Carlos Obregón
Java Champion with 15 years of experience in software programming
int indexOf(int[] a, int key) {
int lo = 0;
int hi = a.length - 1;
while (lo <= hi) {
int mid = lo + (hi - lo) / 2;
if (key < a[mid]) hi = mid - 1;
else if (key > a[mid]) lo = mid + 1;
else return mid;
}
return -1;
}String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = this.value.length;
int i = -1;
while (++i < len) {
if (value[i] == oldChar) {
break;
}
}
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = value[j];
}
while (i < len) {
char c = value[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(buf);
}
}
return this;
}void sort(int[] a, int[] aux, int lo, int hi) {
if (hi <= lo) return;
int mid = lo + (hi - lo) / 2;
sort(a, aux, lo, mid);
sort(a, aux, mid + 1, hi);
merge(a, aux, lo, mid, hi);
}
void merge(int[] a, int[] aux, int lo, int mid, int hi) {
for (int k = lo; k <= hi; k++) {
aux[k] = a[k];
}
int i = lo, j = mid+1;
for (int k = lo; k <= hi; k++) {
if (i > mid) a[k] = aux[j++];
else if (j > hi) a[k] = aux[i++];
else if (aux[j] < aux[i]) a[k] = aux[j++];
else a[k] = aux[i++];
}
}
String pyramid(int size) {
StringBuilder builder = new StringBuilder();
int spaces = size - 1;
int characters = 1;
for (int row = 1; row <= size; ++row) {
for (int s = 1; s <= spaces; ++s) {
builder.append(" ");
}
for (int c = 1; c <= characters; ++c) {
builder.append("*");
}
--spaces;
characters += 2;
}
return builder.toString();
}for (int v = 0; v < V; v++) {
for (int w = 0; w < V; w++) {
distTo[v][w] = Double.POSITIVE_INFINITY;
}
}
for (int v = 0; v < G.V(); v++) {
for (DirectedEdge e : G.adj(v)) {
distTo[e.from()][e.to()] = e.weight();
edgeTo[e.from()][e.to()] = e;
}
if (distTo[v][v] >= 0.0) {
distTo[v][v] = 0.0;
edgeTo[v][v] = null;
}
}
for (int i = 0; i < V; i++) {
for (int v = 0; v < V; v++) {
if (edgeTo[v][i] == null) continue; // optimization
for (int w = 0; w < V; w++) {
if (distTo[v][w] > distTo[v][i] + distTo[i][w]) {
distTo[v][w] = distTo[v][i] + distTo[i][w];
edgeTo[v][w] = edgeTo[i][w];
}
}
}
}void move(int n, char source, char target, char auxiliary) {
if (n < 0) {
return;
}
move(n - 1, source, auxiliary, target)
println(String.format("Move %i from %s to %s", n, source, target))
move(n - 1, auxiliary, target, source)
}int[] data = new int[]{10, 5, 3};
| 1100 | 1104 | 1108 | -> dirección
+------+------+------+
| 10 | 5 | 3 | -> elementos
// Dado un arreglo, "data" de objecto T
// para saber la dirección en memoria
// del i-ésimo elemnto, siendo sizeof(T)
// una operación que devuelve el tamaño de T
// la fórmula es:
// data + sizeof(int) * i
// data[2] -> *(1100 + 4 * 2) == 1108public int[] agrandar(int[] data, int longitud) {
int[] copia = new int[longitud];
for (int i = 0; i < data.length; ++i) {
copia[i] = data[i];
}
return copia;
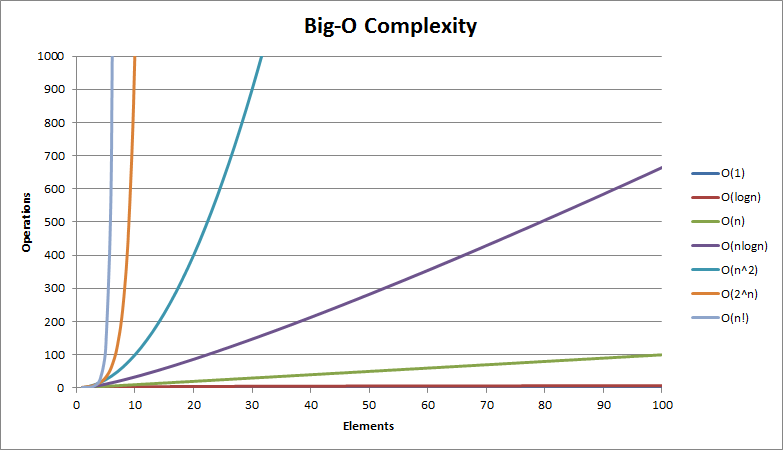
}O(n)
public int[] set(int[] data, int índice, int e) {
int[] copia = new int[data.length + 1];
int i = 0;
while (i < índice) {
copia[i] = data[i];
++i;
}
copia[i] = e;
++i;
while (i < copia.length) {
copia[i] = data[i - 1];
++i;
}
return copia;
}/**
* Establece el orden natural de T
*/
public interface Comparable<T> {
/**
* Retorna un entero negativo, cero, o un entero positivo
* si este objeto es menor, igual o mayor que otro.
*/
int compareTo(T otro);
}public class Niño
implements Comparable<Niño> {
private String nombre;
private String apellido;
private int edad;
// código
@Override
public int compareTo(Niño otro) {
return this.edad - otro.edad;
}
}La resta de 2 números muy
grandes puede causar overflow
public class Niño
implements Comparable<Niño> {
private String nombre;
private String apellido;
private int edad;
// código
// Si Overflow es una preocupación mejor usar
// código de este estilo:
@Override
public int compareTo(Niño otro) {
if (this.edad < otro.edad) return -1;
else if (this.edad == otro.edad) return 0;
else return 1;
}
}public class Niño
implements Comparable<Niño> {
private String nombre;
private String apellido;
private int edad;
// código
// En general siempre es mejor
// apoyarse en el lenguaje
@Override
public int compareTo(Niño otro) {
return Integer.compare(this.edad, otro.edad);
}
}// Horrible, antes de Java 8
public int compareTo(Niño otro) {
int cmp1 = Integer.compare(this.edad, otro.edad);
if (cmp1 != 0) {
return cmp1;
}
int cmp2 = this.apellido.compareTo(otro.apellido);
if (cmp2 != 0) {
return cmp2;
}
return this.nombre.compareTo(otro.nombre);
}@FunctionalInterface
public interface Comparator<T> {
/**
* Mismo concepto que Comparable#compareTo
*/
int compare(T o1, T o2);
}List<String> data = Arrays.asList("ba", "b", "aa");
Collections.sort(data); // [aa, b, ba]
// Horrible, antes de Java 8
Collections.sort(data, new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
int cmp = Integer.compare(s1.length(), s2.length());
if (cmp != 0) {
return cmp;
}
return s2.compareTo(s1);
}
}); // [b, ba, aa]
List<String> data = Arrays.asList("ba", "b", "aa");
Collections.sort(data,
Comparator.comparingInt(String::length)); // [b, ba, aa]
Collections.sort(data,
Comparator.comparingInt(String::length)
.reversed()
.thenComparing(String::toString)); // [aa, ba, b]@Override
public int compareTo(Niño otro) {
return Comparator.comparingInt(Niño::getEdad)
.thenComparing(Niño::getApellido)
.thenComparing(Niño::getNombre)
.compare(this, otro);
// ¿Cuáles son los objetos a comparar?
}Comparable en Java 8
boolean add(E e)
boolean addAll(Collection<E> c)
void clear()
boolean contains(Object o)
boolean isEmpty()
Iterator<E> iterator()
boolean remove(Object o)
boolean removeAll(Collection<E> c)
boolean removeIf(Predicate<E> filter)
boolean retainAll(Collection<E> c)
int size()
Stream<E> stream()
Object[] toArray()
T[] toArray(T[] a)void add(int index, E element)
E get(int index)
int indexOf(Object o)
E remove(int index)
E set(int index, E element)
List<E> subList(int fromIndex, int toIndex)public class ArrayList<E>
implements List<E> {
private Object[] elementData;
// más código
}public class ArrayList<E> implements List<E> {
// código
private int size = 0;
public ArrayList() {
this.elementData = new Object[10];
}
public boolean add(E e) {
asegurarCapacidad(this.size + 1);
elementData[size++] = e;
return true;
}
private void asegurarCapacidad(int minCapacity) {
if (minCapacity - elementData.length > 0) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
}public class LinkedList<E> implements List<E> {
private int size = 0;
private Node<E> first;
private Node<E> last;
public LinkedList() {
}
// más código
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}public class LinkedList<E> implements List<E> {
// más código
public E get(int index) {
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
}
}public class LinkedList<E> implements List<E> {
// más código
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
}
}public class LinkedList<E> implements List<E> {
// más código
public void add(int index, E element) {
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
}
}public class TreeMap<K,V> {
private final Comparator<K> comparator;
private Node<K, V> root;
private int size = 0;
static final class Node<K,V> {
K key;
V value;
Node left;
Node right;
Node(K key, V value) {
this.key = key;
this.value = value;
}
}
// más código
}public V get(K key) {
return get(root, key);
}
private V get(Node x, K key) {
if (x == null) return null;
int cmp = this.comparator(key, x.key);
if (cmp < 0) return get(x.left, key);
else if (cmp > 0) return get(x.right, key);
else return x.val;
}
public boolean contains(Key key) {
return get(key) != null;
}private Node put(Node x, K key, V val) {
if (x == null) return new Node(key, val);
int cmp = this.comparator(key, x.key);
if (cmp < 0) x.left = put(x.left, key, val);
else if (cmp > 0) x.right = put(x.right, key, val);
else x.val = val;
return x;
}public int hashCode(String s) {
int h = 0;
for (int i = 0; i < s.length(); i++) {
h = 31 * h + s.charAt(i);
}
return h;
}
Posible implementación para String
class Foo {
private String a;
private int b;
private double c;
@Override
public int hashCode() {
return Objects.hash(a, b, c);
}
}private int bucket(Object o) {
return o.hashCode() % arreglo.length();
}La solución más simple
public final class String {
private final char value[];
private int hash = 0;
// más código
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
}public class HashSet<E> {
private HashMap<E,Object> map;
private static final Object PRESENT = new Object();
// más código
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean contains(Object o) {
return map.containsKey(o);
}
}
public class TreeSet<E> {
private NavigableMap<E,Object> m;
private static final Object PRESENT = new Object();
// más código
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
public boolean contains(Object o) {
return m.containsKey(o);
}
}public interface Deque<E> {
void addFirst(E e);
void addLast(E e);
E pollFirst();
E pollLast();
boolean isEmpty();
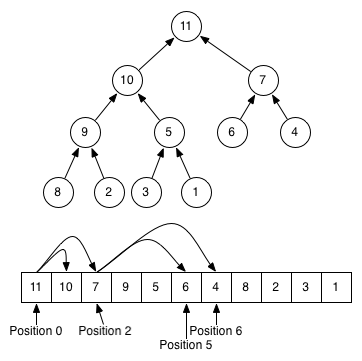
}public class PriorityQueue<E> {
private E[] elements = (E[]) new Object[8];
private int size = 0;
public boolean add(E e) {
elements[size++] = e;
heapify();
}
private void heapify() {
int index = size;
while (hasParent(index) && less(index, parent(index))) {
swap(index, parentIndex(index));
index = parentIndex(index);
}
}
}public class PriorityQueue<E> {
public E element() {
E e = elements[0];
swap(0, size);
elements[size--] = null;
makeHeap();
return e;
}
// código
}private void makeHeap() {
int index = 0;
while (hasLeftChild(index)) {
int smallerChild = leftIndex(index);
if (hasRightChild(index)
&& greater(leftIndex(index), rightIndex(index))) {
smallerChild = rightIndex(index);
}
if (greater(index, smallerChild)) {
swap(index, smallerChild);
} else {
break;
}
index = smallerChild;
}
}public class Foo {
private Set<String> data;
public Foo(final Set<String> data) {
// Todas las colecciones
// tienen constructores de copia
this.data = new HashSet<>(data);
}
}public class Foo {
private Set<String> data;
// más código
public Set<String> getData() {
// Collections.unmodifiableCollection()
// Collections.unmodifiableList()
// Collections.unmodifiableMap()
// Collections.unmodifiableNavigableMap()
// Collections.unmodifiableNavigableSet()
// Collections.unmodifiableSet()
// Collections.unmodifiableSortedMap()
// Collections.unmodifiableSortedSet()
return Collections.unmodifiableSet(data);
}
}StreamUtils.toStream(page.listChildren())
.filter(child -> Pages.isPublished(child))
.map(child -> Link.of(child))
.limit(MAX_LINKS)
.collect(Collectors.toList());Arrays.asList("A", "B", "C");
new HashSet<>(Array.asList(1, 2, 3));List.of("A", "B", "C");
Set.of(1, 2, 3);
Map.of("foo", 1, "bar", 2, "baz", 3);
Map.ofEntries(
entry("foo", 1),
entry("bar", 2),
entry("baz", 3)
);List<Post> allPosts =
(!appId.isEmpty() && !appSecret.isEmpty())
? getPosts(screenName, appId, appSecret)
: new ArrayList<>();List<Post> allPosts =
(!appId.isEmpty() && !appSecret.isEmpty())
? getPosts(screenName, appId, appSecret)
: Collections.emptyList();
// Collections.emptySet()
// Collections.emptySet()
// Collections.emptyMap()
// Collections.emptyIterator()
// ...Specification getSpecifications(String id,
List<Product> products, List<Specification> specs) {
for (Product product: products) {
if (product.getId().equals(id)) {
for (Specification spec: specs) {
if (spec.getCode().equals(product.getCode()) {
return spec;
}
}
}
}
return null;
}Una historia de la vida real
By Carlos Obregón
Una charla sobre Complejidad, Arreglos, Lis, Set, Map, Queue y desempeño



