{Modelagem de Estruturas NoSQL}
O mundo moderno de armazenamento de dados.
- Mestre em Ciências da Computação (UEM)
- Bacharel em Informática (UEM)
- Diretor de projetos de Dados na Mentorstec
- 11 anos na área de sistemas/software
- 5 anos na área de dados
- 3 ano com liderança técnica.
- Professor na Graduação e Pós na Unicesumar
- Palestrante no Pentaho Day 2019, After Data, cerveja com Dados, NPD UEM, Serpro e UNESPAR.
- Entusiasta cultural de Ciências de Dados, Engenharia de Dados, Arquitetura de software, boas práticas e Ágil
Henrique Vignando

- Quem quer ser um cientista de dados?
Vocês

1
Introdução,
Modelos de dados Agregados, Modelos de Distribuição, consistência, marcadores de versão, map reduce
2
Banco de dados de Documentos
3
Banco de dados de Chave Valor
4
Armazenamentos em Família e Coluna
Atividades Práticas supervisionadas (APS)
5
Banco de dados de Grafos
6
Migração de Esquemas, Persistência Poliglota
APS RHtech
Você acaba de ser contrato por uma StartUp de RH, as RHtech, (ex. Vulpi, Gupy, etc...). Você será responsável por toda a Governança de Dados do aplicativo/sistema.
- Como modelar os dados deste app/sistema?
- Como os dados serão inseridos e recuperados?
- Onde estarão dados (nuvem)?
- O que podemos fazer depois?
- O modelo de dados relacional é o melhor para todos os cenários de dados?
APS RHtech
Temos que desenvolver uma app para a StartUp que possa gerar, armazenar e recuperar dados de forma performática:
- Relatório de ponto por colaborador
- Manter versões de contrato dos colaboradores
- Criar modelo de rede social de colaboradores "um colaborador pode seguir outro"
- Modelagem OLAP de fatos e dimensões para o Data Warehouse da app
O Problema do Modelo Relacional
Alto volume de consultas (leitura do dados)
Alto volume de dados
Manutenção das alterações de dados
Rigidez e burocracia no modelo relacional
Imcompatibilidade de Impedância
1.
2.
Novos desafios
Advento da internet
"Ataque dos clusters"
Crescimento dos indicadores de negócio (KPI) e Data Warehouse
Arquitetura Micro Serviços
3.
No SQL é "Not Only SQL"
Manifesto "precisamos atender a novas necessidades e novos modelos deaplicações, devemos possuir novas formas de armazenar os dados"
No começo, a sigla era interpretada como 'No SQL' (Não SQL, em inglês). Era um movimento contrário à utilização de um RDBMS.
Não suporta operações de Joins
# 1 - Introdução
Introdução
- Principais modelos de dados NoSQL
- Documento
- Grafo
- Chave-valor
- Colunar
- Pricipais diferenças do modelo relacional
- O Teorema CAP
- Modelos Relacionais versus NoSQL
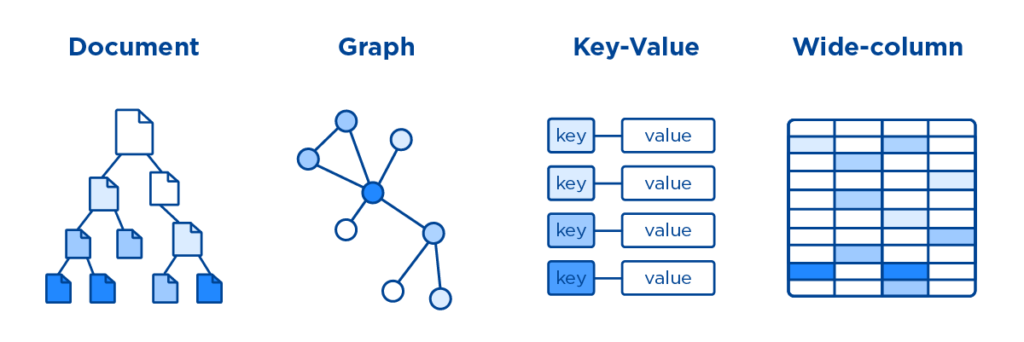
# 1 - Introdução
- Cada registro fica armazenado em uma coleção especifica mas dentro de uma colação, não existe um equema fixo apara o registros;
- Os dados e os metadados são armazenados hierarquicamente em documentos baseados em JSON no banco de dados.
Exemplo: Nota fiscal
# 1 - Introdução
- Os registros são nós em um grafo interligados por relacionamentos (arestas);
- Os dados são armazenados em uma estrutura de grafo como propriedades de nó, borda e dados.
Exemplo: Rede Social
# 1 - Introdução
- Todos os registros fazem parte da mesma coleção de elementos, e a unica coisa que todos eles tem em comun é uma chave unica;
- O mais simples dos bancos de dados NoSQL, que são representados como uma coleção de pares chave-valor.
Exemplo: Log de sistema
# 1 - Introdução
- Todos os registros fazem parte de da mesma tabela, mas cada um deles pode ter colunas diferentes;
- Os dados relacionados são armazenados como um conjunto de pares de valor/chave aninhados em uma única coluna.
Exemplo: Corridas do "Uber"
# 1 - Introdução
-
O teorema afirma que os sistemas de dados distribuídos oferecerão uma compensação entre consistência, disponibilidade e tolerância à partição. E que qualquer banco de dados só pode garantir duas das três propriedades
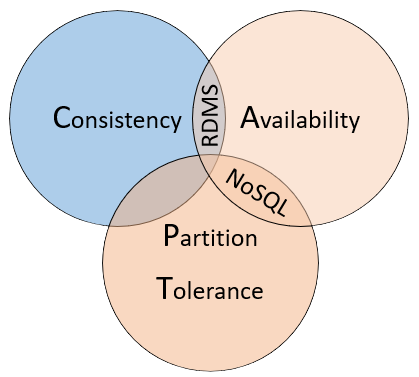
O Teorema CAP
# 1 - Introdução
Disponibilidade
- Cada nó retorna uma resposta imediata, mesmo que essa resposta não seja os dados mais recentes. Se você consultar um "sistema disponível" para um item que está sendo atualizado, obterá a melhor resposta possível que o serviço pode fornecer nesse momento.
O Teorema CAP
# 1 - Introdução
Tolerância a partições
- Garante que o sistema continue operando mesmo que um nó de dados replicado falhe ou perca a conectividade com outros nós de dados replicados.
O Teorema CAP
# 1 - Introdução
Modelos Relacionais versus NoSQL
| Considere um armazenamento de dados NoSQL quando: | Considere um banco de dados relacional quando: |
|---|---|
| Você tem cargas de trabalho de alto volume que exigem latência previsível em grande escala (por exemplo, latência medida em milissegundos ao executar milhões de transações por segundo) | O volume de carga de trabalho geralmente se ajusta a milhares de transações por segundo |
| Seus dados são dinâmicos e frequentemente são alterados | Seus dados são altamente estruturados e exigem integridade referencial |
| As relações podem ser modelos de dados des normalizados | As relações são expressas por meio de junções de tabela em modelos de dados normalizados |
| A recuperação de dados é simples e expressa sem junções de tabela | Você trabalha com consultas e relatórios complexos |
| Os dados normalmente são replicados entre geografias e exigem um controle mais fino sobre consistência, disponibilidade e desempenho | Os dados normalmente são centralizados ou podem ser replicados de forma assíncrona |
| Seu aplicativo será implantado no hardware de mercadoria, como com nuvens públicas | Seu aplicativo será implantado em hardware grande e high-end |
# 1 - Introdução
Apresente uma implementação para cada tipo de aplicação de banco de dados NoSQL no contexto da StartUp RHTech.
# 1 - Introdução
APS RHtech
APS01 - Quais modelo de dados do projeto RHTech podemos aplicar sobre os quatros principais tipos de NoSQL.
- Key-Value
- Relatório de ponto por colaborador
- Document
- Manter versões de contrato dos colaboradores
- Grafo
- Rede social de colaboradores "um colaborador pode seguir outro" e classificar em estrelas
- Colunar
- Modelagem OLAP, Data Warehouse para fatos de folha de pagamento
RHTech
Modelos de dados Agregados, Modelos de Distribuição, consistência, marcadores de versão, map reduce
- Modelagem de dados Agregado
- visão dos modelos chave-valor, documentos e familia de colunas
- Modelo de Distribuição
- conceitos de computação distribuida
- Consistencia, Marcadores e Map Reduce
- uma visão geral
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Limitação do modelo relacional
- Uma tupla é uma estrutura de dados limitada, ela captura um conjunto de valores, de modo que não é possivel aninhar uma dentro da outra para obter registros aninhados nem é possível colocar uma lista de valores ou tuplas dentro de uma ou de outra.
Modelagem de dados Agregado
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Uma abordagem diferente
- Desejamos trabalhar com dados na forma de unidades que tenham uma estrutura mais complexa do que um conjunto de tupla. Por exemplo, um registro complexo pode permitir que listas e outras estruturas de dados sejam aninhadas dentro dele.
- O termo modelagem agregada vem de uma definição do Domain-Driven Design (Projeto Orientado a Domínios), pois nele, um agregado é um conjuto de objetos relacionados que desejamos tratar como uma unidade
Modelagem de dados Agregado
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Modelagem de dados Agregado
Exemplo: comercio eletronico
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Vamos supor que temos que construir um site de comércio eletrônico;
- vender itens pela web
- armazenar dados sobre usuários, catálogo de produtos, pedidos, endereços de entrega, endereços de cobrança e dados de pagamento.
Podemos modelar os dados usando um armazenamento de dados de relacional ou armazenamentos de dados NoSQL
Trataremos seus prós e contras.
Modelagem de dados Agregado
Exemplo: comercio eletronico
# 1 - Modelos de dados Agregados, Modelos de Distribuição
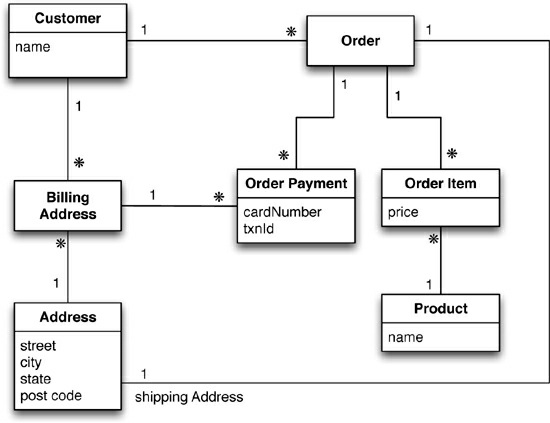
Modelagem Relacional
Modelagem de dados Agregado
Exemplo: comercio eletronico
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Um exemplo de povoamento.
Veja esta tudo normalizado
- Integridade referencial
- não há repetição de dados
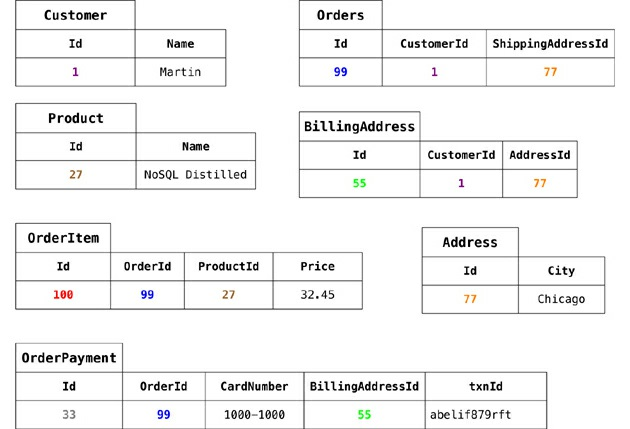
Modelagem de dados Agregado
Exemplo: comercio eletronico
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Modelo NoSQL
Aqui temos
2 agragados
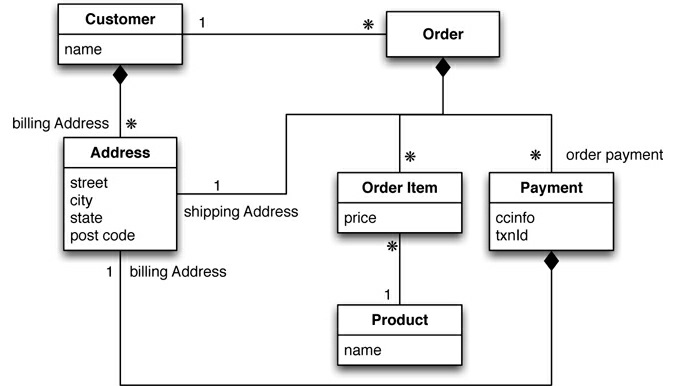
Modelagem de dados Agregado
Exemplo: comercio eletronico
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Um exemplo de povoamento.
- Endereços duplicados
- Relacionamento entre agregados
- Desnormalização (nome do produto)
- "Nova forma de pensar" a modelagem de dados
// in customers
{
"id": 1,
"name": "Martin",
"billingAddress": [
{
"city": "Chicago"
}
]
}
// in orders
{
"id": 99,
"customerId": 1,
"orderItems": [
{
"productId": 27,
"price": 32.45,
"productName": "NoSQL Distilled"
}
],
"shippingAddress": [
{
"city": "Chicago"
}
]
"orderPayment": [
{
"ccinfo": "1000-1000-1000-1000",
"txnId": "abelif879rft",
"billingAddress": {
"city": "Chicago"
}
}
],
}Modelagem de dados Agregado
Consequencia da orientação a agregados
# 1 - Modelos de dados Agregados, Modelos de Distribuição
-
Degradação na performance
- Vejamos o sequinte cenário:
- Para obter o histórico das vendas do produto, será necessårio pesquisar cada agregado do banco de dados separadamente. -
- Vejamos o sequinte cenário:
- Clustering
- O principal motivo para a orientaçao a agregados é que ela calmente auxilia a execução em um cluster. Segregação das consultas
- Transações ACID
- pricipalemente as atomicas x insert em várias tabelas do banco
Modelagem de dados Agregado
Pontos importamtes
# 1 - Modelos de dados Agregados, Modelos de Distribuição
- Um agregado é um conjunto de dados como qual interagimos como uma unidade. Agregados formam os limites de operações ACID com o banco de dados.
- Os agregados facilitam, para o banco de dados, o gerenciamento do armazenamento de dados em clusters.
- Bancos de dados orientados a agregados funcionam melhor quando a maioria da interação com os dados é realizada no mesmo agregado
Modelo de Distribuição
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Modelo de Distribuição
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Beneficios
- Lidar com quantidade maior de dados
- Processar um trafego maior de leitura e gravação
- Disponibilidade
- Recuperação à falhas - resiliência
Modelos de implantação
- Fragmentação
- Replicação
Modelo de Distribuição
Fragmentação
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Um armazenamento de dados pode ficar muito ocupado, pois várias pessoas estão acessando partes diferentes do conjunto dos dados.
Nessas circunstâncias a fragamentação (sharding), dÁ suporte a escalabilidade horizontal, colocando partes diferentes dos dados em servidores diferentes.
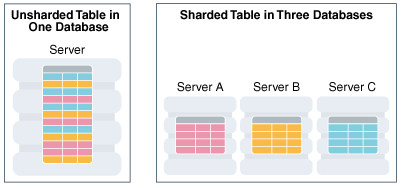
Modelo de Distribuição
Fragmentação
# 1 - Modelos de dados Agregados, Modelos de Distribuição
- Muitos bancos de dados NoSQL oferecem a autofragmentação, em que o banco de dados fhca responsável por alocar os dados nos fragmentos e por assegurar-se de que o acesso aos dados vá para o fragmento correto
- A fragmentação vem resolver o problema de pertormance, pois
pode melhorar o desempenho de leitura e gravaçāo. principalmente por fornecer uma maneira de ampliar horizontalmente as gravações. - Quando os recursos computacionais forem suficientes para aplicar a fragmentação, use antes de precisar dela.
Modelo de Distribuição
Replicação Mestre-escravo
# 1 - Modelos de dados Agregados, Modelos de Distribuição
- Nesse modelo podemos replica os dados em múltiplos nodos.
- Um nodo é designado como o mestre, ou primário, o qual é a fonte oficial dos dados e, geralmente, fica responsável por processar e atualizar os dados.
- Os outros nodos são escravos, ou secundários.
- Os dados são replicados do mestre para os escravos. O mestre serve a todasas gravações; as leituras podem vir do mestre ou dos escravos.
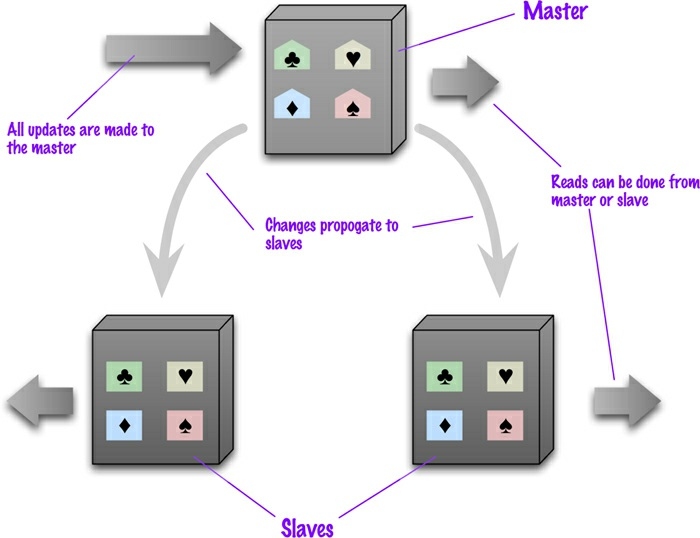
# 1 - Modelos de dados Agregados, Modelos de Distribuição
- Outra vantagem da replicação é a resiliência de leitura: se o mestre talhar, os escravos ainda podem lidar com as solicitações de leitura. Novamente, isso é útil se a maioria de seus acessos aos dados for para leitura.
- A falha no mestre elimina a capacidade de lidar com gravações até que ele seja restaurado ou que um novo mestre seja designado.
- Entretanto, ter escravos como replicações do mestre acelera a recuperação após uma falha, já que um escravo pode ser designado como um novo mestre muito rapidamente.
Modelo de Distribuição
Replicação Mestre-escravo
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Ponto de Atenção
- Areplicação traz ponto negativo inevitável - a inconsistência.
- O risco é que clientes diferentes, lendo diterentes escravos, vejam valores diferentes, pois as alterações nāo foram todas propagadas para os escravos.
- No pior caso, isso significa que um cliente não conseguirá ler uma gravação que acabou de fazer.
- Mesmo que utilize a replicação apenas para a cópia de segurança ativa, isso pode ser um problema, pois, se o mestre falhar, quaisquer atualizações que não tenham sido transmitidas para a cópia de segurança estarão perdidas.
Modelo de Distribuição
Replicação Mestre-escravo
# 1 - Modelos de dados Agregados, Modelos de Distribuição
Problema:
- A replicação mestre-escravo ajuda com a escalabilidade de leitura, mas
- não com a escalabilidade de gravação.
- Ela fornece resiliência contra a falha de um escravo, mas não de um mestre, o mestre ainda é um gargalo e um ponto único de falha.
Modelo de Distribuição
Replicação Mestre-escravo
Modelo de Distribuição
Replicação Ponto a ponto (P2P)
# 1 - Modelos de dados Agregados, Modelos de Distribuição
- A replicação ponto a ponto combate esses problemas, pois não tem um mestre.
- Todas as réplicas têm peso igual, todas podem receber gravações e a perda de alguma delas não impede o acesso ao armazenamento de dados.
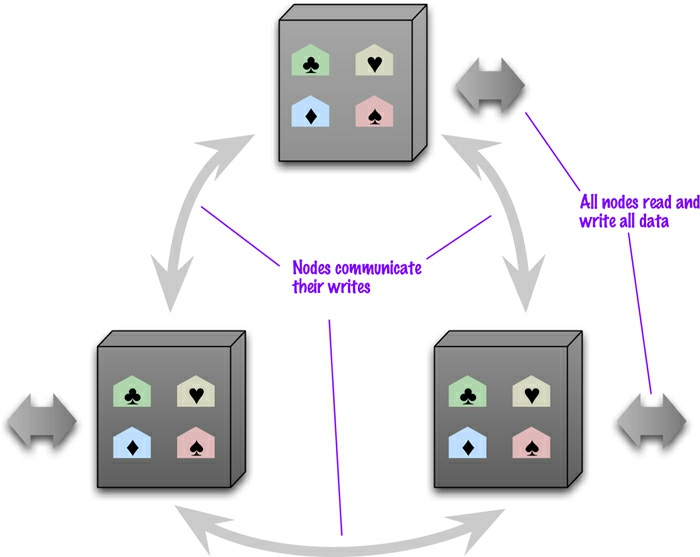
Consistência
Visão Geral
# 1 - Modelos de dados Agregados, Modelos de Distribuição
- Problema escrita-escrita
- Conflitos de gravação ocorrem quando dois clientes tentam gravar os mesmos dados ao mesmo tempo.
- Conflitos de leitura-gravação ocorrem quando um cliente lê dados inconsistentes durante a gravação de outro cliente.
- Abordagens pessimistas bloqueiam os registros de dados para evitar conflitos.
- Abordagens otimistas detectam conflitos e os resolvem.
- Sistemas distribuídos veem conflitos de leitura-gravação devido a alguns nodos receberem atualizações e outros não.
- Consistência eventual significa que, o sistema se tornará consistente, assim que as gravações tiverem sido propagadas para todos os nodos.
Marcadore de Versão
Visão Geral
# 1 - Modelos de dados Agregados, Modelos de Distribuição
- Problema atualizações de dados
- Marcadores de versões ajudam a detectar conflitos de concorrência.
- Quando atualizamos os dados, pode verificar o marcador de versão para assegurar que ninguém atualizou os dados entre sua leitura e sua gravação.
- Marcadores de versões podem ser implementados por meio de contadores, GUIDs, hashes de conteúdo, timestamps ou uma combinação deles.
- Com sistemas distribuídos, um marcador vetorial permite detectar quando nodos diferentes têm atualizações conflitantes.
Map-Reduce - mapear e reduzir
Visão Geral
# 1 - Modelos de dados Agregados, Modelos de Distribuição
- Problema
- processamento dos dados distribuidos
- reduzir a quantidade de dados trafegado ne rede entre os nodos
- Map-reduce é um padrão que permite que computações sejam paralelizadas em um cluster.
- A tarefa de mapeamento lê dados de um agregado e agrupa em pares de chave-valor relevantes.
- Mapeamentos somente leem um único registro de cada vez e podem, assim, ser paralelizadose executados no nodo que armazena o registro.
- A tarefa redução recebe muitos valores de uma única chave de saída, a partir da tarefa mapeamento, e os resume em uma única saída.
- Operações de map-reduce podem ser compostas em pipelines, nas quais a saída de uma redução é a entrada do mapeamento de outra operação
- Se o resultado de um map-reduce tor amplamente utilizado, pode ser armazenado como uma visão materializada, que podem ser atualizadas por meio de outras operacões map-reduce que apenas computem alteraçoes na visão
Apresente uma implementação em alguma parte da modelagem relacional com modelo agregado documental. Ex. um JSON do reistro ponto.
# 1 - Introdução
APS RHtech
APS02 - Como pode ser um modelo da dados agragados (NoSQL) para a modelagem relacional proposta inicialmente para nossa App?
# 1 - Introdução
APS RHtech
APS02.b - Configurar cluster Amazon DocumentDB e conectar com Robo 3T
Vamos criar um banco documental para a app/sistema usando como base o resultado do passo anterior.



Banco de dados de Documentos
- Visão geral
- Características
- Consistência
- Transações
- Disponibilidade
- Consulta
- Escalabilidade
- Quando não usar
# 2 - Banco de dados de Documentos
Banco de dados de Documentos
Visão Geral
- O banco de dados armazena e recupera documentos, os quais podem ser XML, JSON, BSON, etc...
- Documentos são estruturas de dados na forma de árvores hierárquicas e autodescritivas,
constituídas de mapas, coleções e valores escalares. - Os documentos armazenados são semelhantes entre si, mas não têm de ser exatamente os mesmos
- Em documentos, não há atributos vazios;
- Os documentos permitem que novos atributos sejam criados sem a necessidade de definição prévia ou de alteração nos documentos existentes.
# 2 - Banco de dados de Documentos
Banco de dados de Documentos
Características
- Cada instância do MongoDB possui múltiplos bancos de dados e cada banco de dados pode ter múltiplas coleções.
- Quando comparamos isso com os SGBDs relacional, uma instância de SGBD é igual a uma instância em MongoDB, os esquemas de SGBDs são semelhantes aos bancos de dados MongoDB e as tabelas de SGBDs são coleções em MongoDB.
-
Quando armazenamos um documento, temos de escolher em qual banco de dados
e em qual coleção irá ser persistido o documento.
# 2 - Banco de dados de Documentos
# 2 - Banco de dados de Documentos
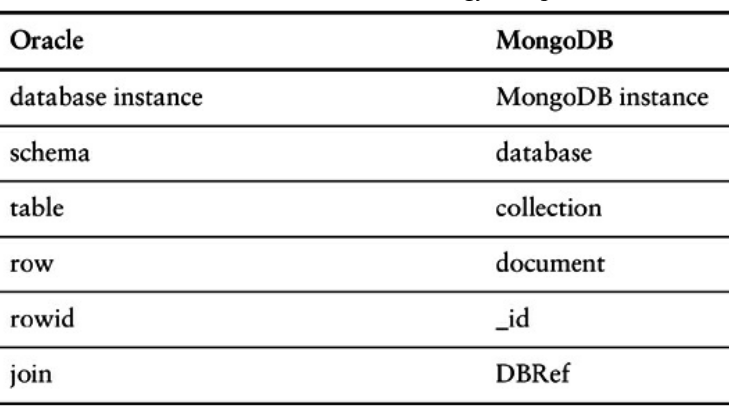
Banco de dados de Documentos
Características
Banco de dados de Documentos
Características
Consistência
-
db.runCommand({ getlasterror : 1 , w : "majority" })-
w com valor majority -> persistencia imediata
-
se o cluster tiver mais de uma nó, a persistencia deverá ser completa em pelo menos n-1 nós
-
-
mongo.slaveOk()
- permite a leitura de nós escravos
# 2 - Banco de dados de Documentos
Banco de dados de Documentos
Características
Transações
-
Uma gravação é bem-sucedida ou falha. Transações no nível de um único documento são conhecidas como transações atômicas.
-
Transações envolvendo mais de uma operação não são possíveis
# 2 - Banco de dados de Documentos
Banco de dados de Documentos
Características
Disponibilidade
- O MongoDB fornce disponibilidade por meio da implementação de réplicas
- Autogerenciamento de elegibilidade de novos nós mestre
# 2 - Banco de dados de Documentos
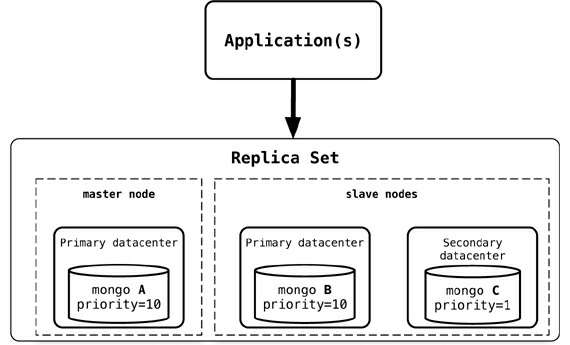
Banco de dados de Documentos
Características
Consultas
-
SELECT * FROM order
-
db.order.find()
-
-
SELECT orderId,orderDate FROM order WHERE customerId = "883c2c5b4e5b"
-
db.order.find({customerId:"883c2c5b4e5b"},{orderId:1,orderDate:1})
-
# 2 - Banco de dados de Documentos
Banco de dados de Documentos
Características
Escalabilidade
- Essa característica é atingida ao passo de adicionar mais un nó no cluster
- Uma vantagem dessa conhguraçăo é que não temos de reiniciar qualquer outro nodo e o aplicativo não fica tempo algum fora do ar.
- Os dados são movidos dinamicamente entre os nodos para assegurar-se de que os tragmentos sempre estejam balanceados
# 2 - Banco de dados de Documentos

Banco de dados de Documentos
Quando não usar
- Transações complexas com muitas operações diferentes
- Consultas em estruturas de dados agregadodos com muitas variáveis
# 2 - Banco de dados de Documentos
# 1 - Introdução
APS RHtech
APS03 - Configurar cluster Atlas e conectar com Robo 3T
Vamos criar um banco documental para a app/sistema usando como base o resultado do passo anterior.
# 1 - Introdução
APS RHtech
APS03.b - Desafio: Configurar App Django e conectar com cluster Atlas
Connectar App Django com cluster Atlas MongoDB e criar tela de registro ponto - persistindo ponto no cluster.

Banco de dados de Chave Valor
- Visão geral
- Tabela hash
- Características
- Consistência
- Transações
- Consultas
- Escalabilidade
- Quando não usar
# 3 - Banco de dados de Chave Valor
# 3 - Banco de dados de Chave Valor
Banco de dados de Chave Valor
Visão Geral
- Um armazenamento de valor-chave é uma tabela de hash simples, usada principalmente quando todo o acesso ao banco de dados é via chave primária. Pense em uma tabela em um RDBMS tradicional com duas colunas, como ID e NOME, sendo a coluna ID a chave e a coluna NAME armazenando o valor.
# 3 - Banco de dados de Chave Valor

- O valor é um blob que o banco de dados apenas armazena, sem se importar ou saber o que está dentro
- É responsabilidade do aplicativo entender o que foi armazenado
- Eles geralmente têm ótimo desempenho e podem ser facilmente dimensionados
Banco de dados de Chave Valor
Tabela hash
- É um tema da disciplina de estrutura de dados
- A idéia central do Hash é utilizar uma função, aplicada sobre parte da informação (chave), para retornar o índice onde a informação deve ou deveria estar armazenada.
- https://docente.ifrn.edu.br/camilataumaturgo/disciplinas/2014.2/estruturas-de-dados/tabela-hash
# 3 - Banco de dados de Chave Valor
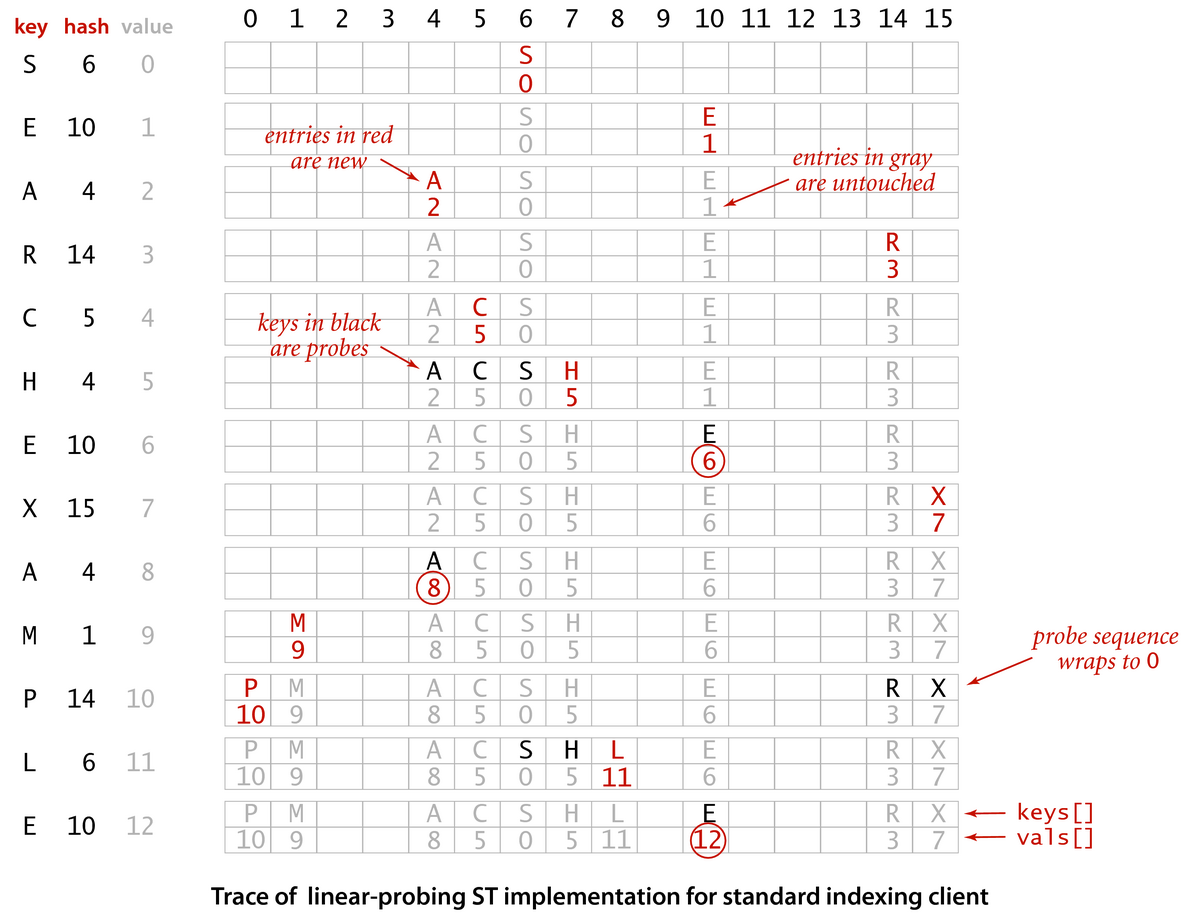
Banco de dados de Chave Valor
Características
# 3 - Banco de dados de Chave Valor
Consistência
-
A consistência é aplicável apenas para operações em uma única chave
-
O modelo de consistência é implementado é o de Consistencia Eventual
-
Há duas maneiras de resolver conflitos de atualização:
-
ou a gravação mais recente vence e as gravações mais antigas são liberadas,
-
ou ambos (todos) os valores são retornados, permitindo que o "cliente" resolva o conflito.
-
-
Uma gravação só é considerada boa apenas quando os dados são consistentes em todos os nós onde os dados estão armazenados.
Banco de dados de Chave Valor
Características
# 3 - Banco de dados de Chave Valor
Transações
-
Diferentes implementações de bancos de dados chave valor têm diferentes tipos de especificações de transações
-
De um modo geral, não há garantias sobre as gravações.
-
As transações Redis permitem a execução de um grupo de comandos em um único passo
-
As transações Redis oferecem duas garantias importantes:
-
Todos os comandos em uma transação são serializados e executados sequencialmente.
-
O comando EXEC aciona a execução de todos os comandos na transação
-
Banco de dados de Chave Valor
Características
# 3 - Banco de dados de Chave Valor
Consultas
-
Todos os armazenamentos de chave valor podem consultar pela chave
-
- e isso é (quase) tudo!
-
-
O cliente precisa ler o valor para descobrir se o atributo atende às condições
-
É muito importante projetar um esquema bem elaborado para a chave.
-
Porem no Redis existe algumas estratégias diferentes
Banco de dados de Chave Valor
Características
# 3 - Banco de dados de Chave Valor
Escalabilidade
-
Muitos bancos de dados chave valore são dimensionados usando fragmentação
-
Para a fragmentação, o nome da chave pode determinar qual nó nó a chave deve ser armazenada pelo valor da chave
-
A fragmentação também apresenta alguns problemas. Se o nó usado para armazenar f ficar inativo, os dados armazenados nesse nó ficam indisponíveis, e novos dados podem ser gravados com chaves que começam com f.
Banco de dados de Chave Valor
Quando não usar
# 3 - Banco de dados de Chave Valor
-
Relacionamento entre dados
-
Transações de várias operações
-
Consulta complexas por dados
-
Operações por conjuntos (joins)
APS RHtech
APS04 - Configurar cluster Redis Cloud e conectar com RedisInsight Desktop Client
Vamos criar um banco chave valor para a app.

# 3 - Banco de dados de Chave Valor
APS RHtech
APS04.b - Desafio: Conectar app Django ao com cluster Redis.
Conectar App Django com cluster Redis Lab e criar tela de listagem de registro ponto - persistir e recuperar ponto.
# 3 - Banco de dados de Chave Valor
Armazenamentos em Família e Coluna
- Visão geral
- Características
- Consistência
- Transações
- Disponibilidade
- Consultas
- Escalabilidade
- Quando não usar
# 4 - Armazenamentos em Família e Coluna
Armazenamentos em Família e Coluna
Visão Geral
- Os bancos de dados de família de colunas armazenam dados em famílias de colunas como linhas que possuem muitas colunas associadas a uma chave de linha
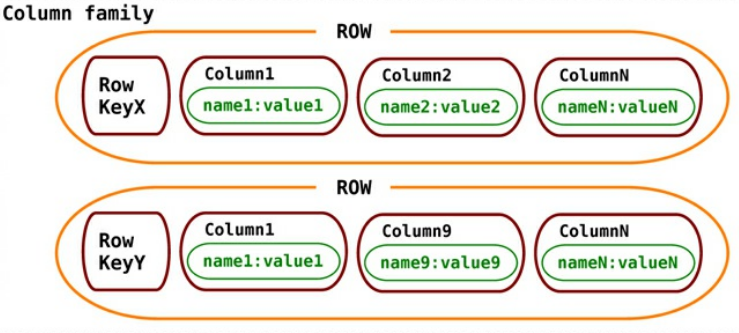
# 4 - Armazenamentos em Família e Coluna
Armazenamentos em Família e Coluna
Características
- Uma coluna do Cassandra consiste em um par nome-valor onde o nome também se comporta como a chave
- Cada um desses pares de valores-chave é uma única coluna e sempre é armazenado com um valor de marcação timestamp
- A marcação timestamp é usado para expirar dados, resolver conflitos de gravação, lidar com dados obsoletos (desatualizados) e mais...
# 4 - Armazenamentos em Família e Coluna
{
name: "fullName",
value: "Martin Fowler",
timestamp: 12345667890
}Armazenamentos em Família e Coluna
Características
- Uma linha é uma coleção de colunas anexadas ou vinculadas a uma chave
- Uma coleção de linhas semelhantes forma uma família de colunas.
- Quando as colunas em uma família de colunas são colunas simples, a família de colunas é conhecida como família de colunas padrão.
# 4 - Armazenamentos em Família e Coluna
//column family
{
//row
"pramod-sadalage": {
"firstName": "Pramod",
"lastName": "Sadalage",
"lastVisit": "2012/12/12"
},
//row
"martin-fowler": {
"firstName": "Martin",
"lastName": "Fowler",
"location": "Boston"
}
}Armazenamentos em Família e Coluna
Características
- Cada família de colunas pode ser comparada a um contêiner de linhas em uma tabela RDBMS onde a chave identifica a linha e a linha consiste em várias colunas.
- A diferença é que várias linhas não precisam ter as mesmas colunas, e as colunas podem ser adicionadas a qualquer linha a qualquer momento sem ter que adicioná-la a outras linhas
- Cassandra coloca as famílias de colunas em keyspaces.
- Um keyspace é semelhante a um banco de dados em RDBMS onde todas as famílias de colunas relacionadas ao aplicativo são armazenadas.
- Os keyspaces devem ser criados para que famílias de colunas possam ser atribuídas a eles
# 4 - Armazenamentos em Família e Coluna
Armazenamentos em Família e Coluna
Características
# 4 - Armazenamentos em Família e Coluna
Consistência
-
Quando uma gravação é recebida pelo Cassandra, os dados são registrados primeiro em um commit log, em seguida, gravados em uma estrutura de memória conhecida como memtable.
-
Uma operação de gravação é considerada bem-sucedida quando é gravada no log de confirmação e na memtable.
-
As gravações são agrupadas na memória e periodicamente gravadas em estruturas conhecidas como SSTable.
Armazenamentos em Família e Coluna
Características
# 4 - Armazenamentos em Família e Coluna
Consistência - 3 configurações
-
ONE: quando uma solicitação de leitura for feita, o Cassandra retornará os dados da primeira réplica, mesmo que os dados estejam obsoletos. O baixo nível de consistência é bom para usar quando você não se importa se obter dados obsoletos e/ou se precisar de um alto desempenho de leitura
-
QUORUM:para operações de leitura e gravação garante que a maioria dos nós responda à leitura e a coluna com a marcação timestamp mais recente seja retornada ao cliente. Nesse modelo a gravação deve ser propagada para a maioria dos nós antes de ser considerado bem-sucedida
-
ALL: significa que todos os nós terão que responder a leituras ou gravações, o que tornará o cluster não tolerante a falhas, mesmo quando um nó estiver inativo, a gravação ou leitura será bloqueada e relatada como uma falha.
Armazenamentos em Família e Coluna
Características
# 4 - Armazenamentos em Família e Coluna
Transações
-
No Cassandra, uma gravação é atômica em relação a linha, o que significa que inserir ou atualizar colunas para uma determinada chave de linha será tratada como uma única gravação e terá êxito ou falha.
-
Se um nó ficar indisponível, o commit log é usado para aplicar alterações no nó.
Armazenamentos em Família e Coluna
Características
# 4 - Armazenamentos em Família e Coluna
Disponibilidade
-
A disponibilidade de um cluster pode ser aumentada reduzindo o nível de consistência das solicitações
-
A disponibilidade é regida pela fórmula (R + W) > N onde
-
W é o número mínimo de nós em que a gravação deve ser gravada com êxito
-
R é o número mínimo de nós que devem responder com êxito a uma leitura
-
N é o número de nós que participam da replicação de dados.
-
-
Para ajustar o nível de disponibilidade é só alterar os valores R e W para um valor fixo de N
-
Dessa forma podemos deixar os keyspace com maior disponibilidade para gravação ou maior disponibilidade para leitura.
Armazenamentos em Família e Coluna
Características
# 4 - Armazenamentos em Família e Coluna
Consulta
-
O Cassandra não possui uma rica linguagem de consulta
-
Conforme os dados são inseridos nas famílias de colunas, os dados em cada linha são classificados pelos nomes das colunas.
-
Se tivermos uma coluna que é recuperada com mais frequência do que outras colunas, é melhor usar esse valor para a chave de linha.
-
Obter uma coluna específica é mais eficiente, pois apenas os dados necessários são retornados, isso ajuda a economizar o movimento de dados dentro do banco, especialmente quando a família de colunas tem um grande número de colunas.
Armazenamentos em Família e Coluna
Características
# 4 - Armazenamentos em Família e Coluna
Consulta
-
Cassandra possui uma linguagem de consulta que suporta comandos do tipo SQL, chamada Cassandra Query Language (CQL)
-
Podemos usar os comandos CQL para criar e manipular uma família de colunas
-- Create a column family
CREATE COLUMNFAMILY Customer (
KEY varchar PRIMARY KEY,
name varchar,
city varchar,
web varchar);
-- Insert the same data using CQL
INSERT INTO Customer (KEY,name,city,web)
VALUES ('mfowler',
'Martin Fowler',
'Boston',
'www.martinfowler.com');
-- SELECT the columns we need
SELECT name,web FROM CustomerArmazenamentos em Família e Coluna
Características
# 4 - Armazenamentos em Família e Coluna
Escalabilidade
-
Escalar um cluster Cassandra é somente uma questão de adicionar mais nós - Escalabilidade horizontal.
-
Este tipo de dimensionamento horizontal permite que tenhamos o máximo de tempo de atividade
Armazenamentos em Família e Coluna
Quando não usar
# 4 - Armazenamentos em Família e Coluna
-
Sistemas que exigem transações ACID para gravações e leituras
-
Atomicidade, Consistência, Isolamento e Durabilidade
-
-
Cassandra não é recomendados para protótipos iniciais ou adoções tecnológicos iniciais, pois nestes projetos o design do banco família de colunas pode mudar constantemente.
Armazenamentos em Família e Coluna
Links
# 4 - Armazenamentos em Família e Coluna
Cluster free in Cloud de Cassandra
Banco de dados de Grafos
- Visão geral
- Teoria dos Grafos
- Características
- Consistência
- Transações
- Disponibilidade
- Consultas
- Escalabilidade
- Quando usar
- Quando não usar
# 5 - Banco de dados de Grafos
Banco de dados de Grafos
Visão Geral
Teoria dos Grafos
- A teoria dos grafos ou de grafos é um ramo da matemática que estuda as relações entre os objetos de um determinado conjunto.
- Um grafo G = (V(G), E(G)) é uma estrutura matemática composta por dois conjuntos:
- V(G), um conjunto de elementos que são chamados de vértices,
- E(G), um conjunto de pares de elementos de V(G), cada par é chamado de aresta
- Medium XP
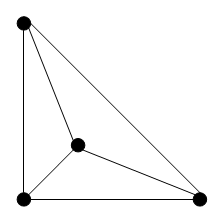
# 5 - Banco de dados de Grafos
Banco de dados de Grafos
Visão Geral
- Os bancos de dados gráficos permite armazenar entidades e relacionamentos entre essas entidades.
- As entidades também são conhecidas como nós e possuem propriedades.
- As relações são conhecidas como arestas que podem ter propriedades.
- As arestas têm significado direcional
- A organização do gráfico permite que os dados sejam armazenados uma vez e interpretados de diferentes maneiras com base em relacionamentos
# 5 - Banco de dados de Grafos
Banco de dados de Grafos
Visão Geral
# 5 - Banco de dados de Grafos
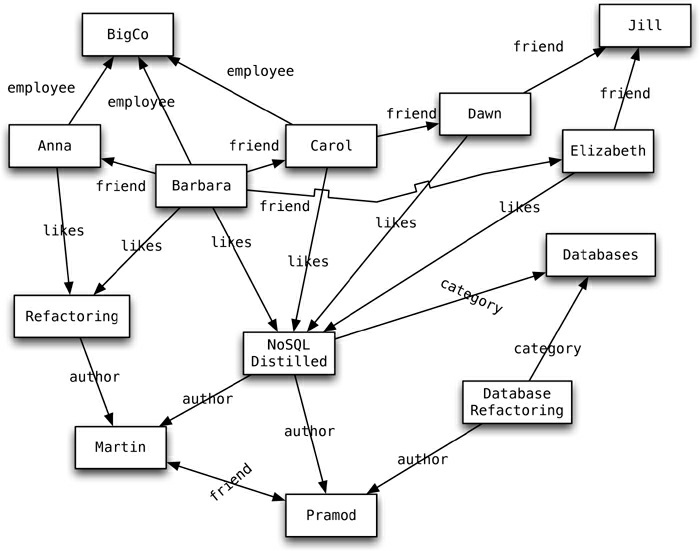
- Dado o grafo construido, podemos executar a seguinte consultar “obter todos os nós empregados pela Big Co que gostam do NoSQL Distilled”.
- Uma consulta no gráfico também é conhecida como travessia do gráfico
Banco de dados de Grafos
Visão Geral
# 5 - Banco de dados de Grafos
- Vantagens:
- Ao armazenamos uma estrutura semelhante a um gráfico no SGBD, como por exemplo um único tipo de relacionamento (“quem é meu gerente”). Adicionar outro relacionamento significa muitas mudanças de esquema e movimentação de dados
- Em bancos de dados relacionais modelamos o grafo antecipadamente com base na travessia que queremos, se a travessia mudar, os dados/relacionamentos terão que mudar também.
- Em bancos de dados de grafos, percorrer as junções ou relacionamentos é muito rápido.
- O relacionamento entre os nós não é calculado no momento da consulta, mas no momento da persistência do relacionamento.
- Percorrer relacionamentos persistentes é mais rápido do que calculá-los para cada consulta.
Banco de dados de Grafos
Visão Geral
# 5 - Banco de dados de Grafos
- No Neo4J, criar um gráfico é tão simples quanto criar dois nós e depois criar um relacionamento
Node martin = graphDb.createNode();
martin.setProperty("name", "Martin");
Node pramod = graphDb.createNode();
pramod.setProperty("name", "Pramod");
// create relationship between the nodes in both direction
martin.createRelationshipTo(pramod, FRIEND);
pramod.createRelationshipTo(martin, FRIEND);Banco de dados de Grafos
Visão Geral
# 5 - Banco de dados de Grafos
- A direção do relacionamento importa: Por exemplo, um nó de produto pode ser curtido pelo usuário, mas o produto não pode curtir do usuário.
- Os nós conhecem os relacionamentos INCOMING e OUTGOING que podem ser percorridos nos dois sentidos.
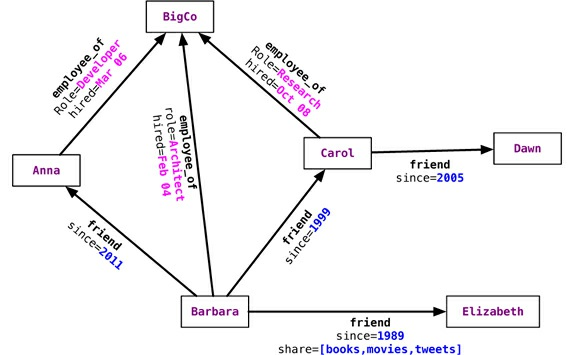
Banco de dados de Grafos
Características
# 5 - Banco de dados de Grafos
Consistência
-
Dentro de um único servidor, os dados são sempre consistentes
-
Neo4J é totalmente compatível com ACID.
-
Ao executar o Neo4J em um cluster, uma gravação no mestre é eventualmente sincronizada com os escravos, enquanto os escravos estão sempre disponíveis para leitura
-
Caracterizando a Consistência Eventual
Banco de dados de Grafos
Características
# 5 - Banco de dados de Grafos
Transações
-
Neo4J é compatível com ACID
-
Marcamos a transação como bem-sucedida (success) e finalmente a completamos com um finish.
-
Uma transação precisa ser marcada como bem-sucedida, senão o Neo4J supõe que ela falhou e a desfaz quando o comando fnish for executado.
-
Essa maneira de gerenciar transações deve ser lembrada durante o desenvolvimento, uma vez que difere do modo padrão de executar transações em um SGBD.
Banco de dados de Grafos
Características
# 5 - Banco de dados de Grafos
Disponibilidade
-
O Neo4J alcança alta disponibilidade fornecendo escravos replicados.
-
Os escravos podem lidar com gravações: eles sincronizam a gravação com o mestre atual e a gravação é confirmada primeiro no mestre e depois no escravo
-
O Neo4J usa o Apache ZooKeeper para acompanhar os últimos IDs de transação persistidos em cada nó escravo e no nó mestre atual
Banco de dados de Grafos
Características
# 5 - Banco de dados de Grafos
Consulta
-
O Neo4J possui uma linguagem de consulta chamada Cypher para consultar o grafo.
-
Neo4J permite consultar o grafo para propriedades dos nós, percorrer o grafo ou navegar pelos relacionamentos dos nós usando suas ligações.
-
Encontrar nós e suas relações imediatas pode ser feito em bancos de dados relacionais. quala diferença?
-
Os bancos de dados de grafos são poderosos quando precisamos percorrer os grafos em qualquer profundidade e especificar um nó inicial para a travessia.
-
À medida que a profundidade do gráfico aumenta, faz mais sentido percorrer os relacionamentos usando um Traverser, permitindo possamos explorar estruturas de árvore
Banco de dados de Grafos
Características
# 5 - Banco de dados de Grafos
Consulta - Estrutura
START beginingNode = (beginning node specification)
MATCH (relationship, pattern matches)
WHERE (filtering condition: on data in nodes and relationships)
RETURN (What to return: nodes, relationships, properties)
ORDER BY (properties to order by)
SKIP (nodes to skip from top)
LIMIT (limit results)Banco de dados de Grafos
Características
# 5 - Banco de dados de Grafos
Escalabilidade
-
Para bancos de dados de grafos, a fragmentação é difícil, pois os bancos de dados de grafos não são orientados por agregação, mas por relacionamento.
-
Como qualquer nó pode ser relacionado a qualquer outro nó, armazenar nós relacionados no mesmo servidor é melhor para a travessia do grafo.
-
Percorrer um gráfico quando os nós estão em máquinas diferentes não é bom para o desempenho.
-
Quando o tamanho do conjunto de dados torna a replicação impraticável, podemos fragmentar os dados do lado do aplicativo usando conhecimento específico do domínio.
Banco de dados de Grafos
Características
# 5 - Banco de dados de Grafos
Escalabilidade
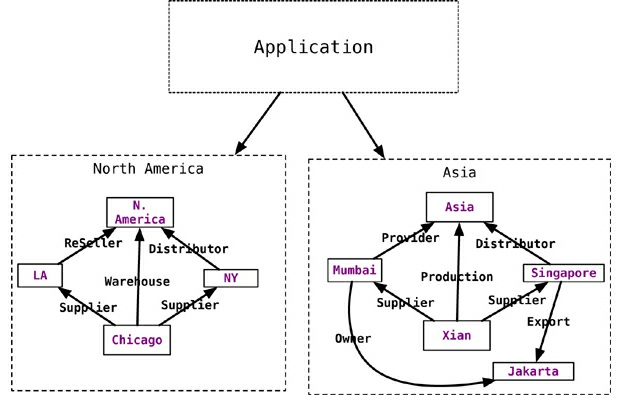
Banco de dados de Grafos
Quando usar
# 5 - Banco de dados de Grafos
-
Dados conectados - Redes sociais
-
Roteamento - serviços de localização
-
uma origem e um destino - um caminho
-
-
Mecanismos de recomendação
-
identifica caracteristicas semelhantes
-
arestas com ligações parecidas
-
Banco de dados de Grafos
Quando não usar
# 5 - Banco de dados de Grafos
-
Quando você deseja atualizar todas ou um subconjunto de entidades,
-
Por exemplo:
-
em uma solução de análise em que todas as entidades podem precisar ser atualizadas com uma propriedade alterada, pois alterar uma propriedade em todos os nós não é uma tarefa simples.
-
Banco de dados de Grafos
Links
# 5 - Banco de dados de Grafos
Cluster free in Cloud de Neo4j
Migração de Esquemas
Persistência Poliglota
# 6 - Migração de Esquemas, Persistência Poliglota
Migração de Esquemas, Persistência Poliglota
- As empresas tendem a usar o mesmo mecanismo de banco de dados para armazenar
- transações comerciais,
- dados de gerenciamento de sessão
- relatórios,
- BI e data warehousing
- informações de log.
# 6 - Migração de Esquemas, Persistência Poliglota
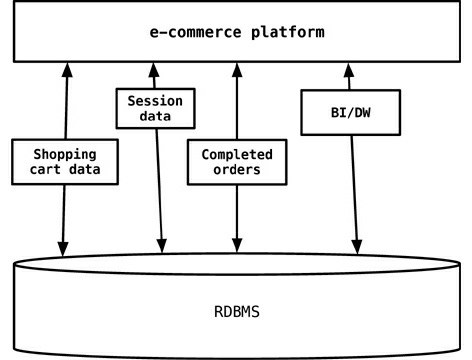
Migração de Esquemas, Persistência Poliglota
- Em 2006, Neal Ford cunhou o termo programação poliglota, para expressar a ideia de que os aplicativos devem ser escritos em uma mistura de linguagens para aproveitar o fato de que linguagens diferentes são adequadas para lidar com problemas diferentes.
- Da mesma forma, ao trabalhar em um problema comercial de comércio eletrônico, é importante usar um armazenamento de dados para o carrinho de compras que é altamente disponível e pode ser dimensionado, mas o mesmo armazenamento de dados não pode ajudar a encontrar produtos comprados pelos amigos dos clientes.
- Usamos o termo persistência poliglota para definir essa abordagem híbrida de persistência.
# 6 - Migração de Esquemas, Persistência Poliglota
Migração de Esquemas, Persistência Poliglota
# 6 - Migração de Esquemas, Persistência Poliglota

Migração de Esquemas, Persistência Poliglota
# 6 - Migração de Esquemas, Persistência Poliglota
Migração de Esquemas, Persistência Poliglota
- A persistência poliglota é sobre o uso de diferentes tecnologias de armazenamento de dados para lidar com diferentes necessidades de armazenamento de dados
- A persistência poliglota pode ser aplicada em uma empresa ou em um único aplicativo
- Encapsular o acesso a dados em serviços reduz o impacto das escolhas de armazenamento de dados em outras partes de um sistema
- Adicionar mais tecnologias de armazenamento de dados aumenta a complexidade na programação e nas operações, portanto, as vantagens de um bom ajuste de armazenamento de dados precisam ser ponderadas em relação a essa complexidade.
# 6 - Migração de Esquemas, Persistência Poliglota
{Referências}

Senai-Pos-Modelagem-de-Estruturas-NoSQL
By Henrique Vignando



