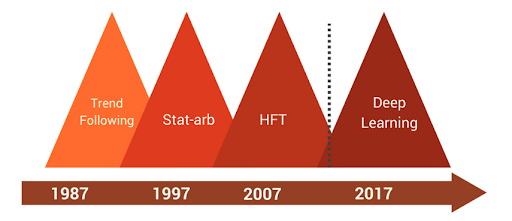
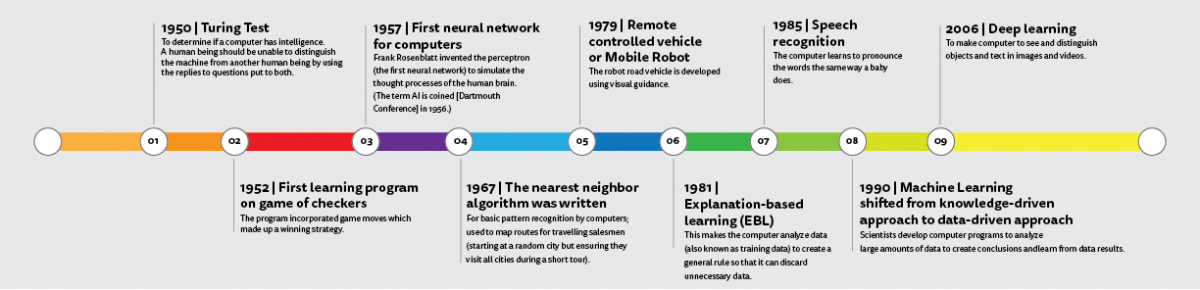


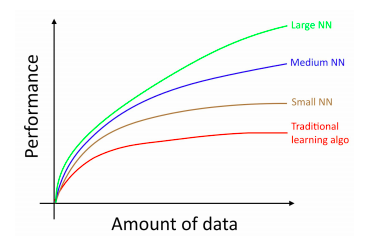


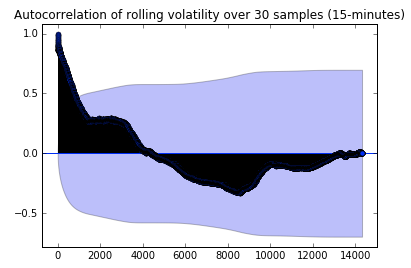
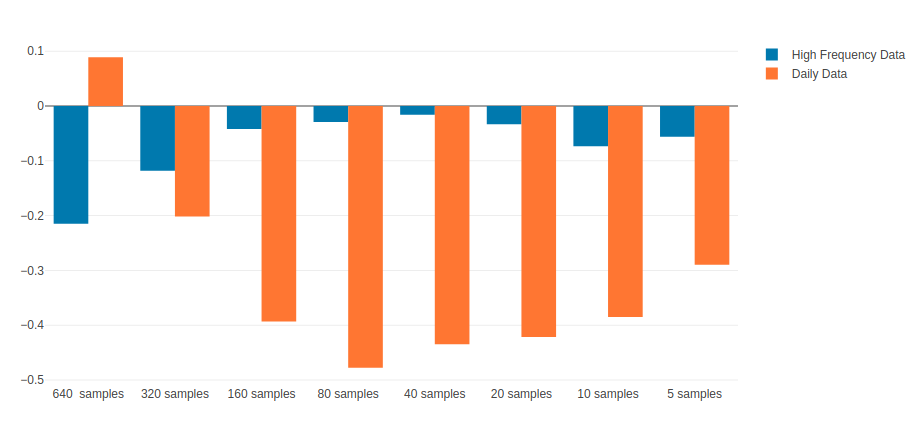
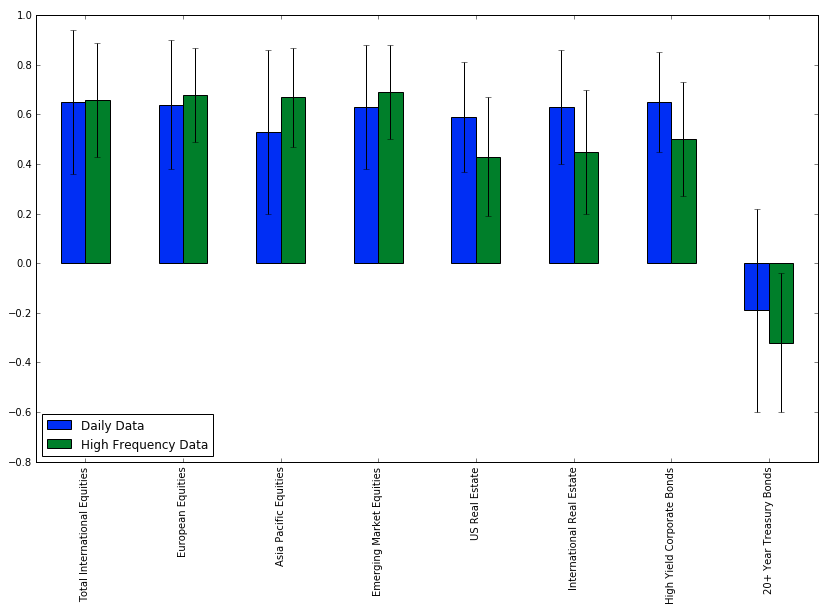
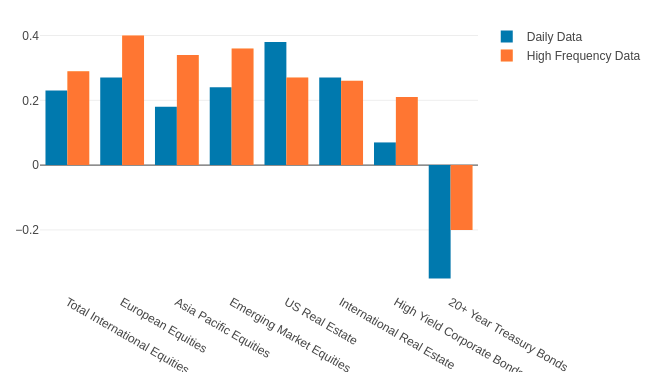
Gaurav Chakravorty
My dream is to make investing a science ... not a competition, but a truly inclusive process. The way I think we can come together to achieve that is to make investment management more (1) Thorough (2) Efficient (3) Transparent. Means: A.I and Tech




