



























He Wang PRO
Knowledge increases by sharing but not by saving.
第 2 部分 基于 Python 的数据分析基础
主讲老师:王赫
2023/12/07 & 2023/12/10
ICTP-AP, UCAS
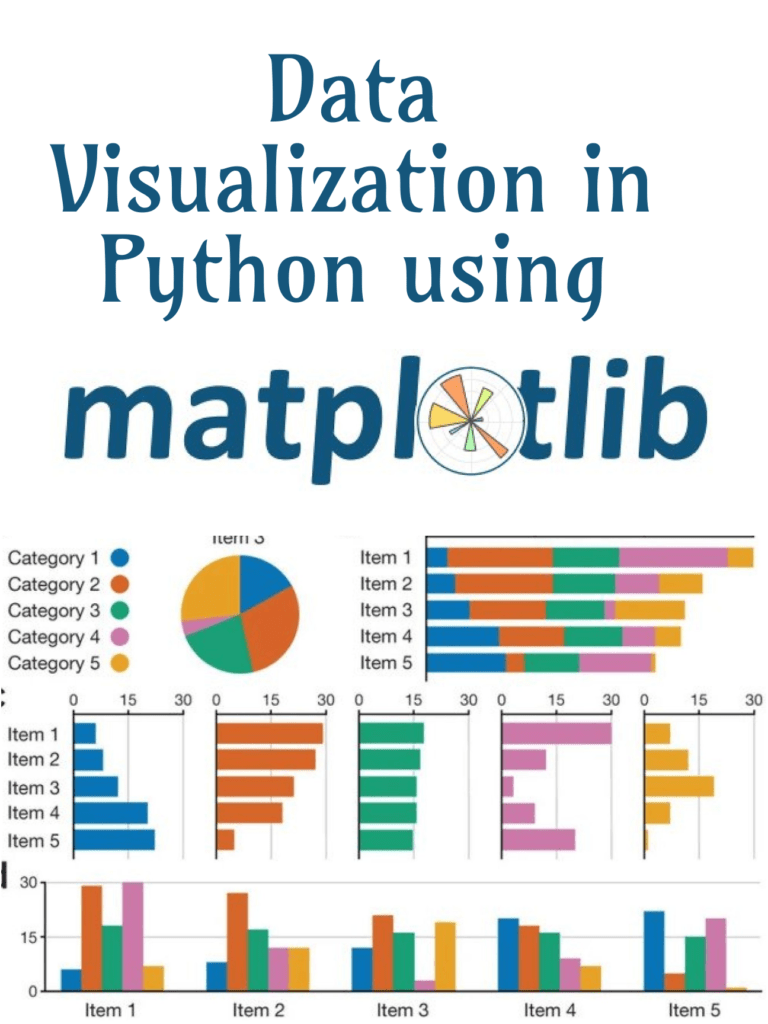
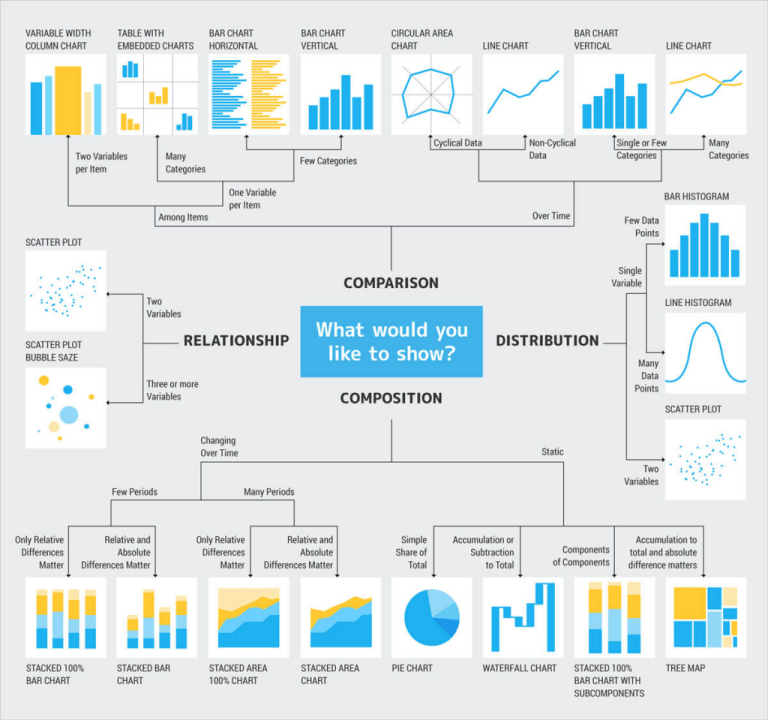
数据分析可视化之 Matplotlib / Seaborn
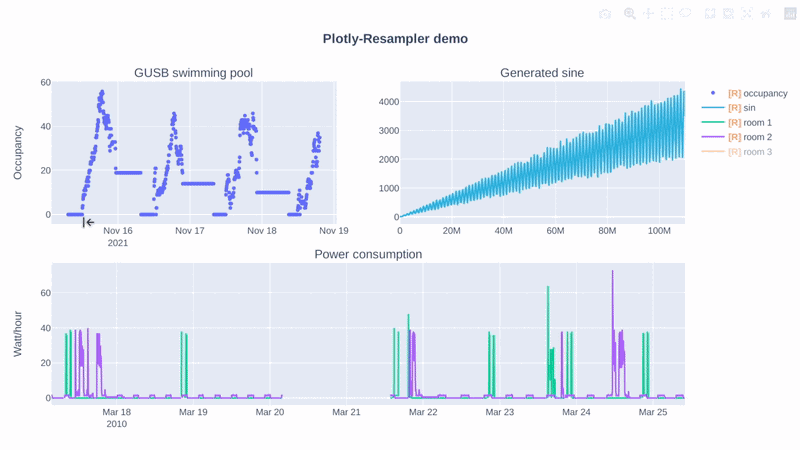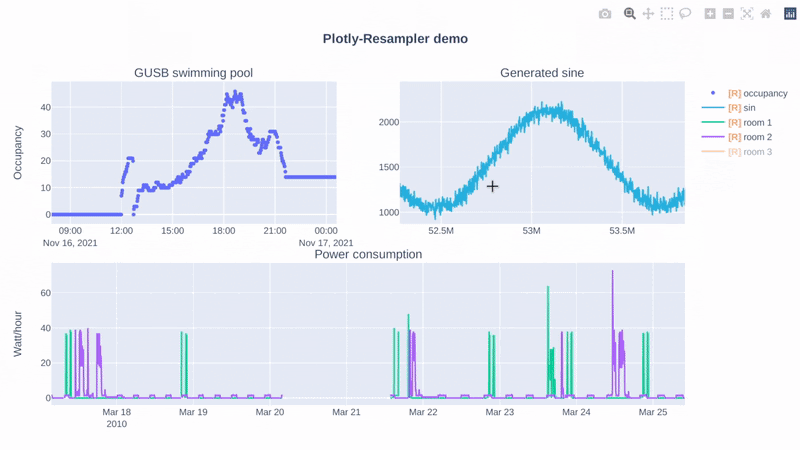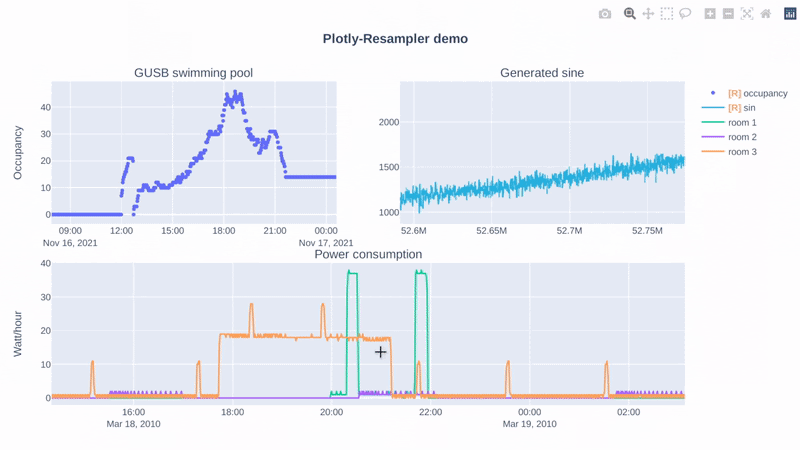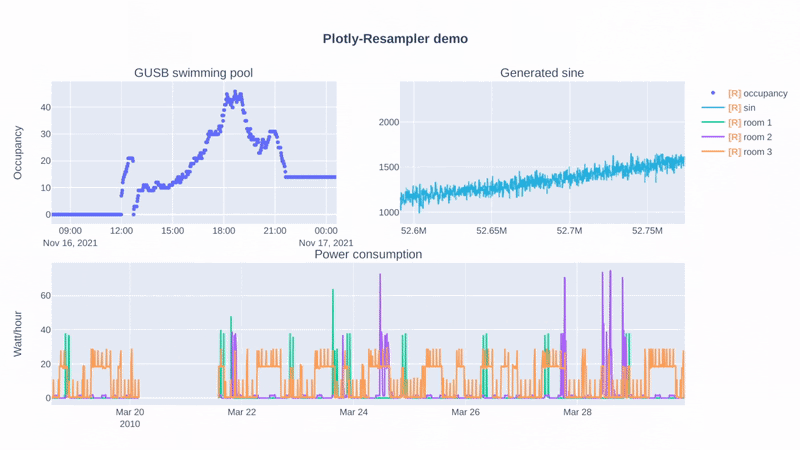
# Response
# Data Visualization
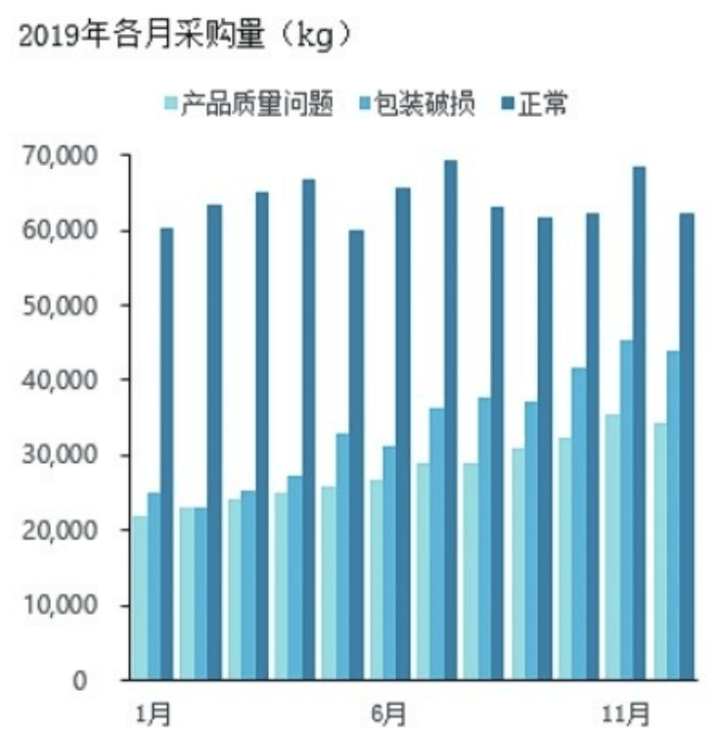
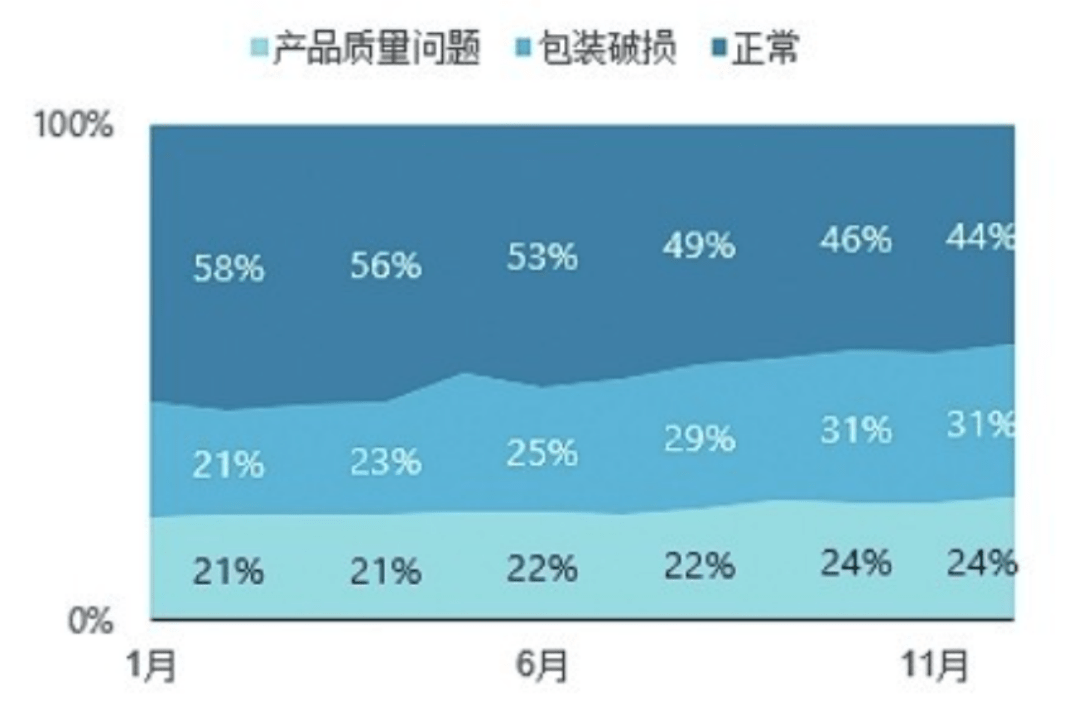
往年的双十一展示用大屏的数据可视化系统实时监控,通过这些数据对网站进行优化、对用户群体进行基本的分析等。
图片来源于网络
数据可视化,是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。
它是一个处于不断演变之中的概念,其边界在不断地扩大。主要指的是技术上较为高级的技术方法,而这些技术方法允许利用图形、图像处理、计算机视觉以及用户界面,通过表达、建模以及对立体、表面、属性以及动画的显示,对数据加以可视化解释。与立体建模之类的特殊技术方法相比,数据可视化所涵盖的技术方法要广泛得多。
# Data Visualization
数据可视化 的巨大需求,带动了诸多领域应用
几乎所有涉及 Data 这个行业的岗位招聘,都会或多或少的涉及到 Data VIsualization 能力的需求,甚至有不少是招专门的数据可视化分析师(Data Visualization Analyst)
工业界
学术界
工商管理
工业界: 以高效性、建设性方式的讨论结果,理解运营管理与业务性能之间的关系,提供直接有效的决策依据。
学术界: 在庞大繁杂的资源环境中,有目的的挖掘数据背后的特征信息,揭示不同思考角度下的潜在客观规律。
# Data Visualization
数据化思维是指根据数据来思考事物的一种思维模式,是一种量化的、重视事实、追求真理的思维模式。
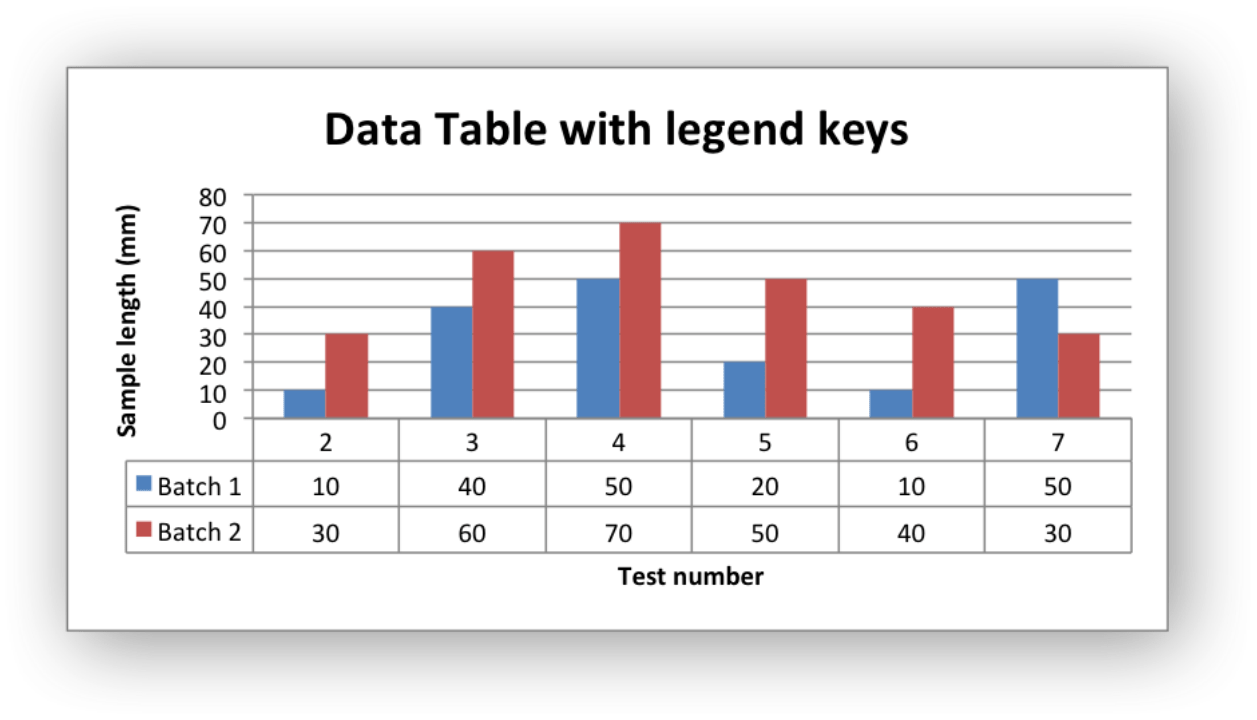
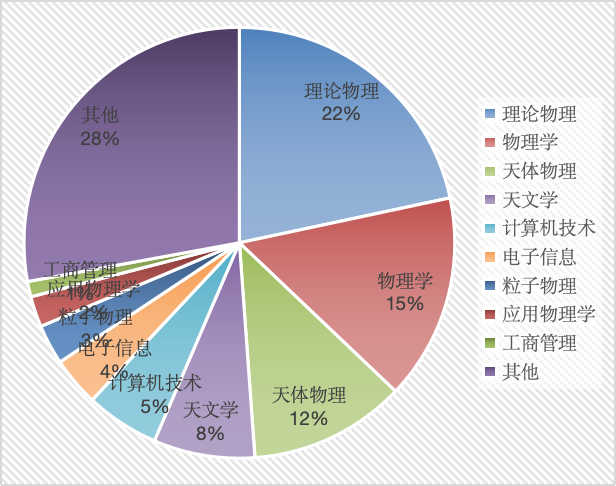
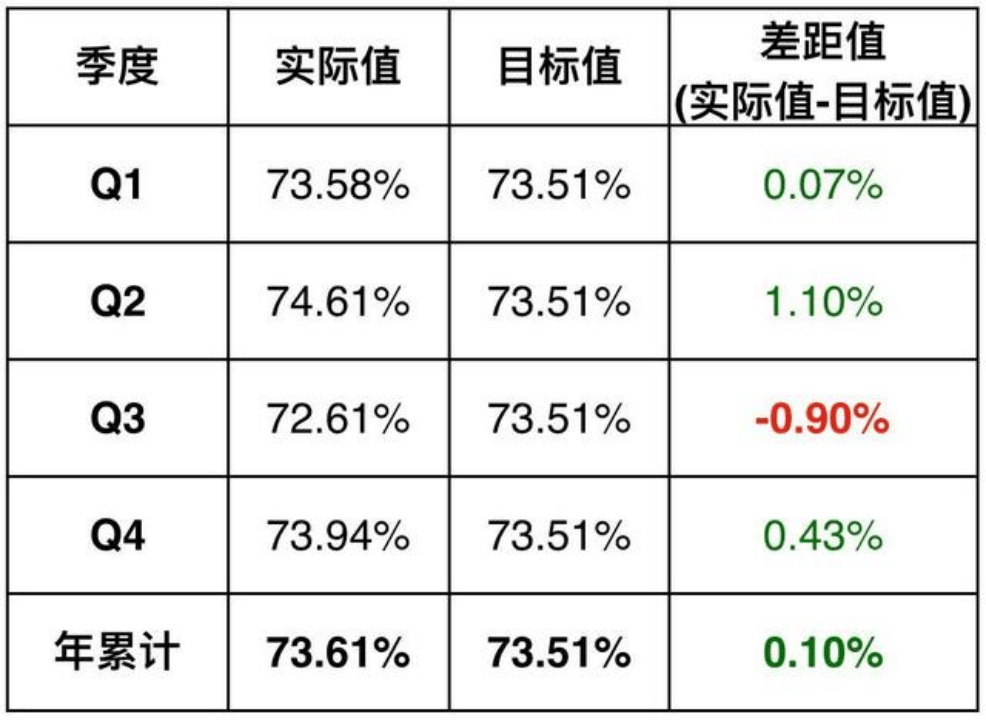
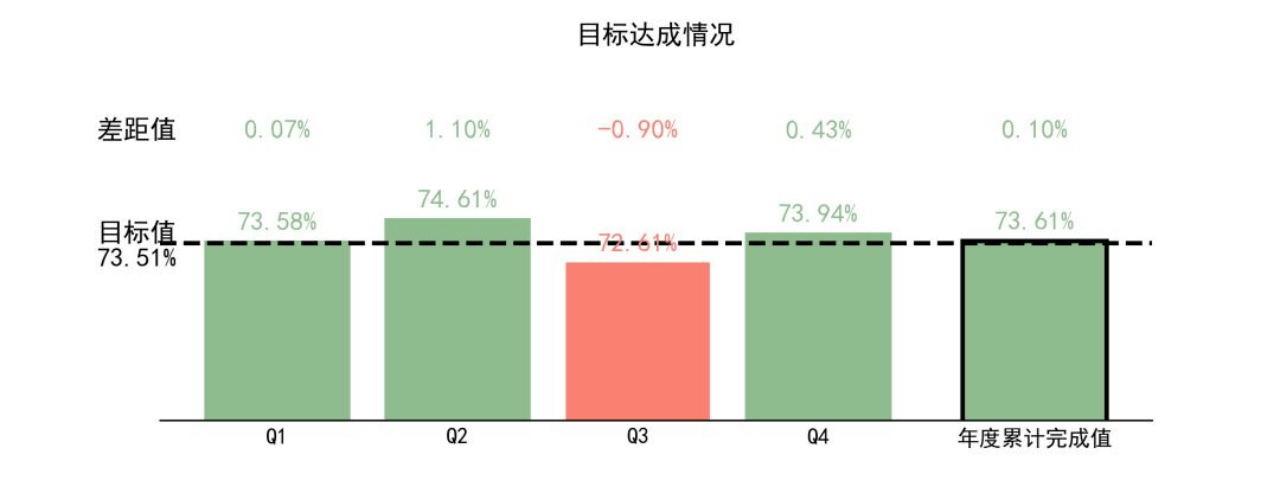
| 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|
| Batch 1 | 10 | 40 | 50 | 20 | 10 | 50 |
| Batch 2 | 30 | 60 | 70 | 50 | 40 | 30 |
数据
结论
数据分析
数据
结论
数据分析
数据可视化
# Data Visualization
以高效性、建设性方式的讨论结果,理解运营管理与业务性能之间的关系,提供直接有效的决策依据
在庞大繁杂的资源环境中,有目的的挖掘数据背后的特征信息,揭示不同思考角度下的潜在客观规律
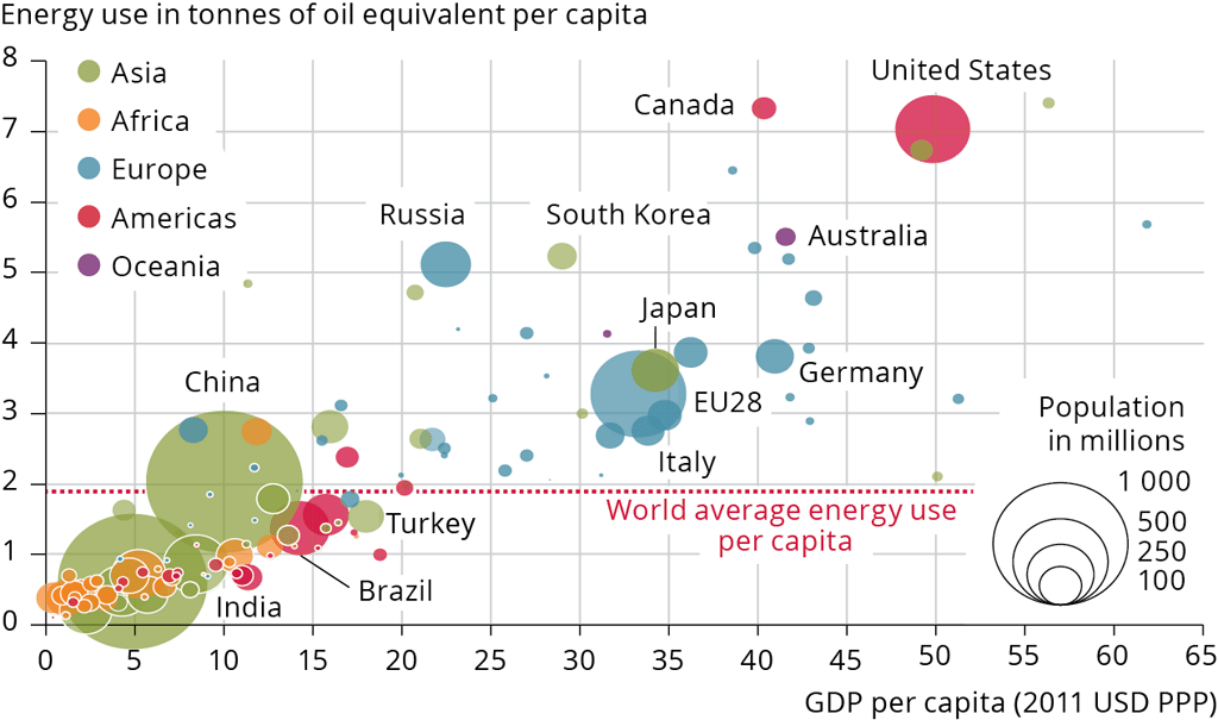
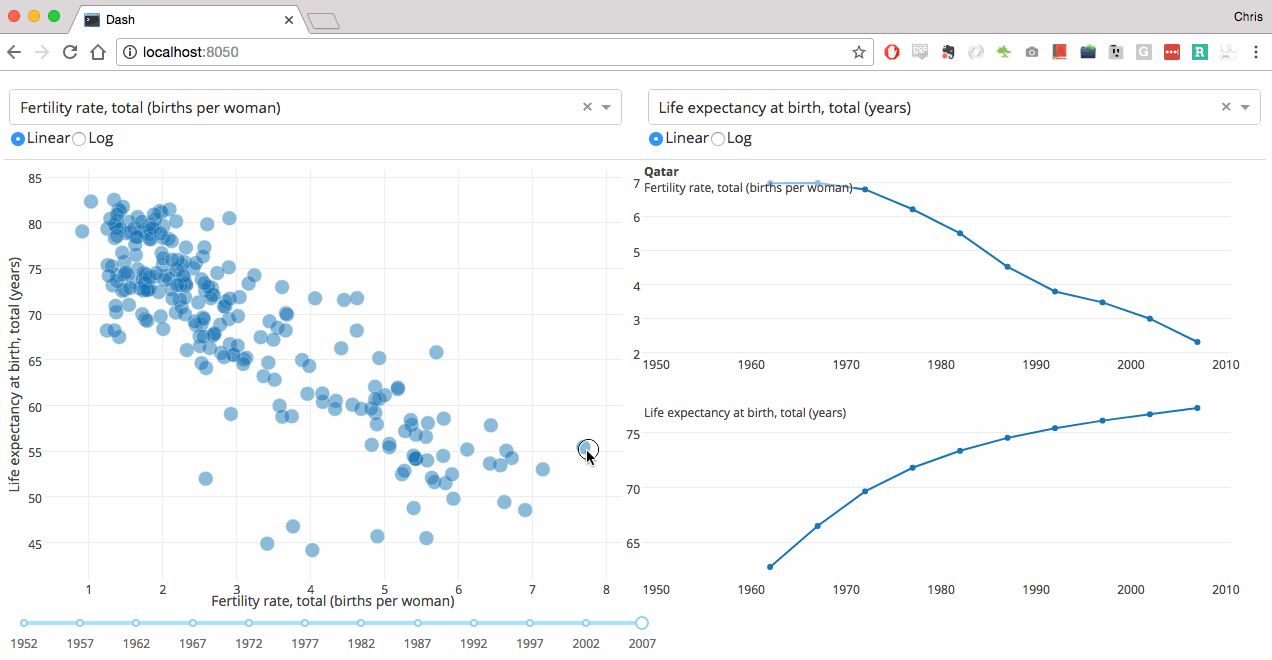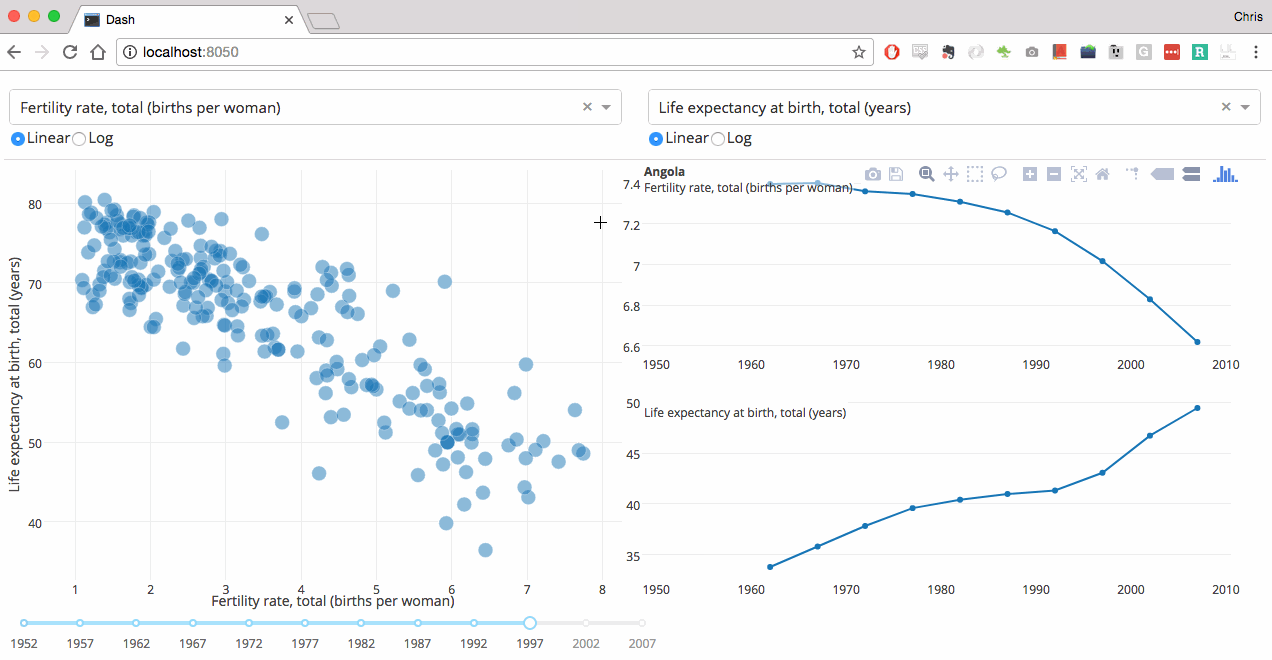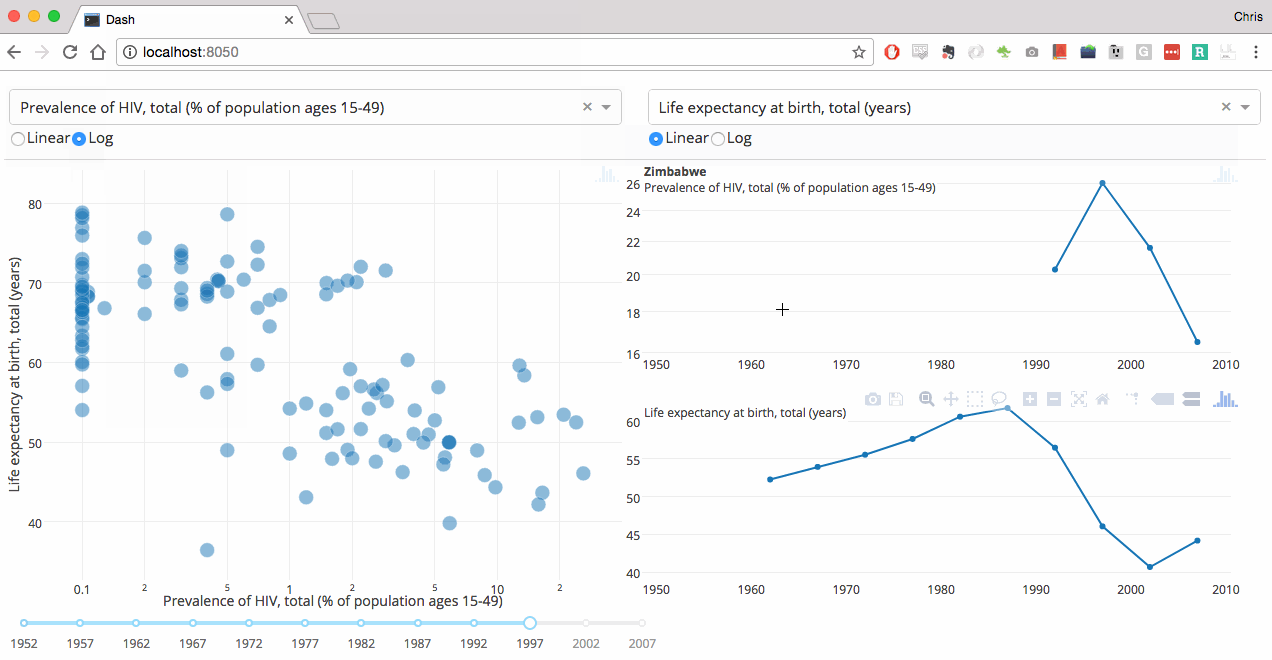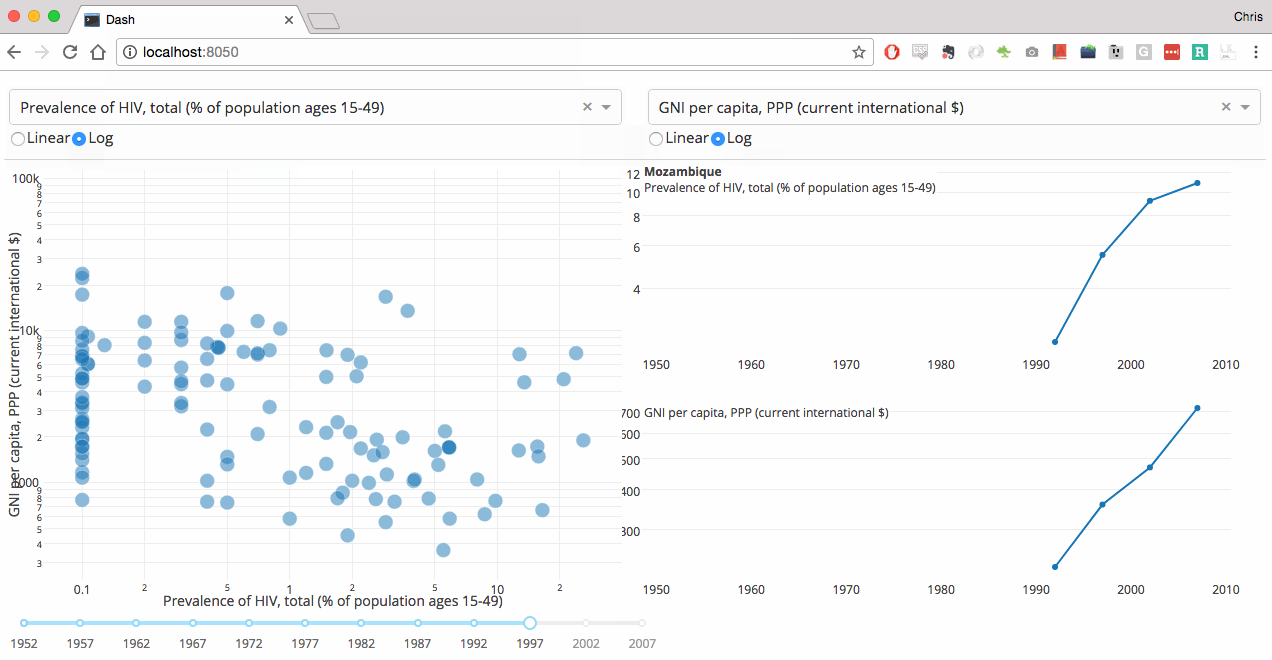
Data source: World Bank World development indicators Note: The graph shows the correlation of national per capita energy consumption and per capita GDP.
The size of the bubbles denotes total population per country. All values refer to the year 2011.
Level 1 有强烈的用可视化技术去呈现分析结果的欲望
Level 2 针对具体的问题能够快速确定可视化实施方案
Level 3 养成一种能用图说清楚的事绝不用文字的习惯
Level 4 有意识地提升可视化结果的审美和自解释属性
# Data Visualization
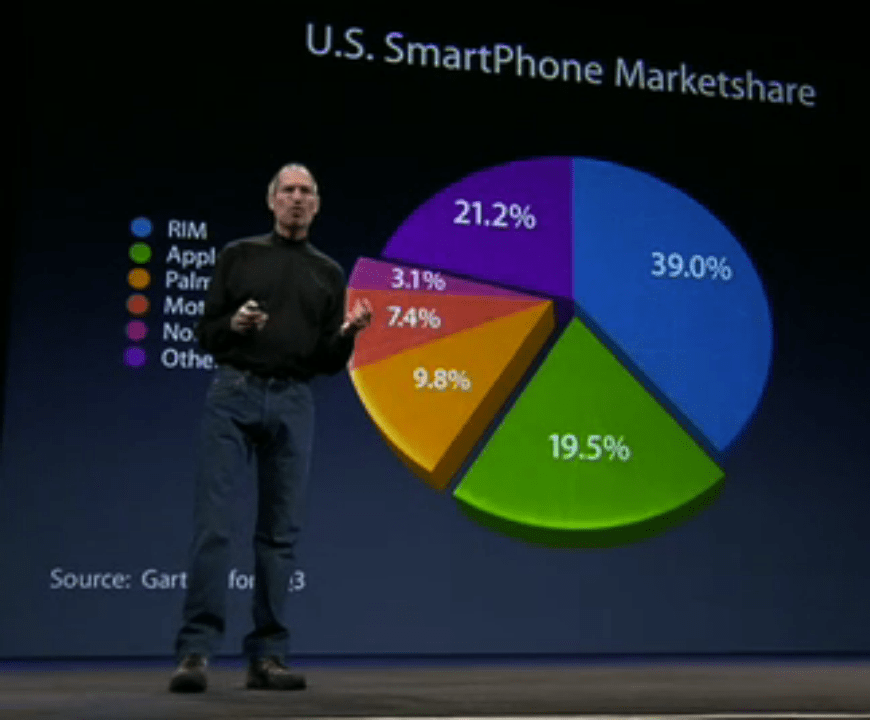
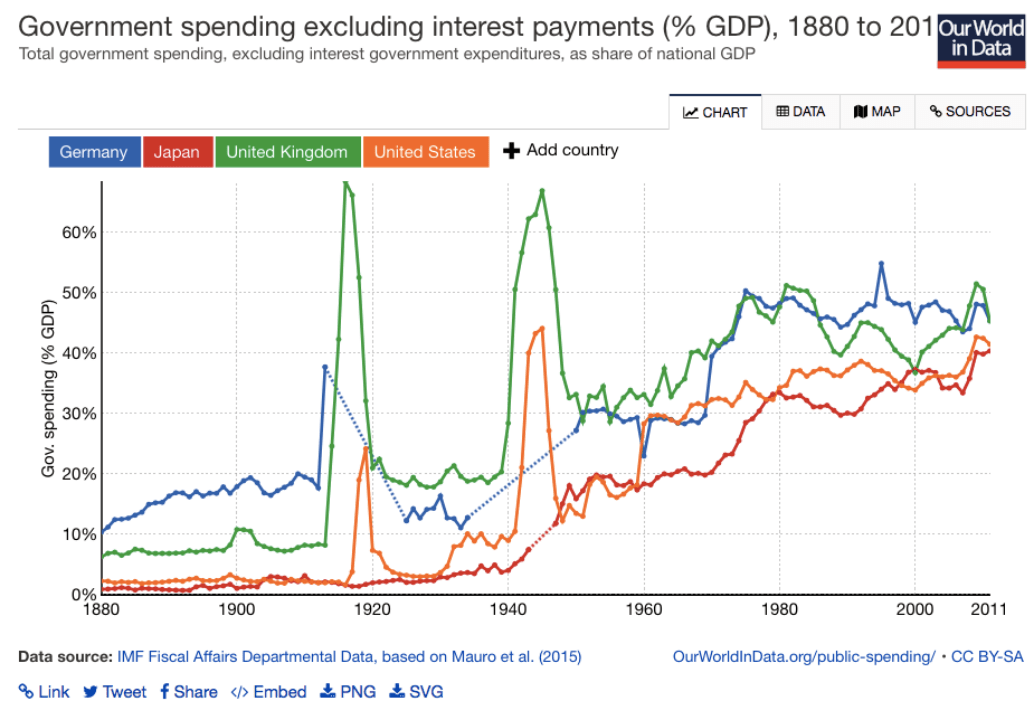
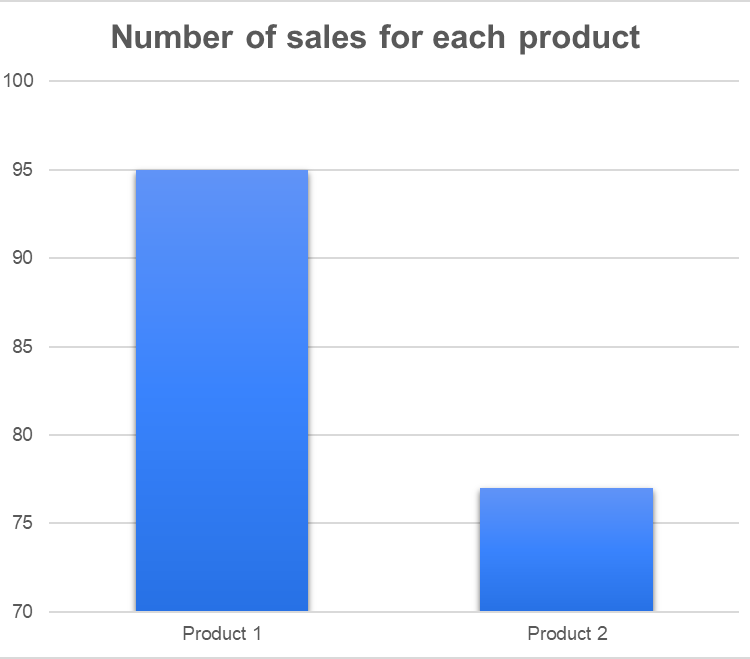
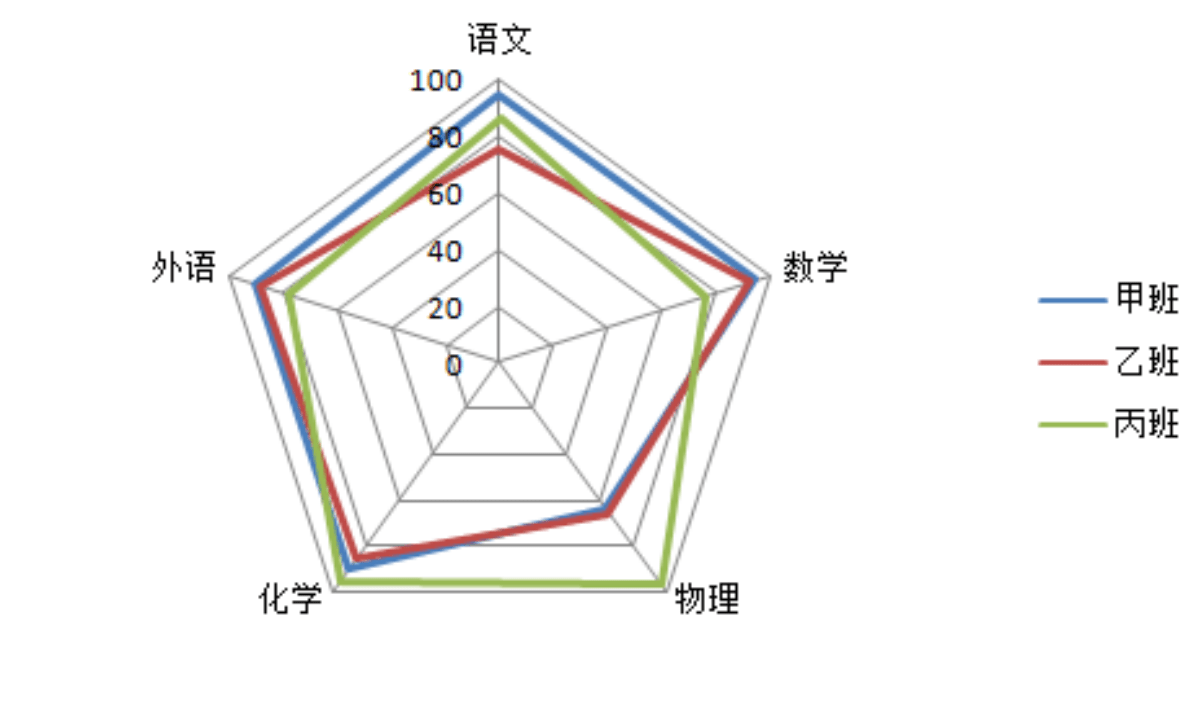
比较两个数据的大小 (可以很直观的做比较,可视化建立起数据和人之间的桥梁)
校验两组数据的差异 (比如看两组数据是否来自同一个分布,数据可视化可以帮到你!)
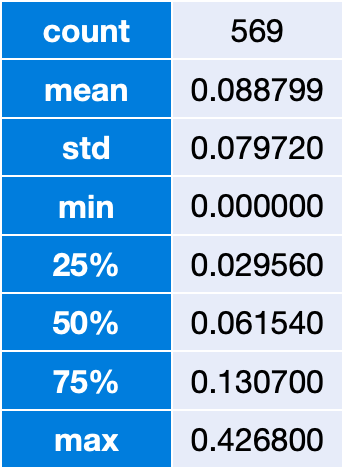
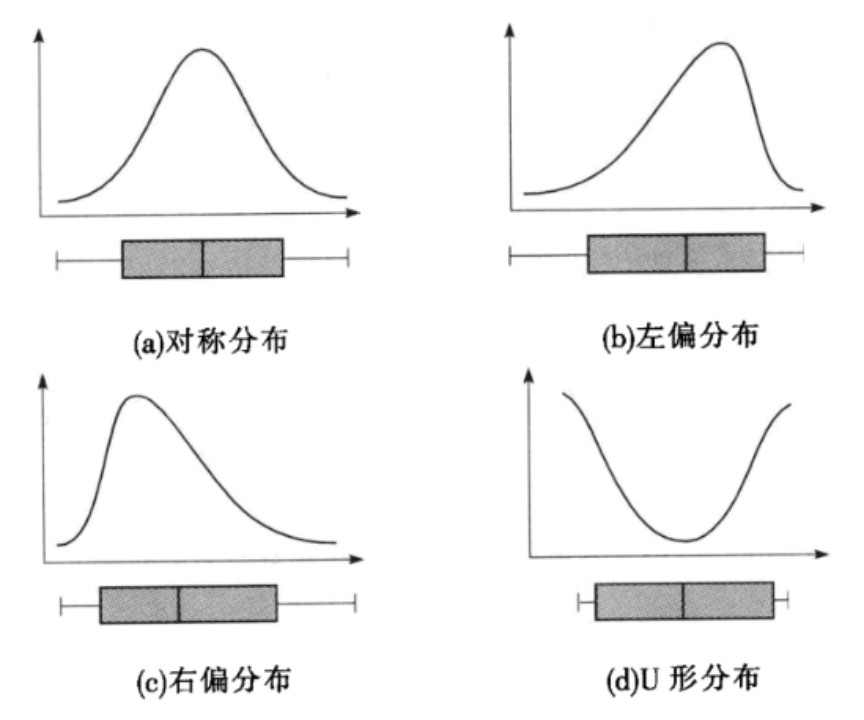
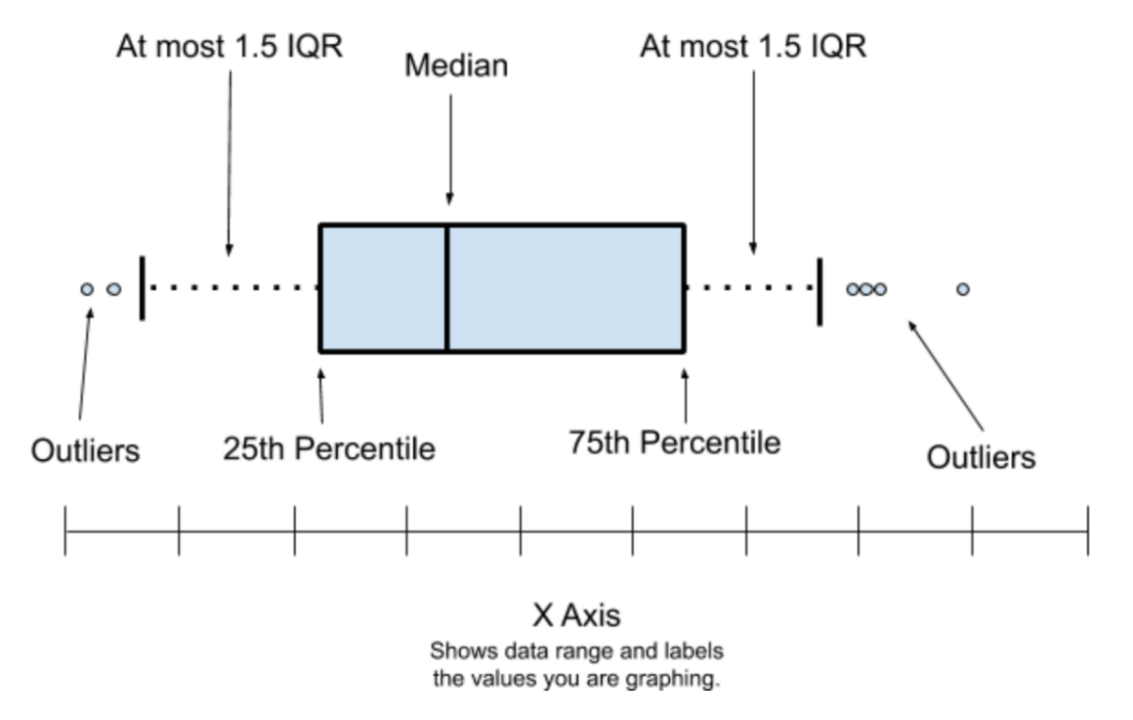
统计随机变量的分布 (如分位数、3σ区间等统计量的可视化,可以不言自明的获得信息!)
数据
# Data Visualization
比较两个数据的大小 (可以很直观的做比较,可视化建立起数据和人之间的桥梁)
校验两组数据的差异 (比如看两组数据是否来自同一个分布,数据可视化可以帮到你!)
统计随机变量的分布 (如分位数、3σ区间等统计量的可视化,可以不言自明的获得信息!)
设计
数据
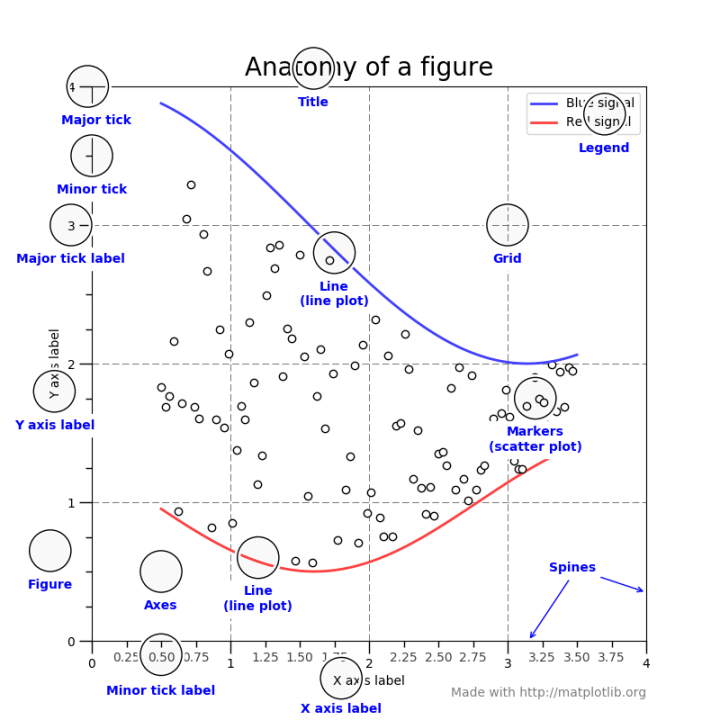
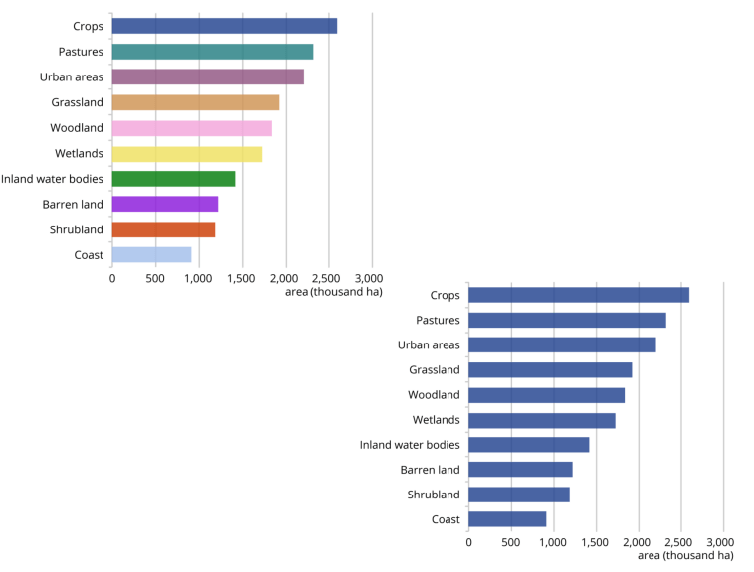
Simpler is almost always better!
高效的表达 = 清晰的思路 = 有价值的工作
尽量用低维度表达
要避免视觉噪声(标记、注释、颜色)切忌喧宾夺主!
确保各个元素清晰
# Data Visualization
比较两个数据的大小 (可以很直观的做比较,可视化建立起数据和人之间的桥梁)
校验两组数据的差异 (比如看两组数据是否来自同一个分布,数据可视化可以帮到你!)
统计随机变量的分布 (如分位数、3σ区间等统计量的可视化,可以不言自明的获得信息!)
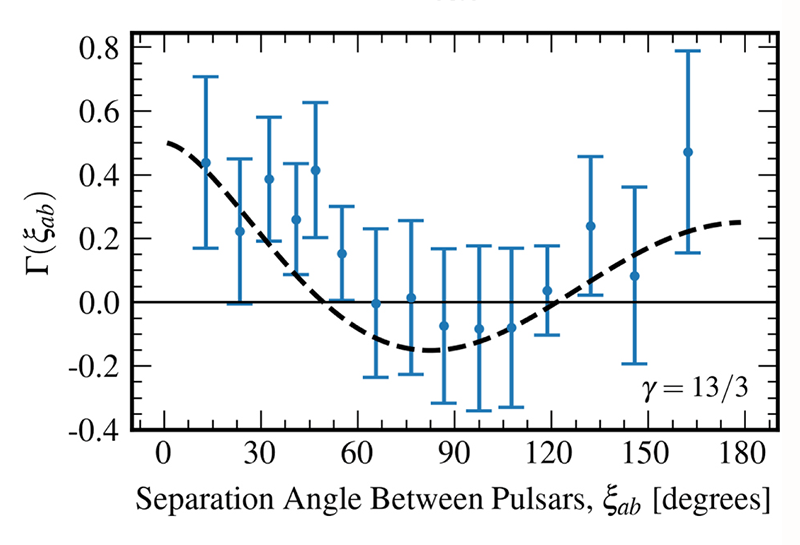
G. Agazie et al., “The NANOGrav 15 yr data set: Evidence for a gravitational-wave background,” Astrophys. J., Lett. 951, L8 (2023).
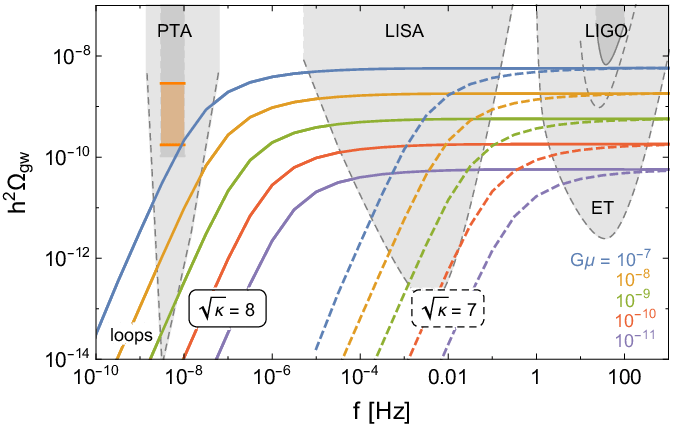
Stochastic gravitational-wave background from metastable cosmic strings - Buchmuller, Wilfried et al - arXiv:2107.04578 CERN-TH-2021-107DESY 21-101
Lommen, A. Pulsar timing for gravitational wave detection. Nat Astron 1, 809–811 (2017).
设计
数据
# Data Visualization
一般来说,数据可视化的表现形式(模式),有三种:交互式、交互呈现式和呈现式。
呈现式:用于展示/讲述,服务于群体(本课程的内容)
交互式:用于引导/发现,服务于个体
表现形式
# Data Visualization
一般来说,数据可视化的表现形式(模式),有三种:交互式、交互呈现式和呈现式。
呈现式:用于展示/讲述,服务于群体(本课程的内容)
交互式:用于引导/发现,服务于个体
表现形式
# Data Visualization
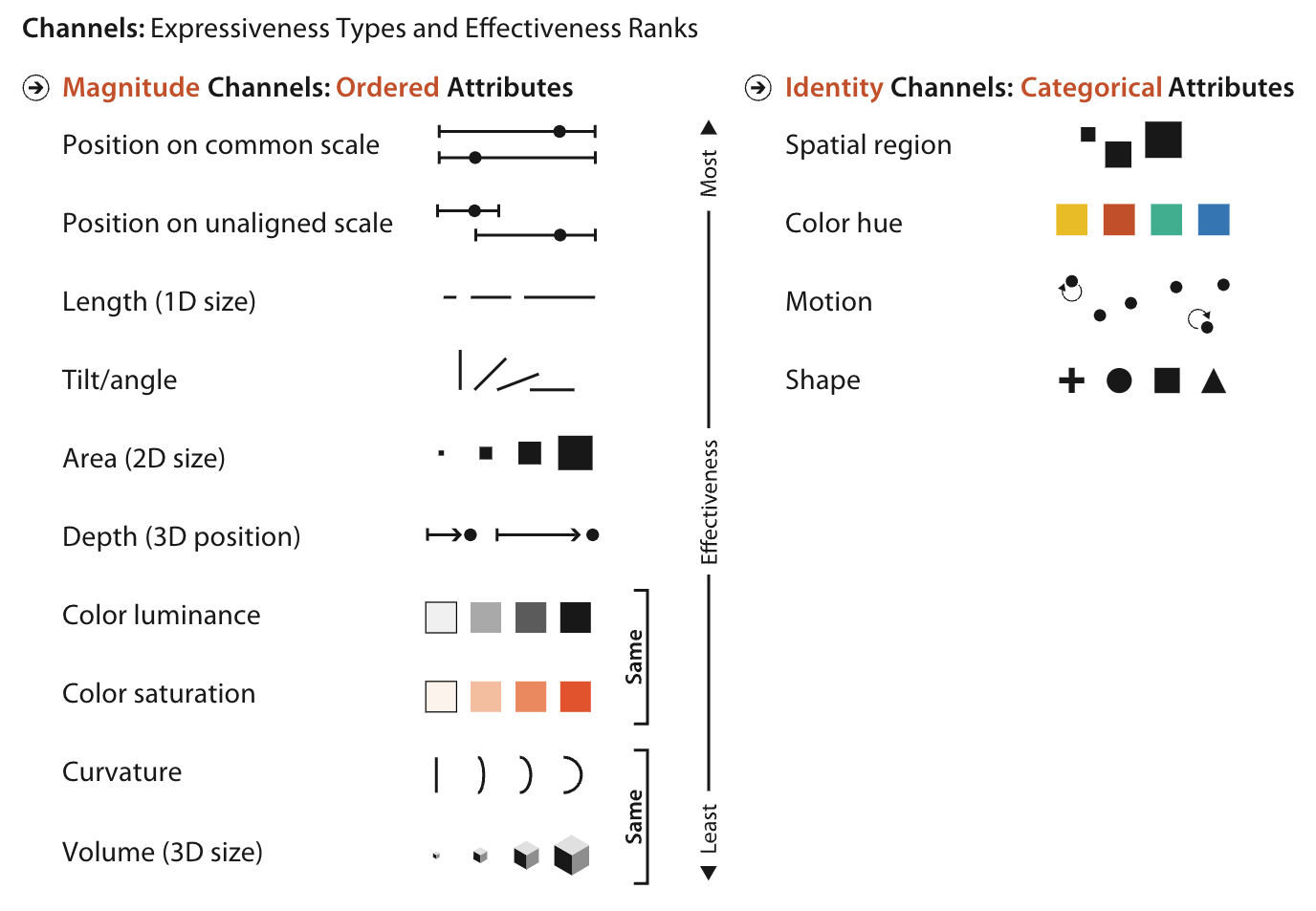
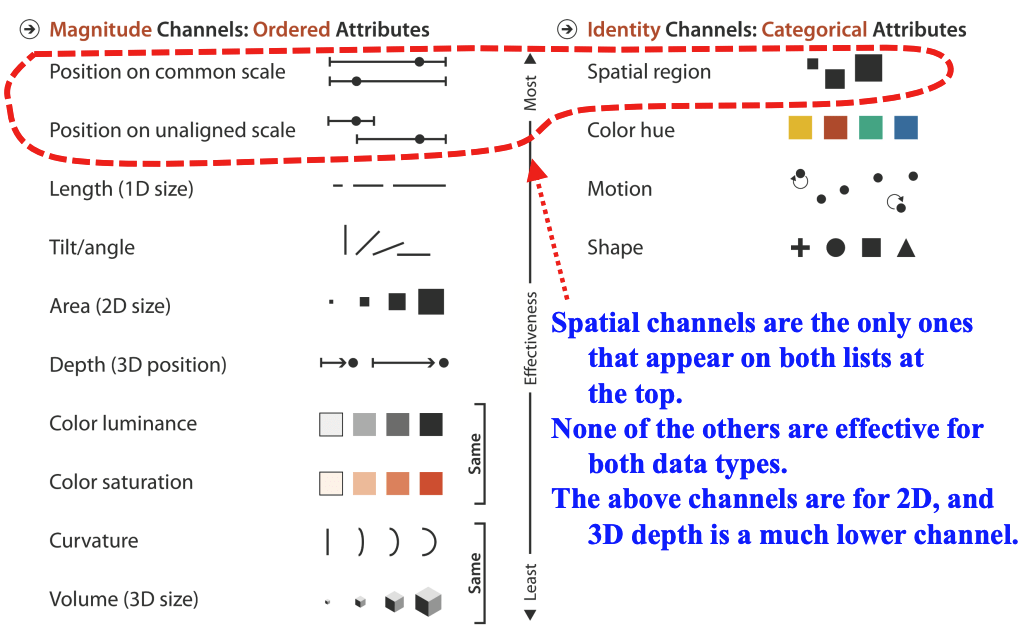
一般来说,数据可视化的数据(对象)有三类概念:(本课程的重点)
定量数据(Quantitative):连续、离散
定类数据(Categorical):城市、品类等
定序数据(Ordinal):尺码、态度等
数据类型
表现形式
# Data Visualization
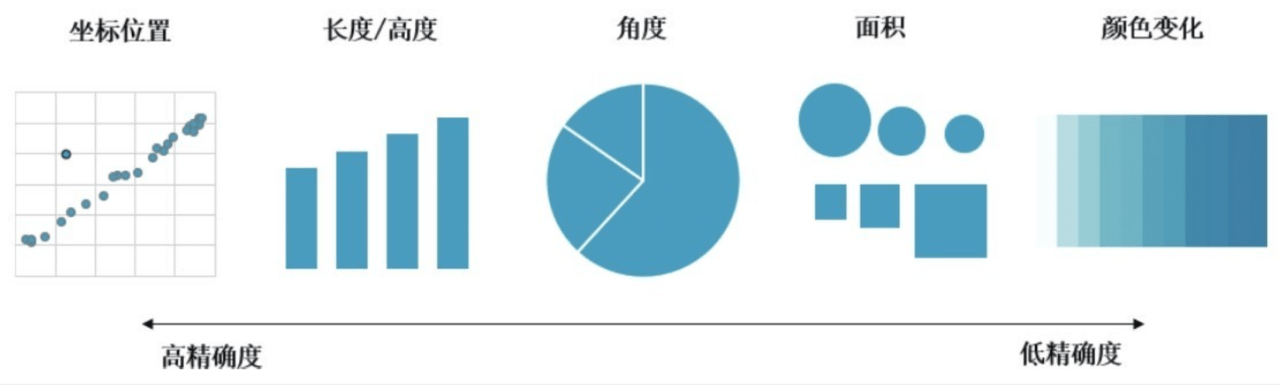
定量数据(Quantitative)
位置 > 长度/角度 > 面积 > 体积 > 密度 > 颜色
上述为优选关系,体现了低维度优选的原则。
定序数据(Ordinal)
位置 > 密度 > 颜色 > 连接 > 包含
其中的密度可以通过疏密程度来体现;
颜色主要是通过深浅体现,避免视觉噪声;
连接可以用箭头等从属关系来体现有序性。
定类数据(Categorical)
位置 > 颜色 > 连接 > 包含 > 形状
表现类之间的关系,确保元素清晰。
数据类型
表现形式
Munzner T. Visualization analysis and design[M]. CRC press, 2014.
# Data Visualization
定量数据(Quantitative)
位置 > 长度/角度 > 面积 > 体积 > 密度 > 颜色
上述为优选关系,体现了低维度优选的原则。
定序数据(Ordinal)
位置 > 密度 > 颜色 > 连接 > 包含
其中的密度可以通过疏密程度来体现;
颜色主要是通过深浅体现,避免视觉噪声;
连接可以用箭头等从属关系来体现有序性。
定类数据(Categorical)
位置 > 颜色 > 连接 > 包含 > 形状
表现类之间的关系,确保元素清晰。
数据类型
表现形式
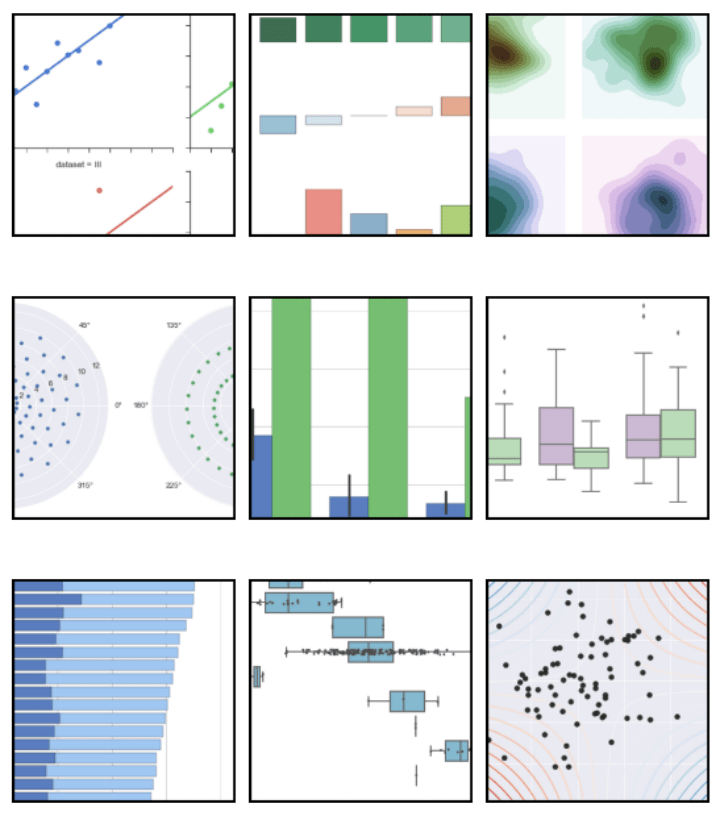
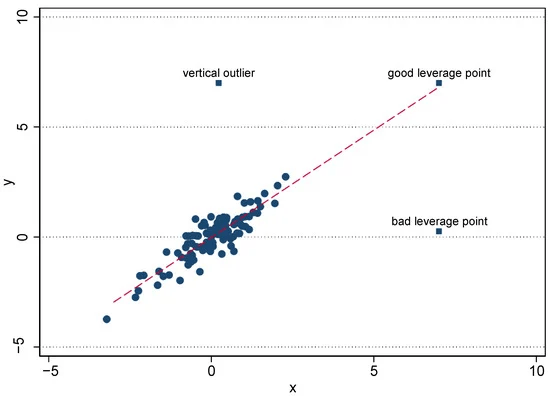
Bad examples
# Data Visualization
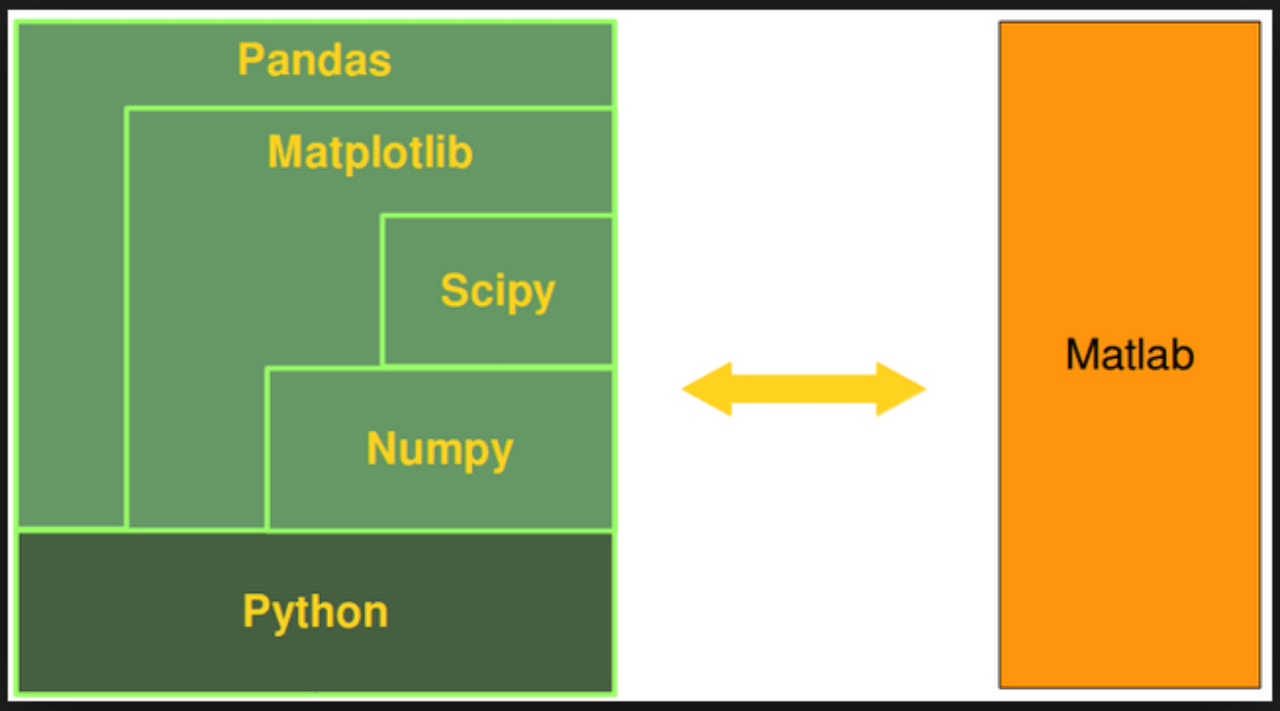
基于编程语言
RSutdio, Matploblib, Seaborn, Bokeh, Plotly, Streamlit, Gradio, ...
不基于编程语言
Plotly, Tableau, Icharts, QlikView, FineBI, Power BI, Infogram, RAW Graphs, ...
Matplotlib
Seaborn
Plotly
本课程是基于 Python 编程语言,讲解开源免费的数据可视化工具。
Matplotlib:满足基本的需求 (用的好可以满足所有的需求,就是用起来太麻烦)
Seaborn:满足颜控的需求 (非常漂亮!非常容易!)
Bokeh:满足交互呈现的需求
Plotly:强大的在线交互可视化框架
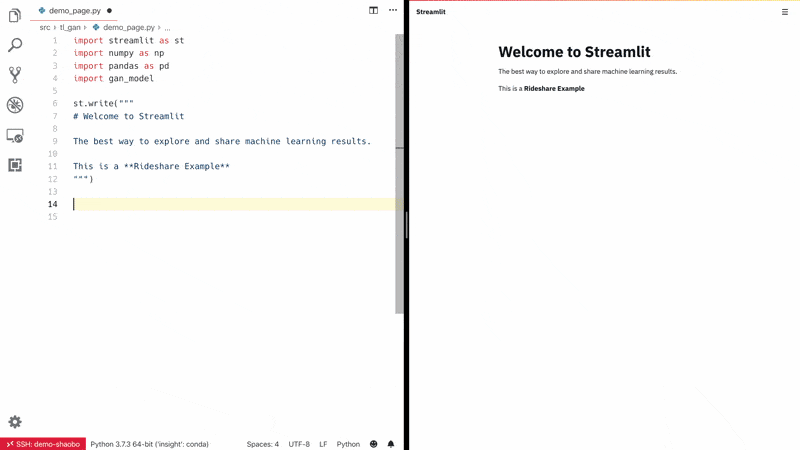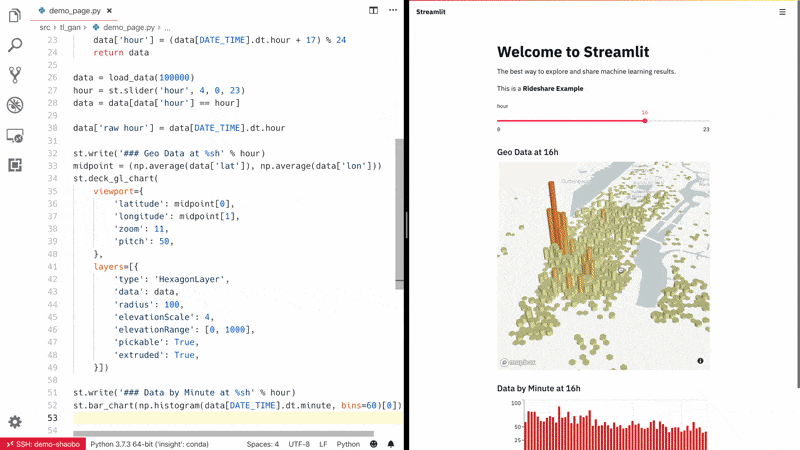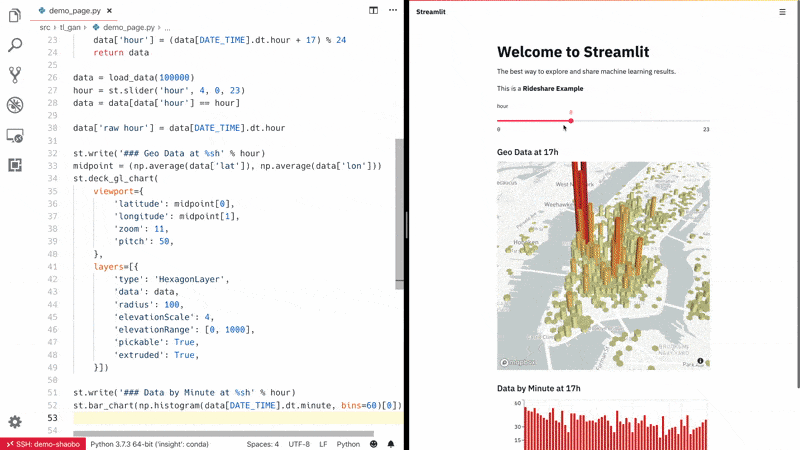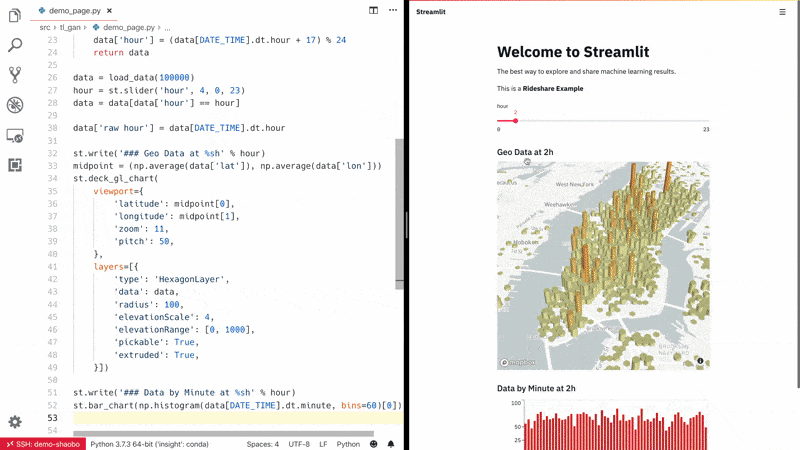
Streamlit:专注于机器学习和数据科学团队的用户交互可视化 app
# Data Visualization
Plotly
Tableau
基于编程语言
RSutdio, Matploblib, Seaborn, Bokeh, Plotly, Streamlit, Gradio, ...
不基于编程语言
Plotly, Tableau, Icharts, QlikView, FineBI, Power BI, Infogram, RAW Graphs, ...
本课程是基于 Python 编程语言,讲解开源免费的数据可视化工具。
Matplotlib:满足基本的需求 (用的好可以满足所有的需求,就是用起来太麻烦)
Seaborn:满足颜控的需求 (非常漂亮!非常容易!)
Bokeh:满足交互呈现的需求
Plotly:强大的在线交互可视化框架
Streamlit:专注于机器学习和数据科学团队的用户交互可视化 app
# Data Visualization
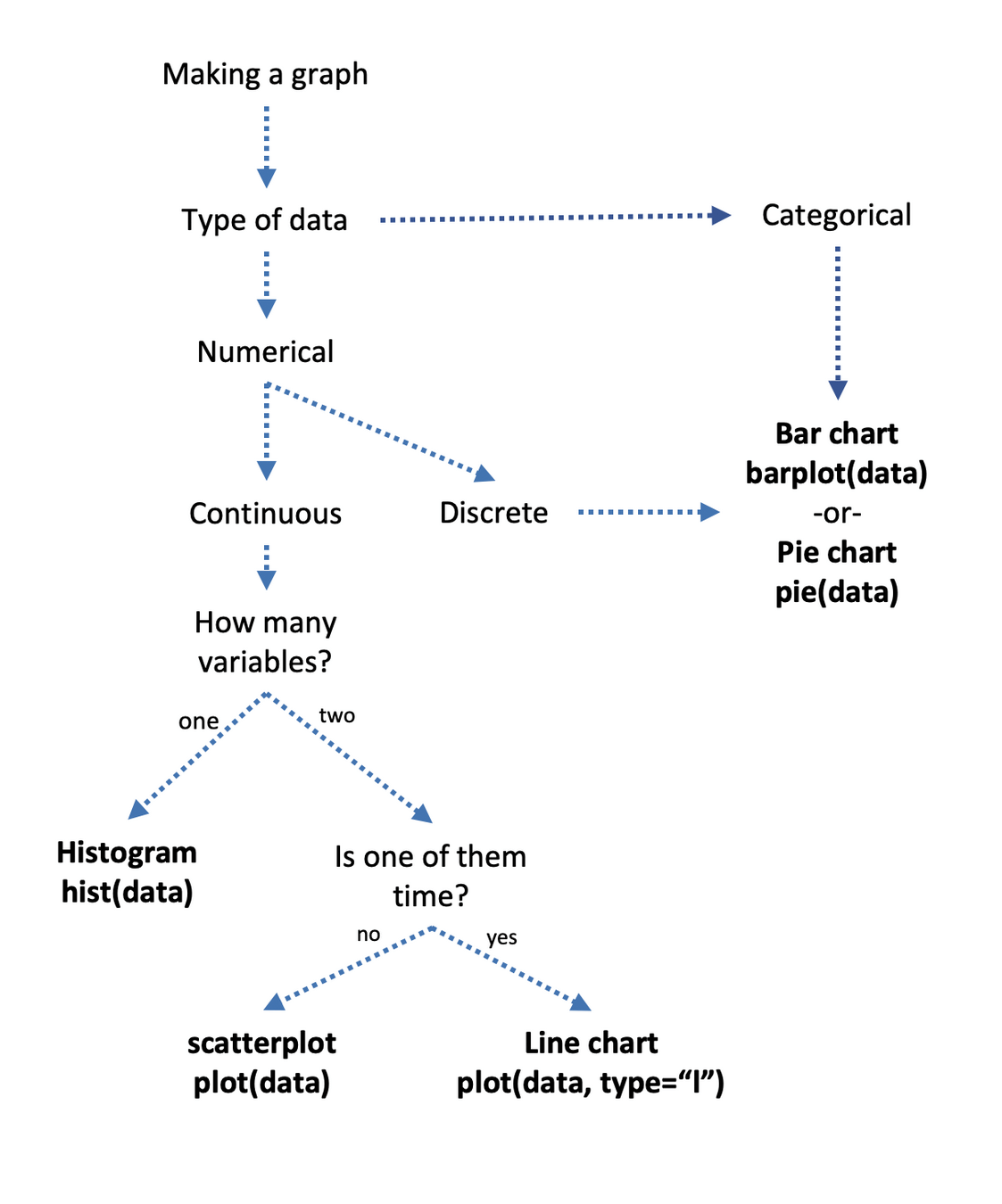
数据准备
数据规模:数据分组、数据采样(处理大数据时尤为需要)
数据类型:数值数据、分类数据(一定要对数据结构特别清楚:连续?离散?有序吗?)
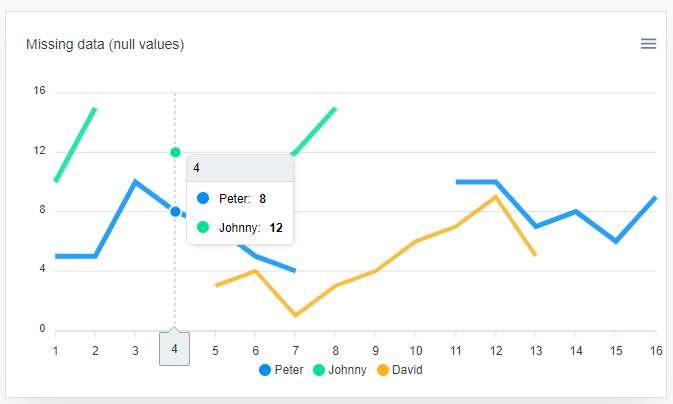
数据异常:取值异常、数据缺失(通常应对的是数据爬虫等采集后的原始数据)
# Data Visualization
数据准备
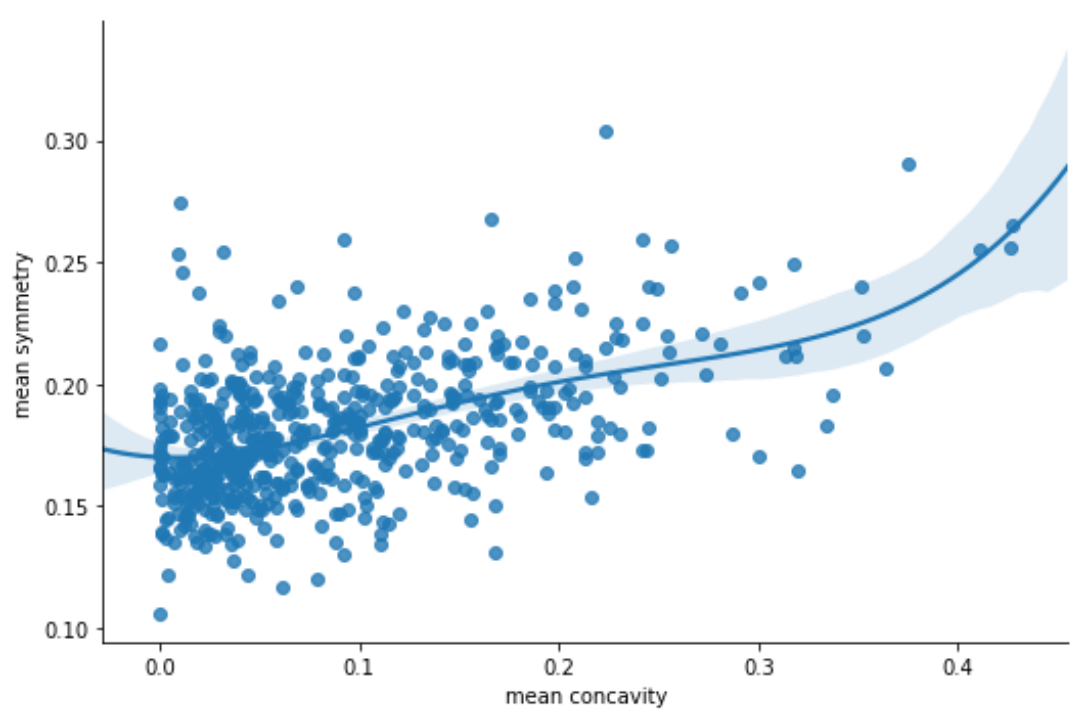
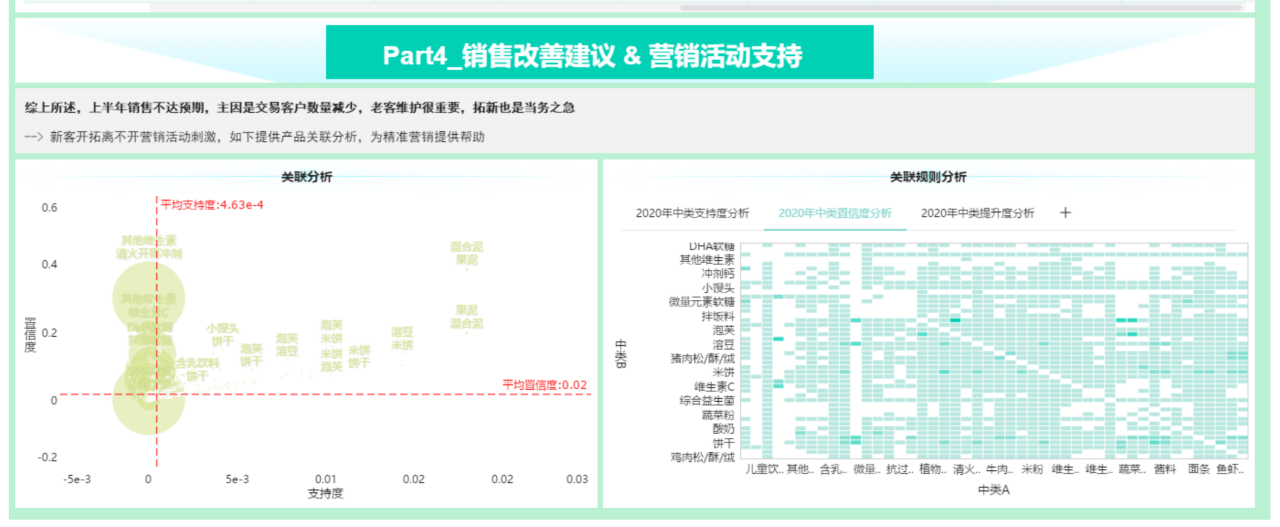
关联分析、定量数值比较:散点图,曲线图(scatter,plot)
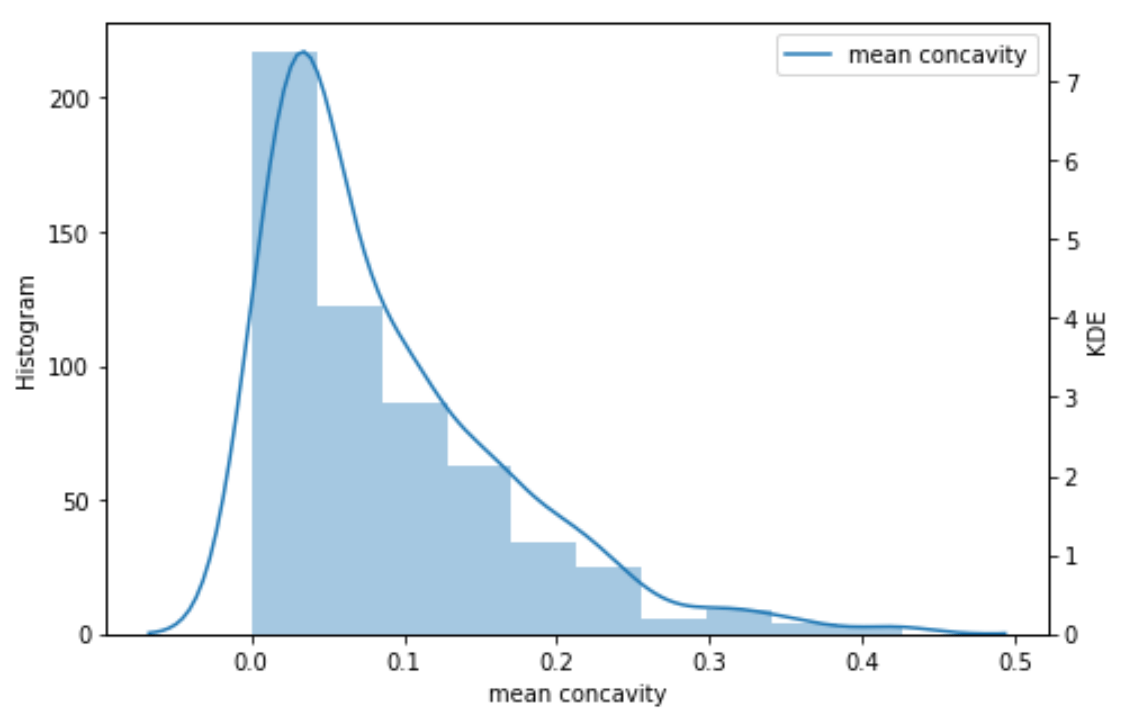
分布分析(定量数据:粗粒度 / 细粒度):灰度图,密度图(hist,gaussian_kde,plot)
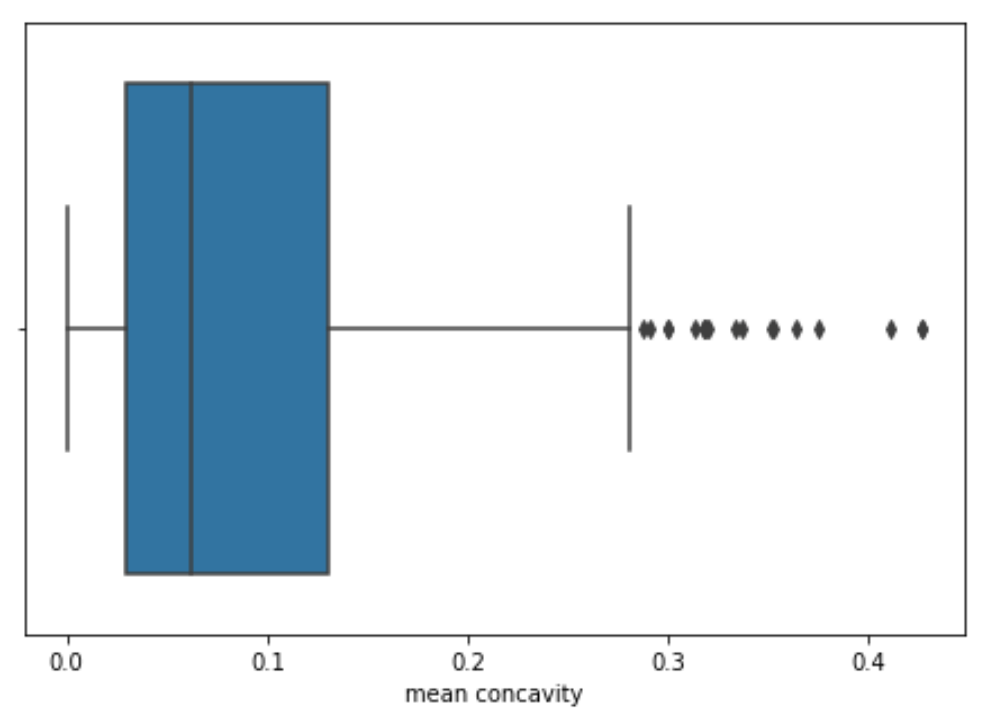
分类分析(关于定序 / 定类数据):柱状图,箱式图(bar,boxplot)
# Data Visualization
数据准备
确定图表
分析迭代的要素,不仅依赖于数据本身,也依赖于人的分析角度
# Data Visualization
数据准备
确定图表
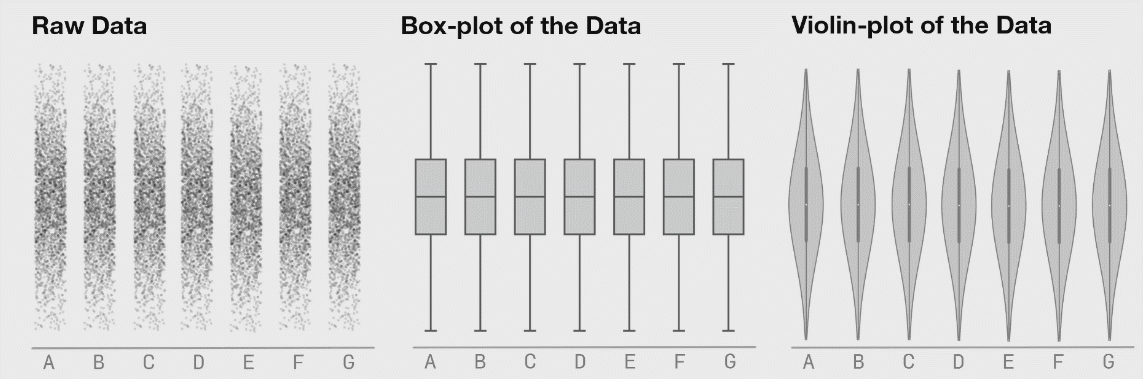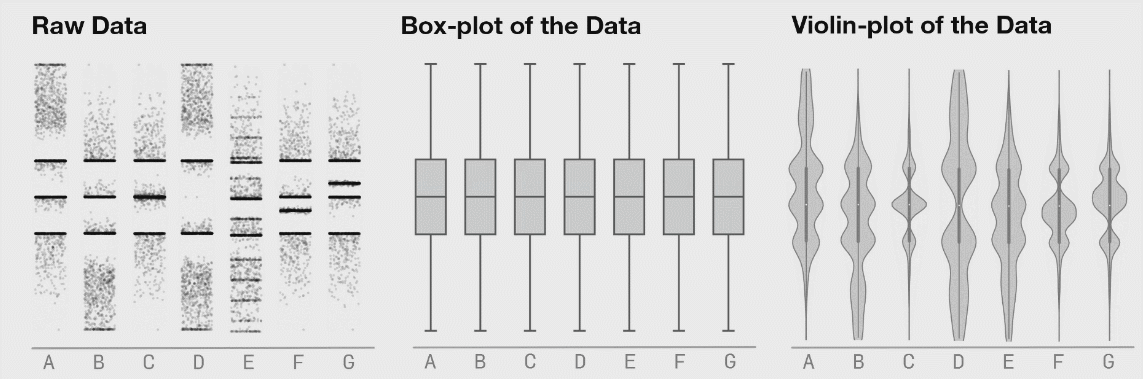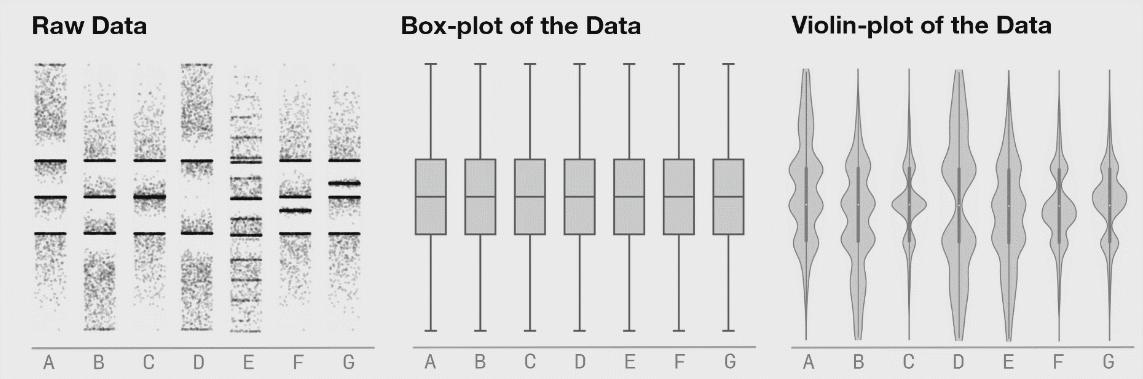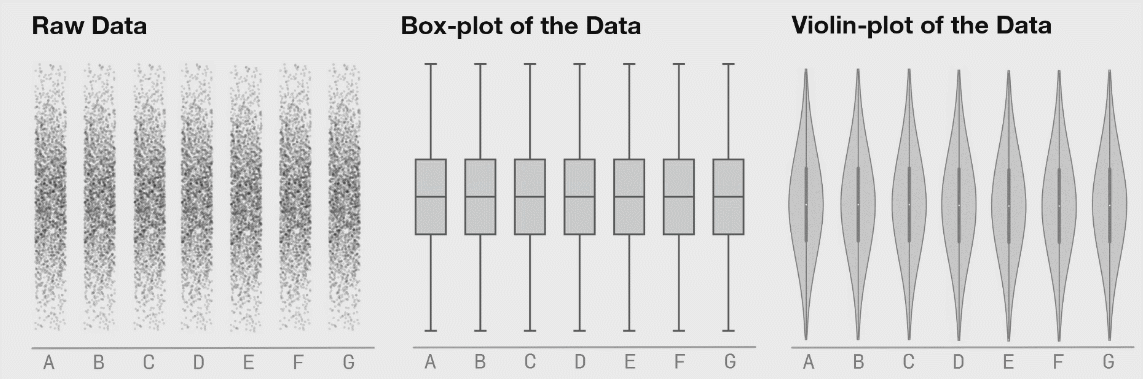
# Data Visualization
数据准备
确定图表
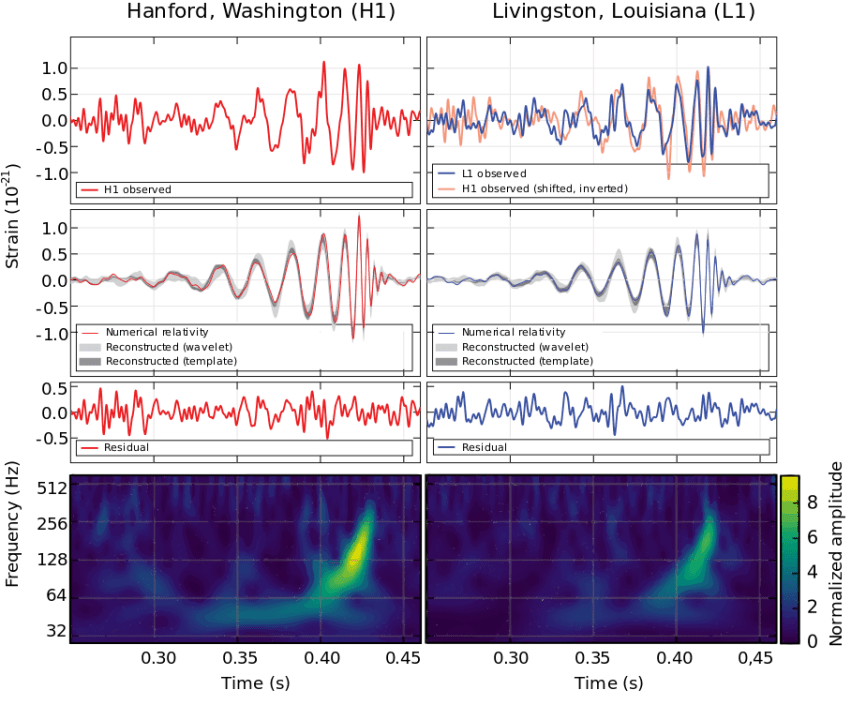
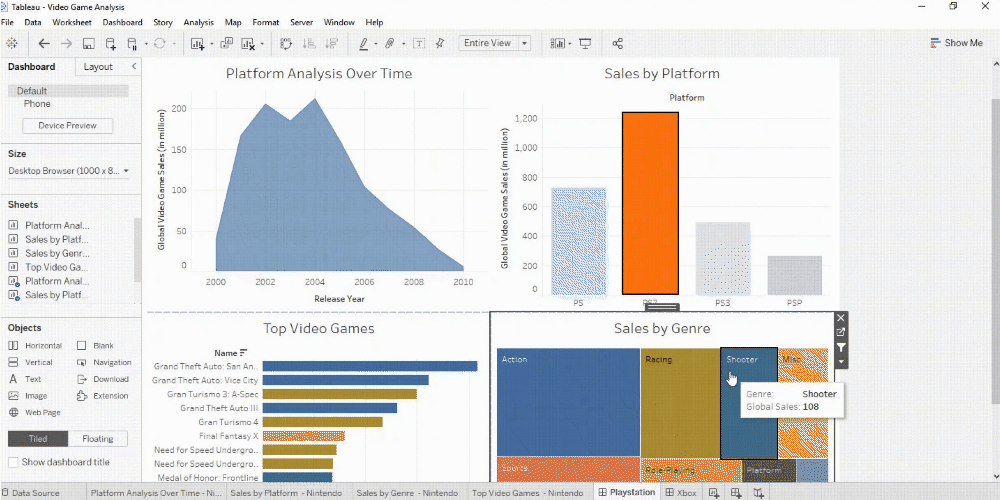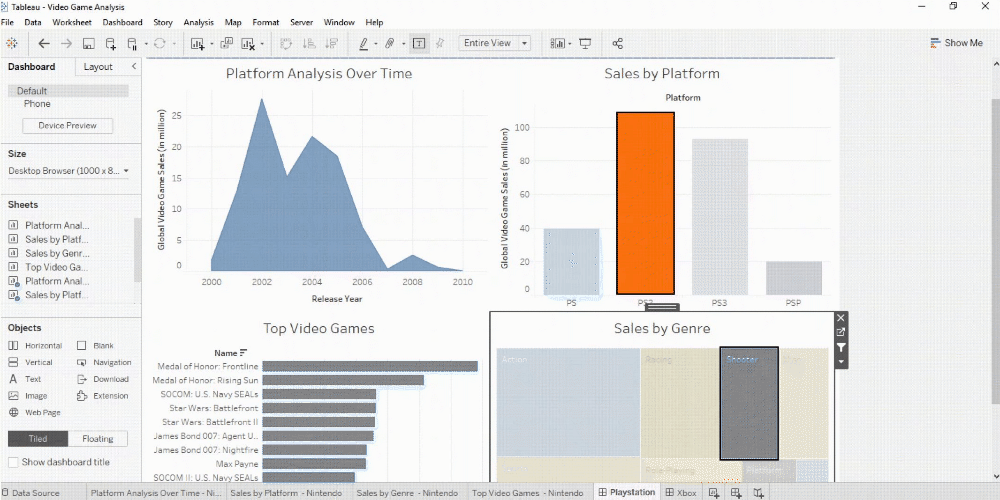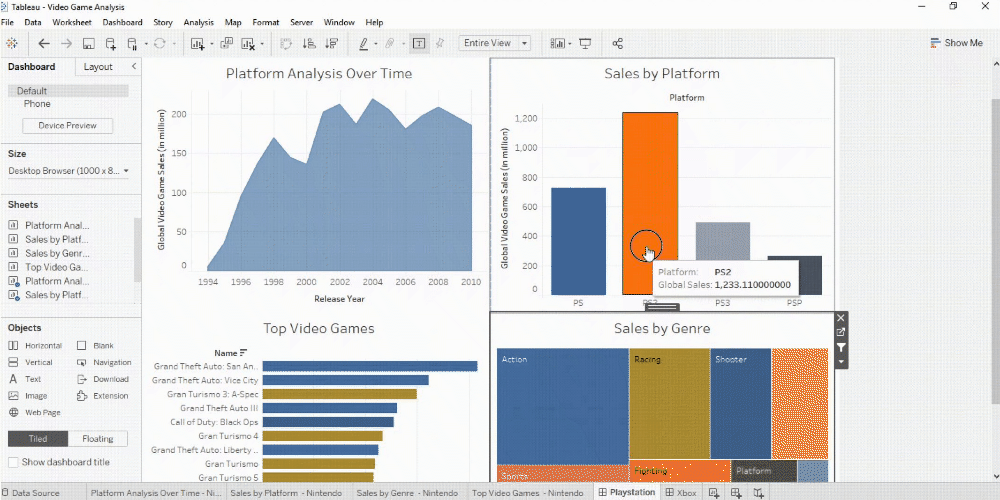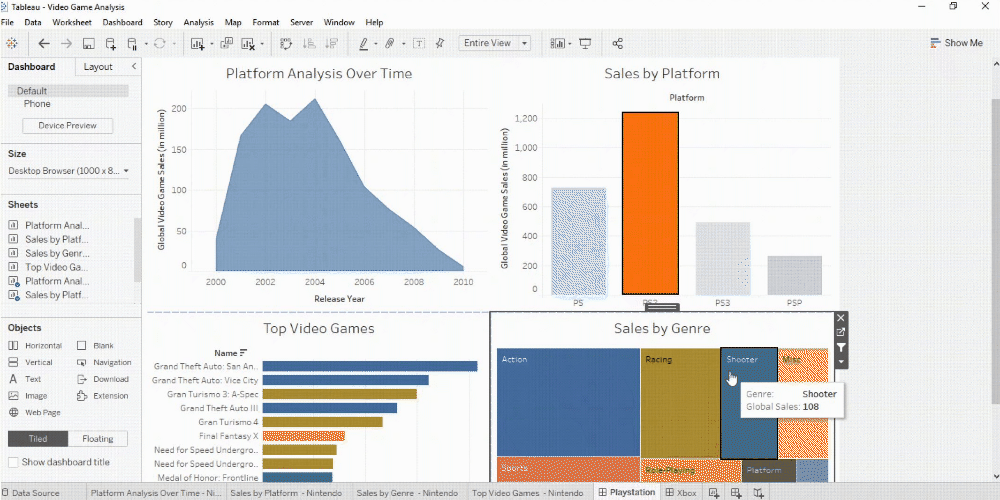
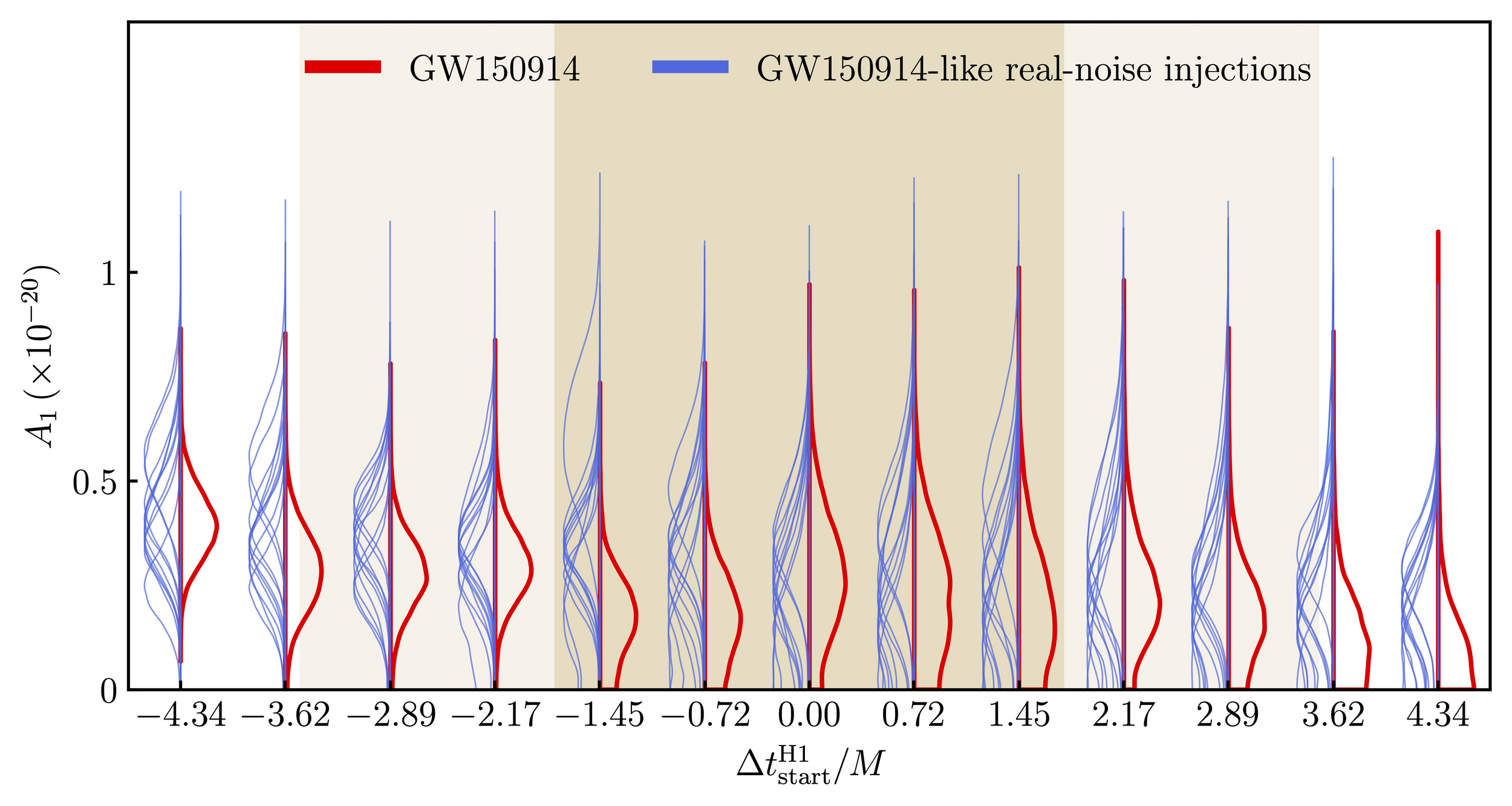
Red violin plots: reconstructed amplitude of the first overtones of GW150914 for different estimates of the waveform peak time. Blue violin plots: amplitudes inferred by injecting a GW150914-like signal in different noise realizations at those same starting times. (Phys. Rev. Lett. 129, 111102)
# Data Visualization
数据准备
确定图表
分析迭代
Data source: World Bank World development indicators Note: The graph shows the correlation of national per capita energy consumption and per capita GDP.
The size of the bubbles denotes total population per country. All values refer to the year 2011.
Intensified global competition for resources?
Global demand vs GDP per person
# Data Visualization
图片来源:CrossHands - AhongPlus
# Data Visualization
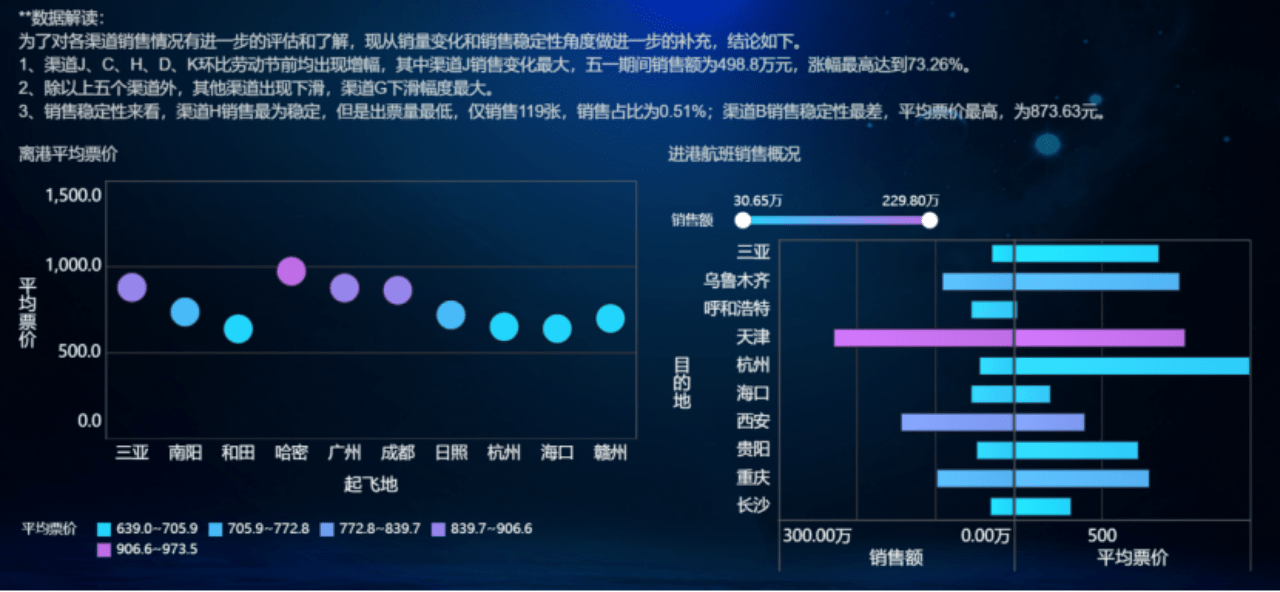
马世权老师在「乐见数据:商业数据可视化思维」里提出,一个成功的商业数据可视化要满足两要素:
提供足够的商业价值
帮助读者快速理解信息
那什么是好的商业数据可视化图表?
图片来源于网络
恰如其分地表达科学观点
帮助读者快速理解观点
G. Agazie et al., “The NANOGrav 15 yr data set: Evidence for a gravitational-wave background,” Astrophys. J., Lett. 951, L8 (2023).
Stochastic gravitational-wave background from metastable cosmic strings - Buchmuller, Wilfried et al - arXiv:2107.04578 CERN-TH-2021-107DESY 21-101
# Data Visualization
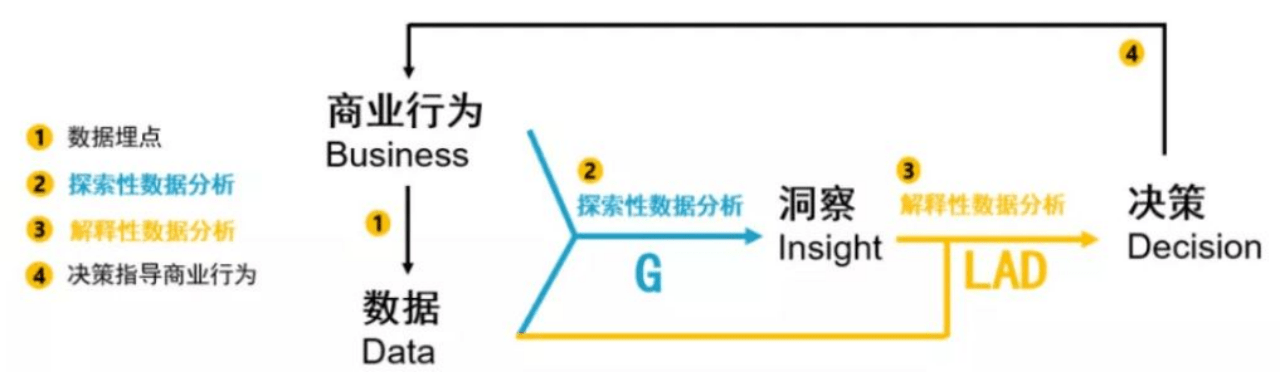
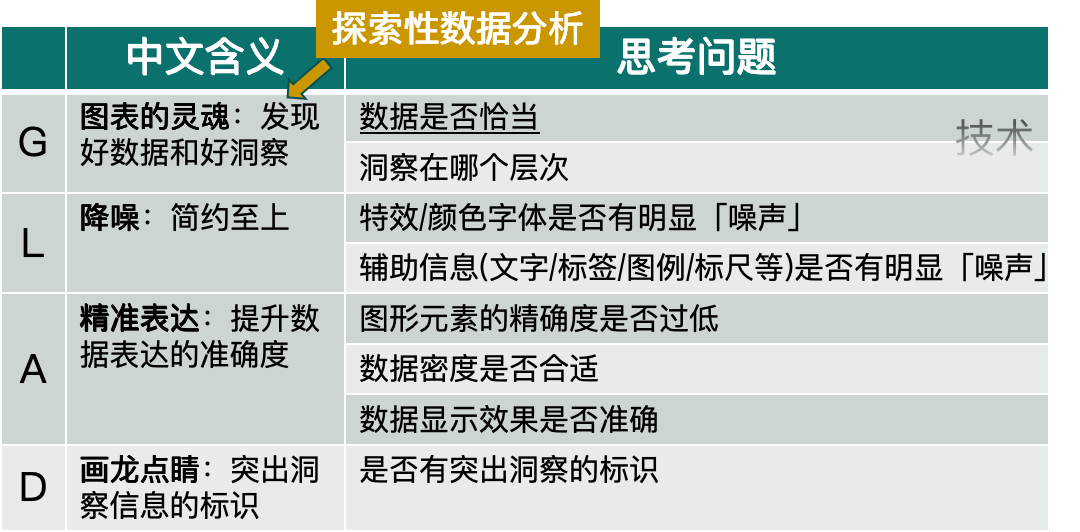
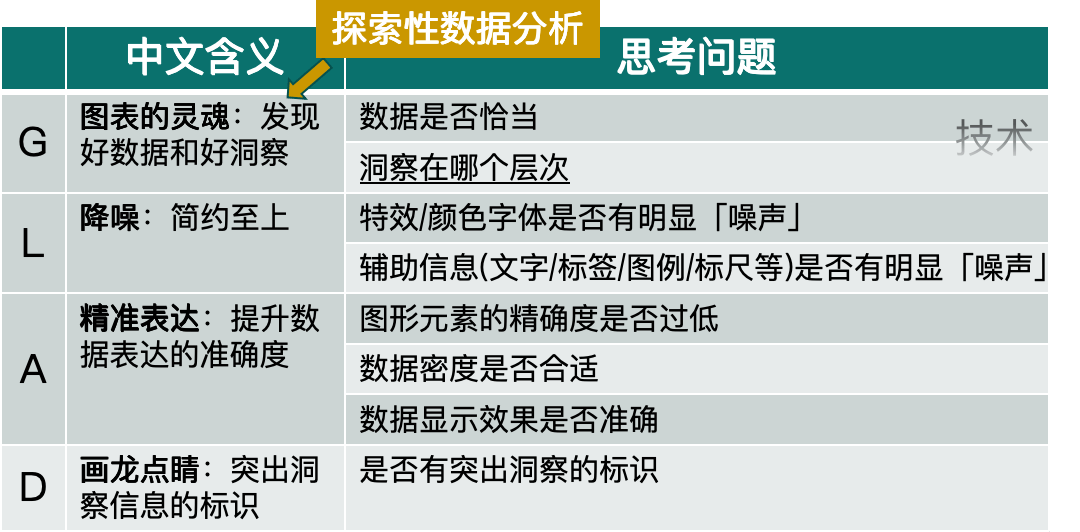
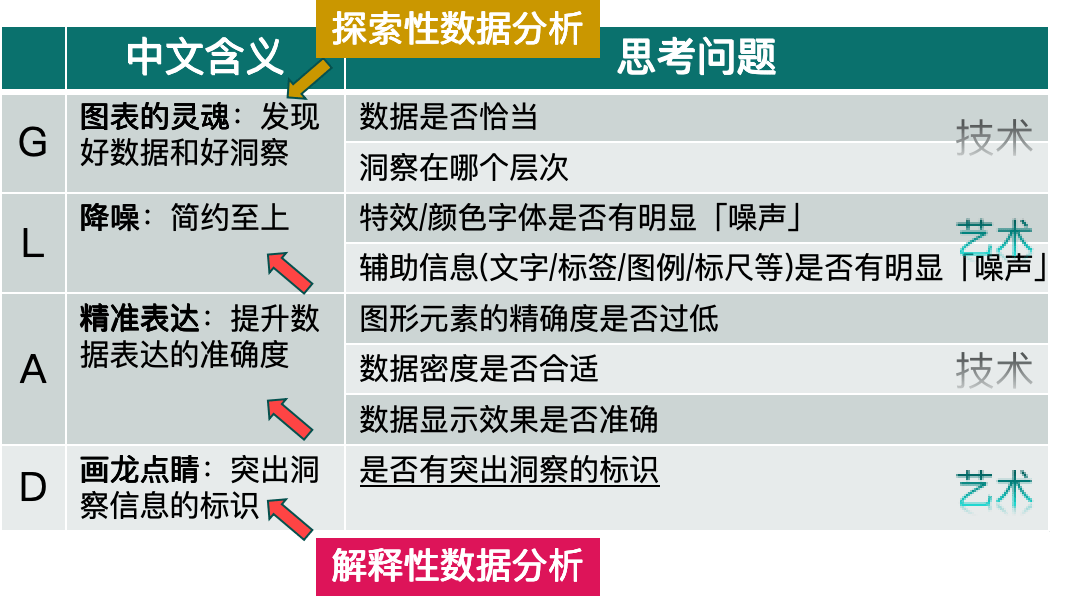
GLAD 原则:
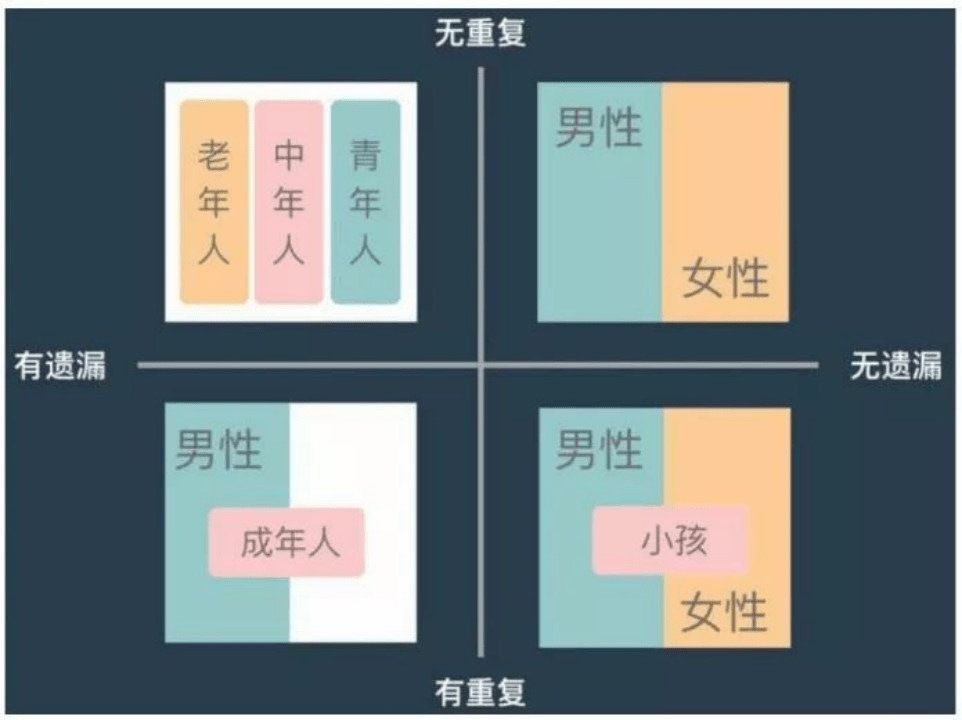
如类别和度量使用是否恰当
图片来源于网络
# Data Visualization
GLAD 原则:
如类别和度量使用是否恰当
# Data Visualization
GLAD 原则:
如类别和度量使用是否恰当
# Data Visualization
GLAD 原则:
# Data Visualization
GLAD 原则:
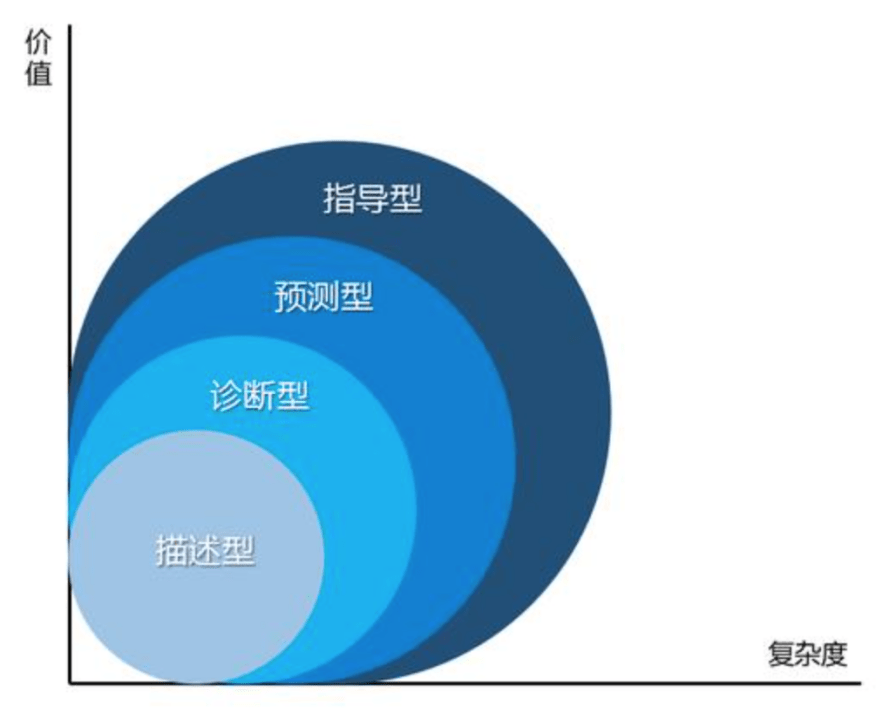
描述性分析 < 诊断/预测性分析 < 指导性分析
# Data Visualization
GLAD 原则:
描述性分析 < 诊断/预测性分析 < 指导性分析
# Data Visualization
GLAD 原则:
确保图表中的颜色用于传递特定的信息,如果不是或有其他方式能够更有效地传递该信息,那就避免使用颜色。
# Data Visualization
GLAD 原则:
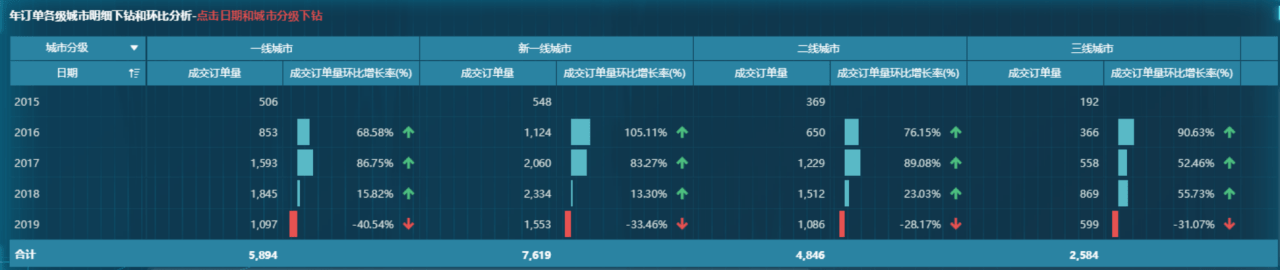
当对象与信息标注分隔较远的话,用户需要花较多的时间让视线来回切换,不利于信息快速获取。
# Data Visualization
GLAD 原则:
选择图形元素要准确。
# Data Visualization
GLAD 原则:
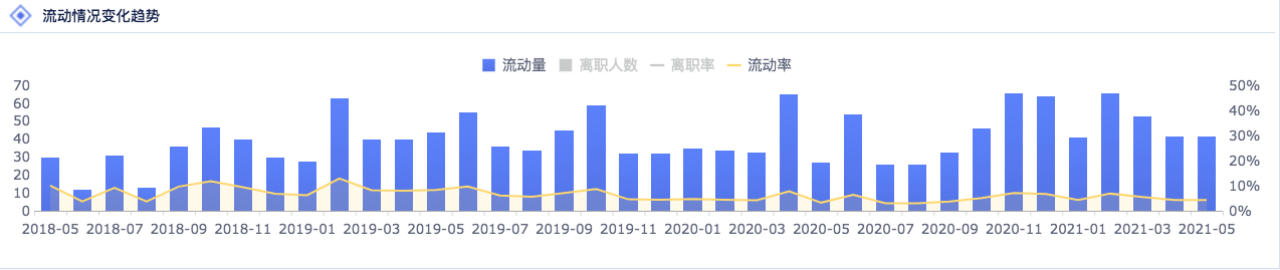
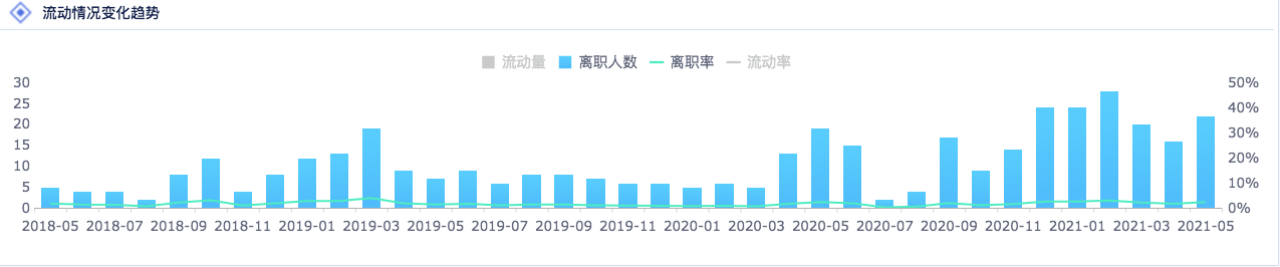
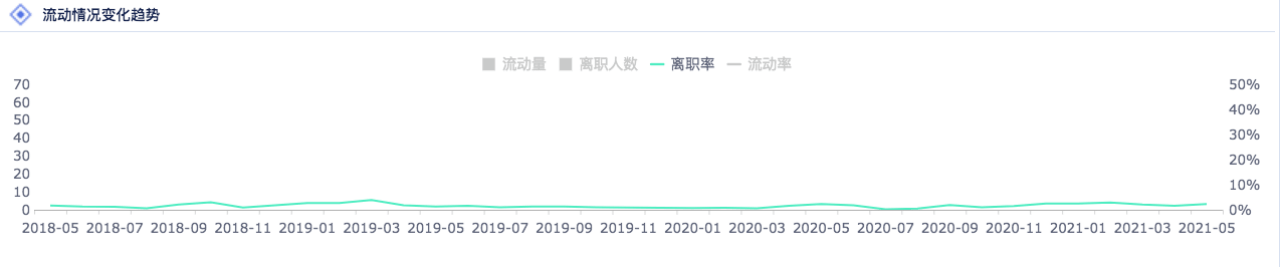
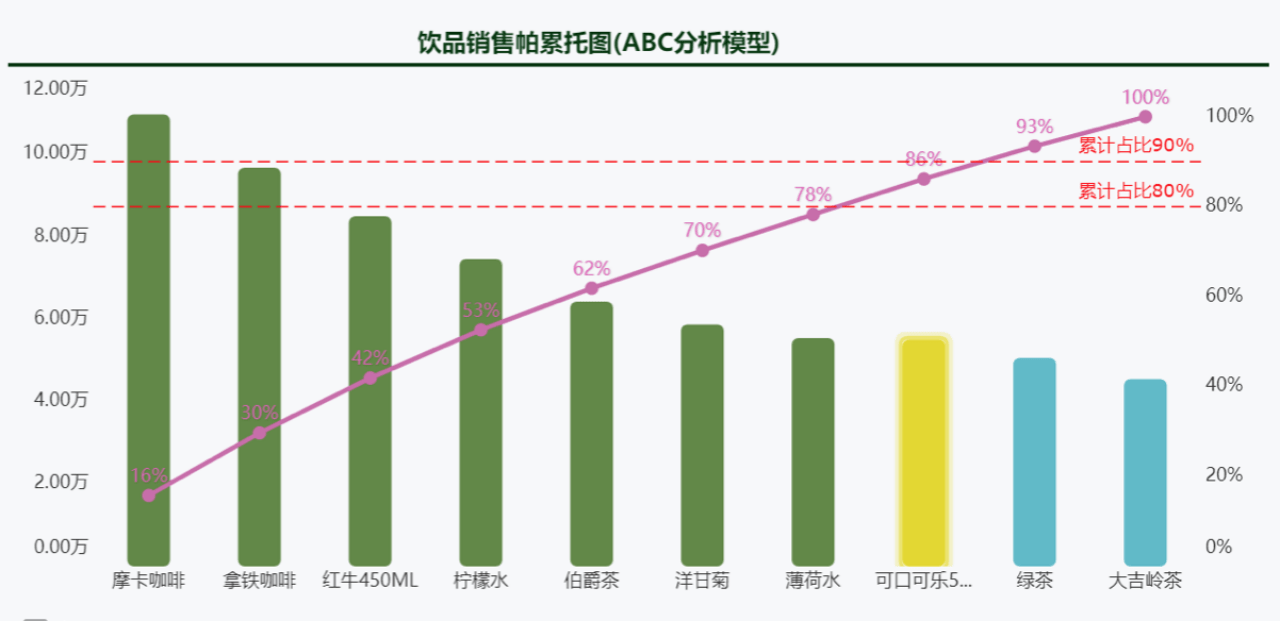
数据的密度是指单位面积图表中所包含的数据量。 图表所能承载的数据量是有限的:
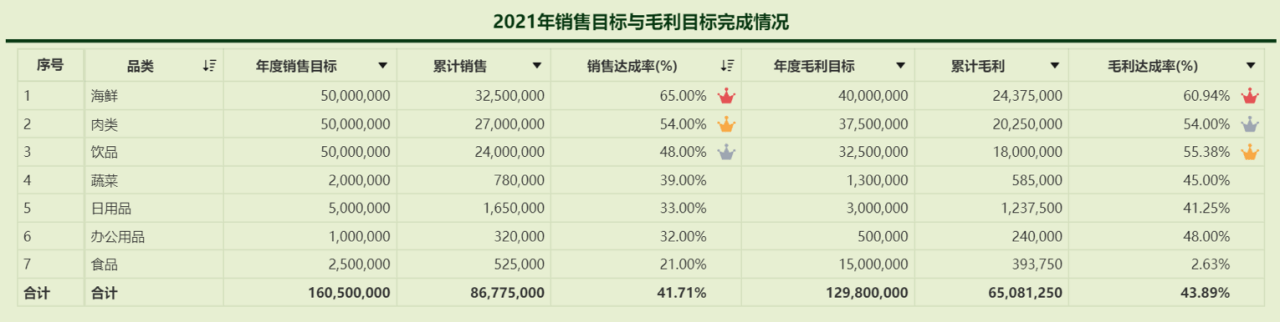
一张图表的数据密度 = 类别的数量 + 度量指标的数量
# Data Visualization
GLAD 原则:
选择合适的图表类型和把控数据密度属于粗调,在最后的展示前还需要对显示效果的细节做精调,否则也可能导致数据与事实的偏离。
# Data Visualization
GLAD 原则:
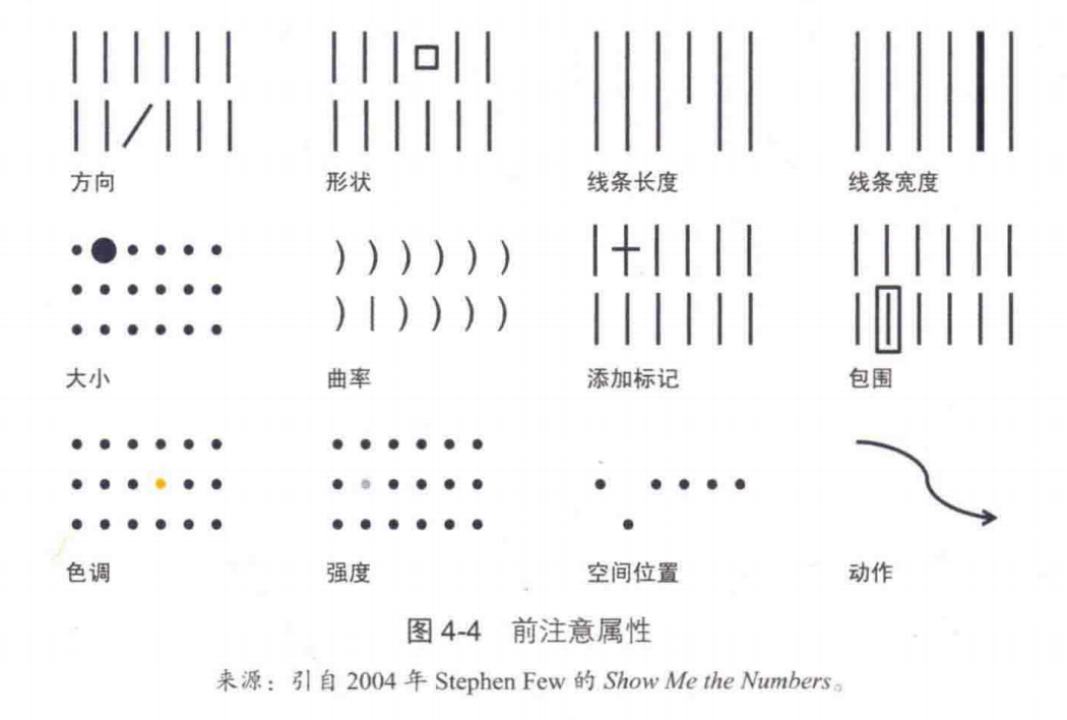
现代心理学把颜色、形状等能快速引起心理反应的信号统称为「前注意属性」,它们在我们的潜意识中活动,只需要 0.25 秒就可以作出识别。
# Data Visualization
GLAD 原则:
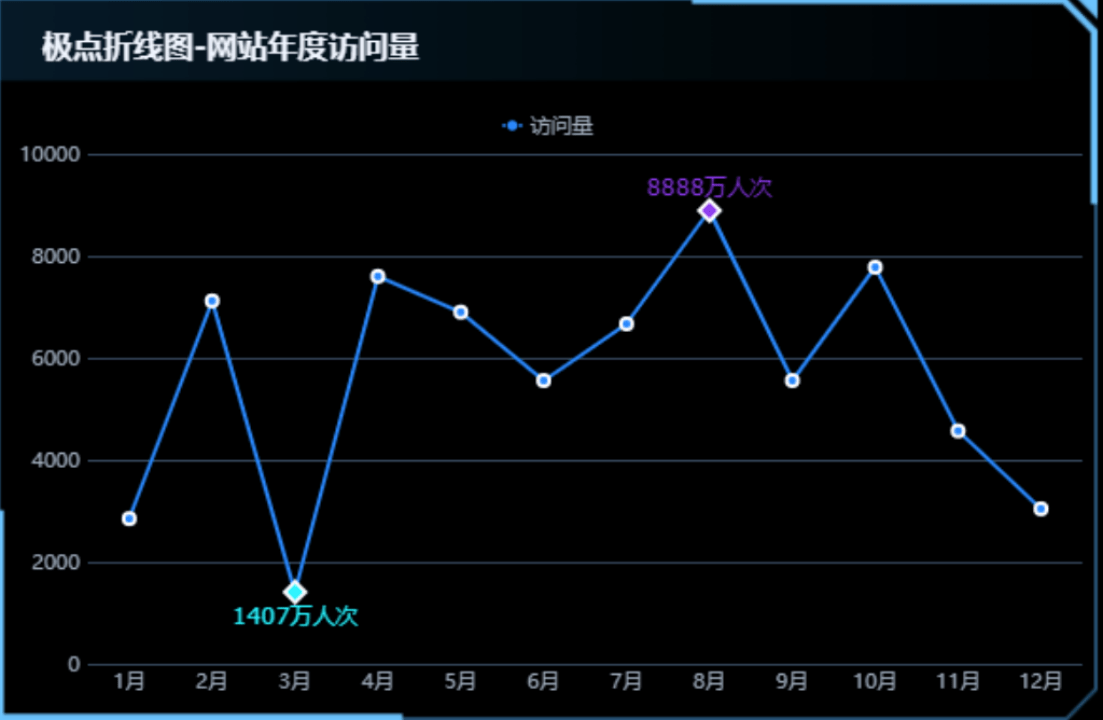
打造视觉反差:我们可以利用颜色、形状、线的粗细用来打造视觉差异。
举几个例子(你第一眼被什么吸睛了?):
# Data Visualization
GLAD 原则:
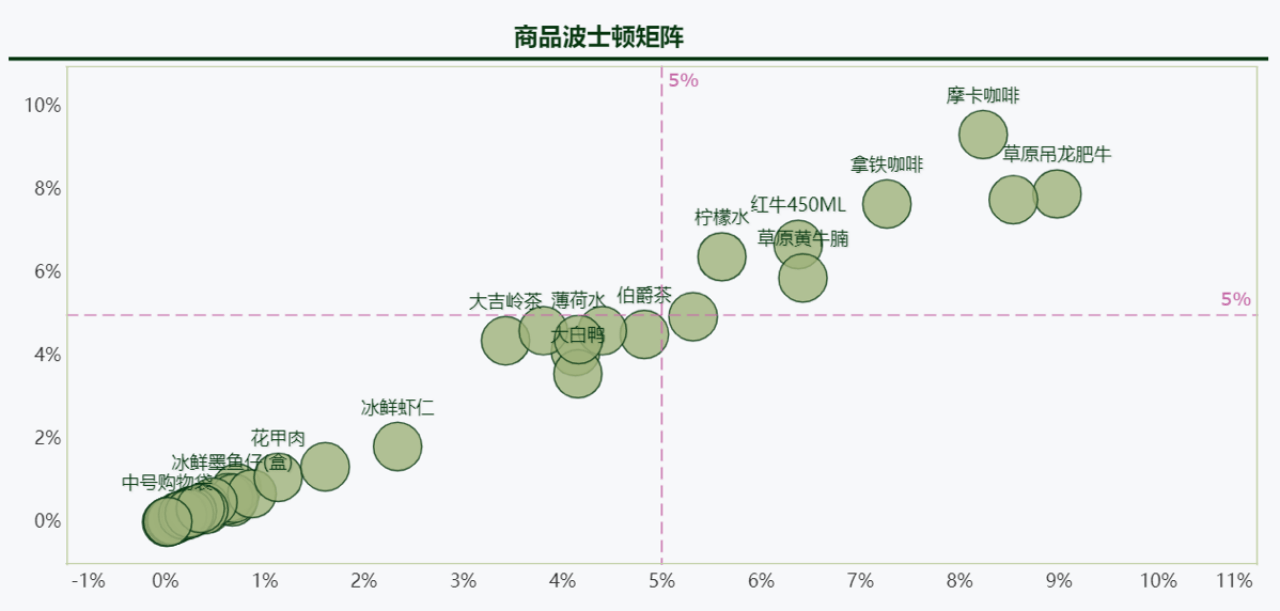
还可以绘制神奇的线:水平线、趋势线、划分区间...
举几个例子(你第一眼被什么吸睛了?):
# Data Visualization
GLAD 原则:
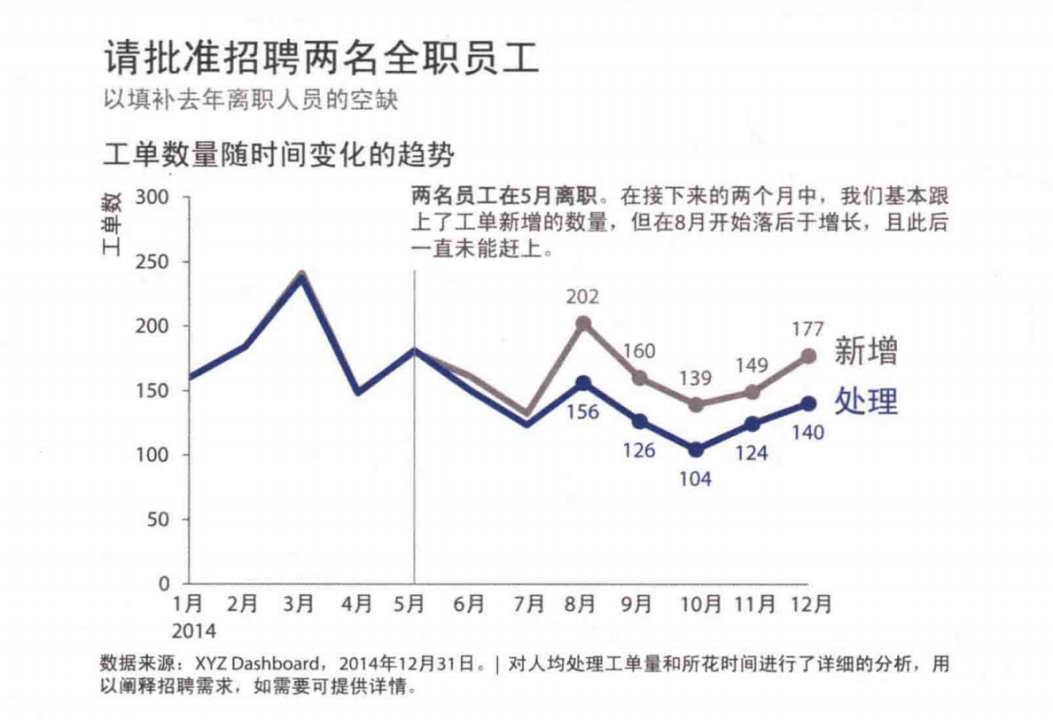
添加文字:文字在数据沟通中能起到以下作用:标签、简介、解释、强调、突出、推荐和讲故事。
举几个例子(你第一眼被什么吸睛了?):
# Homework
Repo of the course: https://github.com/iphysresearch/GWData-Bootcamp
航班乘客变化分析 (2个题)
基础作业:
By He Wang
引力波数据探索:编程与分析实战训练营。课程网址:https://github.com/iphysresearch/GWData-Bootcamp




