Title Text

BIG DATA
on AWS
Title Text
Contact
Javi Moreno
@ciberado
javi.moreno@capside.com

Title Text
Agenda: first part
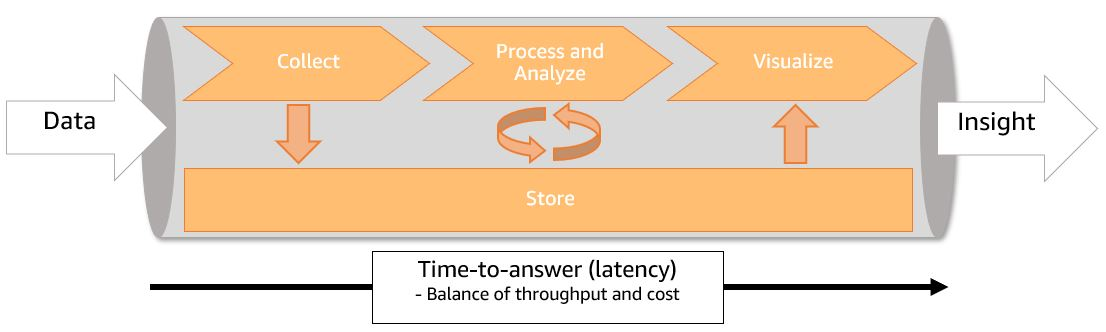
Quick and fast intro
Datalakes with S3
Format transformation and ETL with Glue
Ingestion with Kinesis Streams y Firehose
Preparing raw data with Lambda
Realtime processing with Kinesis Analytics
DynamoDB for processed dataon
Title Text
Querying the datalake with Athena
Transforming massive amounts of data with EMR/Hive
Interactive queries with Redshift
Spectrum for integrating Redshift and S3
Data visualization with QuickSight
Realtime dashboards with Kinesis Client Library
Cleanup and conclusion
Agenda: second part
Title Text
Quick and fast intro
Title Text

Title Text
Datalakes with S3
Unlimited and affordable object-based storage
99.999999999% data durability
Easy world-wide replication
Data encryption at rest and on the fly
Versioning and life cycle management

Title Text
ETL with Glue
Extract, transform and load managed service
Data catalog for partition management
Optional schema discovery with Crawlers
Advanced job schedule
Code generation

Title Text
Ingestion with Kinesis
Managed near real-time queue
Capacity measured in Shards (1000 rps or 1MBs)
Unlimited ingestion scalability
Up to seven days retention period
Easy processing
Long-term storage integration with Firehose

Title Text
Preparing with Lambda
Serverless star product
Integrated with most services
$0.20 per 1.000.000 invocations
Nodejs, Python, Java, C# and Java
C9 editor integrated with the console
Seamless massive autoscaling

Title Text
Kinesis analytics
Codeless near real-time processing
Powered by a SQL-like language
Input transformation available
Results can be processed with Lambda
Text
Text

Title Text
DynamoDB
Semi-structured database
Very fast and predictable performance
Integrated autoscaling
Global tables
Easy backup procedure
SDK based support for JSON

Title Text
Querying with Athena
Query S3 without ETL
Serverless Presto-based infrastructure
Standard SQL variant supported
Pay per scanned amount of data
Title Text
Elastic Map Reduce
Managed infrastructure for Yarn
Supports Hadoop MapReduce, Presto, Spark...
Integrated with S3
Master node, core nodes and task nodes
Scale up without problems
Cost effective with spot instances support

Title Text
Redshift datawarehouse
Columnar based storage
Interactive query over 1.5PB of data
Postgresql SQL dialect and connectivity
Included snapshot for backup
Change cluster size at any time
Extreme performance for aggregation

Title Text
Spectrum tables
Massive managed cluster
Integrated with Redshift nodes
Join with tables stored directly on S3
Pay for amount of scanned data
SQL dialect compatible with Redshift
Title Text
Quicksight visualizations
Software as a Service data explorer
Powered by S.P.I.C.E on-memory engine
Flexible visualization library
Easy-to-use and attractive user interface
Integrated with most data sources

Title Text
Dashboards with KCL
Powerful java wrapper over Kinesis API
Automatic recovery from failure based on DynamoDB
Supports batch processing
Makes easy to create scalable consumers
Designed to be run on EC2 instances
Title Text
Cleanup
S3 buckets
EC2 instances ¡
Glue databases
DynamoDB tables
Athena catalogs
Redshift clusters
Quicksight datasets

Title Text
@ciberado

Title Text

Bigdata on AWS
By Javier Moreno




