











Geisa Santos
Workshops for more Diversity in Tech
a moeda da Era da Informação
Image: https://publish.illinois.edu/frontiers-big-data-symposium/
https://gist.github.com/fmasanori
Resource: https://github.com/ptwobrussell/Mining-the-Social-Web-2nd-Edition
Site do livro em inglês: http://pythonscraping.com
Código disponível: https://github.com/REMitchell/python-scraping
A ideia do Hackeando pela Diversidade é pensar em soluções que visam melhorar a vida de pessoas do público LGBT, mulheres cis e trans, como também pessoas portadoras de necessidades especiais e em situação de risco.
Repositório do Hack Nights: https://github.com/perifericas/hacknights
Pad (documento colaborativo) público: https://antonieta.vedetas.org/p/hackeando_diversidade
Extração
Limpeza
Análise
Visualização
Image credits: Udemy | Olhares.org
JavaScript Object Notation - www.json.org
Documentação Python: https://docs.python.org/3/library/json.html
http://jsonviewer.stack.hu/
Sensepedia:
API part 1 e 2 - bit.ly/2ffxEmc
API de AI - bit.ly/2e65UOf
Mais info em www.acessoainformacao.gov.br
Pedidos através do www.esic.gov.br
cd pasta
$ sudo apt-get install virtualenvwrapper
mkvirtualenv nome_da_env
Ou usando apenas virtualenv
cd pasta
$ sudo apt-get install python-virtualenv
virtualenv nome_da_env
source nome_da_env/bin/activate
Para desativar:
deactivate
Biblioteca BS4
Download: https://www.crummy.com/software/BeautifulSoup/
IDLE 1.1.1
>>> from BeautifulSoup import BeautifulSoup$sudo apt-get install python-bs4
Python3.x
$sudo python3 setup.py install
Ou pelo pip
(myenv) pip3 install beautifulsoup4 pip install scrapy
cat > myspider.py <<EOF
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://blog.scrapinghub.com']
def parse(self, response):
for title in response.css('h2.entry-title'):
yield {'title': title.css('a ::text').extract_first()}
next_page = response.css('div.prev-post > a ::attr(href)').extract_first()
if next_page:
yield scrapy.Request(response.urljoin(next_page), callback=self.parse)
EOF
scrapy runspider myspider.pyPython, R e Julia
Image credits: http://bit.ly/2eB4R9Q
p5js.org
py.processing.org
android.processing.org
Hora do Código
http://hello.processing.org
from urllib.request import urlopen
html = urlopen("http://raulhc.cc/Agenda/JSON")
print(html.read())Resultados
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://oxentimenina.wordpress.com/blog")
bsObj = BeautifulSoup(html.read());
print(bsOj.h1)Outras chamadas da função:
bsObj.html.body.h1
bsObj.body.h1
bsObj.html.h1
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://oxentimenina.wordpress.com/blog")
bsObj = BeautifulSoup(html.read());
print(bsOj.h1)import os
import json
import requests
from bs4 import BeautifulSoup
START_URL = "http://oxentimenina.wordpress.com/blog"
def get_posts_links():
"""
Returns an iterator with the a tags with the titles
"""
html = requests.get(START_URL).content
soup = BeautifulSoup(html)
return soup.findAll('a', rel='bookmark')
def extract_data_from_link(post_link_tag):
"""
Given a tag object, return it href value and post title
"""
return {
'link': post_link_tag.attrs['href'],
'title': post_link_tag.getText(),
}
def creates_output_file(data):
"""
Creates a json file with data parameter
"""
file_path = os.path.join(os.path.dirname(__file__), 'out.json')
with open(file_path, 'w') as fp:
json_data = json.dumps(data)
fp.write(json_data)
def extract_data_from_link(post_link_tag):
"""
Given a tag object, return it href value and post title
"""
return {
'link': post_link_tag.attrs['href'],
'title': post_link_tag.getText(),
}
def creates_output_file(data):
"""
Creates a json file with data parameter
"""
file_path = os.path.join(os.path.dirname(__file__), 'out.json')
with open(file_path, 'w') as fp:
json_data = json.dumps(data)
fp.write(json_data)
if __name__ == '__main__':
posts = get_posts_links()
data = []
for post in posts:
post_data = extract_data_from_link(post)
data.append(post_data)
creates_output_file(data)Resultados
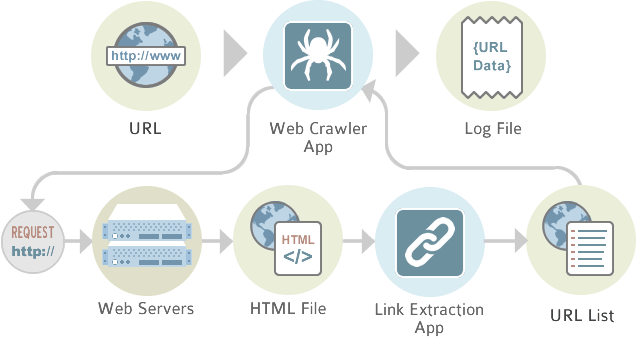
Web crawler, em português rastreador web, é um programa de computador que navega pela World Wide Web de uma forma metódica e automatizada.
Outros termos para Web crawlers são indexadores automáticos, bots, web spiders, Web robot, ou Web scutter.
Tutorial: http://support.import.io/knowledgebase/articles/740868-create-your-first-data-extractor
Exemplos: https://magic.import.io/examples
Canal no You Tube:
https://www.youtube.com/channel/UClf0cJlTFWyb5zmsBhjo2lg
https://github.com/stanfordjournalism/search-script-scrape
https://gist.github.com/fmasanori
By Geisa Santos
In proguess




