











federica bianco
astro | data science | data for good
dr.federica bianco | fbb.space | fedhere | fedhere
Tree methods
what is machine learning
classification
prediction
feature selection
supervised learning
understanding structure
organizing/compressing data
anomaly detection dimensionality reduction
unsupervised learning
clustering
PCA
Apriori
k-Nearest Neighbors
Regression
Support Vector Machines
Classification/Regression Trees
Neural networks
Clustering
partitioning the feature space so that the existing data is grouped (according to some target function!)
Classifying & regression
finding functions of the variables that allow to predict unobserved properties of new observations
Unsupervised learning
All features are observed for all datapoints
unsupervised vs supervised learning
prediction and classification based on examples
All features are observed for all datapoints
Some features can't be observed
for some datapoints
x
y
observed features:
(x, y)
models typically return a partition of the space
goal is to partition the space so that the unobserved variables are
separated in groups
consistently with
an observed subset
target features:
(color)
x
y
observed features:
(x, y)
ax+b
if y <= a*x + b :
return blue
else:
return orangetarget features:
(color)
x
y
observed features:
(x, y)
if x**2 + y**2 <= (x-a)**2 + (y-b)**2 :
return blue
else:
return orangetarget features:
(color)
x
y
observed features:
(x, y)
if x**2 + y**2 <= (x-a)**2 + (y-b)**2 :
return blue
else:
return orangetarget features:
(color)
x
y
observed features:
(x, y)
this is a solution SVM would provide:
Support Vector Machine
target features:
(color)
x
y
observed features:
(x, y)
Support Vector Machine:
finds a hyperplane that partitions the space
A subset of variables has class labels. Guess the label for the other variables
target features:
(color)
x
y
observed features:
(x, y)
Support Vector Machine:
finds a hyperplane that partitions the space
A subset of variables has class labels. Guess the label for the other variables
2d hyperplane: line (curve)
3d hyperplane: surface
4d hyperplane: volume
...
target features:
(color)
x
y
observed features:
(x, y)
Tree Methods
split spaces along each axis separately
A subset of variables has class labels. Guess the label for the other variables
target features:
(color)
x
y
observed features:
(x, y)
Tree Methods
split spaces along each axis separately
A subset of variables has class labels. Guess the label for the other variables
split along x
if x <= a :
return blue
else:
return orangetarget features:
(color)
x
y
observed features:
(x, y)
Tree Methods
split spaces along each axis separately
A subset of variables has class labels. Guess the label for the other variables
split along x
if x <= a :
if y <= b:
return blue
return orangethen
along y
target features:
(color)
Predicted
Actual
232
4
1
263
TN
FP
TP
FN
negative
positive
negative
positive
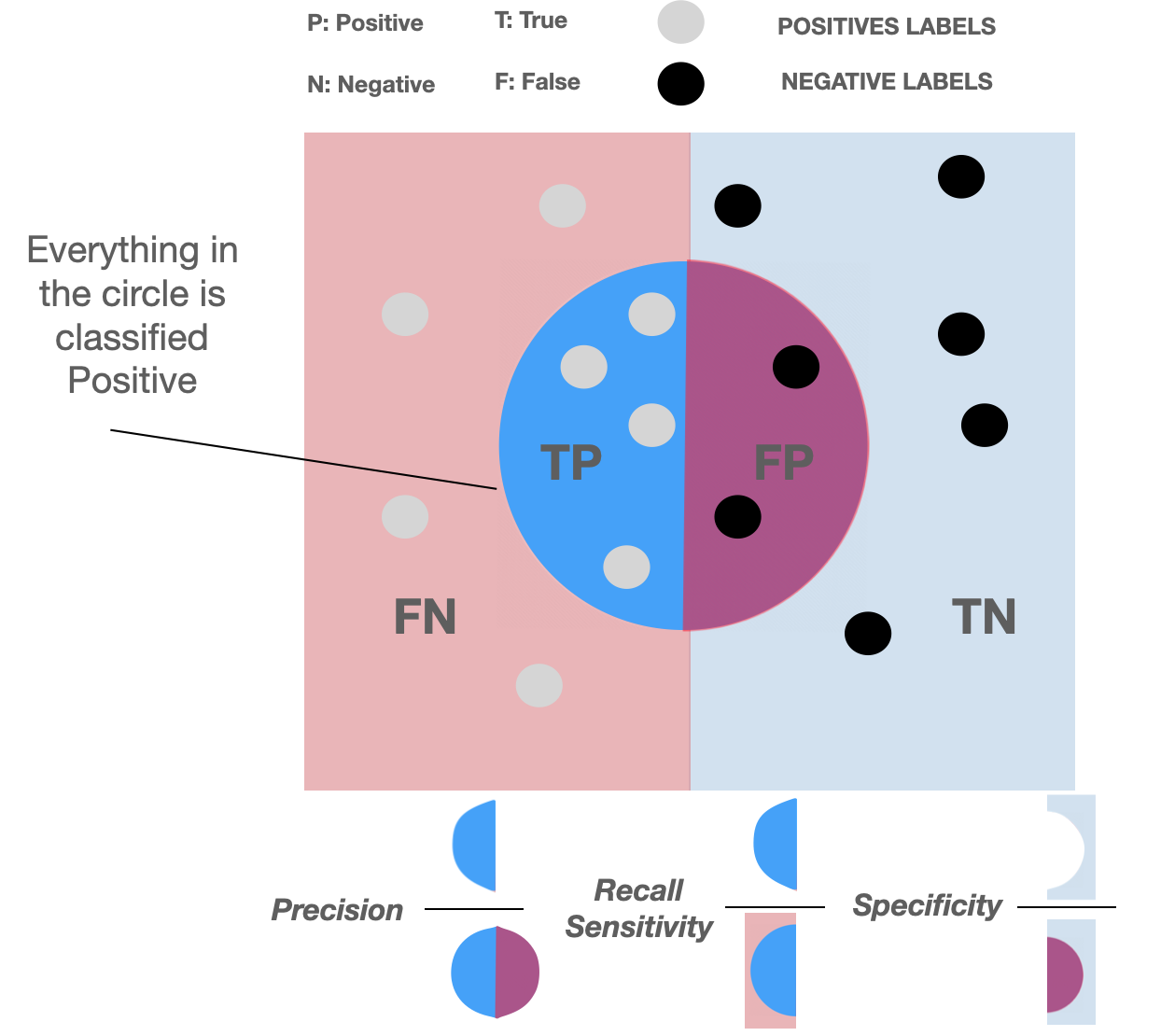
Classification outcomes:
true positives (TP) : "+" correctly labeled as "+"
true negatives (TN) : "-" correctly labeled as "-"
false positives (FP) : "-" incorrectly labeled as "+"
false negatives (FN) : "+" incorrectly labeled as "-"
accuracy:
accuracy =
precision:
(or specificity)
recall:
(or sensitivity)
Fraction of objects you think are positive that actually are positive
Fraction of positive objects that you were able to find
F1-score:
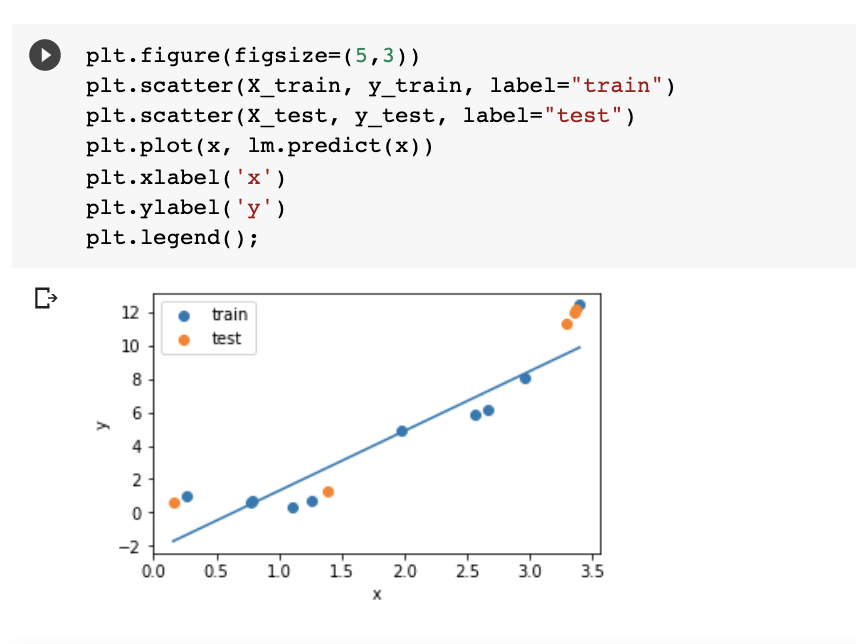
Training and testing
1
263
Wnen we want to train a model to predict we
SPLIT THE DAT INTO 2 or 3 SETS
training:
we use it to train the model
testing:
we use it to test the model.
we use the test set to report our result
Predicted
Actual
220
14
13
253
TN
FP
TP
FN
negative
positive
positive
accuracy =
Predicted
Actual
232
4
1
263
TN
FP
TP
FN
negative
positive
negative
positive
accuracy =
negative
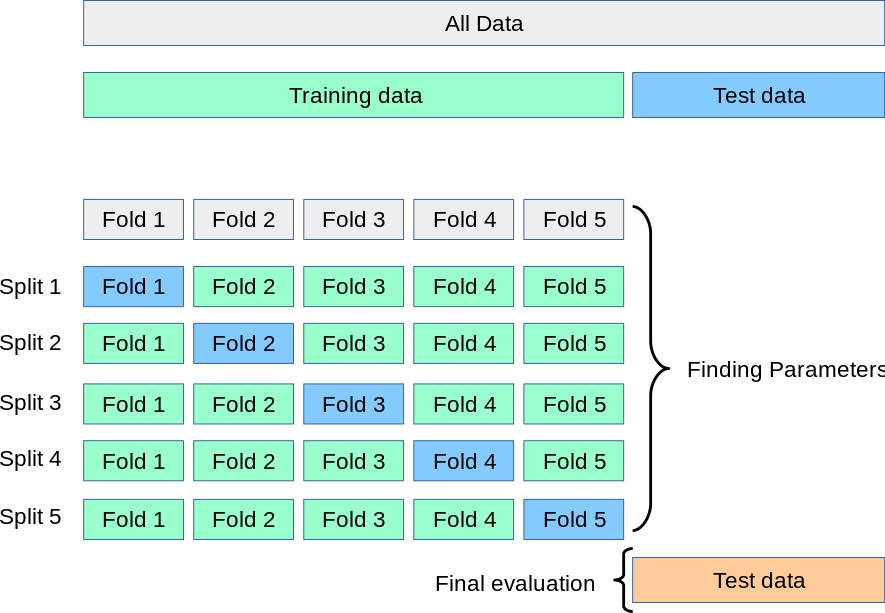
test train validation
train parameters on training set
run only once on the test set to assess the model performance
test + train + validation
train parameters on training set
adjust parameters on validation set
run only once on the test set to assess the model performance
k-fold cross validation
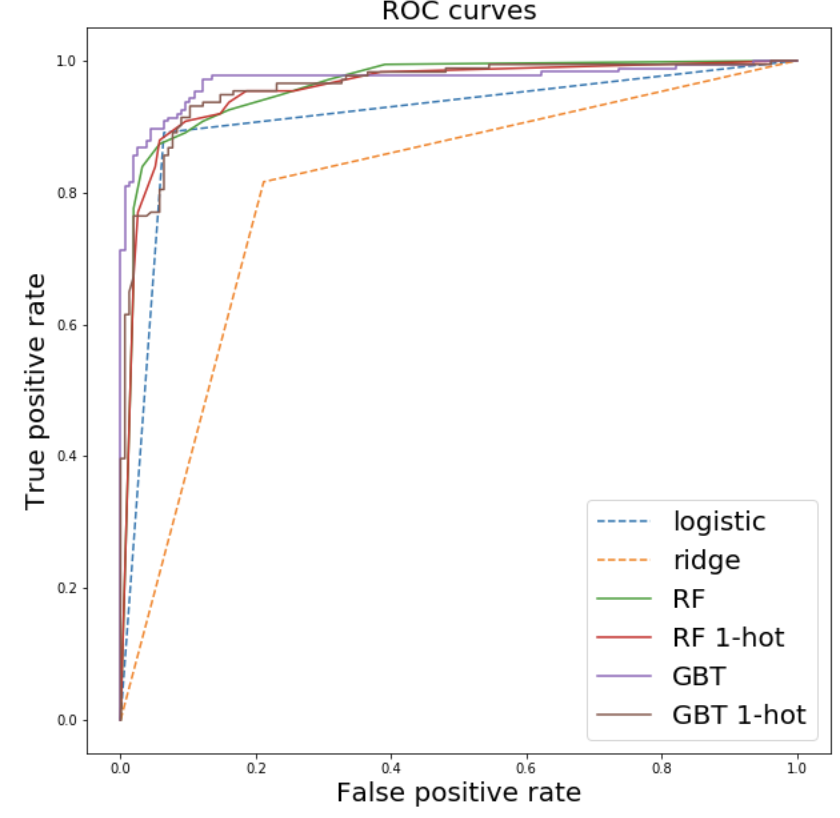
ROC: Receiver Operator Characteristics Curve
AUC: Area Under the Curve
GOOD
BAD
tuning models by changing hyperparameters
(e.g. threshold)
For probabilistic models where you can choose a threshold for "positive": every threshold pputs a point in this plot
positive iff p(positive) > threshold
For probabilistic models where you can choose a threshold for "positive": every threshold pputs a point in this plot
threshold ~1.0: everything is negative
threshold ~0.0 : everythong is positive
positive iff p(positive) > threshold
GOOD
BAD
AUC: Area Under the Curve
a global assessment of the potential of the model
AUC: Area Under the Curve
a global assessment of the potential of the model
the larger the area the better
a global assessment of the potential of the model
AUC: Area Under the Curve
a global assessment of the potential of the model
AUC: Area Under the Curve
a global assessment of the potential of the model
the larger the area the better
Tree Methods
supervised learning method
partitions feature space along each feature separately
The good
The bad
Application:
a robot to predict surviving the Titanic
714 passengers Ns=424 Nd=290
features:
target variable:
-> survival (y/n)
gender (binary)
M
Ns=93 Nd=360
F
Ns=197 Nd=64
Application:
a robot to predict surviving the Titanic
features:
target variable:
-> survival (y/n)
gender (binary)
M
Ns=93 Nd=360
F
Ns=197 Nd=64
optimize over purity:
714 passengers Ns=424 Nd=290
Application:
a robot to predict surviving the Titanic
features:
target variable:
-> survival (y/n)
gender (binary)
M
Ns=93 Nd=360
F
Ns=197 Nd=64
optimize over purity:
714 passengers Ns=424 Nd=290
Application:
a robot to predict surviving the Titanic
features:
target variable:
-> survival (y/n)
gender (binary)
M
Ns=93 Nd=360
F
Ns=197 Nd=64
optimize over purity:
714 passengers Ns=424 Nd=290
Application:
a robot to predict surviving the Titanic
features:
target variable:
-> survival (y/n)
1st
Ns=120 Nd=80
2nd +3rd
Ns=234 Nd=298
class (ordinal)
714 passengers Ns=424 Nd=290
Application:
a robot to predict surviving the Titanic
features:
target variable:
-> survival (y/n)
age (continuous)
>6.5
Ns=250 Nd=107
<=6.5
Ns=139 Nd=217
714 passengers Ns=424 Nd=290
Application:
a robot to predict surviving the Titanic
features:
target variable:
-> survival (y/n)
age (continuous)
>6.5
Ns=250 Nd=107
<=6.5
Ns=139 Nd=217
714 passengers Ns=424 Nd=290
Application:
a robot to predict surviving the Titanic
target variable:
-> survival (y/n)
gender (binary)
M
Ns=93 Nd=360
F
Ns=197 Nd=64
features:
714 passengers Ns=424 Nd=290
Application:
a robot to predict surviving the Titanic
target variable:
-> survival (y/n)
gender (binary)
M
Ns=93 Nd=360
F
Ns=197 Nd=64
features:
714 passengers Ns=424 Nd=290
Application:
a robot to predict surviving the Titanic
target variable:
-> survival (y/n)
gender
M
Ns=93 Nd=360
F
Ns=197 Nd=64
age
>6.5
Ns=250 Nd=107
<=6.5
Ns=139 Nd=217
class
1st + 2nd
Ns=120 Nd=80
3rd
Ns=234 Nd=298
features:
714 passengers Ns=424 Nd=290
Application:
a robot to predict surviving the Titanic
target variable:
-> survival (y/n)
gender
M
Ns=93 Nd=360
F
Ns=197 Nd=64
age
>6.5
Ns=250 Nd=107
p=82%
<=6.5
Ns=139 Nd=217
p=67%
class
age
>2.5
Ns=1 Nd=1
p=50%
<=2,5
Ns=8 Nd=139
p=95%
age
>38.5
Ns=44 Nd=46
<=38.5
Ns=11 Nd=1
1st + 2nd
Ns=120 Nd=80
3rd
Ns=234 Nd=298
features:
714 passengers Ns=424 Nd=290
Application:
a robot to predict surviving the Titanic
features:
target variable:
-> survival (y/n)
gender
M
Ns=93 Nd=360
F
Ns=197 Nd=64
>6.5
Ns=250 Nd=107
p=82%
<=6.5
Ns=139 Nd=217
p=67%
1st + 2nd
Ns=120 Nd=80
3rd
Ns=234 Nd=298
1st
Ns=100 Nd=20
p=80%
2nd
Ns=40 Nd=40
p=50%
age
>38.5
Ns=44 Nd=46
<=38.5
Ns=11 Nd=1
class
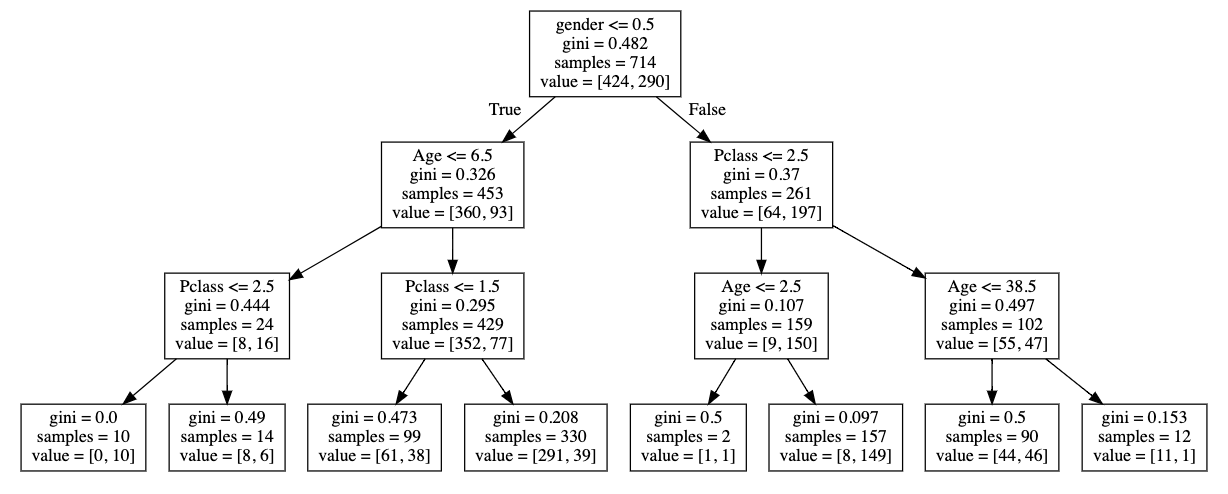
age
class
714 passengers Ns=424 Nd=290
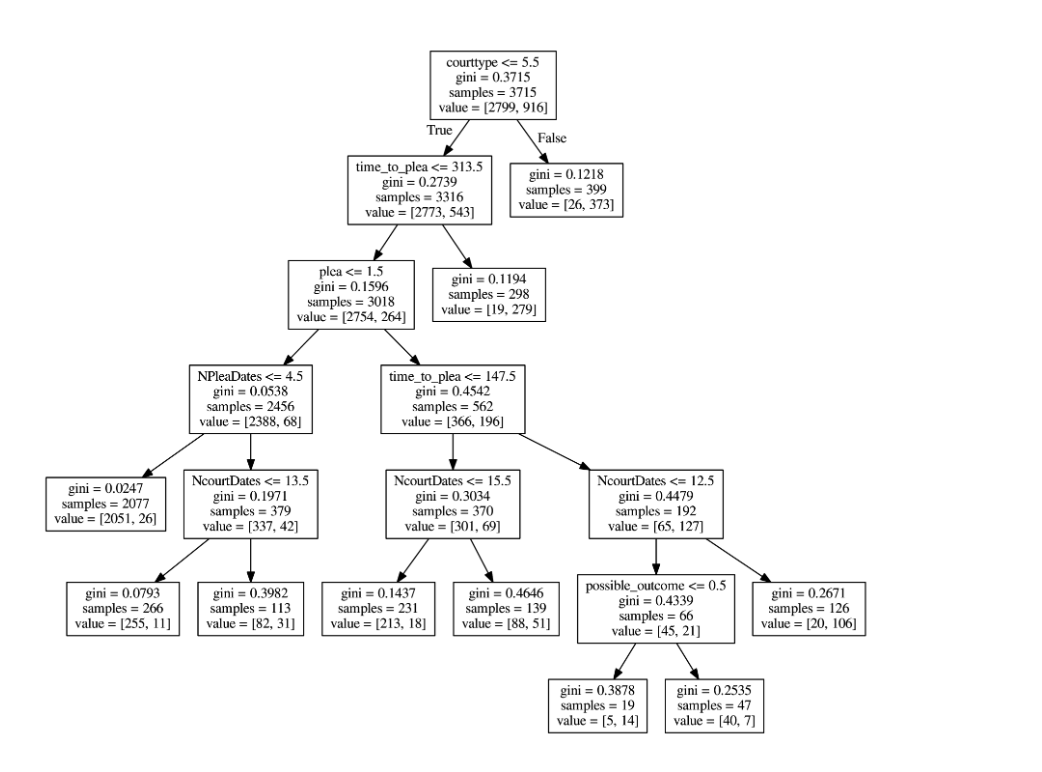
A single tree
nodes
(make a decision)
root node
branches
(split off of a node)
leaves (last groups)
A single tree
this visualization is called a "dendrogram"
gini impurity
information gain (entropy)
A single tree: hyperparameters
depth
A single tree: hyperparameters
max depth = 2
A single tree: hyperparameters
max depth = 2
PREVENTS OVERGFITTING
A single tree: hyperparameters
alternative: tree pruning
A single tree: hyperparameters
CART: Classification and Regression Trees
mean square error
A single tree: hyperparameters
mean absolute error
variance:
different trees lead to different results
variance:
different trees lead to different results
why?
because calculating the criterion for every split and every mote is an untractable problem!
e.g. 2 coutinuous variables would be a problem of order
variance:
different trees lead to different results
solution
run many trees and take an "ensamble" decision!
Random Forests
Gradient Boosted Trees
a bunch of parallel trees
a series of trees
run multiple versions of the same model with some small (stochastic or progressive) variation and learn from the emsemble of models
The decision is put together in one of two ways: bagging and boosting
Reduced variance in the decision
Reduces bias
Gradient boosted trees: (boosting)
trees run in series (one after the other)
each tree uses different weights for the features learning the weighs from the previous tree
the last tree has the prediction
Random forest: (bagging)
trees run in parallel (independently of each other)
each tree uses a random subset of observations/features (boostrap - bagging)
class predicted by majority vote:
what class do most trees think a point belong to
Gradient boosted trees:
Random forest:
Reading
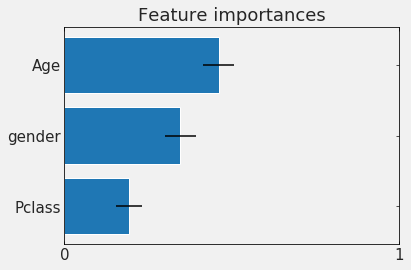
In principle CART methods are interpretable
you can measure the influence that each feature has on the decision : feature importance
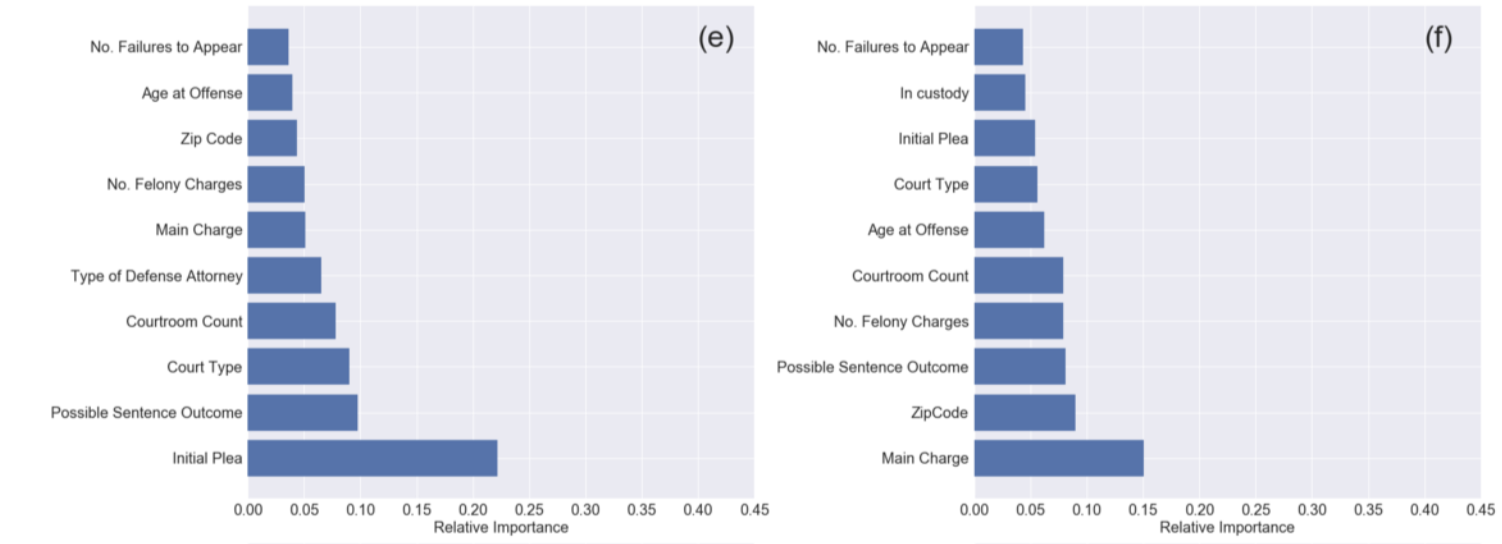
A Data-Driven Evaluation of Delays in Criminal Prosecution
feature importance:
how soon was a feature chosen,
how many times was it used...
RF
GBT
| spicies | age | weight |
|---|---|---|
| dog | 7 | 32.3 |
| bird | 1 | 0.3 |
| cat | 3 | 8.1 |
| spicies | age | weight |
|---|---|---|
| dog | 7 | 32.3 |
| bird | 1 | 0.3 |
| cat | 3 | 8.1 |
continuous
| spicies | age | weight |
|---|---|---|
| dog | 7 | 32.3 |
| bird | 1 | 0.3 |
| cat | 3 | 8.1 |
continuous
ordinal
| spicies | age | weight |
|---|---|---|
| dog | 7 | 32.3 |
| bird | 1 | 0.3 |
| cat | 3 | 8.1 |
continuous
ordinal
categorical
change categorical to (integer) numerical
| spicies | age | weight |
|---|---|---|
| 1 | 7 | 32.3 |
| 2 | 1 | 0.3 |
| 3 | 3 | 8.1 |
change each category to a binary
| cat | bird | dog | age | weight |
|---|---|---|---|---|
| 0 | 0 | 1 | 7 | 32.3 |
| 0 | 1 | 0 | 1 | 0.3 |
| 1 | 0 | 0 | 3 | 8.1 |
change categorical to (integer) numerical
| spicies | age | weight |
|---|---|---|
| 1 | 7 | 32.3 |
| 2 | 1 | 0.3 |
| 3 | 3 | 8.1 |
change each category to a binary
implies an order that does not exist
| cat | bird | dog | age | weight |
|---|---|---|---|---|
| 0 | 0 | 1 | 7 | 32.3 |
| 0 | 1 | 0 | 1 | 0.3 |
| 1 | 0 | 0 | 3 | 8.1 |
change categorical to (integer) numerical
| spicies | age | weight |
|---|---|---|
| 1 | 7 | 32.3 |
| 2 | 1 | 0.3 |
| 3 | 3 | 8.1 |
change each category to a binary
implies an order that does not exist
| cat | bird | dog | age | weight |
|---|---|---|---|---|
| 0 | 0 | 1 | 7 | 32.3 |
| 0 | 1 | 0 | 1 | 0.3 |
| 1 | 0 | 0 | 3 | 8.1 |
ignores covariance between features
change categorical to (integer) numerical
| spicies | age | weight |
|---|---|---|
| 1 | 7 | 32.3 |
| 2 | 1 | 0.3 |
| 3 | 3 | 8.1 |
change each category to a binary
implies an order that does not exist
| cat | bird | dog | age | weight |
|---|---|---|---|---|
| 0 | 0 | 1 | 7 | 32.3 |
| 0 | 1 | 0 | 1 | 0.3 |
| 1 | 0 | 0 | 3 | 8.1 |
ignores covariance between features
Definitely Preferred!
problematic if you are interested in feature importance
Machine Learning includes models that learn parameters from data
ML models have parameters learned from the data and hyperparameters assigned by the user.
Unsupervised learning:
Supervised learning:
Tree methods:
single trees have high variance as the optimization has to be local
ensemble methods solve variance issue by running multiple trees and making an ensemble decision
random forest: trees run in parallel with a random subset of features
and the decision scheme is "majority" decision
gradient boosted trees: trees run in series with feature weighted learning the weights from the outcome of the previous tree. The last tree has the division
feature importance: the importance of each feature can be extracted. In presence of covariance the feature importance may be hard to interpret
encoding categorical variables:
variables have to be encoded as numbers for computers to understand them. You can encode categorical variables with integers or floating point but you implicitly impart an order. The standard is to one-hot-encode which means creating a binary (True/False) feature (column) for each category of a categorical variables but this increases the feature space and generated covariance.
model diagnostics for classifiers: Fraction of True Positives and False Positives are the metrics to evaluate classifiers. Combinations of those numbers include Accuracy (TP/ (TP+FP)), Precision (TP/(TP+FN)), Recall ((TP+TN)/(TP+TN+FP+FN)).
ROC curve: (TP vs FP) is a holistic metric of a model. It can be used to guide the choice of hyperparameters to find the "sweet spot" for your problem
http://what-when-how.com/artificial-intelligence/decision-tree- applications-for-data-modelling-artificial-intelligence/
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4466856/
resource on coding
Distributed and parallel time series feature extraction for industrial big data applications
Maximilian Christ a , Andreas W. Kempa-Liehrb,c, Michael Fein
https://arxiv.org/pdf/1610.07717.pdf
TL;DR:
Feature extractions from time series
Data Science
Interpretability Methods in Machine Learning: A Brief Survey
Insights by Two Sigma
- Download the Higgs boson data from Kaggle (programmatically within the notebook, see how in the Titanic notebook)
- Split the provided training data into a training and a test set. For each model calculate and discuss the training and test score results.
- Use a Random Forest and a Gradiend Boosted Tree Classifier model to predict the label of the particles.
- Produce a confusion matrix for each model and compare them
- Use a Random Forest and a Gradiend Boosted Tree Regressor model to predict the weight of the particles.
- Calculate the L1 and L2 metrics of each model and compare them.
- For the Random Forest classifier, select the 4 most important features (see how in the Titanic notebook) and explore the parameter space with the sklearn module sklearn.model_selection.RandomizedSearchCV for a model that uses only those features to predict the labels https://scikit-learn.org/stable/auto_examples/model_selection/plot_randomized_search.html#sphx-glr-auto-examples-model-selection-plot-randomized-search-py
- Generate an ROC curve plot for the best model and discuss it https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_curve.html or https://scikit-learn.org/stable/auto_examples/model_selection/plot_roc_crossval.html#sphx-glr-auto-examples-model-selection-plot-roc-crossval-py
- EC and 667
---- Download the script provided in the kaggle challenge to validate your model.
---- Generate an output file as required by this script for your best model
---- Report on the result
Higgs Boson Search
By federica bianco
CART methods



