an introduction to
distributed computing
using Spark and Dask
Israel Saeta Pérez
Adrián Pino Alcalde
June 2016
slides.com/israelsaetaperez/distributed-computing-spark-dask

What will we cover?
- What is distributed computing
- What is Apache Spark
- Main concepts of Spark architecture
- Drivers and workers
- RDDs and DAGs
- Transformations vs. Actions
- Dataframes
- Dask:
- Lazy operations and the DAG
- Dataframes
- Caching
- If time permits: example Analyzing Expedia dataset
with Spark & Dask

What is distributed computing?
Process a long list of (similar) tasks

- Simple
- Slow if lots of tasks
- More complex
- Needs scheduling & orchestration
- Faster only if maaany tasks
Building blocks of distributed computing
- Computing nodes: Threads, processes, machines, executors...
- Distributed-friendly task definition language
- Task partitioning
- Aggregation logic
- Scheduler: Assigns tasks to nodes
- Message Passing channel and protocol
Single machine easy distributed computing
-
Pipelining commands in bash (W10 too!) zcat train.csv.gz | cut -d"," -f1 | grep 2014-12 - Some library ops like numpy.dot(A,B) can use parallel algebra implementations (OpenBLAS/MKL)
-
scikit-learn 'n_jobs' for Grid Search, Random Forest, Cross-Validation...
- Python and R packages for multi-processing and multi-threading
- Need parallelization framework for more complex tasks!
But what if computing needs start growing...
DeepMind
Answer to the Ultimate Question of Life, The Universe, and Everything


AWS EC2 X1
2 TB RAM, 128 vCPU
$4,000/hour
But what if computing needs start growing...
Raspberry Pi cluster
ContinuumIO Dask


Hadoop cluster
HDFS + MapReduce, 2006
- Framework for cluster computing
- Started around 2009 at Berkeley
- Top level Apache project 2014
- Last version 1.6.1 March 2016
- Written mainly in Scala
- Interfaces for Scala, Java, Python and R
- Can run standalone (EC2 scripts available) or Mesos/YARN
- Cool UI for cluster and tasks status
- Emiliano says it's the future
- Correlates with higher salaries

When should you use Spark?
- Client already has a Hadoop/Spark cluster
- You have to process 100s or 1000s of GBs
- You have the $$$, time and knowledge to build a cluster of machines
- You want to use Spark MLLib parallel algorithms, or Spark Streaming
- For anything else... use GNU Utils or Dask!
How is it different from plain Hadoop MapReduce?
- Easy interactive lazy task definition using RDDs
- LRU data caching - but Spark is NOT in-memory!
- Efficient pipelining via DAGs
- Result: Better suited for iterative algorithms and data exploration
- BUT: It needs Hadoop HDFS and libraries for distributed data access (data locality)
Spark cluster architecture
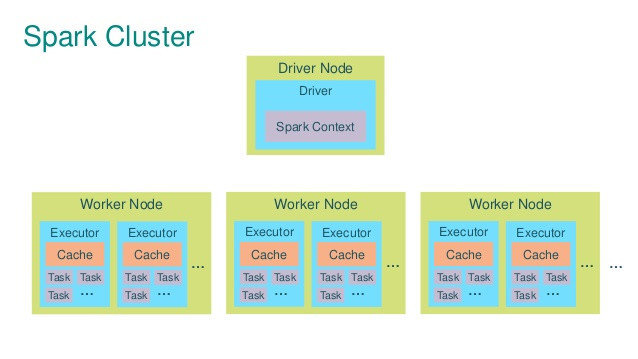
Image credit: Alexey Grishchenko
- Entry point
- Task definition
- Scheduler
- WebUI monitor
- Work, work work...
- Data I/O
Easy start
- spark.apache.org/downloads.html
- Get last pre-built version
- Launch Jupyter notebook
IPYTHON_OPTS="notebook" /path/to/spark/bin/pyspark --master local[nthreads]
Driver Web UI
port 4040 by default
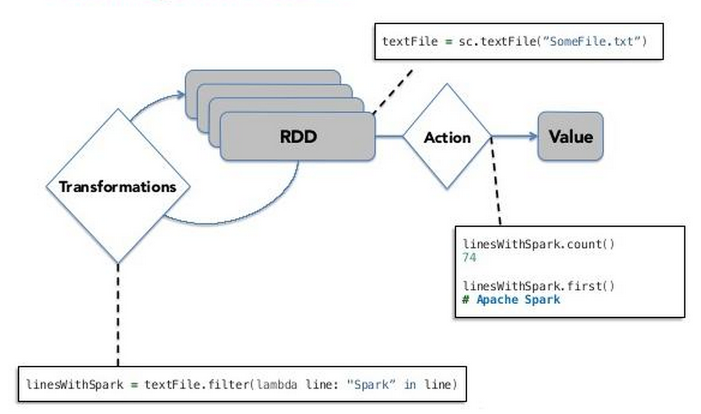
Resilient Distributed Datasets
- Representation of unit of data
- List of elements
- Follow map-reduce paradigm
- (Just) metadata:
- Where data comes from
- How is it partitioned
- Computations to be performed (tasks definition)
Map-Reduce paradigm
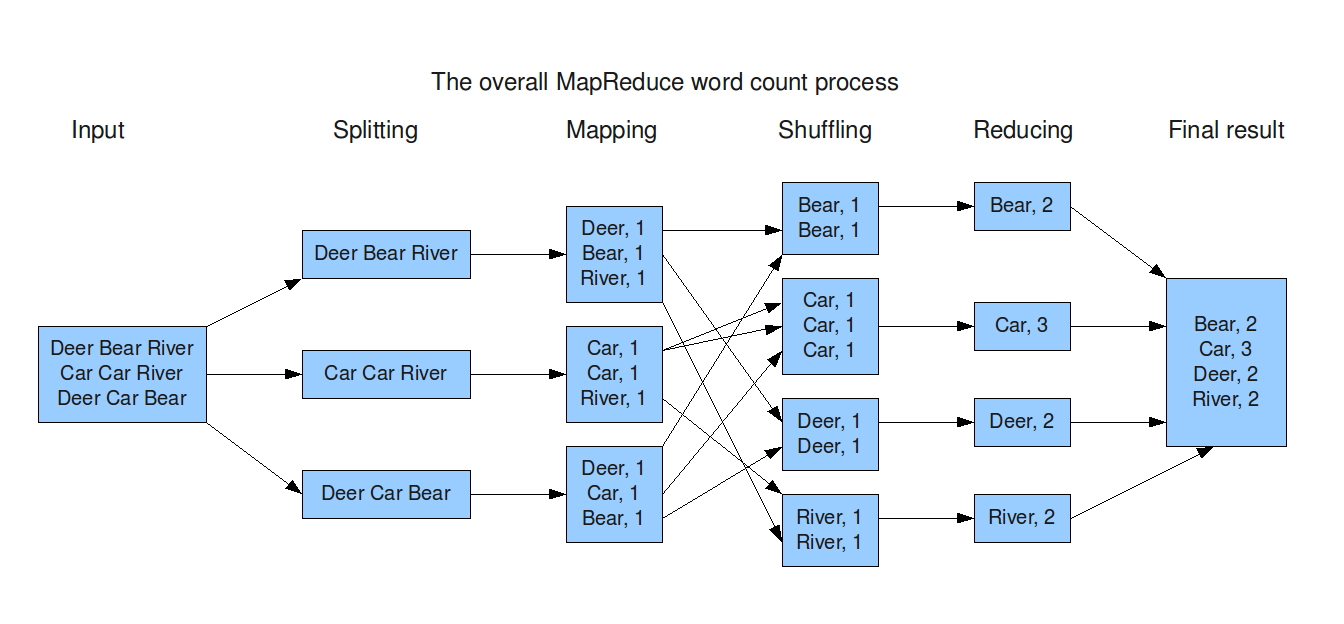
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)RDDs transformations & actions
Basic transformations
-
map: Apply an arbitrary function to every element of the RDD. Example:
-
filter: Keep only elements satisfying the specified condition. Example:
-
reduceByKey: Aggregate values by key. Example:
-
join: Return an RDD containing all pairs of elements with matching keys in self and other. Example:
>>> rdd = sc.parallelize(["b", "a", "c"])
>>> sorted(rdd.map(lambda x: (x, 1)).collect())
[('a', 1), ('b', 1), ('c', 1)]>>> rdd = sc.parallelize([1, 2, 3, 4, 5])
>>> rdd.filter(lambda x: x % 2 == 0).collect()
[2, 4]>>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
>>> sorted(rdd.reduceByKey(lambda x, y: x + y).collect())
[('a', 2), ('b', 1)]>>> x = sc.parallelize([("a", 1), ("b", 4)])
>>> y = sc.parallelize([("a", 2), ("a", 3)])
>>> sorted(x.join(y).collect())
[('a', (1, 2)), ('a', (1, 3))]Basic actions
- collect: Take all elements. Can destroy computers.
-
reduce: Aggregate the elements of the RDD using a commutative and associative function that takes two arguments and returns one. Example:
-
take: Take the first num elements of the RDD. Similar to df.head() Example:
- takeOrdered: Get the N elements from a RDD ordered in ascending order or as specified by the optional key function. Example:
>>> sc.parallelize([1, 2, 3, 4, 5]).reduce(lambda x, y: x + y)
15>>> sc.parallelize([2, 3, 4, 5, 6]).cache().take(2)
[2, 3]>>> sc.parallelize([10, 1, 2, 9, 3, 4, 5, 6, 7], 2).takeOrdered(6, key=lambda x: -x)
[10, 9, 7, 6, 5, 4]Directed Acyclic Graphs

Image credit: Alexey Grishchenko
Stages: Parallel tasks grouped
Disk shuffle
Caching
- Data is not cached by default
- Least Recent Used approach: If cache mem is full, drop oldest blocks
- Several storage levels: Cache to memory and/or disk
- .cache() == .persist(MEMORY_ONLY)
>>> lines = sc.textFile('expedia.csv')
>>> lines.cache() # transformation, doesn't compute anything
>>> lines.count() # performs expensive count and caches 'lines'
37670293
>>> lines.count() # faster b/c 'lines' is in RAM
37670293Spark Dataframes
- Released Spark 1.3, Feb 2015
- Mimics pandas dataframes
- No more map-reduce crap, better for DS
- Columnar format
- Can run SQL Queries! (better in Spark 2.0)
- Great speedup for native ops b/c no Python serialization
young = users[users.age < 21] # filter users by age
young.select(young.name, young.age + 1) # increment everybody’s age by 1
young.groupBy("gender").count() # return ppl count for each genderSpark MLLib
Parallelized Large ScaleMachine Learning
- Logistic Regression, with SGD and LBGFS
- Ridge, Lasso, Linear Regression
- SVM, Naïve Bayes
- Random Forest, GBTrees
- Alternating Least Squares (recommendations)
- See also: spark-sklearn, sparkit-learn
Dask
Pandas meets distributed computing
What is Dask
It's a parallel computing library for analytics in python.
- Performs operations from disk, so fits in memory becomes fits in disk
- Very easy to set up (you probably have it installed already) and use it (really)
- It's a python library, not an interface to Scala, Java or any weird thing.
- Scales from your laptop to clusters.
What is Dask
Three main core elements:
-
Dask array: distributed numpy arrays
-
Dask bag: to work with arbitrary collections of data (equivalent to RDD in Spark)
-
Dask dataframe: distributed pandas dataframes
What does under the hood
- Operations in Dask are performed lazily
- When you define a computation, dask elaborates the Direct Acyclic Graph (DAG) of the tasks required to complete it.
- Example with dask arrays:
import dask.array as da
x = da.arange(1e7, chunks = 3e6)
res = x.dot(x) - da.var(x)- We do this, and nothing is calculated (lazy evaluation)
What did just happened?
To see what dask did, we call the method visualize:
res.visualize()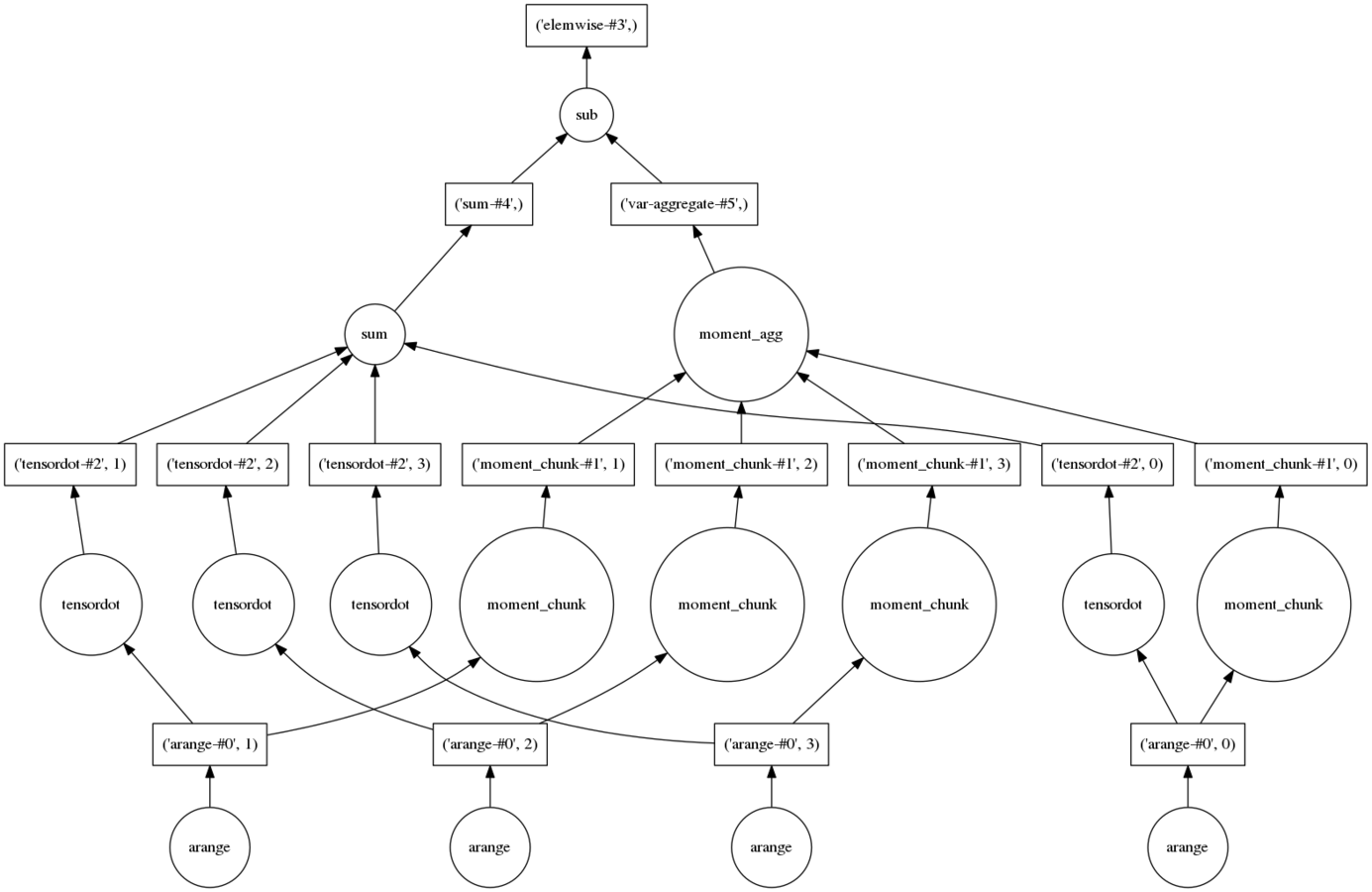
How to get results?
To trigger computation of a graph of tasks we call the method compute:
res.compute()We can chain different operations, and evaluate them at the end, without having to have them in RAM
Multicore madness
Take for instance:
res = da.arange(1e9, chunks = 3e6)
res = x.dot(x) - da.var(x)
%timeit res.compute()
1 loop, best of 3: 6.96 s per loopMulticore!

Dask dataframes
- On-disk parallel equivalent to pandas famous library for data analysis.
- Very easy to use, (really):
import dask.dataframe as dd
df = dd.read_csv('filename.csv')- Lazy operations again, this does not load any data to disk, but sets the partitions:
Dask dataframes
- On-disk parallel equivalent to pandas famous library for data analysis.
- Very easy to use, (really):
import dask.dataframe as dd
df = dd.read_csv('filename.csv')
result = df.groupby([list_columns]).var.mean()
result.compute()- Lazy operations again, this does not load any data to disk, but sets the partitions:
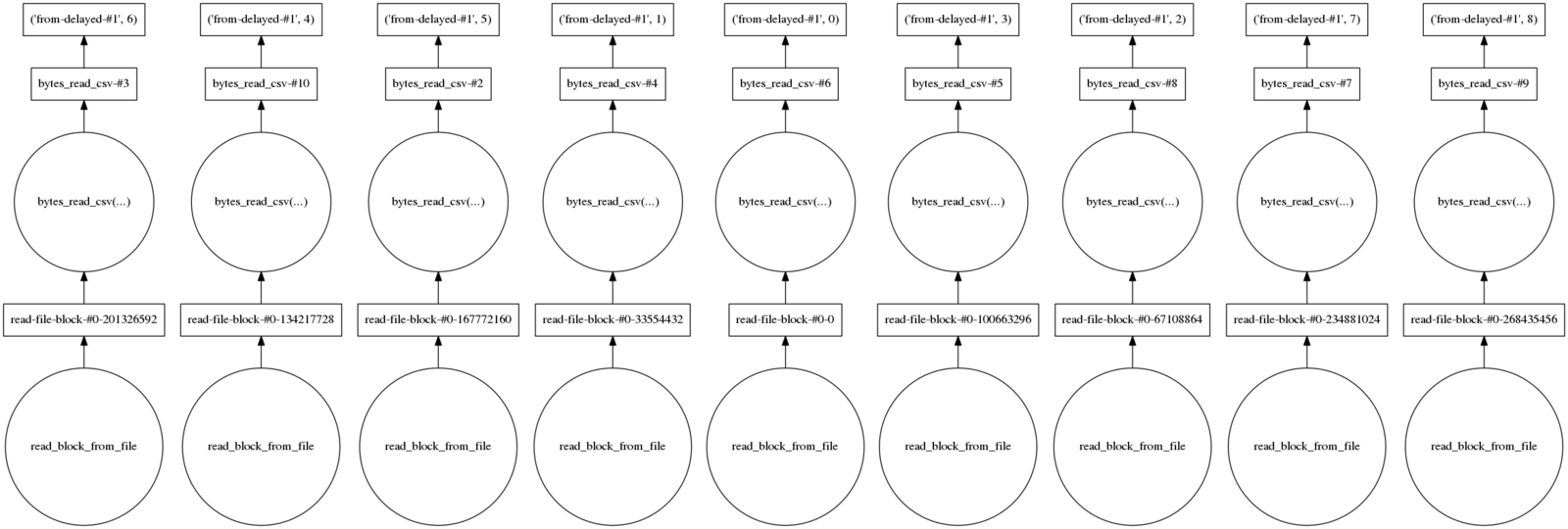
Dask dataframes
Dask dataframes
If you're confortable using pandas, you'll find like at home.

Pandas and the GIL
- In CPython's implementation of Python, native python code can't run into multiple threads simultaneously (safety reasons). It's called the Global Interpreter Lock (GIL).
- Still, if python interpreter runs functions written in external libraries (C/Fortran) can release the GIL.
- Most of pandas methods are written in C (Cython).
- Dask splits dataframe operations into different chunks and launch them in different threads achieving parallelism.
I/O operations
Load data from a single and multiple files using globstrings:
df1 = dd.read_csv('file.csv')
df2 = dd.read_csv('file_*.csv')
df3 = df2.to_csv('file_output.csv')Read and write to hdf files.
dd.read_hdf('file_input.hdf5', '/data')
dd.to_hdf('file_output.hdf5', key='data')Integration with new generation of compressed/columnar storage (castra, bcolz)
Indices
Partitioning of dataframes is determined by a column of the dataframe, its index.
df.divisions
df_new = df.set_index(df.column)Doing this will reshufle the data, but subsequent operations involving this index will be faster.
df.set_index(df.column, compute=False).to_castra('df.castra')
df.groupby('column').apply(foo)
Dask's own columnar format, castra, stores data in columns, compressed and partitioned on the index.
Caching
As with Spark, dask support caching for faster repetitive computations, but it works differntly.
LRU may not be the best for analytic computations. Instead, we can be more opportunistic and keep:
- Expensive to compute
- Cheap to store
- Frequently used
np.std(x) # small result, costly to recompute
np.transpose(x) # big result, cheap to recompute
from dask.cache import Cache
cache = Cache(cache=1e9)
cache.register()
df.column.apply(whatever).compute()
(df.column.apply(whatever) + 1).compute() # this call will be fastSummary
When to use dask:
- Doing exploratory analysis on larger-than-memory datasets
- Working with multiple files at the same time.
- Applying embarrasingly parallel tasks
When not to use dask :
- When your operations require shuffling (sorting, merges, etc.)
- Simple operations with fast on th command line: sorts, deduplicating files, subselecting cols, etc.
Remember: GNU Coreutils is your friend

References
Spark:
- Spark docs (obviously)
- Data Science and Engineering with Spark XSeries
- Alexey Grishchenko blog
- Mastering Apache Spark gitbook (incomplete but deep)
Dask
Distributed computing with Spark & Dask
By Israel Saeta Pérez
Distributed computing with Spark & Dask
An introduction to the concepts of distributed computing with examples in Spark and Dask




