Connection between adversarial robustness and differential privacy
Certified Robustness to Adversarial Examples with Differential Privacy
Current Defenses
- Best effort defense
- Disadvantages: Often broken by more advanced attacks, no security guarantees.
- Only Madry's adversarial training not consider broken.
- But it cannot scale to large networks.
- Certified defense
- Disadvantages: not scalable, not generic.
- Can only be used on small and specific DNNs.
Contribution of this paper
- establish the DP-robust connection
- propose PixelDP, the first certified defense based on DP
- the first evaluation of an ImageNet-scale certified adversarial-examples defense
- PixelDP's advantage: broadly applicable, generic, and scalable
Definitions - Adv ML
- model \(f: \R \rightarrow \mathcal K\)
- \(\mathcal K=\{1, \cdots, K\}\)
- Scoring function \(y(x) = (y_1(x), \cdots, y_K(x))\)
- \(\sum_{k=1}^K y_k(x)=1\)
- \(f(x) = \arg \max_{k \in \mathcal K} y_k(x)\)
- \(B_p(r) = \{\alpha \in \R^n:\lVert \alpha \rVert_p \le r \}\)
Definitions - Adv ML
- \(f\) is robust to attacks of \(p\)-norm \(L\) on a given \(x\) if:$$\forall \alpha \in B_p(L): y_k(x + \alpha) > \max_{i:i\neq k} y_i(x + \alpha)$$
- where \(k=f(x)\)
Definitions - DP
- A randomized algorithm \(A\) that takes database \(d\) as input, and outputs a value in \(O\) is \((\epsilon, \delta)\)-DP with respect to metric \(\rho\) if \(\forall \rho(d, d')\le 1, S \subseteq O:\)$$P(A(d) \in S) \le e^\epsilon P(A(d') \in S) + \delta$$
- The same definition taught in class.
Properties - DP
- Post processing property:
Any computation applied to the output of an \((\epsilon, \delta)\)-DP algorithm remains \((\epsilon, \delta)\)-DP. - Expected output stability property: Expected output of \((\epsilon, \delta)\)-DP algorithm with bounded output is stable.
Properties - DP
- Expected output stability property: Expected output of \((\epsilon, \delta)\)-DP algorithm with bounded output is stable.
if the output of \(A\) is bounded to \([0, b]\). - Proof via $$\mathbb E (A(x)) = \int_0^bP(A(x) > t)dt$$
\forall \alpha \in B_p(1):\mathbb E(A(x))\le e^\epsilon \mathbb E(A(x + \alpha)) + b \delta
DP-Robust Connection
- Regard an input image as a database of features (pixels).
- Construct a scoring function that is DP with regard to the pixels.
- Recall the scoring function:$$y(x)=(y_1(x), \cdots, y_K(x))$$
- If the scoring function is \((\epsilon, \delta)\)-DP for a given metric, we say it is \((\epsilon, \delta)\)-PixelDP.
- Why use a new name?
Corollary 1
- Suppose \(A\) satisfies \((\epsilon, \delta)\)-PixelDP with respect to a \(p\)-norm metric, and \(A=(y_1(x), \cdots, y_K(x))\), since \(y_k(x) \in [0, 1]\):
by the expected output stability property. - The expected value of each class's scoring function is bounded with regard to perturbation.
\forall k, \forall \alpha \in B_p(1): \mathbb E(y_k(x)) \le e^\epsilon \mathbb E(y_k(x + \alpha)) + \delta
Robustness Condition
- Consider any \(\alpha \in B_p(1), x' = x + \alpha,k=f(x)\)
- By Corollary 1:
- \(\mathbb E(A_k(x)) \le e^\epsilon \mathbb E(A_k(x')) + \delta\)
- \(\mathbb E(A_i(x')) \le e^\epsilon \mathbb E(A_i(x)) + \delta, i \ne k\)
- \(\mathbb E(A_k(x'))\) is lower-bounded
- \(\max_{i \ne k} \mathbb E(A_i(x'))\) is upper-bounded
- If the latter is less than the former, the prediction using expected value of scoring function is robust!
Robustness Condition
- A sufficient condition (robust condition):
- If this condition holds, the classifier is exactly robust for input \(x\), this is not a high probability condition.
- Later we'll see that, PixelDP's probability comes from the approximation of the expected value, not the DP algorithm.
\mathbb E(A_k(x)) > e^{2\epsilon} \max_{i:i\ne k}\mathbb E(A_i(x)) + (1 + \epsilon)\delta
Robustness Condition
- In practice, we do not know how to calculate the exact expected value.
- We can use sample mean \(\mathbb {\hat E}(A(x))\) to set up a confidence interval we believe containing the true expected value.
- Goal:
we want to find a bound \([\mathbb {\hat E}^{lb}(A(x)), \mathbb{\hat E}^{ub}(A(x))]\) that contains \(\mathbb E(A(x))\) with probability \(\eta\)
Hoeffding's Inequality
- If \(X_i\)'s are independent and bounded by \([0, 1]\):$$P(|\bar X - \mathbb E[\bar X]| \ge t) \le 2 \exp(-2nt^2)$$
- Let \(2 \exp(-2nt^2) = 1 - \eta\), we can obtain
$$t=\sqrt{\frac{1}{2n}\ln\frac{2}{1 - \eta}}$$ - Random draws of \(A(x)\)s are independent and bounded by \([0, 1]\)
- So by Hoeffding's inequality, we can obtain the bound
\([\mathbb{\hat E}^{lb}(A(x)), \mathbb{\hat E}^{ub}(A(x))]=[\mathbb{\hat E}(A(x)) - t,\mathbb{\hat E}(A(x)) + t]\)
Robustness Condition
- The generalized robust condition:
- If this condition holds, the classifier is robust for input \(x\) with probability \(\ge \eta\)
- The failure probability comes from the estimation of the expected value, not from DP.
- It can be made arbitrarily small by increasing draws.
\mathbb{\hat E}^{lb}(A_k(x)) > e^{2\epsilon} \max_{i:i\ne k}\mathbb{\hat E}^{ub}(A_i(x)) + (1 + \epsilon)\delta
Robustness Condition
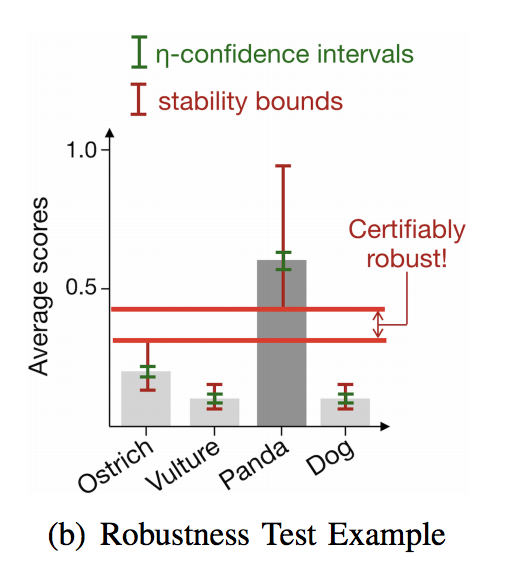
PixelDP Architecture
- Adds calibrated noise to turn Q into an (\(\epsilon\),\(\delta\))-DP randomized function \(A_Q\) (Q has unbounded sensitivity)
\(Q(x) = h(g(x))\)
\(A_Q(x)\)= \(h(\hat g + noise\)) \(\hat g\) has fixed sensitivity to inputs. - The expected output will have bounded sensitivity to p-norm changes in input by adding the noise layer after g.
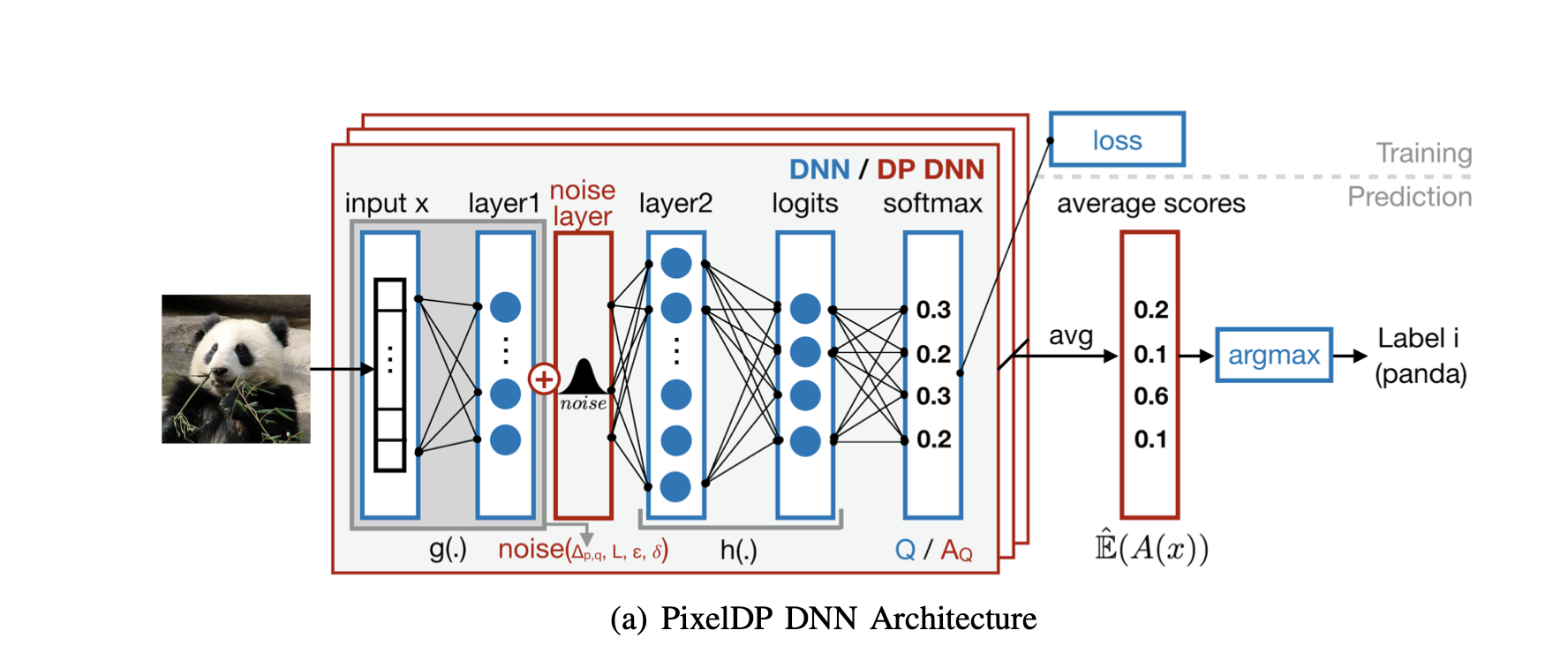
PixelDP Architecture (cont'd)
- Use Monte Carlo to estimate the output expectations in prediction time.
- Get the \(\eta\)-confidence interval. If the lower bound of the label with top score is greater than every other label's upper bound \(\rightarrow\) The prediction of x is robust to any p-norm attack L
- Error probability \(1 - \eta\) can be make really small for increasing the invocation numbers.
Sensitivity
For a function f: D\(\mapsto\)\(\R^k\)
on datasets D₁, D₂ differing on at most one element
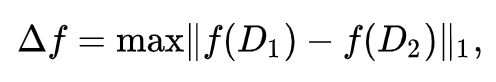
Sensitivity
The sensitivity of function g(pre-noise layers) => the maximum change in output that can be produced by a change in the input. (input: p-norm, output: q-norm)
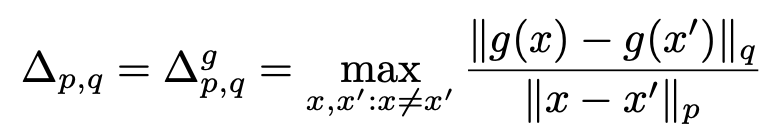
Why do we need to bound sensitivity
- Adversarial examples are from the the unbounded sensitivity of Q.
- We have to bound or fix the sensitivity or else the training procedure will change the sensitivity significantly which voids the DP guarantees .
DP noise layer
- Uses Laplace and Gaussian mechanisms(both rely on bounded sensitivity).
- Laplace noise with µ = 0 and \(\sigma\ = \sqrt{2}\Delta_{p,1}L/\epsilon\) which gives (\(\epsilon\),0)-DP
- Gaussian noise with µ = 0 and \(\sigma\ = \sqrt{2(\ln{\frac{1.25}{\delta}})}\Delta_{p,2}L/\epsilon\) which gives (\(\epsilon,\delta\))-DP
- For every x, the layer computes g(x)+ Z, where Z is the independent random variable from the noise distribution
- Where to place this layer? => Choose a location that the computation of sensitivity of the pre-noise function is easier to do. (Post-processing of DP carries the guarantee to the end.)
DP noise layer (cont'd)
- Noise in the image => trivial sensitivity analysis. \(\Delta_{1,1}\) = \(\Delta_{2,2}\) = 1
- Noise after the first layer => For 1-norm and 2-norm attack, \(\Delta_{p,q}\) when p=1 or 2 q = 1 or 2 is easy to compute. However, for ∞-norm attacks computing a tight bound for \(\Delta_{∞,2}\) is computation hard, so we use a relatively loose bound which results not as good as 1-norm or 2-norm attacks.
DP noise layer (cont'd)
- Noise deeper in the network => Difficult to generalize for the sensitivity analysis for combining bounds.
- Noise in autoencoder => Add noise before the DNN in a separately trained autoencoder. Stack the autoencoder before the predictive DNN.
- Smaller and easier to train which leads to a first certified model for large Imagenet dataset
- Holds DP with post-processing property.
- Also easy to compute the sensitivity.
Certified Prediction
- Prediction choose the argmax label based on Monte Carlo estimation of E(A(x)) => \(\hat E\)(A(x)), which can be obtained by invoking A(x) multiple times.
- PixelDP not only returns the prediction for x but also a robustness size certificate for the prediction.
- PixelDP gives the maximum attack size \(L_{max}\) (in p-norm) against which the prediction on x is guaranteed to be robust by robustness condition.
Evaluation
- How does DP noise affect model accuracy?
- What accuracy can PixelDP certify?
- What is PixelDP’s computational overhead
How does DP noise affect the model
Larger L = robustness against larger attacks = larger noise std
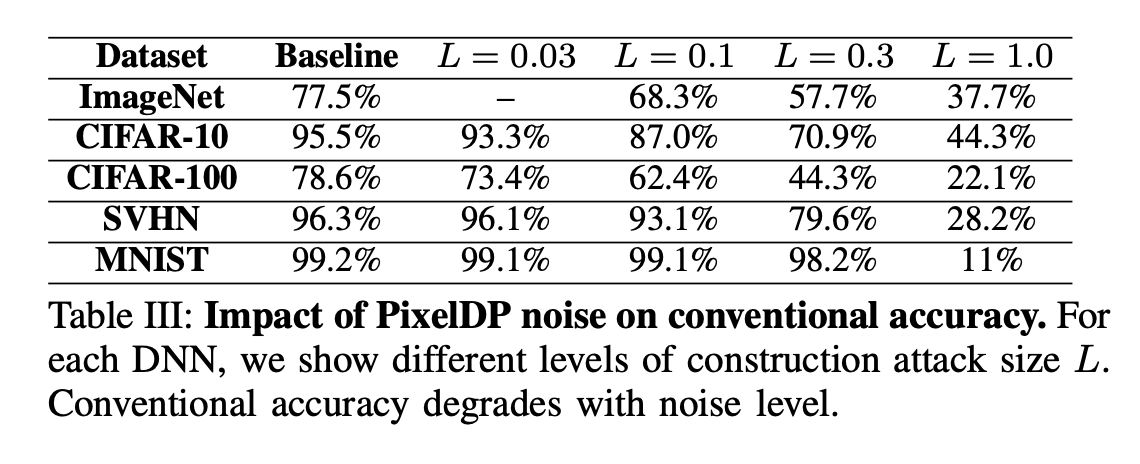
What accuracy can PixelDP cerifify
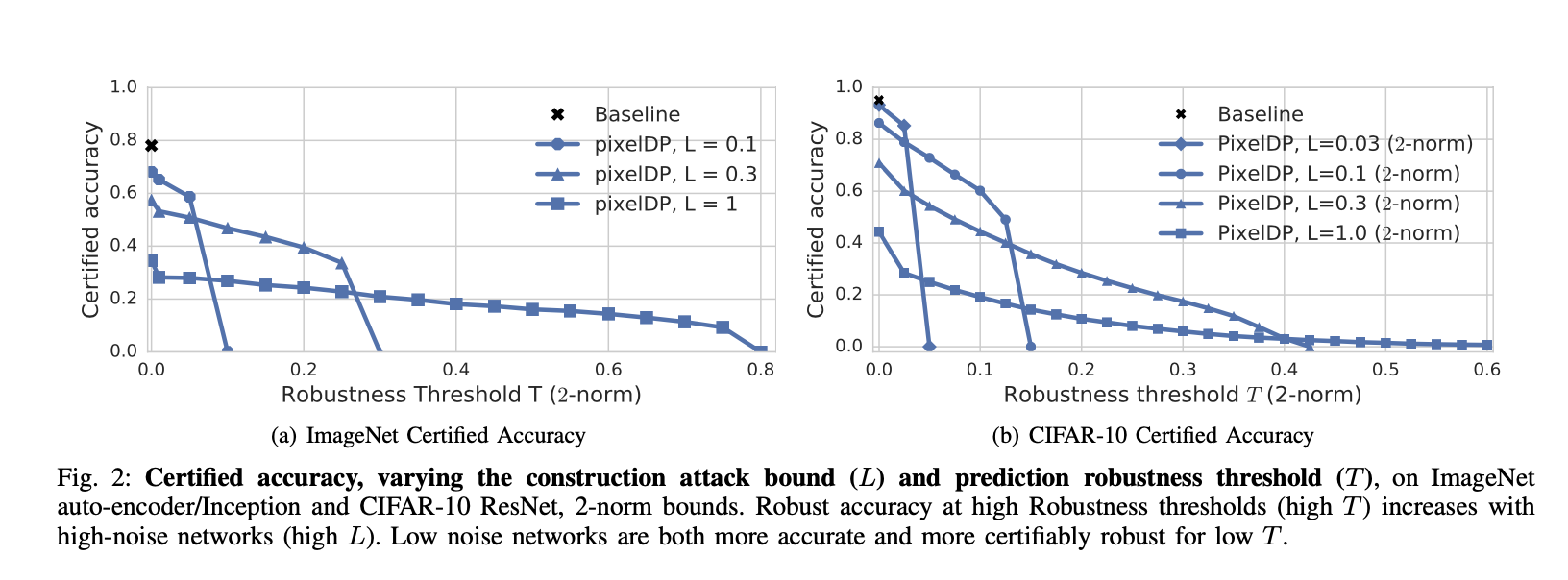
Computational Overhead
- For training, CIFAR-10 ResNet baseline takes on average 0.65s per training step. => PixelDP versions take at most 0.66s per training step (1.5% overhead).
- Sample time.
- Significant benefit over Madry's work(adversarial training)
Conclusion
- This work demonstrates the connection between robustness against adv. examples and DP.
- The certified defense against attacks is:
- As effective at defending 2-norm attacks as today's state-of-the-art.
- More scalable and applicable to large networks.
- It is the first work to evaluate the certified 2-norm defense on ImageNet dataset.
- Future work: Infinity norm attacks can be improved by designing a tighter bound for the sensitivity.
A unified view on differential privacy and robustness to adversarial examples
Renyi Divergence
\( D_\lambda(\mu_1,\mu_2) := \dfrac{1}{\lambda-1} \log \int_{\mathcal{Y}}g_2(y)(\dfrac{g_1(y)}{g_2(y)})^{\lambda}d\mathcal{V}(y) \)
\( Where\ g_1\ and\ g_2\ are\ the\ probability\ density\ of\ \mu_1,\ and\ \mu_2\\ with\ respect\ to\ \mathcal{V} \)
On Measures of Entropy and Information
RENYI, A.
- Renyi Divergence
\( D_{\lambda}(P\|Q) := \dfrac{1}{\lambda-1}\log{E_{x \sim Q}(\dfrac{P(x)}{Q(x)})^{\lambda}} \)
- Kullback-Leibler Divergence
\( D_1(P\|Q) = E_{x \sim P}\log\dfrac{P(x)}{Q(x)} \)
- Maximum Divergence
\( D_{\infty}(P\|Q) = \sup\limits_{x \in supp\ Q}\log\dfrac{P(x)}{Q(x)} \)
\( For\ two\ probability\ distributions\ P\ and\ Q\ defined\ over\ \mathcal{R} \)
Definition -
Classical differential privacy
\( Let\ \mathcal{X}\ be\ a\ space\ of\ databases,\ \mathcal{Y}\ an\ output\ space,\ and\ \sim_h\ denoting\ the\ that\ two\ databases\ from\ \mathcal{X}\ only\ differ\ from\ one\ row.\\ A\ probabilistic\ mapping\ \mathcal{M}\ from\ \mathcal{X}\ to\ \mathcal{Y}\ is\ called\\ differentially\ private\ if\ for\ any\ x,x' \in \mathcal{X}\ s.t.\ x \sim_h x' and\\ for\ any\ Y \in \sigma(\mathcal{Y})\ on\ has\ \mathcal{M}(x)(Y) \le \exp(\epsilon)\mathcal{M}(x')(Y). \)
The algorithmic foundations of differential privacy.
Dwork, C., Roth, A.
Definition -
Metric differential privacy
\( Let\ \epsilon > 0,\ (\mathcal{X},d_{\mathcal{X}})\ an\ arbitrary\ (input)\ metric\ space,\ and\\ \mathcal{Y}\ an\ output\ space.\ A\ probabilistic\ mapping\ \mathcal{M}\ from\ \mathcal{X}\ to\ \mathcal{Y}\\ is\ called\ (\epsilon,\alpha)\)-\(d_{\mathcal{X}}\ private\ if\ for\ any\ x,x'\\ s.t.\ d_{\mathcal{X}}(x,x') \le \alpha,\ one\ has\ D_{\infty}(\mathcal{M}(x),\mathcal{M}(x')) \le \epsilon. \)
Broadening the scope of differential privacy using metrics.
Chatzikokolakis, K., Andrés, M.E., Bordenabe, N.E., Palamidessi, C.
Definition -
Renyi differential privacy
\( Let\ \epsilon > 0,\ (\mathcal{X},d_{\mathcal{X}})\ an\ arbitrary\ (input)\ metric\ space,\ and\\ \mathcal{Y}\ an\ output\ space.\ A\ probabilistic\ mapping\ \mathcal{M}\ from\ \mathcal{X}\ to\ \mathcal{Y}\\ is\ called\ (\lambda,\epsilon,\alpha)\)-\(d_{\mathcal{X}}\ Renyi\)-\(private\ if\ for\ any\\ x,x'\ s.t.\ d_{\mathcal{X}}(x,x') \le \alpha,\ one\ has\ D_{\lambda}(\mathcal{M}(x),\mathcal{M}(x')) \le \epsilon. \)
Renyi Differential Privacy
Mironov, I.
Definition -
Adversarial robustness
\( A\ classifier\ h\ is\ said\ to\ be\ (\alpha,\gamma)\)-\(robust\\ if\ \mathbb{P}_{x \sim D_{\mathcal{X}}}[\exists x' \in B(x,\alpha)\ s.t.\ h(x') \ne h(x)] \le \gamma \)
Definition -
Generalized adversarial
\( Let\ D_{\mathcal{P}(\mathcal{Y})}\ be\ a\ metric/divergence\ on\ \mathcal{P}(\mathcal{Y}).\\ A\ randomized\ classifier\ \mathcal{M}\ is\ said\ to\ be\\ D_{\mathcal{P}(\mathcal{Y})}\)-\( (\alpha,\epsilon,\gamma)\)-\( robust\ if\\ \mathbb{P}_{x \sim D_{\mathcal{X}}}[\exists x' \in B(x,\alpha)\ s.t.\ D_{\mathcal{P}(\mathcal{Y})}(\mathcal{M}(x'),\mathcal{M}(x)) > \epsilon] \le \gamma \)
Theoretical evidence for adversarial robustness through randomization
Claim: Equivalent
\( D_{\lambda}\)-\((\alpha,\epsilon,0)\)-\(robust\\ \Leftrightarrow\\ D_{\mathcal{X}}\)-\(almost\ surely\\ (\lambda,\epsilon,\alpha)\)-\(d_{\mathcal{X}}\ Renyi\)-\(differentially\ private \)
\(x,x'\ s.t.\ d_{\mathcal{X}}(x,x') \le \alpha,\\ D_{\lambda}(\mathcal{M}(x),\mathcal{M}(x')) \le \epsilon \)
\( \mathbb{P}_{x \sim D_{\mathcal{X}}}[\exists x' \in B(x,\alpha)\\ s.t.\ D_{\mathcal{P}(\mathcal{Y})}(\mathcal{M}(x'),\mathcal{M}(x)) > \epsilon] \le \gamma \)
Discussion & QA
SPML Paper Presentation
By Howard Yang



