正则表达式
什么是正则表达式
Regular Expression (regex / regexp)
正则表达式:一种描述文本规则的表达式
- Regular 表示规则、规律之意
- Expression 即表达式
另一个与正则类似的东西:通配符
*.doc 匹配 .doc / 1.doc / 12.doc / ...
1000? 匹配 1000a / 10000 / 10009 / ...
区别在于:正则表达式功能更强大(语法更复杂)
用正则做什么?
- 检测字符串是否符合某种规则
- 替换字符串
很多软件、编程语言都支持正则
- Sublime Text / VIM / Notepad++
- Python / JavaScript / Java / Perl
方便起见,我们在 Sublime Text 上试试
如何在 Sublime 里使用
搜索 & 替换
开启正则功能
是否大小敏感
匹配单词
1. 用 hi 匹配 hi
2. 用 hi 匹配 hi / HI / Hi / hI
某些单词里包含hi这两个连续的字符,比如him,history,high
3. \bhi\b (\b 指的是边界 boundary)
\b是一个特殊代码(也叫元字符,metacharacter)
代表着单词的开头或结尾,也就是单词的分界处。
虽然通常英文的单词是由空格,标点符号或者换行来分隔的
但是\b并不匹配任何字符,它只匹配一个位置。
匹配任意字符
hi后面不远处跟着一个Frank,应该用\bhi\b.*\bFrank\b 表示
.是另一个元字符,匹配除了换行符以外的任意字符。
*是元字符,不过它代表的不是字符,也不是位置,而是数量——*前边的内容可以连续重复使用任意次
.*连在一起就意味着任意数量的不包含换行的字符
更多元字符
0\d\d-\d\d\d\d\d\d\d\d 以0开头,然后是两个数字,然后是一个连字号“-”,最后是8个数字
为了避免那么多烦人的重复,我们也可以这样写:0\d{2}-\d{8}
\d 匹配一个一位数字(0到9)
更多元字符
\s 匹配任意的空白符,包括空格、制表符(Tab)、换行符、中文全角空格等
\ba\w*\b
匹配以字母a开头的单词——先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)。
\d+
匹配1个或更多连续的数字。这里的+是和*类似的元字符,不同的是*匹配重复任意次(可能是0次),而+则匹配重复1次或更多次。
\b\w{6}\b
匹配刚好6个字符的单词。
\w匹配一个字母或一个一位数字或一个下划线
更多元字符 - 起始和结束
元字符^和$都匹配一个位置,这和\b有点类似。
^匹配你要用来查找的字符串的开头,
$匹配结尾。
注意:$是否跨行是可以配置的。
这两个代码在验证输入的内容时非常有用,比如一个网站如果要求你填写的QQ号必须为5位到12位数字时,可以使用:^\d{5,12}$。
这里的{5,12}和前面介绍过的{2}是类似的,只不过{2}匹配只能不多不少重复2次,{5,12}则是重复的次数不能少于5次,不能多于12次,否则都不匹配。
因为使用了^和$,所以输入的整个字符串都要用来和\d{5,12}来匹配,也就是说整个输入必须是5到12个数字,因此如果输入的QQ号能匹配这个正则表达式的话,那就符合要求了。
小结
\b
^
$
.
\d
\w
\s
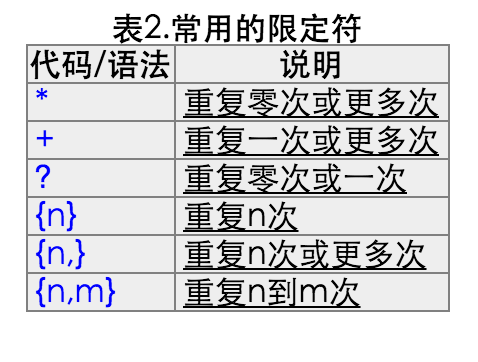
*
+
{2}
{5,12}
{0,12} {2,}
限定符
转义
. 是元字符,那么我怎么匹配一个真正的英文句号呢?
这时我们可以使用\来取消这些字符的特殊意义。
应该使用\.和\*和匹配.和*。
要查找\本身,就得用\\.
例如:
deerchao\.net匹配deerchao.net
C:\\Windows匹配C:\Windows
重复
字符组合
要想查找数字,字母或数字,空白是很简单的,因为已经有了对应这些字符集合的元字符:\d \w \s
但是如果你想匹配没有预定义元字符的字符集合(比如0到7),该怎么办?
很简单,你只需要在方括号里列出它们就行了
[01234567]匹配0到7之中任意一个数字
[.?!]匹配标点符号.或?或!
注意:方括号里面的.与外面的.含义不同
我们还可以指定字符范围
[0-9]代表的含意与\d就是完全一致的
[a-z0-9A-Z_]等同于\w
或
0\d{2}-\d{8}|0\d{3}-\d{7}
这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)
13812345677|8
13812345677|13812345678
要注意或两边的范围
分组
之前提到了如何重复单个字符;
但如果想要重复多个字符又该怎么办?比如重复多次 abc
(\d{1,3}\.){3}\d{1,3}是一个简单的IP地址匹配表达式。
(abc)+
一个正确的IP地址:
(0|1?[1-9]\d|2[0-4][0-9]|25[0-5]\.){3}0|1?[1-9]\d|2[0-4][0-9]|25[0-5]
被括号括起来的叫:子表达式
反义

例子:
\S+匹配不包含空白符的字符串。
<a[^>]+>匹配用尖括号括起来的以a开头的字符串。
引用
每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
\1代表分组1匹配的文本
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, 或者kitty kitty。
\b(\w+)\b\s+\1\b不同于 \b(\w+)\b\s+(\w+)\b
断言
指定一个位置,这个位置应该满足一定的条件,如 \b 和 ^ 和 $
(?=exp)
比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc
贪婪与懒惰
当正则表达式中包含能接受重复的限定符时,通常的行为是匹配尽可能多的字符。
例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。
如果用它来搜索aabab的话,它会匹配到aabab。这被称为贪婪匹配。
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。
只要在限定符后面加上一个问号? 就能做到。
例:.*?意味着匹配任意数量的重复,但是使用最少次数的重复
正则表达式30分钟入门教程
http://deerchao.net/tutorials/regex/regex.htm
更多知识,请看
在JS里使用正则
var regexp = /\w+/igm
regexp.test(string) : bool
regexp.exec(string) : array?
string.replace(regexp, newString | function)
动态页面串讲
一个增删改查页面
下节课
正则表达式
By 方方



