


















Vladislav Shpilevoy PRO
Backend C++ developer at VirtualMinds. Database C developer at Tarantool.
Version: 3
System programming
Lecture 3:
Memory. Virtual and physical. Cache levels, cache line. User space and kernel space memory. False sharing.
.text
.data
.stack
.heap
.stack
.stack
File descriptors
Signal queue
IPC
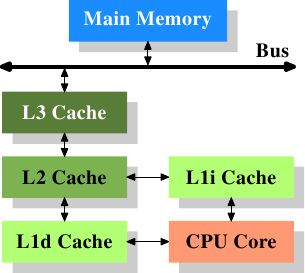
Memory
Registers
Cache L1
Cache LN
Main memory
Flash memory
Magnetic memory
Speed
Volume
Trigger to save a value
Value to save
Saved value
NAND - Not And
Static Random Access Memory - SRAM
pc
mar
ir
asid
eax
ebx
ecx
edx
esi
...
<=128 bits
Time locality
Space locality
for (int i = 0; i < count; ++i)
{
/* ... cache 'i' */
}char buffer[128];
/* ... cache buffer */
read(buffer, 0, 64);
/* ... */
read(buffer, 64, 128);
/* ... */
read(buffer, 32, 96);
/* ... */| Cache | Size | Access speed |
|---|---|---|
| L1 | tens of Кб | ~1 tick, < nanosecond |
| L2 | ones of Мб | tens of ticks, ones of nanoseconds |
| L3 | tens of Мб | hundreds of ticks, tens of nanoseconds |
Why so big difference in access speeds to cache levels?
Bigger size - longer search. Farther from processor - electricity goes notably longer.
1 point
1 - in a big cache search is longer, many comparisons
2 - going to a place in the cache and back really costs time
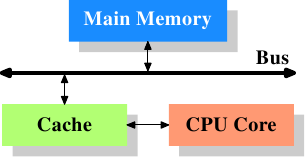
Main memory
Bus
Cache L3
Cache L2
Cache L1
Processor core
Processor chip
Inclusive
L3
L2
L1
Exclusive
L3
L2
L1
NINE
L3
L2
L1
L1
L2
Х
A processor reads Х ...
Read from L1
L1
L2
Х
Copy into L1
Х
L1
L2
Х
Load into L1 and L2
Х
Y
Y
Read from L1
Fix inclusion
Read from L1
Y
Х
L1
L2
Х
Read from L1
L1
L2
Х
Move to L1
Х
L1
L2
Х
Load into L1
Read from L1
Read from L1
A processor reads Х ...
How are filled L2, L3 exclusive cache levels?
With records evicted from the previous level
L1
L2
Х
Evict old into L2, load new into L1
Read from L1
Y
Y
1 point
Not Inclusive Not Exclusive
L1
L2
Х
Read from L1
L1
L2
Х
Load into L1 and L2
Read from L1
L1
L2
Х
Copy into L1
Х
Read from L1
Y
Y
X
Same data in L1 and L2 - not exclusive
No eviction from L1 to satisfy inclusion with L2 - not inclusive
Y
L3
L2
L1
Main memory
Write through
Need to wait when write is done
L3
L2
L1
Main memory
Write back
Set dirty bit
Need to sync caches between processor cores
64 B
64 B
64 B
64 B
64 B
...
addr1
addr2
addr3
addr4
addrN
char *
read_from_cache(unsigned long addr)
{
/* This is machine code, 64 bit. */
unsigned offset = addr & 63;
unsigned cache_addr = addr ~ offset;
char *line = lookup_line(cache_addr);
return line + offset;
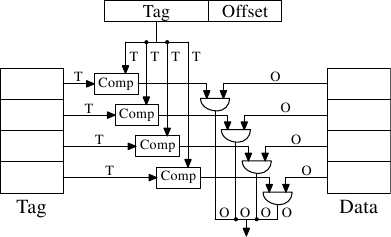
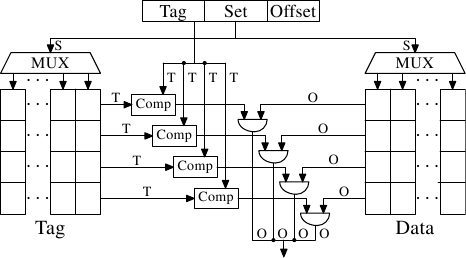
}Address mapping policy
Storage and reading in blocks
64 bytes
Cache line:
Address layout:
tag
tag
offset
6 bits
policy helper
user data
Addresses
Cache
...
Address
tag
offset
6 bits
58 bits
Hardware schema
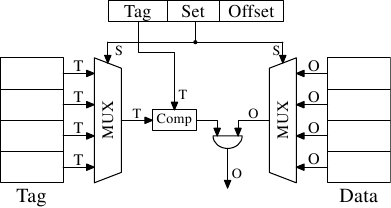
Addresses
Cache
Address
tag
offset
6 bits
26 bits
Hardware schema
index
32 bits
Addresses
Cache
Address
tag
offset
6 bits
Hardware schema
index
...
- cache line count
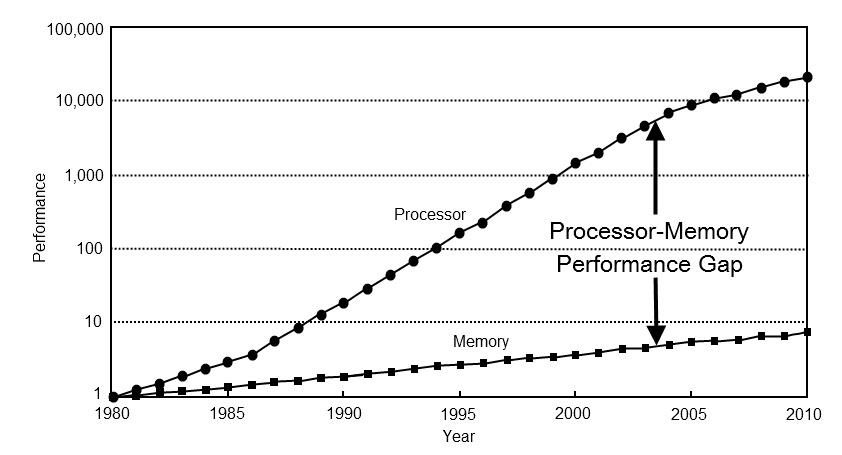
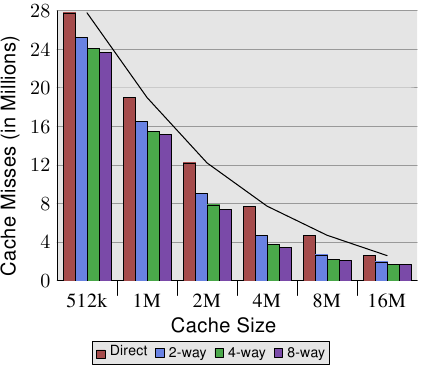
Gap declines and almost disappears
<opcode> := <argcount> <argtypes> <indirect_args>
<ret_type> <target_dev>Argument count
Argument types
Implicit arguments
Return type
Where to execute?
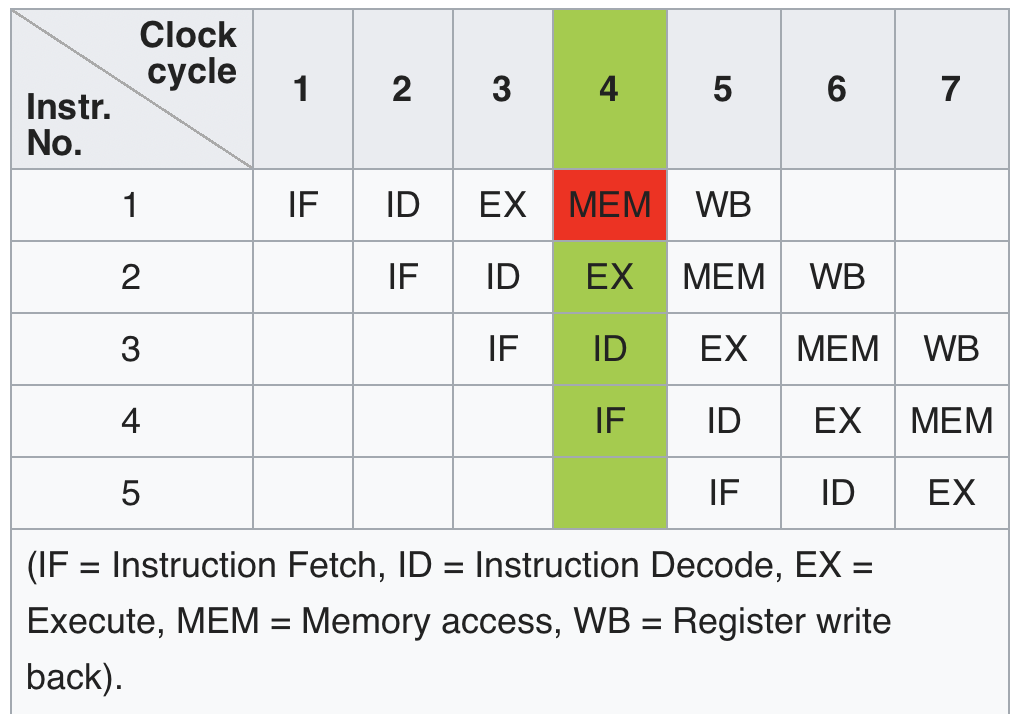
CPU Pipeline:
are decoding
instructions now
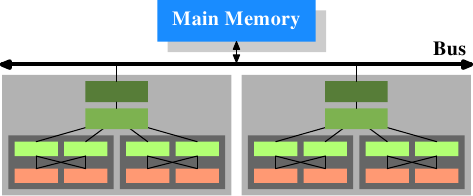
Shared cache?
Separate cache?
struct my_object {
int32_t a;
int32_t b;
int32_t c;
int32_t d;
};
struct my_object object;
void
thread1_func()
{
while (true) {
do_something(object.a);
do_something(object.b);
}
}
void
thread2_func()
{
while (true) {
write_into(&object.c);
write_info(&object.d);
}
}a, b
c, d
Cache line
8 bytes
8 bytes
48 bytes
Reading thread
Writing thread, invalidates the cache
struct my_object {
int32_t a;
int32_t b;
char padding[56];
int32_t c;
int32_t d;
};a, b
padding
Cache lines
8 bytes
56 bytes
Reading thread
Writing thread
c, d
8 bytes
56 bytes
Since C++17 can use
std::hardware_destructive_interference_size.
Now here
Execution in advance, speculation, branch prediction
Privileges check after speculation
static jmp_buf jmp;
void
process_signal(int code)
{
printf("Process SIGSEGV, code = %d, "\
"SIGSEGV = %d\n", code, SIGSEGV);
longjmp(jmp, 1);
}
int
main()
{
char *p = NULL;
signal(SIGSEGV, process_signal);
printf("Before SIGSEGV\n");
if (setjmp(jmp) == 0)
*p = 100;
printf("After SIGSEGV\n");
return 0;
}It is not hard to get segfault - just access invalid memory
vladislav$> gcc 2_catch_sigsegv.c vladislav$> ./a.out Before SIGSEGV Process SIGSEGV, code = 11, SIGSEGV = 11 After SIGSEGV vladislav$>
Set a handler on SIGSEGV, which ignores it
char userspace_array[256 * 4096];
char kernel_byte_value;
char
get_kernel_byte(const char *kernel_addr)
{
clear_cache_for(userspace_array);
register_exception_handler(process_exception);
char index = *kernel_addr;
/* Next code is for speculation. */
char unused = userspace_array[index * 4096];
/* Next code is after exception handler. */
return kernel_byte_value;
}
void
process_exception()
{
uint min_time = UINT_MAX;
for (char i = 0; i < 256; ++i) {
uint start = time();
char unused = userspace_array[i * 4096];
uint duration = time() - start;
if (duration < min_time) {
min_time = duration;
kernel_byte_value = i;
}
}
}Location to read kernel memory into
Cleanup caches, because the attack needs them empty
Read a forbidden address into a variable, which then is used to read another memory location
The kernel throws a segfault, but the needed element is already loaded into a cache. Its index is a value from the kernel memory
PROFIT
Average Access Time
Assume these pessimistic values:
Result average access time:
x44
Latency Comparison Numbers (~2012)
+ "World constants 2022" from Andrey Aksenov
----------------------------------
L1 cache reference 0.3 ns
Branch mispredict 5 ns
L2 cache reference 7 ns
Main memory reference 25 ns
Mutex lock/unlock 100 ns
Compress 1K bytes with Zippy 3,000 ns
Send 1K bytes over 1 Gbps network 10,000 ns
Read 1 MB sequentially from memory 66,000 ns
Read 4K randomly from SSD* 150,000 ns
Read 1 MB sequentially from SSD* 333,000 ns
Round trip within same datacenter 500,000 ns
Disk seek 10,000,000 ns
Read 1 MB sequentially from disk 20,000,000 ns
Send packet CA->Netherlands->CA 150,000,000 nsstruct complex_struct {
int id;
double a;
long d;
char buf[10];
char *long_buf;
};
struct complex_struct *
complex_struct_bad_new(int long_buf_len)
{
struct complex_struct *ret =
(struct complex_struct *) malloc(sizeof(*ret));
ret->long_buf = (char *) malloc(long_buf_len);
return ret;
}
struct complex_struct *
complex_struct_good_new(int long_buf_len)
{
struct complex_struct *ret;
int size = sizeof(*ret) + long_buf_len;
ret = (struct complex_struct *) malloc(size);
ret->long_buf = (char *) ret + sizeof(*ret);
return ret;
}
int main()
{
return 0;
}This is bad
Structure and its buffer are sequential in memory and in one cache line
*This is good
Dynamic Random Access Memory - DRAM
DRAM bit
SRAM bit
Main memory - main problem. It is slow
Disks
External devices, transfer data through main memory, accessed via kernel always
Next is virtual memory
Memory Management Unit - a chip to translate virtual addresses into physical ones
Physical and virtual memory consists of pages of fixed size (like 4-8 KB)
virt_page
offset
MMU:
Virtual address
// Linux-specific
size = getpagesize();
// Portable.
size = sysconf(_SC_PAGESIZE);
1.
2.
3.
4.
5.
6.
7.
123
54
68
90
230
170
13
Physical page number
Array index - virtual page number
void *
translate(void *virt)
{
int virt_page = virt >> offset_bits;
int phys_page = page_table[virt_page];
int offset = virt ~ (virt_page << offset_bits);
return (phys_page << offset_bits) | offset;
}One huge hardware table? - too expensive
Everything in main memory? - too slow
Page table
How to solve MMU and page table lookup speed problem?
Don't know what to do? - add a cache
1 point
1.
2.
3.
4.
5.
6.
7.
123
54
68
90
230
170
13
Page table
187.
232.
34.
48.
519.
94.
58
123
54
68
90
230
170
13
TLB
Translation Lookaside Buffer
std::vector<unsigned>std::map<unsigned, unsigned>Hardware, < 100 records. It is a core part of MMU.
Programmatic, thousands and millions of records
Processor loads needed pages in advance, before they are accessed. It can be helped with
__builtin_prefetchContent Addressable Memory - CAM
Page global directory
Page middle directory
Page table entry
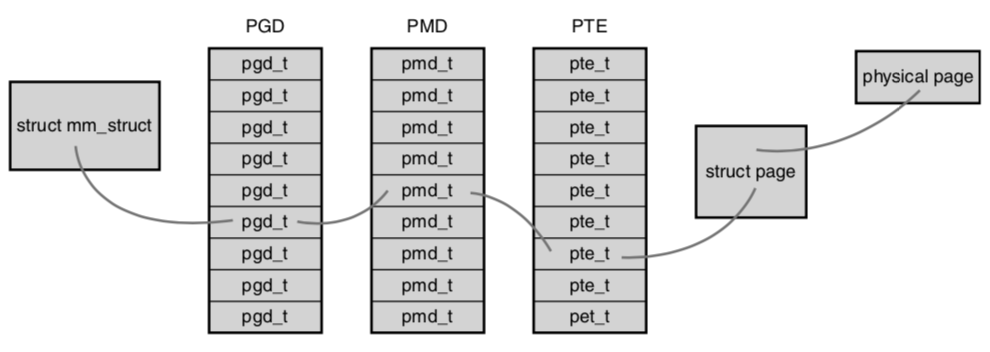
L1_idx
Virtual address
L2_idx
offset
L3_idx
How to share TLB between processes?
Address Space Identifier, ASID. It is an implicit prefix of each address in the TLB, and each process has ASID.
1 point
/**
* 16.10.2018
* 138 lines.
*/
struct page {
unsigned long flags;
void *virtual;
struct list_head lru;
};Page tables are maintained by the kernel
0x0
0xffffffff
.text
.data
.bss
.heap
.stack
.env
0xс0000000
.kernel
KASLR - Kernel Address Space Layout Randomization
KAISER - Kernel Address Isolation to have Side-channels Efficiently Removed
Fight against errors in the kernel code
Fight against attacks like Meltdown - with an implicit channel leaking information
#define __builtin_prefetch
#define __builtin_expect
int
madvise(void *addr, size_t len, int advice);Cache and physical memory concepts are hidden from user, except for some small bits of info
But virtual memory management is fully accessible in user space
void *
mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);
void *
brk(const void *addr);
void *
alloca(size_t size);
void *
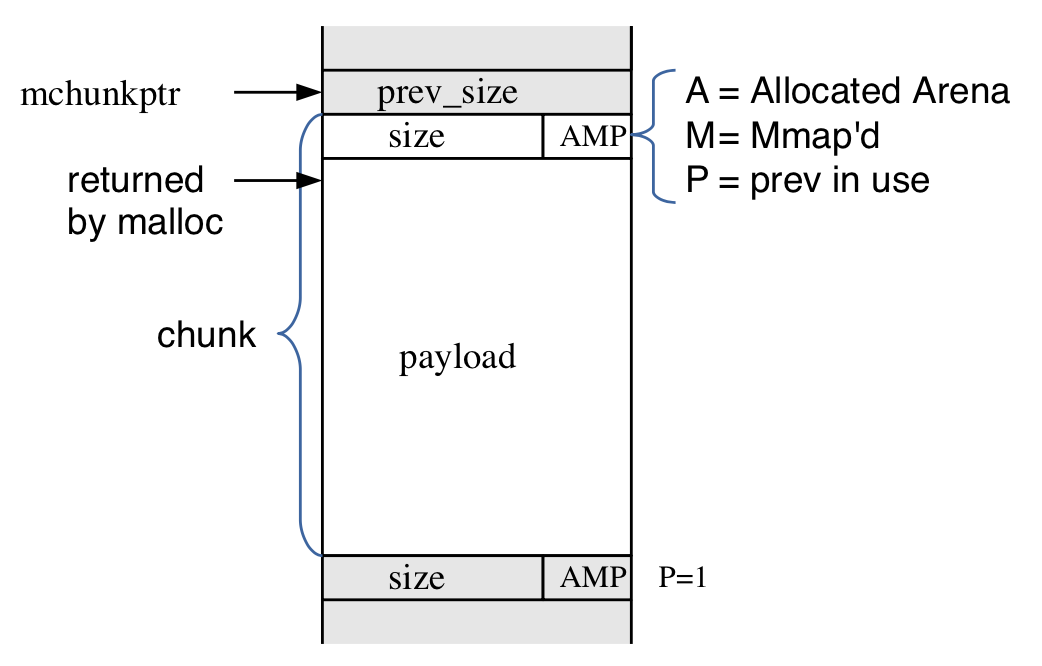
malloc(size_t size);32MB
32MB
16MB
16MB
16MB
16MB
8MB
8MB
8MB
8MB
8MB
8MB
8MB
8MB
malloc(size);Rounds up to the nearest block size, fills headers, returns
Memory has many layers - CPU registers, CPU cache, main (RAM)), virtual addresses, abstractions like heap
Virtual addresses are important. All processes have the same address space, but different mappings to the physical memory. Same virtual address in 2 processes always* points at 2 different physical bytes.
Kernel manages memory in pages. Both physical and virtual. For each process it stores a map like {virtual page address -> physical page address}. Page address points at its first byte.
Hardware translates the addresses on each memory access. Special device TLB uses a cached subset of the page mapping. Sometimes it falls back to the kernel for pages missing in the cache.
Heap, stack, mmap also operate on virtual addresses and whole pages. They are just abstractions on top of the virtual address space.
Shell
Write a simplified version of a command line console. It should read lines like this:
> cmd1 arg arg | cmd2 arg | cmd3 arg arg arg ...
and execute them, just like a normal console, like 'bash'. Use pipe() + dup() + fork() + exec().
Points: 15 - 25.
Deadline: 3 weeks.
Expected complexity: ~300 lines
Penalty: -1 for each day after deadline, max -10
Publish your solution on Github and give me the link. Assessment: any way you want - messengers, calls, emails.
Lectures: slides.com/gerold103/decks/sysprog_eng
Next time:
Signals. Hardware and programmatic interrupts, their nature. Top and bottom halves. Signals and system calls, signal context.
Press on the heart, if like the lecture
By Vladislav Shpilevoy
Virtual and physical memory. Cache, cache line, cache levels, cache coherence, false sharing. High and low memory. Page tables. User space and kernel space memory, layout. Functions brk, madvice, mmap. Malloc and alternative libraries.




