









Grégoire Hébert
PHP / Symfony lead Developper @ Les-Tilleuls.coop
Lead-Developper & Formateur @ Les-Tilleuls.coop
@gheb_dev
REACTIVE MACHINES (Scenarii reactive)
LIMITED MEMORY (+ aware of changes in an environment)
THEORY OF MIND (+ aware of the people in it)
SELF AWARE (+ capable of self councious choices)
REACTIVE MACHINES (Scenarii reactive)
LIMITED MEMORY (+ aware of changes in an environment)
THEORY OF MIND (+ aware of the people in it)
SELF AWARE (+ capable of self councious choices)
IN
IN
?
IN
?
OUT
IN
?
OUT
PERCEPTRON
?
?
Or NOT
?
0 -> 10
Or NOT
?
0 -> 1
0 -> 10
Or NOT
?
0 -> 1
0 -> 10
Or NOT
0 -> 1
?
0 -> 1
0 -> 10
Or NOT
0 -> 1
0 -> 1
?
0 -> 1
0 -> 10
Or NOT
0 -> 1
0 -> 1
0 -> 1
?
0 -> 1
activation
0 -> 10
Or NOT
0 -> 1
activation
0 -> 1
0 -> 1
?
0 -> 1
BinaryStep
Gaussian
HyperbolicTangent
Parametric Rectified Linear Unit
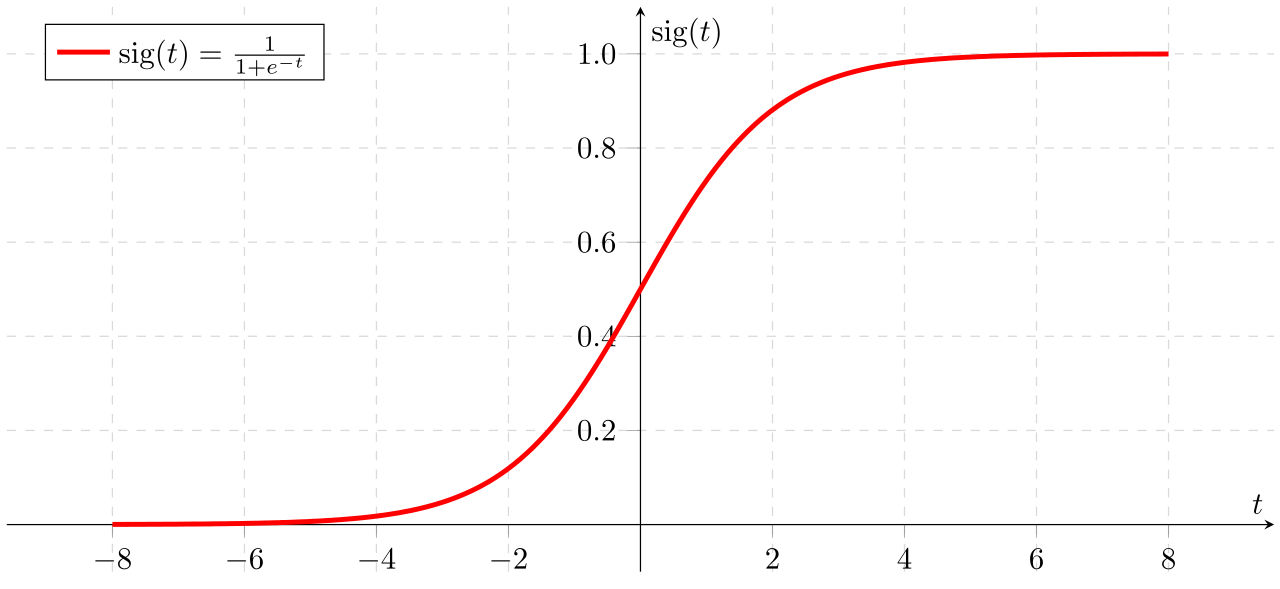
Sigmoid (default)
Thresholded Rectified Linear Unit
0 -> 10
Or NOT
activation
0 -> 1
activation
0 -> 1
0 -> 1
?
0 -> 1
0 -> 10
Or NOT
BinaryStep
Gaussian
HyperbolicTangent
Parametric Rectified Linear Unit
Sigmoid (default)
Thresholded Rectified Linear Unit
activation
0 -> 1
activation
0 -> 1
0 -> 1
?
0 -> 1
0 -> 10
Or NOT
BinaryStep
Gaussian
HyperbolicTangent
Parametric Rectified Linear Unit
Sigmoid (default)
Thresholded Rectified Linear Unit
activation
0 -> 1
activation
0 -> 1
0 -> 1
?
0.2
8
Or NOT
0.3
Sigmoid
0.4
0.8
Sigmoid
H
Or NOT
0.3
0.4
0.8
0.2
8
Sigmoid
Sigmoid
H = sigmoid( (8x0.2) + 0.4 )
H
Or NOT
0.3
0.4
0.8
0.2
8
Sigmoid
Sigmoid
H = sigmoid( (8x0.2) + 0.4 )
H = 0.88079707797788
H
Or NOT
0.3
0.4
0.8
H = sigmoid( (8x0.2) + 0.4 )
H = 0.88079707797788
0.2
8
Sigmoid
Sigmoid
O = sigmoid( (Hx0.3) + 0.8 )
O = 0.74349981350761
H
0.3
0.4
0.8
H = sigmoid( (8x0.2) + 0.4 )
H = 0.88079707797788
0.2
8
Sigmoid
Sigmoid
O = sigmoid( (Hx0.3) + 0.8 )
O = 0.74349981350761
H
0.3
0.4
0.8
H = sigmoid( (8x0.2) + 0.4 )
H = 0.68997448112761
0.2
2
Sigmoid
Sigmoid
O = sigmoid( (Hx0.3) + 0.8 )
O = 0.73243113381927
H
0.3
0.4
0.8
0.2
2
Sigmoid
Sigmoid
TRAINING
H
0.3
0.4
0.8
0.2
2
Sigmoid
Sigmoid
TRAINING
BACK PROPAGATION
H
0.3
0.4
0.8
0.2
2
Sigmoid
Sigmoid
BACK PROPAGATION
H
0.3
0.4
0.8
0.2
2
Sigmoid
Sigmoid
BACK PROPAGATION
H
0.3
0.4
0.8
0.2
Sigmoid
Sigmoid
BACK PROPAGATION
2
H
0.3
0.4
0.8
0.2
Sigmoid
Sigmoid
BACK PROPAGATION
2
ERROR = EXPECTATION - OUTPUT
H
0.3
0.4
0.8
0.2
Sigmoid
Sigmoid
BACK PROPAGATION
2
LINEAR GRADIENT DESCENT
ERROR = EXPECTATION - OUTPUT
H
0.3
0.4
0.8
0.2
Sigmoid
Sigmoid
BACK PROPAGATION
2
LINEAR GRADIENT DESCENT
ERROR = EXPECTATION - OUTPUT
H
0.3
0.4
0.8
0.2
Sigmoid
Sigmoid
BACK PROPAGATION
2
LINEAR GRADIENT DESCENT
ERROR = EXPECTATION - OUTPUT
BACK PROPAGATION
BACK PROPAGATION
BACK PROPAGATION
BACK PROPAGATION
BACK PROPAGATION
BACK PROPAGATION
BACK PROPAGATION
BACK PROPAGATION
derivative
learning
rate
H
0.3
0.4
0.8
0.2
DSigmoid
DSigmoid
BACK PROPAGATION
2
LINEAR GRADIENT DESCENT
ERROR = EXPECTATION - OUTPUT
H
0.3
0.4
0.8
0.2
DSigmoid
DSigmoid
BACK PROPAGATION
2
GRADIENT = Derivative of Sigmoid (OUTPUT)
LINEAR GRADIENT DESCENT
ERROR = EXPECTATION - OUTPUT
H
0.3
0.4
0.8
0.2
DSigmoid
DSigmoid
BACK PROPAGATION
2
multiply by the ERROR
ERROR = EXPECTATION - OUTPUT
LINEAR GRADIENT DESCENT
GRADIENT = Derivative of Sigmoid (OUTPUT)
ERROR = EXPECTATION - OUTPUT
H
0.3
0.4
0.8
0.2
DSigmoid
DSigmoid
BACK PROPAGATION
2
LINEAR GRADIENT DESCENT
multiply by the ERROR
multiply by the LEARNING RATE
ERROR = EXPECTATION - OUTPUT
GRADIENT = Derivative of Sigmoid (OUTPUT)
ERROR = EXPECTATION - OUTPUT
H
0.3
0.4
0.8
0.2
DSigmoid
DSigmoid
BACK PROPAGATION
2
GRADIENT = DSigmoid (OUTPUT) * ERROR * LR
ERROR = EXPECTATION - OUTPUT
LINEAR GRADIENT DESCENT
H
0.3
0.4
0.8
0.2
DSigmoid
DSigmoid
BACK PROPAGATION
2
GRADIENT = DSigmoid (OUTPUT) * ERROR * LR
ERROR = EXPECTATION - OUTPUT
LINEAR GRADIENT DESCENT
ΔWeights = GRADIENT * H
H
0.3
0.4
0.8
0.2
DSigmoid
DSigmoid
BACK PROPAGATION
2
GRADIENT = DSigmoid (OUTPUT) * ERROR * LR
ERROR = EXPECTATION - OUTPUT
LINEAR GRADIENT DESCENT
ΔWeights = GRADIENT * H
Weights = Weights + ΔWeights
H
0.3
0.4
0.8
0.2
DSigmoid
DSigmoid
BACK PROPAGATION
2
GRADIENT = DSigmoid (OUTPUT) * ERROR * LR
ERROR = EXPECTATION - OUTPUT
LINEAR GRADIENT DESCENT
ΔWeights = GRADIENT * H
Weights = Weights + ΔWeights
Bias = Bias + GRADIENT
H
0.4
0.8
0.2
DSigmoid
BACK PROPAGATION
2
Sigmoid
0.3
DSigmoid
Sigmoid
H
-26.6143
-3.75104
4.80418
DSigmoid
BACK PROPAGATION
2
Sigmoid
7.62213
DSigmoid
Sigmoid
H
-26.6143
-3.75104
4.80418
DSigmoid
BACK PROPAGATION
2
Sigmoid
7.62213
DSigmoid
Sigmoid
0.02295
H
-26.6143
-3.75104
4.80418
DSigmoid
BACK PROPAGATION
2
Sigmoid
7.62213
DSigmoid
Sigmoid
0.02295
H
-26.6143
-3.75104
4.80418
DSigmoid
BACK PROPAGATION
8
Sigmoid
7.62213
DSigmoid
Sigmoid
0.97988
CONGRATULATIONS !
CONGRATULATIONS !
Let's play together :)
Hungry
?
EAT
Hungry
EAT
MULTI LAYER
PERCEPTRON
Hungry
EAT
Hungry
EAT
Sleepy
Excited
RUN
SLEEP
Hungry
EAT
Sleepy
Excited
RUN
SLEEP
Hungry
EAT
Sleepy
Excited
RUN
SLEEP
?
NEAT
NEAT
Hungry
EAT
Sleepy
Excited
RUN
SLEEP
?
Neuro Evolution of Augmented Topologie
NEAT
Hungry
EAT
Sleepy
Excited
RUN
SLEEP
?
Neuro Evolution of Augmented Topologie
By Grégoire Hébert
UnConference




