Cross-curvature: new areas of applications
Flavien Léger
joint works with François-Xavier Vialard, Pierre-Cyril Aubin-Frankowski
1. Gradient descent
2. The Laplace method
Outline
1. Gradient descent
Gradient descent as minimizing movement
Two steps:
1) majorize: find the tangent parabola (“surrogate”)
2) minimize: minimize the surrogate
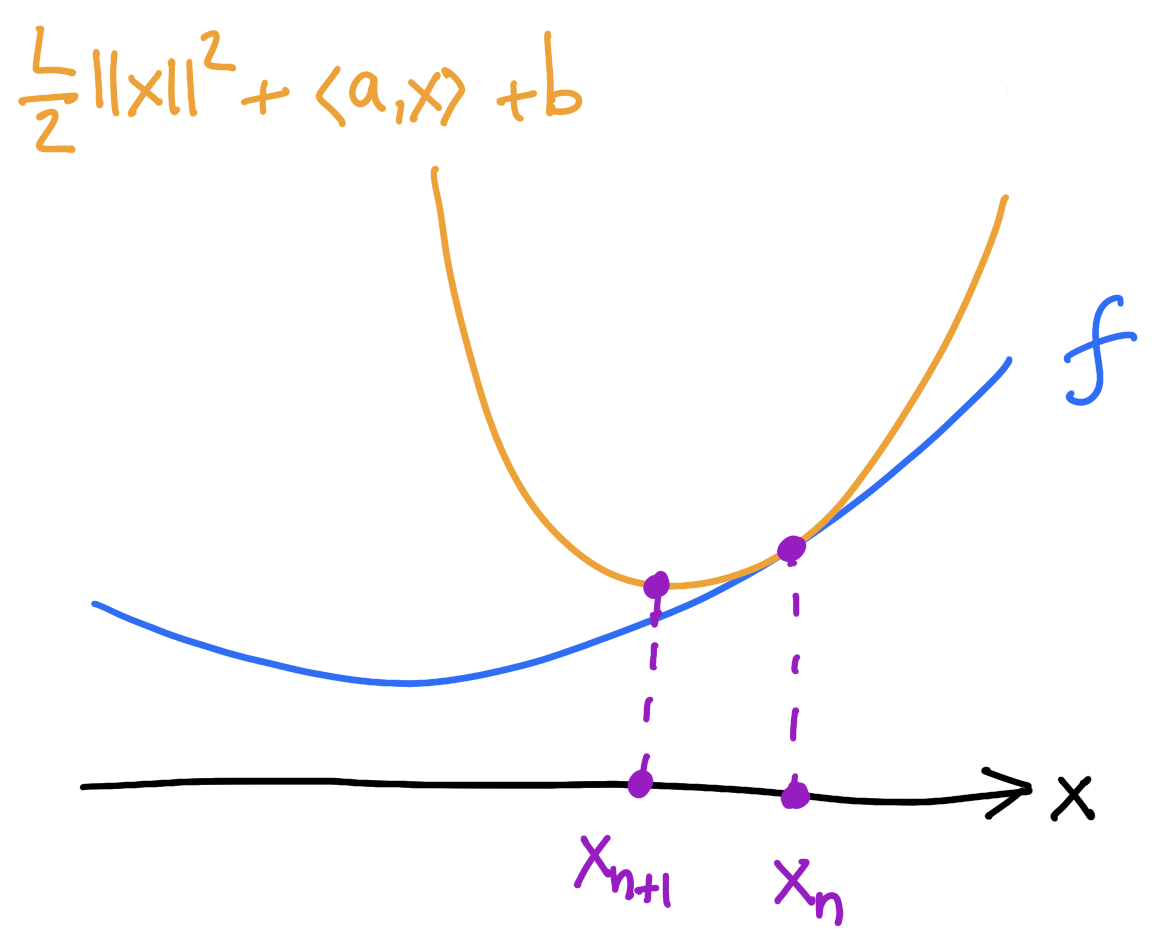
\[x_{n+1}=x_n-\frac{1}{L}\nabla f(x_n),\]
objective function \(f\colon \mathbb{R}^d\to\mathbb{R}\)
\(f\) is \(L\)-smooth if \[\nabla^2f\leq L I_{d\times d}\]
D E F I N I T I O N
\[f(x)\]
\[\leq\]
\[f(x_n)+\langle\nabla f(x_n),x-x_n\rangle+\frac{L}{2}\lVert x-x_n\rVert^2\]
The \(y\)-step and the \(x\)-step
The \(y\)-step (“majorize”):
\[y_{n+1} = \argmin_{y}\phi(x_n,y)\]
The \(x\)-step (”minimize”):
\[x_{n+1} = \argmin_{x}\phi(x,y_{n+1})\]

Family of majorizing functions \(\phi(x,y)\)
\(\phi(\cdot,y_{n+1})\)
General cost
\[f^c(y)=\inf\{\lambda\in\mathbb{R} : \forall x\in\mathbb{R}^d, \,f(x)\le c(x,y)+\lambda\}\]
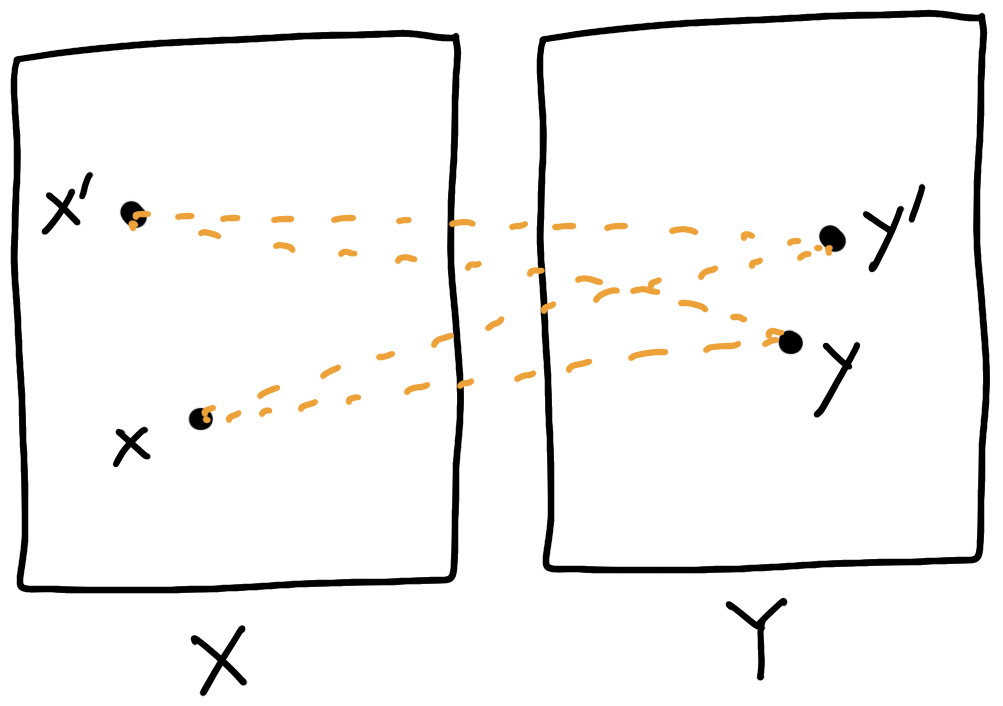
Given: \(X\) and \(f\colon X\to\mathbb{R}\)
Choose: \(Y\) and \(c(x,y)\)
\(c(\cdot,y)+f^c(y)\)
\(c(\cdot,y)+\lambda\)
\[f(x)\leq \underbrace{c(x,y)+f^c(y)}_{\phi(x,y)}\]
\(f\) is \(c\)-concave if
\[f(x)=\inf_{y\in Y}c(x,y)+f^c(y)\]
Envelope of the surrogates
D E F I N I T I O N

\[\inf_{x\in X} f(x)=\inf_{x\in X}\inf_{y\in Y} c(x,y)+f^c(y)=\phi(x,y)\]
\[\inf_{x}f(x)=\inf_{x,y}c(x,y)+f^c(y)\]
Gradient descent with a general cost
(FL–PCAF '23)
\begin{aligned}
y_{n+1} &= \argmin_{y\in Y} c(x_n,y)+f^c(y)\\
x_{n+1} &= \argmin_{x\in X} c(x,y_{n+1})+f^c(y_{n+1})
\end{aligned}
\begin{aligned}
-\nabla_xc(x_n,y_{n+1})&=-\nabla f(x_n)\\
\nabla_xc(x_{n+1},y_{n+1})&=0
\end{aligned}
“majorize”
“minimize”
A L G O R I T H M
\(\phi(\cdot,y_{n+1})\)
Examples
\(\bullet \,\,\,c(x,y)=\overbrace{u(x)-u(y)-\langle\nabla u(y),x-y\rangle}^{\eqqcolon u(x|y)}\): mirror descent
\[\nabla u(x_{n+1})-\nabla u(x_n)=-\nabla f(x_n)\]
\(\bullet\,\,\,c(x,y)=u(y|x)\): natural gradient descent
\[x_{n+1}-x_n=-\nabla^2 u(x_n)^{-1}\nabla f(x_n)\]
\(\bullet\,\,\,c(x,y)=\frac{L}{2}d_M^2(x,y)\): Riemannian gradient descent
\[x_{n+1}=\exp_{x_n}(-\frac{1}{L}\nabla f(x_n))\]
Newton
\(-\nabla_xc(x,y)=\xi\Leftrightarrow y=\exp_x(\frac{1}{L}\xi)\)
\begin{aligned}
y_{n+1} &= \argmin_{y\in Y} \phi(x_n,y)\\
x_{n+1} &= \argmin_{x\in X} \phi(x,y_{n+1})
\end{aligned}
\(X,Y\), \(\phi\colon X\times Y\to\mathbb{R}\)
Alternating minimization
\(\phi(x,y)=c(x,y)+g(x)+h(y)\)
\[\operatorname*{minimize}_{x\in X,y\in Y} \;\phi(x,y)\]
A L G O R I T H M
The five-point property
For all \(x,y,y_0,x_{1},y_{1}\),
\[\phi(x,y_{1})+(1-\lambda)\phi(x_0,y_0)\leq \phi(x,y)+(1-\lambda)\phi(x,y_0)\]
They show: \(\phi(x_n,y_n)\to\inf \phi\)
(FPP)
D E F I N I T I O N (Csiszár–Tusnády ’84 (\(\lambda=0\)))
\[\operatorname*{minimize}_{x\in X,y\in Y} \;\phi(x,y)\]
If \(\phi\) satisfies the FPP then
\[\phi(x_n,y_n)\leq \phi(x,y)+\frac{\phi(x,y_0)-\phi(x_0,y_0)}{n}\]
If \(\phi\) satisfies the \(\lambda\)-FPP then
\[\phi(x_n,y_n)\leq \phi(x,y)+\frac{\lambda[\phi(x,y_0)-\phi(x_0,y_0)]}{\Lambda^n-1},\]
where \(\Lambda\coloneqq(1-\lambda)^{-1}>1\).
T H E O R E M (FL–PCAF '23)
The Kim–McCann geometry
\(\delta_c(x+\xi,y+\eta;x,y)=\underbrace{-\nabla^2_{xy}c(x,y)(\xi,\eta)}_{\text{Kim--McCann metric ('10)}}+o(\lvert\xi\rvert^2+\lvert\eta\rvert^2)\)
\(\delta_c(x',y';x,y)=\)
\[W_c(\mu,\nu)=\inf_{\pi\in\Pi(\mu,\nu)}\iint_{X\times Y}c(x,y)\,\pi(dx,dy)\]

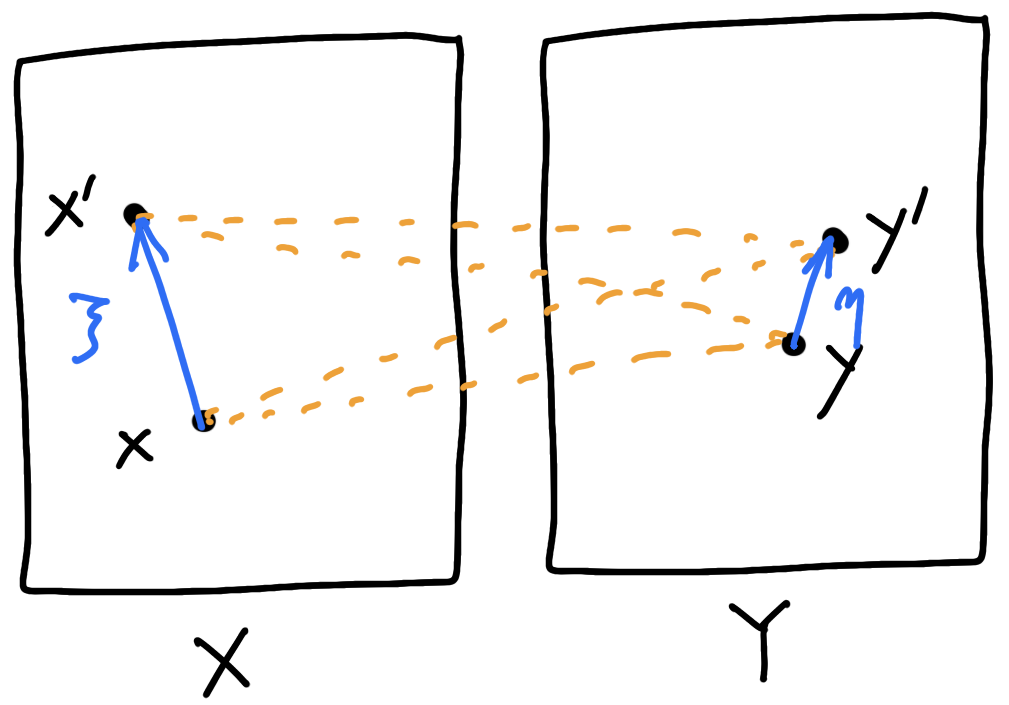
\([c(x,y')+c(x',y)]-[c(x,y)+c(x',y')]\)


Cross-curvature
The cross-curvature or Ma–Trudinger–Wang tensor is
\[\mathfrak{S}_c(\xi,\eta)=(c_{ik\bar s} c^{\bar s t} c_{t \bar\jmath\bar\ell}-c_{i\bar \jmath k\bar\ell}) \xi^i\eta^{\bar\jmath}\xi^k\eta^{\bar\ell}\]
(Ma–Trudinger–Wang ’05)
\[c_{i\bar \jmath}=\frac{\partial^2c}{\partial x^i\partial y^{\bar\jmath}},\dots\]
\(\mathfrak{S}_c\) uniquely determines the curvature of the Kim–McCann metric.
D E F I N I T I O N
T H E O R E M (Kim–McCann '11)
\[\mathfrak{S}_c\geq 0 \iff c(x(t),y)-c(x(t),y')\text{ convex in } t\]
for any Kim–McCann geodesic \(t\mapsto (x(t),y)\)
A local criteria for the five-point property
Suppose that \(c\) has nonnegative cross-curvature.
If \(F(x)\coloneqq\inf_{y\in Y}\phi(x,y)\) is convex on every Kim–McCann geodesic \(t\mapsto (x(t),y)\) satisfying \(\nabla_x\phi(x(0),y)=0\), then \(\phi\) satisfies the FPP.
"... \(F(x)-\lambda\phi(x,y)\) ..." \(\leadsto\) \(\lambda\)-FFP.
\[\phi(x,y)=c(x,y)+g(x)+h(y)\]
T H E O R E M (FL–PCAF '23)
Application: Newton's method
\(c(x,y)=u(y|x)\longrightarrow\) NGD
\[x_{n+1}-x_n=-\nabla^2u(x_n)^{-1}\nabla f(x_n)\]
If \[\nabla^3u(\nabla^2u^{-1}\nabla f,-,-)\leq \nabla^2f\leq \nabla^2u+\nabla^3u(\nabla^2u^{-1}\nabla f,-,-)\] then
\[f(x_n)\leq f(x)+\frac{u(x_0|x)}{n}\]
Newton's method: new global convergence rate.
New condition on \(f\) similar but different from self-concordance
T H E O R E M
Riemannian/metric space setting
\(c(x,y)=\frac{1}{2\tau} d^2(x,y)\)
2. Implicit: \(x_{n+1}=\argmin_{x} f(x)+\frac{1}{2\tau}d^2(x,x_n)\)
\(R\leq 0\): \(\nabla^2f\geq 0\) gives \(O(1/n)\) convergence rates
\(R\geq 0\): if \(\mathfrak{S}_c\geq 0\) then convexity of \(f\) on Kim–McCann geodesics gives \(O(1/n)\) convergence rates
Wasserstein gradient flows, generalized geodesics (Ambrosio–Gigli–Savaré '05)
da Cruz Neto, de Lima, Oliveira ’98
Bento, Ferreira, Melo ’17
1. Explicit: \(x_{n+1}=\exp_{x_n}\big(-\tau\nabla f(x_n)\big)\)
\(R\geq 0\): (smoothness and) \(\nabla^2f\geq 0\) gives \(O(1/n)\) convergence rates
\(R\leq 0\): ? (nonlocal condition)
\[\operatorname*{minimize}_{x\in M} f(x)\]
2. The Laplace method
Motivation
- Heat kernel asymptotics on \((M,g)\)
- Inverse problems
\[y = T(x) + \sqrt{\varepsilon}\xi, \quad\xi\sim\mathcal{N}(0,I)\]
\[\partial_tf=\frac12\Delta f\]
\[f_t(x)=\int_Mp_t(x,y)f_0(y)\,dy\]
\[\int_M \frac{e^{-\frac{d(x,y)^2}{2t}}}{(2\pi t)^{d/2}}f_0(y)\,dy\]
vs
- Entropic transport
\[\pi_{\varepsilon}(dx,dy)=e^{-[c(x,y)-\varphi(x)-\psi(y)]/\varepsilon}\mu(dx)\nu(dy)\]
Law of \(y\) given \(x\propto\)
\[e^{-\lVert y-T(x)\rVert^2/2\varepsilon}\]
Behavior as \(\varepsilon\to 0\) of \[I(\varepsilon)=\iint_{X\times Y}e^{-u(x,y)/\varepsilon}\,dr(x,y)\]
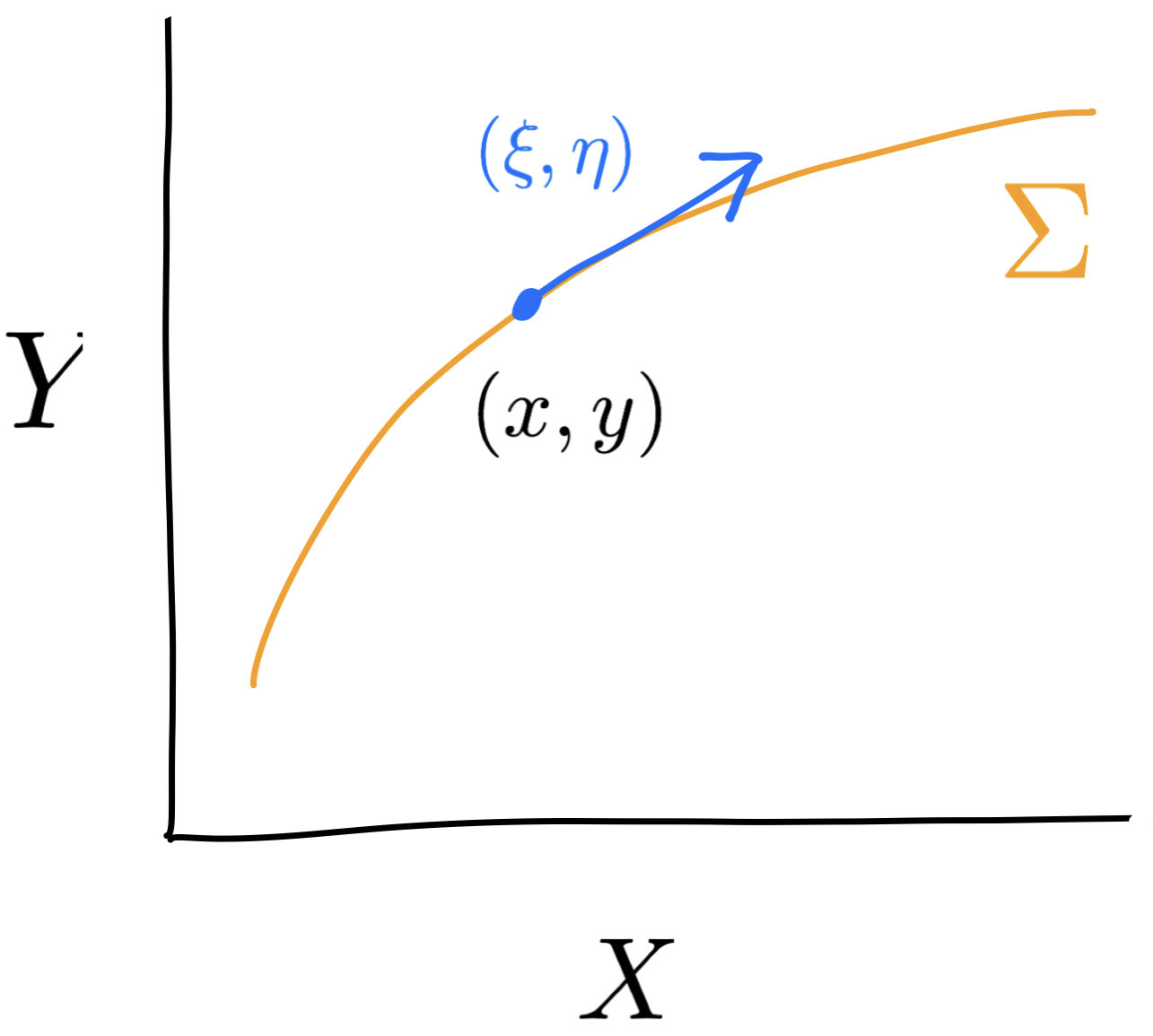
\(u\) vanishes on \(\Sigma=\{(x,T(x)) : x\in X\}\)
Setting
\(X,Y\) \(u\colon X\times Y\to\mathbb{R}\), \(u(x,y)\geq 0\)
I(\varepsilon)=\displaystyle\int_X \Big(\frac{1}{\sqrt{\det[u_{ij}]}}\Big[r + \varepsilon\Big(\frac 12 u^{ij}\partial_{ij}r-\frac 12 u_{jk\ell}u^{ij}u^{k\ell}\partial_ir \\
+ \frac 18 ru_{ijk}u_{\ell mn}u^{ij}u^{k\ell}u^{mn}+\frac{1}{12} r u_{ijk}u_{\ell mn} u^{i\ell} u^{jm} u^{kn}
- \frac 18 r u_{ijk\ell}u^{ij}u^{k\ell}\Big)\Big]_{(x,T(x))} + O(\varepsilon^2)
Standard Laplace's method:
\(g_{\scriptscriptstyle\text{KM}}\) is Riemannian on \(\Sigma\)
$$-D_{xy}^2c(x,y)(\xi,\eta)\ge 0$$
The Kim–McCann geometry of \(\Sigma\)
\((X,Y,u)\)
In summary, we have
On \(X\times Y\)
On \(\Sigma\)
Extrinsic curvatures
\(\hat g_{\scriptscriptstyle\text{KM}}\) semi-metric
\(\hat m\) volume form
\(\hat \nabla\) Levi-Civita connection
\(\hat R\) scalar curvature
\(g_{\scriptscriptstyle\text{KM}}\) metric
\(m\) volume form
\(\nabla\) Levi-Civita connection
\(R\) scalar curvature
\(h\) second fundamental form
\(H\) mean curvature
$$\iint_{X\times Y}\frac{e^{-u(x,y)/\varepsilon}}{(2\pi\varepsilon)^{d/2}}f(x,y)\,d\hat m(x,y) = \int_\Sigma fdm\,+$$
$$\varepsilon\int_\Sigma \bigg[-\frac 18\hat\Delta f+ \frac 14 \hat\nabla_{\!H} f+ f \Big( \frac{3}{32}\hat R-\frac18R+\frac{1}{24}\langle h,h\rangle-\frac18\langle H,H\rangle\Big)\bigg] \,dm$$
T H E O R E M
$$+O(\varepsilon^2)$$
Main result
Thank you!
(Milan 2023-10-11) Gradient descent and the Laplace method
By Flavien Léger




