Analysis, Modelling and Protection of Online Private Data
A dissertation presented by: Silvia Puglisi
To: The Department of Telematics Engineering
In partial fulfilment of the requirements for the degree of Doctor of Philosophy in the subject of Privacy and Security
Advisers: Jordi Forné & David Rebollo-Monedero
Agenda
-
Motivations && Objectives
-
User profiling in social tagging systems
-
Privacy in proximity-based applications
-
How advertising networks collect users' browsing patterns
-
Measuring the anonymity risk of time-variant user profiles.
-
Conclusions and future work
Motivations && Objectives
Motivation






This work is motivate by understanding how data, created by users, flows between applications and services and how this does affect web privacy.



The problem of web privacy
In the early age of the Internet users enjoyed a large level of anonymity.
Users can't be anonymous online without a certain investment in time/skills/money.

The problem of web privacy
Traditional
Modern
Traditional

- Market research
- Census data
- Public records
- Surveys
- Purchases
- Loyalty programs
- Clubs
- Credit history
- Insurances
- Healthcare
- Employers
- Public web data
- Social networks
- Web activity
- App statistics
- Online shopping
- Smart TV
- Activity trackers
- Cars
- Smart watches
- E-readers
- ISPs




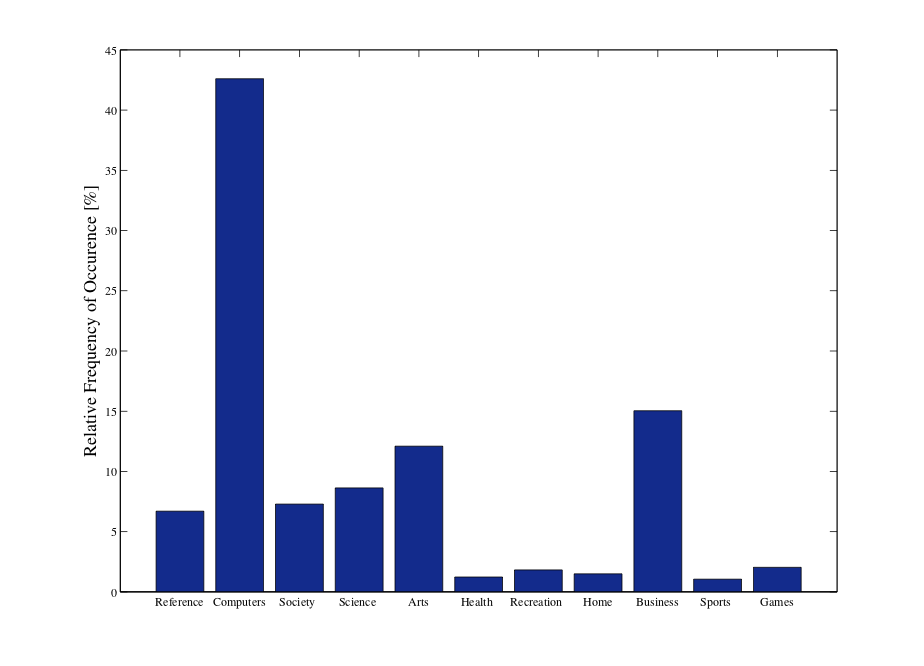
Objectives
The main objectives of this work are summarised as follows:
- Analysing recommendation systems and how these are affected by Privacy Enhancing Technologies (PETs).
- Analysing privacy violation in proximity-based applications.
- Analysing how users are tracked while they surf the web.
- Measuring the differential update of the anonymity risk for time variant user profiles.
1. User profiling in social tagging systems
User Profiling
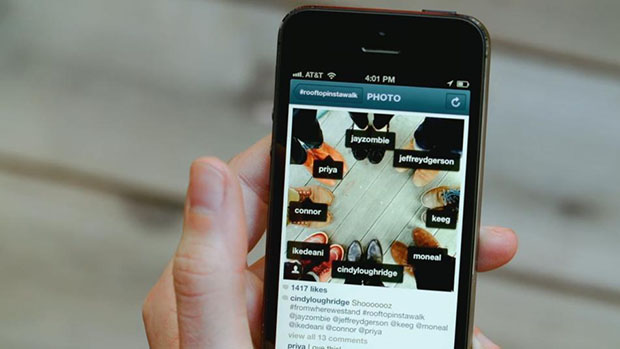
Recommendation systems use tags to categories users' preferences.
We want to express the trade-off between recommendation utility and user privacy.
p_m = (p_{m,1},...,p_{m,L})
p_m = (p_{m,1},...,p_{m,L})
Objectives
-
Measuring the trade-off between user privacy and utility.
A metric of privacy
D(p \| u) = \log u - H(p) = - \sum{p_i \log{p_i}}
D(p\,\|\,q)=\sum p_i \log \frac{p_i}{q_i}
R_0 = D(p_0\,\|\,q)
R = D(p\,\|\,q)
T.M.Cover and J.A. Thomas. Elements of Information Theory. Wiley,New York, second edition, 2006.
Edwin T. Jaynes. On the rationale of maximum-entropy methods. Proceedings of the IEEE, 70(9):939–952, 1982.
JavierParra-Arnau, David Rebollo-Monedero, and Jordi Forne. Measuring the privacy of user profiles in personalized information systems. Future Generation Computer Systems, 33:53–63, 2014.
the Kullback–Leibler divergence is a measure of discrepancy between two probability distributions
Defining similarity and utility
Similarity Metric
Utility of Information Metric
s(p,t)= \frac { p \cdot t } { \|p\|_2 \|t\|_2 }
Precision is the fraction of relevant instances among the retrieved instances. Precision is based on an understanding and measure of relevance.

Privacy enhancing techniques
We focus on those technologies that rely on the principle of tag forgery.
When a user wishes to apply tag forgery, first they must specify a tag-forgery rate, i.e. the ratio of forged tags to total tags the user is disposed to submit.
\rho
The ratio of forged tags can be considered a measure of utility.
Privacy enhancing techniques
In this work, we consider three different forgery strategies:
- optimised tag forgery,
- the popular TMN mechanism
- and a uniform tag forgery.
The optimised tag forgery corresponds to choosing the strategy r* that minimises privacy risk for a given strategy.
David Rebollo-Monedero and Jordi Forne. Optimized query forgery for private information retrieval. IEEE Transactions on Information eory, 56 (9):4631–4642, 2010.
D. Rebollo-Monedero, J. Parra-Arnau, and J. Forne. An information- theoretic privacy criterion for query forgery in information retrieval. In Proc. Int. Conf. Secur. Technol.(SecTech), Lecture Notes Comput. Sci. (LNCS), pages 146–154, Jeju Island, South Korea, dec 2011. Springer- Verlag. Invited paper.
Architecture
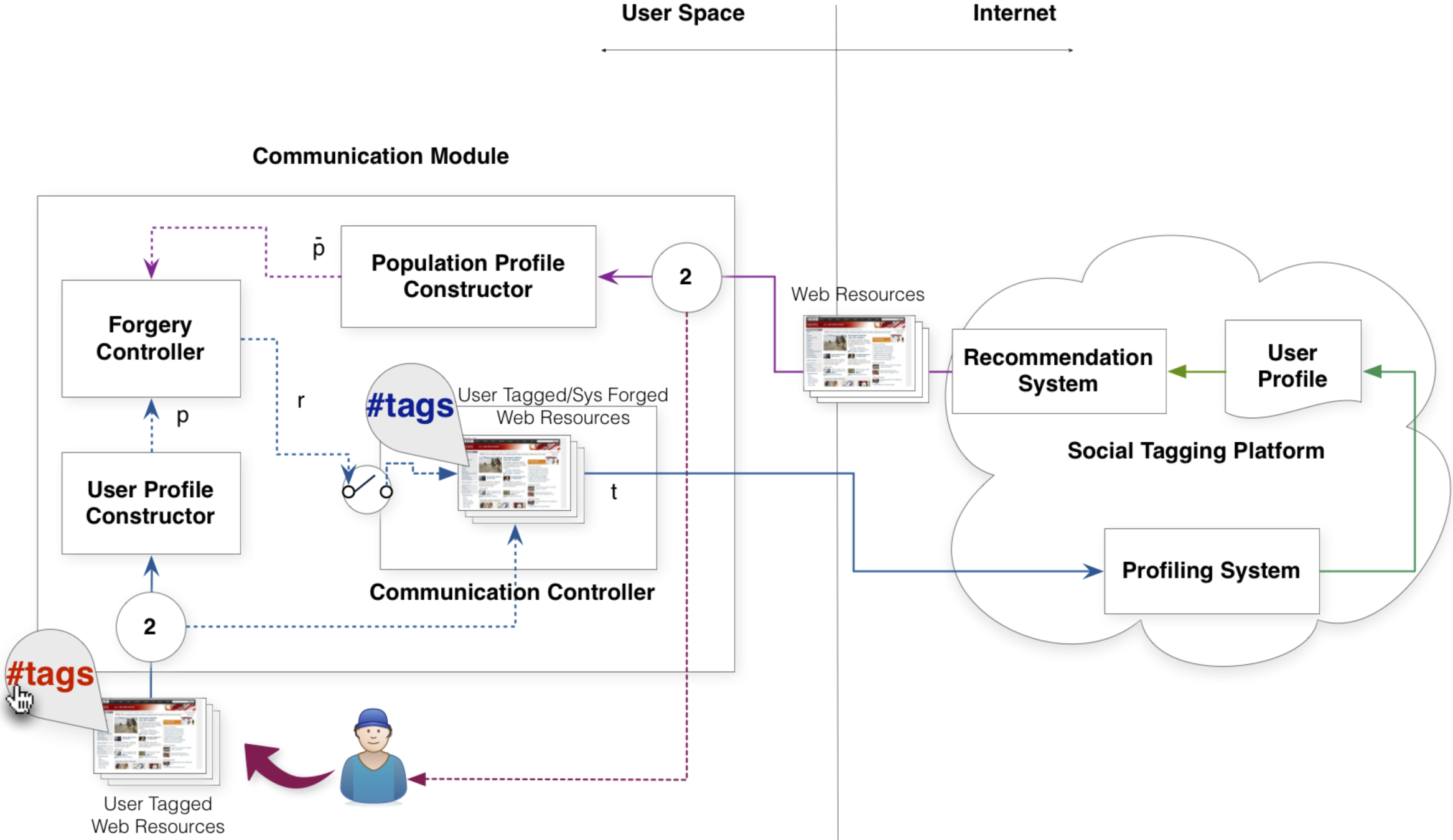
Evaluation
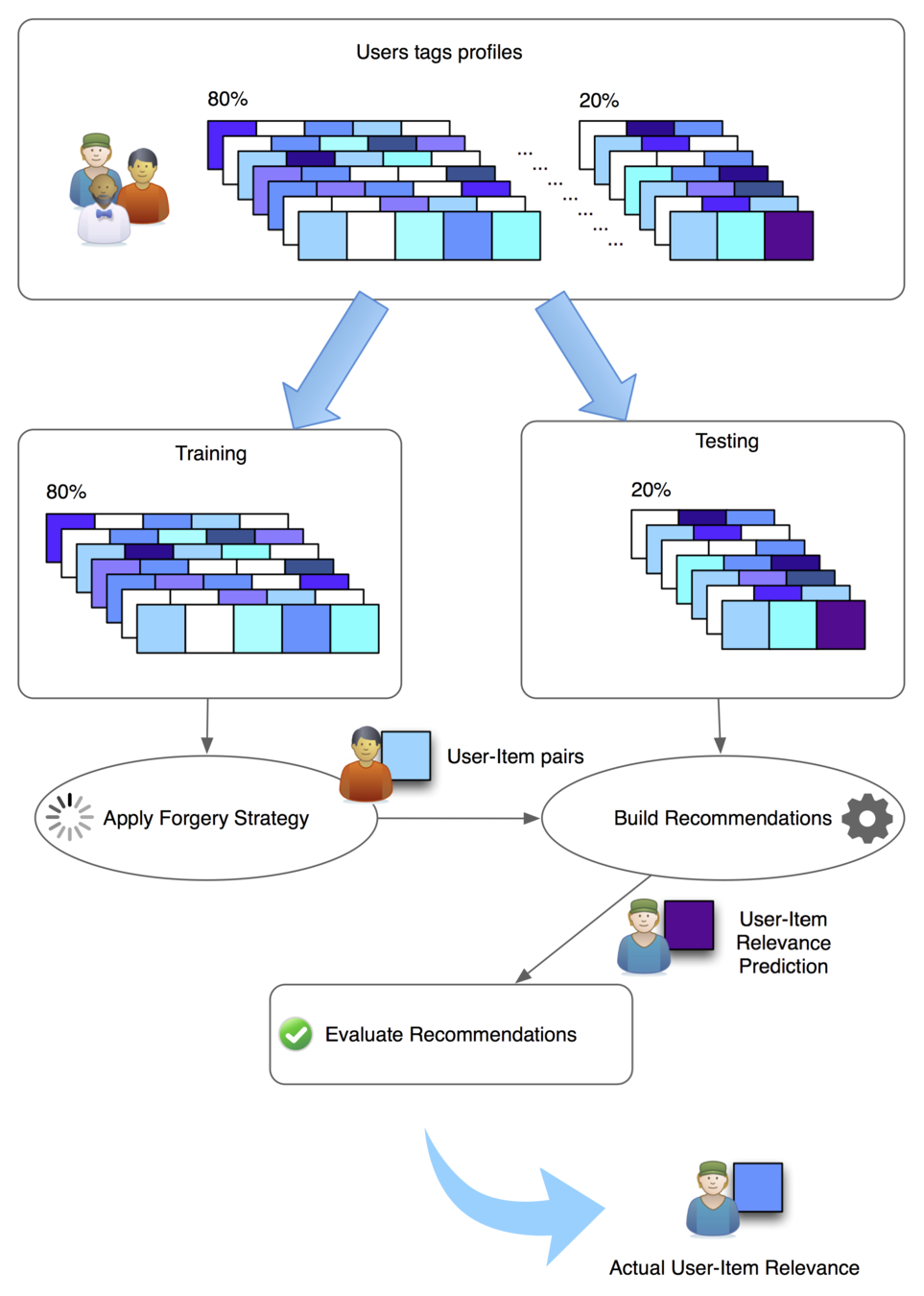
Evaluation
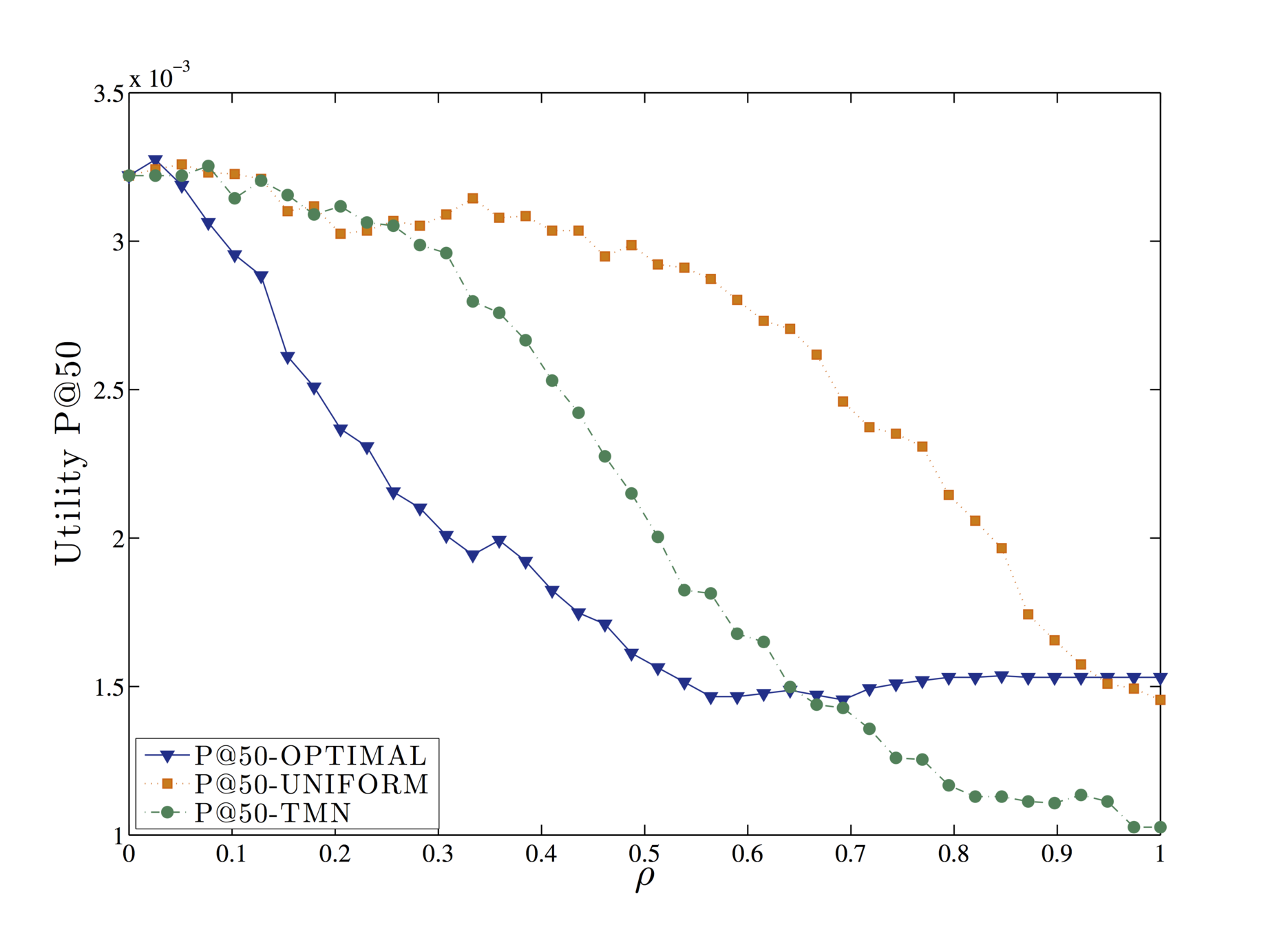
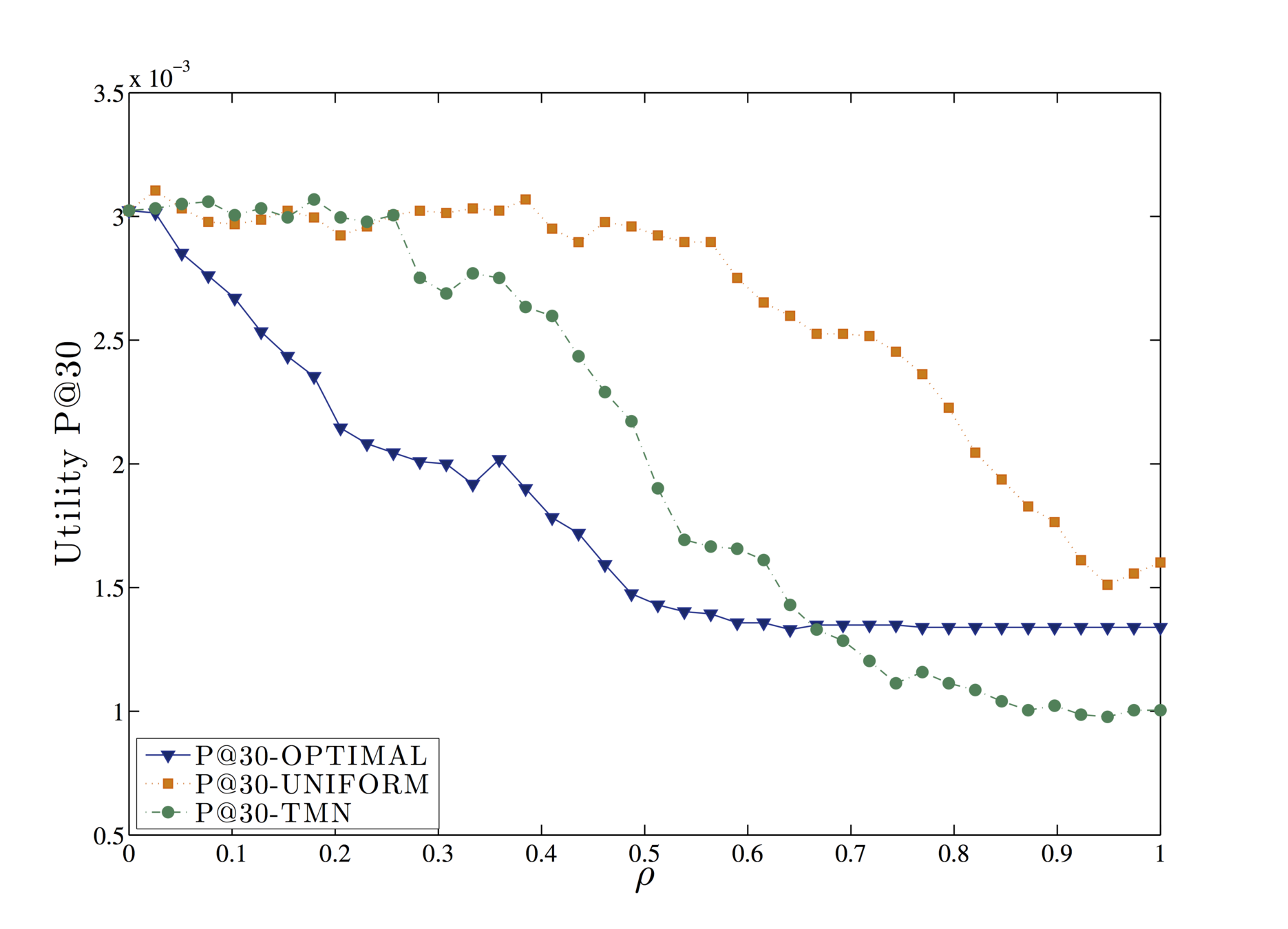
Evaluation
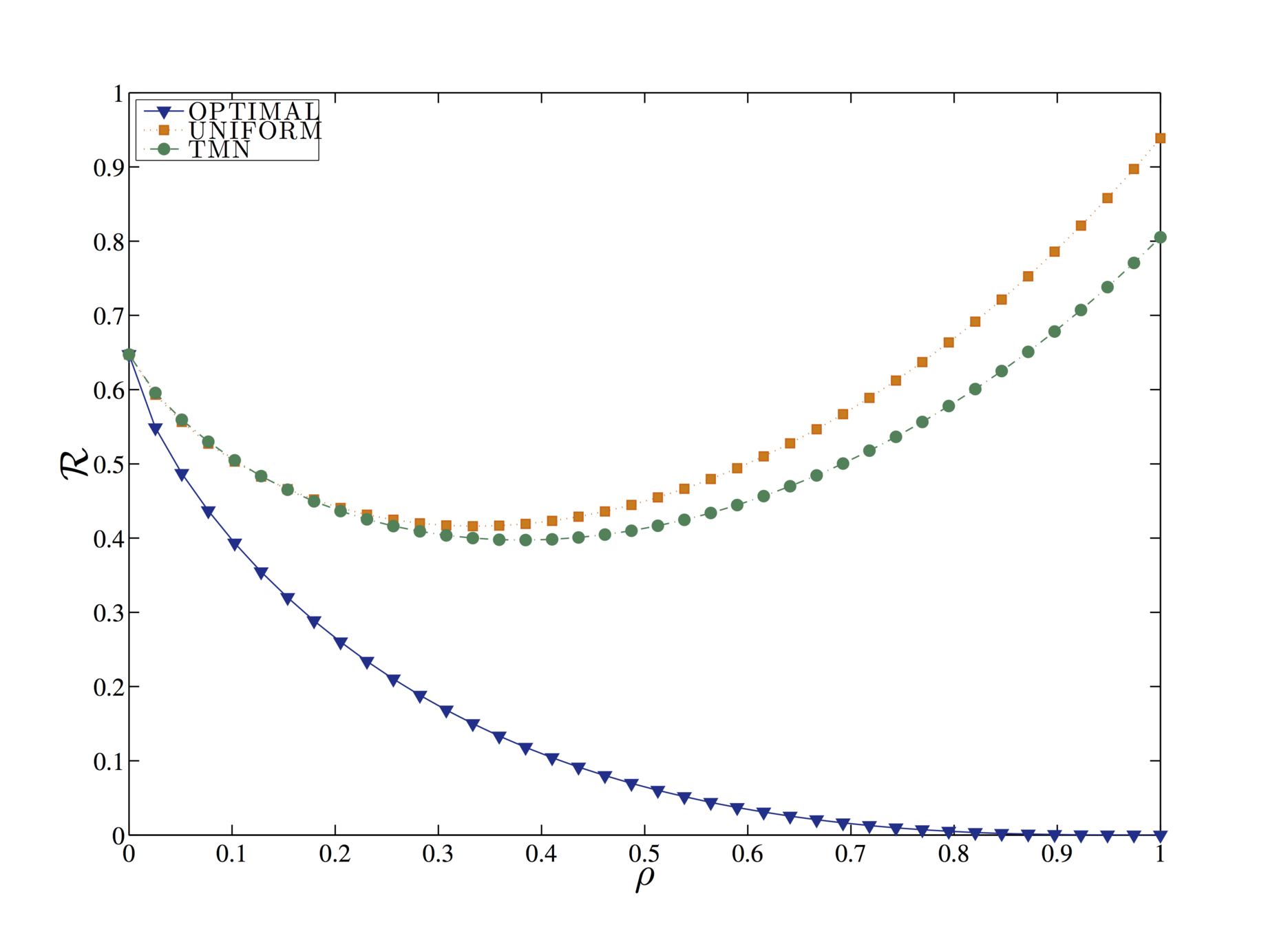
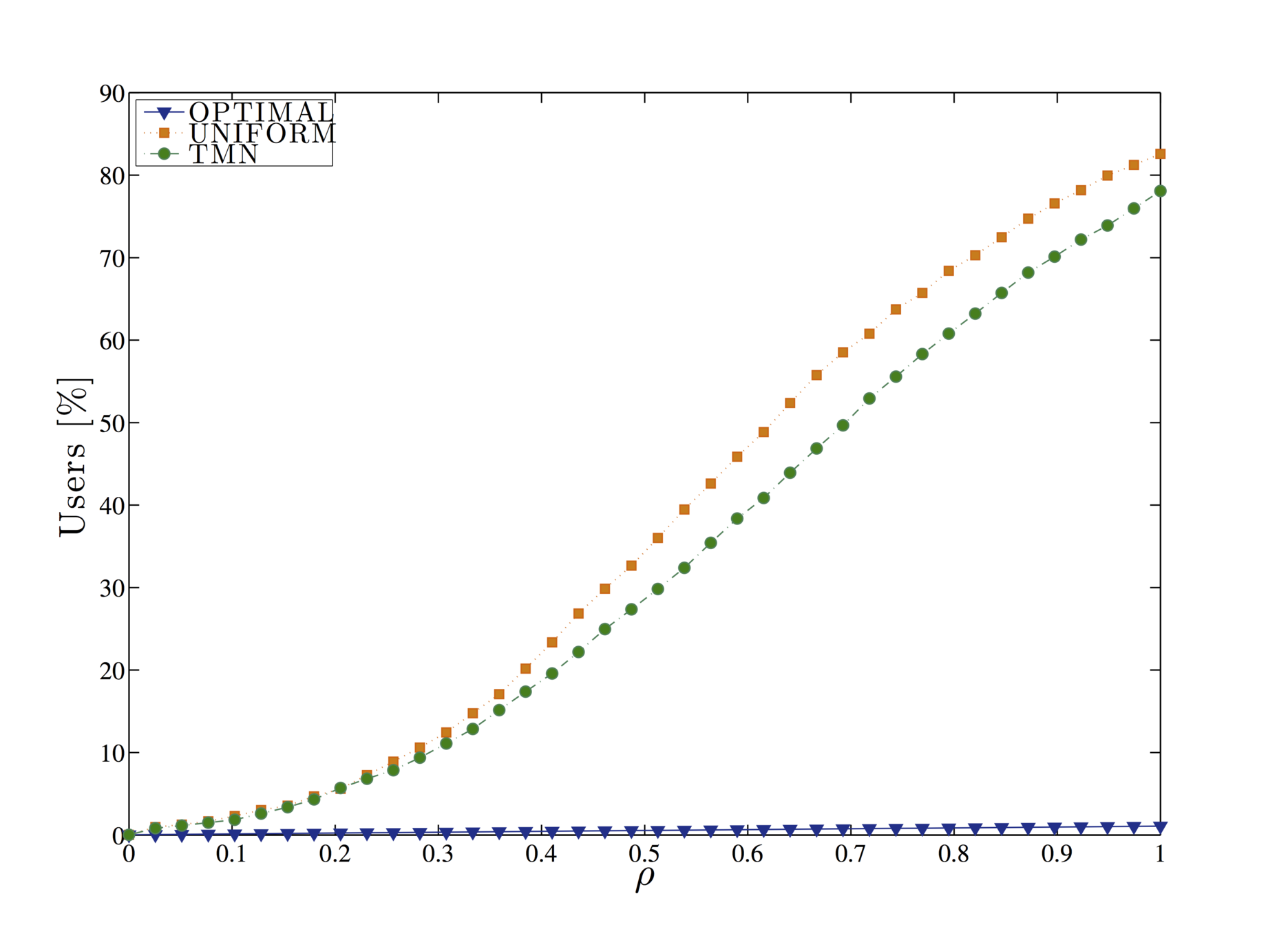
Query forgery is an effective strategy, as no third parties or external entities need to be trusted by the user in order to be implemented.
2. Privacy in proximity based applications
Proximity based applications
- Proximity-based social applications build a sense of serendipitous discovery of people, places and interests.
- We are interested in analysing privacy issues in this set of services.
Objectives
- Classify privacy threats in proximity-based applications*.
- Formalise a location attack showing how these applications are inherently insecure.
- Build a Social Graph attack using Facebook likes to profile the victim.
* Solove, Daniel J. "A taxonomy of privacy." University of Pennsylvania law review (2006): 477-564.
Privacy violations
- Collection
- Processing
- Dissemination
- Invasion
Collection
Information collection is possible on these applications through different techniques.
We have intercepted APIs call from mobile devices through Man In The Middle (MITM) attack in some occasions, and interacted with the APIs directly in other occasions.

MITM
Invasion
Once a user location has being inferred, we can continue tracking the same users and their preferences for an unlimited amount of fetches.
Processing
1) Multilateration attack:
Once we posses the user’s id on the specific application we are able to query their APIs and update our information about the user location constantly.
2) Hyper graph attack:
Facebook token is used to authenticate and/or authorise the app to request and obtain certain information about the user.
Hyper graph attack

The probability that an attacker can guess a facebook page like is p=0.1 based on the number of active facebook* users and most popular Facebook fan pages**.
*https://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-worldwide/
**https://www.statista.com/statistics/269304/international-brands-on-facebook-by-number-of-fans/
Multilateration attack
Multilateration measures the difference in distance between two stations which results in an infinite number of locations that satisfy the measurement, forming a hyperbolic curve.

Mitigation possibilities
Risk in such applications could be reduced by applying a variety of technique.
Some errors are naive and have important consequences for users' privacy.
Some implementation mistakes could be easily avoided.
3. How advertising networks collect users' browsing patterns
The problem of web tracking
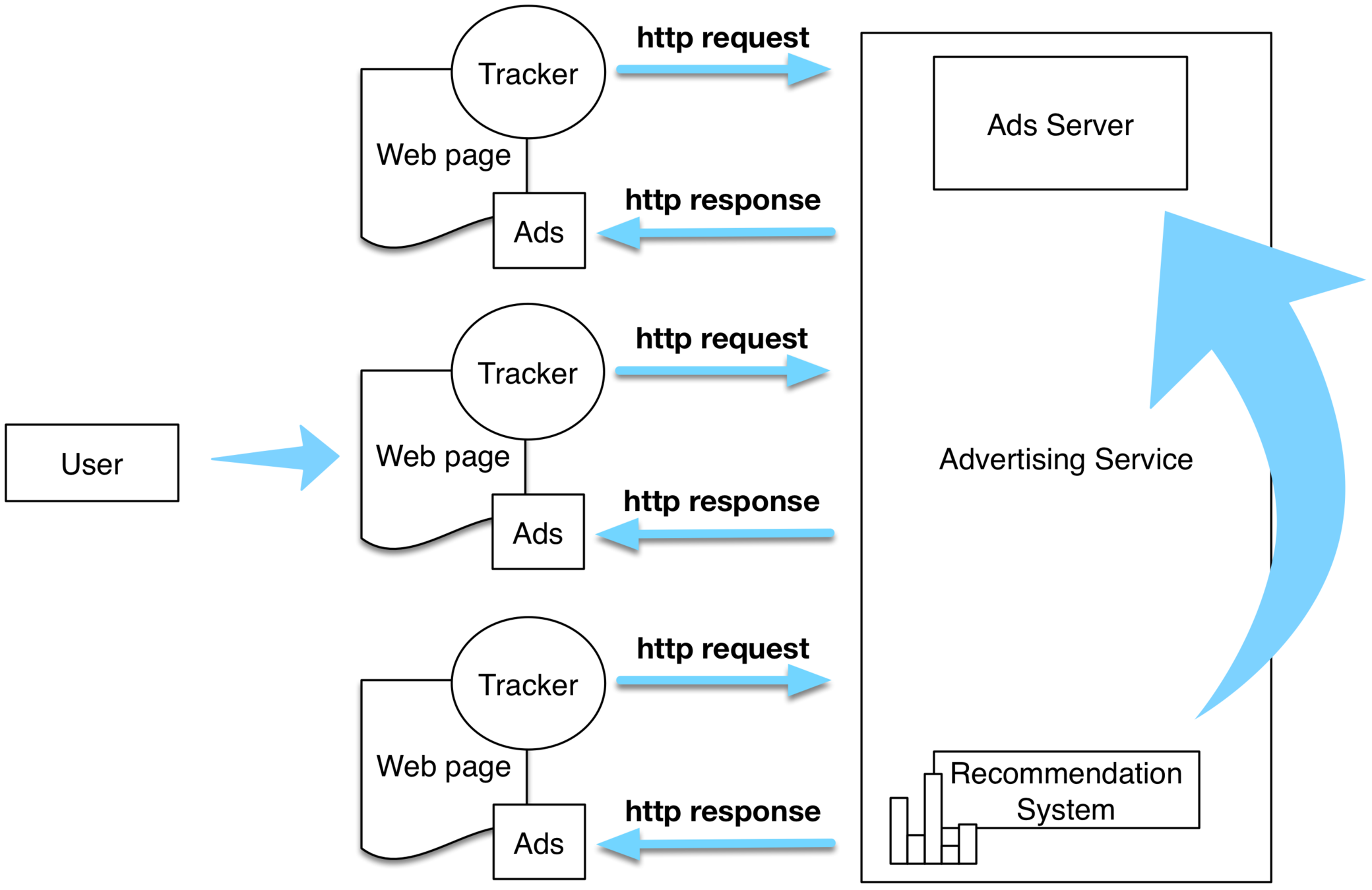
Tracking networks follow users' browsing habits while they surf the web.
The objective is collecting users' traces and surfing patterns.
These data constitute what is called the user's online footprint.
Objectives
- Build a model of users' online footprints.
- Measure how tracking network follow user browsing patterns.
- Identify tracking networks from their network properties.
- Measure the impact of tracking on user privacy.
Anatomy of tracking networks
https://blog.twitter.com/2014/introducing-the-website-tag-for-remarketing
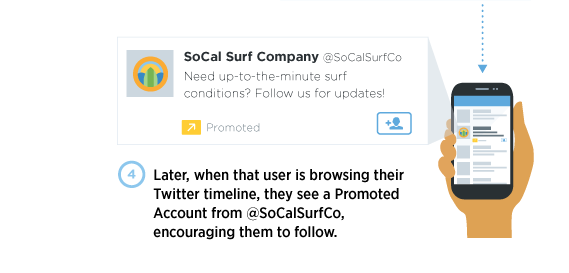
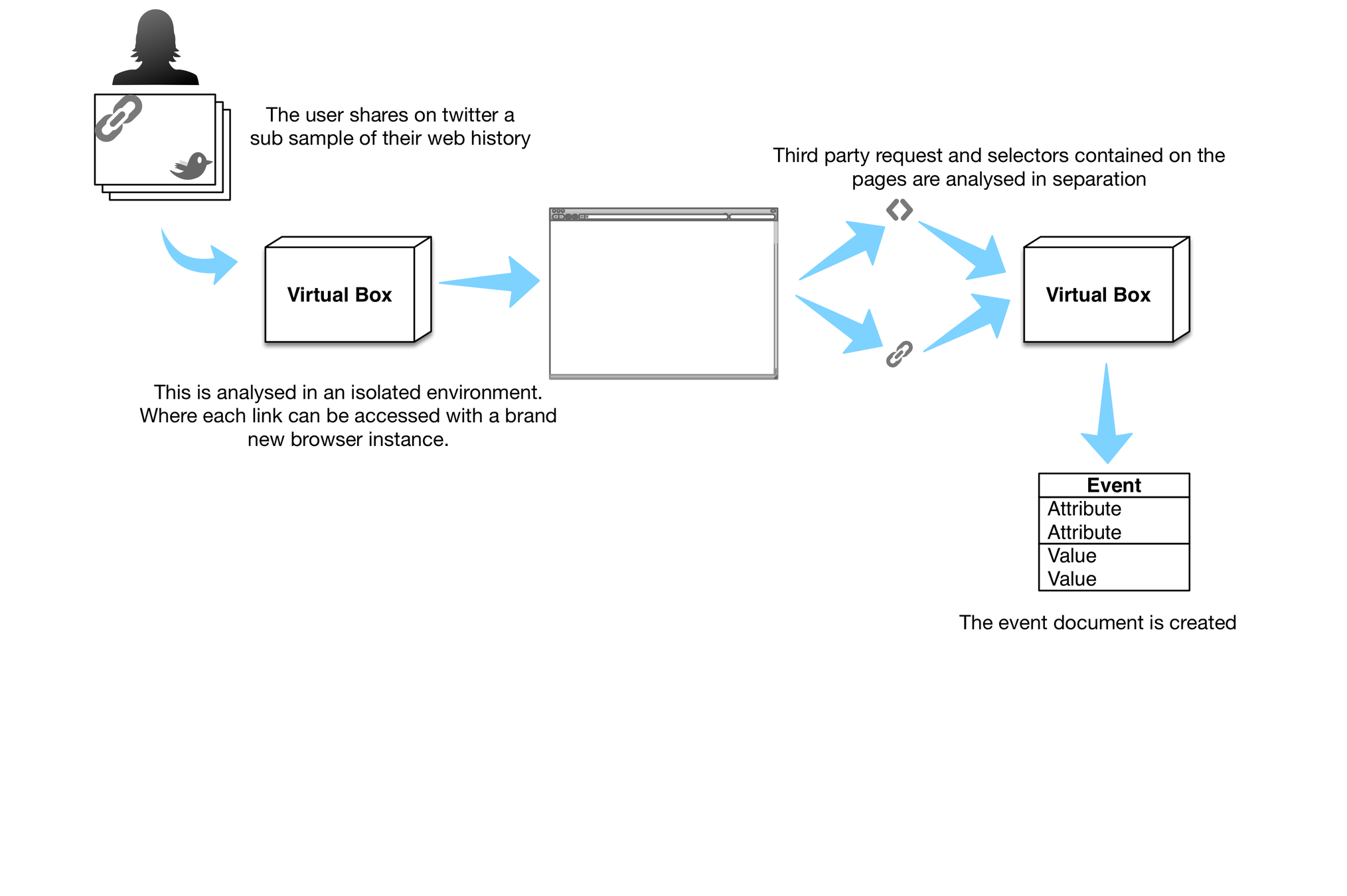
Modelling the user profile
\hat{p} = (\hat{p}_1,\ldots, \hat{p}_L).
q =(q_1,\ldots, q_L)
p = (p_1,\ldots, p_L)

Partial user profile - what the tracker sees
Ad profile - what the tracker uses
Modelling the user profile
p = (p_1,\ldots, p_L)
| Categories | 16 | Users | 50 |
|---|---|---|---|
| Pages per user | 100 | Total Pages | 5000 |
Measuring the effect of tracking
We wish to find a systematic measure of the discrepancy between the partial profile as observed by an advertising platform and the genuine user profile. We propose two metrics:
The normalised 𝛂-norm between the vectors:
\mathrm{GV}_\alpha(p, q) = \frac {1} {\sqrt[\alpha]{2}} {\| p - q \|}_\alpha = \sqrt[\alpha]{{ {\frac {1} {2}} {\sum_l{ | p_{l} - q_{l}|^\alpha }} }} ,\quad \alpha \in [1,\infty].
D(p\,\|\,q)=\sum p_i \log \frac{p_i}{q_i}
The KL-divergence:
Modelling users' activities
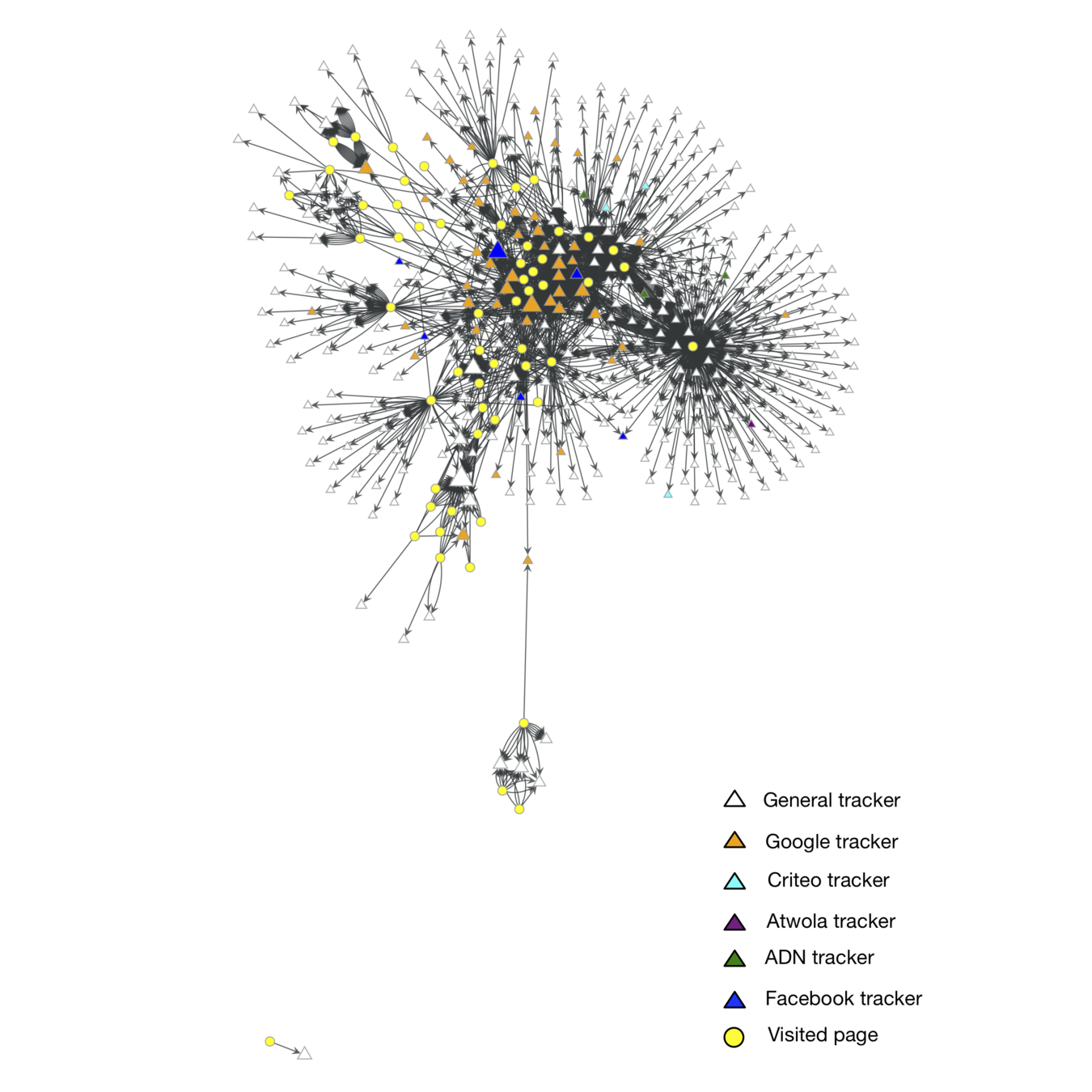
We built a graph model of tracking networks and how these are connected to pages.
Tracker were categorised according to the average degree of the neighbourhood of each node.
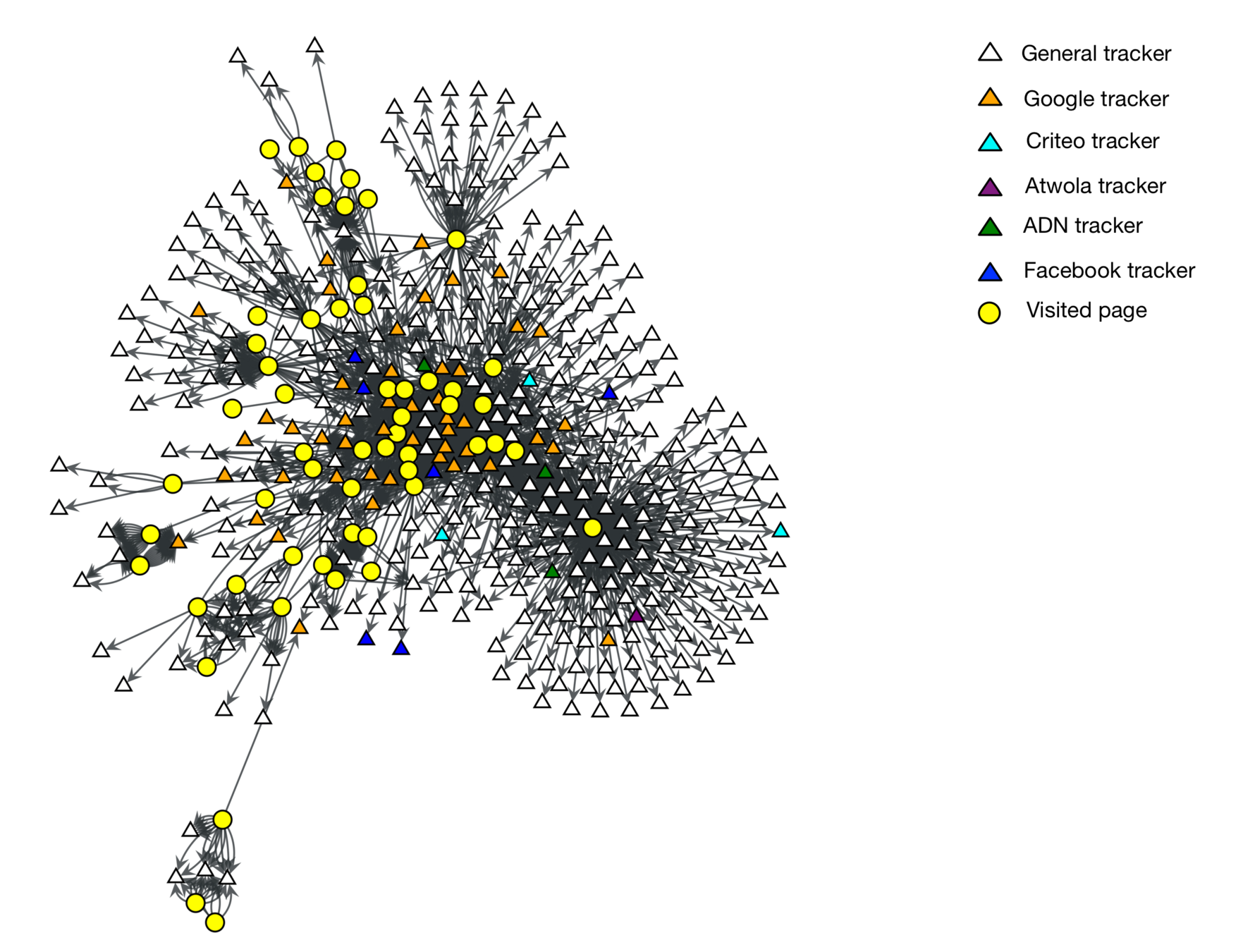
\langle k_{nn,i} \rangle= \frac{1}{| N(i) |} \sum_{j \in N(i) } {k_j}
Page impact on the actual user's profile
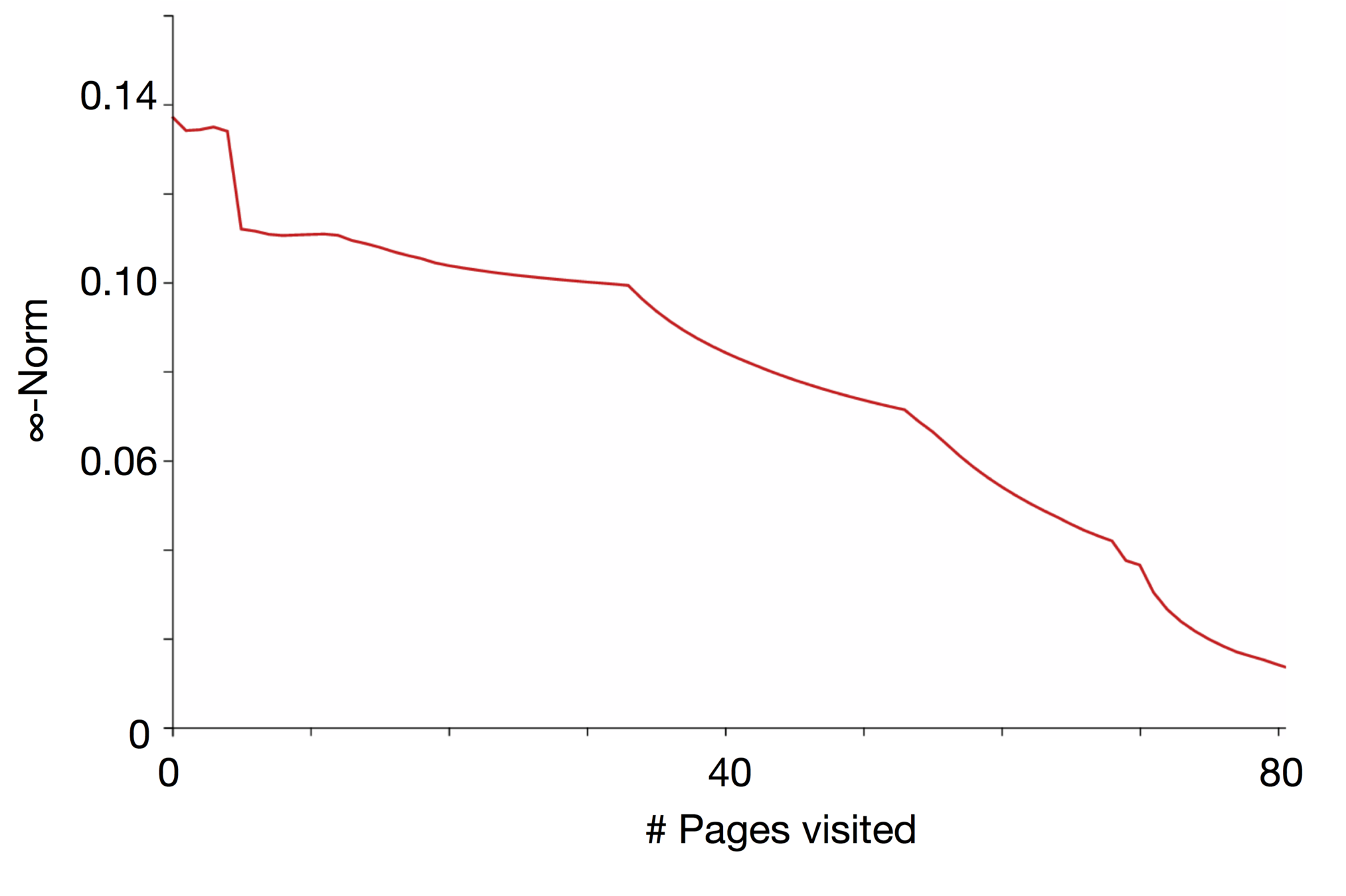
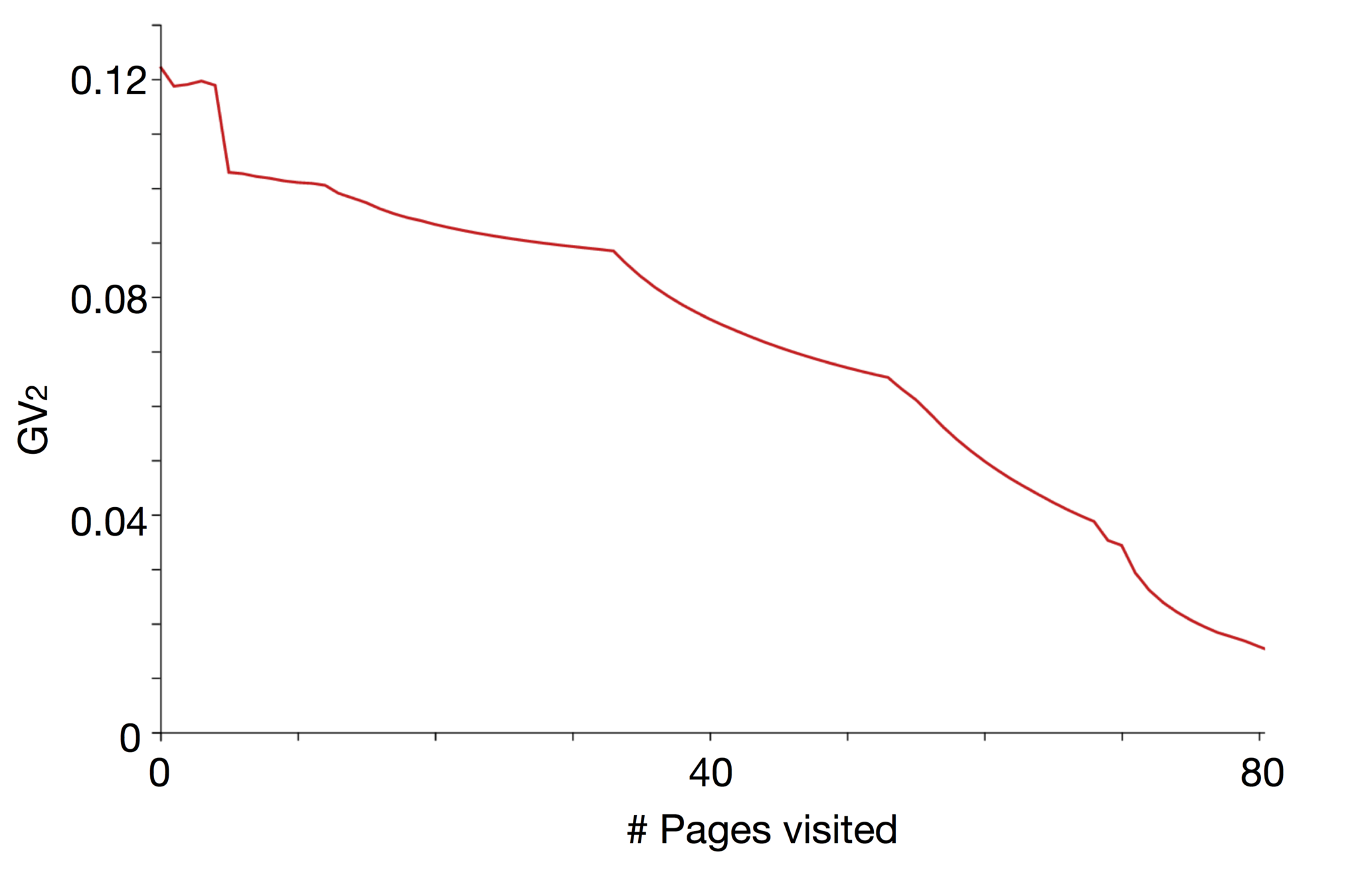
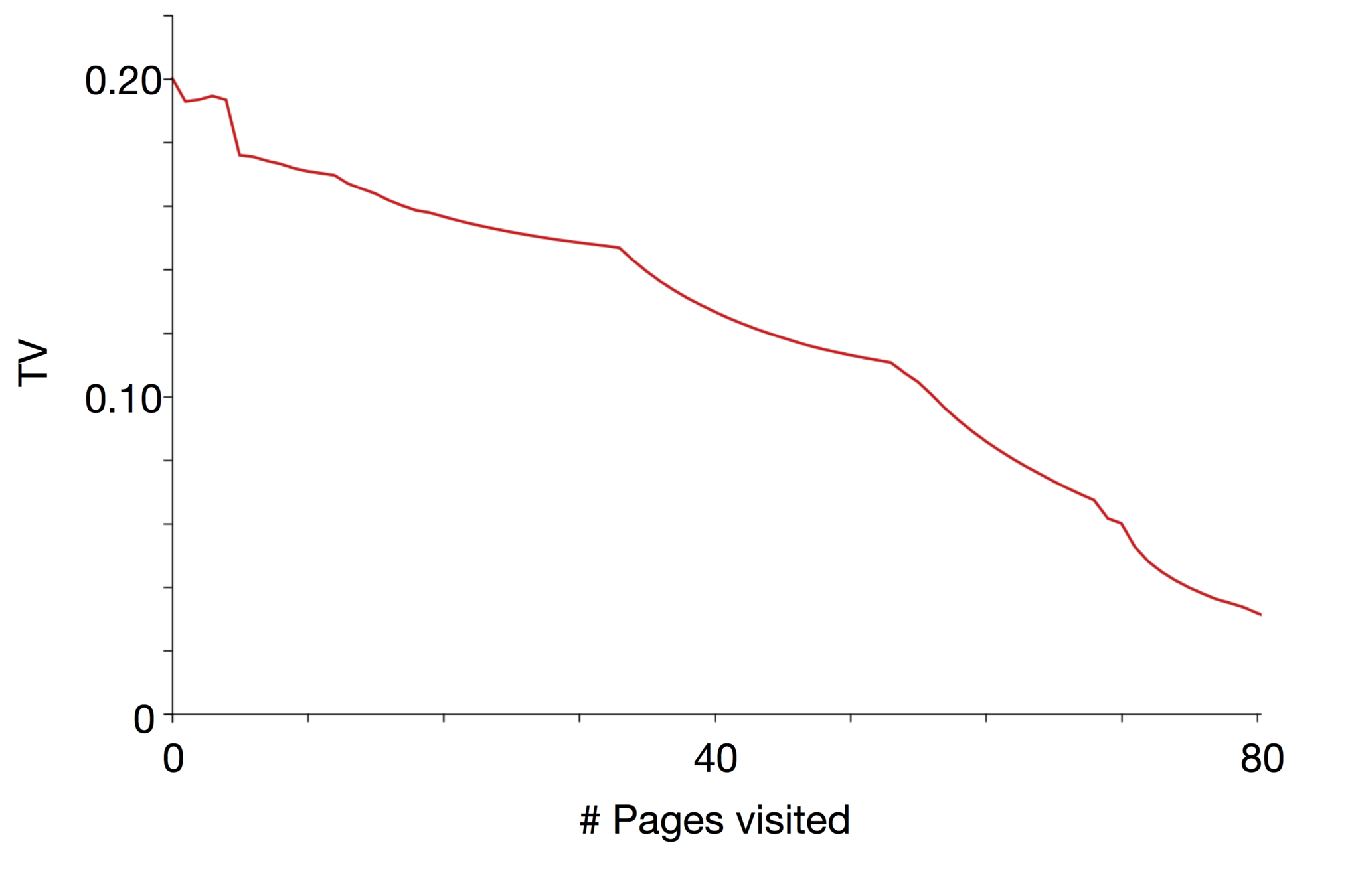
How Facebook track the user's profile
Profile third-party requests to Facebook
| Tracker domain | avg k |
|---|---|
| tacoda.at.atwola.com | 180 |
| bcp.crwdcntrl.net | 180 |
| match.prod.bidr.io | 180 |
| glitter.services.disquis.com | 180 |
| ad.afy11.net | 180 |
| idsync.lcdn.com | 180 |
| mpp.vindicosuite.com | 180 |
| aka-cdn-ns.adtechus.com | 180 |
| client6.google.com |
180 |
| i.simpli.fi |
180 |
| ads.p161.net |
180 |
| cms.quantserve.com |
180 |
| ads.yahoocom |
129 |
| graph.facebook.com |
118 |
| ib.adnxs.com |
110 |
| rs.gwallet.com |
108 |
| bid.g.doubleclick.net |
98.333 |
4. Measuring the anonymity risk of time-variant user profiles.
An information-theoretic model
We want to understand how users' privacy is affected when new content is shared online.
We consider profiles that change over time.

Objectives
- Measure the anonymity risk for profiles that change over time.
- Use actual Facebook data to show how our model can be applied to a real-world scenario.
An information-theoretic model
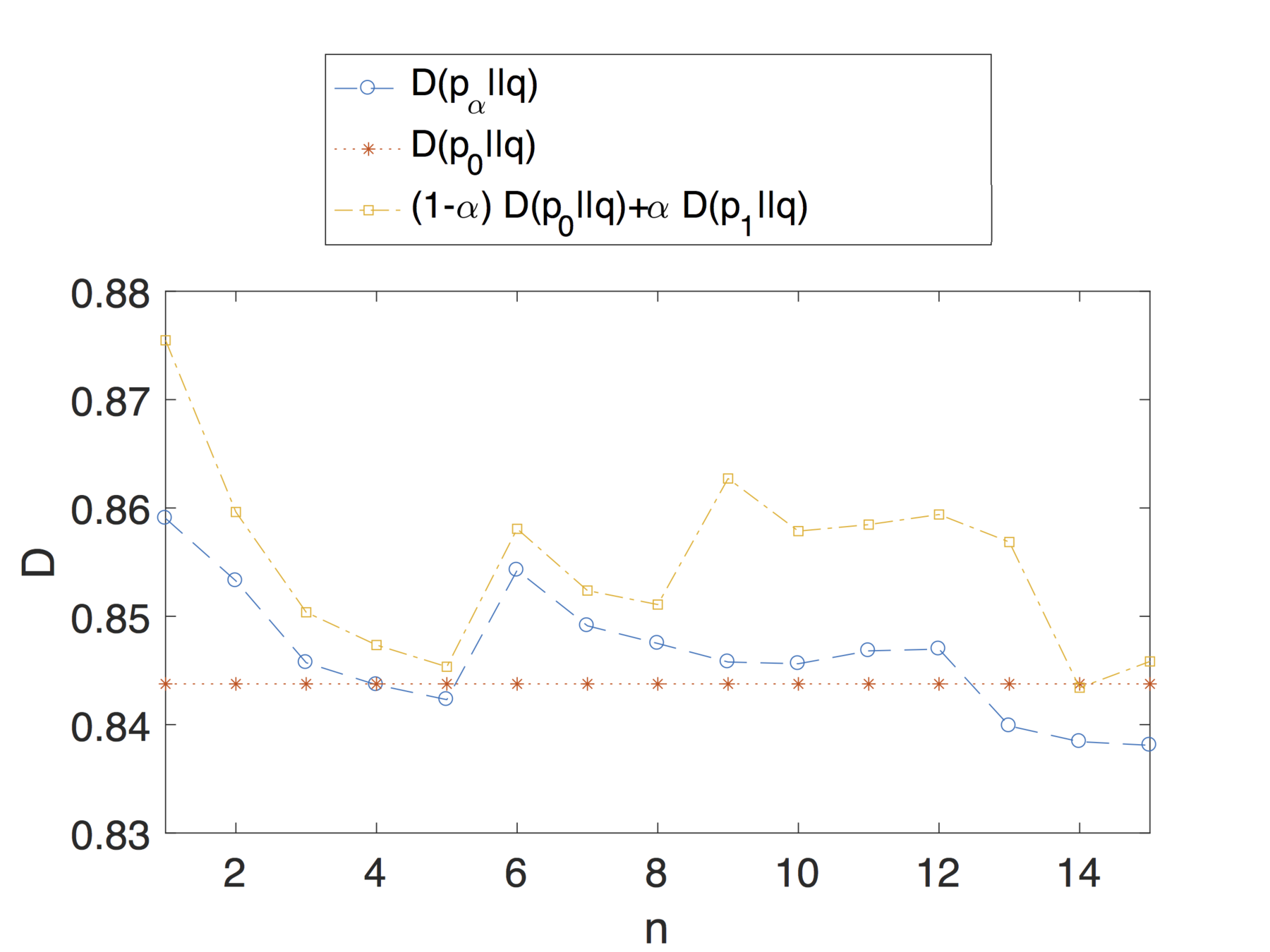
Our metrics are based on an information-theoretic measure of anonymity risk: the KL divergence between a user profile and the average population's profile.
D(p\|q)=\sum_{i=1}^m p_i\log \frac{p_i}{q_i}
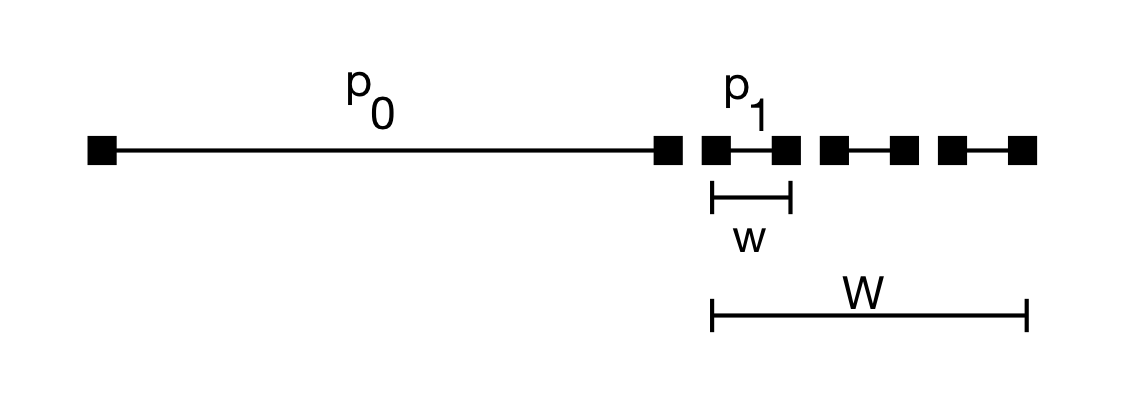
p_\alpha = (1-\alpha)p_0+\alpha p_1
\mathrm{D}((1-\alpha)p_0+\alpha p_1\|q)

p_0
p_1
\alpha
Evaluation
We consider an experimental evaluation based on Facebook data, that is, a realistic scenario for which a population of users is sharing posts on Facebook.
For the purpose of this study we have used data extracted from the Facebook-Tracking-Exposed project.
The extracted dataset contained 59188 posts of 4975 timelines, categorised over 10 categories of interest.
We selected two users out of this dataset and considered the total of posts collected for each of them, i.e., their entire timelines.
Evaluation
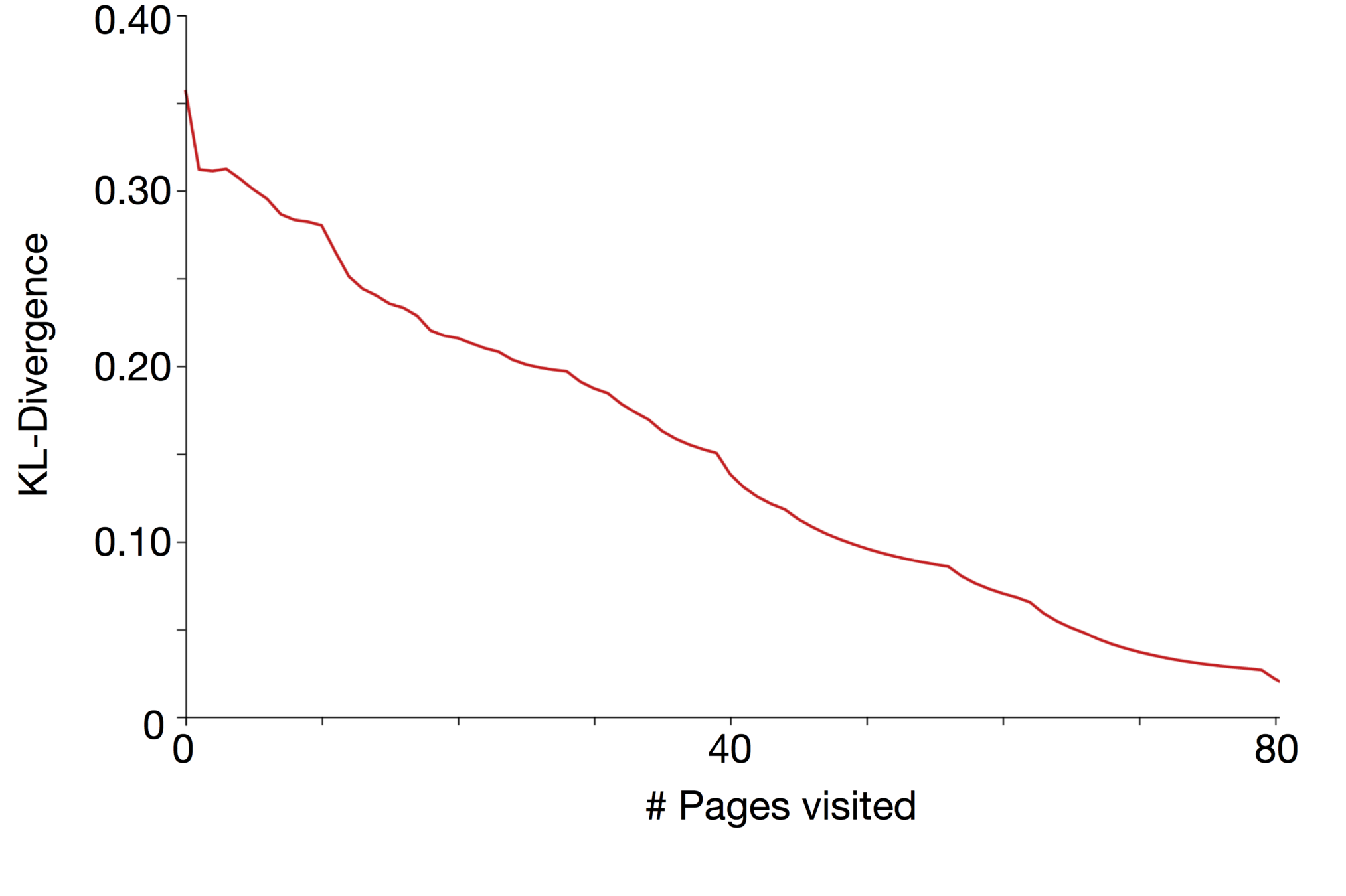
For each user we considered a historical profile comprising of the entirety of their posts minus a window of 15 posts.
Over this window we consider a smaller sliding window for computing the updated profile of 5 posts.
We set the activity parameter:
where L is the total number of posts in the timeline, w represents the sliding window of 5 posts .
This choice captures the idea that we want to simulate how the profile changes when the user shares n new posts.
\alpha = w/L
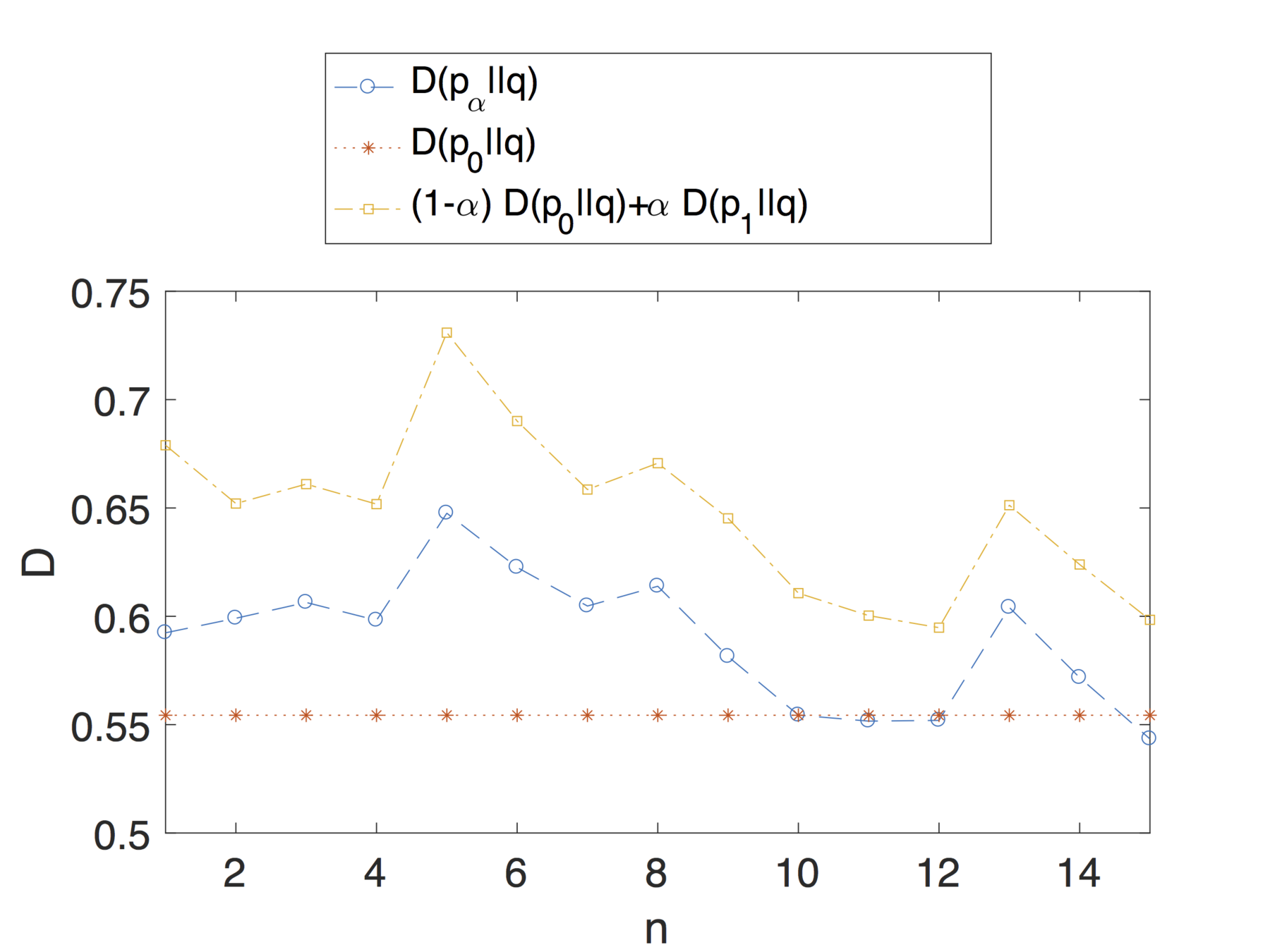
Evaluation
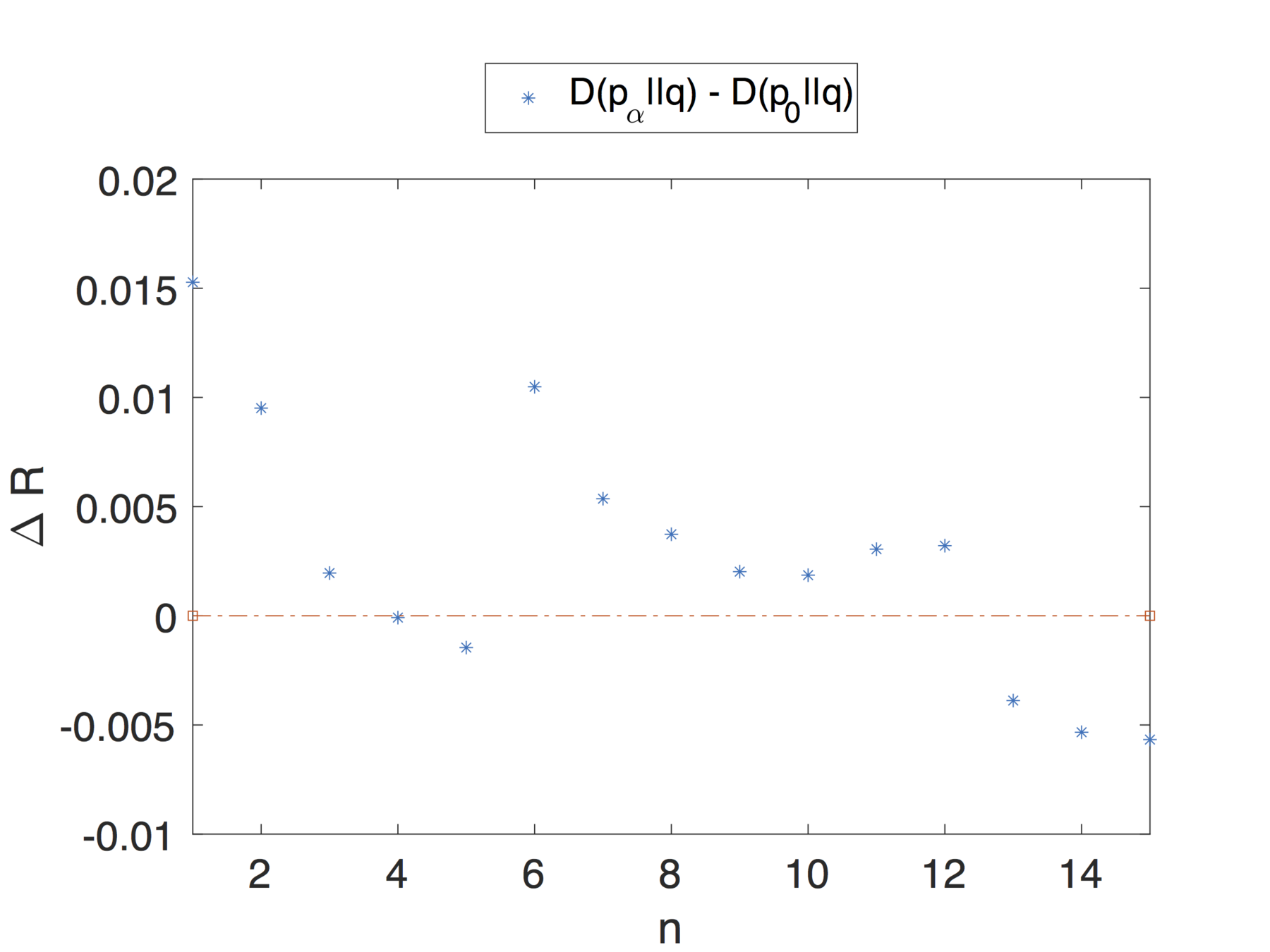
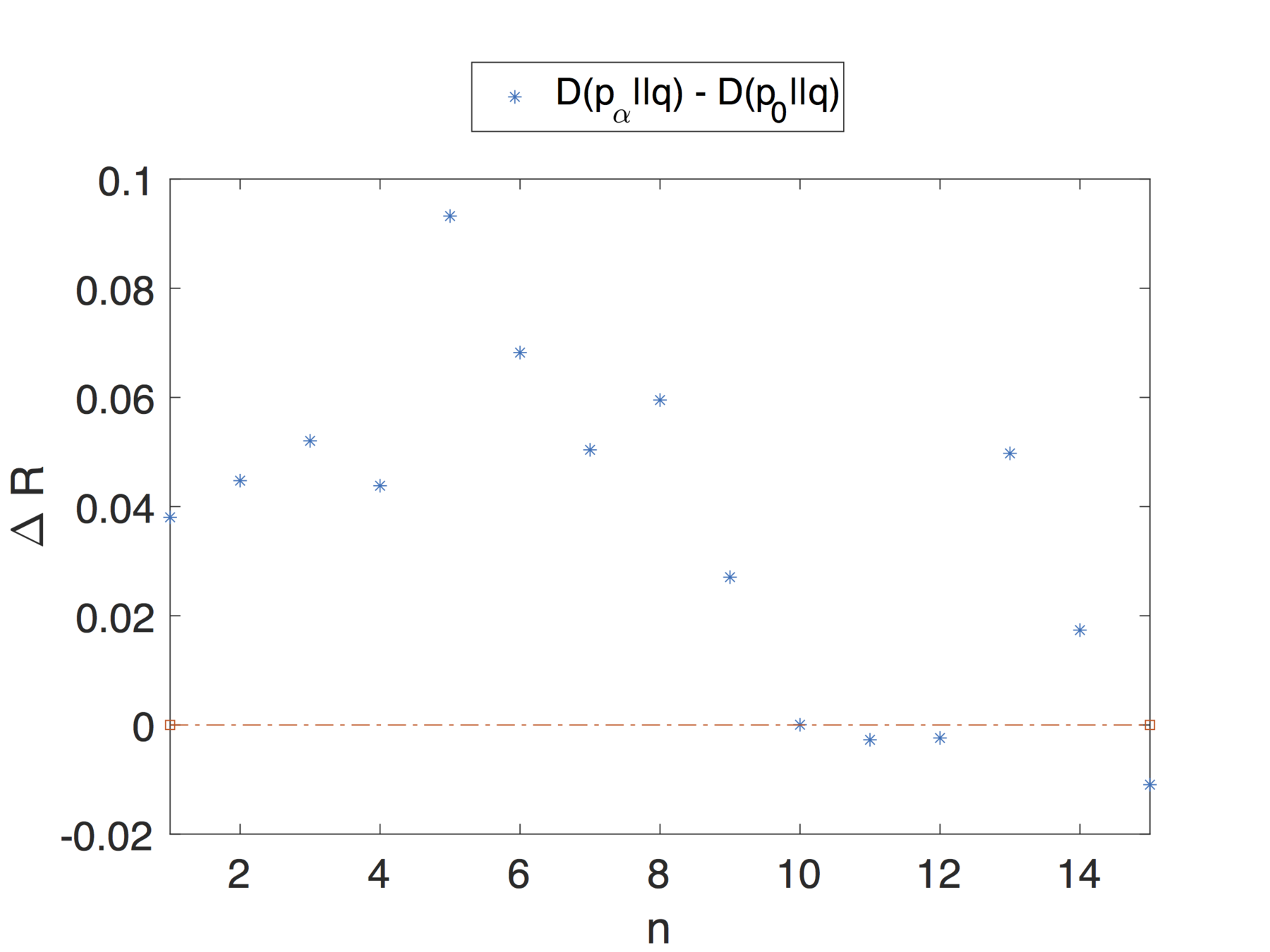
Note that the theoretical analysis and results proposed in this article apply to dynamic profiles that change over time.
We are not simply considering profiles as a snapshot of the user's activity, over a small interval, but we are also taking into account changes in interests and general behaviour that can impact the privacy risk.
Profiles might have different privacy risk in different moments of time.
Conclusions and future work
Conclusions
This dissertation examined a class of privacy issues for online communication, proposing a model for the user identity and a possible new approach to information privacy management.
This work focused on the analysis of privacy violation that can be found in different scenarios, on the web, on mobile applications and, more generally, on communication services.
The motivation behind this work was understanding how data, created by users, flows between applications and services.
Future work
In future work, we would like to explore the possibility to consider how users interacting with web services and applications use hypermedia protocols and therefore, consider their profiles as a collection of hypermedia documents.
We find that this model is able to express the user's online footprint as a collection of traces left across different services.
Furthermore, by using a hypermedia approach we can grasp the connections between the different profiles that the user has created.
Journal articles
S. Puglisi, J. Parra-Arnau, J. Forné, and D. Rebollo-Monedero, "On content-based recommendation and user privacy in social-tagging systems," Computer Standards & Interfaces, vol. 41, pp. 17–27, Sep. 2015. https://doi.org/10.1016/j.csi.2015.01.004
S. Puglisi, D. Rebollo-Monedero and J. Forné, "On web user tracking of browsing patterns for personalised advertising," International Journal of Parallel, Emergent and Distributed Systems, pp. 1–20, 2017, accepted for publication. https://doi.org/10.1080/17445760.2017.1282480
S. Puglisi, D. Rebollo-Monedero and J. Forné, "On the anonymity risk of time-varying user profiles," Entropy, vol. 19, no. 5, 2017. https://www.mdpi.com/1099-4300/19/5/190. DOI: 10.3390/e19050190.
Conference articles
S. Puglisi, D. Rebollo-Monedero and J. Forné, "Potential mass surveillance and privacy violations in proximity-based social applications," in Proc. IEEE Int. Conference on Trust, Security and Privacy (TrustCom), Helsinki, Finland, Aug. 2015, pp. 1045–1052. https://doi.org/10.1109/Trustcom.2015.481
S. Puglisi, D. Rebollo-Monedero and J. Forné, "You Never Surf Alone. Ubiquitous Tracking of Users’ Browsing Habits," in Proc. International Workshop on Data Privacy Management (DPM), ser. Lect. Notes Comput. Sci. (LNCS), vol. 9481, Vienna, Austria, Sep. 2015, pp. 273–280. https://doi.org/10.1007/978-3-319-29883-2\_20
S. Puglisi, D. Rebollo-Monedero and J. Forné, "On Web user tracking: How third-party HTTP requests track users' browsing patterns for personalised advertising," in Proc. IFIP Mediterranean Ad Hoc Networking Workshop (MedHocNet), Vilanova i la Geltrú, Spain, Jun. 2016, pp. 1–6. https://doi.org/10.1109/MedHocNet.2016.7528432
Complementary
S. Puglisi, "RESTful Rails Development: Building Open Applications and Services," O'Reilly Media, Inc., 2015
Puglisi, Silvia, Ángel Torres Moreira, Gerard Marrugat Torregrosa, Mónica Aguilar Igartua, and Jordi Forné. "MobilitApp: Analysing mobility data of citizens in the metropolitan area of Barcelona." In Internet of Things. IoT Infrastructures: Second International Summit, IoT 360° 2015, Rome, Italy, October 27-29, 2015. Revised Selected Papers, Part I, pp. 245-250. Springer International Publishing, 2016.
Complementary
Fouce, Sergi Casanova, Silvia Puglisi, and Mónica Aguilar Igartua. "Design and implementation of an Android application (MobilitApp+) to analyze the mobility patterns of citizens in the Metropolitan Region of Barcelona." M.Sc. Thesis arXiv preprint arXiv:1503.03452 (2015).
Torregrosa, Gerard Marrugat, Monica Aguilar Igartua, and Silvia Puglisi. "Improvement of algorithms to identify transportation modes for MobilitApp, an Android Application to anonymously track citizens in Barcelona." M.Sc. Thesis arXiv preprint arXiv:1605.05342 (2016).
Thank you
The only way to deal with an unfree world is to become so
absolutely free that your very existence is an act of rebellion.Albert Camus
Analysis, Modelling and Protection of Online Private Data
By hiropaw


