RAG & AGents
DS Ops day Nov 2024
PUB TIME
Go drink too much and have fun
Index
Recall:
- GenAI is just "predict the next token (word) with a loop"
- Normally with "LLMs" we mean "instruction tuned"
- Good zero/few shot learners
- They have no connectivity/access to data they haven't been trained upon
That means we have to inject information the LLM doesn't know if we want it to do well
LLMs and limitations
LLMs and limitations
In AVA right now we use "few shot learning"
- idea is we just provide some examples to the LLM when we define the prompt
- number of examples is limited to the LLM context size (ie max length)
- have to rework/reevaluate the prompt for new examples
Instead inject only relevant examples
Injecting Knowledge
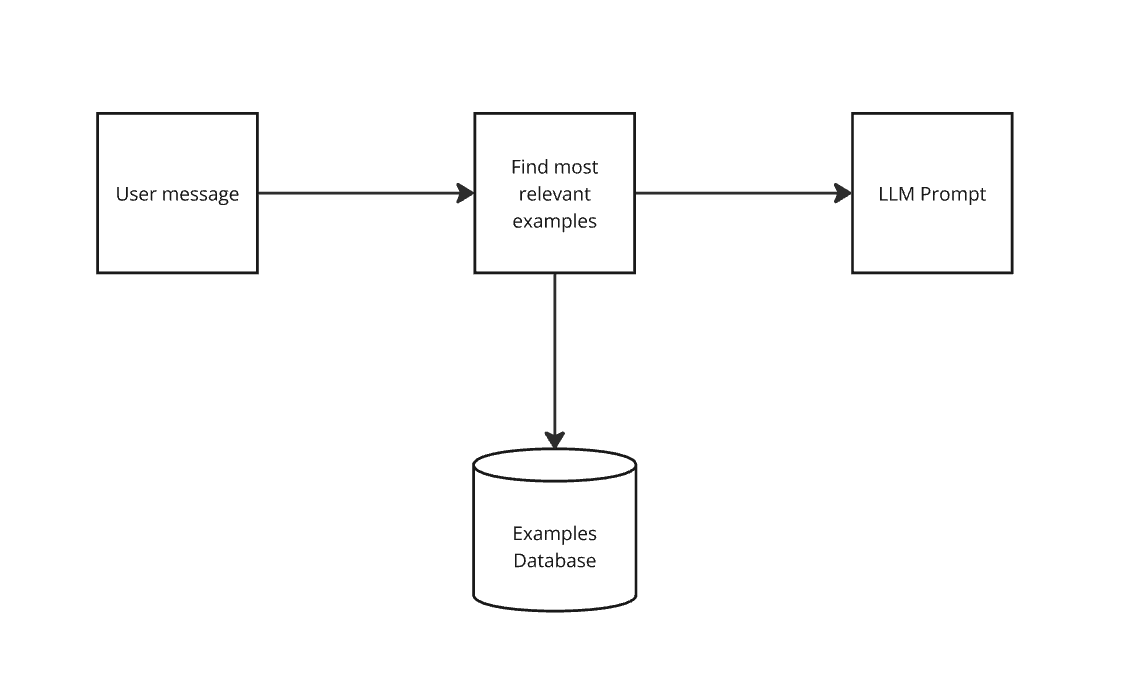
Now decoupled, can add/update knowledge at any time
How do we pick what the right examples are?
Lots of ways to do this:
- tf-idf (standard search)
- tf-idf with boosting (useful when you have time components)
- similarity search (most popular for documents)
- QA similarity search
- knowledge graphs
Injecting knowledge
similarity Search
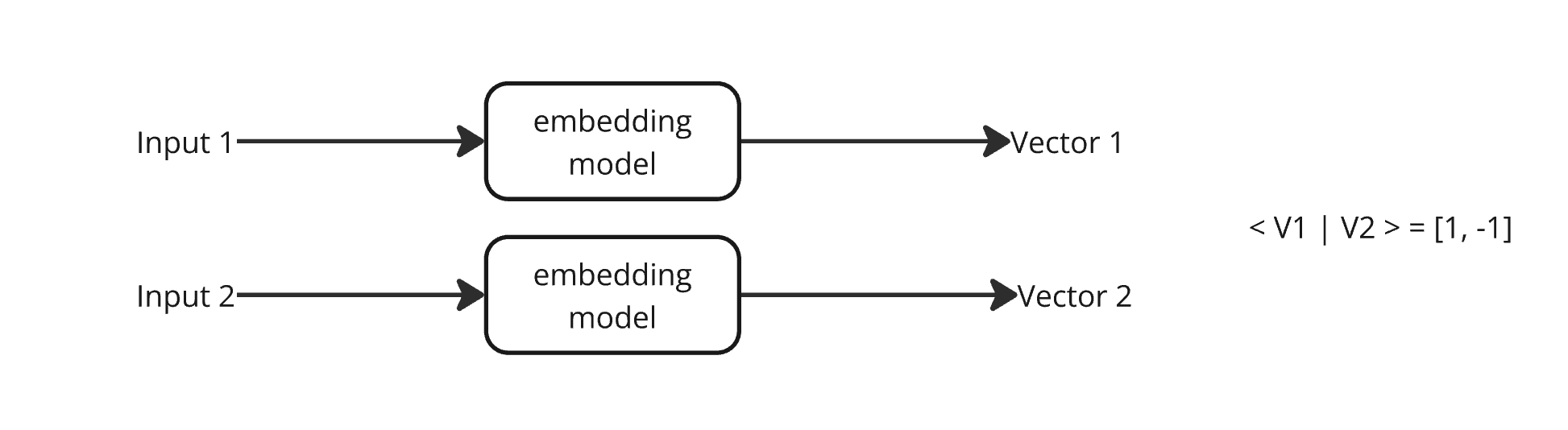
Idea is you have an embedding model which:
- embeds text into vectors
- where the vectors are close to 1 if similar
- 0 if unrelated
- -1 if opposite
Similarity Search
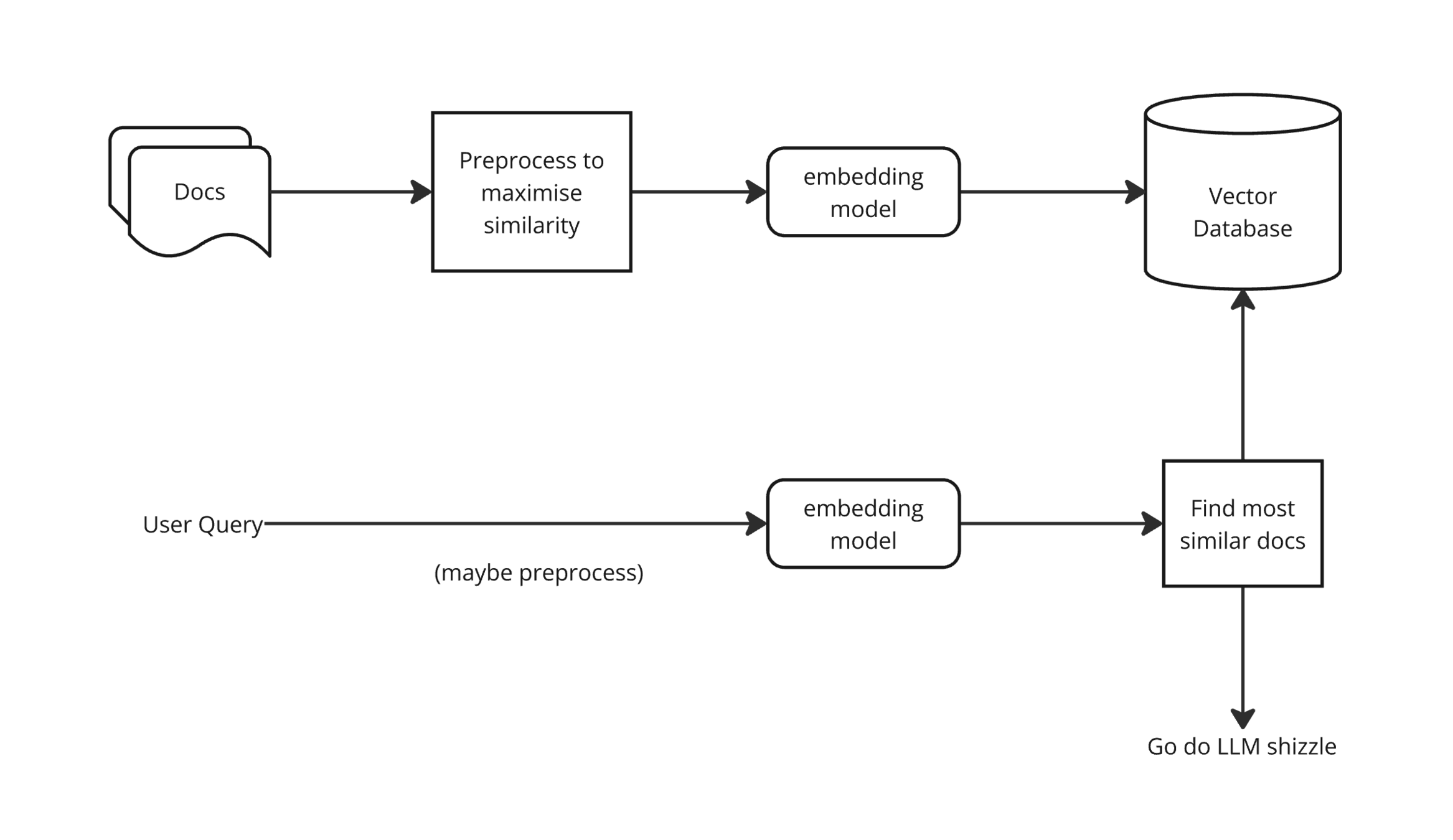
quick demo
Injecting Knowledge
Pros:
- You can boost performance for classifiers by providing examples
- You can widen the scope of what's injected, eg help articles
- You can ask the LLM to build things like action plans
Cons:
- Testing becomes harder (no static prompt)
- Preprocessing + embeddings matter a lot
- More infra to juggle
Injecting Knowledge
How should we evaluate this?
We should evaluate end-to-end, this is what any user sees
We also want to evaluate the components, this is how we spot weak points/improve:
- How often does retrieval return the best docs?
- How good is our prompt given the right docs?
Injecting knowledge
Our systems use code to decide what to do when, they use LLMs as a component in a system
We can invert this and give an LLM system "agency", ie control over what is called when - these are Agents
Agents use LLMs to make decisions including what LLMs or code to call
Typically you chain these together into a graph of Agents ("Agentic")
What's an Agent?
Let's dive into tool use
With Agents we can call functions (tools) directly, the LLM decides when it needs to do this to complete it's task
note: you don't need Agents to call tools, some LLMs support this directly, but Langchain (and others) do this and more for you
Agents and tool use
quick demo
agents and tool use
How to evaluate?
End to end
Tool use:
- how often does the LLM correctly identify the tool should be called?
- was the tool called with the correct params?
- how did the LLM do if the above are perfect?
Agents and tool use
Idea is to create a graph of agents which talk to one another to solve problems
These can be cyclic, so if the result isn't good enough it can dynamically retry
Agents typically have access to tools (eg we can build them to call KAPI) and RAG
Agentic
Agentic
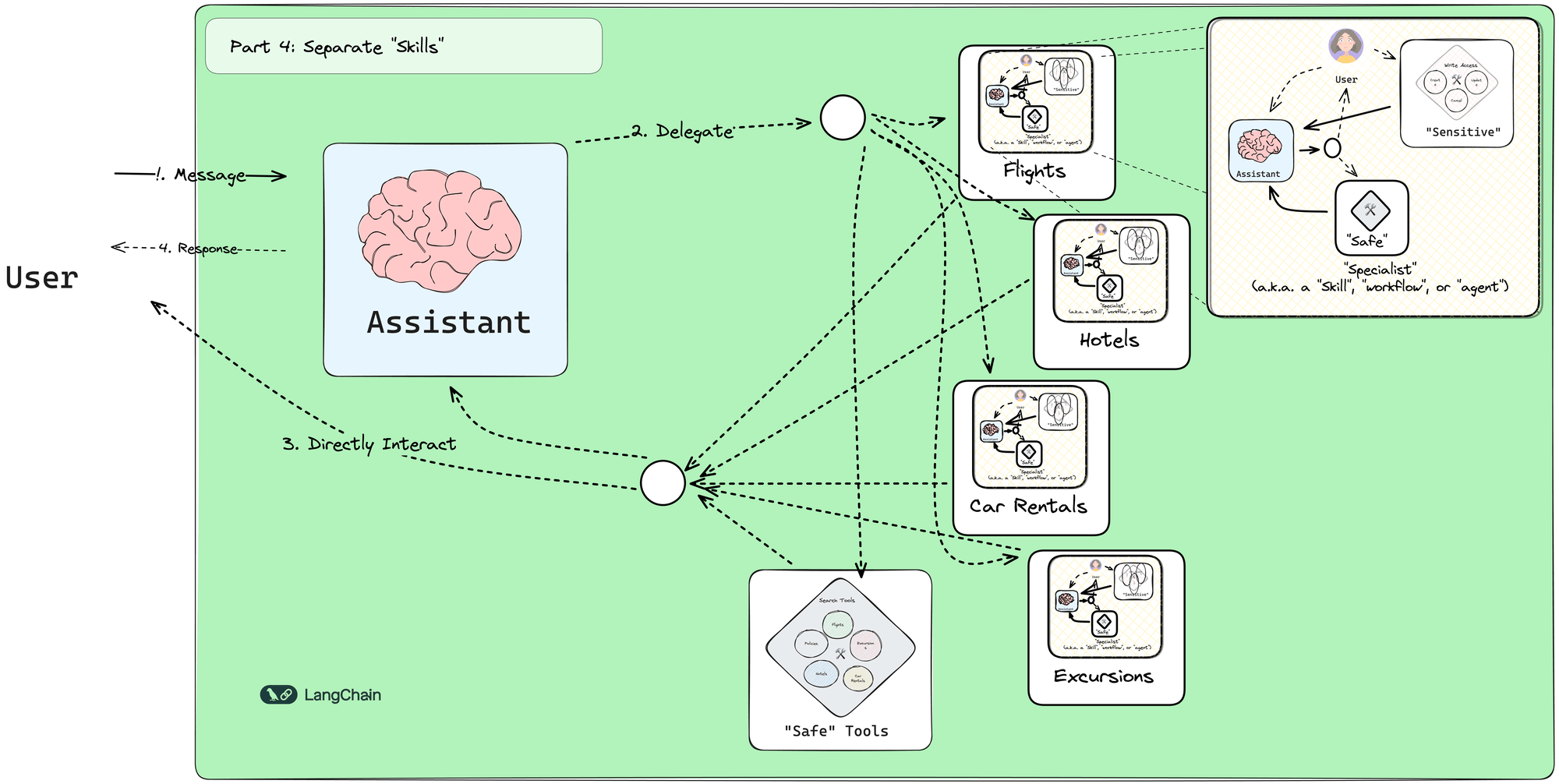
Agentic
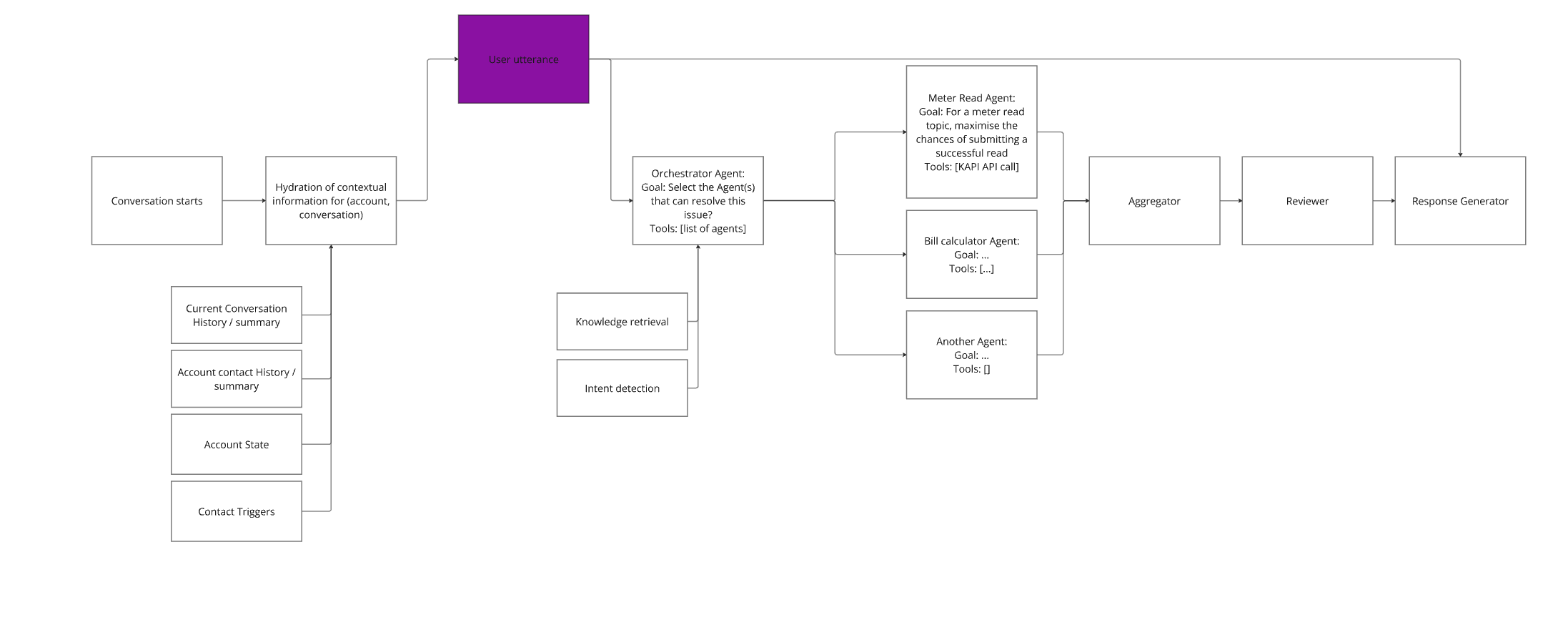
Agentic

Agentic
End to end becomes very important
- Dealing with cyclic non-deterministic graphs
- Multiple prompts, tool use, RAG, changing state
- Often dealing with multi-turn conversations
- Very hard to model individual parts offline, but can decide if end result is correct
- Often the output is highly variable
- Value/Reward models become important (input, state) -> (response, actions) -> R
- Sometimes use LLMs as a judge to approx reward models
Agents can and should be evaluated individually
Miro
Extra: When to use what when
Minimal
By Hamish dickson



