










Harvey Jhuang
Backend Engineer, Golang Developer
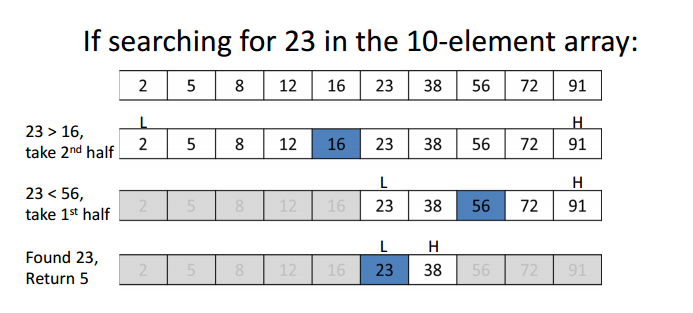
以讀取 1MB 的連續數據:
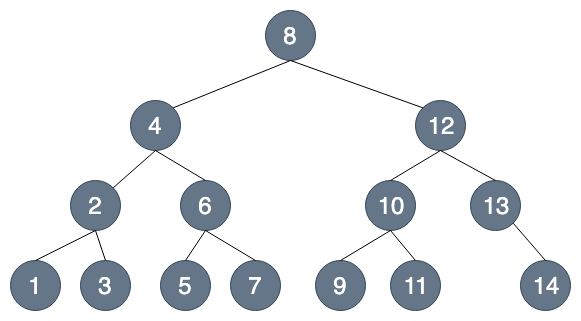
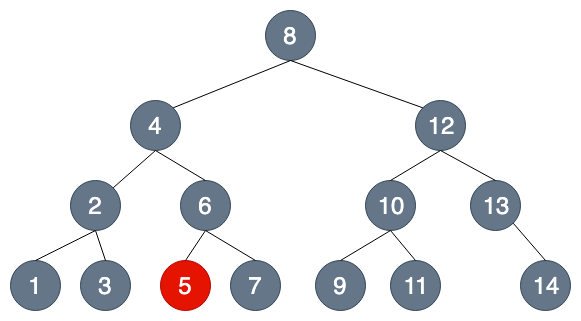
假設我們今天要找 5
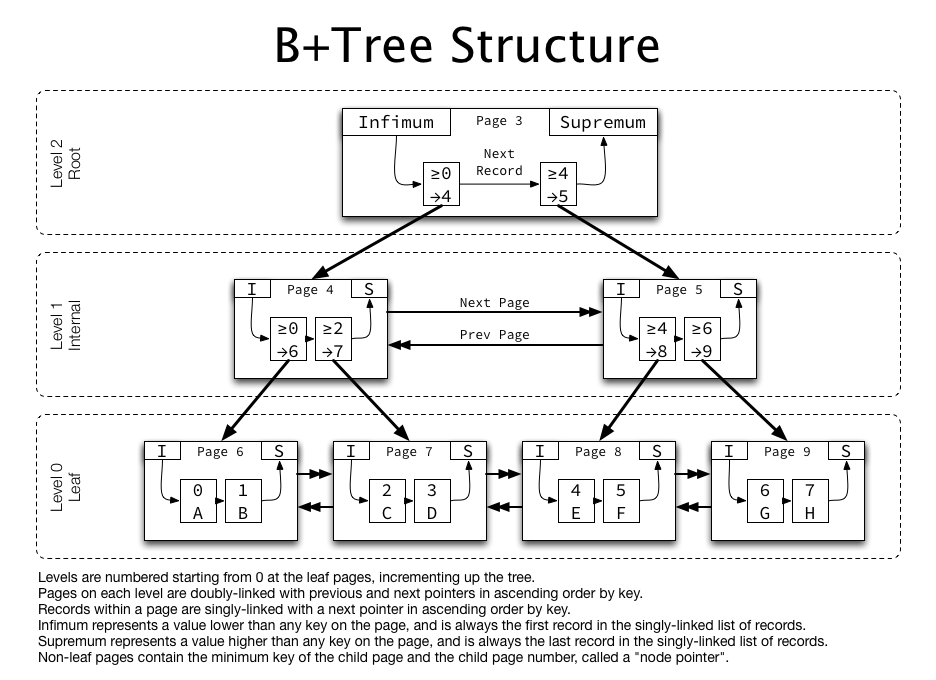
BST
B-Tree
(為方便講解,以B-Tree說明)
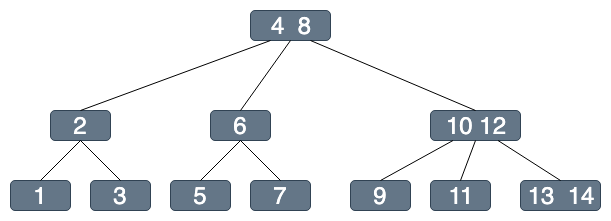
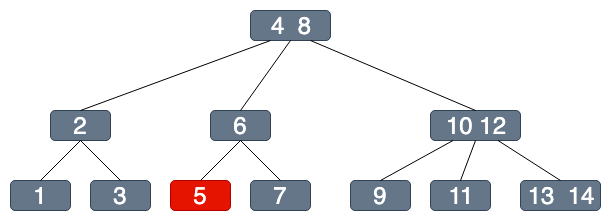
假設我們今天要找 5
BST
B-Tree
(為方便講解,以B-Tree說明)
1次IO
1次IO
假設我們今天要找 5
BST
B-Tree
(為方便講解,以B-Tree說明)
1次IO
2次IO
假設我們今天要找 5
BST
B-Tree
(為方便講解,以B-Tree說明)
2次IO
3次IO
假設我們今天要找 5
BST
B-Tree
(為方便講解,以B-Tree說明)
3次IO
4次IO
n = 1 + 2 + 4 + ... + 2^(h-1) + 2^h = 2^(h+1) - 1
h = O(log(n))
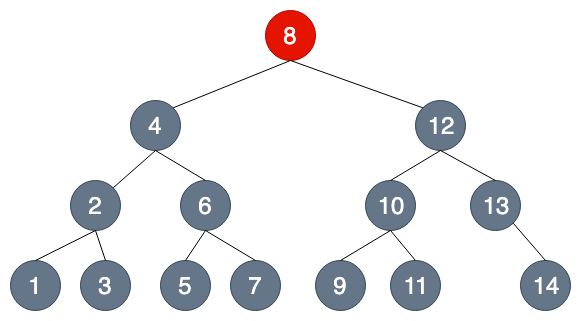
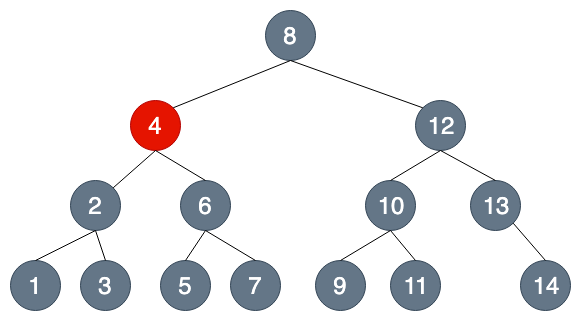
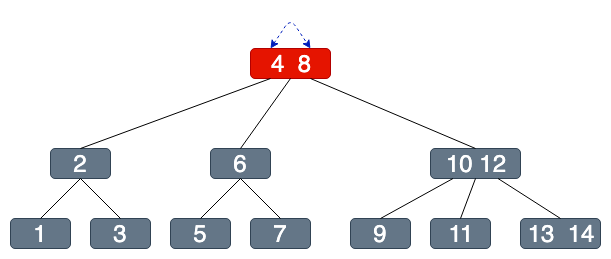
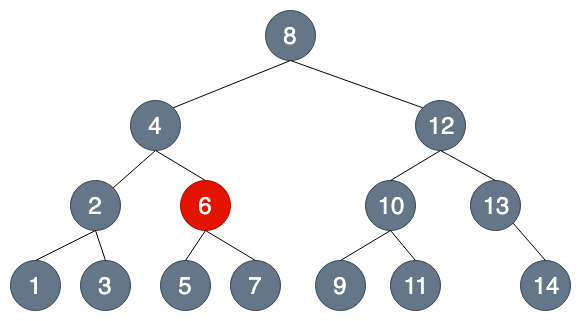
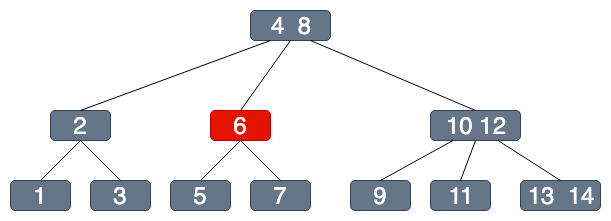
假設我們要查找7這個節點....
超級比一比:你能發現幾個不同?
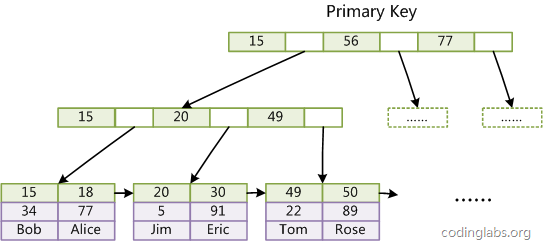
假設我們今天要找 5
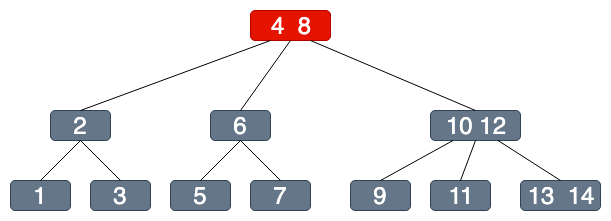
假設我們今天要找 5
1次IO+1次內存定位
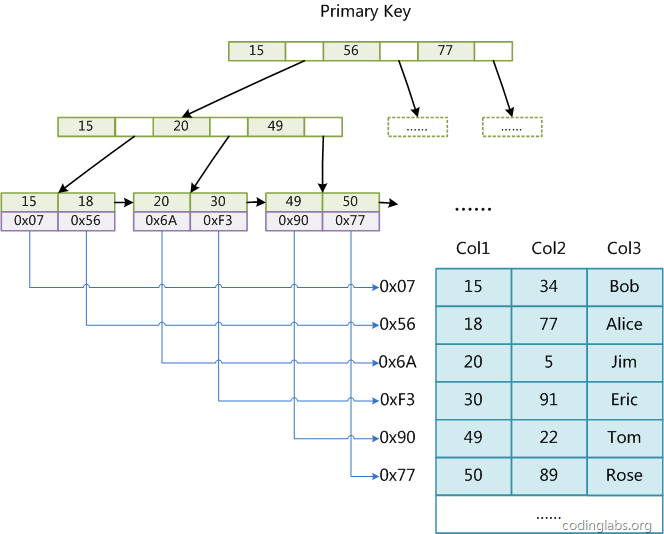
假設我們今天要找 5
2次IO+1次內存定位
假設我們今天要找 5
3次IO+1次內存定位
每增加一個 index 時~
有額外要改動的 index data page
有額外可能性因為遇上 index page lock 而需要等待/發生 deadlock
以手遊來說,目前大多支持帳號、FB、Google、Game Center 等登入方式...
假設你要設計Table的話,你會採取哪個方式?
法 2 相較 1 有以下優點:
資料庫正規化就是指把關聯式資料庫的欄位與表單做規劃,讓資料重覆性與相依性能夠降到最低。當然這個"資料重覆性與相依性能夠降到最低"情況下,還必須讓資料庫可以正常運作。
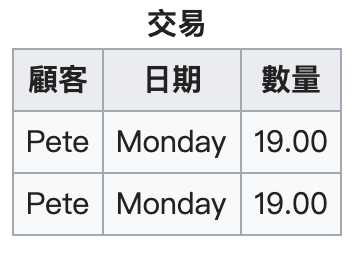
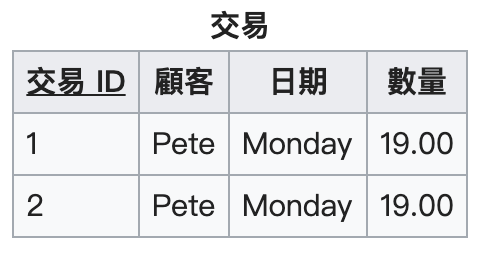
重點:去除重複資料!
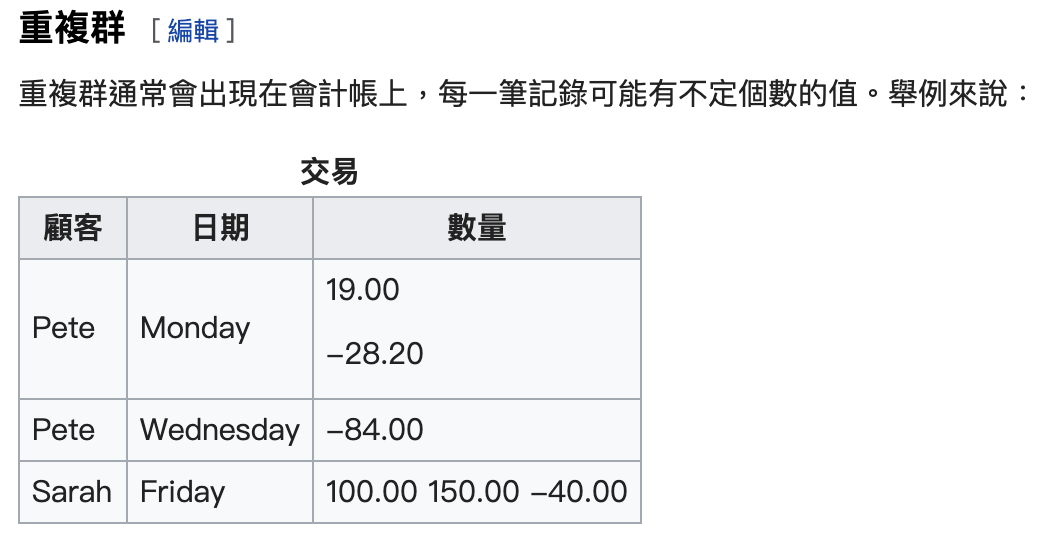
重複群通常會出現在會計帳上,每一筆記錄可能有不定個數的值。舉例來說:
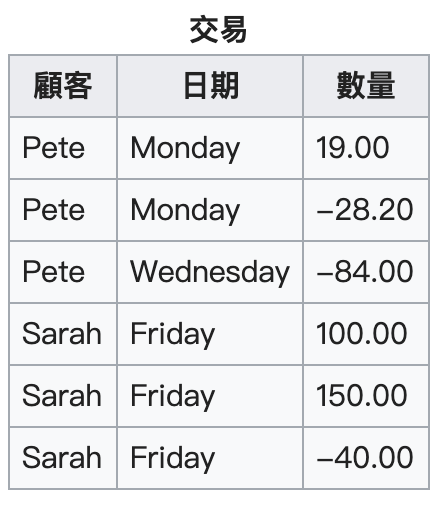
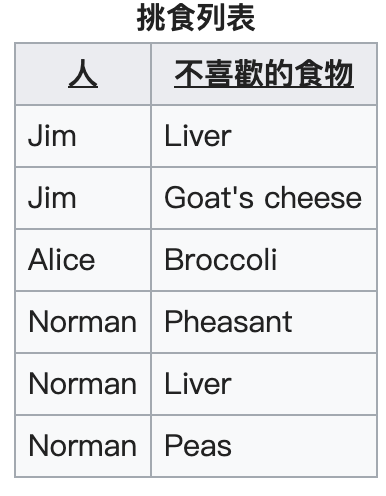
想要消除重複群的話,只要把每筆記錄都轉化為單一記錄即可:
如果是因為缺乏唯一的識別碼而違反 1NF,只需要加入一個唯一識別碼即可:
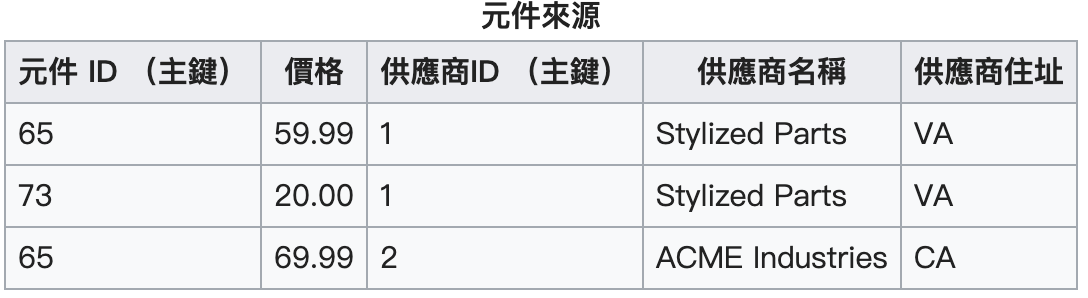
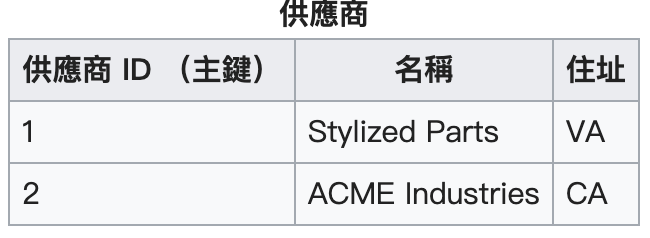
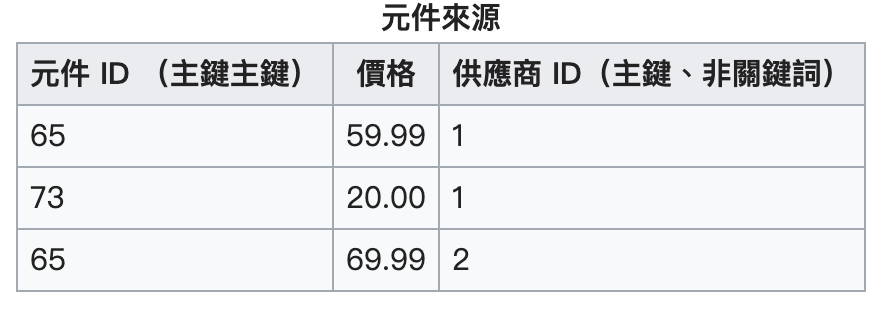
供應商的名稱和住址就只和供應商 ID 有關(部分依賴),這不符合第二正規化的原則:
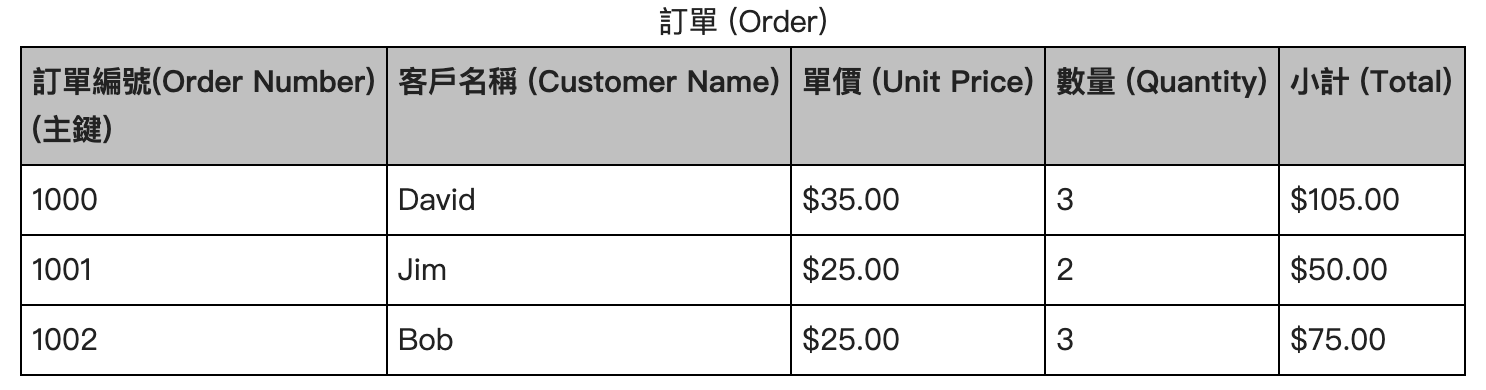
小計依賴於非主鍵欄位「單價」和「數量」,不符合第三正規化:
判別方法:系統需要知道這個 column /其他 column 的 value ,才知道具體怎去使用這個 column 的內容
| id | member | type | time |
|---|---|---|---|
| 1 | Harvey | 到職 | 20200101 |
| 2 | Matt | 出生 | 20000101 |
| 3 | Matt | 到職 | 20200101 |
WHY NOT DO THIS?
判別方法:
這個 table 內有一個叫「 type 」或是「 kind 」的 column , application 需要先知道這個 column 的值才 能決定這個 Record 怎麼使用
| id | member | type | subtype | time | amount |
|---|---|---|---|---|---|
| 1 | Harvey | 注單 | 大樂透 | 20191231 | $10 |
| 2 | Matt | 入款 | 20191231 | $10,000,000 | |
| 3 | Jimmy | 出款 | 20191231 | $10,000 |
WHY NOT DO THIS?
判別方法:
發現當修改一筆資料時,許多資料要跟著變動
當有天中港路變成台灣大道......
| Name | 縣市 | 街名 |
|---|---|---|
| 台中榮總 | 台中市 | |
| 澄清醫院 | 台中市 |
| Name | 縣市 | 街名 |
|---|---|---|
| 銀櫃 | 台中市 | |
| 好樂迪 | 台中市 |
台灣大道
比較好的作法可能是
| Name | 縣市 | 街名ID |
|---|---|---|
| 台中榮總 | 台中市 | 1 |
| 澄清醫院 | 台中市 | 1 |
| Name | 縣市 | 街名ID |
|---|---|---|
| 銀櫃 | 台中市 | 1 |
| 好樂迪 | 台中市 | 1 |
台灣大道
| ID | Name |
|---|---|
| 1 | |
| 2 | 公益路 |
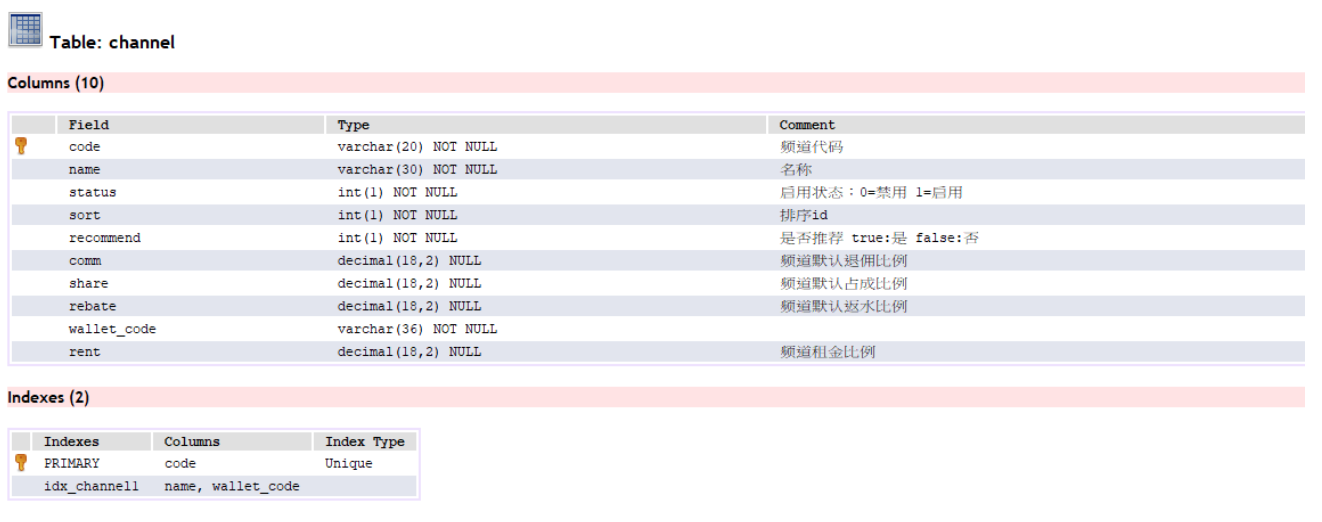
判別:當一個表的欄位過多的時候
| 訂單號 | 會員 | 產品 | 聯絡電話 | 寄件地址 | 聯絡地址 | 價格 | 數量 |
|---|---|---|---|---|---|---|---|
| 1 | Harvey | OO | 6666666 | Taipei | Tainan | 10 | 10 |
| 2 | Matt | XXX | 7777777 | Tainan | Taipei | 1 | 8 |
判別:
解決:水平或垂直分表
目的:改善效能
判別:
缺點:
判別:
建議:
提早規劃優化流程,避免造成無法挽回的傷害
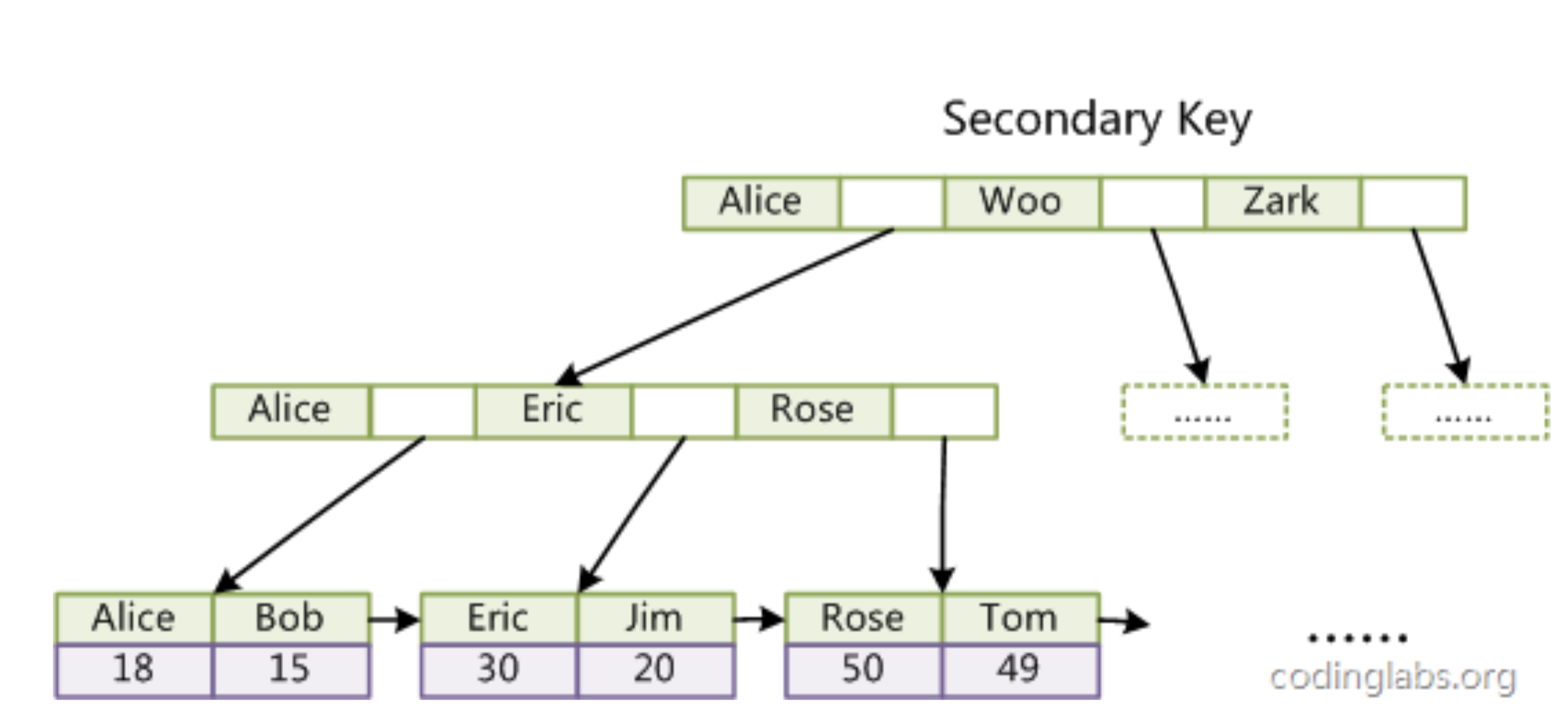
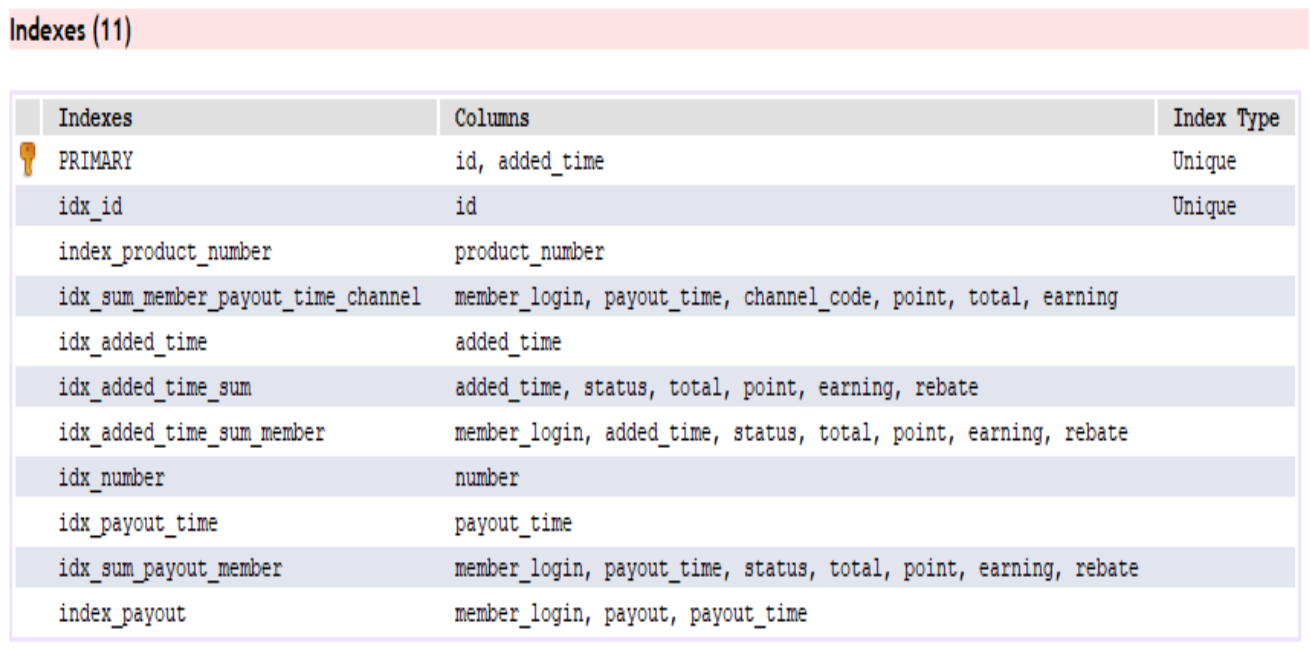
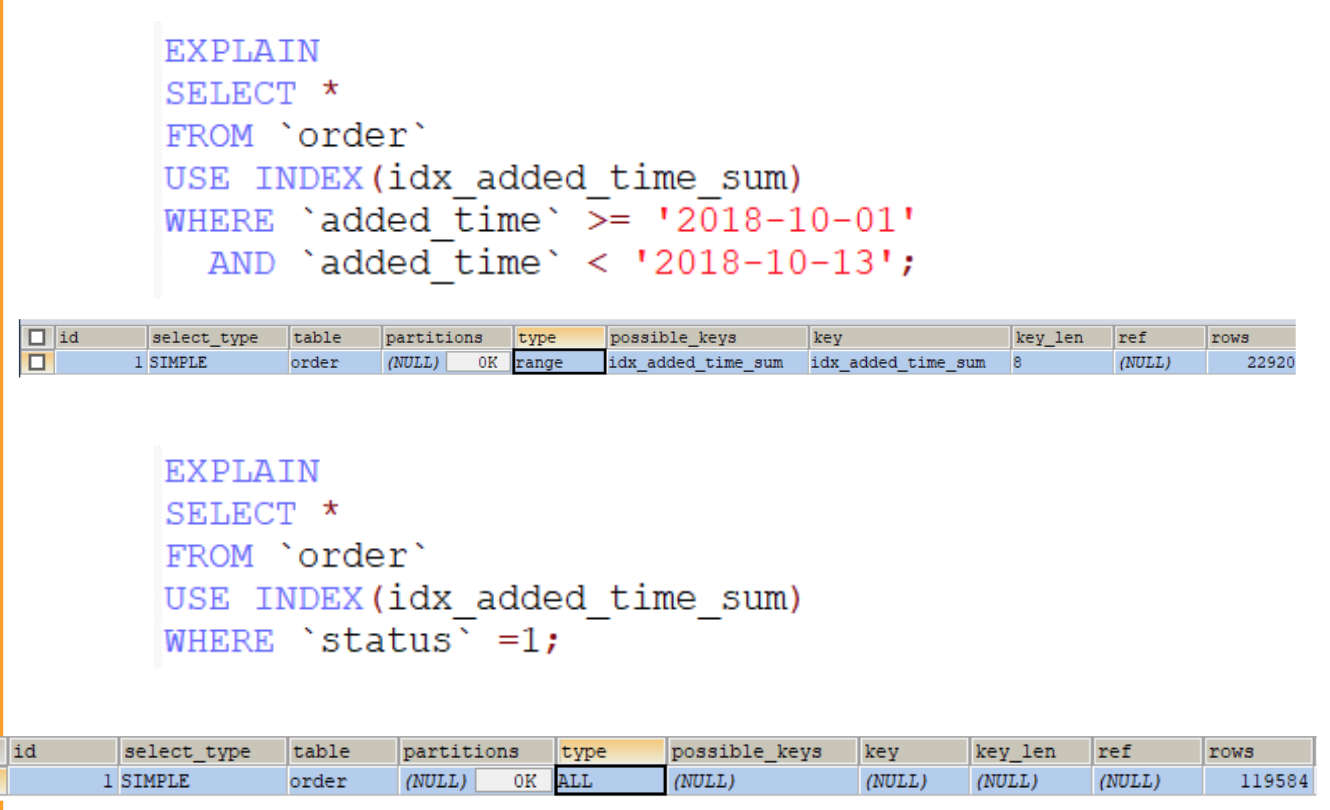
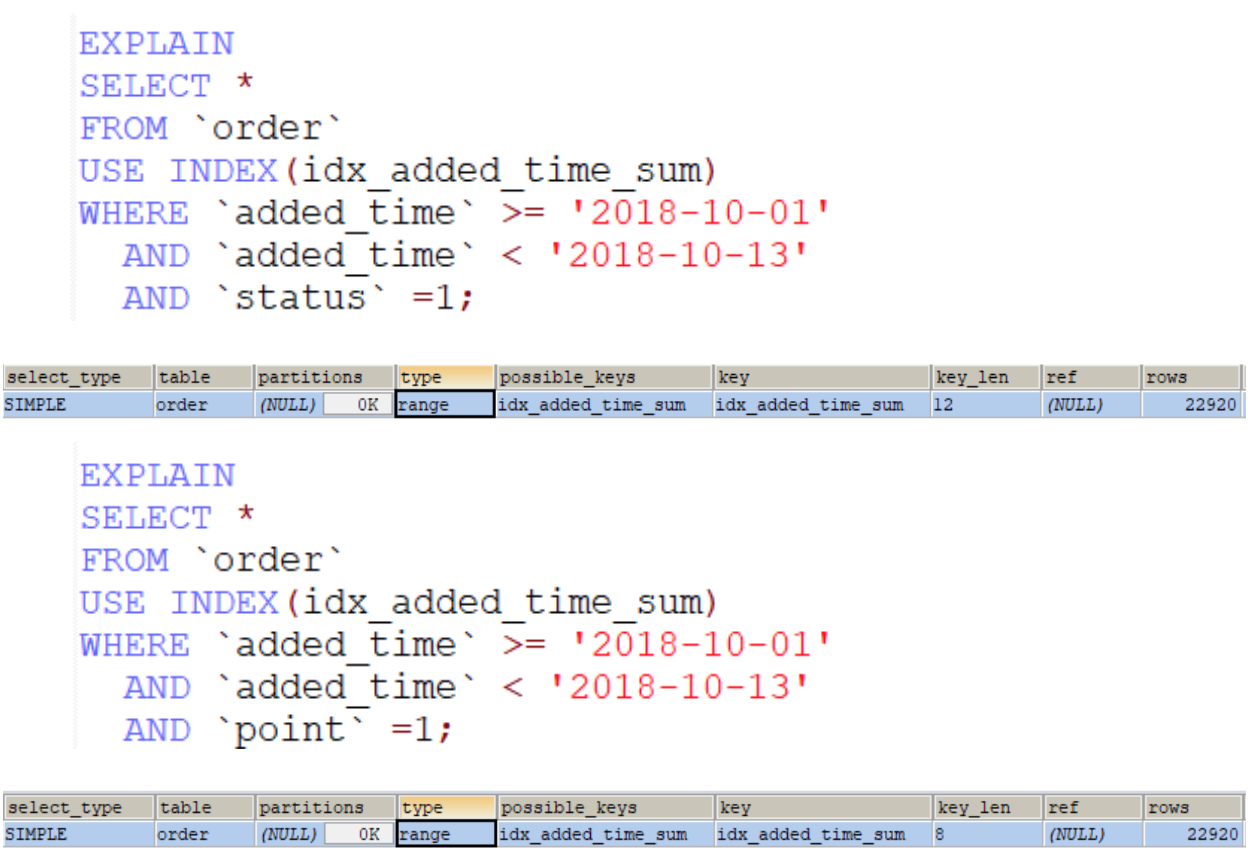
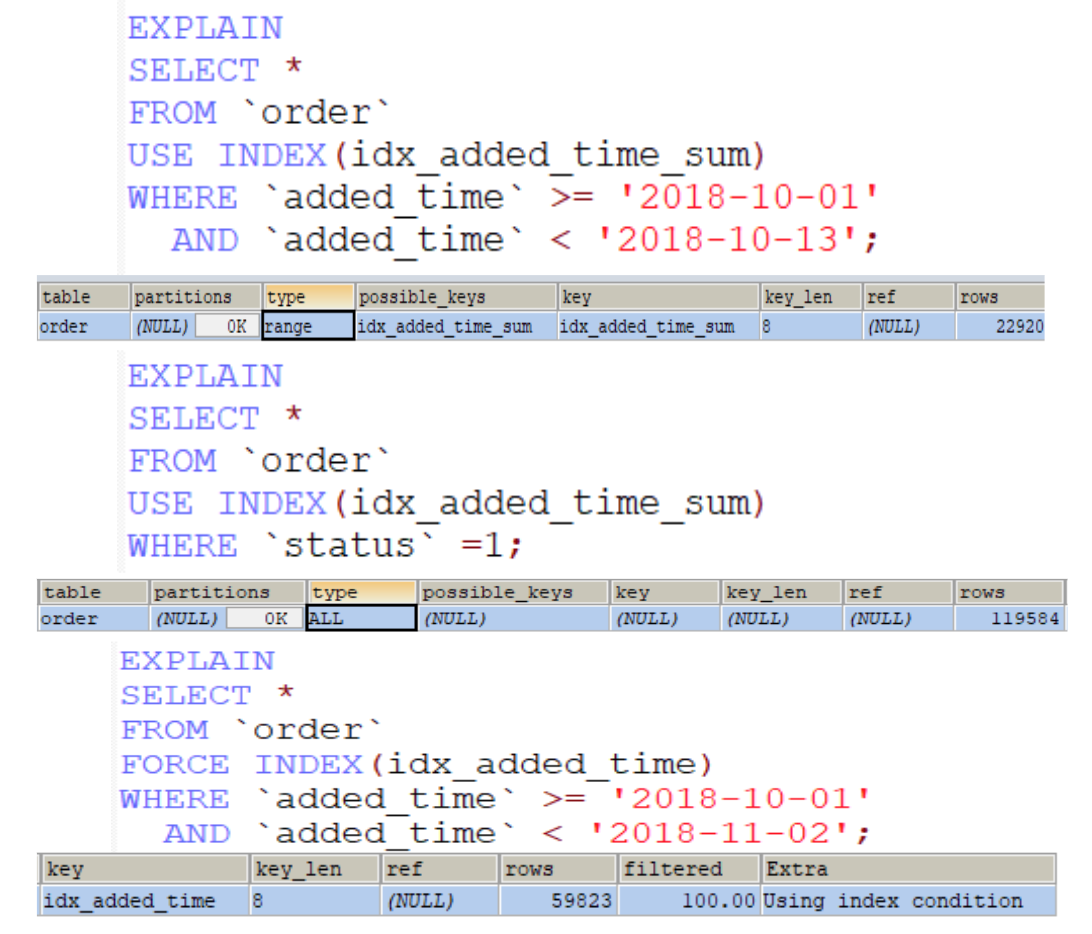
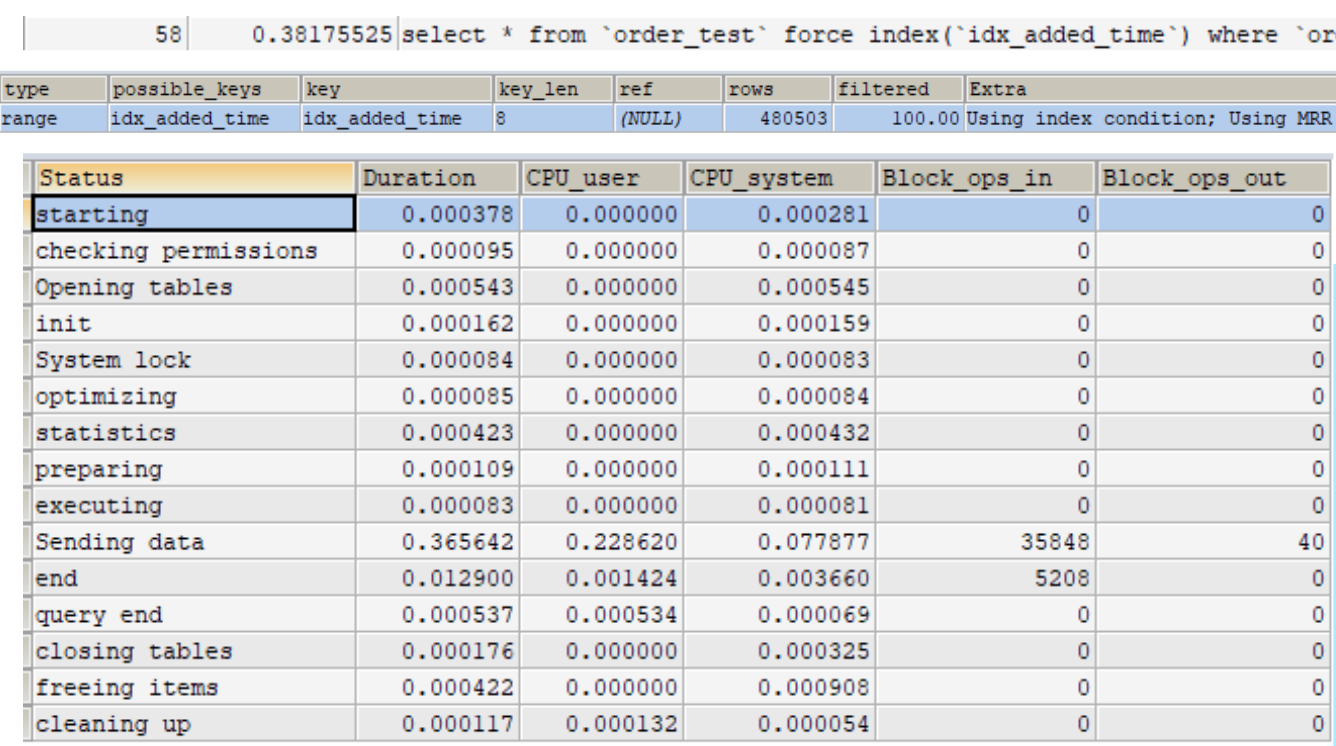
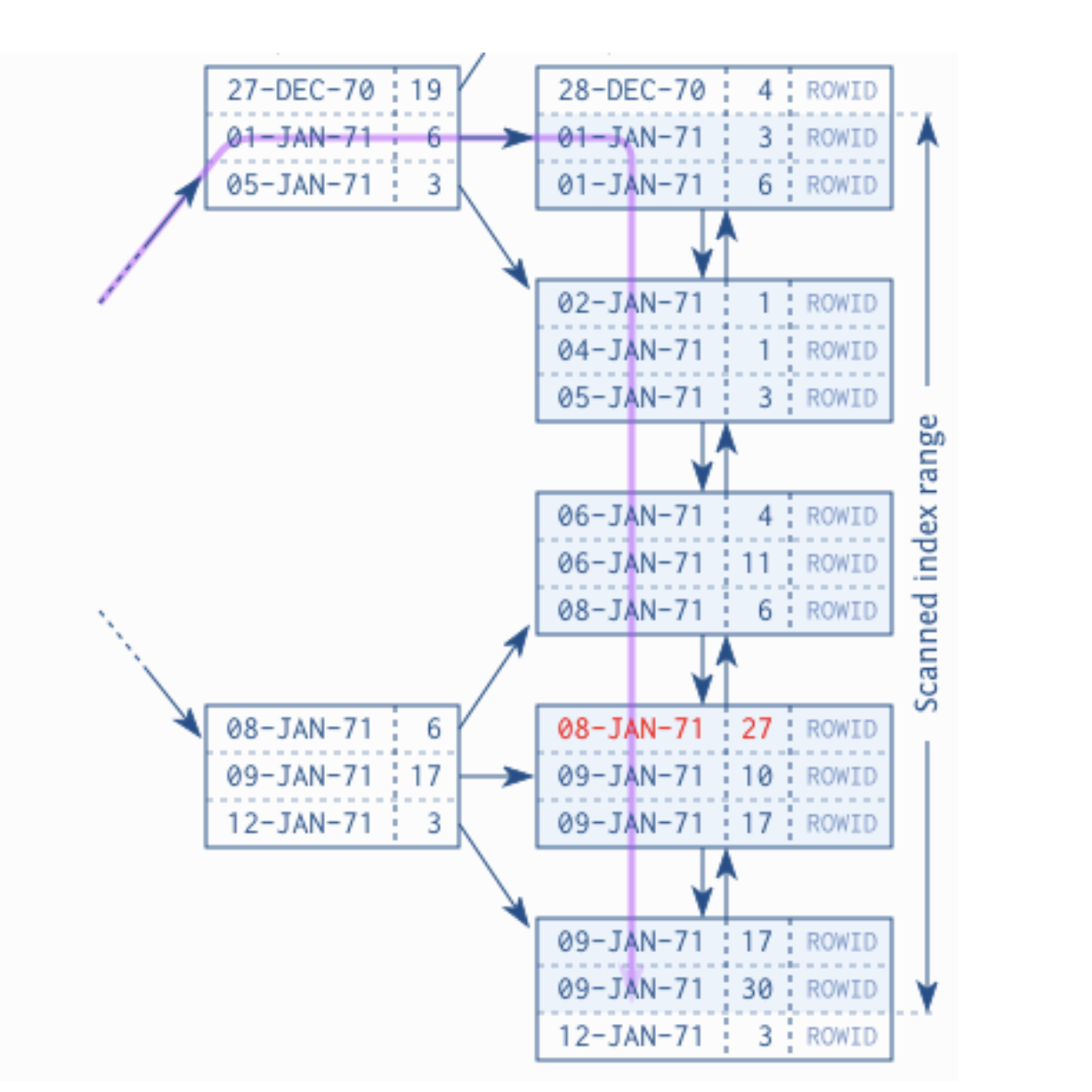
由前面的例子就會發現索引有 leftmost prefixes 的特性,因此考量使用場景,下面的索引只有約一半有用
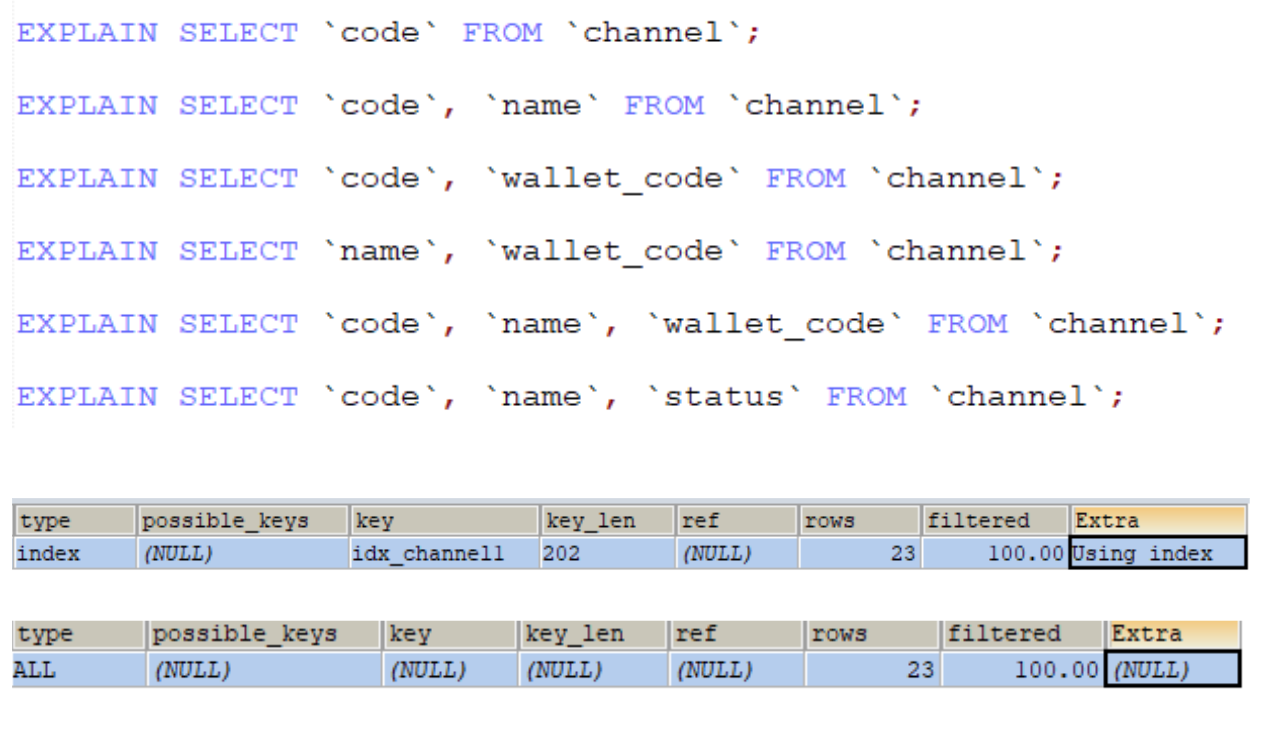
覆蓋索引即從索引中就可以拿到所有資訊
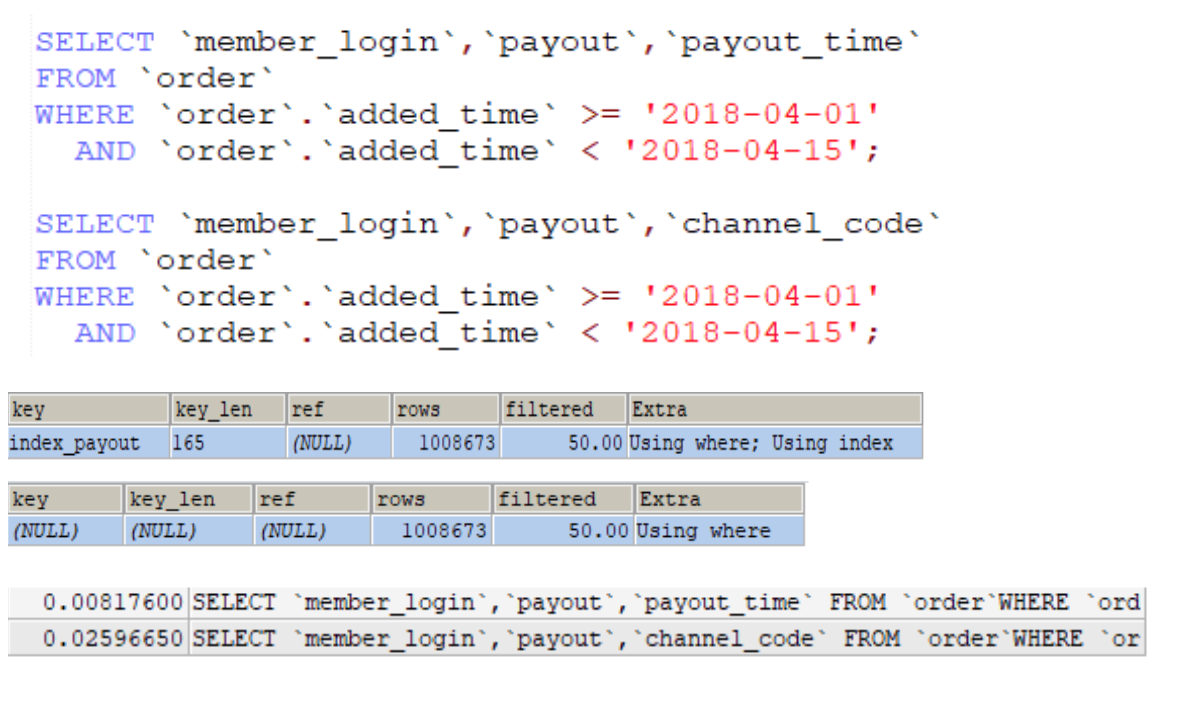
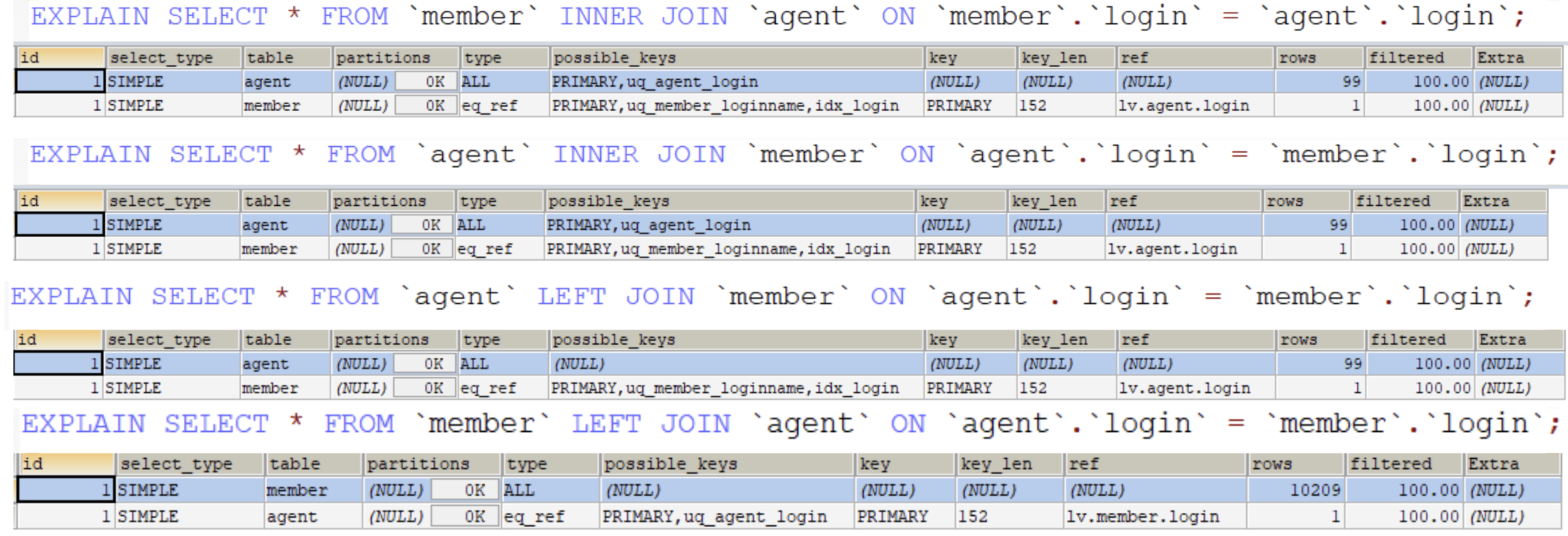
猜猜看哪一種查詢會對應到哪一個結果?
ICP 優化,取出索引同時會判斷是否可進行 where 條件過濾
原則:盡可能小、有序
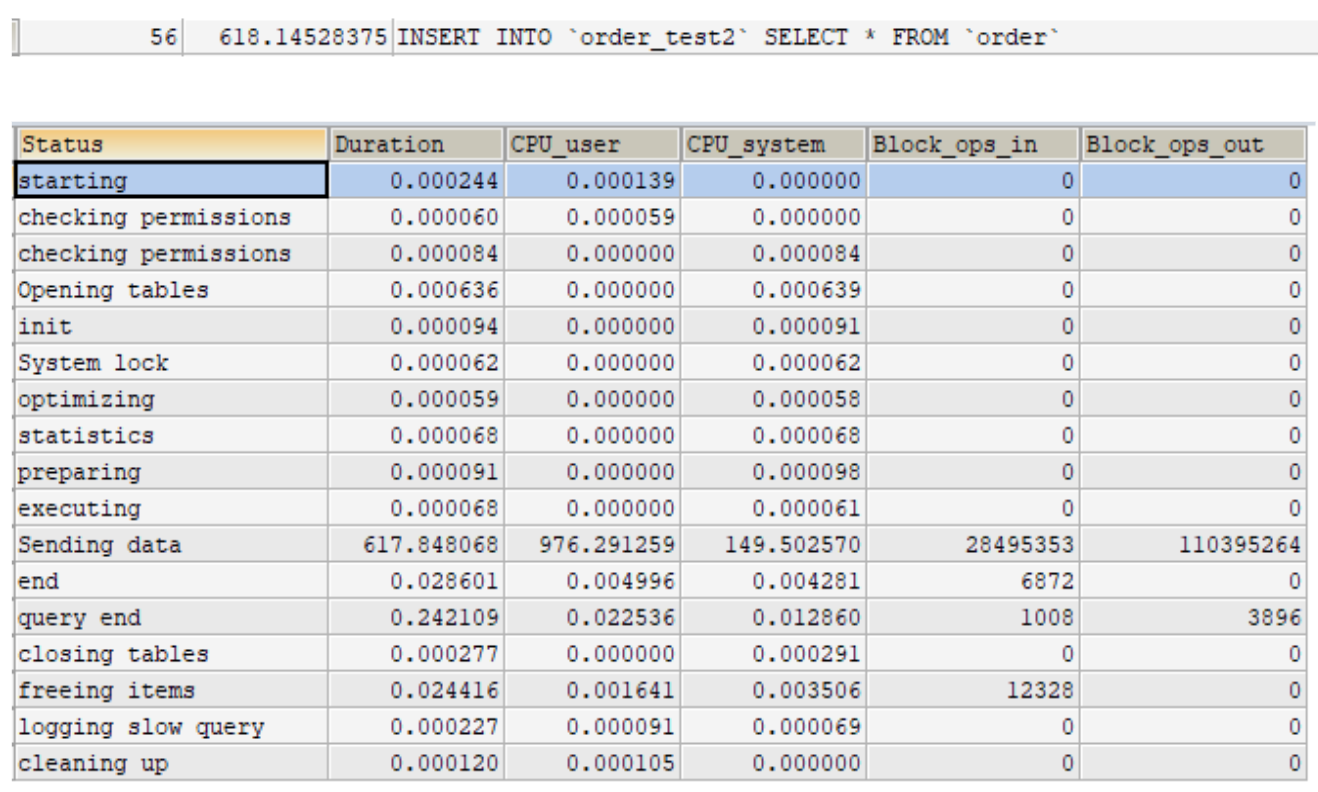
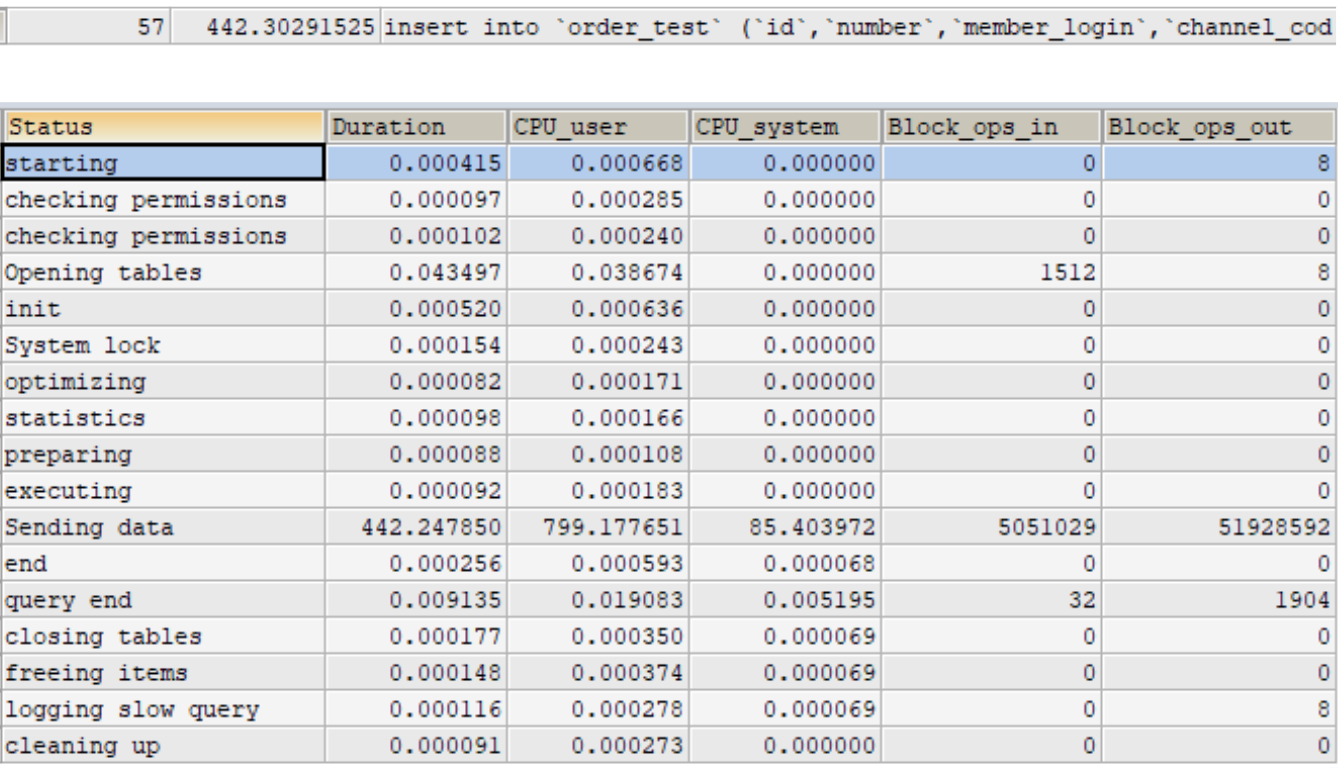
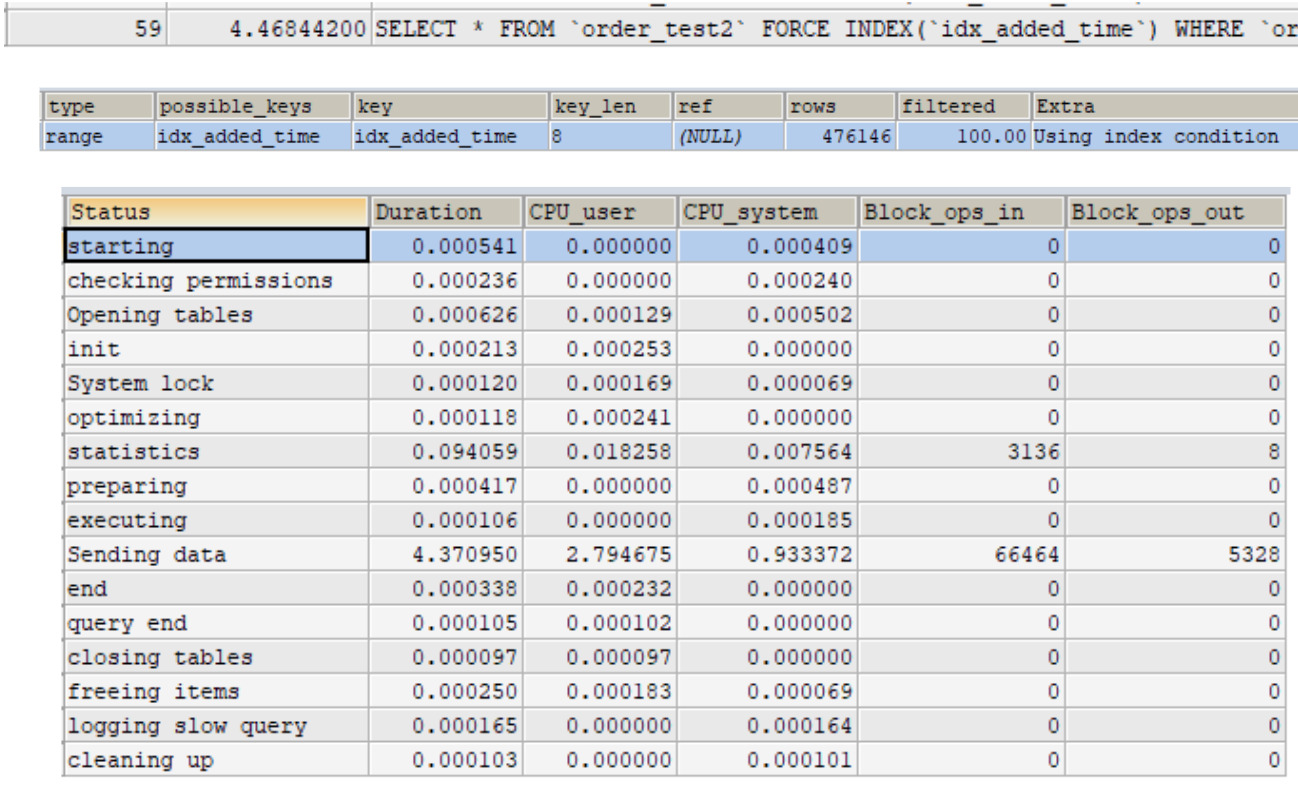
版本:PK非遞增且佔用空間大 操作:寫入資料
版本:PK遞增且佔用空間小 操作:寫入資料
版本:PK非遞增且佔用空間大 操作:查詢資料
版本:PK遞增且佔用空間小 操作:查詢資料
PS: 搜尋範圍包含資料數佔整體資料筆數的權重很高時,execution plan optimizer會選擇全表查詢
By Harvey Jhuang
簡述MySQL索引原理,並且如何利用這些特性優化系統



