
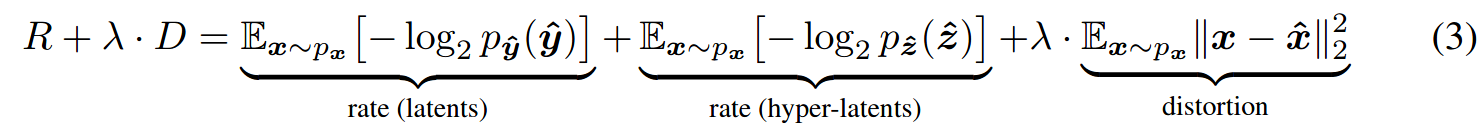
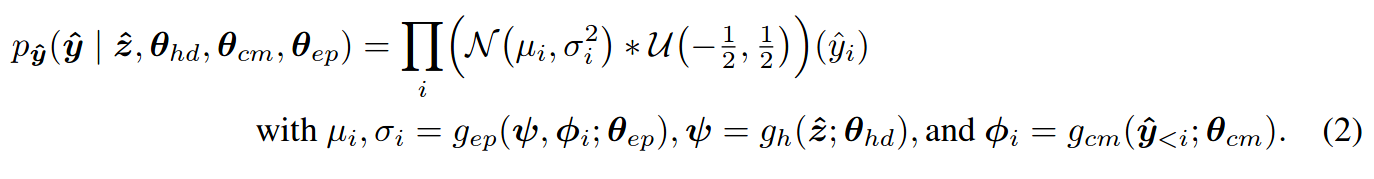
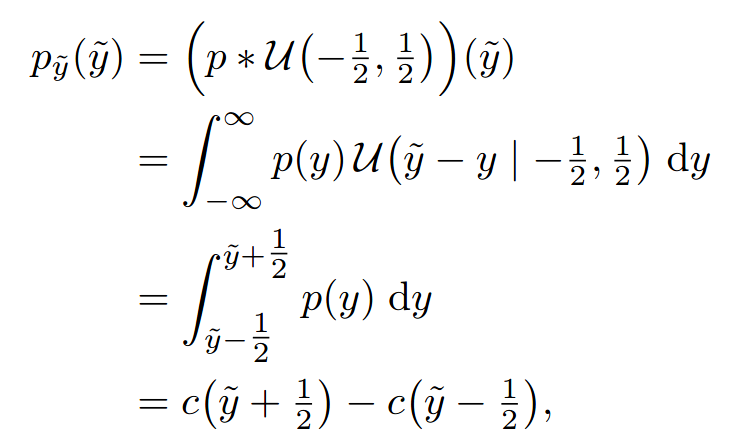
Hugo Hadfield
Cambridge University PhD student, Signal Processing and Communications Laboratory
Summary Presentation of:
Hugo Hadfield
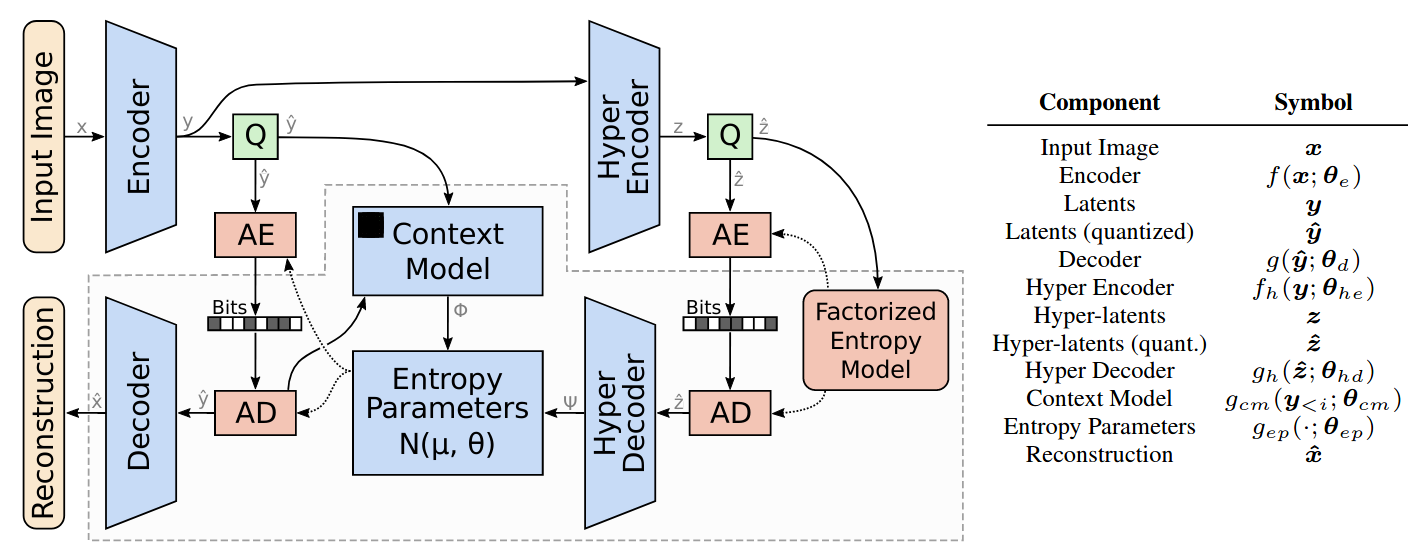
Hyper-prior entropy model learns a family of entropy models, side information in z parameterises where in distribution an image is
Context model allows local context of previously decoded latents to help decode later ones, reduces required amount of information to transmit
Entropy of the latent image bitstream under the model given by the quantised entropy model parameters
Entropy of the hyper-latent bitstream
Error in the reconstructed image
rate-distortion tradeoff weight
Key trick is to substitute quantisation for the addition of uniform noise: convolution with a uniform distribution
This allows us to write down
Where \(c\) is the cumulative density of the underlying model, ie. a normal distribution
By Hugo Hadfield
This presentation is a summary of a paper on deep learning for Image Compression. For more technical content check out my website http://hh409.user.srcf.net




