Data Oriented Programming
by Gendo (aka Daniele Maccioni)
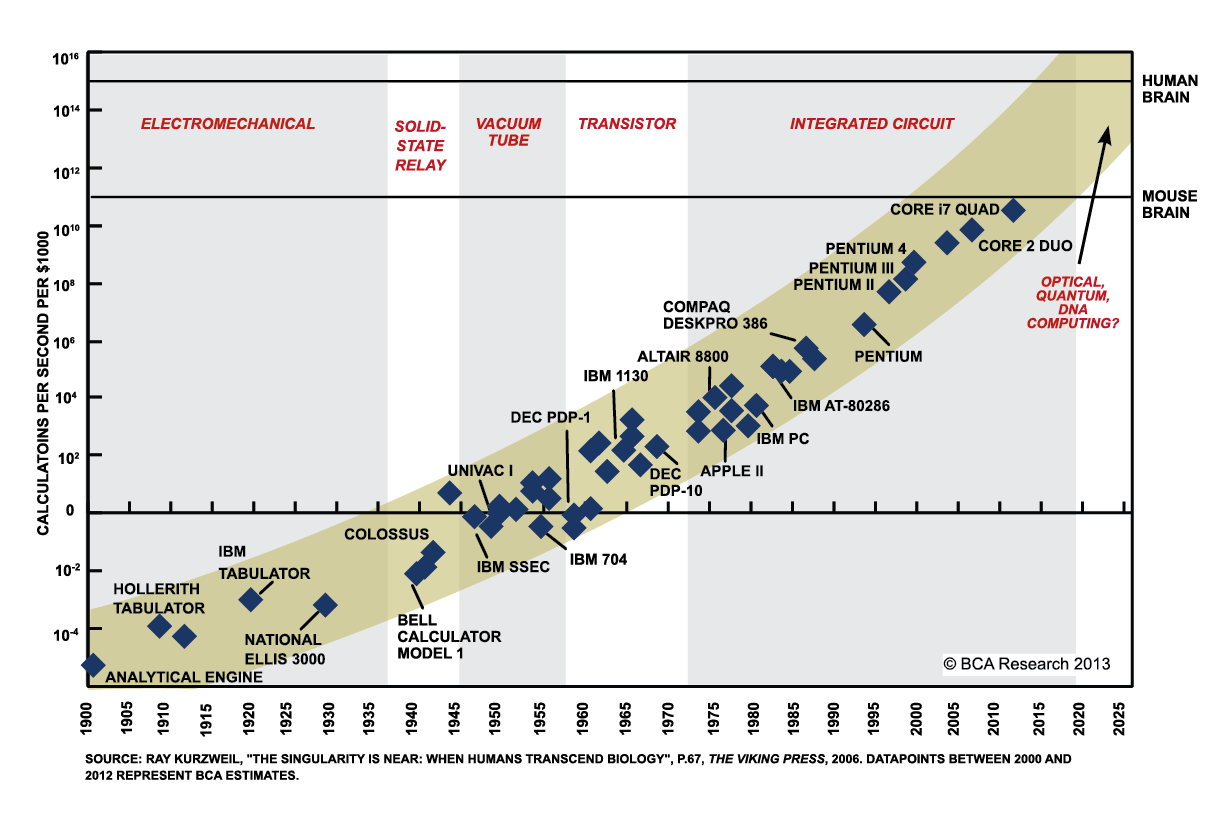
Moore's Law


Hello! I'm important too!
Memory Gap
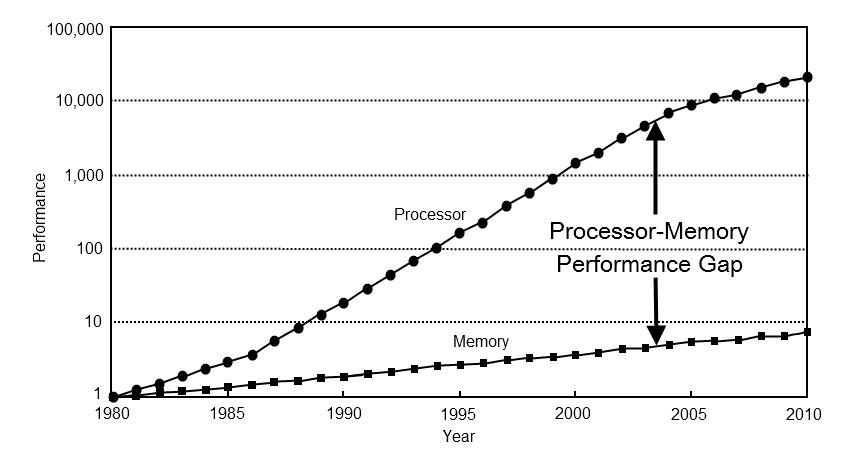
1980
RAM latency = ~1-2 cycles
2015
RAM latency = ~200 cycles
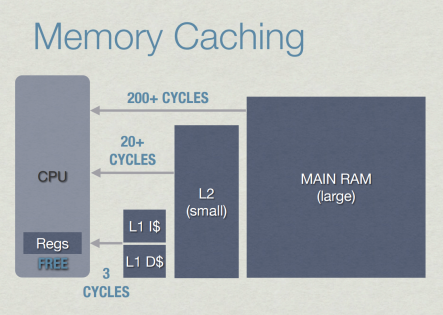
Cache Hit :)
- Fetch instruction or data
(L1-I vs L1-D) - Search for a cache entry with correct tag
- Load instruction
Cache Miss D:
- Every layer is an order of magnitude worse than the previous one
- L1 -> L2 -> RAM
- If everything fails and we need to access RAM, we can spend HUNDREDS of cycles just waiting
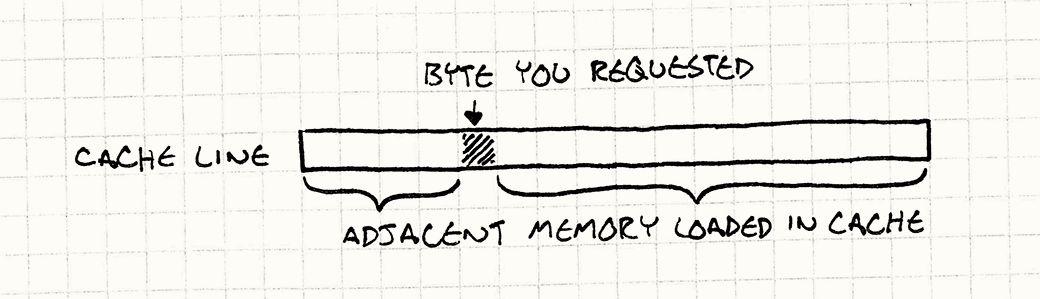
Spatial Locality
- if you reference a memory location it is likely that you will reference nearby locations too
Temporal Locality
- if you reference a memory location it is likely that you will reference it again in the near future
When a byte of code or data is loaded in cache from the RAM a chunk of contiguous memory is fetched instead, called: cache line
Memory is the bottleneck...
...and if you care about performance...
...software hardware is the platform!
Intel Haswell i7-4770
- 32 kb L1
- 256 kb L2
- 8 mb L3
- 64 b cache line
- L1 latency ~4-5 cycles
- L2 latency ~12 cycles
- L3 latency ~43 cycles
- RAM latency ~230 cycles

OOP
Is not
So great...
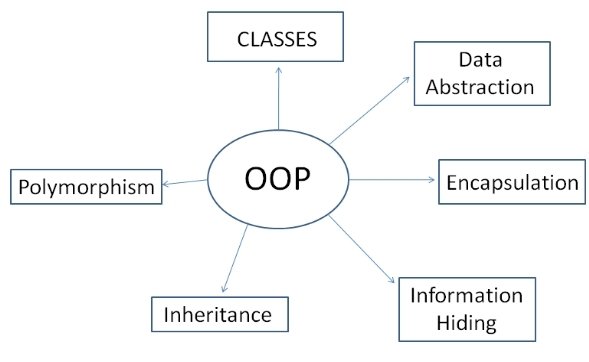
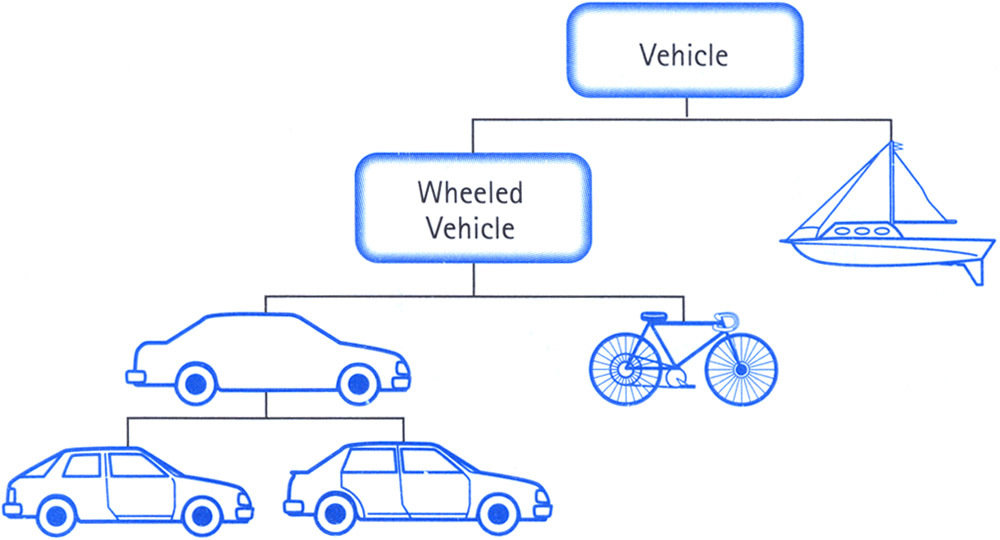
- Code following a model of the world
- Creating independent "reusable" objects"
- Hiding complexity
- Code and data mixed together
- Code is more important than data
- Array of structures or...
- ...array of pointers to structure
class Object {
public:
void addChild(Object *child);
void removeChild(Object *child);
virtual void update();
private:
int ID;
int width;
int height;
std::vector<Object *> children;
};
class MovableObject: public Object {
public:
void translate(int x, int y);
private:
int x;
int y;
};Side Effects
- Memory is very fragmented:
code mixed with data, polymorphism,
encapsulation, templates... - High complexity
- Very difficult to understand what's
going on under the hood - Tons of cache misses
- Memory unfriendly
- The cache will hate you
- ...
"General" Solutions
class ObjectManager : public Manager {
public:
// ...
void initObject(Object *);
void updateObject(Object *);
void removeObject(Object *);
// ...
};Do we really have only one object?
The common case for data is not considered
Branch Mispredictions
class SystemNetwork : public SystemSocket {
public:
// ...
void sendMessage(Message message) {
int message_type = message.type;
if (message_type == Message::Type::Text) {
// ...
} else if (message_type == Message::Type::Binary) {
// ...
}
if (inactive) {
// ...
}
}
// ...
};Difficult to predict the code path
Data
Oriented
Principles
- Guidelines to create simpler code...
- ...and cleaner code paths...
- ...that are also cache-friendly and more efficient
Is All About Data
- A software is a sequence of data transformations
- Problems are always about data
- Computers are data processing machines
Code Designed Around a Model of Data
- Data flow is the focus
- How data is read, how it is processed, how it is stored in memory
- Follow the nature of the problem data: minimize transformations
Implement the Common Case
- What's the common case for the data I'm dealing with?
- Implement the common case not the "general" solution
// The Common Case
void updateObjects(Objects *objects, int count) {
// ...
}
class Object {
// The 0.01%: I will always have multiple objects!
void update() {}
}Separate Code From Data
- Make data emerge from the code
- Simpler code
- Pipeline of data transformations
class Object {
// ...
int x
int y
void move(int x, int y);
// ...
}Point2D positions[COUNT_OBJS];
Point2D movements[COUNT_OBJS];
void moveObjects() {
for (int i = 0; i < COUNT_OBJS; ++i) {
positions[i] += movements[i];
}
}
Packing Data
- Avoid branching
- Avoid complex code path
class Object {
// ...
void update() {
if (active) {
// ...
} else {
// ...
}
}
// ...
};void updateObjects(Objects *objects) {
int numActives = sortByActive(objects);
for (int i = 0; i < numActives; ++i) {
// ...
Object *obj = objects[i];
// ...
}
}Hot/Cold Splitting
- Split very frequently used data from rarely used one
- Reduce the size of objects and structs in memory
- Make data flow more explicit
Avoid Polymorphism
- Simpler structure
- Easy memory layout
- Arrays of simple homogeneous data are better than complex hierarchies
- Avoid vtable
- Avoid memory fragmentation
Happy Cache
- Data is gathered together in homogeneous chunks of memory
- Memory layout is simpler
- More predictable code paths
- One array for each type of data
- Logic grouped together to use what's already in cache
- No virtual methods and tables that make you jump around in memory
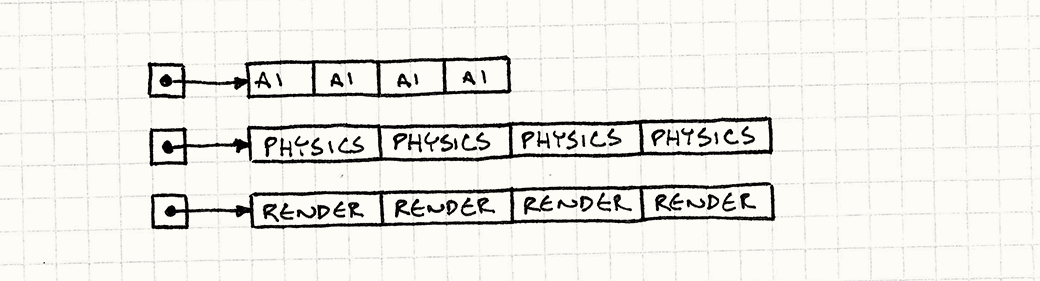
What can we do?
- Flat the hierarchy
- Avoid array of pointers
- Extract data from code
- Identity the transformation flow
- Pre-allocate memory
- Group similar operations together
Questions?
Data Oriented Programming
By Gendo Ikari
Data Oriented Programming
Cpp2016



