Deep Multi-task Representation Learning on Tabular Data
Presents: Jacobo G. González León
7th PDTA
Thesis advisors:
- PhD. Miguel Félix Mata Rivera
- PhD. Rolando Menchaca Méndez



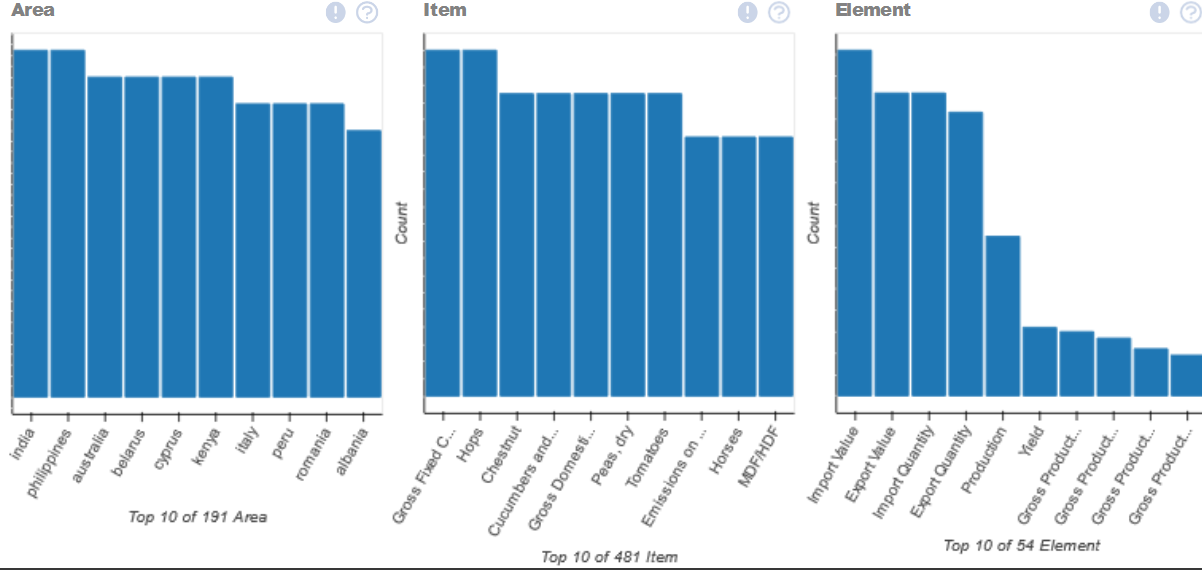
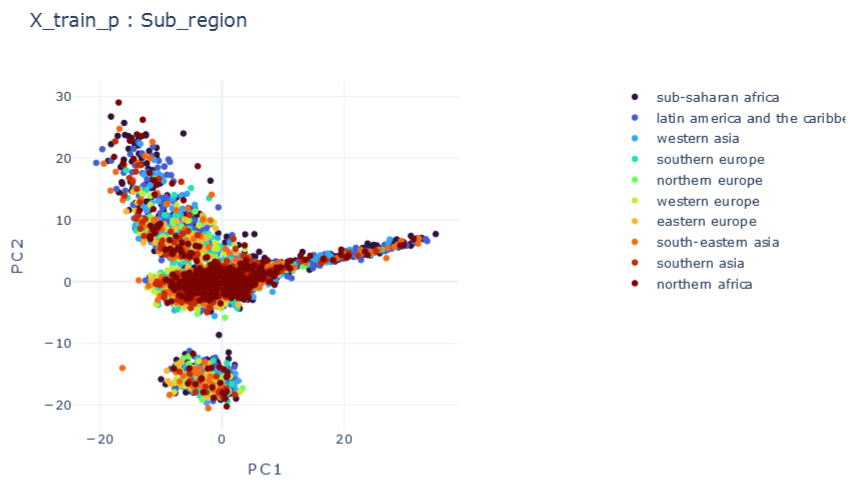
(Mixed) Tabular Data
\(X\) : features
\(y^T\) : target
4 categorical, 30 numerical
2 categorical
Correlation
Preprocessed Data (VSM)
\(X\) : features
296 numerical (from categorical), 30 numerical
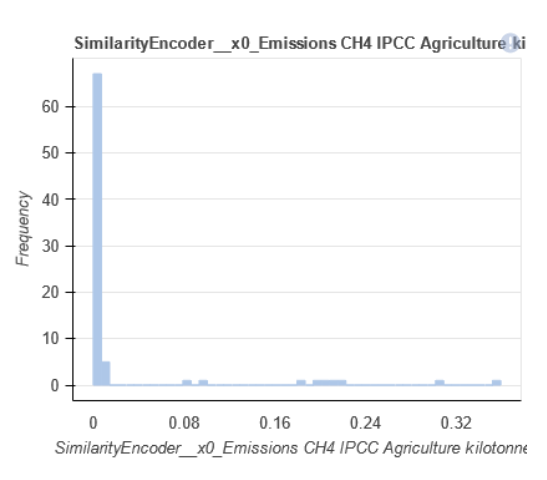
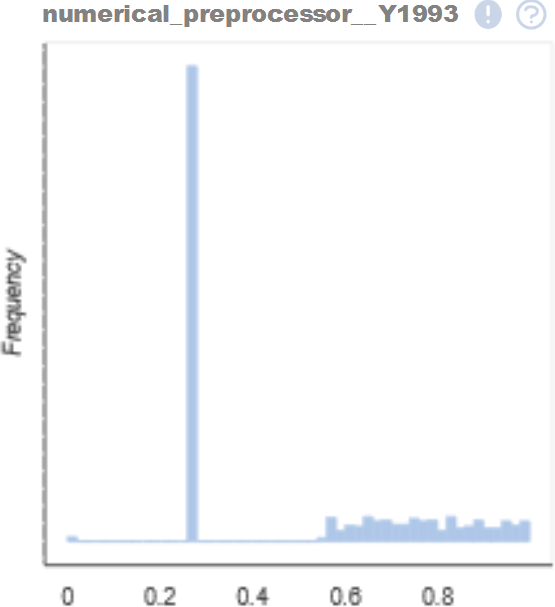
Long-tail distribution
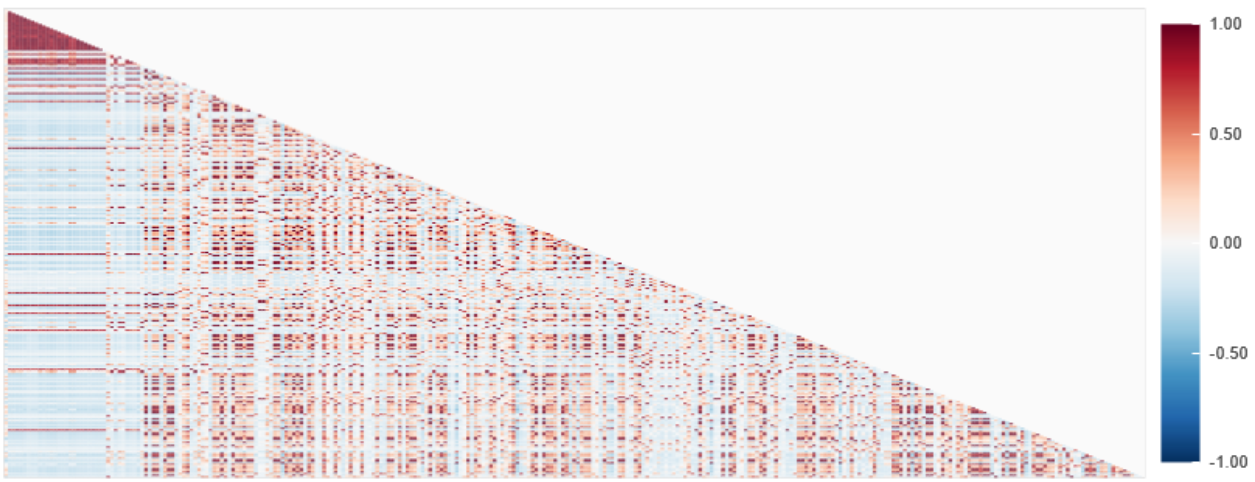
Correlation
Preprocessed Data (VSM)
\(y\) : targets
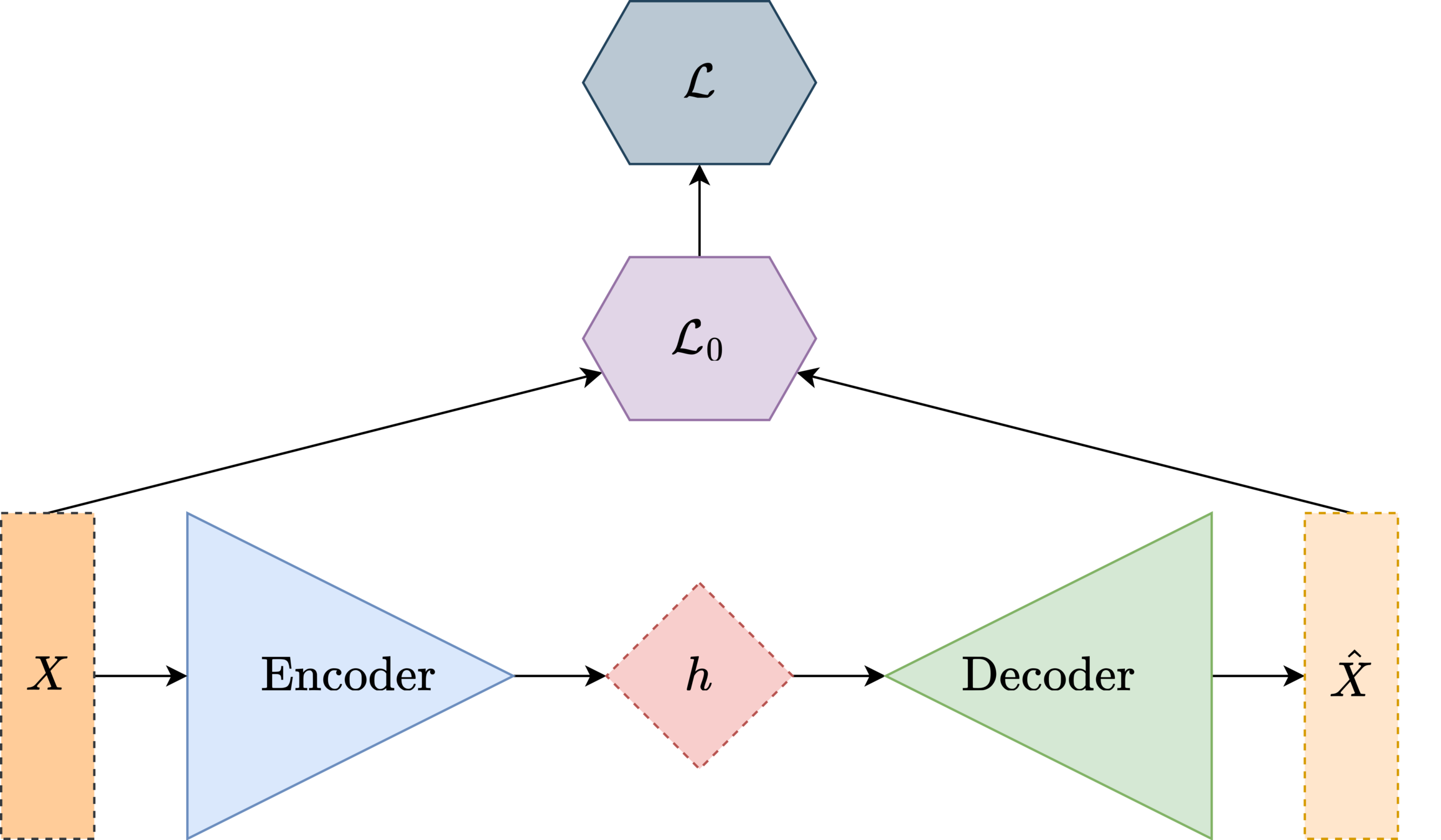
Isolated Learning
Autoencoder
\(f(X)\)
\(g(h)\)
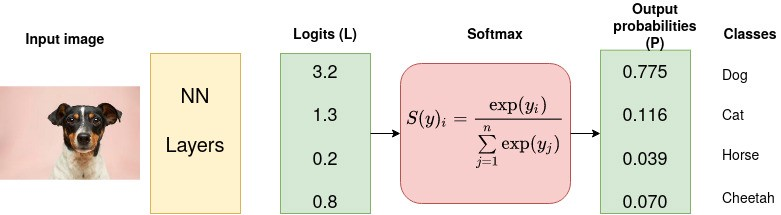
\( f(\hat{y}_i) = \frac{e^{\hat{y}_i}}{\sum_{i}^C {e^{\hat{y}_i}}} \)
\( \mathcal{L}= {\sum_{i}^C {e^{\hat{y}_i}}}{\log{f(\hat{y}_i)}} \)
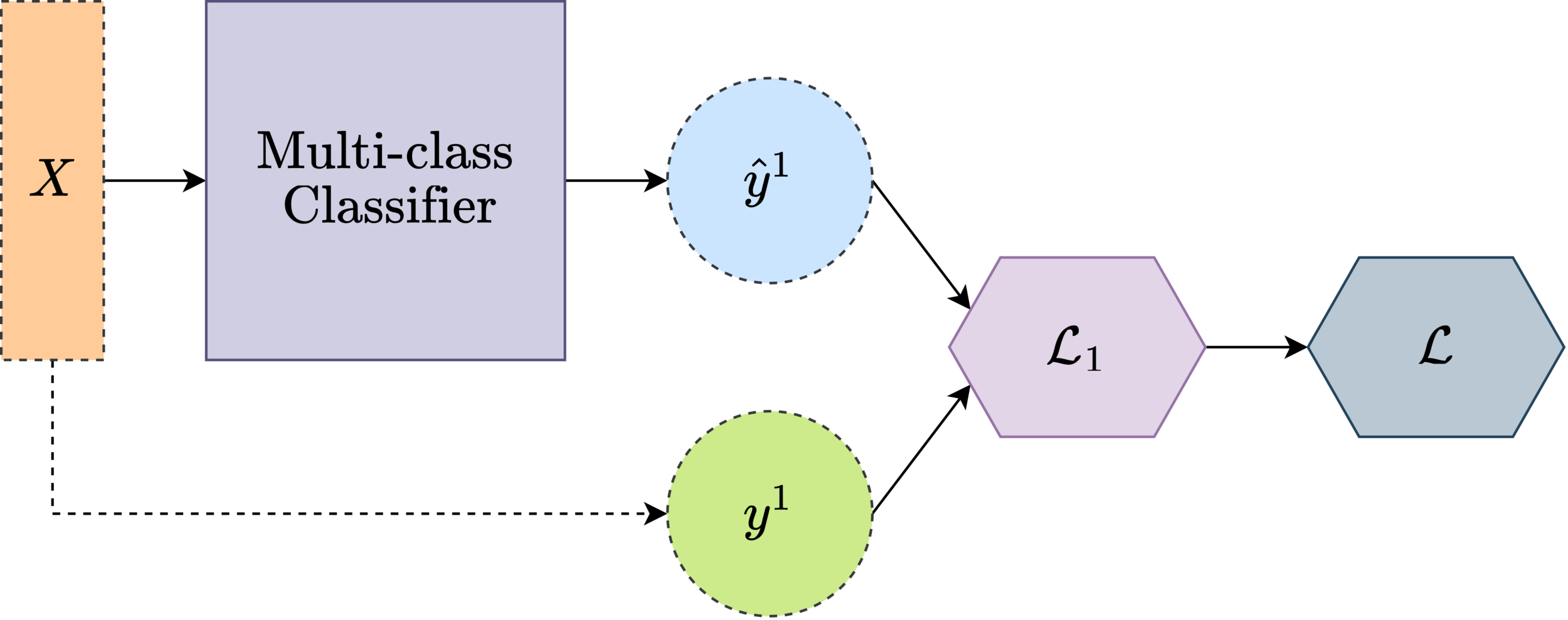
Multi-class Classifier
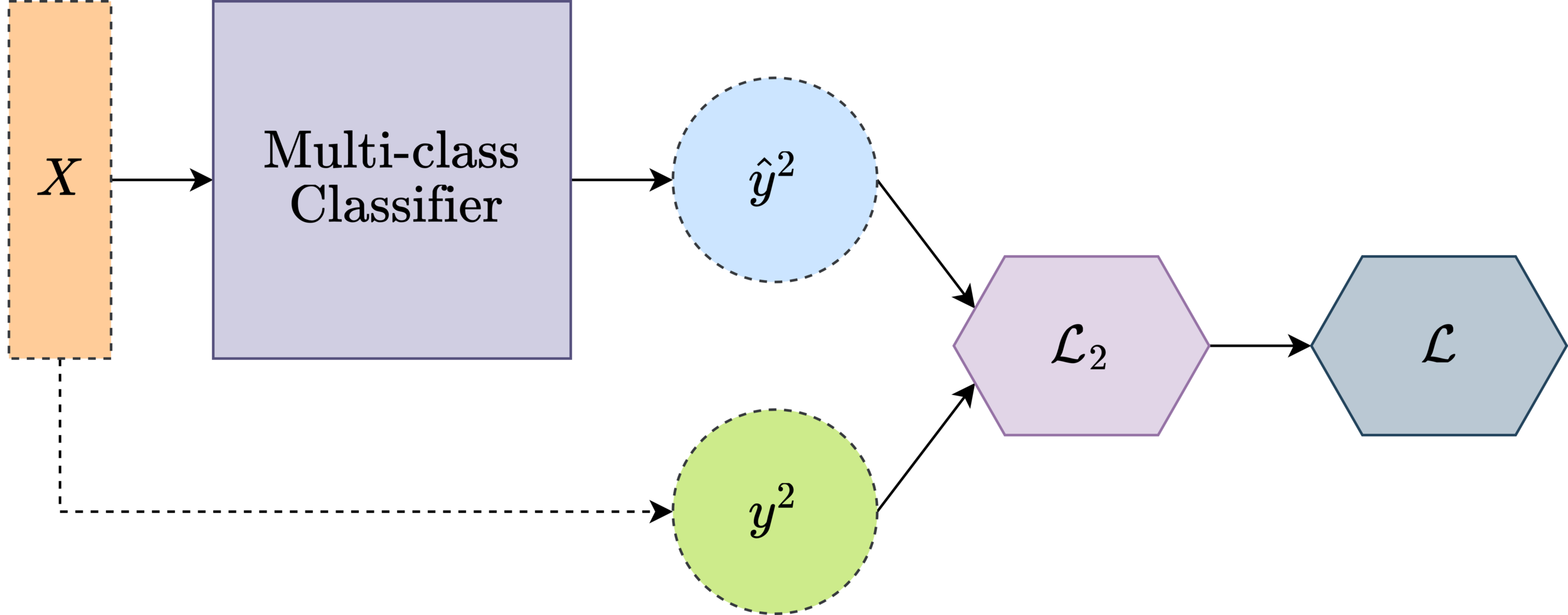
Loss function
Loss function
softmax
cross entropy loss
\( \mathcal{L}= \text{\textbardbl}{X-\hat{X}}\text{\textbardbl} \)
reconstruction error
TASK 0
TASK 1
TASK 2
1)
2)
Research question
Can we design a centralized architecture that learns from multi-task simultaneously ?
Design a low-dimensional multitasking representation for mixed preprocessed data
Problem definition
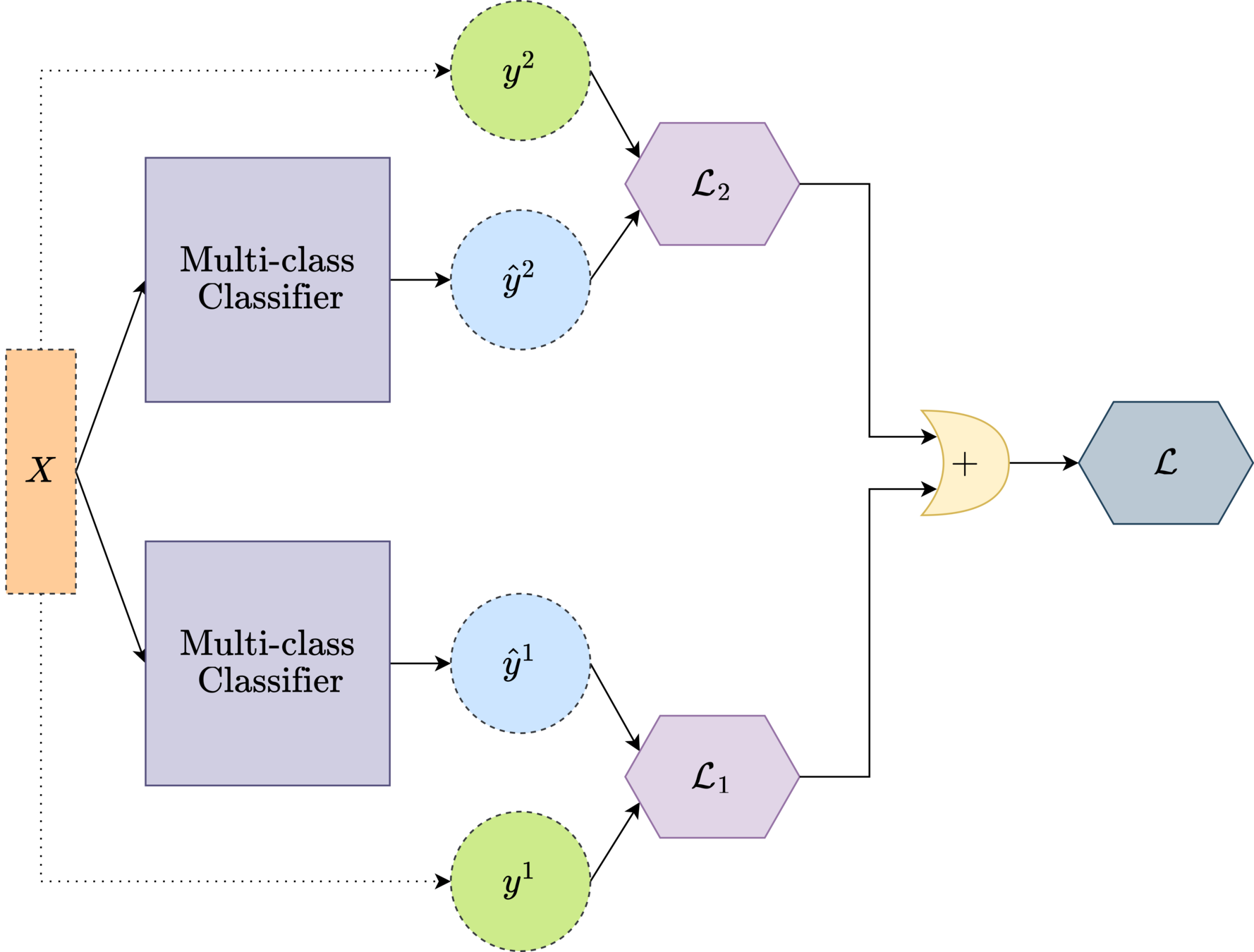
Loss function
weighted cross entropy loss
Multi-task Learning
TASK 1
TASK 2
\( \mathcal{L}= {\psi_1} {\sum_{i}^C {e^{\hat{y}_i^1}}}{\log{f(\hat{{y}_i^1})}} + {\psi_2} {\sum_{i}^C {e^{\hat{y}_i^2}}}{\log{f(\hat{{y}_i^2})}} \)
TASK 1 + TASK 2
\({\psi_1}\)
\({\psi_2}\)
Deep Multi-task Learning
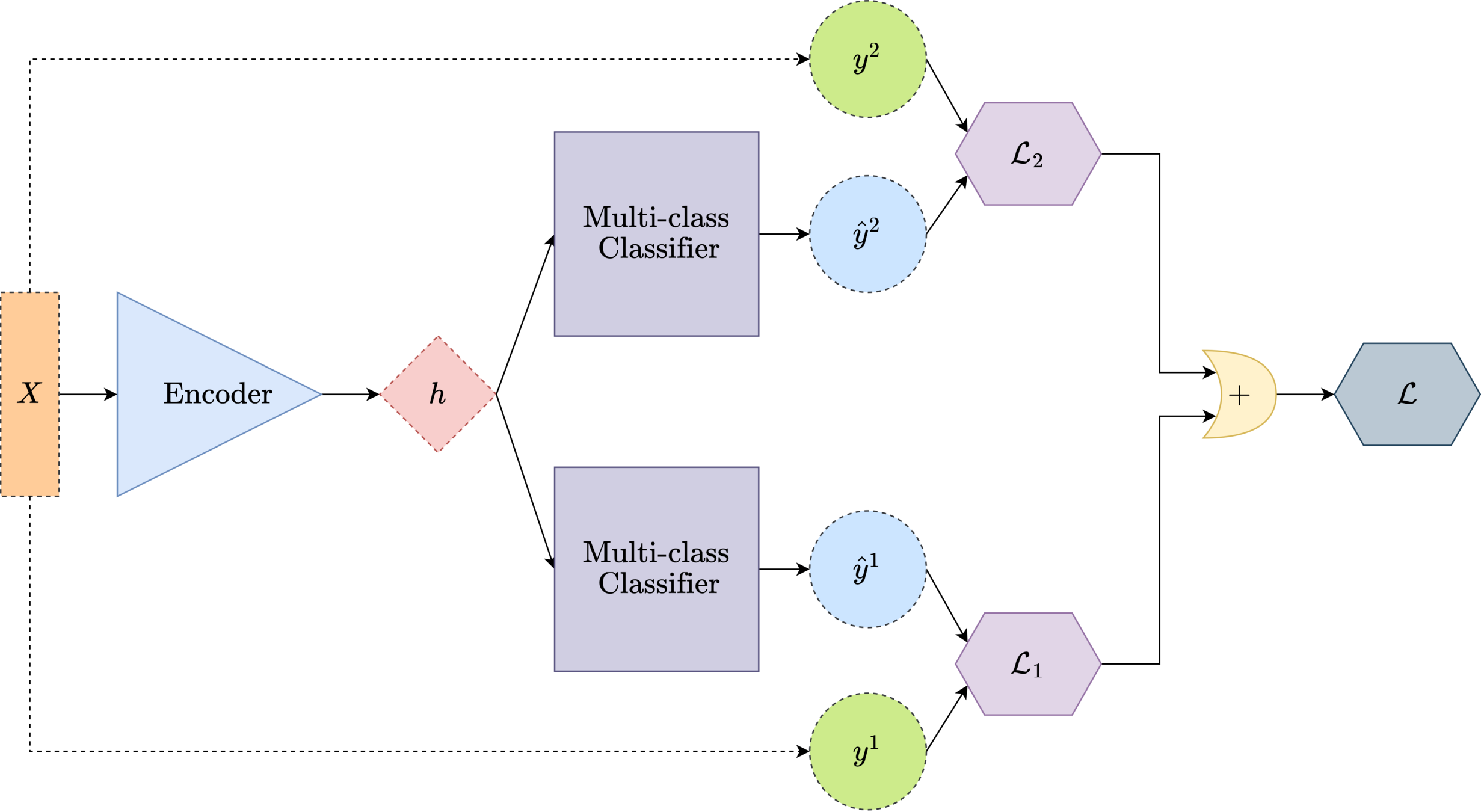
ENCODER + TASK 1 + TASK 2
Loss function
weighted cross entropy loss
\( \mathcal{L}= {\psi_1} {\sum_{i}^C {e^{\hat{y}_i^1}}}{\log{f(\hat{{y}_i^1})}} + {\psi_2} {\sum_{i}^C {e^{\hat{y}_i^2}}}{\log{f(\hat{{y}_i^2})}} \)
\({\psi_1}\)
\({\psi_2}\)
Deep Multi-task Representation Learning
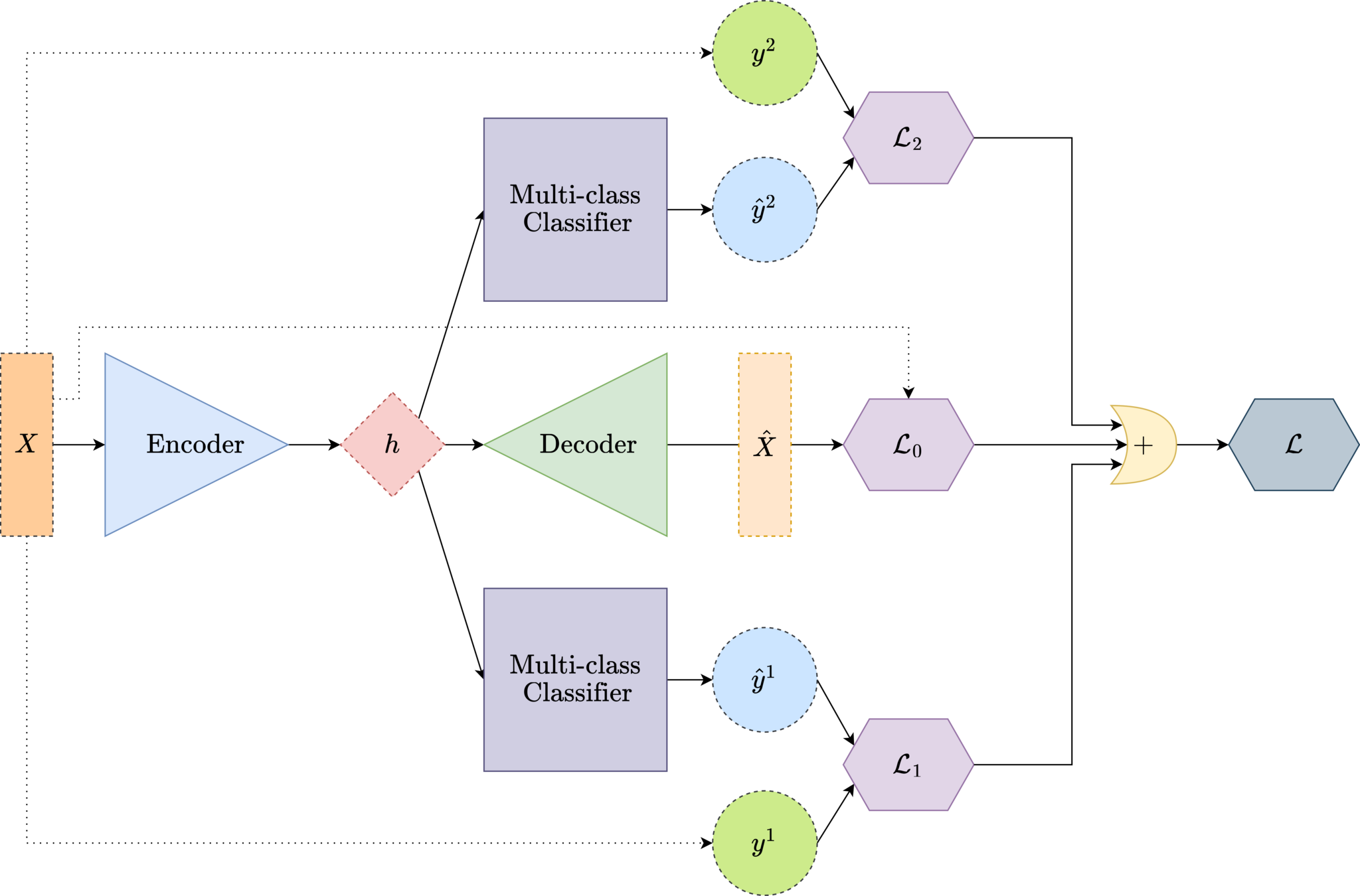
TASK 0 + TASK 1 + TASK 2
Loss function
weighted reconstruction error with weighted cross entropy loss
\( \mathcal{L}= {\psi_0} \text{\textbardbl}{X-\hat{X}}\text{\textbardbl} + {\psi_1} {\sum_{i}^C {e^{\hat{y}_i^1}}}{\log{f(\hat{{y}_i^1})}} + {\psi_2} {\sum_{i}^C {e^{\hat{y}_i^2}}}{\log{f(\hat{{y}_i^2})}} \)
\({\psi_1}\)
\({\psi_2}\)
\({\psi_0}\)
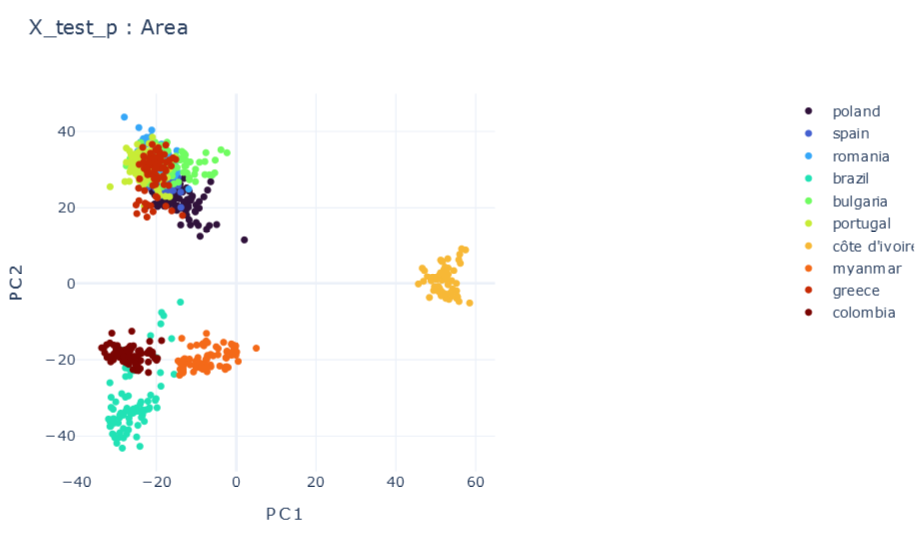
Validation (Methodology)




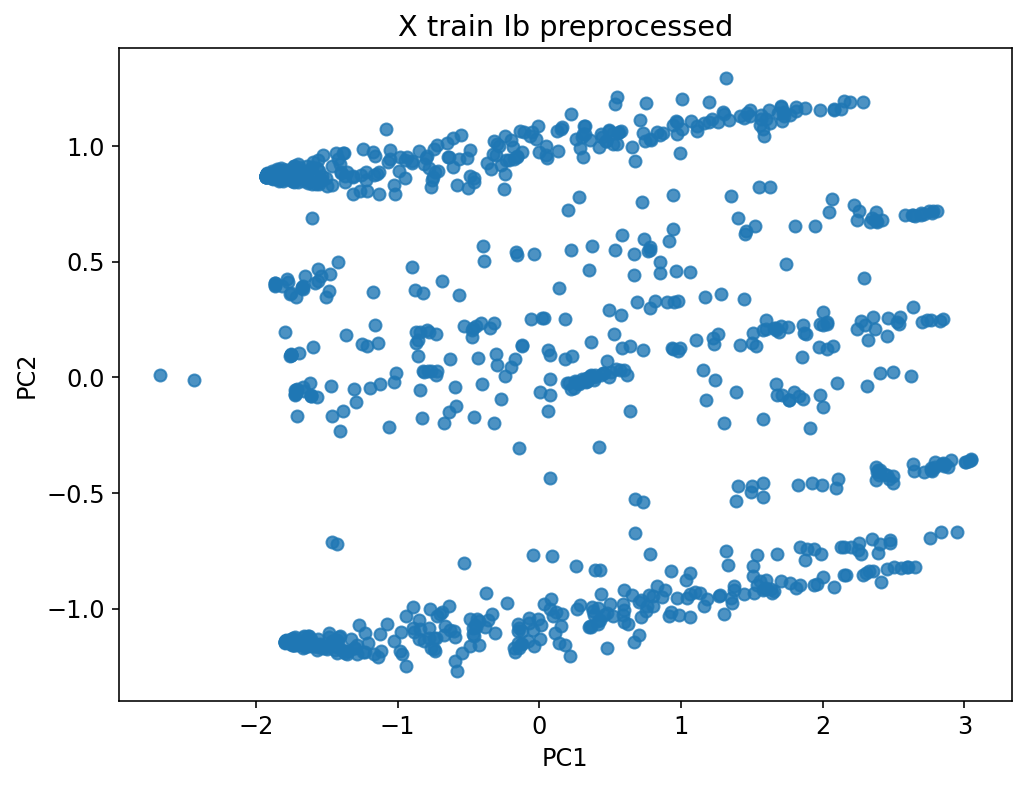
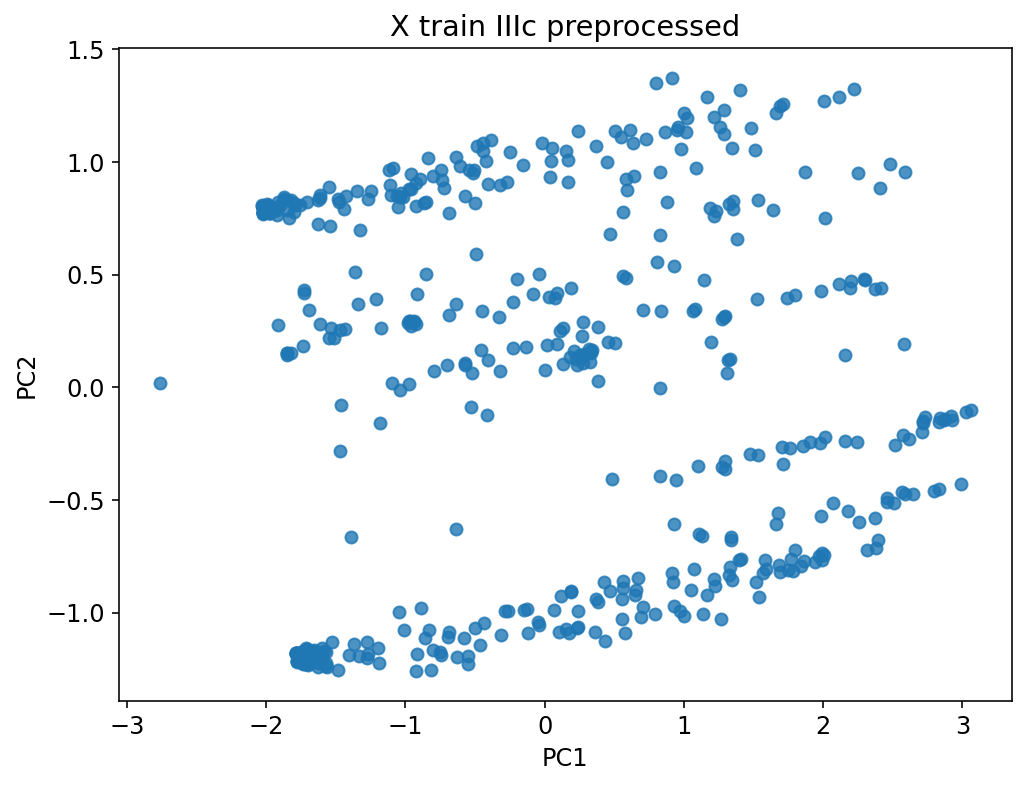
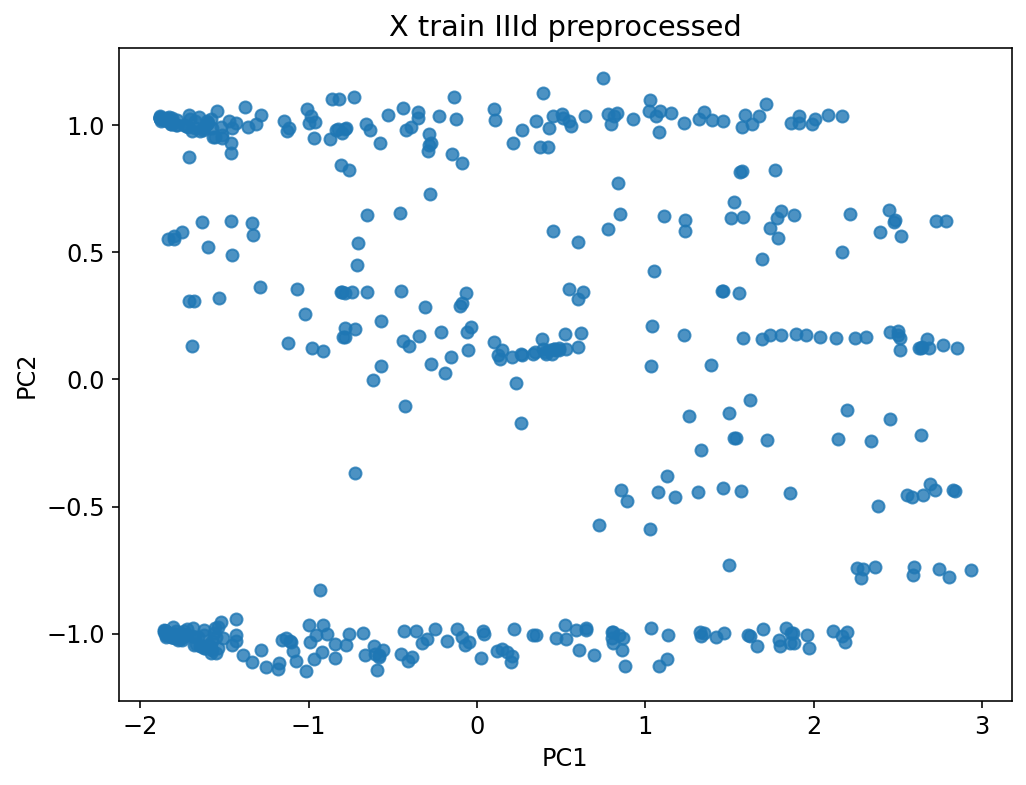
80 %
10 %
10 %
40 %
40 %
20 %
20 %
10 %
10 %
Warm-up
Trainning
Test/Val
60 %
20 %
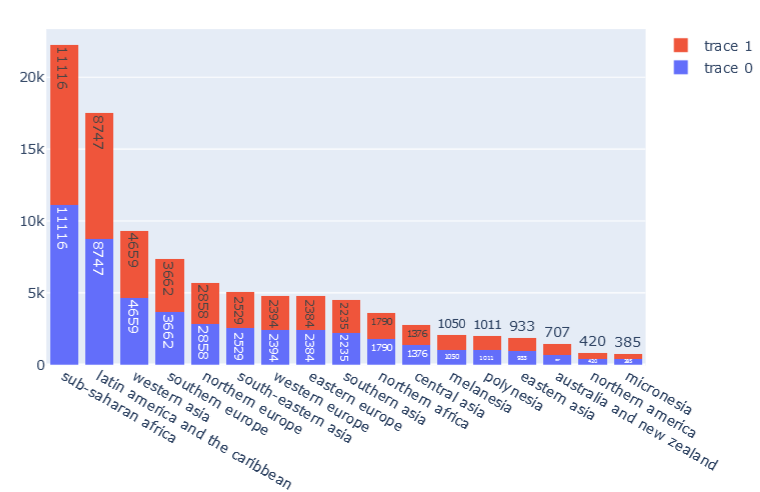
Targets
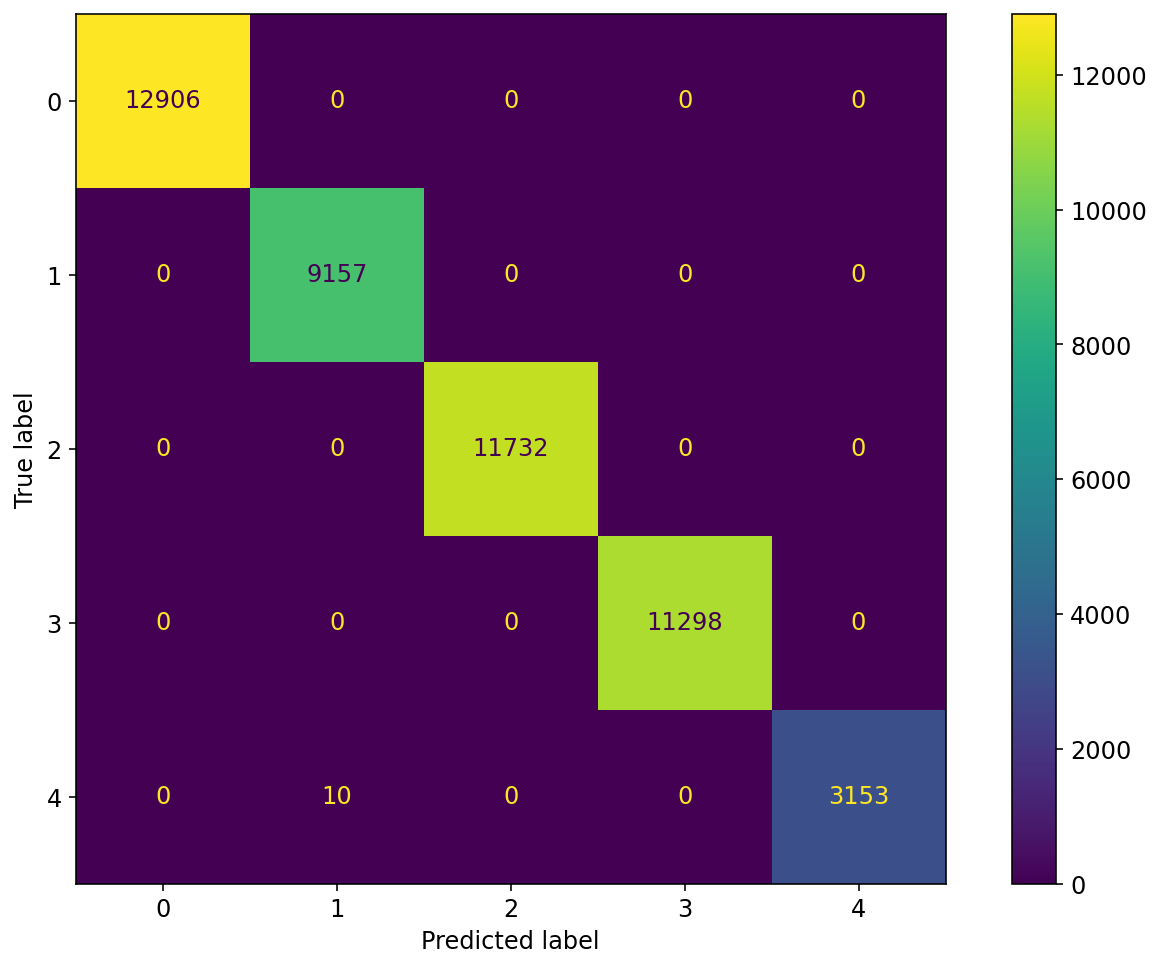
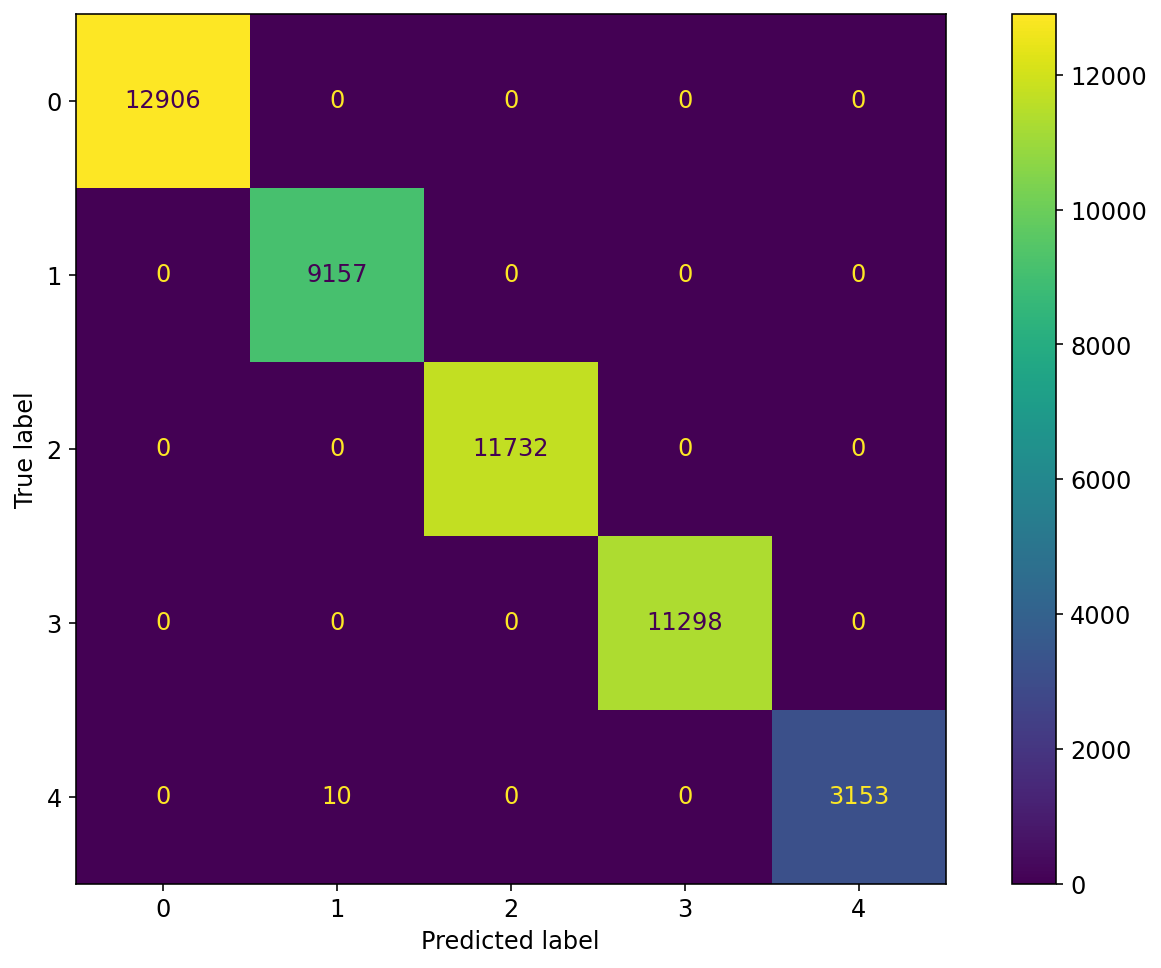
Model Validation Results
SIMILARITIES
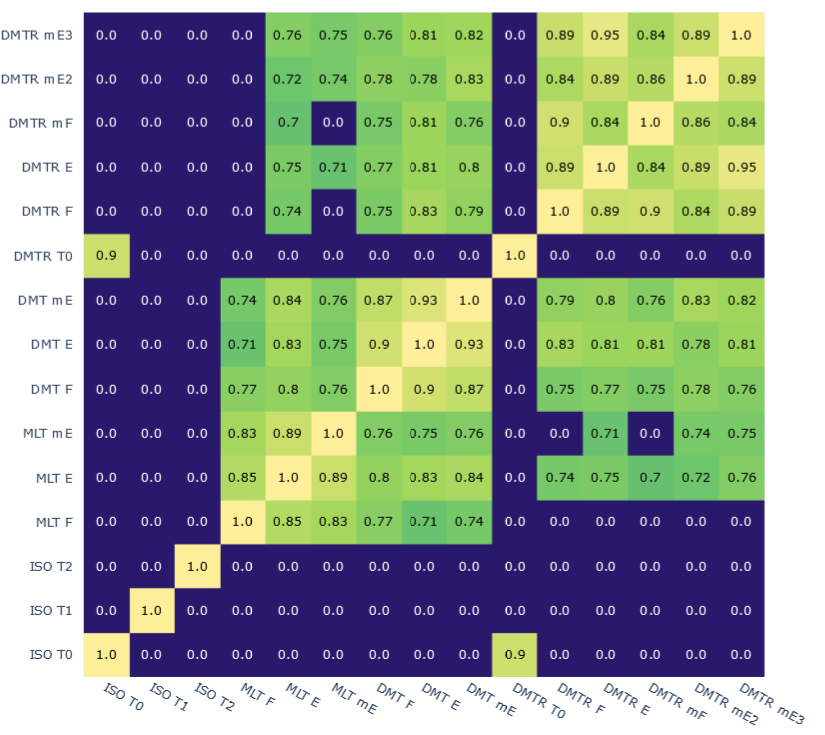
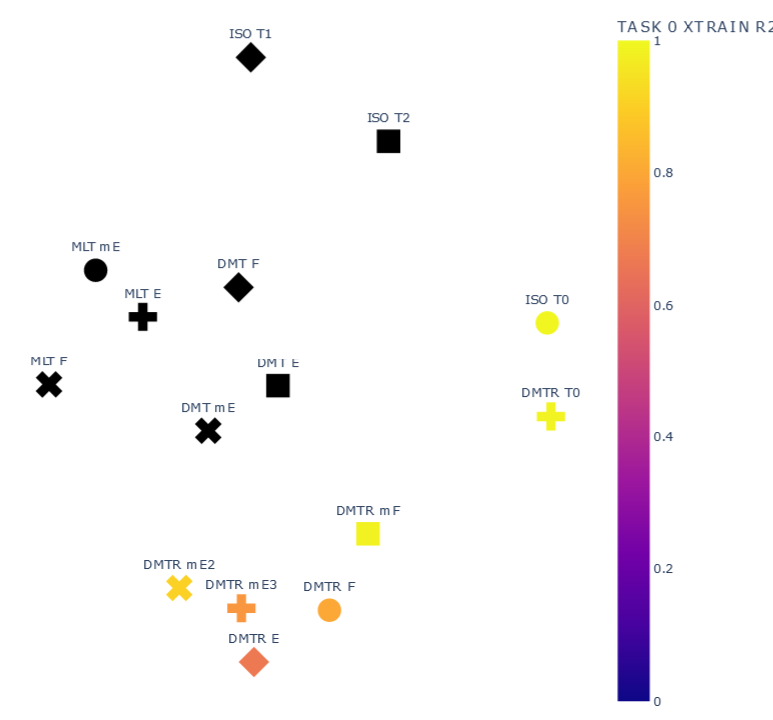
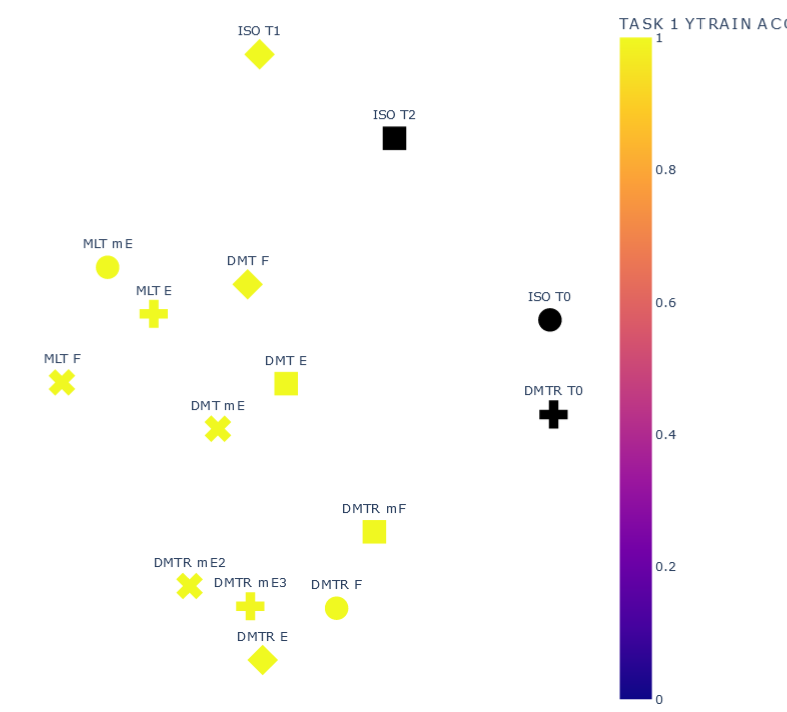
TASK 1
TASK 2
Model similarities
Train/Val/Test Results
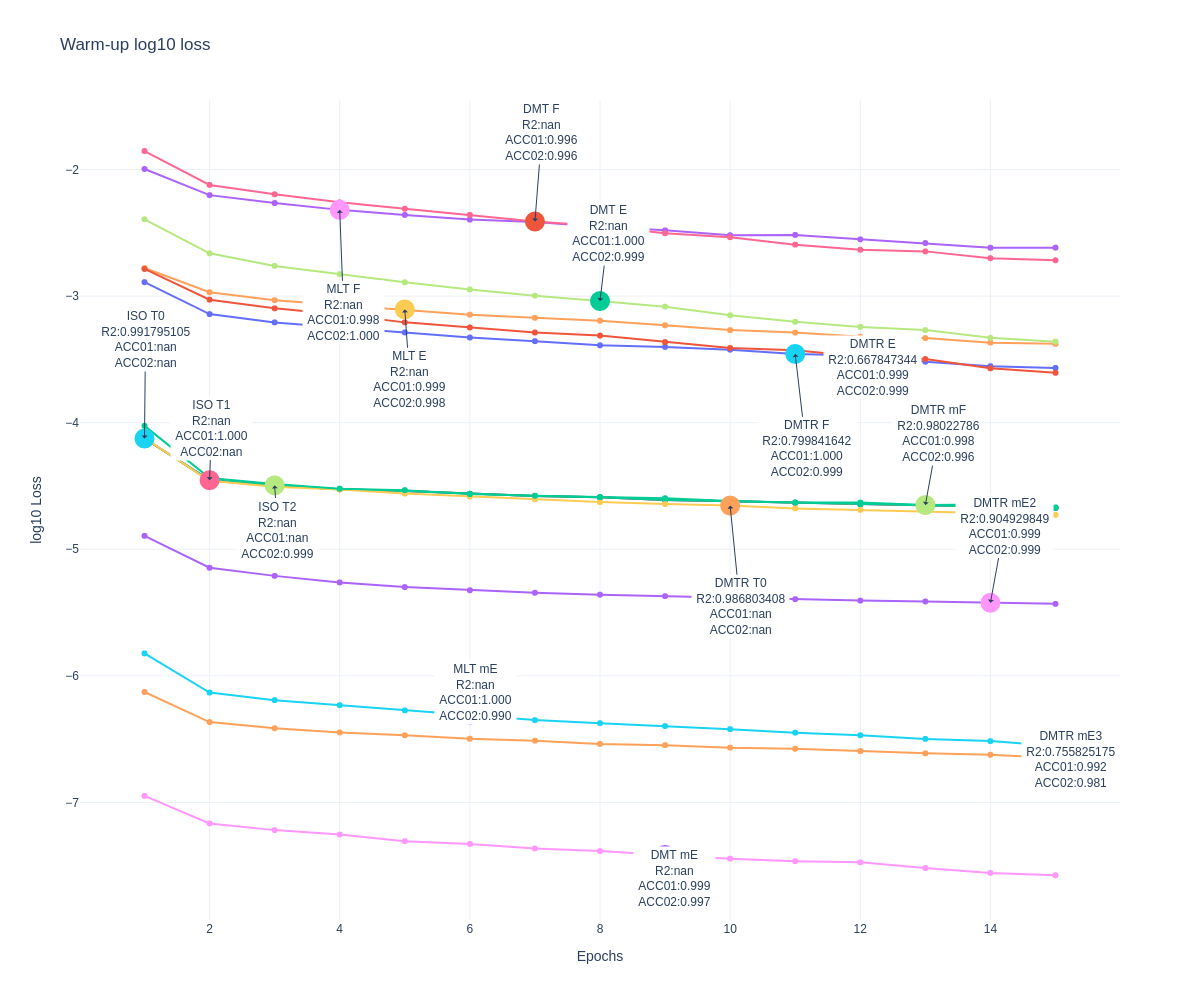
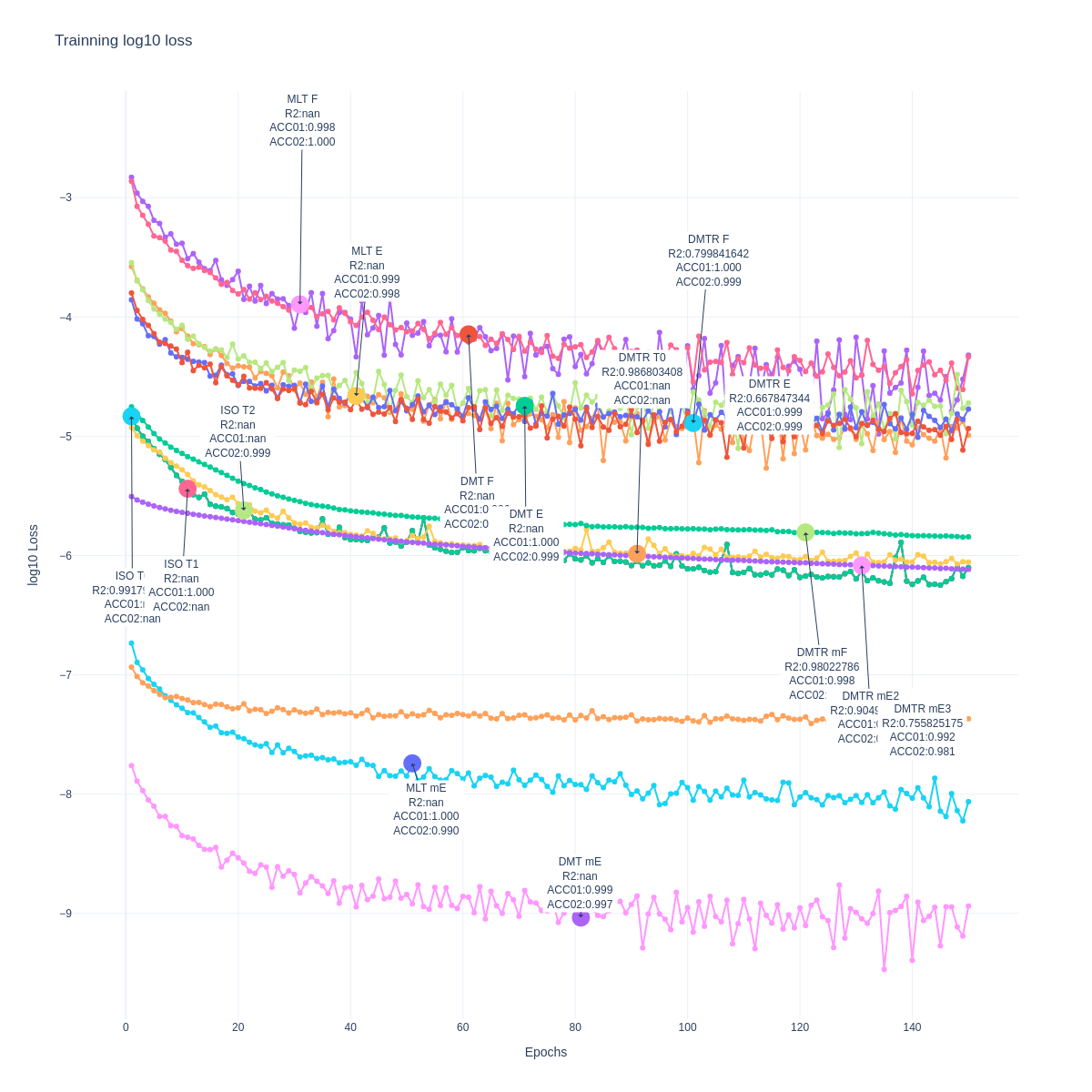
Warm-up
Trainning
Loss function
Warm-up
Trainning
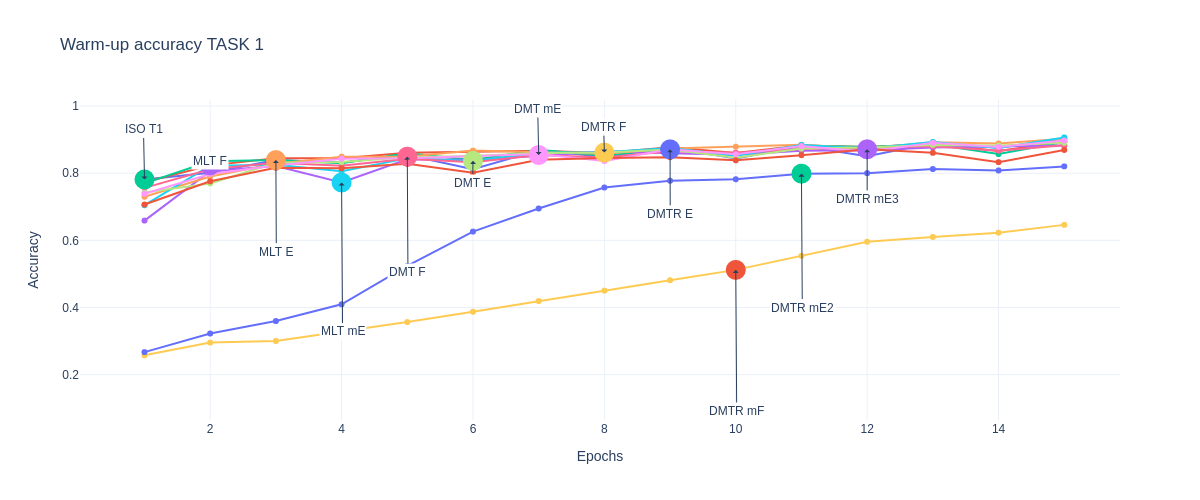
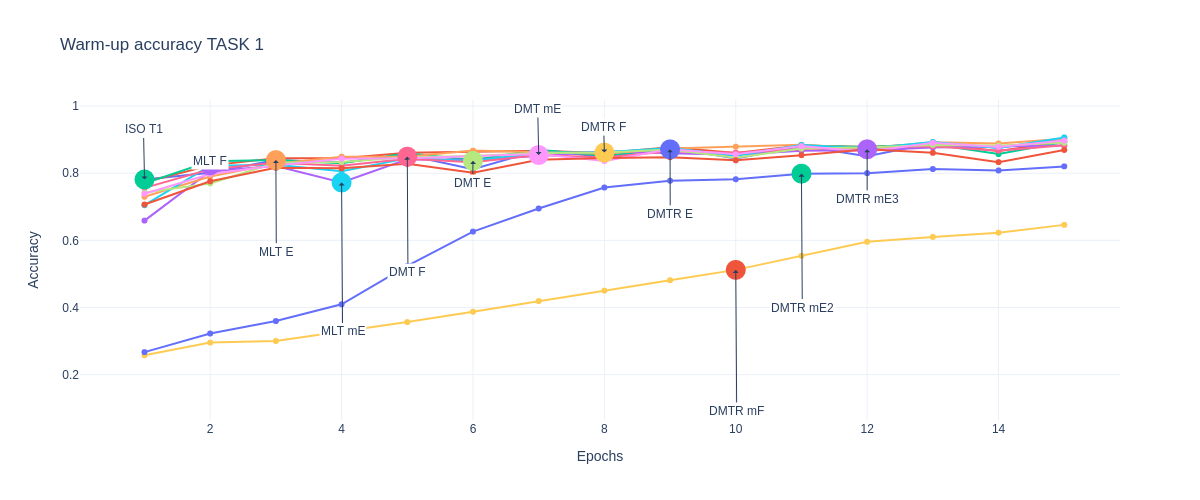
Accuracy TASK 1
Train/Val/Test Results
Warm-up
Trainning
Accuracy TASK 2
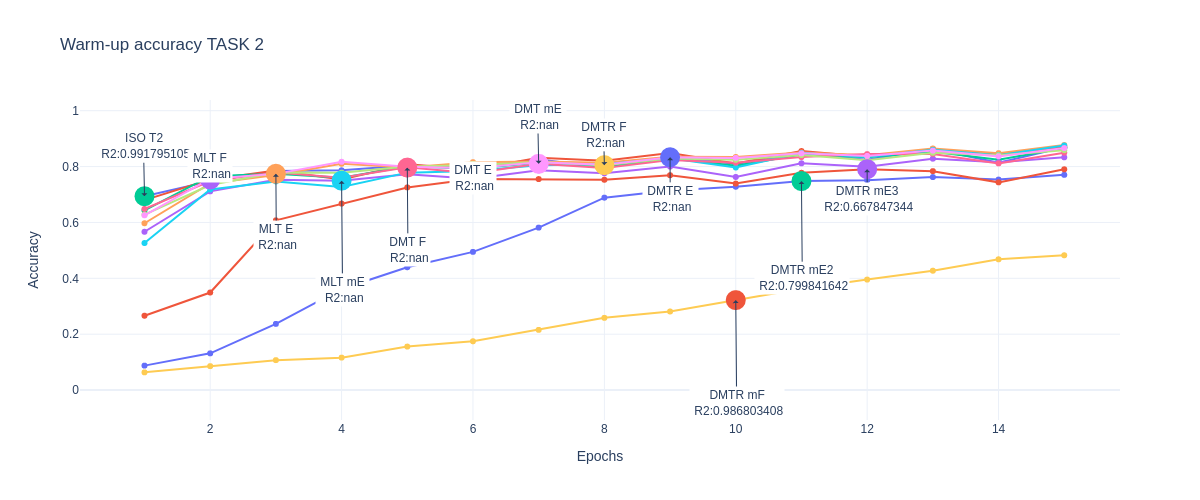
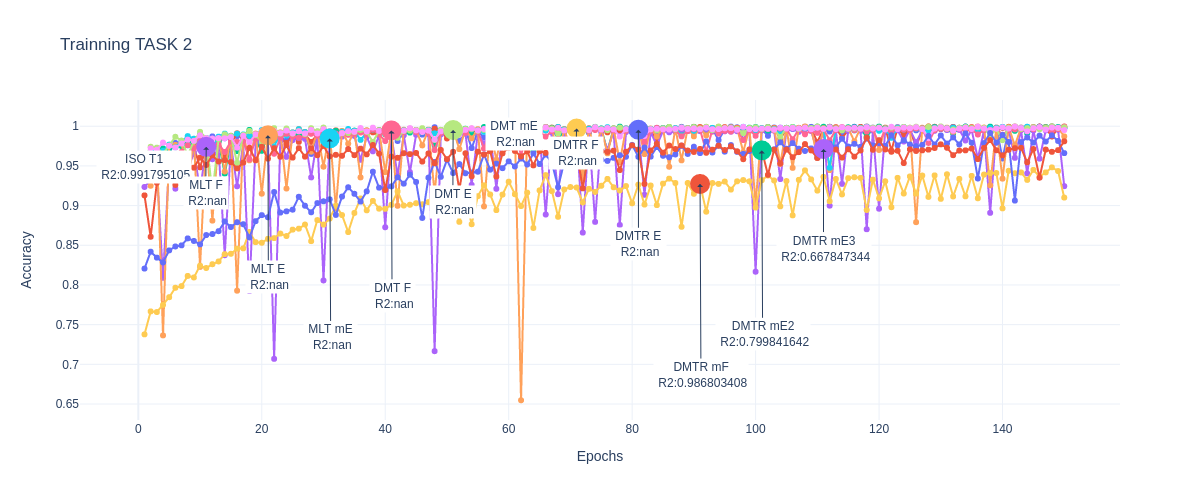
Train/Val/Test Results
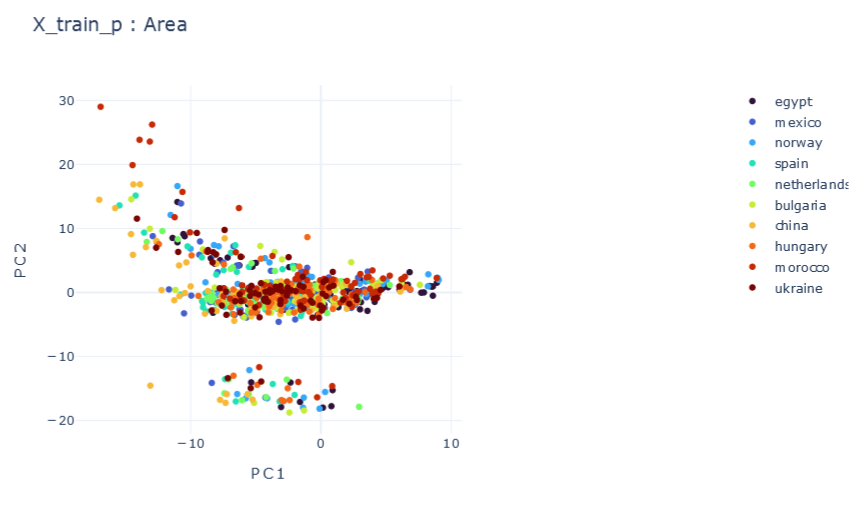
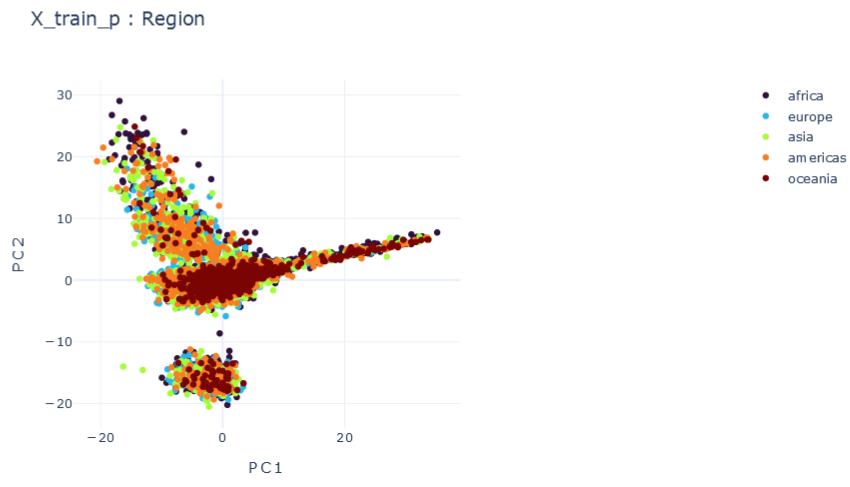
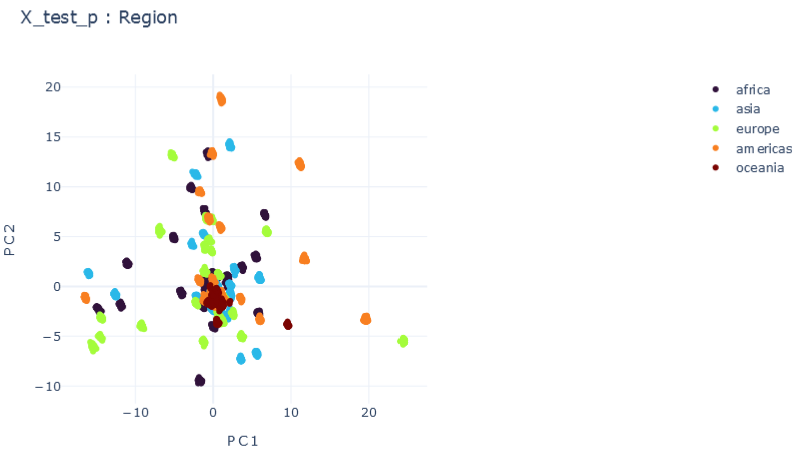
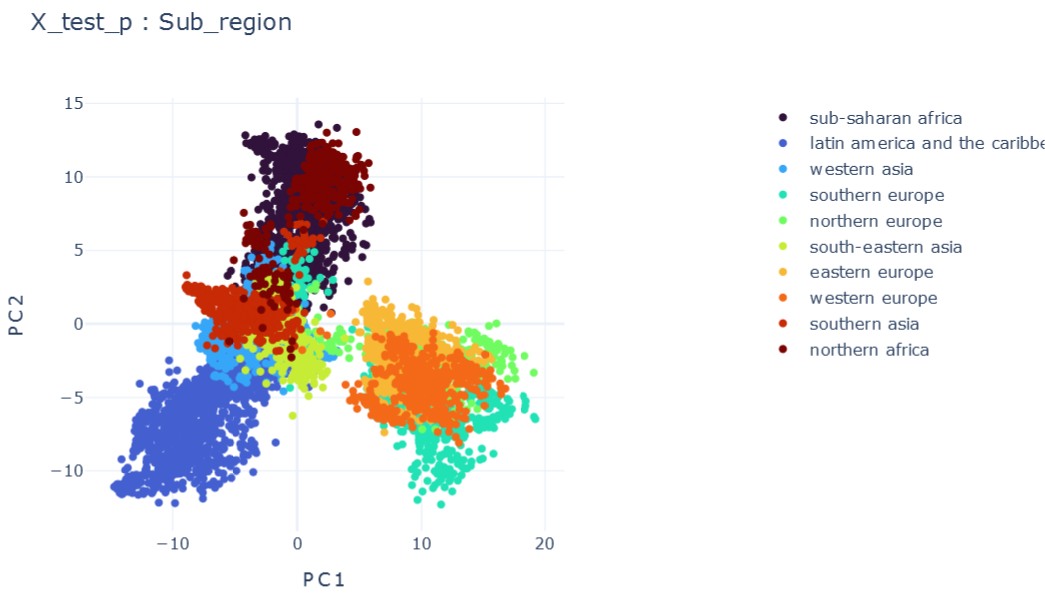
Representation Results
ISOLATED
T0 \(\psi_0=1\)
\(R2:0.99\)
T1 \(\psi_1=1\)
\(ACC:0.9997\)
T2 \(\psi_2=1\)
\(ACC:0.9998\)
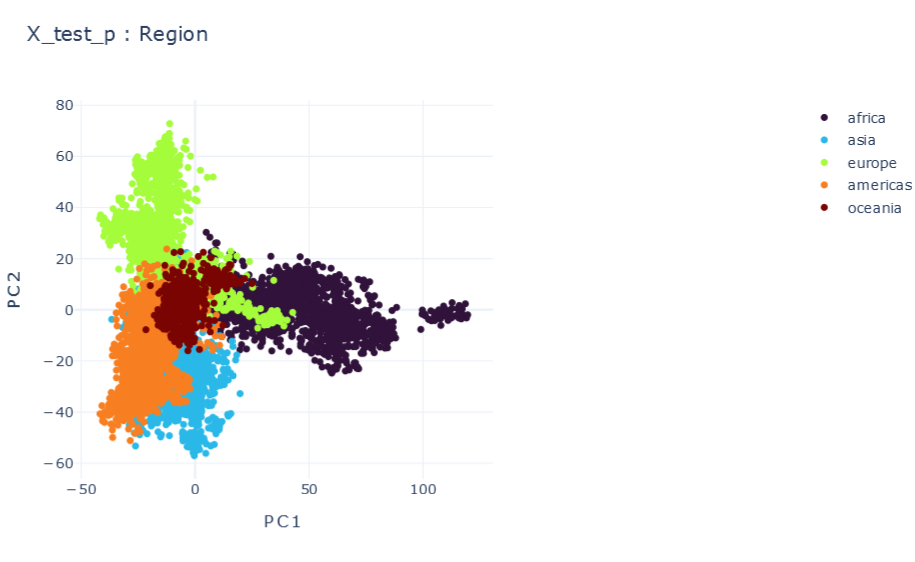
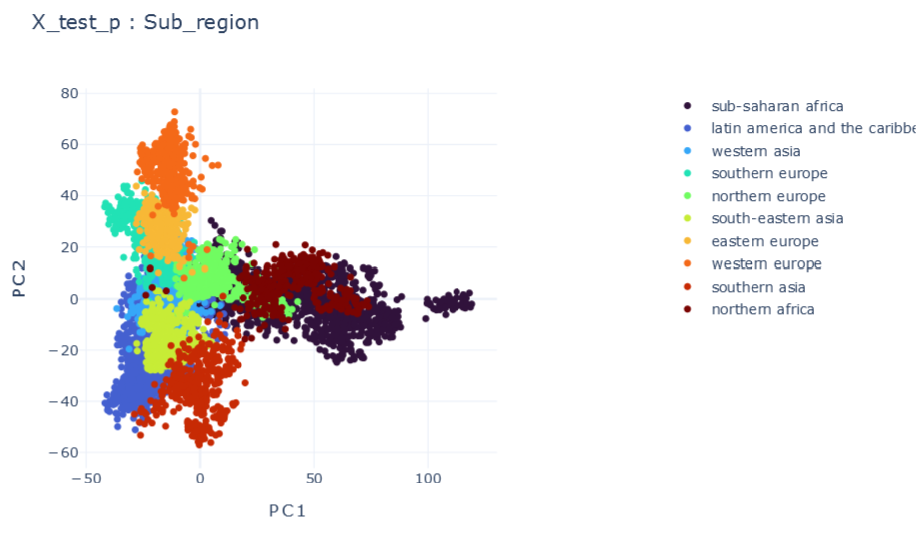
DMTL
F \(\psi_1=1 , \psi_2=1\)
E \(\psi_1=0.25, \psi_2=0.25\)
mE \(\psi_1=1E-5, \psi_2=1E-5\)
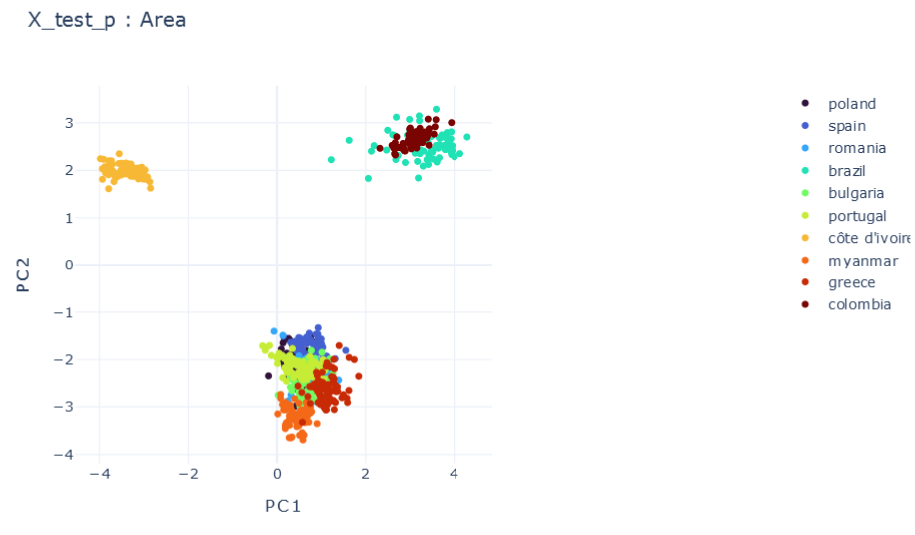
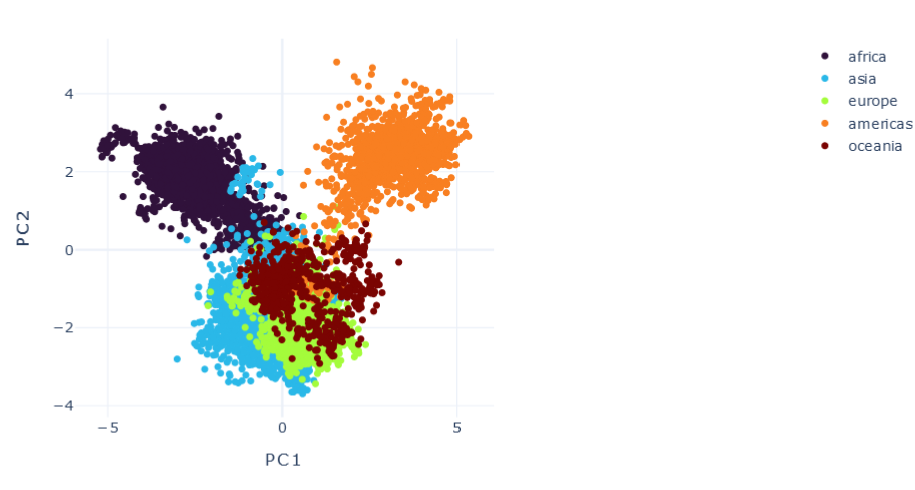
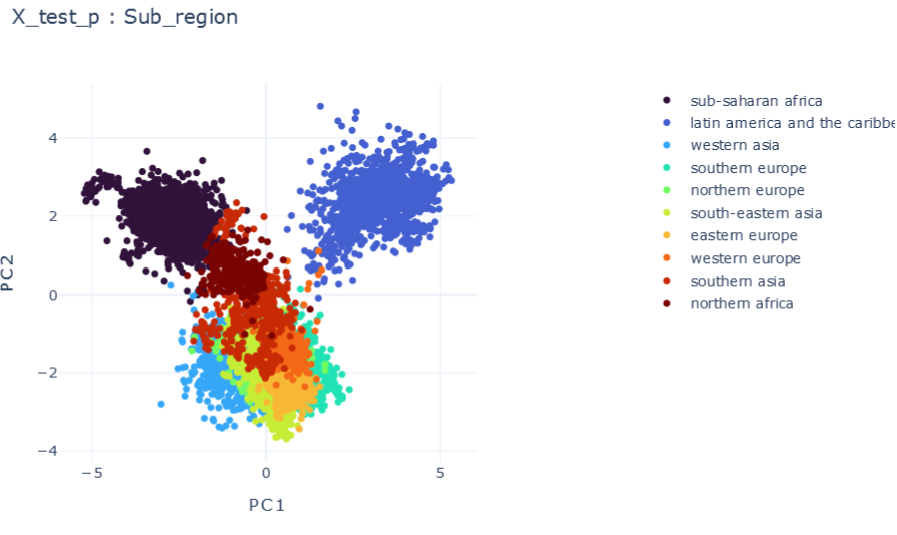
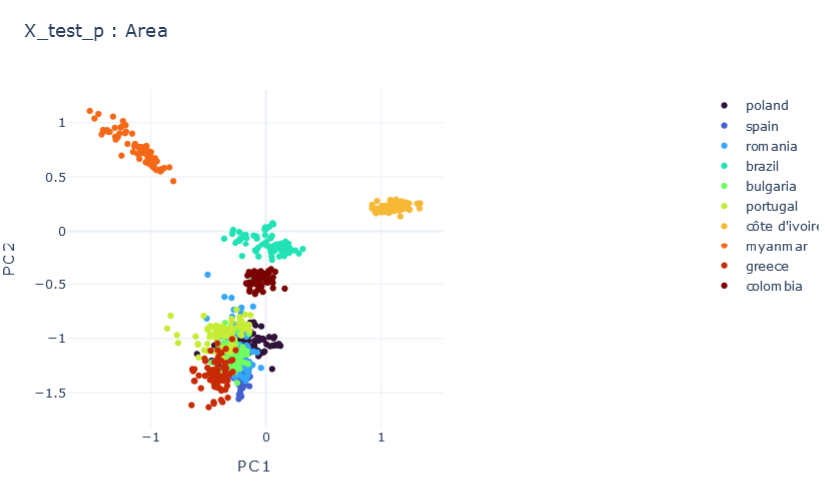
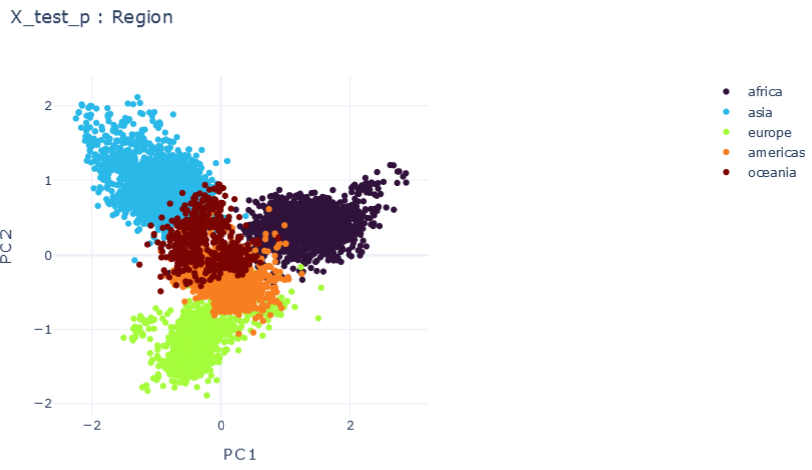

Representation Results
DMTRL
T0 \(\psi_0=1\)
\(R2:0.986\)
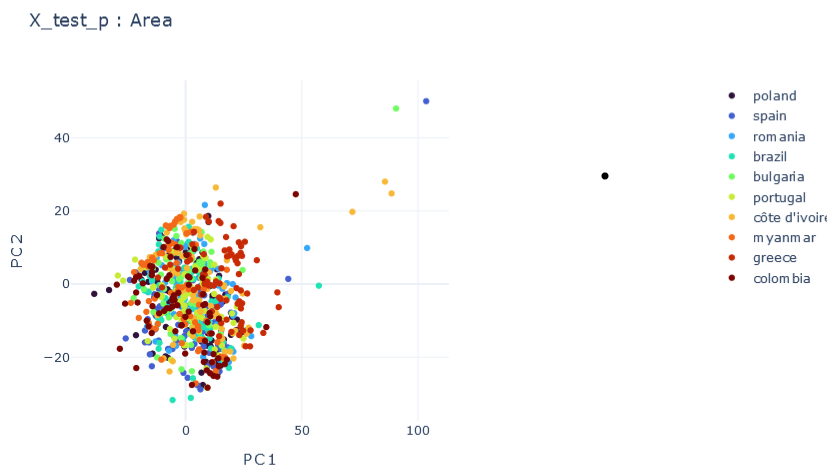
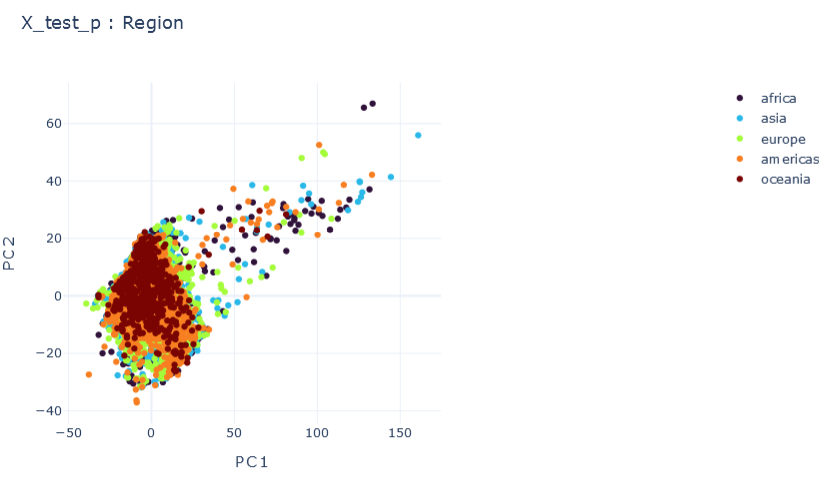
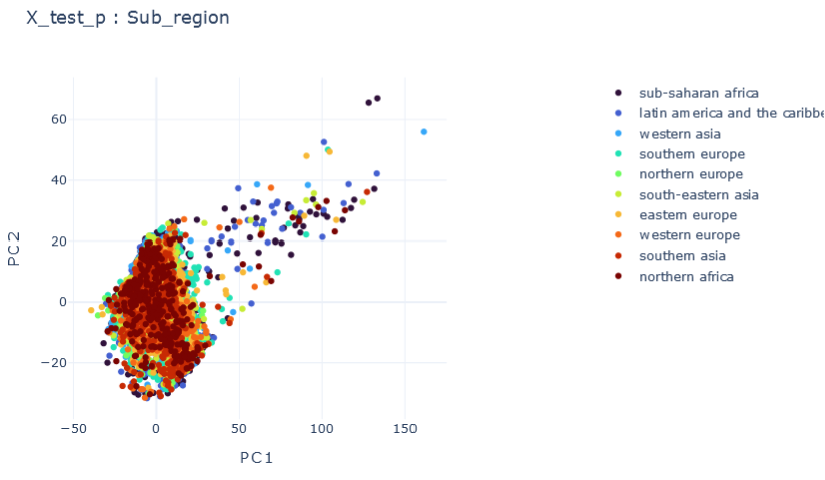
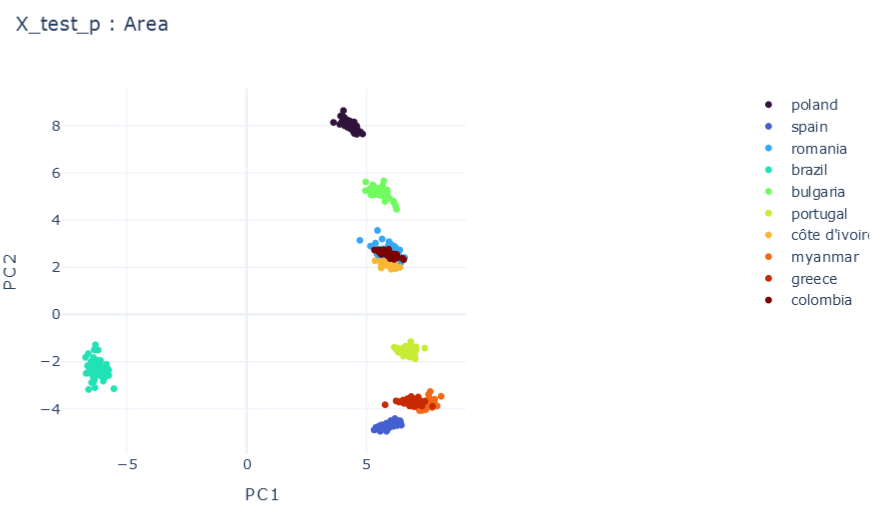
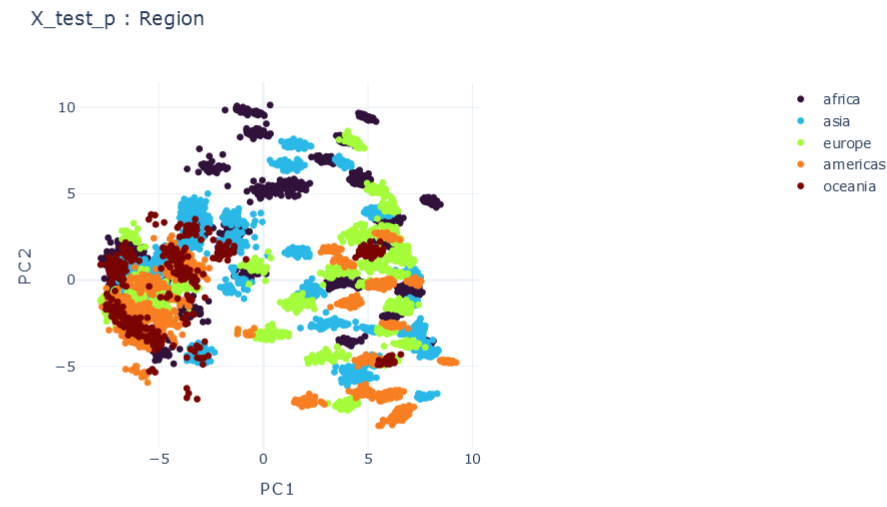
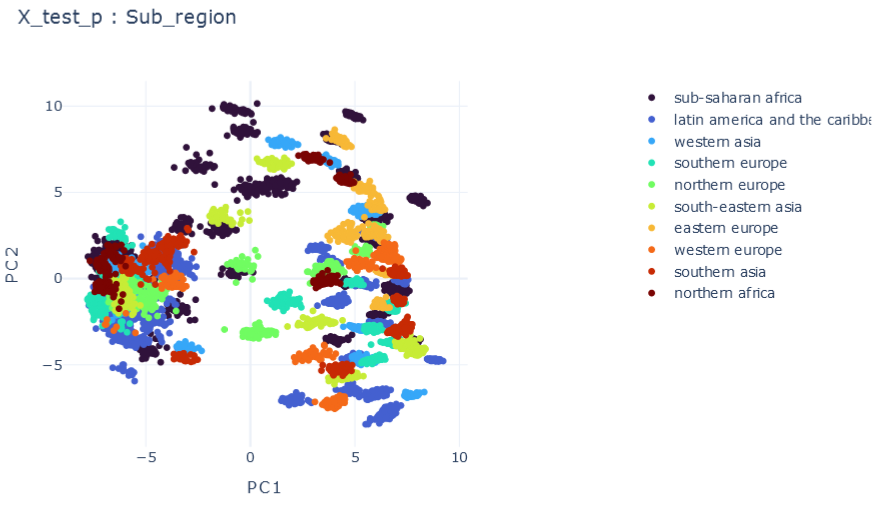
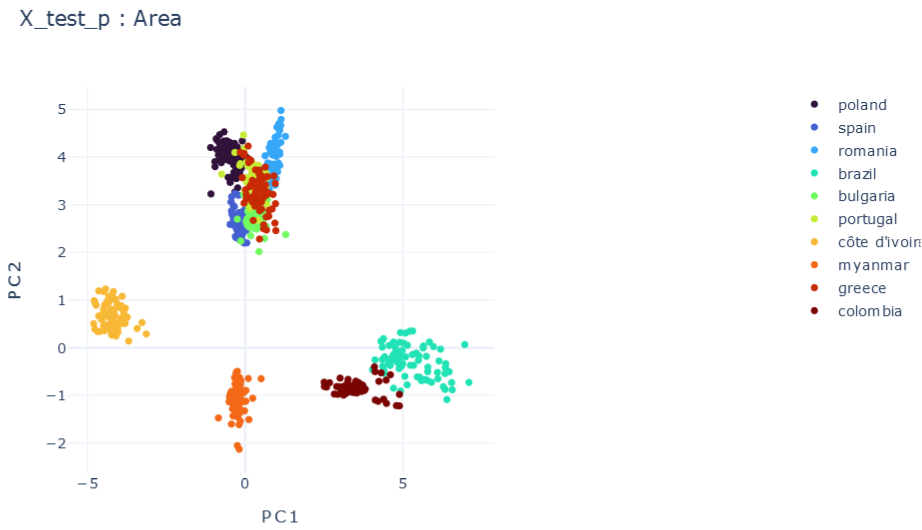
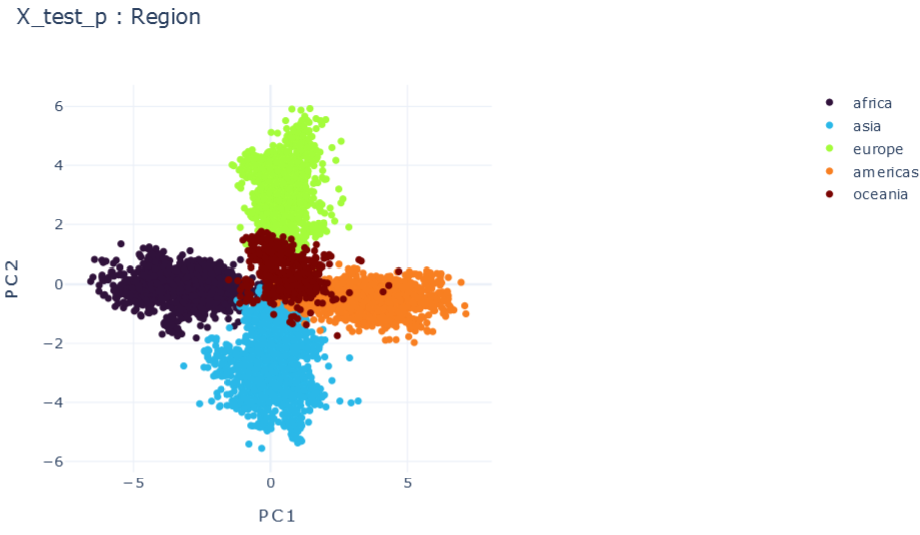
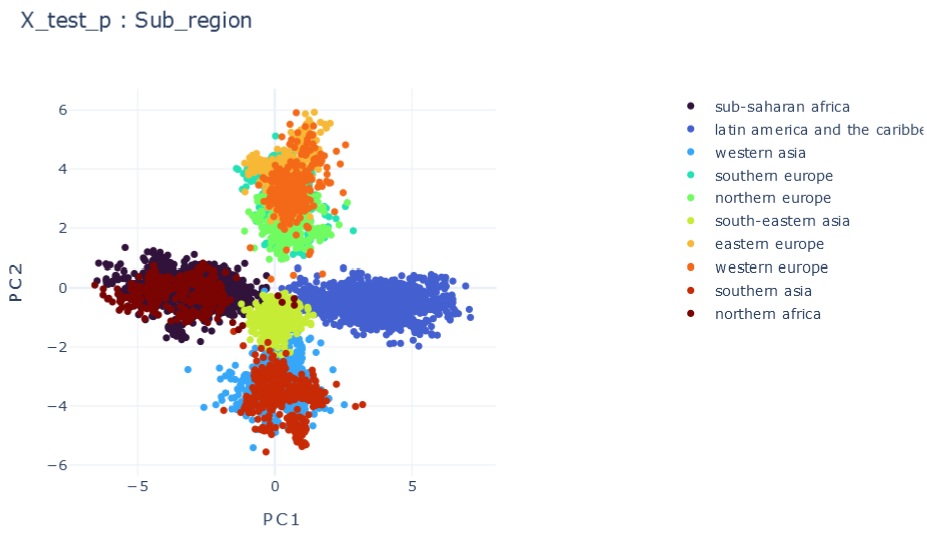
E \(\psi_0=0.1, \psi_1=0.1 , \psi_2=0.1\)
\(R2:0.66\)
F \(\psi_0=1, \psi_1=0.1 , \psi_2=0.1\)
\(R2:0.79\)
Representation Results
DMTRL
mE2 \(\psi_0=0.1, \psi_1=1E-5 , \psi_2=0.0001\)
\(R2:0.90\)
mE3 \(\psi_0=0.01, \psi_1=0.0001 , \psi_2=1E-5\)
\(R2:0.75\)
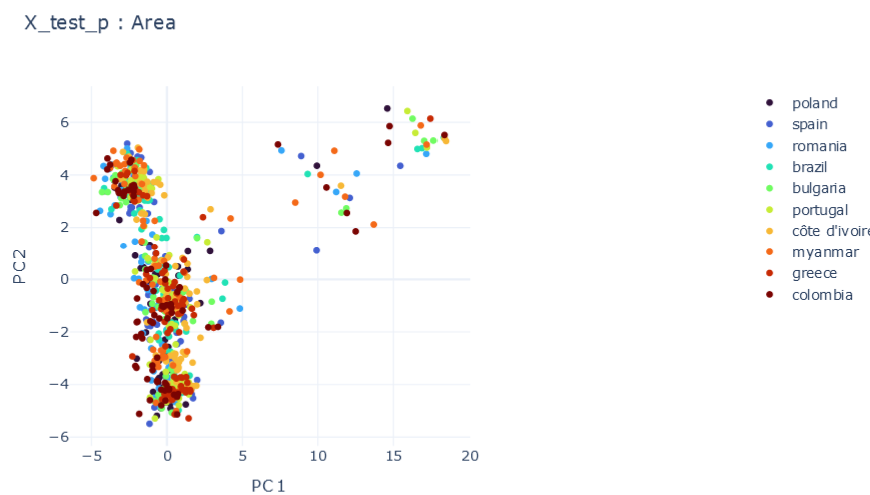
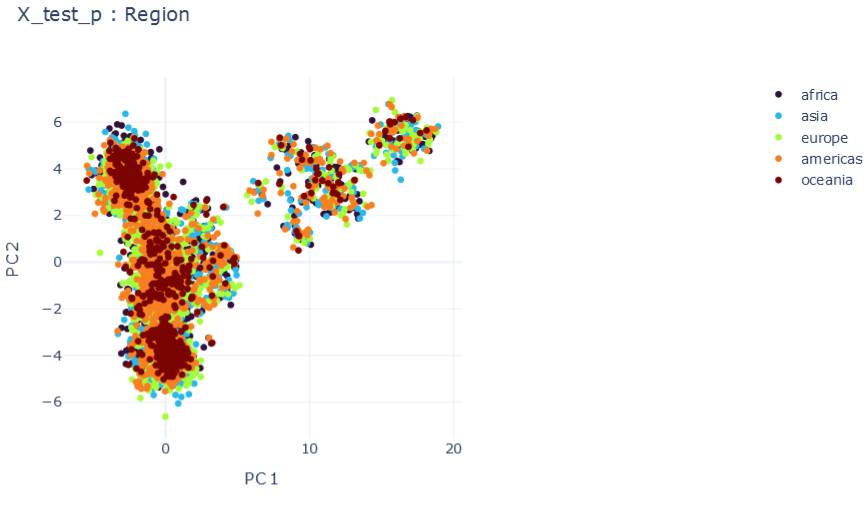
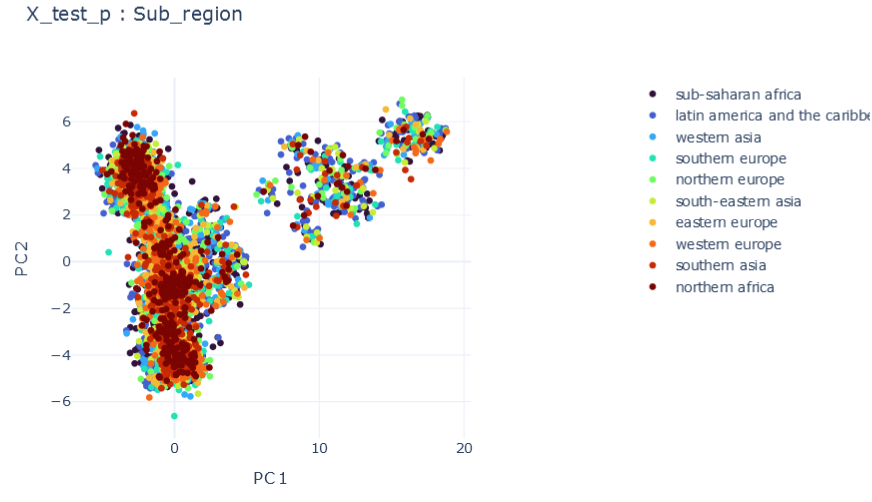
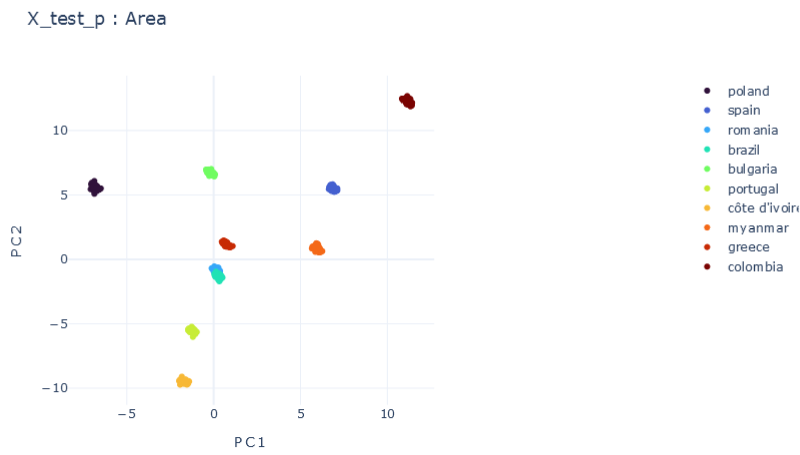
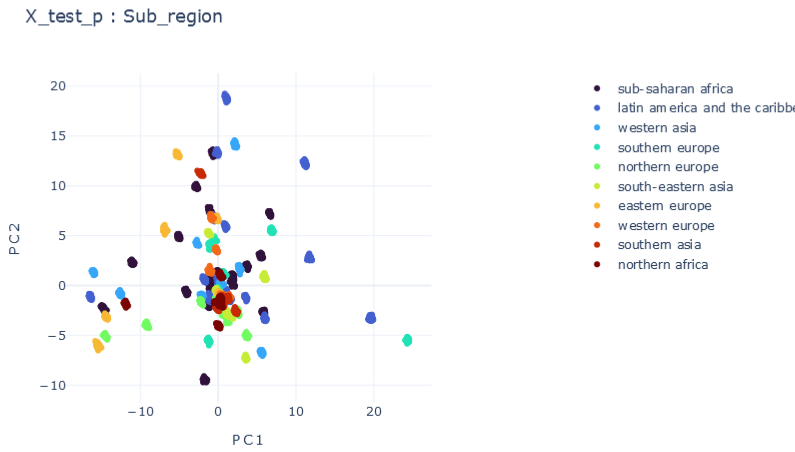
mF \(\psi_0=1, \psi_1=1E-5 , \psi_2=1E-5\)
\(R2:0.980\)
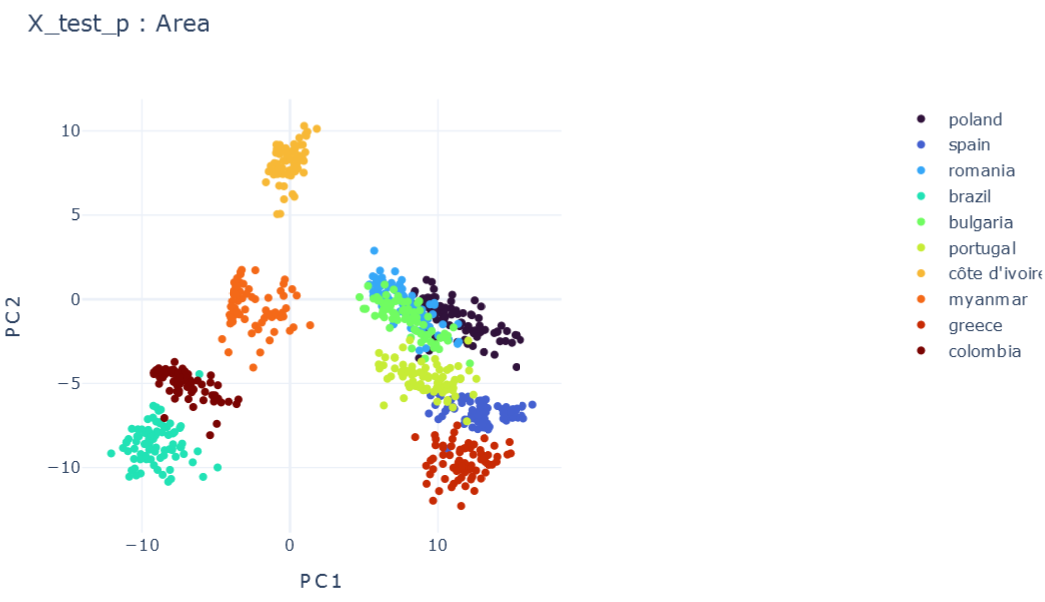
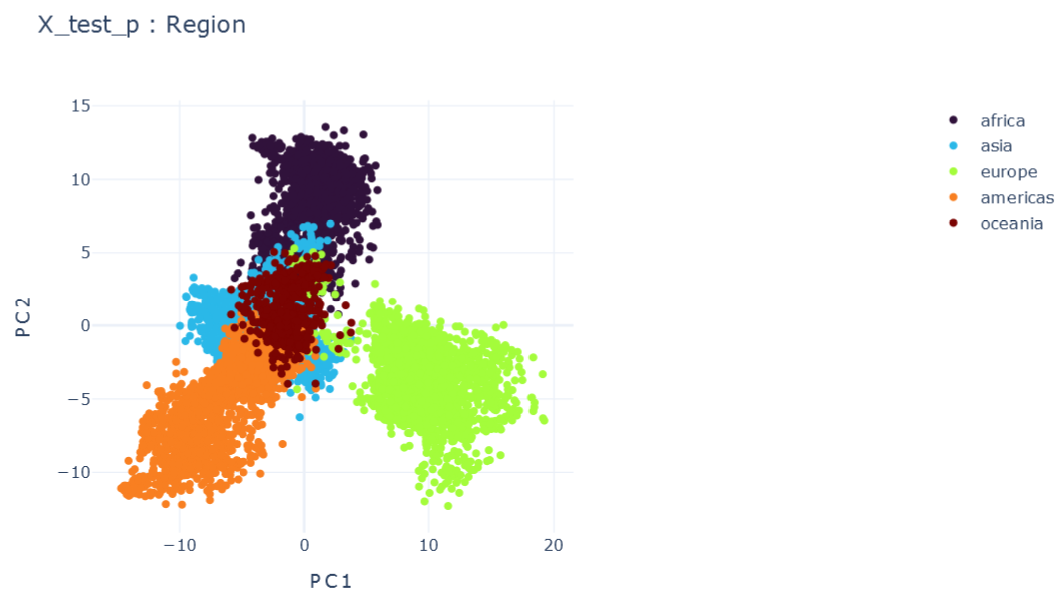
Representation Results
Validation Results
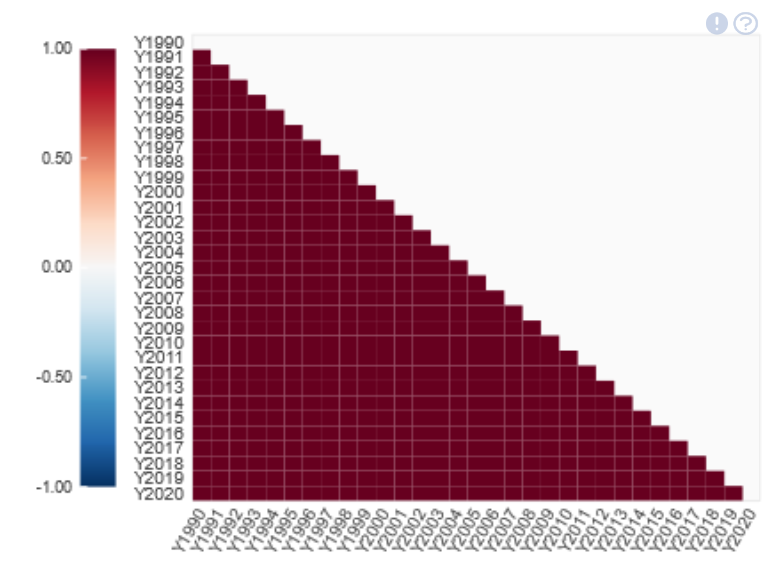
CORRELATIONS
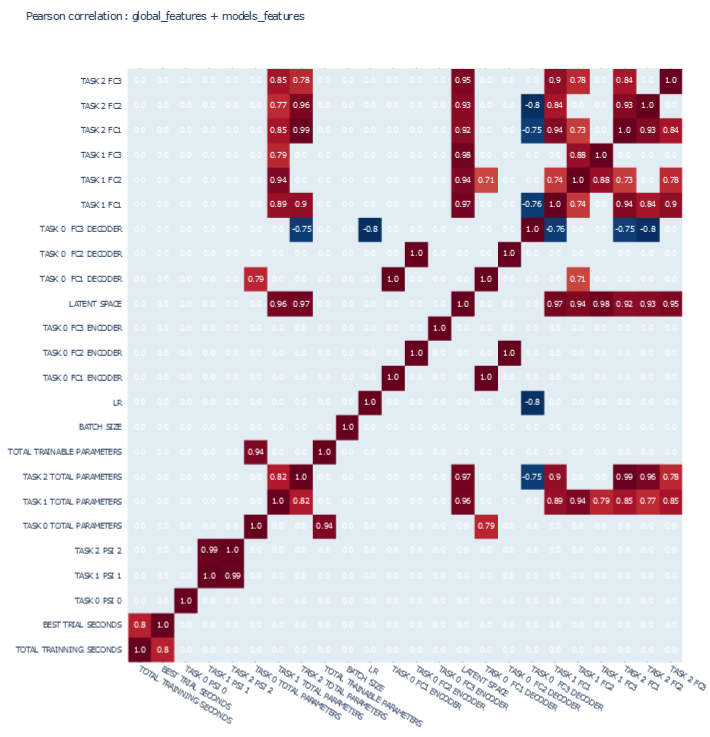
Global features
- 'TOTAL TRAINNING SECONDS', 'BEST TRIAL SECONDS',
- 'TASK 0 PSI 0', 'TASK 1 PSI 1', 'TASK 2 PSI 2',
- 'TASK 0 TOTAL PARAMETERS', 'TASK 1 TOTAL PARAMETERS', 'TASK 2 TOTAL PARAMETERS', 'TOTAL TRAINABLE PARAMETERS',
- 'BATCH SIZE', 'OPTIMIZER', 'LR',
Models features
-
'TASK 0 ACTIVATION', 'TASK 1 ACTIVATION', 'TASK 2 ACTIVATION',
-
'TASK 0 FC1 ENCODER', 'TASK 0 FC2 ENCODER , 'TASK 0 FC3 ENCODER', 'LATENT SPACE', 'TASK 0 FC1 DECODER', 'TASK 0 FC2 DECODER', 'TASK 0 FC3 DECODER',
-
'TASK 1 FC1', 'TASK 1 FC2', 'TASK 1 FC3',
-
'TASK 2 FC1', 'TASK 2 FC2', 'TASK 2
Global features
- 'TOTAL TRAINNING SECONDS', 'BEST TRIAL SECONDS',
- 'TASK 0 PSI 0', 'TASK 1 PSI 1', 'TASK 2 PSI 2',
- 'TASK 0 TOTAL PARAMETERS', 'TASK 1 TOTAL PARAMETERS', 'TASK 2 TOTAL PARAMETERS', 'TOTAL TRAINABLE PARAMETERS',
- 'BATCH SIZE', 'OPTIMIZER', 'LR',
Warm-up features
-
'TASK 0 TRAIN LOSS WARM-UP', 'TASK 0 VALID LOSS WARM-UP',
-
'TASK 1 TRAIN ACC WARM-UP', 'TASK 1 VALID ACC WARM-UP',
-
'TASK 2 TRAIN ACC WARM-UP', 'TASK 2 VALID ACC WARM-UP',
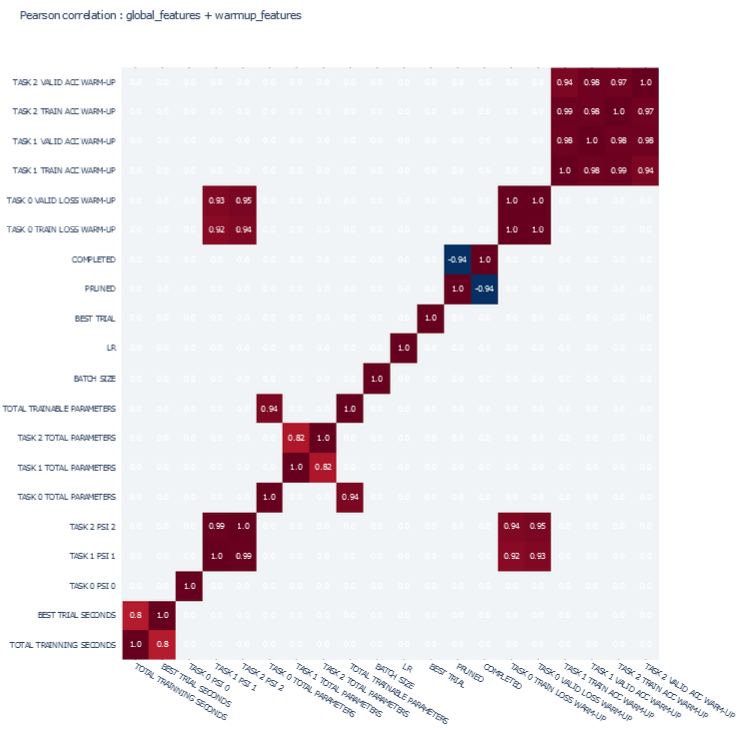
Validation Results
CORRELATIONS
Global features
- 'TOTAL TRAINNING SECONDS', 'BEST TRIAL SECONDS',
- 'TASK 0 PSI 0', 'TASK 1 PSI 1', 'TASK 2 PSI 2',
- 'TASK 0 TOTAL PARAMETERS', 'TASK 1 TOTAL PARAMETERS', 'TASK 2 TOTAL PARAMETERS', 'TOTAL TRAINABLE PARAMETERS',
- 'BATCH SIZE', 'OPTIMIZER', 'LR',
Task 0 results features
-
'TASK 0 XTEST RMSE', 'TASK 0 XTEST MSE', 'TASK 0 XTEST R2',
-
'TASK 0 XVAL RMSE', 'TASK 0 XVAL MSE', 'TASK 0 XVAL R2',
-
'TASK 0 XTRAIN RMSE', 'TASK 0 XTRAIN MSE', 'TASK 0 XTRAIN R2',
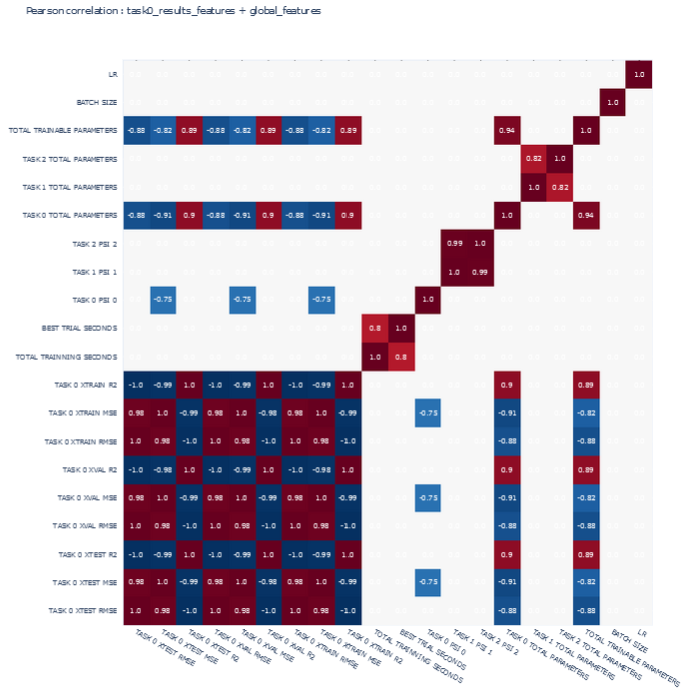
Validation Results
CORRELATIONS
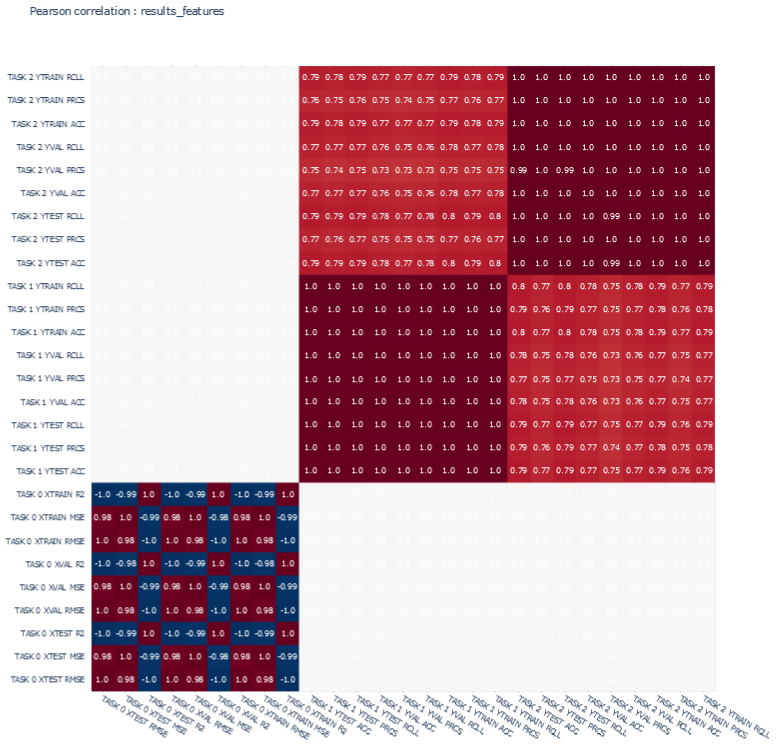
Global features
-
'TASK 0 XTEST RMSE', 'TASK 0 XTEST MSE', 'TASK 0 XTEST R2',
-
'TASK 0 XVAL RMSE', 'TASK 0 XVAL MSE', 'TASK 0 XVAL R2',
-
'TASK 0 XTRAIN RMSE', 'TASK 0 XTRAIN MSE', 'TASK 0 XTRAIN R2',
-
'TASK 1 YTEST ACC', 'TASK 1 YTEST PRCS', 'TASK 1 YTEST RCLL',
-
'TASK 1 YVAL ACC', 'TASK 1 YVAL PRCS', 'TASK 1 YVAL RCLL',
-
'TASK 1 YTRAIN ACC', 'TASK 1 YTRAIN PRCS', 'TASK 1 YTRAIN RCLL',
-
'TASK 2 YTEST ACC', 'TASK 2 YTEST PRCS', 'TASK 2 YTEST RCLL',
-
'TASK 2 YVAL ACC', 'TASK 2 YVAL PRCS', 'TASK 2 YVAL RCLL',
-
'TASK 2 YTRAIN ACC', 'TASK 2 YTRAIN PRCS', 'TASK 2 YTRAIN RCLL'
Validation Results
CORRELATIONS
- Contributions:
- Models:
- Isolated, Multi-task, Deep Multi-task, Deep Multi-task Representation Learning approaches
- Shared weights contributions
- Methodologies:
- Data train/test/val split strategy
- Models warm-up/trainning strategy
- Metrics & validation strategy
- Results correlations and similarities strategy
- Models:
Conclusions
deck
By Goa J


