1.5 Years of GraphQL in Production
Agenda
- Architecture + Motivation
- GraphQL Schema in Sangria
- Operations
- Closing Thoughts
Architecture Then
Frontend
Backend (Services)
REST
Server-Side-Rendering
Browser (TypeScript)
API-Gateway Features
-
"Fields" query-params
/users/1?fields=name,age,avatar_urls[thumbnail]
=> Prevent over-/underfetching
-
Batched fetching of (sub-)entities
=> Prevent N+1 service-calls -
Versioned API
=> Allows deprecation/breaking changes
API-Gateway Pain Points
-
Mismatch between expected json and "Fields" parameters
can cause problems
-
Batched fetching works, but is manual and annoying to maintain
(part of it over-engineered, part of it under-engineered)
-
Resilience is manual and inconsistent
-
Versioned API means the whole endpoint is duplicated even if
the actual difference is small (e.g. type of one field)
Architecture Now
Frontend
Backend (Services)
REST
GraphQL
Server-Side-Rendering
Browser (TypeScript)
In GraphQL: API == Schema
- A Schema is composed of Fields
-
Fields have a specific Type and Resolver (and optionally arguments)
-
ObjectType contains one or more Fields
Building Blocks:
A minimal example
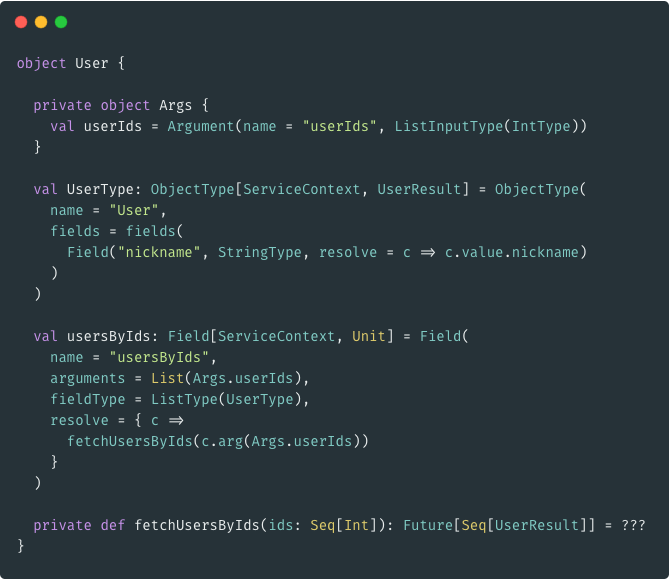
A minimal example
Extending the schema
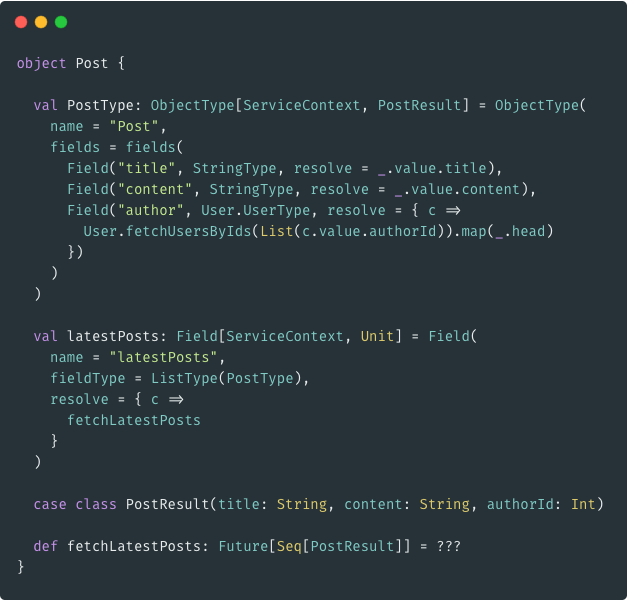
Using "Fetcher"
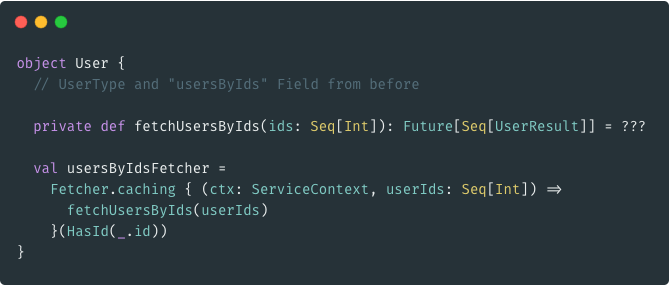
Using "Fetcher"
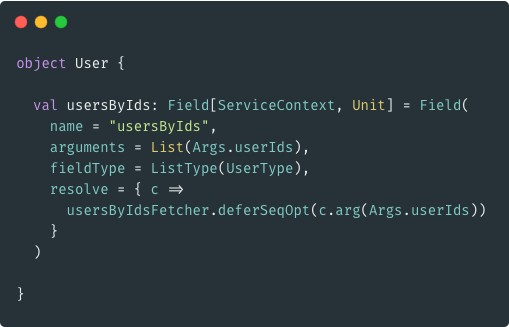
Using "Fetcher"
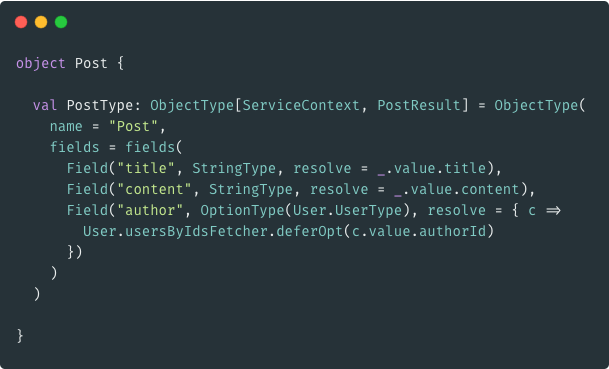
Using "Fetcher"

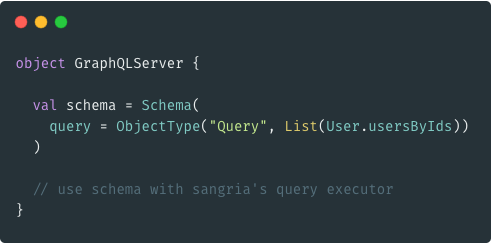
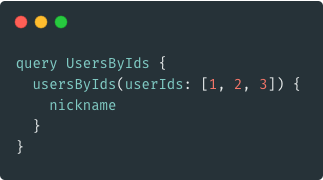
A more realistic query
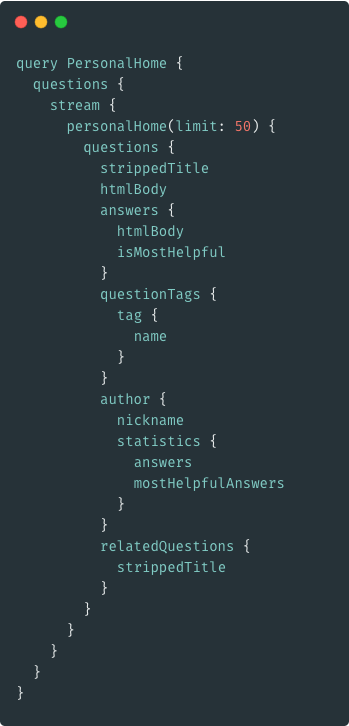
So far...
- Modular and declarative schema and data-fetching
- Less code
- Less error-prone manual optimization/resilience
- The queries and the schema are both just data
- Introspection by tools (e.g. GraphiQL)
- (Fairly) easy code-generation for clients ("e2e-type-safety")
- Schema diffing detects breaking changes in your local tests
- Sangria is flexible and extendable
- Choose whatever web-server, protocol and codec you want
- Custom types (e.g. UnitType) fairly easy to add
- Resolvers can be extended to understand other effect types
- Integrated documentation is Markdown
The OPs side
GraphQL is protocol-agnostic!
- Traditional http-specific tools don't work out-of-the-box
- http-caching-layers
- health-checks based on status codes
- observability which clusters based on request-path (e.g. /users/)
- You can separate queries from their input-data (think prepared sql statements)
- Less likely to accidentally log sensitive data (e.g. passwords)
- You can decide whether you only log the query name or the whole thing, etc.
The OPs side
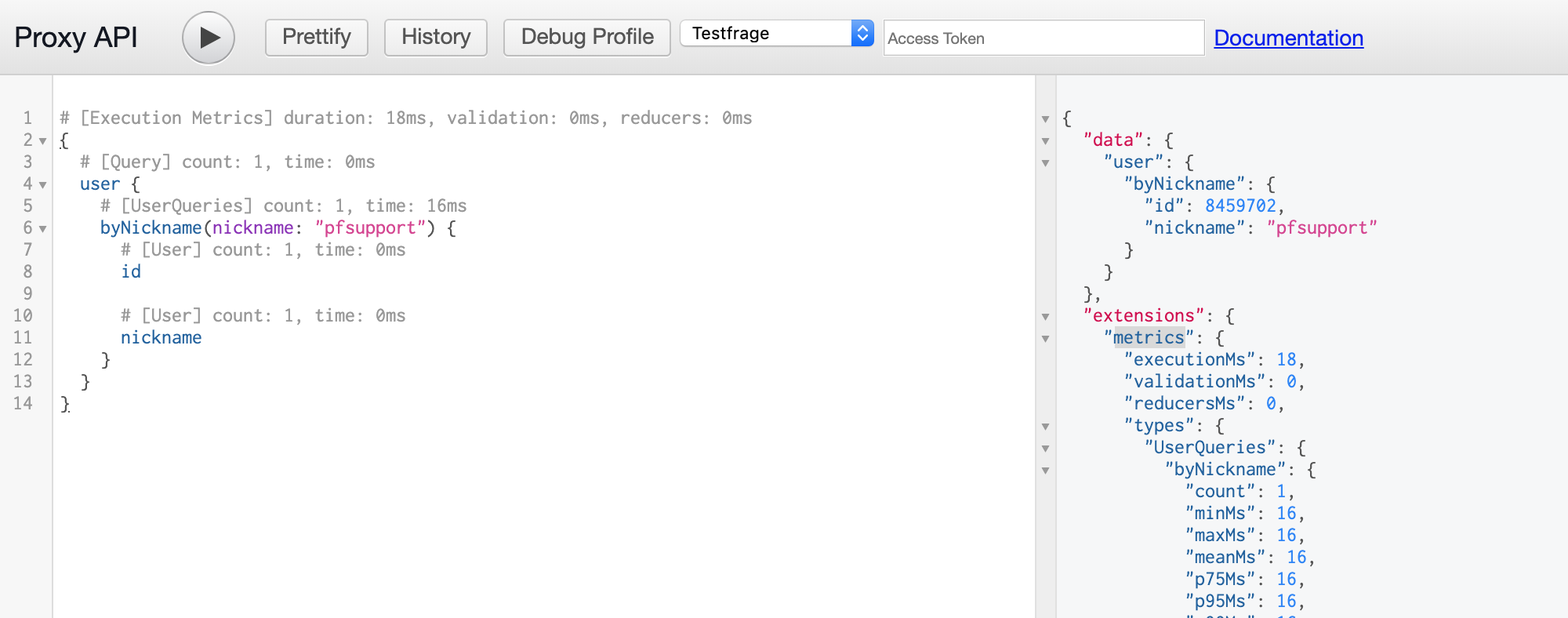
- Sangria makes it easy to instrument GraphQL down to the field-level
- query-depth and query-complexity analysis
- deprecation-tracking ("Is this field still in use or can we remove it?")
- slow-log and performance profiling
- Schema and Queries are built from very few generic building-blocks
- Writing custom generic middleware is not hard
The OPs side
Closing Thoughts
- The introduction of GraphQL as an API-Gateway was seen as a clear success by both backend- and frontend-devs
- Compared to our REST-API it is easier, safer and faster to extend on the server-side and to use in the frontend
- Mistakes in the API-design are easier to remedy and the tooling is already better than in the REST-era
- Interesting consequence: Feature turnaround is faster and a lot more autonomous full-stack development
Thank you!
1.5 Years of GraphQL in Production
By Felix Bruckmeier



