Apache Spark
Gleb Kanterov
@kanterov
gleb@kanterov.ru
simple things should be simple, complex things should be possible"
Alan Kay
class RDD[A] {
def map[B](f: A => B): RDD[B]
def filter(f: A => Boolean): RDD[A]
def union(other: RDD[A]): RDD[A]
def groupBy[B](f: A => B): RDD[(B, Seq[A])]
def collect(): Array[A]
}class DataFrame {
def select(cols: Column*): DataFrame
def filter(condition: Column): DataFrame
def col(name: String): Column
def collect(): Array[Row]
}
def min(col: Column): Column
def avg(col: Column): Columnclass Dataset[A: Encoder] {
def select[U1: Encoder, U2: Encoder](
c1: TypedColumn[A, U1],
c2: TypedColumn[A, U1]
): Dataset[(U1, U2)]
def map[U: Encoder](
func: A => U
): Dataset[U]
def filter(f: A => Boolean): Dataset[A]
}Frameless
1
Provide more typeful experience
working with Apache Spark
- Statically derived Encoders
- Columns are safely referenced
- Mirrors value-level computation to type-level for dataset methods
github.com/adelbertc/frameless
Structured Streaming
val logs = ctx
.read.format("json")
//.open("s3://logs")
.stream("s3://logs")
logs
.groupBy(logs("user_id"))
.agg(sum(logs("time")))
.write.format("jdbc")
//.save("jdbc:mysql://...")
.stream("jdbc:mysql://...")Analytics
-
data-driven
-
adhoc research
-
models
-
classifiers
-
predictors
-
-
number crunching
-
KPI
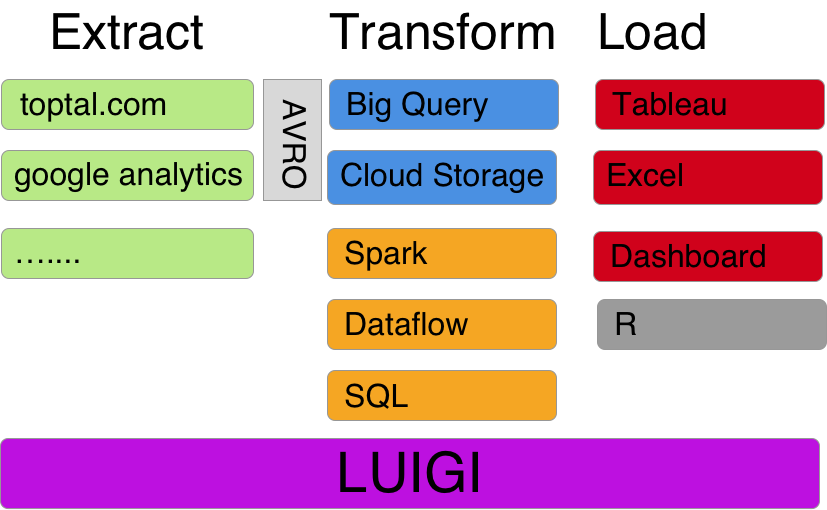
- Google Cloud
- Storage
- Big Query
- Compute Engine
- Luigi
- Avro
- Spark, Dataflow, BigQuery
- R, dplyr, ggplot2
- Tableua, Excel, shiny, dashboard
Apache Spark
By Gleb Kanterov



