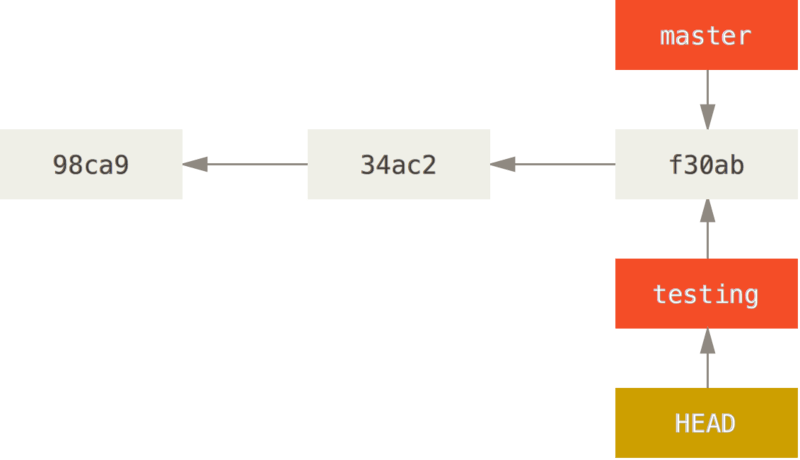
Branches et fusions
Prenons un exemple pour comprendre l'intérêt des branche. Considérons la branche master comme la branche d'un site web en production. Si on souhaite ajouter une nouvelle fonctionnalité (une messagerie par exemple) on va créer une nouvelle branche pour le faire:
$ git branch messagerie
$ git checkout messagerie
Switched to branch 'messagerie'Alors qu'on travaille sur la messagerie, un bug vient d'être remonté sur notre site. On va alors créer une branche pour appliquer un correctif au plus vite:
$ git checkout master
Switched to branch 'master'
$ git checkout -b correctif-34
Switched to branch 'correctif-34'Ou alors, on peut créer une nouvelle branche et basculer sur cette dernière avec le flag -b:
$ git checkout -b messagerie
Switched to a new branch "messagerie"Branches et fusions (2)
$ git checkout master
Switched to branch 'master'
$ git merge correctif
Updating f42c576..3a0874c
Fast-forwardAprès trouver le correctif, on peut maintenant fusionner notre branche correctif avec notre branche master, et retourner travailler sur notre branche messagerie.
Si le commit du correctif se trouve directement devant le dernier commit de la branche master, alors git peut faire une fusion des branches (car on sait qu'il n'y aura pas de conflits). Dans ce cas, on est dans une situation d'avance rapide dans les commits (fast-forward).
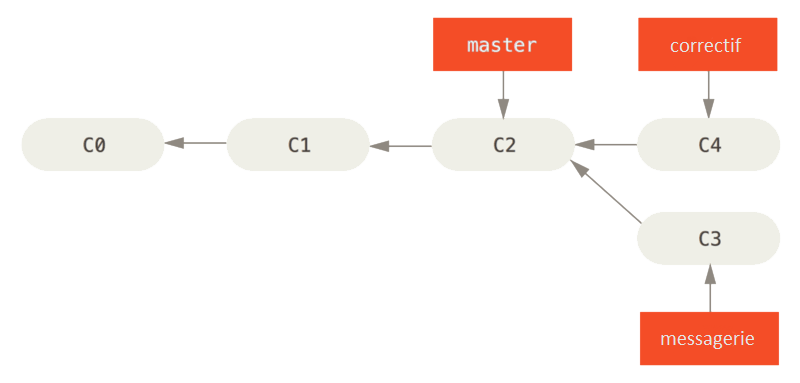
Branches et fusions (3)
$ git branch -d correctif
Deleted branch correctif (3a0874c).Maintenant qu'on a appliqué notre correctif sur la branche master, on peut supprimer notre branche correctif. Pour ce faire, on utilisera le flag -d à la commande git branch:
Si on souhaite rapatrier le correctif appliqué à la branche master sur la branche messagerie, il faudra exécuter:
$ git checkout messagerie
Switched to branch 'messagerie'On va pouvoir retourner sur la branche messagerie où se trouve le travail en cours sur cette fonctionnalité.
$ git merge master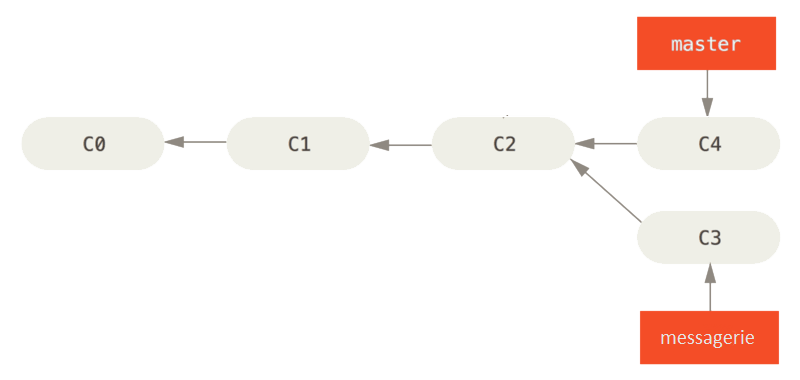
Branches et fusions (4)
$ git checkout master
Switched to branch 'master'
$ git merge messagerie
Merge made by the 'recursive' strategy.Si on décide de faire la fusion plus tard, après effectuer un commit supplémentaire, notre situation sera différente (la branche master à avancé par rapport à l’ancêtre commun. Dans ce cas, Git réalise une simple fusion à trois sources (three-way merge)
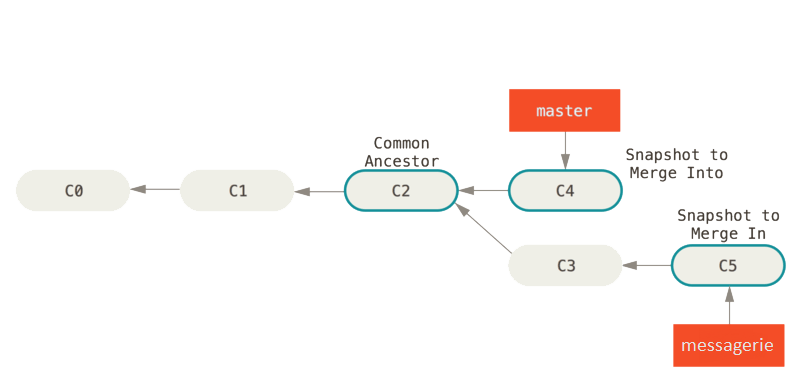
Branches et fusions (5)
Au lieu d’avancer simplement le pointeur de branche, Git crée un nouvel instantané qui résulte de la fusion à trois sources et crée automatiquement un nouveau commit qui pointe dessus. On appelle ceci un commit de fusion (merge commit) qui est spécial en cela qu’il a plus d’un parent.
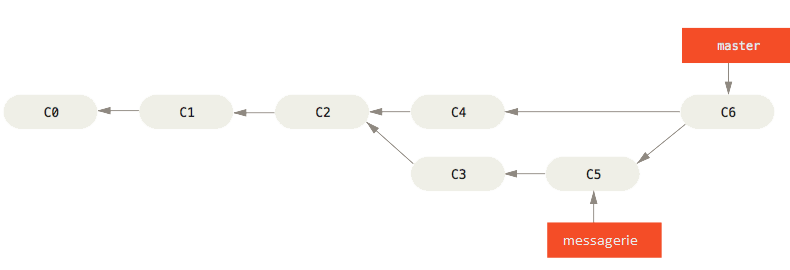
$ git branch -d messagerieUne fois notre travail fusionné, on peut supprimer la branche messagerie:
Conflits de fusion
Quelques fois, il n'est pas possible à git de faire la fusion des fichiers si on a modifié différemment la même partie du même fichier dans les deux branches qu'on souhaite fusionner. Dans ce cas il faudra résoudre les conflits manuellement.
$ git merge messagerie
Auto-merging index.html
CONFLICT (content): Merge conflict in index.html
Automatic merge failed; fix conflicts and then commit the result.
Dans ce cas, il faudra explorer les fichiers et choisir quelle modification garder.
Une fois les conflits sur un fichier résolus,
il faudra exécuter:
$ git add index.html
$ git commit -m "résolution de conflits entre messagerie et master"Éviter les conflits
Pour éviter les conflits, on pourra:
- utiliser des retours à la ligne
- éviter de travailler sur les mêmes fichiers
- séparer les fonctionnalités en différents fichiers
- se répartir le travail par tâches/features
- commiter régulièrement
- faire des branches à courte durée de vie

Gestion des branches
La commande git branch sans argument permet d'obtenir la liste des branches ainsi que la branche courante (*).
$ git branch
* master
backlog-55Avec le flag -v on peut afficher le dernier commit de chaque branche.
Le flag --merged permet de visualiser les branches déjà fusionnées avec la branche courante.
Le flag --no-merged, affiche les branches qui n'ont pas encore été fusionnés avec la branche courante.
$ git branch -v
messagerie 93b412c ajout fonctionnalité envoi et réception de messages
* master 7a98805 résolution de conflits entre messagerie et master
dev fe9d10 ajout test unitaire
$ git branch --merged
messagerie 93b412c ajout fonctionnalité envoi et réception de messages
* master 7a98805 résolution de conflits entre messagerie et master
$ git branch --no-merged
dev fe9d10 ajout test unitaire
Structure des branches
Maintenant que l'on sait travailler avec les branches, on peut se demander quand créer une branche. L'une des structure proposée par git est la branche au long cours.
On créer une branche par degré de stabilité:
Lorsque des fonctionnalités sont stables, on les passe de la branche develop à la branche master. Ici on peut considérer la branche topic comme une branche expérimentale.
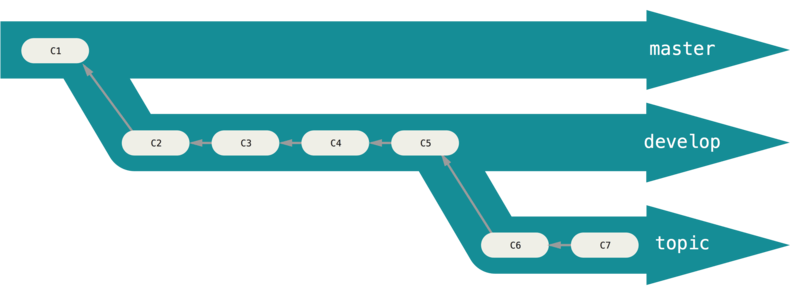
Structure des branches (2)
L'autre solution est d'avoir des branches thématiques, ou des branches à courte durée de vie. On créer une branche pour ajouter une fonctionnalité ou une tâche particulière. Une fois que l'objectif de la branche est atteint, on fusionne la branche avec la branche master.
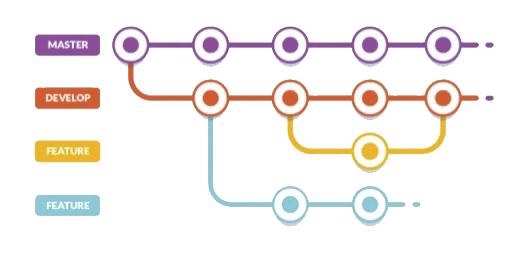
Branches et serveur distant
Etude de cas
Lorsqu'on clone un répertoire depuis un serveur distant, la branche distante aura, par défaut, le nom origin.
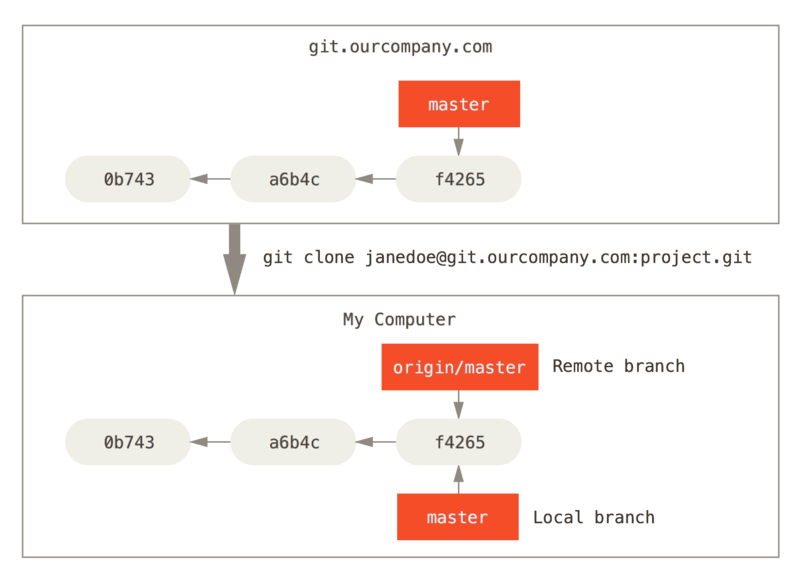
Etude de cas (2)
On travaille alors sur notre branche en local, mais si la branche sur le serveur distant est mise à jour, notre répertoire local ne le sera pas pour autant...
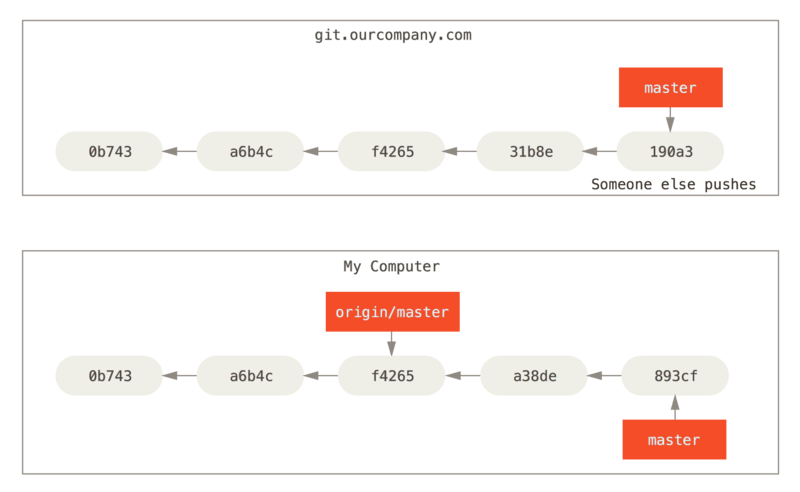
Etude de cas (3) - git fetch
Pour mettre à jour notre répertoire local avec les changements du répertoire distant, on pourra exécuter:
$ git fetch origin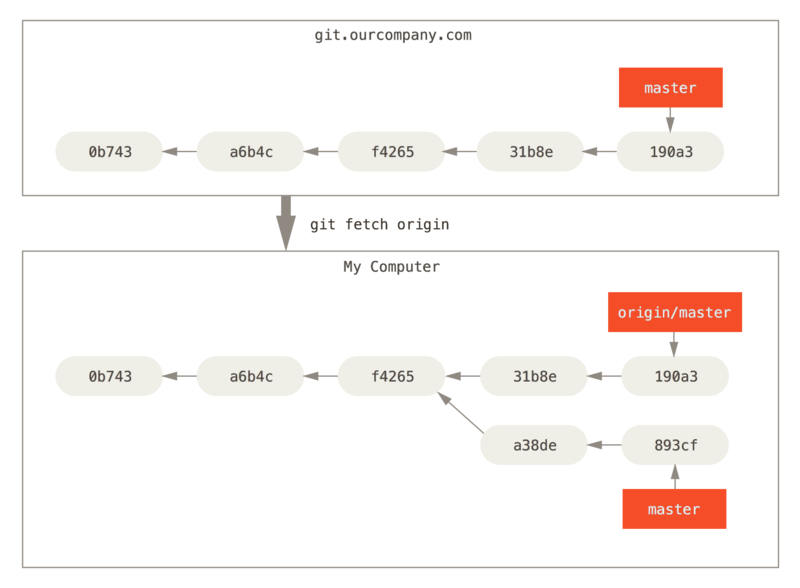
Si on souhaite ensuite appliquer les changements à notre répertoire local, il faudra alors faire un git merge.
git merge
Si on a besoin de fusionner la branche distante avec notre branche actuelle (en local), on pourra le faire comme suit:
$ git merge [nom-du-remote]/[nom-de-la-branche]
$ git merge origin/correctionserveurSi vous souhaitez créer votre propre branche correctionserveur pour pouvoir y travailler, vous pouvez faire qu’elle repose sur le pointeur distant :
$ git checkout -b correctionserveur origin/correctionserveur
Branch correctionserveur set up to track remote branch correctionserveur from origin.
Switched to a new branch 'correctionserveur'
// Equivalent
$ git checkout --track origin/correctionserveur
// Avec un nom différent
$ git checkout -b [nom-different] origin/correctionserveur
$ git checkout -b cs origin/correctionserveur
Branch cs set up to track remote branch correctionserveur from origin.
Switched to a new branch 'cs'git push
Si on souhaite désormais partager le travail effectué en local sur une nouvelle branche du serveur distant, on pourra le faire avec:
$ git push origin [nom-de-la-branche-distante]
$ git push origin [nom-de-la-branche-locale]:[nom-de-la-branche-distante]
$ git push origin correctionserveur
Counting objects: 24, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (15/15), done.
Writing objects: 100% (24/24), 1.91 KiB | 0 bytes/s, done.
Total 24 (delta 2), reused 0 (delta 0)
To https://github.com/schacon/simplegit
* [new branch] correctionserveur -> correctionserveurGit va ainsi créer une nouvelle branche avec le travail qu'on aura accompli.
Une fois ceci effectué, un collaborateur pourra récupérer notre branche, en faire une copie, et la modifier au besoin.
Flag -u / -vv
Si on a déjà une branche locale et qu'on veut l’associer à une branche distante qu'on vient de récupérer ou qu'on veut changer la branche distante qu'on suit, on peut ajouter l’option -u ou --set-upstream-to à la commande git branch à tout moment.
$ git branch -u origin/correctionserveur
Branch correctionserveur set up to track remote branch correctionserveur from origin.Par la suite, lorsqu'on fera un git push ou un git pull, on le fera sur la branche distante (celle-ci est appelé upstream branch). Notre branche locale est quant à elle appelé tracking branch.
Si on souhaite avoir des informations sur la branche de suivi, on pourra exécuter:
$ git branch -vv
master 1ae2a45 [origin/master] deploying index fix
* correctionserveur f8674d9 [equipe1/correction-serveur-ok: ahead 3, behind 1] correction doneahead montre combien de commit locaux n'ont pas été poussé sur le serveur, et behind montre combien de commit n'ont pas été intégrés à notre branche locale.
Pulling - Suppression
Si on souhaite faire un git fetch suivi immédiatement d'un git merge, alors on peut à la place de ces deux commandes effectuer un git pull:
$ git pull [remote] [nom-de-la-branche]
$ git pull origin correctionserveurSi on souhaite supprimer une branche distante - car, par exemple, le travail effectué dessus a été fusionné avec une autre branche - on peut alors ajouter l'option --delete à la commande git push:
$ git push origin --delete correctionserveur
To https://github.com/schacon/simplegit
- [deleted] correctionserveurRebase
Rebase - Concept
Dans Git, il y a deux façons d’intégrer les modifications d’une branche dans une autre : en fusionnant (merge) et en rebasant (rebase).
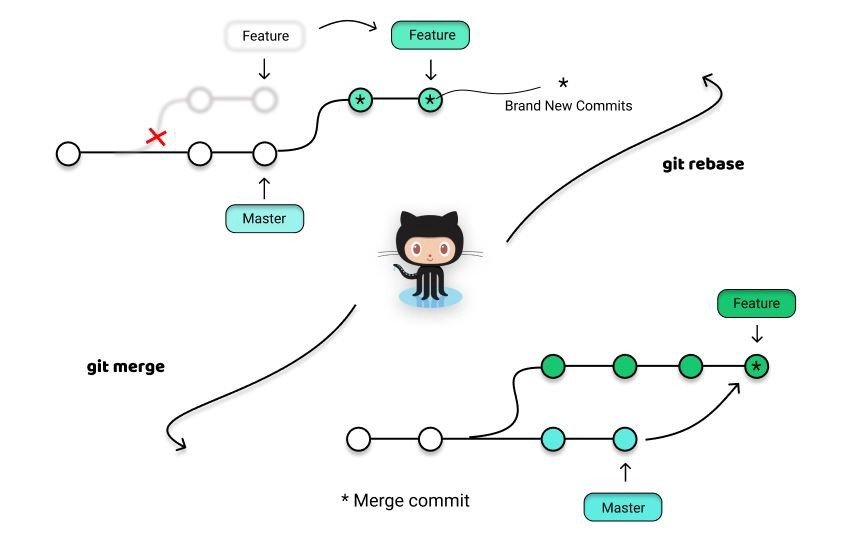
Rebase - Commande
Si on souhaite faire un rebase de master dans feature, on devra faire comme suit:
$ git checkout [branche-de-destination]
$ git rebase [branche-a-fusionner]
$ git checkout feature
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged command
$ git checkout master
$ git merge featureCela va rejouer tout les commits de la branche courante (feature) dans la branche de destination (master), et ce, dans le même ordre.
git rebase permet donc de rendre l'historique plus clair.
Rebase - Étude de cas
On a ici deux branches thématiques. On a travaillé aussi bien sur la partie client que la partie server, mais on ne souhaite que release la partie client pour la mettre en production. On pourra le faire comme suit:
$ git rebase --onto master server client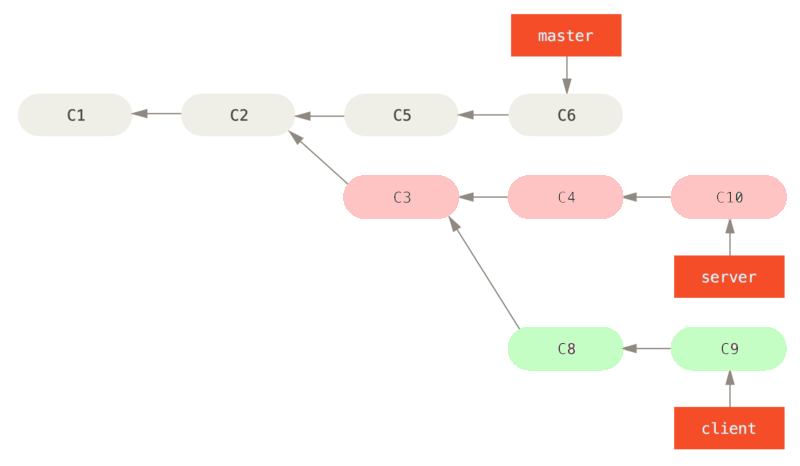
Rebase - Étude de cas (2)
Il faudra maintenant faire une avance rapide sur la branche master:
$ git checkout master
$ git merge client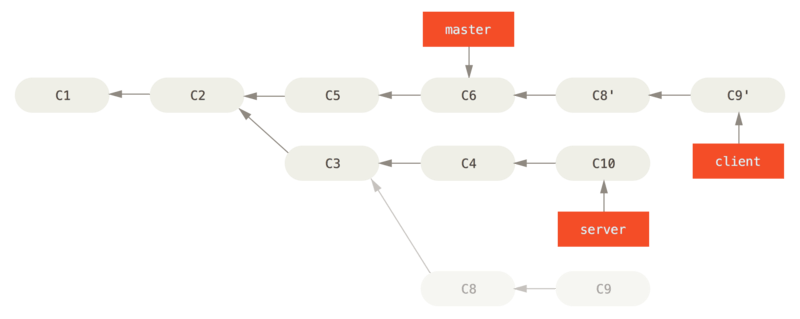
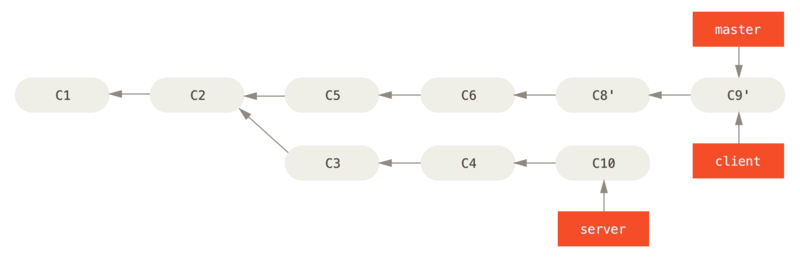
Rebase - Quand l'utiliser
Quand faire un merge-commit?
- Sur les branches durables
- Pour indiquer un fait marquant (release version, mise en production...)
Le merge-commit n'apporte en soi aucune nouvelle information...
Quand faire un rebase?
- Lors de l'acceptation d'un pull request d'une feature
- Pour nettoyer des commits fait localement
- Lors d'un git pull (--rebase)
Quand éviter de faire un rebase?
- lorsque plusieurs personnes travaillent sur la même branche
Stash
git stash
Reprenons l'exemple où on travaille sur une branche, et on nous demande de régler un problème sur une autre branche. Cependant, notre travail n'est pas "propre" et on ne souhaite pas faire un commit en l'état. On peut alors remiser/stasher notre travail afin de le reprendre plus tard:
$ git stashPour obtenir la liste de ce qui est dans notre stash:
$ git stash applyPour ensuite appliquer le contenu de notre dernier stash dans une branche, il faudra écrire:
$ git stash listOu pour appliquer un stash plus ancien:
$ git stash apply stash@{n}Une fois la stash appliqué, il faut la supprimer avec:
$ git stash dropgit stash (2)
Par défaut, git stash ne stash que les fichiers qui sont suivis. Si on souhaite aussi stasher des fichiers non suivis, il faudra appliquer le flag -u (ou --include-untracked):
$ git stash -uSi on souhaite garder l'index lors de l'application du git stash, il faudra ajouter le flag --index:
$ git stash apply --indexPour appliquer une stash et la supprimer, on pourra utiliser:
$ git stash popSi au contraire, on ne souhaite pas garder les fichiers qui sont déjà présent dans l'index (au moyen de git add), on faire le faire avec:
$ git stash --keep-indexgit stash-unapply
Si on souhaite défaire un remise, il n'existe pas de commande unapply, mais on va pouvoir la créer comme suit (avec un alias):
$ git stash
$ #... travail, travail, travail
$ git stash-unapplyPuis pour l'utiliser:
$ git config --global alias.stash-unapply '!git stash show -p | git apply -R'
Les changements appliqués entre stash et stash-unapply seront quant à eux conservés.
Créer une branche depuis une stash
Si on souhaite créer une branche à partir de modifications qui avaient été remisés, on peut le faire à l'aide de la commande:
$ git stash branch [nom-de-la-branche]
Cela créera une nouvelle branche à notre place, récupérant le commit où nous étions lorsqu'on a créé la remise, ré-appliquera notre travail dedans, et supprimera la remise si cela a réussi.
Autres commandes
Clean
Si on a dans notre dépôt énormément de fichiers et/ou dossiers non suivis que l'on souhaite supprimer de notre espace de travail, on peut le faire avec la commande git clean.
Mais d'abord, on veut pouvoir afficher/lister ces fichiers avec le flag -n, et les dossiers avec le flag -d:
$ git clean -n -dPour supprimer de façon effective, on utilisera le flag -f.
Si on ne souhaite supprimer que les fichiers on écrira:
$ git clean -f -dSi on souhaite supprimer les fichiers et les dossiers, on écrira:
$ git clean -fReset - Soft
La commande git reset permet d'annuler le travail que l'on a fait et de revenir à un commit précédent ou a un état d'un fichier en particulier.
Un soft reset ne fait que déplacer ce qui est pointé par HEAD.
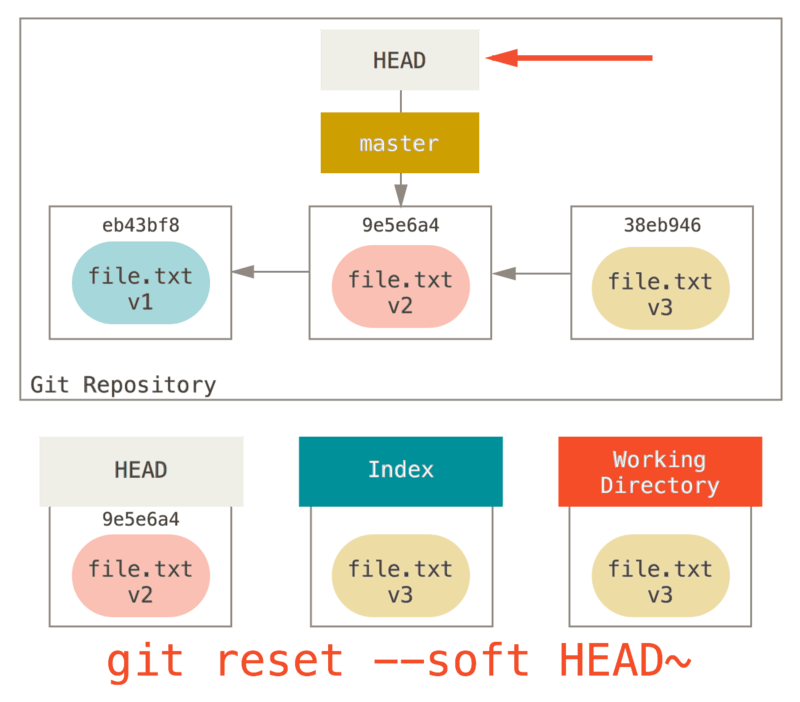
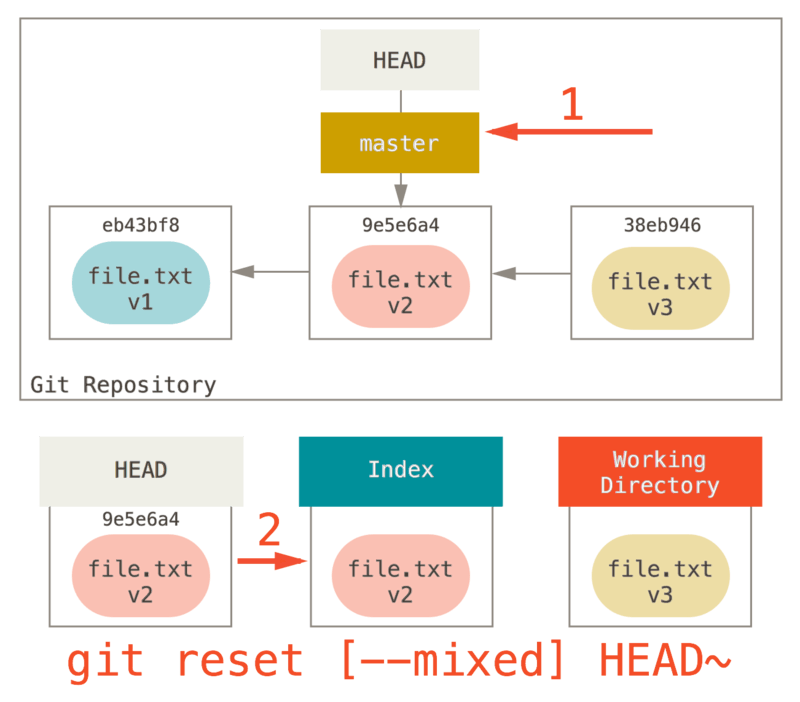
Reset - Mixed
Un mixed mettra à jour HEAD et l'index. Mixed est le comportement par défaut (équivalent à git reset HEAD^).
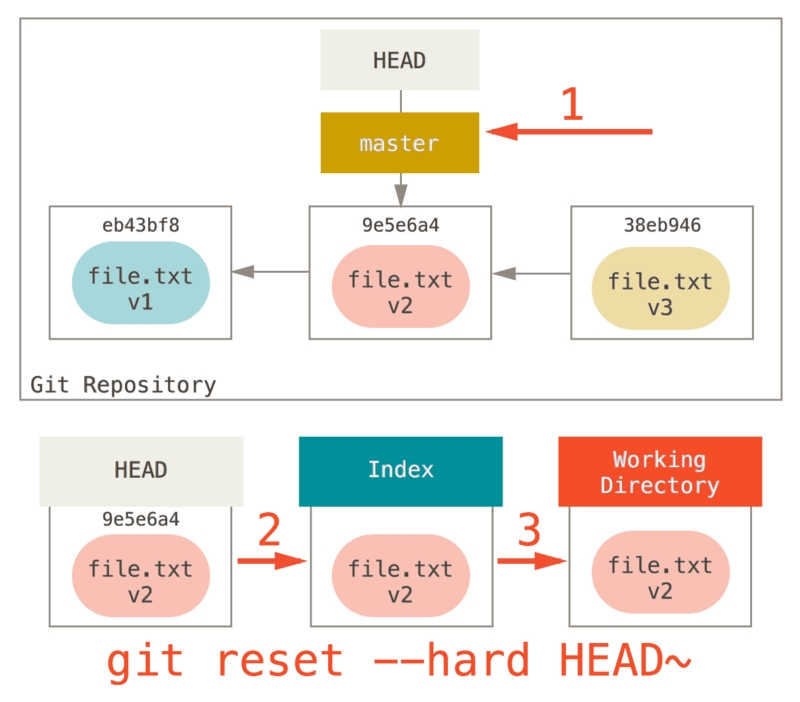
Reset - Hard
En général, on utilise un git reset --hard lorsqu'on pensait avoir une idée de génie... mais en fait non, et on souhaite revenir à une commit donné.

Reflog
Cette commande permet de voir toutes les commandes qui ont étés exécutées et est donc utile pour annuler un git reset par exemple, nous donnant la référence qu'on ne pourrait plus avoir avec un git log:
$ git reflog
8b5b449 (HEAD -> master) HEAD@{0}: reset: moving to HEAD^
17f7149 HEAD@{1}: reset: moving to HEAD^
$ git reset 'HEAD@{1}'Plus d'informations sur cette commande:
$ git reflog show [nom-de-la-branche]
$ git reflog show masterVoir uniquement les reflog d'une branche en particulier:
GitHub Pages
Déployer une page sur Git
Il est également possible de déployer un site statique sur github. Pour ce faire il faudra:
- Déployer le site dans un repository
- Une fois que notre repo a une page index.html aller dans l'onglet Settings de notre projet
- Parcourir la page jusqu'à GitHub Pages
- Sélectionner le branche que l'on souhaite déployer et cliquer sur Save
- Attendre la fin du déploiement pour obtenir le lien
- Contempler son travail 🤩

(point 2)
Git
By Fabio Ginja
Git
Slides de formation Juillet 2020




