Distributed Deep Learning and Transfer Learning with Spark, Keras and DLS

Favio Vázquez
Data Scientist


@faviovaz
Webinars

Eric Feuilleaubois
Phd in Artificial Neural Networks
@Deep_In_Depth
Introduction to Transfer Learning with Convolutional Neural Networks
Webinars
Deep Learner / Machine Learner
Curator of Deep_In_Depth - news feed on Deep Learning, Machine Learning and Data Science
Writer for Medium - Towards data science
Eric Feuilleaubois
Phd in Artificial Neural Networks
@Deep_In_Depth
Principle of Transfer Learning

Aim: Predict classes (labels) that have not been seen by the source (pre-trained) model
ImageNet Dataset
n07714571 - head cabbage
n07714990 - broccoli
n07715103 - cauliflower
n07716358 - zucchini, courgette
n07718472 - cucumber, cuke
n07718747 - artichoke, globe artichoke
n07720875 - bell pepper
n07730033 - cardoon
n07734744 - mushroom
n07742313 - Granny Smith
n07745940 - strawberry
n07747607 - orange
n07749582 - lemon
n07753113 - fig
n07753275 - pineapple, ananas
n07753592 - banana
n07768694 - pomegranate
- 1,000 image categories
- Training - 1,2 Million images
- Validation & test - 150,000 images
Veg Dataset - 4124 records



Pumpkin
Tomato
Watermelon






Motivations for CNN TL
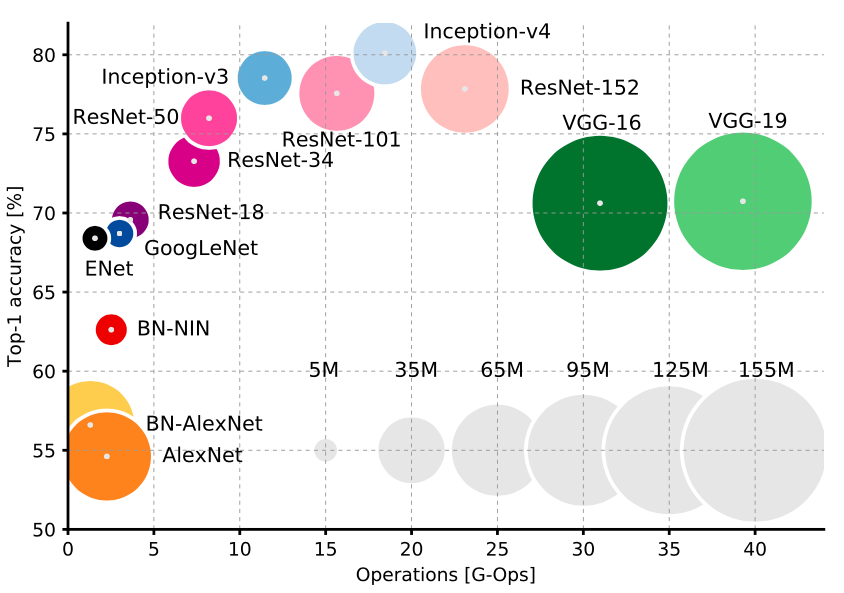
- Availability of Open CNN Models with Top class performance
CNN Transfer Learning
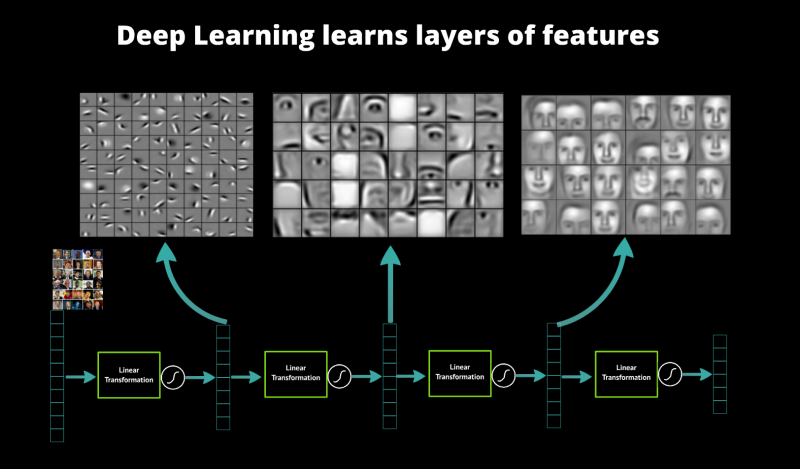
Proof by Features
- CNNs detect visual features (patterns) in images
- First layers learn "basic" features
- Last layers learn "advanced" features
- Top layers classify
Basic features are very similar from one CNN model to another --> No need to
re-learn them, best to re-use them
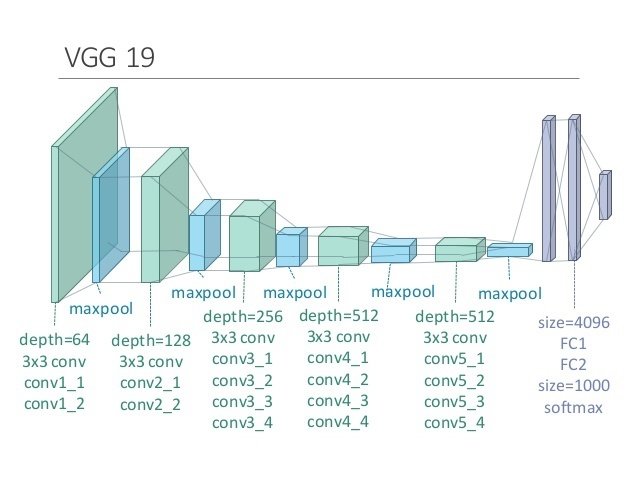
DL model with pre-trained VGG16

Training results
| Dataset | Train Acc. (%) |
Validation Acc. (%) |
|---|---|---|
| 300 - 7% | 95 | 88 |
| 600 - 14% | 96 | 89 |
| 900 - 21% | 97 | 90 |
| 3917 - 95% | 97 | 91 |
| 300 - with Data Aug. | 98 | 88 |
| 600- with Data Aug. | 98 | 90 |
| 900- with Data Aug. | 98 | 90 |
Wrong results

300 - 600 - 900
WaterMelon

Pumpkin

300 - 600 - 900
WaterMelon
300 - 600
Training Dataset
Result for "difficult" images
Pumpkin

WaterMelon
Tomato

300 - 600 - 900
300 - 600 - 900
300 - 600 - 900
Fine-tuning TL models
Two approaches:
1) Fine tune the convolutional part of the CNN
- Retrained the last convolutional layer (Deep Learning Studio provide easy way to do it)
- Freezing and training specific layers
2) Fine tune the classification part of the CNN
- Classification architecture optimisation
- number of neuron in the classification layers
- Hyper-parameter optimization
Simpler DL model with pre-trained VGG16

Training results
| Dataset | Train Acc. (%) |
Validation Acc. (%) |
|---|---|---|
| 300 - Simpler | 99 | 88 |
| 300 - 512 - 64 | 99 | 86 |
| 300 - MSimpler-no BN | 98 | 84 |
| 300 - Simpler VGG 10% trainable |
99 | 89 |
| 3917 - 95% - Simpler | 98 | 93.5 |
| 95% - MSimpler-no BN | 40 | 35 |
| 95% - MSimpler- BN | 97 | 92 |
Benefits of CNN
Transfer Learning
- Dataset does not need to be huge
- Save time and effort
- no CNN architecture search
- training phase faster
- less computing power needed
- Produce very good models that can then be fine tune
- Can be applied to very diverse classification problem
And drawbacks:
- need a fair amount of memory on GPU
- not fully tunable with Keras
Distributed Deep Learning with Spark, Keras and DLS
Favio Vázquez
Data Scientist
@faviovaz

https://github.com/faviovazquez
https://www.linkedin.com/in/faviovazquez/

Webinars
Outline

Timeline
Fundamentals of Apache Spark
Deep Learning Pipelines
Apache Spark on Deep Cognition
Apache Spark
Favio Vázquez

About me
- Venezuelan
- Physicist and Computer Engineer
- Master in Physics UNAM
- Data Scientist
- Collaborator of Apache Spark project on GitHub and StackOverFlow
- Principal Data Scientist at Oxxo
- Chief Data Scientist at Iron
- Main Developer of Optimus
- Creator of Ciencia y Datos

Favio Vázquez
- Very active member of LinkedIn ;)
- Editor - International Journal of Business Analytics and Intelligence
- Lecturer Afi (Data Science program-MX)
- Writer in Towards Data Science, Becoming Human, Planeta Chatbot and more :)

About me

Favio Vázquez


2004 – Google
MapReduce: Simplified Data Processing on Large Clusters
Jeffrey Dean and Sanjay Ghemawat research.google.com/archive/mapreduce.html
2006 – Apache
Hadoop, originating from the Nutch Project
Doug Cutting research.yahoo.com/files/cutting.pdf
2008 – Yahoo
web scale search indexing
Hadoop Summit, HUG, etc. developer.yahoo.com/hadoop/
2009 – Amazon AWS
Elastic MapReduce
Hadoop modified for EC2/S3, plus support for Hive, Pig, Cascading, etc. aws.amazon.com/elasticmapreduce/
Favio Vázquez
What is Spark?
Is a fast and general engine for large-scale data processing.





Favio Vázquez
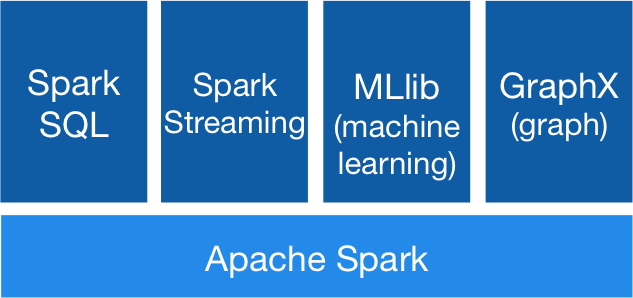
Unified Engine
High level APIs with space for optimization
- Expresses all the workflow with a single API
- Connects existing libraries and storage systems
Favio Vázquez
RDD
Transformations
Actions
Caché
Dataset
Tiped
Scala & Java
RDD Benefits
Dataframe
Dataset[Row]
Optimized
Versatile
Favio Vázquez

Deep Learning Pipelines
Deep Learning Pipelines is an open source library created by Databricks that provides high-level APIs for scalable deep learning in Python with Apache Spark.

Favio Vázquez
Apache Spark on Deep Cognition
Favio Vázquez
Apache Spark on Deep Cognition
- How to load an image to Apache Spark
- How to apply pre-trained models as transformers in a Spark ML pipeline
- Transfer learning with Apache Spark
- Deploying models in DataFrames and SQL
We will learn:


Favio Vázquez
Favio Vázquez
Competition and Prices!!
Take my article on Detecting Breast Cancer with Deep Learning, and using DLS solve it by yourselves!
Create a post or blog, and the top 10 will win $50 Amazon gift card each



DEMO
Favio Vázquez
Distributed Deep Learning and Transfer Learning with Spark, Keras and DLS
By Favio Vazquez




