pixiv小説で
機械学習する
(公開版)
2016-08-19 pixiv社内勉強会 LT
@hakatashi

前座
ErogameScape
データベースに直接
SQLを発行できる
ER図
レビューデータ
博多市は思いついた
レビュー文章に対して評価点で回帰分析を行う
未知の文章に対して評価点を推定できる
評判分析ができる!
やってみた

うまくいかない
TF-IDFとbag-of-wordを用いた
古典的な特徴抽出では
短文解析は難しいのかも
本題
時は21世紀、
時代は深層学習へ
word2vec
word2vec
Facebookの研究者 Tomas Mikolov 氏が
2013年に開発したアルゴリズム
word2vec
名前の通り、単語をベクトルに変換する。
このベクトルは入力コーパスから学習され、
単語の「意味」をよく表現する。
単語の意味?
適切な意味づけと
十分な次元数があれば
単語の「意味」を
ベクトル空間上に
写像することができるはず
とりあえず
最近1ヶ月の
pixivの艦これ小説
1400件で学習してみる
sentence2vecという実装を使用
結果
In [3]: model.most_similar(["駆逐"])ベクトル空間上におけるある単語の
近傍単語を検索してみる
「駆逐」
?
?
In [3]: model.most_similar(["駆逐"])Out[3]:
[('潜水', 0.9531328082084656),
('娘', 0.948664665222168),
('秘書', 0.9383386373519897),
('混血', 0.928562343120575),
('武勲', 0.917698860168457),
('同型', 0.8970655798912048),
('随伴', 0.8891916871070862),
('初期', 0.8798855543136597),
('工作', 0.8794721364974976),
('攻', 0.8708728551864624)]In [6]: model.most_similar(["青葉"])Out[6]:
[('榛名', 0.9007627367973328),
('早霜', 0.8989377617835999),
('ローマ', 0.8870198130607605),
('織姫', 0.8837313055992126),
('弥生', 0.8708004355430603),
('長月', 0.8637794852256775),
('飛鳥', 0.8532511591911316),
('明石', 0.8518548011779785),
('あたし', 0.8504984378814697),
('あなた', 0.8477708101272583)]In [8]: model.most_similar(["横須賀"])
Out[8]:
[('佐世保', 0.7711231112480164),
('主席', 0.7632885575294495),
('整備', 0.7631702423095703),
('舞鶴', 0.741066038608551),
('新造', 0.7339426875114441),
('客室', 0.7318019866943359),
('外国', 0.7297484874725342),
('論', 0.7271702289581299),
('流派', 0.7256584763526917),
('公務', 0.7249108552932739)]In [11]: model.most_similar(["嬉しい"])Out[11]:
[('楽しい', 0.889489471912384),
('興味深い', 0.8587278723716736),
('寂しい', 0.8519048690795898),
('言い返す', 0.8394687175750732),
('みえる', 0.8109815716743469),
('照れくさい', 0.8082438707351685),
('名残惜しい', 0.8045729994773865),
('照れ臭い', 0.8017405867576599),
('窺える', 0.7870444059371948),
('うれしい', 0.7839582562446594)]In [12]: model.most_similar(["死ぬ"])Out[12]:
[('沈む', 0.8655137419700623),
('飲む', 0.8313961029052734),
('持ち込む', 0.802043080329895),
('喜ぶ', 0.7908689975738525),
('話し込む', 0.7821533679962158),
('遊ぶ', 0.7762762904167175),
('巻き込む', 0.7687581777572632),
('済む', 0.7661187052726746),
('混む', 0.7658472061157227),
('突っ込む', 0.761398196220398)]サイコーでは?
それで満足していいのか?
正直類似語を引くだけなら
共起表現を調べるだけでもいける
単語の分散表現の醍醐味は
もっと深いところにある
再チャレンジ
学習対象のコーパスを
直近1ヶ月のpixiv小説
94000件に拡大
(2.1GB)
単語の次元数を
20次元から100次元に拡大
形態素解析辞書に
mecab-ipadic-NEologdを使用
辞書サイズ360MB
AWS EC2の
c4.x8largeインスタンスで学習
- コア数: 36コア
- メモリ: 60GB
結果
In [3]: model.most_similar(positive=['本丸'])Out[3]:
[('鎮守府', 0.9428098797798157),
('町', 0.9225599765777588),
('世界', 0.9113290309906006),
('会社', 0.9099076390266418),
('屋敷', 0.9055248498916626),
('カルデア', 0.9024497866630554),
('教会', 0.9000600576400757),
('旅館', 0.888569712638855),
('事務所', 0.8871119022369385),
('施設', 0.8863613605499268)]In [7]: model.most_similar(positive=['大きい'])Out[7]:
[('強い', 0.8160519599914551),
('速い', 0.7964994311332703),
('固い', 0.7778379917144775),
('硬い', 0.7755194306373596),
('激しい', 0.7726991772651672),
('重い', 0.7720433473587036),
('おおきい', 0.7673165798187256),
('熱い', 0.7659069299697876),
('濃い', 0.7300402522087097),
('小さい', 0.7113799452781677)]これはOK
ベクトルの加減算
「うれしい」ー「笑う」+「泣く」
「うれしい」
「笑う」
「泣く」
???
In [8]: model.most_similar(positive=['うれしい', '泣く'], negative=['笑う'])
Out[8]:
[('悲しい', 0.7828455567359924),
('さみしい', 0.7670904994010925),
('心細い', 0.7660513520240784),
('嬉しい', 0.7657839059829712),
('辛い', 0.7605473399162292),
('つらい', 0.7518221139907837),
('可笑しい', 0.7516210079193115),
('淋しい', 0.7475413084030151),
('哀しい', 0.7413027882575989),
('寂しい', 0.7387726902961731)]「うれしい」ー「笑う」+「泣く」
=「悲しい」
In [14]: model.most_similar(positive=['時計', '場所'], negative=['時間'])
Out[14]:
[('地図', 0.6598266363143921),
('方角', 0.6472755670547485),
('庭園', 0.647152304649353),
('遺跡', 0.6431004405021667),
('ガイドブック', 0.6320757865905762),
('鏡', 0.6296912431716919),
('天井', 0.6265701055526733),
('中庭', 0.6251875162124634),
('オアシス', 0.6211355924606323),
('プラネタリウム', 0.6207263469696045)]「時計」ー「時間」+「場所」
=「地図」
In [9]: model.most_similar(positive=['刀剣男士', '女'], negative=['男'])
Out[9]:
[('艦娘', 0.9148841500282288),
('使用人', 0.8912219405174255),
('サーヴァント', 0.8801556825637817),
('魔族', 0.8772220611572266),
('兄弟', 0.875967264175415),
('英霊', 0.8656594157218933),
('弟', 0.8649518489837646),
('クラスメイト', 0.8640071153640747),
('仲間', 0.8639708757400513),
('遊女', 0.8562957048416138)]「刀剣男子」ー「男」+「女」
=「艦娘」
In [11]: model.most_similar(positive=['チョロ松', 'おそ子'], negative=['おそ松'])
Out[11]:
[('神通', 0.8879709839820862),
('川内', 0.8838446736335754),
('霧島', 0.8780333399772644),
('森山', 0.8707031607627869),
('叢雲', 0.8702427744865417),
('羽黒', 0.8701692819595337),
('龍驤', 0.8699836730957031),
('梓', 0.8688686490058899),
('アスカ', 0.8686019778251648),
('中村', 0.8683927655220032)]「チョロ松」ー「おそ松」+「おそ子」
=「神通」
In [12]: model.most_similar(positive=['アイドル', '川内'], negative=['那珂'])
Out[12]:
[('ヒーロー', 0.8158880472183228),
('パイロット', 0.8007603883743286),
('革命軍', 0.789035439491272),
('警察官', 0.7872180938720703),
('王族', 0.7838584780693054),
('作曲家', 0.783134937286377),
('テロリスト', 0.7792449593544006),
('教師', 0.7765204310417175),
('弁護士', 0.7732360363006592),
('スパイ', 0.7711321711540222)]「アイドル」ー「那珂」+「川内」
=「ヒーロー」
In [85]: model.most_similar(positive=['敦', '現代'], negative=['明治'])
Out[85]:
[('コナン', 0.7646421194076538),
('影山', 0.7485178112983704),
('沢村', 0.744890570640564),
('赤司', 0.7426205277442932),
('月島', 0.7413253784179688),
('カラ松', 0.7408810257911682),
('一騎', 0.7396073341369629),
('芥川', 0.7389757037162781),
('仗助', 0.736397385597229),
('高尾', 0.7344973087310791)]「敦」ー「明治」+「現代」
=「コナン」
In [86]: model.most_similar(positive=['太宰', '現代'], negative=['明治'])
Out[86]:
[('赤井', 0.7817075252532959),
('影山', 0.7703953981399536),
('ヴィジョン', 0.7671884298324585),
('神様', 0.7661879062652588),
('スーパーマン', 0.764479398727417),
('カミュ', 0.7633488774299622),
('自分自身', 0.7630664706230164),
('スモーキー', 0.7627824544906616),
('アルミン', 0.7617053985595703),
('三好', 0.7605339288711548)]「太宰」ー「明治」+「現代」
=「赤井」
In [87]: model.most_similar(positive=['乱歩', '現代'], negative=['明治'])
Out[87]:
[('黒尾', 0.7538242340087891),
('プロデューサー', 0.7511755228042603),
('及川', 0.7510856986045837),
('太宰', 0.7439517974853516),
('カナメ', 0.7422207593917847),
('赤井', 0.7359139919281006),
('啓介', 0.7303615808486938),
('菅原', 0.7300347089767456),
('スーパーマン', 0.7290314435958862),
('天童', 0.7267012000083923)]「乱歩」ー「明治」+「現代」
=「黒尾」
Semantic Morphing
Semantic Morphing
ある単語とある単語の間を
「意味的に」補完するような
別の単語を探索する
In [80]: model.most_similar(positive=['完全', '不完全'])
Out[80]:
[('中途半端', 0.9110033512115479),
('完璧', 0.9008808732032776),
('明確', 0.8872247934341431),
('見事', 0.886226236820221),
('まとも', 0.8742809295654297),
('緩やか', 0.8702829480171204),
('妙', 0.8667787313461304),
('静か', 0.8649251461029053),
('控えめ', 0.8648726344108582),
('従順', 0.8615698218345642)]「完全」と「不完全」の中間
=「中途半端」
In [68]: model.most_similar(positive=['友達', '恋人'])
Out[68]:
[('家族', 0.9201378226280212),
('友人', 0.9052004814147949),
('彼氏', 0.9029746055603027),
('友だち', 0.9006283283233643),
('知り合い', 0.8926475048065186),
('親友', 0.8905645608901978),
('相棒', 0.8887679576873779),
('女の子', 0.8882120251655579),
('身内', 0.8857666254043579),
('妻', 0.8857136964797974)]「友達」と「恋人」の中間
=「家族」
すごい
paragraph2vec
paragraph2vecを用いると
単語と同様に文章もベクトル化できる
pixiv小説の
文章ベクトルに対して、
近傍文書を探索してみる
In [14]: model.docvecs.most_similar([model.docvecs[1000]])
Out[14]:
[('6906197', 1.0000001192092896),
('6941223', 0.6282722353935242),
('7002612', 0.6124914288520813),
('6978427', 0.5993743538856506),
('6971647', 0.5779218673706055),
('6967953', 0.5744274854660034),
('6947502', 0.5634234547615051),
('6905223', 0.5545478463172913),
('6907465', 0.5511782765388489),
('7008107', 0.5498178601264954)]SVMでタグ分類
SVMでタグ分類
小説がベクトル化されたので、
みんな大好きSVMで
小説につけられたタグに対して
学習を行うことができる
「R-18」タグだと判定率89.9%
※五分割交差検定による検定結果
- 真陽性: 2146件
- 偽陽性: 308件
- 真陰性: 14822件
- 偽陰性: 1600件
- 陽性尤度比: 28.08
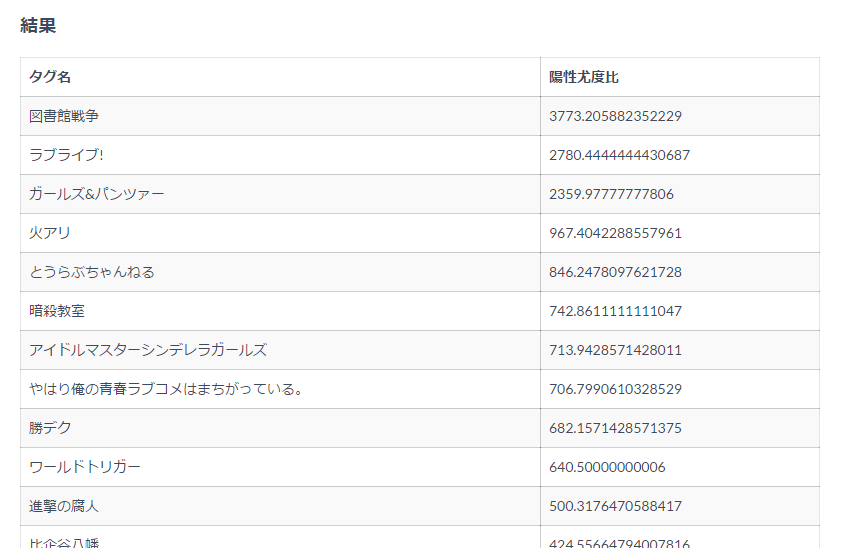
pixiv小説のタグ上位100件について
判定機を作った結果
あと、
- K-means法によるクラスタリング
とかやってみた。
おまけ
fastText
つい昨日、Facebook Research から
word2vecの後継的なプログラム
fastTextがリリースされたので
ついでに使ってみたよ
まとめ
- word2vec, paragraph2vec は本当にすごい
- 意外ともう気軽に応用可能なレベルまで来てる
- レコメンダとか、自動タグ付けとか
- 機械学習楽しいのでみんな軽率にやるといいと思う
- AWS最高!!! (かかった費用130円程度)
End
pixiv小説で機械学習する (公開版)
By Koki Takahashi
pixiv小説で機械学習する (公開版)
2016-08-19 pixiv社内勉強会 LT



