Crawler Service
Business Process
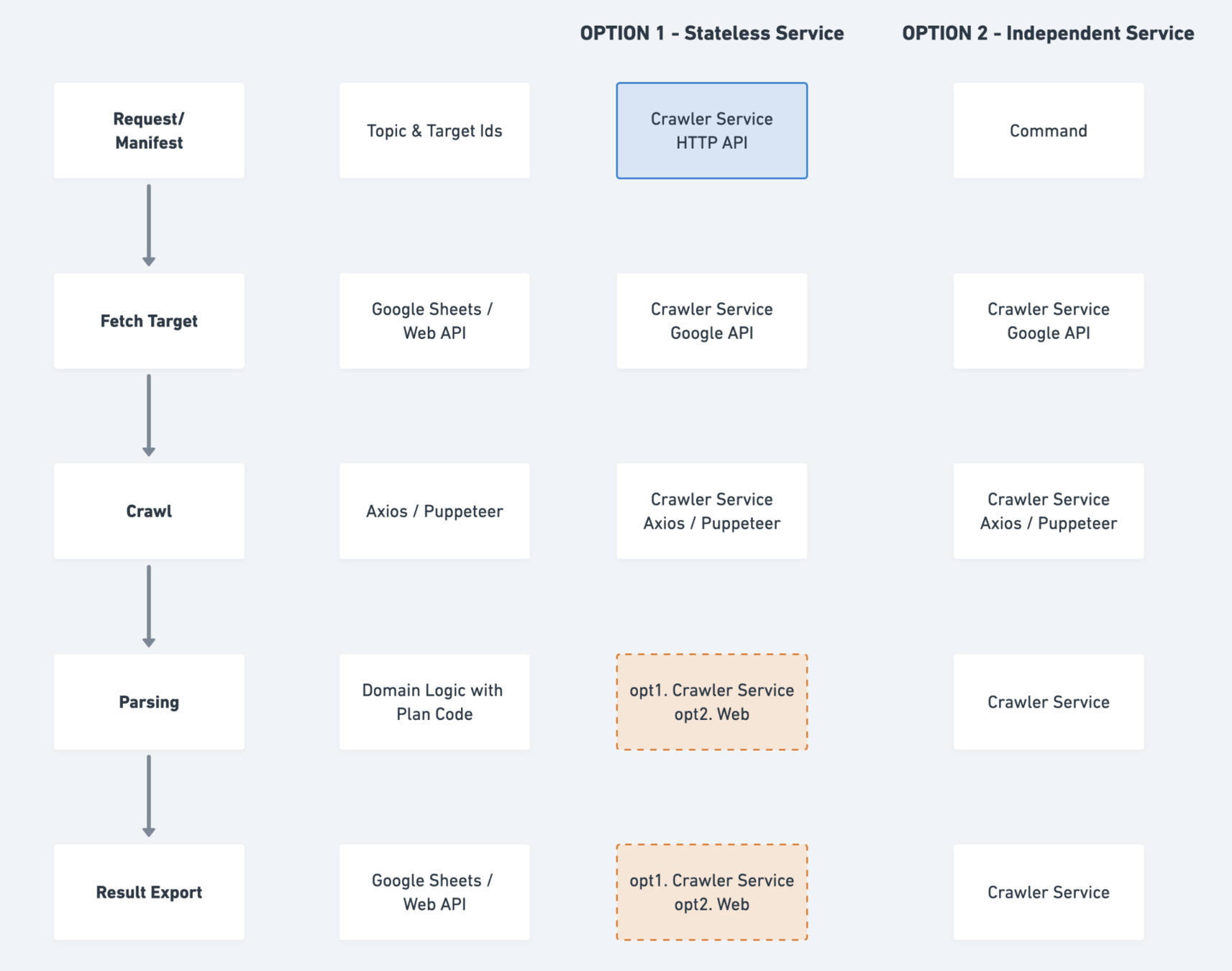
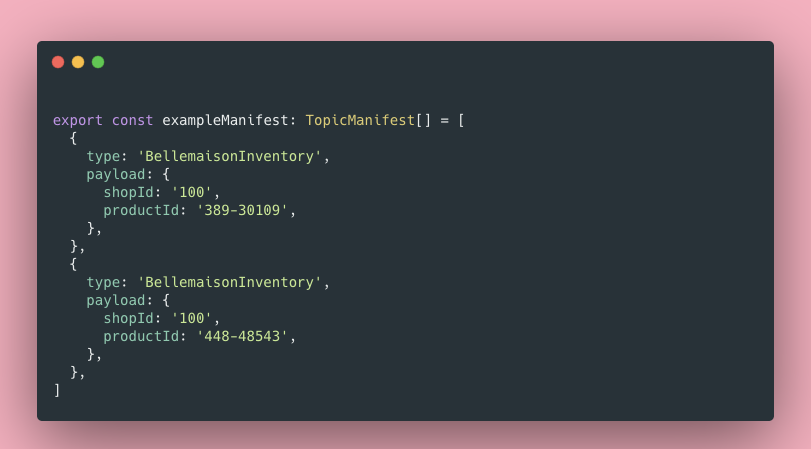
Step1. Targeting
abstraction: Manifest
(the only interface between external service)
Step2. Crawling
abstraction: Topic.source, Record
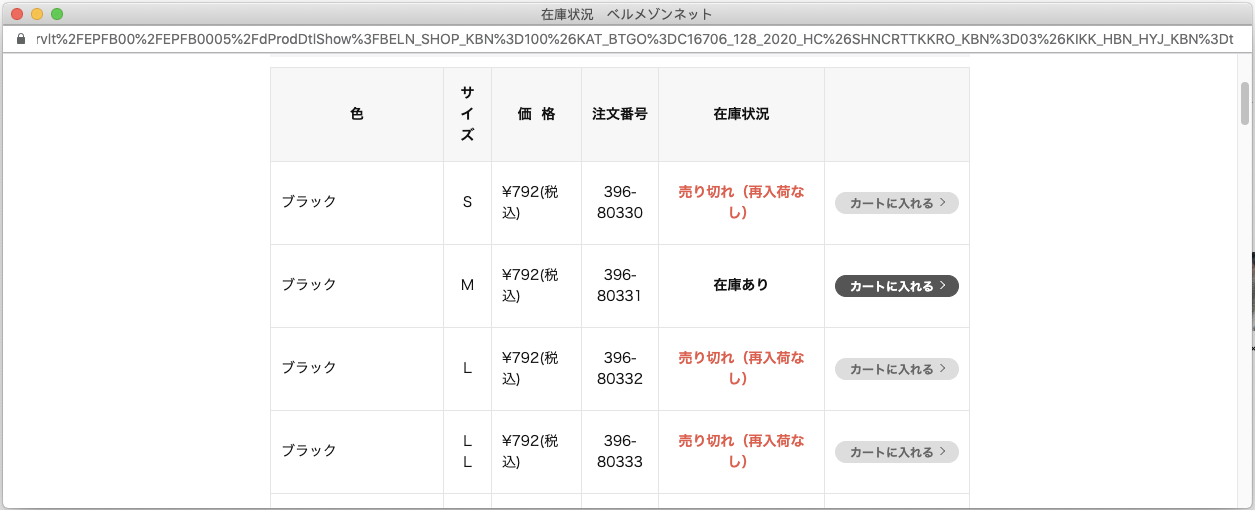
Step3. Parsing
abstraction: Topic.consume
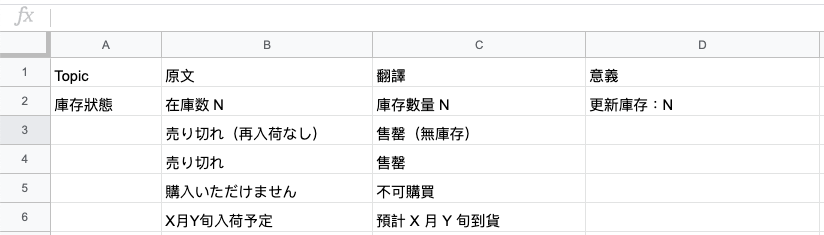
Step4. Upload/Export Result
abstraction: Topic.export
1) Web API - update inventory
2) Export to independent Google Sheets
3) Directly update data in Original Google Sheets
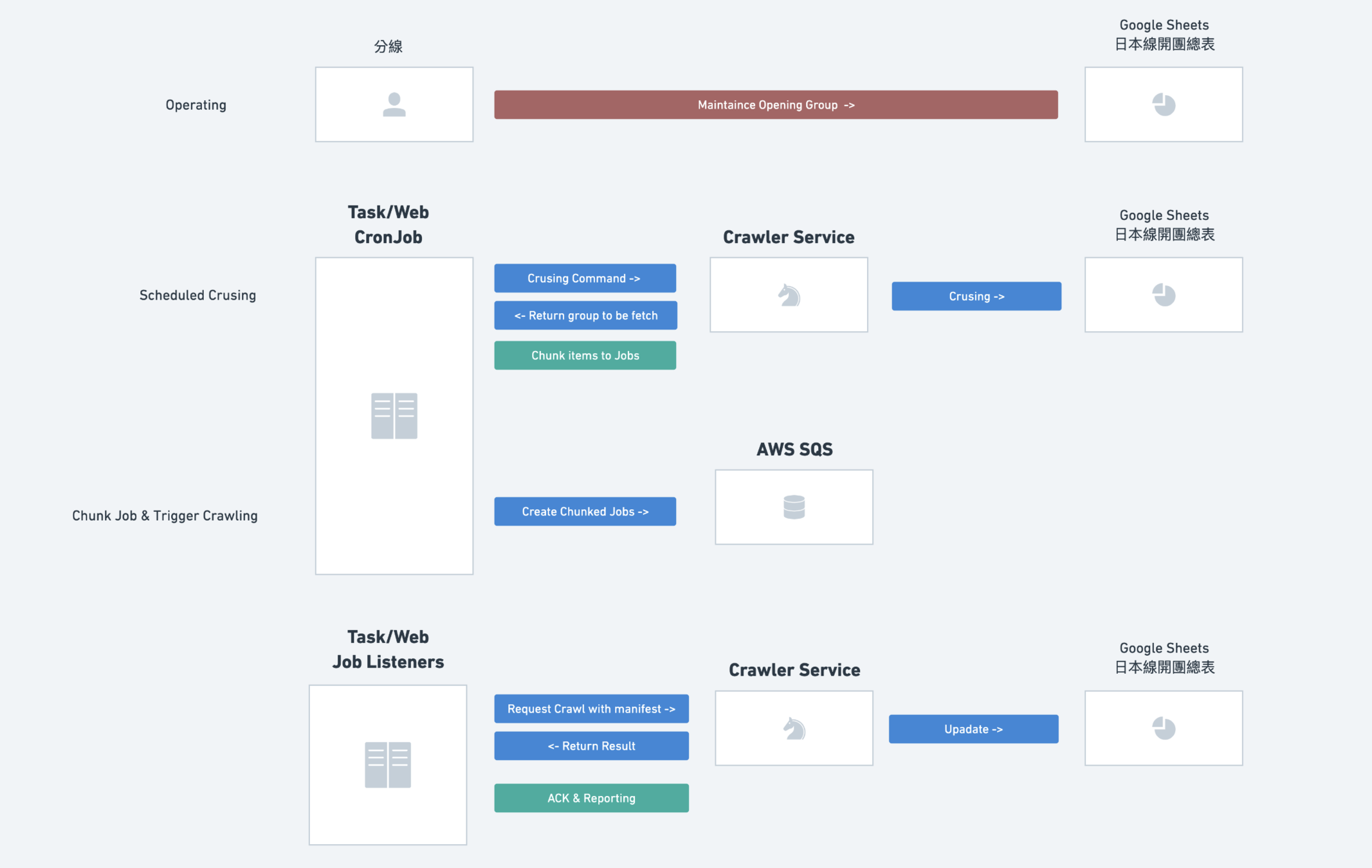
Option #1.
Crawler as a stateless service
with HTTP APIs
High Coupling (The whole Process) with Web infra
But with one-way dependency & error boundary
Summary
Task/Web schedules cron jobs, transformed to SQS.
Task/Web serves as worker in an independent group.
Crawler service as a service, exporting HTTP APIs.
Option #2.
Crawler as a Independent Service
A service with fully self-contain system.
Core Crawling Tech Stack
puppeteer
TypeScript / Node.js
supertest/jest
axios
cheerio
AWS SQS/Redis
Crawling Service
Nest.js
Node.js TypeScript
Code Organization
Application Logic / Domain Logic
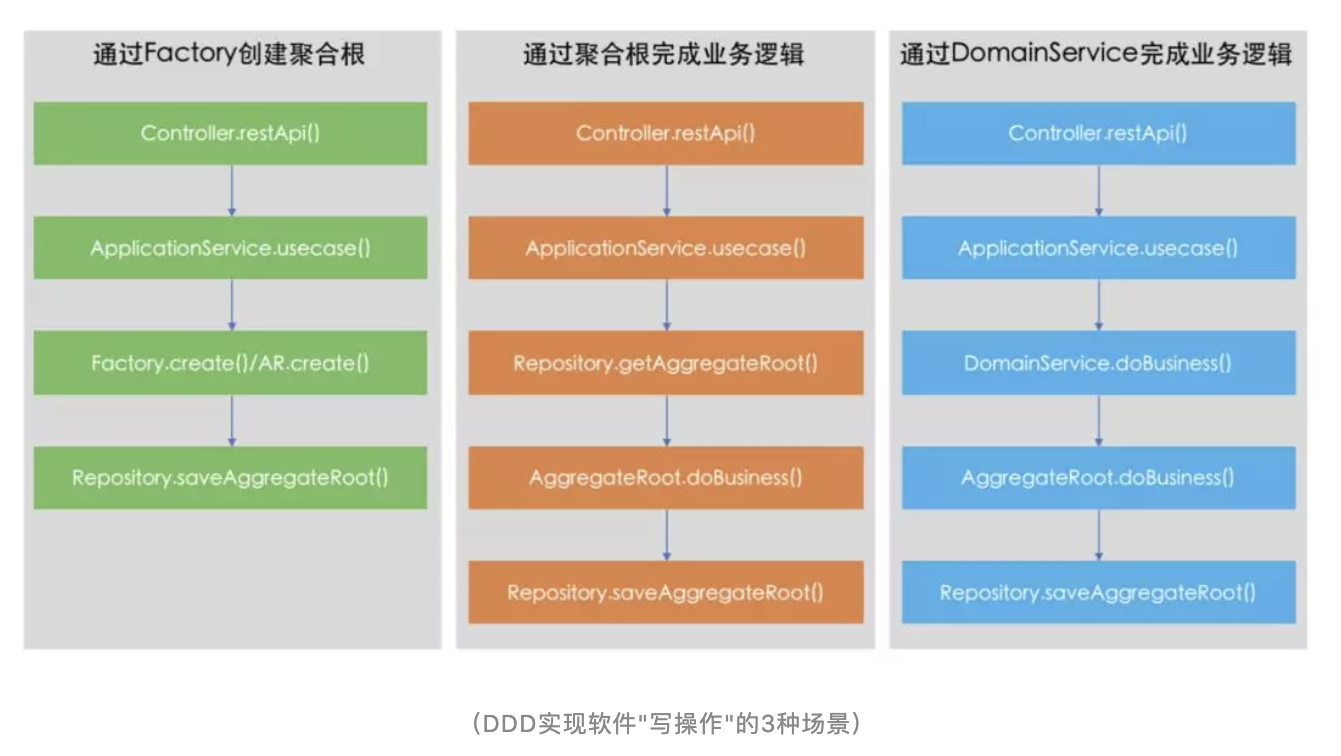
https://mp.weixin.qq.com/s/g1i04xjUgkqLOqtTeFukgQ
Module (DI/IOC)
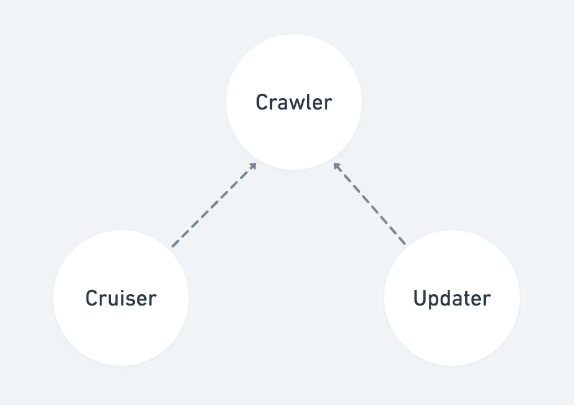
Dependency flow
Module dependency flow
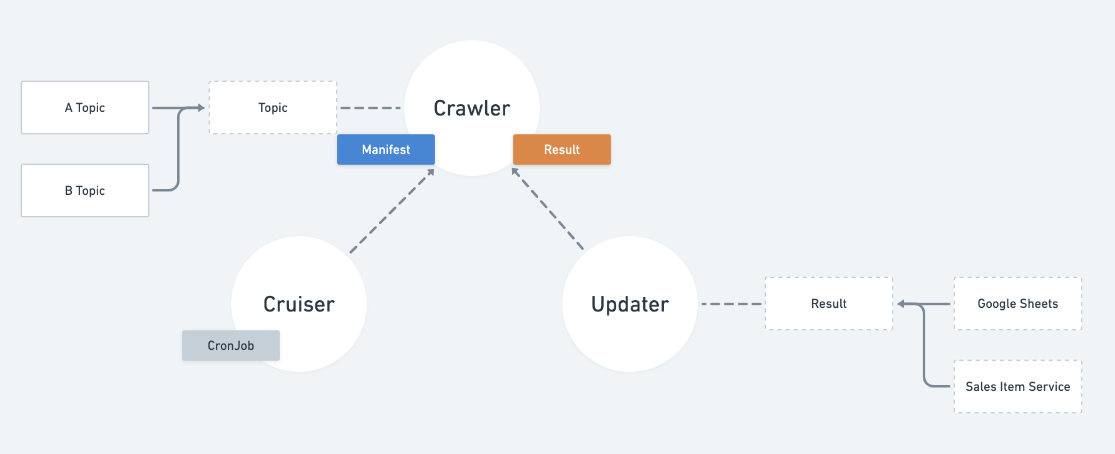
Decision Flow/Error Handling
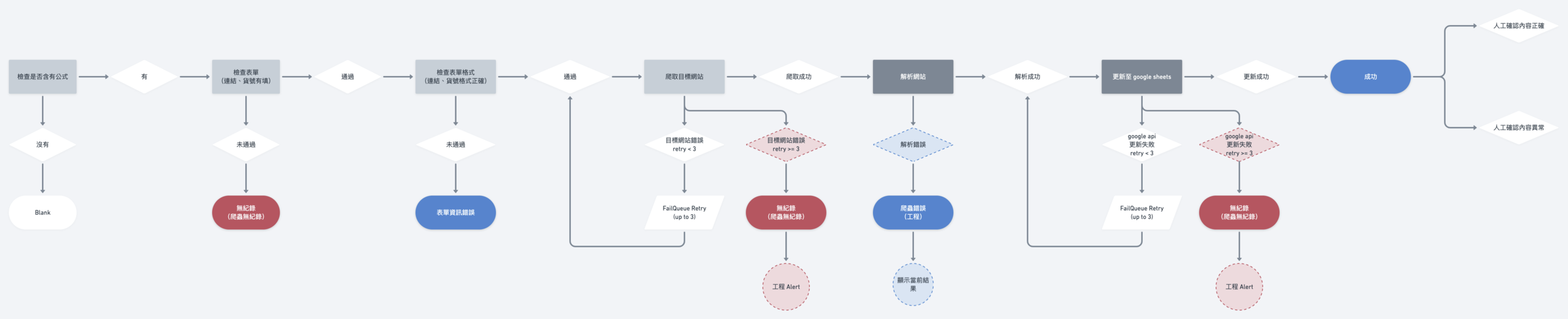
Cruiser & Updater (google sheet)
Puppeteer
Cypress
Crawler Service
By guansunyata



