













Vladislav Shpilevoy PRO
Backend C++ developer at VirtualMinds. Database C developer at Tarantool.
Системное программирование
Лекция 3:
Память. Виртуальная и физическая. Уровни кэша, кэш линия. Пользовательская память и память ядра. False sharing. High and low memory.
Version: 2
The presentation is outdated and not maintained anymore. Please, refer to the English version for the most actual slides.
Дедлайны:
.text
.data
.stack
.heap
.stack
.stack
Файловые дескрипторы
Очередь сигналов
IPC
Память
0x0
0xffffffff
.text
.data
.bss
.heap
.stack
.env
struct task_struct {
/* ... */
struct files_struct *files;
/* ... */
};
struct files_struct {
struct fdtable *fdt;
};
struct fdtable {
unsigned int max_fds;
struct file **fd;
};
struct file {
struct path f_path;
struct inode *f_inode;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
loff_t f_pos;
const struct cred *f_cred;
};Процесс хранит открытые файлы
В таблице дескрипторов
Таблица - обычный массив
Дескриптор в ядре - это структура. В user space - число. Индекс в массиве дескрипторов.
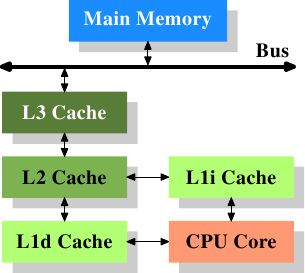
Регистры
Кэш L1
Кэш LN
Оперативная память
Флеш память
Магнитная память
Скорость
Объем
Сохранение
Что сохранить
Хранимое значение
NAND - Not And
Static Random Access Memory - SRAM
pc
mar
ir
asid
eax
ebx
ecx
edx
esi
...
<128 бит
Временная локальность
Пространственная локальность
for (int a = 0; i < count; ++i)
{
/* ... cache 'a' */
}char buffer[128];
/* ... cache buffer */
read(buffer, 0, 64);
/* ... */
read(buffer, 64, 128);
/* ... */
read(buffer, 32, 96);
/* ... */| Кэш | Размер | Скорость доступа |
|---|---|---|
| L1 | десятки Кб | ~1 такт, < наносекунды |
| L2 | единицы Мб | десятки тактов, единицы наносекунд |
| L3 | десятки Мб | сотни тактов, десятки наносекунд |
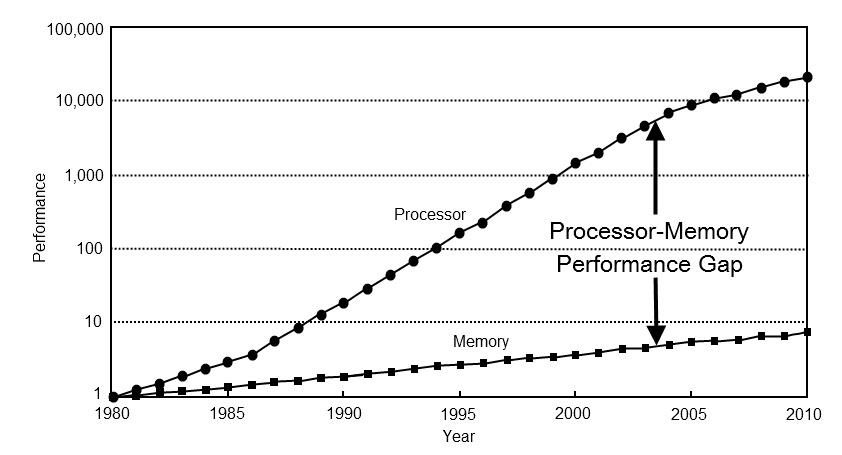
Почему такая разница скоростей кэшей?
Больше размер - дольше поиск. Дальше от процессора - ток передается дольше.
2 балла
1 - в большом кеше дольше поиск, много сравнений
2 - дорога до кеша и обратно тоже стоит времени
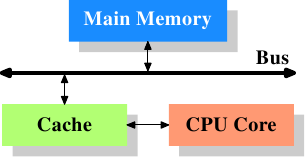
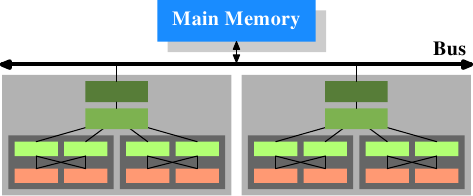
Оперативная память
Шина
Кэш L3
Кэш L2
Кэш L1
Ядро
Чип процессора
Inclusive
L3
L2
L1
Exclusive
L3
L2
L1
NINE
L3
L2
L1
L1
L2
Х
Пусть процессор читает Х ...
Взять из L1
L1
L2
Х
Скопировать в L1
Х
L1
L2
Х
Скопировать в L1 и L2
Х
Y
Y
Взять из L1
Починить включаемость
Взять из L1
Y
L1
L2
Х
Пусть процессор читает Х ...
Взять из L1
L1
L2
Х
Переместить в L1
Х
L1
L2
Х
Скопировать в L1
Взять из L1
Взять из L1
Как пополняются L2, L3 exclusive кэши?
За счет вытеснения из предыдущих кэшей.
L1
L2
Х
Вытеснить старое в L2, новое положить в L1
Взять из L1
Y
Y
2 балла
Not Inclusive Not Exclusive
L1
L2
Х
Взять из L1
L1
L2
Х
Скопировать в L1 и L2
Взять из L1
L1
L2
Х
Скопировать в L1
Х
Взять из L1
Y
Y
X
Нет миграции в L2 - not exclusive
Нет вытеснения L1 из-за L2 - not inclusive
Y
L3
L2
L1
Оперативная память
Write through
Нужно ждать конец записи
L3
L2
L1
Оперативная память
Write back
Установить dirty bit
Нужно синхронизировать кеши c другими ядрами
64 б
64 б
64 б
64 б
64 б
...
addr1
addr2
addr3
addr4
addrN
char *
read_from_cache(unsigned long addr)
{
/* This is machine code, 64 bit. */
unsigned offset = addr & 63;
unsigned cache_addr = addr ~ offset;
char *line = lookup_line(cache_addr);
return line + offset;
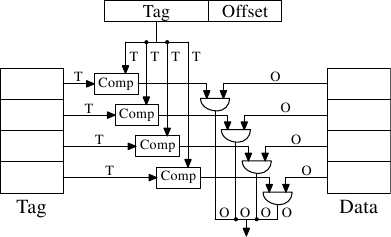
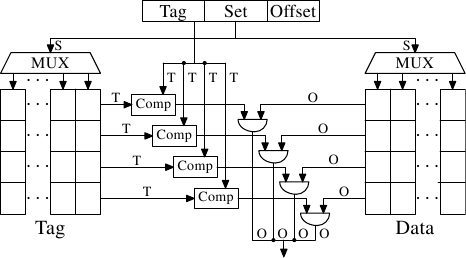
}Политика отображения адресов
Хранение и чтение блоками
64 байта
Кэш-линия:
Интерпретация адреса кэшом:
tag
tag
offset
6 бит
policy helper
user data
Адреса
Кеш
...
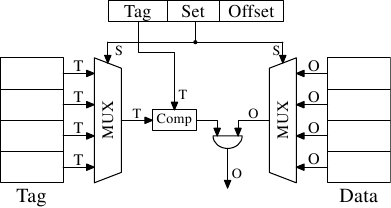
Адрес
tag
offset
6 бит
58 бит
Аппаратная схема
Адреса
Кеш
Адрес
tag
offset
6 бит
26 бит
Аппаратная схема
index
32 бита
Адреса
Кеш
Адрес
tag
offset
6 бит
Аппаратная схема
index
...
- количество cache lines
Разница сглаживается
<opcode> := <argcount> <argtypes> <indirect_args>
<ret_type> <target_dev>Число параметров
Типы параметров
Неявные параметры
Возвращаемый тип
Где выполнять?
CPU Pipeline:
Общий кэш?
Раздельный кэш?
struct my_object {
int32_t a;
int32_t b;
int32_t c;
int32_t d;
};
struct my_object object;
void
thread1_func()
{
while (true) {
do_something(object.a);
do_something(object.b);
}
}
void
thread2_func()
{
while (true) {
write_into(&object.c);
write_info(&object.d);
}
}a, b
c, d
Кэш-линия
8 байт
8 байт
48 байт
Читающий поток
Пишущий поток, инвалидирует кеш
struct my_object {
int32_t a;
int32_t b;
char padding[56];
int32_t c;
int32_t d;
};a, b
padding
Кэш-линии
8 байт
56 байт
Читающий поток
Пишущий поток
c, d
8 байт
56 байт
Сейчас тут
Выполнение наперед, предсказание условий
Проверка привелегий уже после кеширования
static jmp_buf jmp;
void
process_signal(int code)
{
printf("Process SIGSEGV, code = %d, "\
"SIGSEGV = %d\n", code, SIGSEGV);
longjmp(jmp, 1);
}
int
main()
{
char *p = NULL;
signal(SIGSEGV, process_signal);
printf("Before SIGSEGV\n");
if (setjmp(jmp) == 0)
*p = 100;
printf("After SIGSEGV\n");
return 0;
}Добиться сегфолта не сложно - сделать доступ в плохую память
vladislav$> gcc 2_catch_sigsegv.c vladislav$> ./a.out Before SIGSEGV Process SIGSEGV, code = 11, SIGSEGV = 11 After SIGSEGV vladislav$>
На SIGSEGV вешается обработчик, который сразу возвращает управление
char userspace_array[256 * 4096];
char kernel_byte_value;
char
get_kernel_byte(const char *kernel_addr)
{
clear_cache_for(userspace_array);
register_exception_handler(process_exception);
char index = *kernel_addr;
/* Next code is for speculation. */
char unused = userspace_array[index * 4096];
/* Next code is after exception handler. */
return kernel_byte_value;
}
void
process_exception()
{
uint min_time = UINT_MAX;
for (char i = 0; i < 256; ++i) {
uint start = time();
char unused = userspace_array[i * 4096];
uint duration = time() - start;
if (duration < min_time) {
min_time = duration;
kernel_byte_value = i;
}
}
}Сюда будет читаться ядро
Очищаем кеши, так как атака требует пустых кешей
Чтение запретного адреса в переменную, которая поместит в кэш другую доступную переменную
Ядро даст исключение, но нужный элемент уже в кеше. Его индекс - это значение из ядра
PROFIT
Average Access Time
Допустим такие значения:
Тогда:
x44
Latency Comparison Numbers (~2012)
----------------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns
Mutex lock/unlock 25 ns
Main memory reference 100 ns
Compress 1K bytes with Zippy 3,000 ns
Send 1K bytes over 1 Gbps network 10,000 ns
Read 4K randomly from SSD* 150,000 ns
Read 1 MB sequentially from memory 250,000 ns
Round trip within same datacenter 500,000 ns
Read 1 MB sequentially from SSD* 1,000,000 ns
Disk seek 10,000,000 ns
Read 1 MB sequentially from disk 20,000,000 ns
Send packet CA->Netherlands->CA 150,000,000 nsstruct complex_struct {
int id;
double a;
long d;
char buf[10];
char *long_buf;
};
struct complex_struct *
complex_struct_bad_new(int long_buf_len)
{
struct complex_struct *ret =
(struct complex_struct *) malloc(sizeof(*ret));
ret->long_buf = (char *) malloc(long_buf_len);
return ret;
}
struct complex_struct *
complex_struct_good_new(int long_buf_len)
{
struct complex_struct *ret;
int size = sizeof(*ret) + long_buf_len;
ret = (struct complex_struct *) malloc(size);
ret->long_buf = (char *) ret + sizeof(*ret);
return ret;
}
int main()
{
return 0;
}Это плохо
В одной кэш линии
Ничего не знаем про кэш
Dynamic Random Access Memory - DRAM
DRAM бит
SRAM бит
Основная проблема - установка/снятие бита занимает время
Диски?
Просто внешние устройства, передают данные через оперативную память, обращения через ядро
Выше - виртуальная память.
Memory Management Unit - устройство для аппаратной трансляции в физический адрес
Физическая и виртуальная память бьются на страницы по 4-8Кб
virt_page
offset
MMU:
Виртуальный адрес
1.
2.
3.
4.
5.
6.
7.
123
54
68
90
230
170
13
Номер физической страницы
Индекс массива - номер виртуальнойстраницы
void *
translate(void *virt)
{
int virt_page = virt >> offset_bits;
int phys_page = page_table[virt_page];
int offset = virt ~ (virt_page << offset_bits);
return (phys_page << offset_bits) | offset;
}Одна большая таблица? Слишком дорого.
Все в память? Слишком медленно.
Page table
Как решить проблему MMU и таблицы страниц?
Не знаешь, что делать - сделай кэш.
2 балла
1.
2.
3.
4.
5.
6.
7.
123
54
68
90
230
170
13
Page table
187.
232.
34.
48.
519.
94.
58
123
54
68
90
230
170
13
TLB
Translation Lookaside Buffer
std::vector<unsigned>std::map<unsigned, unsigned>Аппаратная, < 100 записей. По сути и есть MMU.
Программная, тысячи, миллионы записей
Процессор наперед подгружает нужные страницы. Можно помочь ему при помощи
__builtin_prefetchContent Addressable Memory - CAM
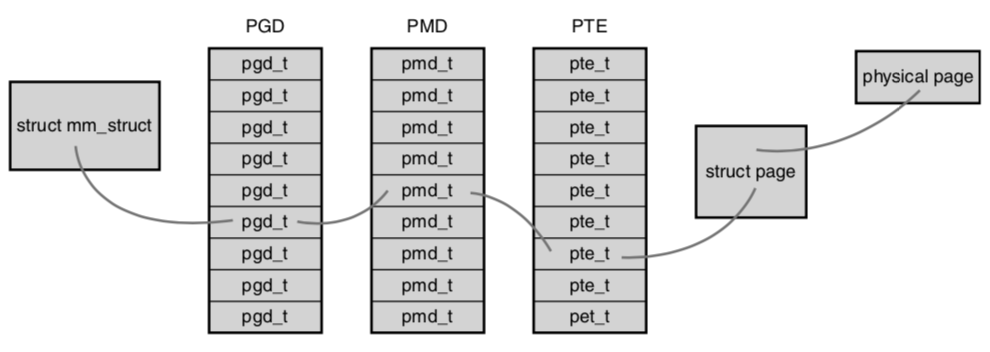
Page global directory
Page middle directory
Page table entry
L1_idx
Виртуальный адрес
L2_idx
offset
Как делить TLB между разными процессами?
Идентификатор адресного пространства - Address Space Identifier, ASID. Это неявный префикс для любого адреса активного процесса в таблицах страниц.
2 балла
/**
* 16.10.2018
* 138 lines.
*/
struct page {
unsigned long flags;
void *virtual;
struct list_head lru;
};Понятие страницы скрыто от пользователя в ядре
В ядре тоже виртуальная память и свои аллокаторы
void *
kmalloc(size_t size, gfp_t flags);
void *
vmalloc(unsigned long size);Таблицы страниц обслуживаются ядром
0x0
0xffffffff
.text
.data
.bss
.heap
.stack
.env
0xс0000000
.kernel
Проблема High и Low memory на 32-битной архитектуре
3Gb для пользователей
~800Мб ядро
~200Мб резерв
KASLR - Kernel Address Space Layout Randomization
KAISER - Kernel Address Isolation to have Side-channels Efficiently Removed
Борьба с атаками на ошибки кода, на прямые уязвимости
Борьба с Meltdown - с побочным каналом утечки
#define __builtin_prefetch
#define __builtin_expect
int
madvise(void *addr, size_t len, int advice);Кэши, физическая память скрыты от пользователя, кроме нескольких подсказок
Но доступна виртуальная память
void *
mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);
void *
brk(const void *addr);
void *
alloca(size_t size);
void *
malloc(size_t size);32MB
32MB
16MB
16MB
16MB
16MB
8MB
8MB
8MB
8MB
8MB
8MB
8MB
8MB
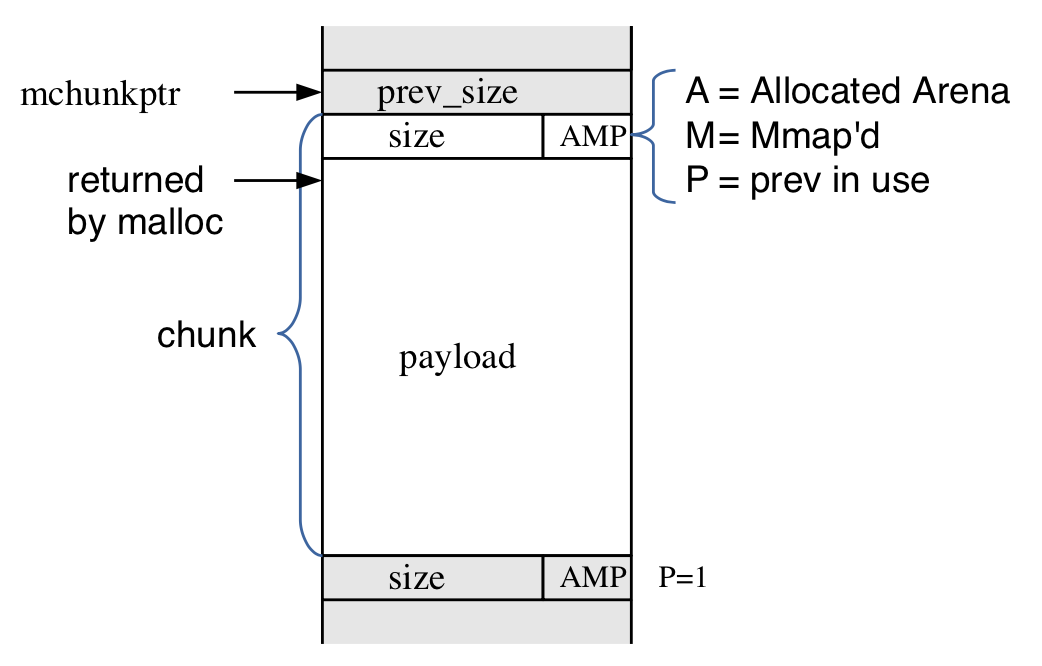
malloc(size);Округляет до ближайшего блока, заполняет заголовки, отдает
Shell
Нужно написать упрощенную версию командной строки. Она должна принимать на вход строки вида:
> command_name param1 param2 ...
и выполнять их при помощи вызова команды command_name с параметрами. То есть работать как терминал.
Нужно реализовать поддержку pipe - |, перенаправления вывода в файл - >, >>.
Цена: 15 - 25 баллов.
Срок: 2 недели после дедлайна первого ДЗ.
Положить на ваш гитхаб и сказать мне его. Сдавать как угодно - лично/удаленно.
Обратная связь: goo.gl/forms/TAeraYrqJcil7GDt1
и на портале Техносферы
В следующий раз:
Сигналы. Аппаратные и программные прерывания, их природа. Top and bottom halves. Сигналы и системные вызовы, контекст сигнала.
By Vladislav Shpilevoy
Виртуальная и физическая память. Cache, cache line, cache levels, cache coherence, false sharing. High and low memory, области памяти. Page tables. Память ядра и процесса пользователя, разметка, вызовы: kmalloc, vmalloc, brk, madvice, mmap, pmap. Malloc, его альтернативы.




