parallel computing with
Israel Saeta Pérez
@dukebody
PyConES Almería Oct 2016

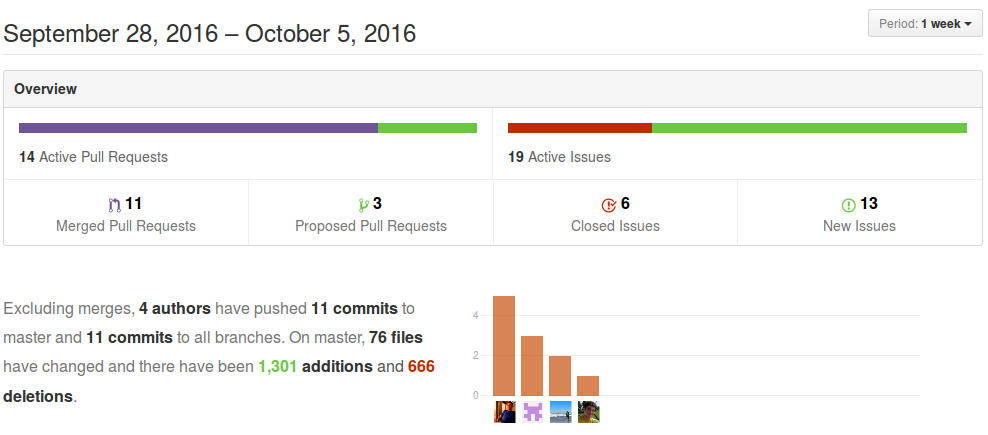
Overview
- intro to analytic parallel computing
- dask features
- dask.distributed
- links

DISCLAIMER
parallel computing
processing a long list of (similar) tasks
- Simple
- Slow if lots of tasks
- More complex
- Needs scheduling & orchestration
- Scheduling overhead → faster?
- Profits from modern multi-core


Building blocks of parallel computing
- Computing nodes: Threads, processes, machines, executors...
- Distributed-friendly task definition language
- Task partitioning
- Aggregation logic
- Scheduler: Assigns tasks to nodes intelligently
- Message Passing channel and protocol
What is Dask?
Dask is a Python library for parallel programming that leverages task scheduling for computational problems

Why dask?
very easy to set up and start using
pip install dask
- No configuration
- No daemons (by default)
- No need to learn Java/Scala
- Feels like a library
- Just pure ol' Python!

amazing support
- SO questions answered in minutes by main author (@mrocklin)
- Very good documentation
- Lots of didactic examples
- Funding for full-time devs
- pandas & scipy devs onboard
- Great GH Pulse, 1000+ *s!
fast and responsive
- Low overhead, low latency job scheduling
- Interactive (Jupyter notebook, non-blocking)
- Progressbar and diagnostics to help humans
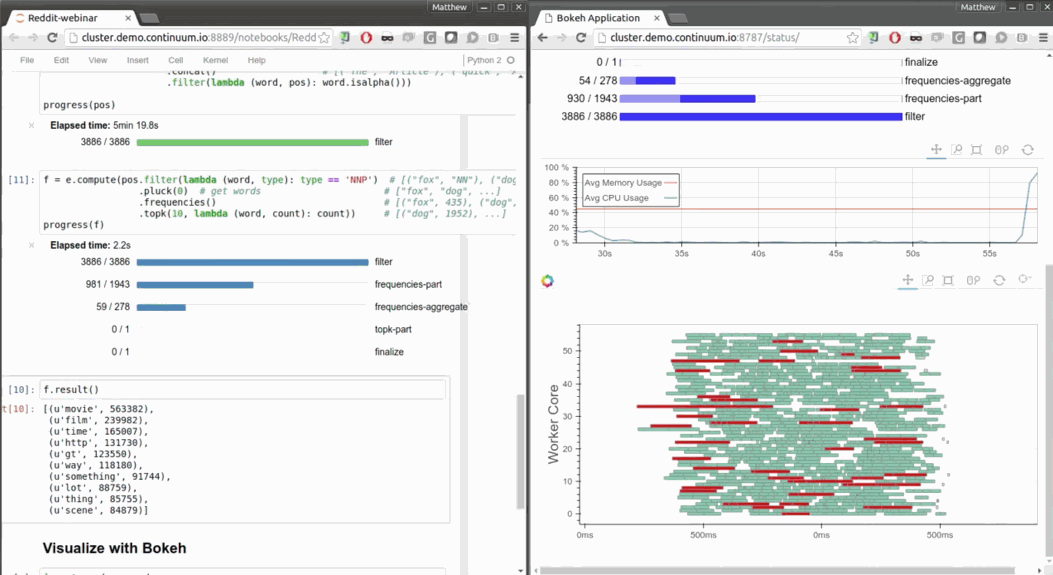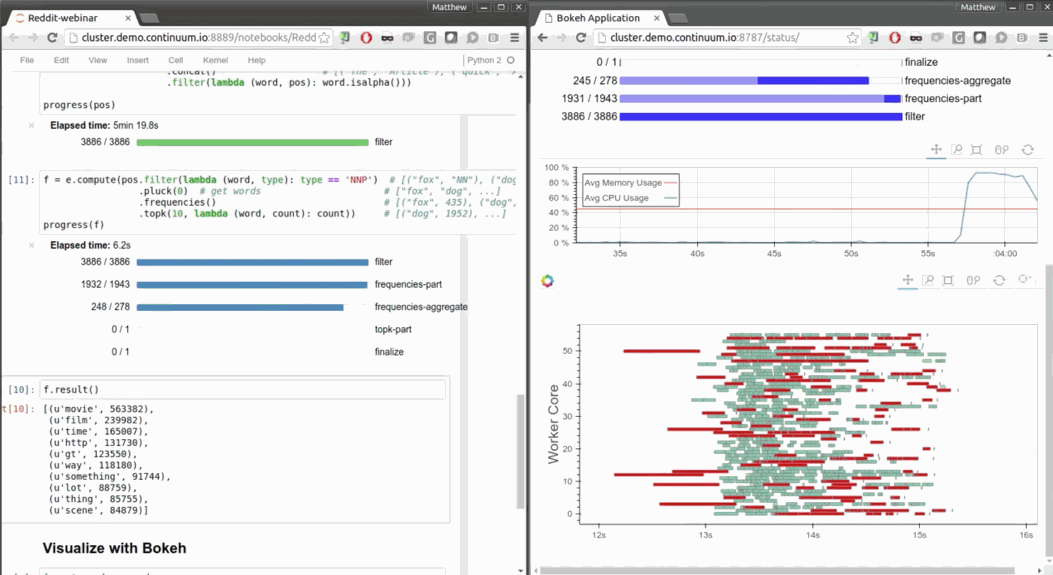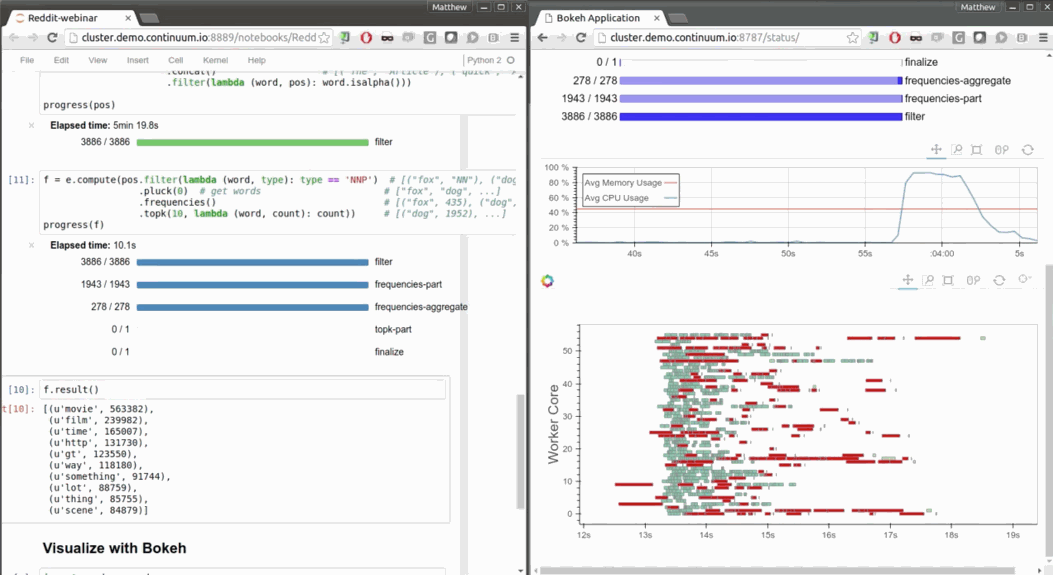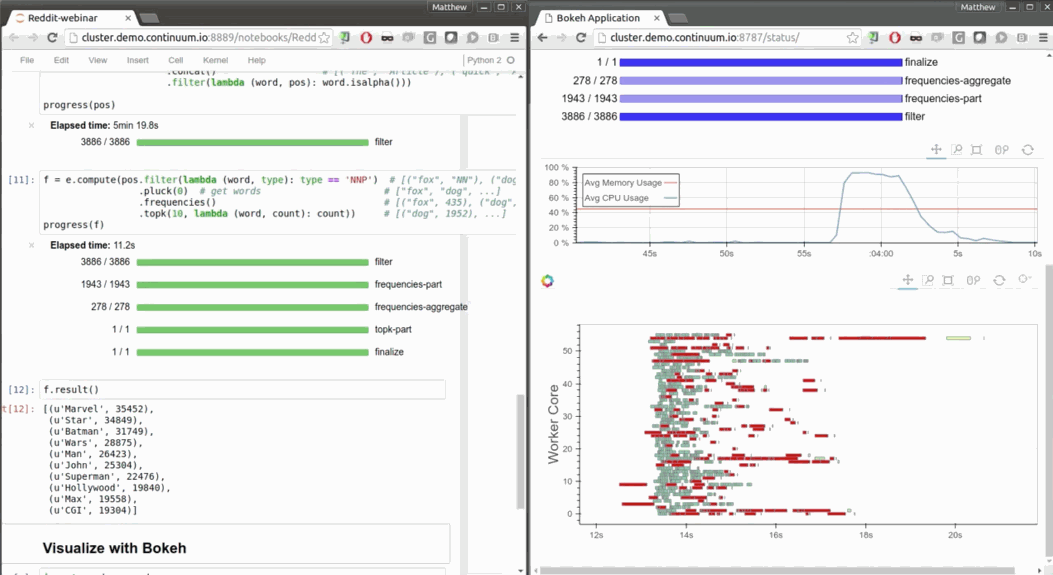
fast and responsive
scales up and down
from a single computer to a cluster
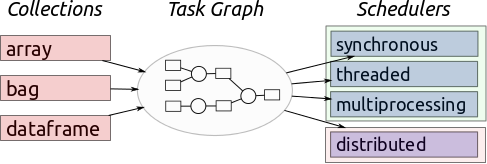
under the hoods
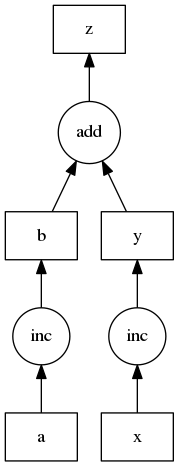
def inc(x):
return x + 1
def add(x, y):
return x + y
# task definition - simple dict!!!
dsk = {'a': 1,
'x': 10,
'b': (inc, 'a'),
'y': (inc, 'x'),
'z': (add, 'b', 'y')}
from dask.threaded import get as tget
tget(dsk, 'z') # execute in multiple threads
from dask.multiprocessing import get as mget
mget(dsk, 'z') # execute in multiple processesfamiliar
to use
map-reduce no more
larger-than-memory
high-level blocked algorithms

dataframes split wrt index
dask.array
# numpy
import numpy as np
f = h5py.File('myfile.hdf5')
x = np.array(f['/small-data'])
x - x.mean(axis=1)
# dask
import dask.array as da
f = h5py.File('myfile.hdf5')
x = da.from_array(f['/big-data'],
chunks=(1000, 1000)) # partition big array
x - x.mean(axis=1).compute()mimics existing known interfaces!
uses numpy arrays under the hood
dask.dataframe
# pandas
import pandas as pd
df = pd.read_csv('2015-01-01.csv')
df.groupby(df.user_id).value.mean()
# dask.dataframe
import dask.dataframe as dd
df = dd.read_csv('2015-*-*.csv')
df.groupby(df.user_id).value.mean().compute()mimics existing known interfaces!
uses pandas dataframes under the hood
dask.bag
import dask.bag as db
b = db.read_text('lines_*.txt')
b.filter(lambda line: 'python' in line)mimics collections, iterators, Spark RDDs
multiprocessing scheduler (GIL)
How does it work?
- Computations defined in dataframes or arrays get translated to a Direct Acyclic Graph (DAG) with all the required tasks
- Array example:
import dask.array as da
x = da.arange(1e9, chunks=3e6)
res = (x + 1).sum()
# res:
dask.array<sum-agg..., shape=(), dtype=int64, chunksize=()>Nothing is calculated yet (lazy evaluation)
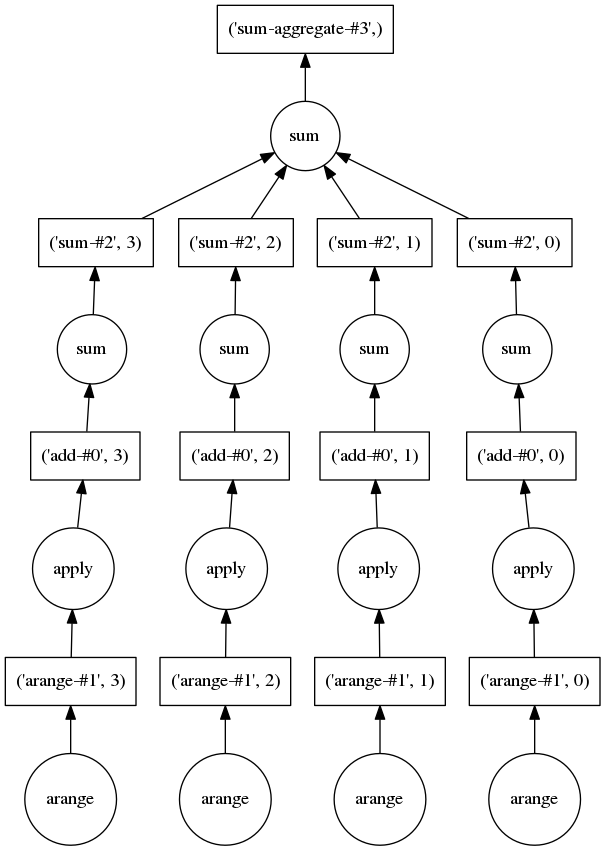
add 1
sum each chunk
add up partial sums
create blocks
res.visualize()operations
results
Compute results
>>> res.compute()
500000000500000000

no GIL - multi-threading madness!
dask.distributed
for computer clusters
dask.distributed
- Separate scheduler that can run on a cluster
- Launches status server a la Spark, using Bokeh
- From Medium Data to Big Data
- Data locality
- Can read from HDFS or S3
- A bit harder to set up, understand and use
setup
# on every computer of the cluster
$ pip install distributed
# on main, scheduler node
$ dask-scheduler
Start scheduler at 192.168.0.1:8786
# on worker nodes (2 in this example)
$ dask-worker 192.168.0.1:8786
Start worker at: 192.168.0.2:12345
Registered with center at: 192.168.0.1:8786
$ dask-worker 192.168.0.1:8786
Start worker at: 192.168.0.3:12346
Registered with center at: 192.168.0.1:8786
# on local machine
$ python
>>> from distributed import Client
>>> client = Client('192.168.0.1:8786')- SSH
- EC2 (script)
- YARN/Mesos
- Marathon
- Kubernetes
- ...
usage
from distributed import Client
# automatically registered as default scheduler
client = Client('192.168.0.1:8786')
import dask.array as da
x = da.arange(1e9, chunks = 3e6)
res = (x + 1).sum()
future = client.compute(res) # returns immediately
# future:
<Future: status: pending, key: finalize-e8bdd...>
# a couple of seconds later...
<Future: status: finished, type: int64, key: finalize-e8bdd...>
future.result() # would block until result is available
# out: 500000000500000000joblib integration
import distributed.joblib
from sklearn.externals.joblib import parallel_backend
from sklearn.datasets import load_digits
from sklearn.grid_search import RandomizedSearchCV
from sklearn.svm import SVC
import numpy as np
digits = load_digits()
param_space = {
'C': np.logspace(-6, 6, 13),
'gamma': np.logspace(-8, 8, 17)
}
model = SVC(kernel='rbf')
search = RandomizedSearchCV(model, param_space, cv=3, n_iter=50, verbose=10)
with parallel_backend('dask.distributed', scheduler_host='localhost:8786'):
search.fit(digits.data, digits.target)
Dask vs Spark
- "Just a library"
- Pure Python
- Good for single computer
- Good for medium data
- Builds on existing libraries
- Easy to write complex algorithms, so other libraries using it! (dask-learn, xarray)
- Whole framework
- JVM, extra serialization
- Aimed for large clusters
- Aimed for Big Big Data
- Replaces existing libraries
- Hard to write complex algorithms
(thanks @eyadsibai)
links & examples
Thanks to all contributors!
- mrocklin
- cowlicks
- jcrist
- sinhrnks
- cpcloud
- shoyer
- 60+!
Thanks to all supporters!
- Continuum Analytics
- XDATA Blaze proyect
- The Moore Foundation
Thank you!
@dukebody
Parallel computing with Dask
By Israel Saeta Pérez
Parallel computing with Dask
Intro to Dask for Data Science




