Predicting Music Preferences
Curation
Prediction
https://github.com/jeangelj/predict_music_taste
Get
Clean
Analyze
Predict
Get Data





song attributes
competition data
user behavior
genre
labels
lyrics
database
Clean Data
#delete columns
data=data.drop('song_id_y',1)
#rename song_id column (got changed during merges)
data=data.rename(columns = {'song_id_x':'song_id'})
#substitute all NaN with 0
data = data.fillna(0)
#add a column with 1, so we can count songs
data['count'] = 1
#substitute 0 values with mean or median of column
median_song_hotness = data['song_hotness'].dropna().median()
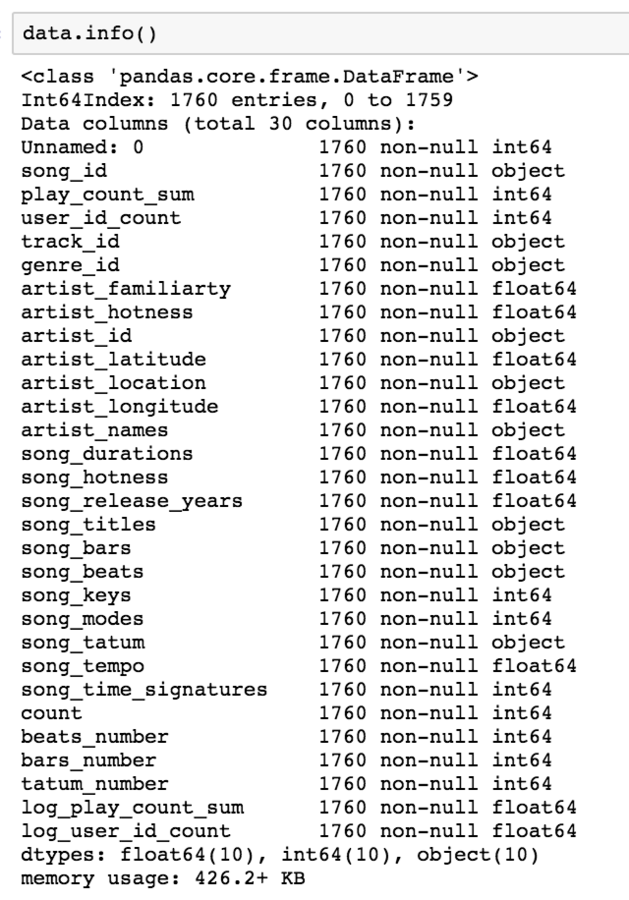
data['song_hotness'] = data.song_hotness.mask(data.song_hotness == 0, median_song_hotness)shape - rows: 1760, columns: 30
Clean Data
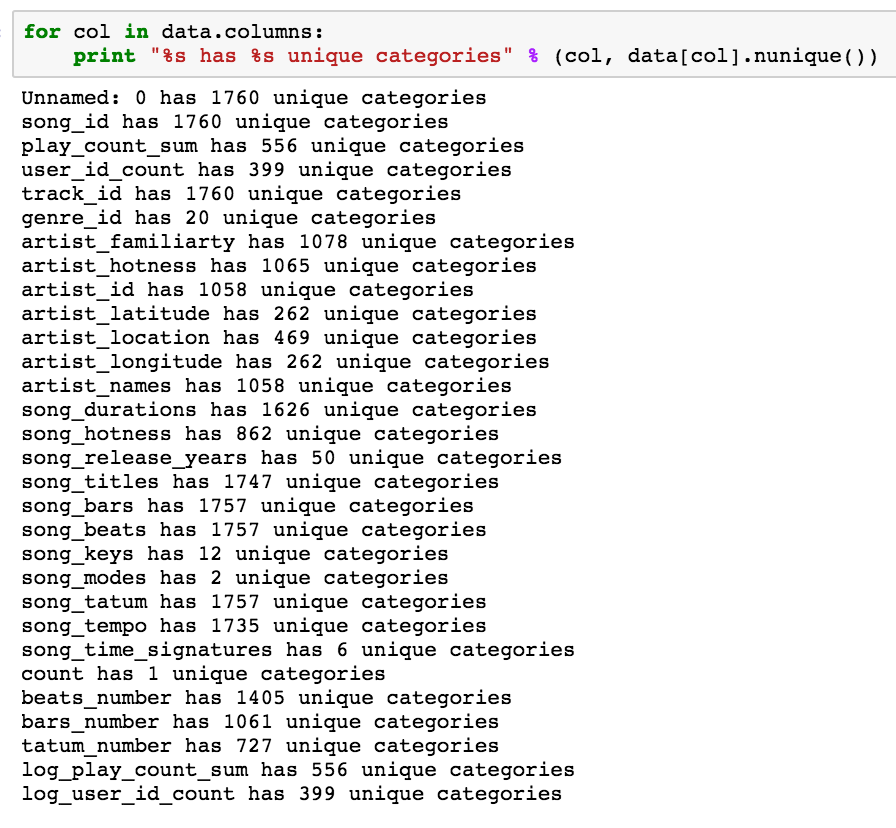
Add features
data['beats_number'] = [len(x) for x in data.song_beats]
funcs = {'play_count':['sum'], 'user_id':['count']}
behavior_df = user_behavior.groupby('song_ids').agg(funcs)
data['log_play_count_sum'] = np.log(data[['play_count_sum']])
data['log_user_id_count'] = np.log(data[['user_id_count']])from sklearn.feature_extraction import DictVectorizer
categorical_features = data[['genre_id']]
dv = DictVectorizer()
cat_matrix = dv.fit_transform(categorical_features.T.to_dict().values())#fix the columns consisting of lists
#add columns for user behavior
#vectorize categorical feature "genre"
Predict
- Song Popularity (supervised learning)
- Song Recommendation (unsupervised learning)
Feature Selection
#RFE
from sklearn.feature_selection import RFE
rfe = RFE(model, 5) #5 features
rfe_support_
rfe.ranking_from sklearn.ensemble import ExtraTreesClassifier
etc= ExtraTreesClassifier()
etc.feature_importances#feature_importance
#Correlation
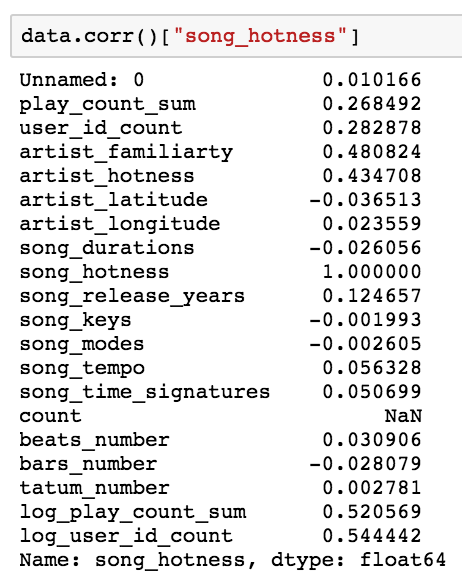
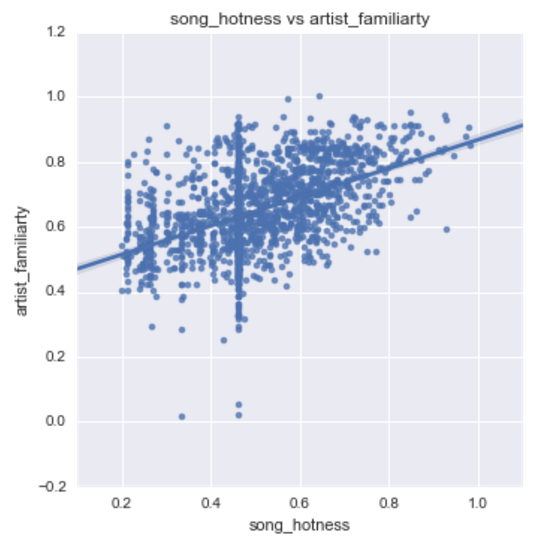
Artist Influence
#artist_familiarty
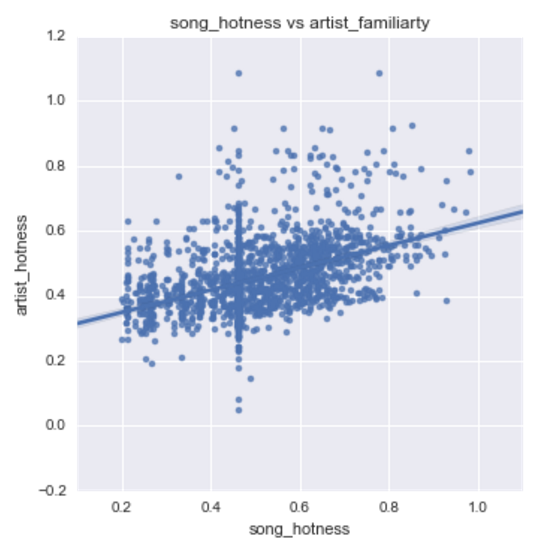
#artist_hotness
Song Popularity
Regression:0.39
- Linear Regression: 0.24
- Logistic Regression:0.23
- dmatrices + Logistic Regression: 0.39
knn:0.24
Features:
artist_familiarity
artist_hotness
song_modes
song_time_signatures
log_play_count_sum
Reguralization
- Lasso (alpha = 0.1): 0.16
- Ridge (alpha = 0.5): 0.36
- make_pipeline(StandardScaler(), PolynomialFeatures(degree), LinearRegression())
Decision Tree
- DecisionTree: 0.13
- RandomForest(n_estimators=300, criterion=entropy): 0.21
SVM:0.33
Features:
artist_familiarty
artist_hotness
song_duration
song_tempo
bars_number
Boosting
- Ada Boost Classifier: 0.33
- Gradient Boosting Classifier: 0.04
Song Recommendation
Feature Matrix
We have 393,727 ratings for 1,780 songs from 20 genres by 266,346 listeners.

new data set
with rating
Feature Matrix
#vectorize genre
from sklearn.feature_extraction import DictVectorizer
categorical_features = df[['genre_id']]
dv = DictVectorizer()
cat_matrix = dv.fit_transform(categorical_features.T.to_dict().values())
#add other features to matrix
from scipy.sparse import hstack
other_features = df[['artist_familiarty','artist_hotness','song_modes',\
'song_time_signatures','song_durations','song_tempo',\
'beats_number','song_release_years']]
#create matrix
X = hstack([cat_matrix, other_features])
y = df.ratingeither change all features to strings
or pandas.get_dummies
Content Filtering
Collaborative Filtering
Predict
This is Charlie



Recommended
NOT Recommended
Conclusion
why 450 attributes are the wrong approach (Pandora)
not considered attributes
is human categorizing really necessary
Thank You
"I have not failed.
I've just found 10,000 ways that won't work."
Thomas A. Edison
Title Text
Predicting Music Preferences
By jdagher