基于统计学习的自动回复
@明朝互动-基础研发部
陈衍铭
2019-12-02
Agenda
- 方向错了——基于规则的局限性
- 学派之争——从规则到统计
- 新方案——基于统计方法
规则/关键字/句法分析
在20世纪60年代,摆在科学家面前的问题是怎样才能理解自然语言,当时普遍的认识是首先要做好两件事,即分析语句和获取语义,这实际上又是惯性思维的结果,它收到传统语言学的影响。
摘自《数学之美》第二章「自然语言处理,从规则到统计」
The pen is in the box.
笔在盒子里。
The box is in the pen.
盒子在围栏里。
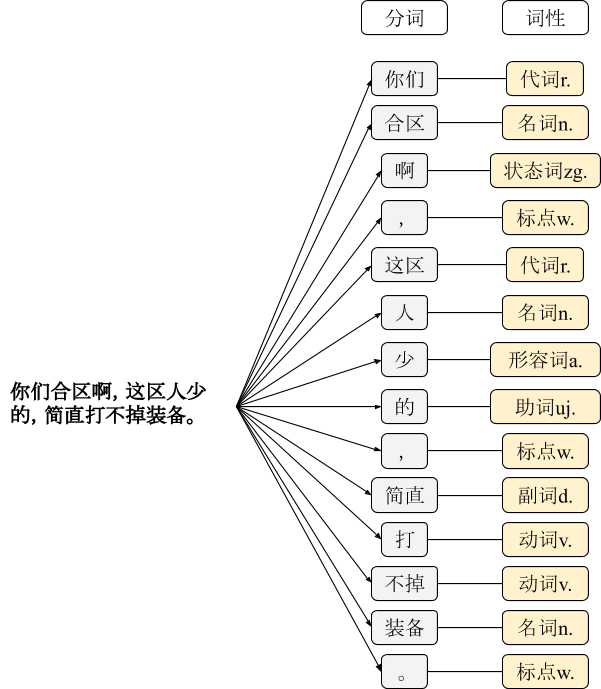
多义性
人工智能专家马文·明斯基举过一个例子:
词云(概率类)

词云(举报类)

从规则到统计
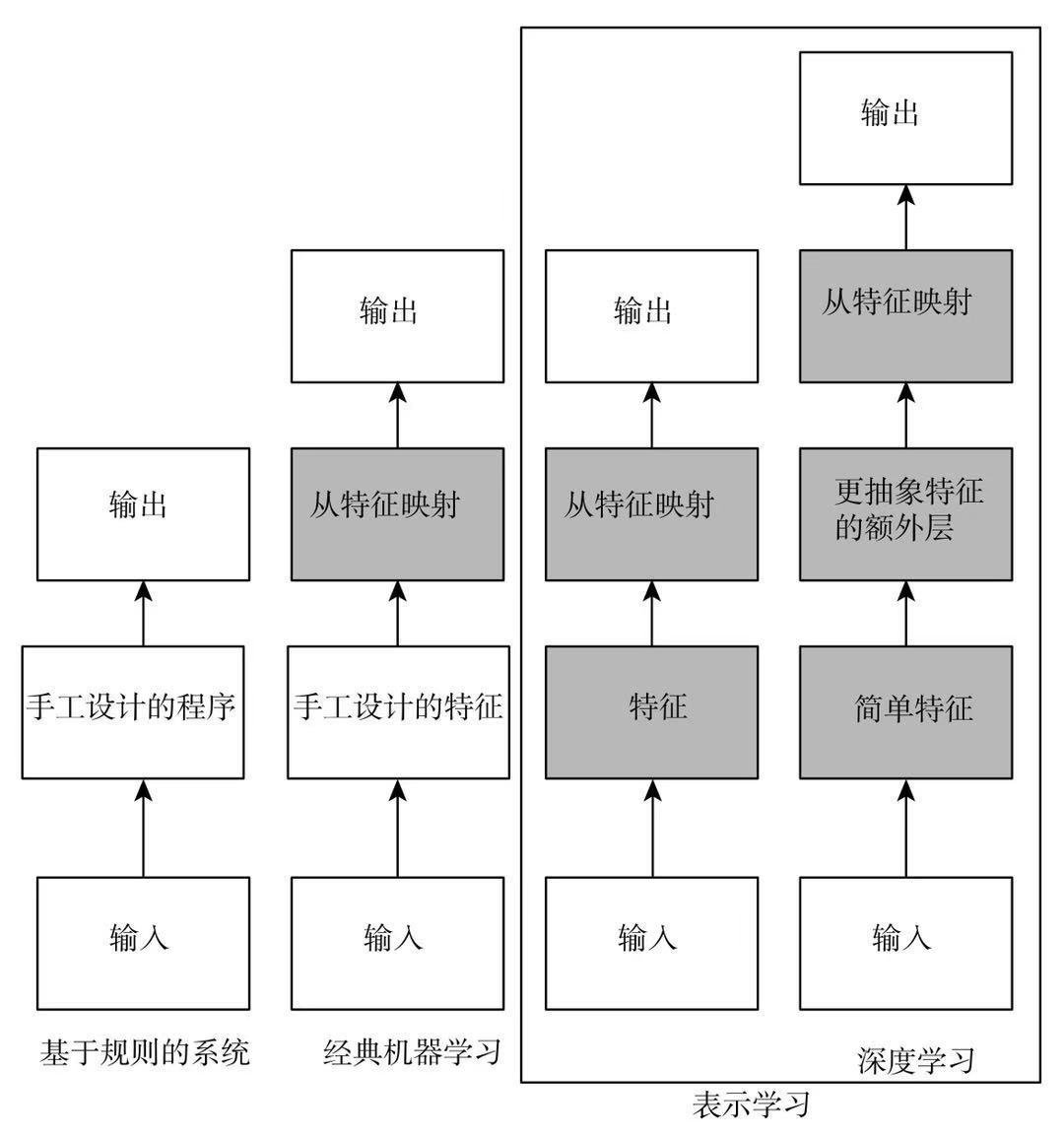
图片来自《深度学习》
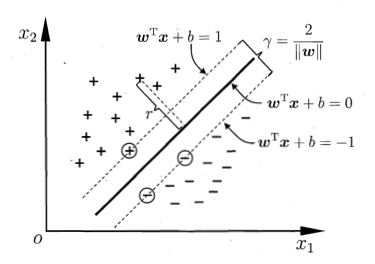
统计学习
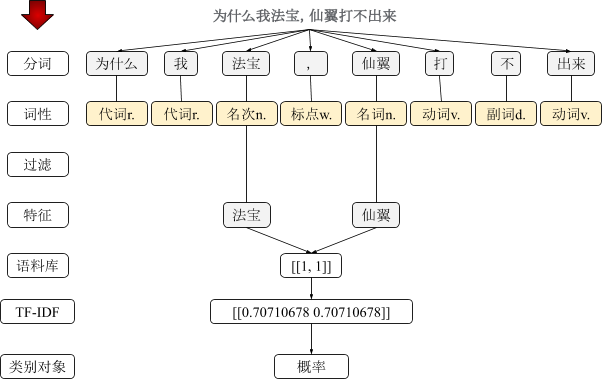
支持向量机
图片来自《机器学习》
新方案
- 第一阶段:结合人工校对和机器分类,生成可用训练的历史投诉记录作为样本
- 第二阶段:基于充足样本数以及高准确率的机器分类,结合原方案(关键字分类)制定新策略
- 第三阶段:完成全部历史记录训练样本,并开始校对匹配记录中的机器判定结果,完成机器分类正反馈闭环
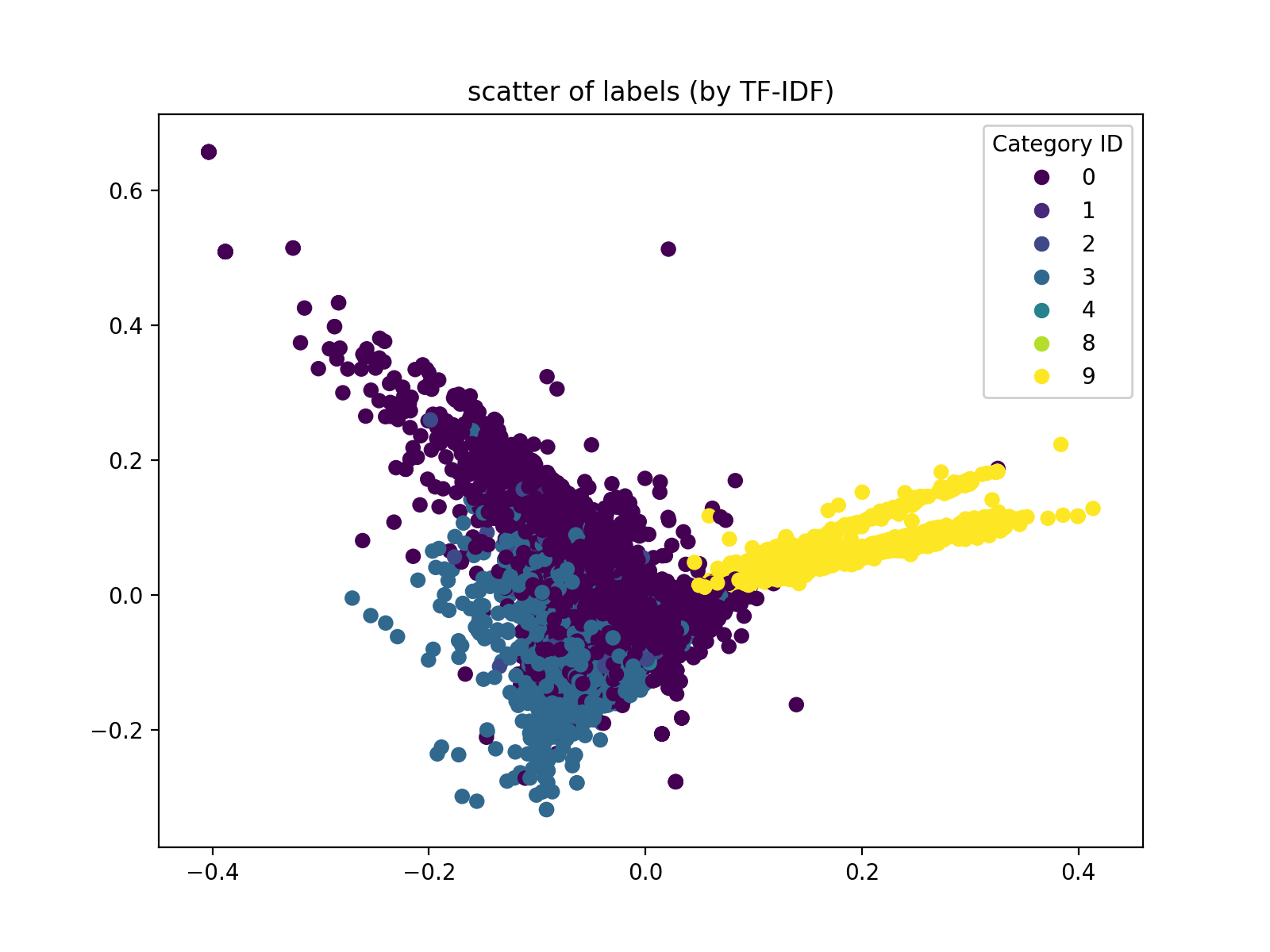
第一阶段:样本集

特征分布情况
第二阶段:新策略
- 结合关键字+机器分类做判断
- 未训练或样本数较少时,使用关键字分类
- 样本集大、高准确率时,使用机器分类
| 关键字分类 | 机器分类 | |
|---|---|---|
| 匹配率 | 18% | 30% |
| 准确率 | 91% | 97% |
新数据上的泛化能力
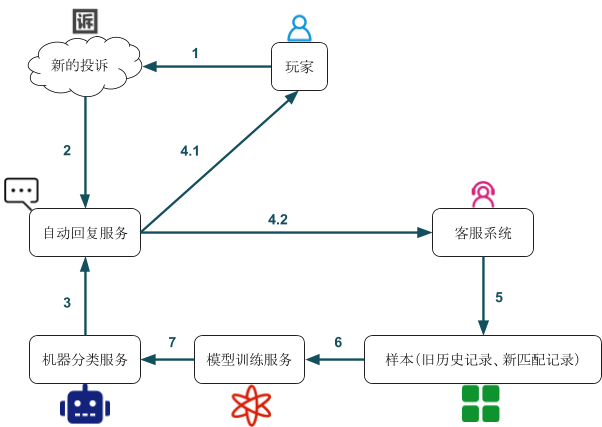
第三阶段:正反馈闭环
机器学习
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。
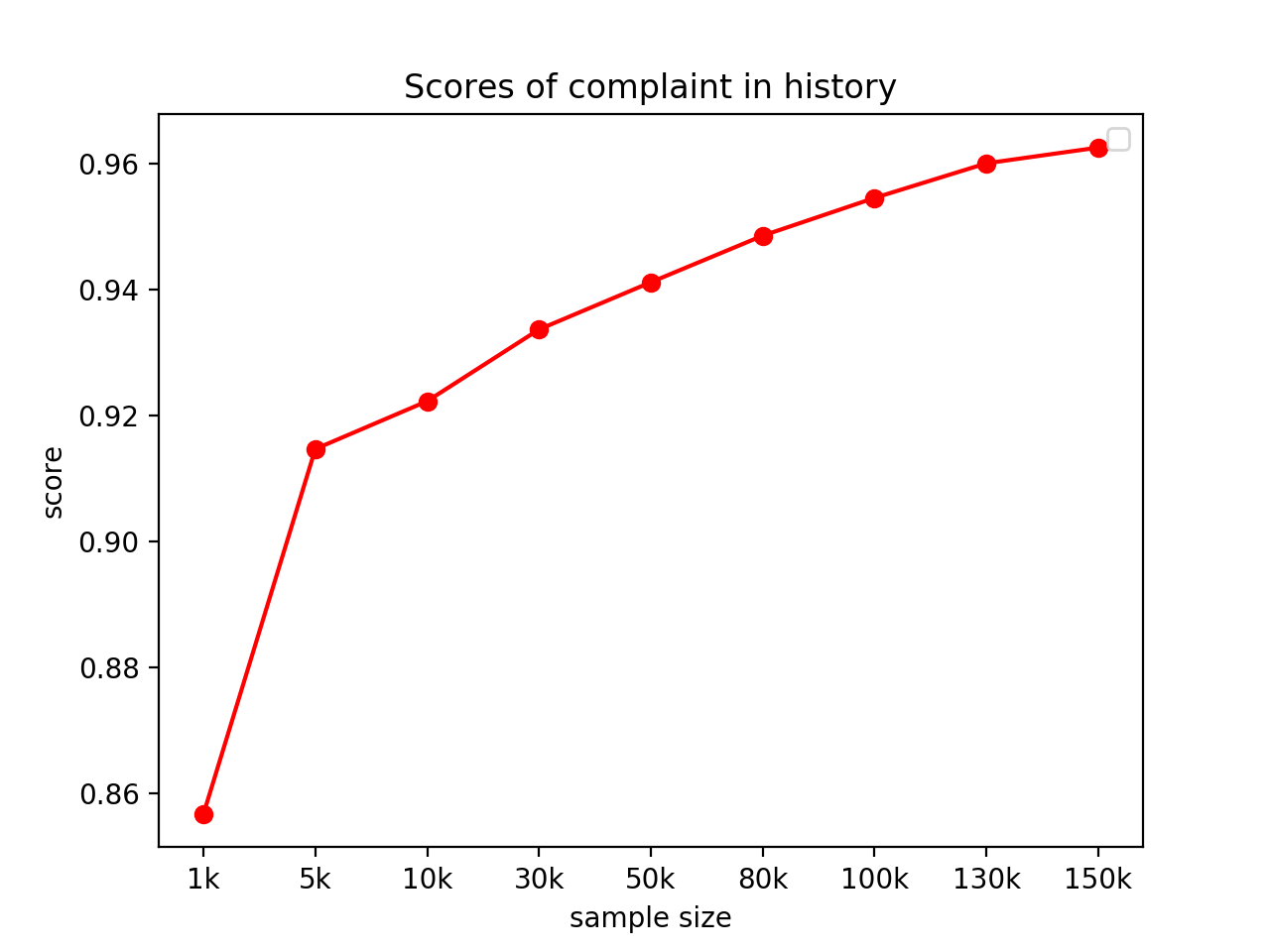
历史投诉记录准确率(测试集)
感谢观看
基于统计学习的自动回复
By funsoul
基于统计学习的自动回复
从规则到统计,统计机器学习在自动回复系统上的落地