FROM ORM TO LEFT OUTER JOIN
How we grew with GO


Jan-Oliver Pantel
Backend @ NewStore
@JanPantel
Give talks!

Project scaffolding

Generics



Package manager

GOLEM

How did X solve Y
Directory structure

Pointers vs. Values
Testing
I [...] think that's one of the "beauties" of Go: it only does what you type -- there's almost no magic involved.
At first I was disappointed with the feature set of IDEs, but now there is Gogland
While I still sometimes long for more advanced language features, I'm always glad when seeing other's code and understanding it immediately. As I read more existing code than writing new, it pays off hugely for me
Using repository-like interfaces makes me think about the interface first.
[In other languages] it feels like I'm just writing helpers to hide the database handling part.
So it feels like my interfaces are more well thought when I write GO code.
ORM
Why?
- Productivity
- Reusability
- Database agnostic apps
- Domain model mapping
- Higher level APIs
- (Lazy loading)
- (Rich compile time checks)
- (Query optimization)
- (Connection pooling)
- (Caching)
Trade offs
- Understanding the query
- Inattention to query performance
- Inattention to the query
- Performance loss
- Implementation specific tech debt
- Serial id field requirement
- Developer specialisation
- Understanding how the cache works
GO is not a good match
- GO's flat type system
- No is-a, but has-a
- Hard to implement ActiveRecord
var user User
err := db.Find("users", 1).Scan(&user)iUser, err := db.Find(User{}, 1)
user := iUser.(*User)
var users []*User
q.Condition(
qbs.NewCondition(
"last_name = ?", "Doe",
).Or(
"age < ?", 12,
),
).Limit(2).
OrderByDesc("age").
FindAll(&users)var users []User
orm.Where(
"last_name = ? OR age < ?", "Doe", 12,
).Limit(2).OrderBy("age").FindAll(&users)type Product struct {
ID string `db:"id"`
Name string `db:"name"`
}
func (p *Product) TableName() string {
return "product"
}type Product struct {
/* ... */
CategoryID string
}SELECT category_i_d FROM products;Inner platform effect
is the tendency of software architects to create a system so customizable as to become a replica, and often a poor replica, of the software development platform they are using.


Considering our use case
- Microservice architecture
- One DB per service
- No shared data
- Few objects per service
- (Connection pooling)
- (Concurrency control)
Rethinking DB use
- Do we really need the whole database object/row available in-memory?
- Don't we do more special queries and not just simple CRUD?
- Can't we store complex data in a non-structured way?
- Do we really need to normalise data?
Repository pattern
- Abstract the data access from business logic
- Reusability ✔️ DB agnostic ✔️
- Write meaningful functions
- Compile time checks ✔️
-
Write context related functions
- Lazy loading ✔️
-
Hand crafted query
- Attention to the query ✔️
-
"It's just SQL"
- No library specialisation needed ✔️
Using repository-like interfaces makes me think about the interface first.
SQL is powerful
database/sql + lib/pq

db.Query("SELECT bar FROM foo WHERE id = $1", id)rows.Scan(&record.ID)Connection pooling
Concurrency safe use
Prepared Stmt
stmt, err := tx.Prepare("INSERT INTO foo VALUES ($1)")
if err != nil {
log.Fatal(err)
}
for i := 0; i < 10; i++ {
_, err = stmt.Exec(i)
if err != nil {
log.Fatal(err)
}
}
if err := stmt.Close(); err != nil {
log.Fatal(err)
}ATTENTION
Bulk imports
stmt, err := txn.Prepare(pq.CopyIn("users", "name", "age"))
if err != nil {
log.Fatal(err)
}
for _, user := range users {
_, err = stmt.Exec(user.Name, int64(user.Age))
if err != nil {
log.Fatal(err)
}
}
_, err = stmt.Exec()
if err != nil {
log.Fatal(err)
}
err = stmt.Close()
if err != nil {
log.Fatal(err)
}Arrays
var infos []string
rows, err := db.Query(
"SELECT infos FROM myTable WHERE id = 'foobar';",
)
// ...
err := rows.Scan(pq.Array(&infos))db.Exec(
"INSERT INTO myTable (infos) VALUES ($1);",
pq.StringArray(infos),
)rows, err := repo.db.Query(
"SELECT infos FROM myTable WHERE id = any($1::text[]);",
pq.StringArray(ids),
)Case study
Inventory
Store
Stock items
Allocations
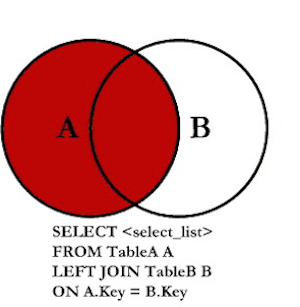
CREATE OR REPLACE VIEW unallocated_stock_items AS (
SELECT items.* FROM stock_items AS items
LEFT OUTER JOIN allocations AS alloc
ON alloc.stock_item_id = items.id
WHERE alloc.stock_item_id IS NULL
);
SELECT (
(SELECT COUNT(si.*) FROM unallocated_stock_items AS si
WHERE si.product_id = $1 AND si.store_location_id = $2)
-
(SELECT COUNT(res.*) FROM reservations AS res
WHERE res.product_id = $1 AND res.store_location_id = $2)
);SELECT (SUM(quantity) > 0) AS available FROM atp
WHERE product_id = $1
GROUP BY product_id
LIMIT 1;Debugging helpers
CREATE OR REPLACE FUNCTION archive_deleted_allocations()
RETURNS trigger AS $$
BEGIN
INSERT INTO allocations_archive VALUES ((OLD).*);
RETURN OLD;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER archive_deleted_allocations
BEFORE DELETE ON allocations
FOR EACH ROW EXECUTE PROCEDURE archive_deleted_allocations();CREATE OR REPLACE FUNCTION update_updated_at()
RETURNS trigger AS $$
BEGIN
NEW.updated_at = (NOW() AT TIME ZONE 'UTC');
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER atp_updated_at_trigger
BEFORE UPDATE ON atp
FOR EACH ROW EXECUTE PROCEDURE update_updated_at();What is missing?
- $16 becomes inconvenient
- ORMs bring data migration tools
- We started to use Alembic
- Debugability suffers when using sophisticated queries
But why?
- Go made me rethink my relationship to databases
- Go's sql tools made the decision easy to digest
- I just wanted to praise the database/sql package :-)

How we grew with go
By Jan Pantel




