Introduction to Apache Spark

Jason Foster - Orion Healthcare
About Me
- Senior Software Engineer at Orion Health
- 10+ years in Healthcare IT, 20+ years in engineering
- Variety of other industry experience, including Mutual Funds, Telecom and HR
- Part of team developing BI & Analytics platform at Orion
Orion Health is a global, independently owned eHealth software company with proven experience in delivering interoperable, connected solutions for healthcare facilities, organizations and regions.
The Scottsdale location is focused on BI & Analytics on a Big Data platform.
About Orion Health
High-Level Agenda
- Background, Components and Architecture
- Key Concepts and Spark Applications
- Installation and Spark Tooling
- Spark Programming
- Real-World Use Case
What is Apache Spark?
- Open-Source cluster computing framework for data analytics
- Originally developed in AMPLab at UC Berkely (2009), open-sourced in 2010, transferred to Apache 2013
- Compatible with Hadoop HDFS
- Designed to be faster and more general purpose than Hadoop MapReduce
MapReduce
MapReduce is a programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster.
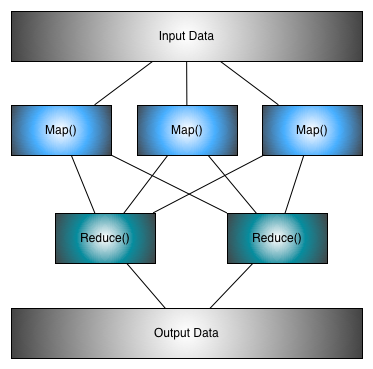
MapReduce Example
Determine maximum temperature for each city in our data set.
Toronto, 20
Whitby, 25
Brooklyn, 22
Rome, 32
Toronto, 4
Rome, 33
Brooklyn, 18Toronto, 21
Whitby, 24
Brooklyn, 23
Rome, 35
Toronto, 5
Rome, 36
Brooklyn, 14Toronto, 19
Whitby, 26
Brooklyn, 19
Rome, 34
Toronto, 6
Rome, 31
Brooklyn, 16Toronto, 22
Whitby, 26
Brooklyn, 21
Rome, 34
Toronto, 2
Rome, 30
Brooklyn, 201. Map() for each file returns the maximum for each city in the file
Toronto, 20
Whitby, 25
Brooklyn, 22
Rome, 33Toronto, 21
Whitby, 24
Brooklyn, 23
Rome, 36Toronto, 19
Whitby, 26
Brooklyn, 19
Rome, 34Toronto, 22
Whitby, 26
Brooklyn, 21
Rome, 342. Reduce() returns the max for the city from all results
Toronto, 22
Whitby, 26
Brooklyn, 23
Rome, 36Advantages Over MapReduce
- Single platform contains multiple tools
- Interactive Queries
- Improved Performance
- Simpler Infrastructure Management
- Clean, concise APIs in Scala, Java and Python

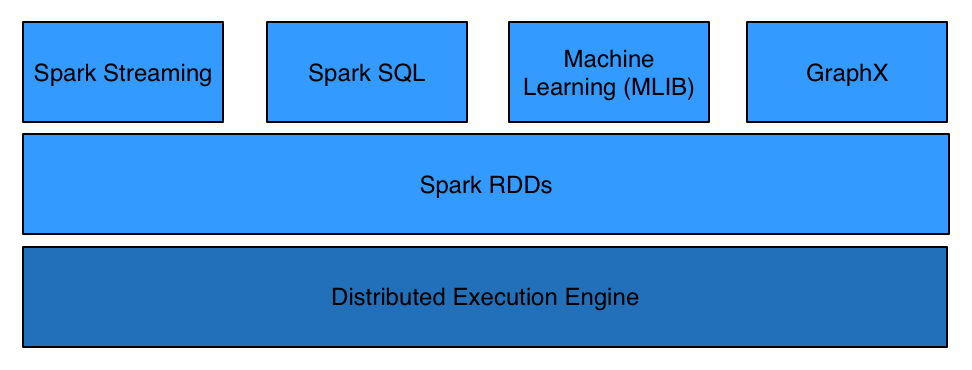
Spark Components
- Spark Core
- Spark Streaming
- Spark Machine Learning (MLib)
- Spark SQL
- GraphX
Spark Streaming
- Extension of the core Spark API
- Fault-tolerant, high throughput processing of real-time data
- Diverse data ingestion (Kafka, Flume, Twitter, ZeroMQ, socket)
- Complex processing of batched data (map, reduce, join)
- Output to filesystem, dashboards, databases or to other Spark tooling
Machine Learning (MLib)
- MLlib is a Spark implementation of some common machine learning algorithms and utilities
- Standard component of Spark
- Includes common algorithms for classification, regression, clustering and collaborative filtering
Spark SQL
- Alpha component of Spark 1.0.2
- Allows relational queries expressed in SQL, HiveQL, or Scala to be executed using Spark
- Based on a special type of RDD, SchemaRDD
- SchemaRDDs can be created from Parquet, JSON or results of HiveQL
Spark GraphX
- Alpha component of Spark
- Enables users to interactively load, transform and compute on massive graph structures
- Fault-tolerant, In-Memory
Spark Architecture
- Resilient Distributed Dataset (RDD)
- Directed Acyclic Graph (DAG) Execution Engine
- ClosureCleaner
Closure & ClosureCleaner
- Closure is a table storing a reference to each of the non-local variables of a function
- Scala sometimes errs on the side of capturing too many outer variables
- ClosureCleaner traverses the object at runtime and prunes the unnecessary references
Concept - RDD
- Spark's primary abstraction
- Collection of objects spread across a cluster
- Allows for in-memory computations on large datasets
- Fault-tolerant - Automatically rebuilt on failure
- Controllable Persistence
RDD Operations
- Transformations - create new datasets from input (e.g. map, flatMap, filter, union, join)
- Actions - return a value after executing calculations on the dataset (reduce, reduceByKey, take, count)
Types of RDDs
- Parallelized collections that are based on existing Scala collections
- Hadoop datasets that are created from the files stored on HDFS
Concept - Execution Engine
- Graph of tasks to execute and where to execute them
- Related to RDD lineage
Spark Application Anatomy
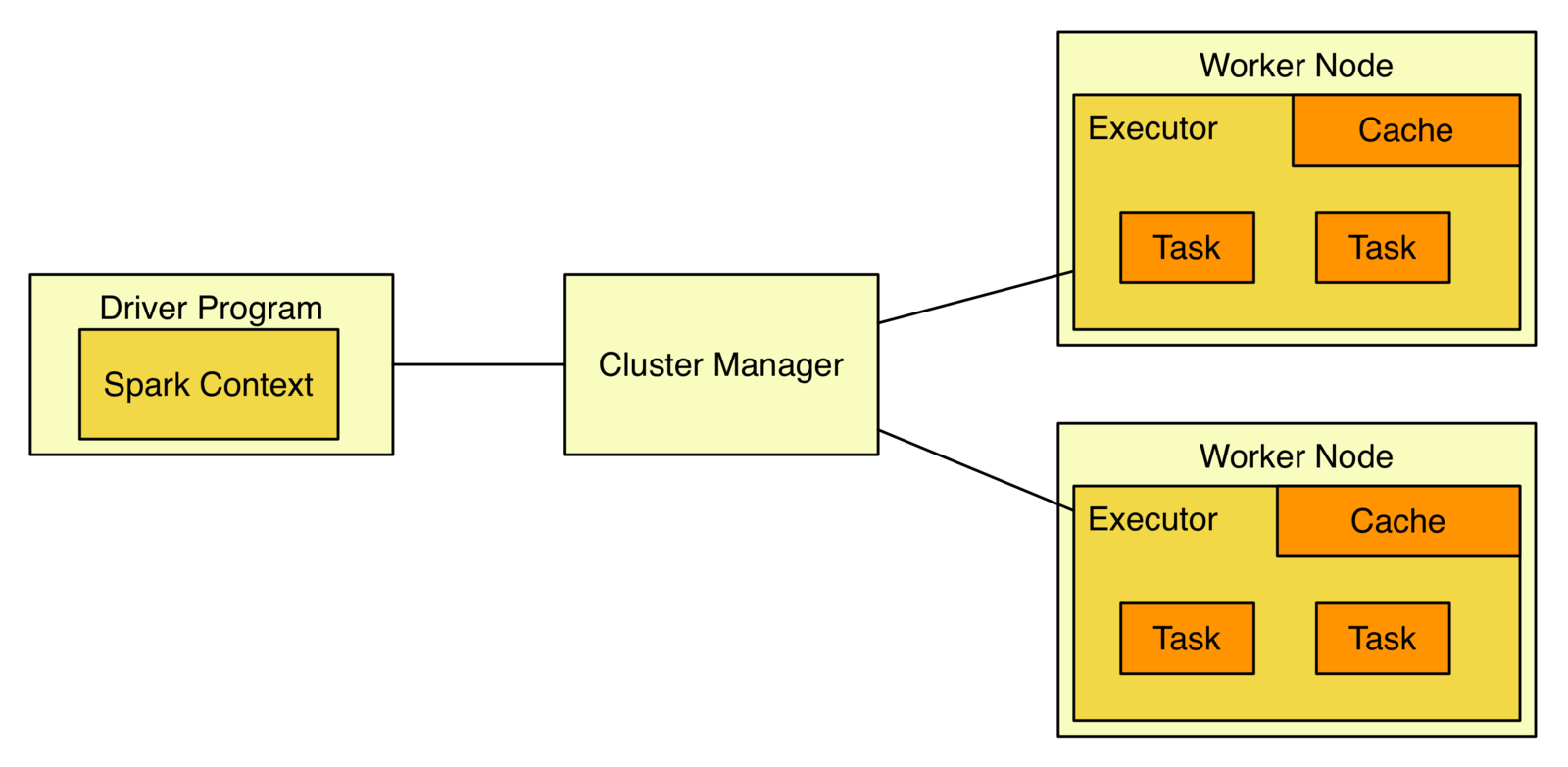
- Spark applications are independent sets of processes on a cluster, coordinated by the SparkContext in a Driver program
- SparkContext can connect to several types of cluster managers
- Once connected, Spark acquires executors on cluster nodes
- It then sends application code (defined by JAR or Python files passed to SparkContext) to the executors
- Finally, SparkContext sends tasks for the executors to run
Installing Spark
- Spark runs on both Windows and Unix
- All that is required is a JVM (Java 6+) with java on the system path, or JAVA_HOME set correctly
- Get the binaries (http://spark.apache.org/downloads.html)
- Untar
$ wget http://d3kbcqa49mib13.cloudfront.net/spark-1.0.2-bin-hadoop2.tgz
$ tar xvf spark-1.0.2-bin-hadoop2.tgz
$ ln -s spark-1.0.2-bin-hadoop2 sparkWill also need some sort of data source, like HDFS, Cassandra, text files, etc. on which Spark will operate
What's In the Box?
- bin - directory containing scripts related to the Spark shell and submitting jobs to Spark
- sbin - directory containing artifacts related to clusters
- conf - directory containing configuration files
- logs - directory containing Spark log files
- Also a web console (http://localhost:8080)
-rw-r--r--@ 318K Jul 25 15:30 CHANGES.txt
-rw-r--r--@ 29K Jul 25 15:30 LICENSE
-rw-r--r--@ 22K Jul 25 15:30 NOTICE
-rw-r--r--@ 4.1K Jul 25 15:30 README.md
-rw-r--r--@ 35B Jul 25 15:30 RELEASE
drwxr-xr-x@ 612B Jul 25 15:30 bin
drwxr-xr-x@ 340B Aug 21 16:03 conf
drwxr-xr-x@ 238B Jul 25 15:30 ec2
drwxr-xr-x@ 102B Jul 25 15:30 examples
drwxr-xr-x@ 238B Jul 25 15:30 lib
drwxr-xr-x 476B Sep 4 20:05 logs
drwxr-xr-x@ 306B Jul 25 15:30 python
drwxr-xr-x@ 544B Jul 25 15:30 sbin
drwxr-xr-x 2.6K Aug 28 13:19 workUsing Spark Shell
- Simple way to learn the API
- Powerful tool to analyze data interactively
- Shell for Scala, and a shell for Python
$ ./bin/spark-shell
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.0.2
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_65)
Type in expressions to have them evaluated.
Type :help for more information.
14/09/07 16:33:35 WARN NativeCodeLoader: Unable to load native-hadoop library for your
platform... using builtin-java classes where applicable
Spark context available as sc.
scala>Spark Shell Demo
Basic Spark Operations
- Creating RDDs
scala> val textFile = sc.textFile("README.md")
textFile: spark.RDD[String] = spark.MappedRDD@2ee9b6e3scala> val fruits = sc.parallelize(List("apples", "bananas"))
fruits: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize
at <console>:12- Transformations
scala> val sparkLines = textFile.filter(line => line.contains("spark"))
sparkLines: org.apache.spark.rdd.RDD[String] = FilteredRDD[2] at filter
at <console>:14- Actions
scala> sparkLines.count()
res0: Long = 8Lazy Evaluation
- Spark will not actually execute until it sees an action
- Internally records meta-data to indicate this operation has been requested
- Affects both loading RDDs and Transformation
- Another improvement over MapReduce
- Users are free to organize their program into smaller, more manageable operations
Passing Functions to Spark
- API relies heavily on passing functions in the driver program to run on the cluster
- Applies to most Transformations and some Actions
- Different mechanisms in different languages
Function Passing - Scala
- Anonymous function syntax
val lines = sc.textFile("README.md")
val lineLengths = lines.map(x => x.length()).reduce((x,y) => x + y)- Static methods in a global singleton object
object CounterHelper {
def myLengthFunction(x: String) : Int = {
return x.length();
}
def myAccumlator(x: Int, y: Int) : Int = {
return x + y
}
}
val lines = sc.textFile("README.md")
val totalLengths = lines.map(x => CounterHelper.myLengthFunction(x))
.reduce((x,y) => CounterHelper.myAccumlator(x, y))Function Passing - Java
- Represented by classes implementing interfaces in org.apache.spark.api.java.function package
- Two ways to implement:
Implement the Function interfaces inline, in your own anonymous inner class or named class and pass an instance of it to Spark
or
Use Java 8 Lambda expressions
Function Passing Java Examples
- Inline
- Anonymous Inner Class
- Java 8 Lambda Expression
JavaRDD<String> lines = sc.textFile("README.md");
JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() {
public Integer call(String s) { return s.length(); }
});
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) { return a + b; }
});class GetLength implements Function<String, Integer> {
public Integer call(String s) { return s.length(); }
}
class Sum implements Function2<Integer, Integer, Integer> {
public Integer call(Integer a, Integer b) { return a + b; }
}
JavaRDD<String> lines = sc.textFile("README.md");
JavaRDD<Integer> lineLengths = lines.map(new GetLength());
int totalLength = lineLengths.reduce(new Sum());JavaRDD<String> lines = sc.textFile("README.md");
JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
int totalLength = lineLengths.reduce((a, b) -> a + b);Common Transformations
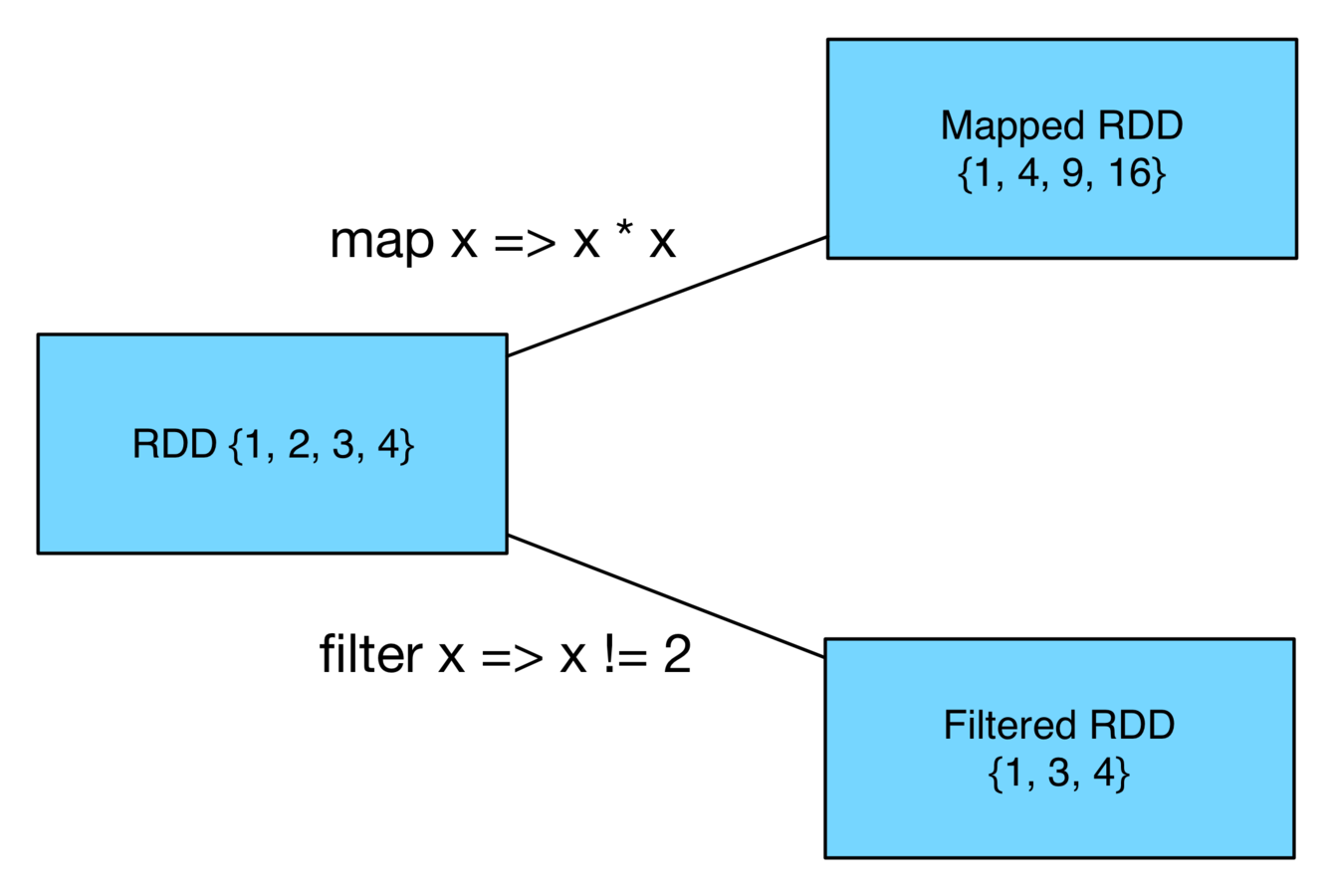
- filter() - takes a function and returns an RDD whose elements pass the filter function
- map() - takes a function and returns an RDD whose elements are the result of the function being applied to each element in the original RDD
- flatMap() - takes a function and returns an RDD of the contents of the iterators of each element
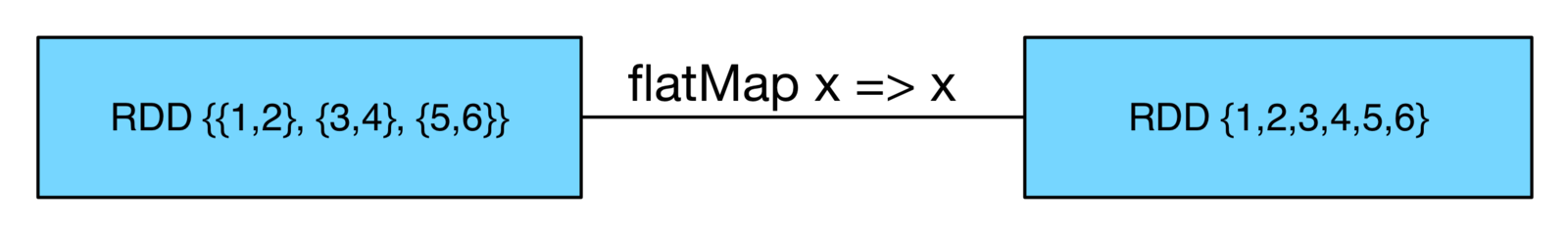
More Common Transformations
- distinct() - removes duplicates
- union() - produce an RDD containing all elements from both RDDs
- intersection() - produce an RDD containing only elements found in both RDDs
- subtract() - produce an RDD that has none of the elements from another RDD
Common RDD Actions
- reduce() - takes a function which operates on two elements of the same type within an RDD and returns a new element of the same type
- fold() - like reduce() but also takes a "zero value" to be used for the initial call on each partition

More Common RDD Actions
- aggregate() - takes a zero value (like fold), a function to combine the elements from an RDD with the accumulator and a function to merge two accumulators
val result = input.aggregate((0, 0))(
(x, y) => (x._1 + y, x._2 + 1),
(x, y) => (x._1 + y._1, x._2 + y._2))
val avg = result._1 / result._2.toDouble
More Common RDD Actions
- foreach() - Apply a provided function to each element of the RDD
- collect() - Return all elements from an RDD
- count() - Returns the number of elements in an RDD
- take(num) -Returns the top num elements from an RDD
- top(num) - Returns num elements from an RDD

Persistence (Caching)
- Recall Spark RDDs use lazy evaluation
- Reusing the same RDD multiple times causes Spark to recompute the RDD and all its dependencies
- Nodes that compute the RDD store their partitions
- Spark re-computes lost partitions on failure (when needed)
- Can also replicate across nodes to mitigate performance hit in the event of failure
Persistence is a key tool for iterative algorithms and fast interactive use
Avoid re-computing by utilizing persistence
Spark Persistence - Levels
| Level | Meaning |
|---|---|
| MEMORY_ONLY | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, some partitions will not be cached and will be recomputed on the fly each time they're needed. This is the default level. |
| MEMORY_ONLY_SER | Store RDD as serialized Java objects (one byte array per partition). This is generally more space-efficient than deserialized objects, especially when using a fast serializer, but more CPU-intensive to read. |
| MEMORY_AND_DISK | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, store the partitions that don't fit on disk, and read them from there when they're needed. |
| MEMORY_AND_DISK_SER | Similar to MEMORY_ONLY_SER, but spill partitions that don't fit in memory to disk instead of recomputing them on the fly each time they're needed. |
| DISK_ONLY | Store the RDD partitions only on disk. |
Spark Persistence - Levels
| Level | Space Used | CPU Time | In-Memory | On Disk | Comments |
|---|---|---|---|---|---|
| MEMORY_ONLY | High | Low | Y | N | |
| MEMORY_ONLY_SER | Low | High | Y | N | |
| MEMORY_AND_DISK | High | Medium | Some | Some | Spills to disk if too much data |
| MEMORY_AND_DISK_SER | Low | High | Some | Some | Spills to disk if too much data |
| DISK_ONLY | Low | High | N | N |
Spark Persistence - Notes
- Attempt to cache too much, Spark will auto-evict old partitions using an LRU cache policy
- Memory-only storage Spark recomputes the next time they are accessed... memory-and disk are written out to disk
- Don't have to worry if you ask Spark to cache too much data
- Caching unnecessarily can lead to excessive re-compute
- unpersist() to manually remove items from cache
Working With Pair RDDs
- groupByKey() - groups together values with the same key. The values are iterable per key
- reduceByKey() - returns an RDD where the values for each key are aggregated using the given reduce function
- sortByKey() - returns an RDD in key order
- keys() - returns an RDD of just the keys
- values() - returns an RDD of just the values
- mapValues() - Apply a function to each value of a pair RDD without changing the key
Working with Pair RDDs
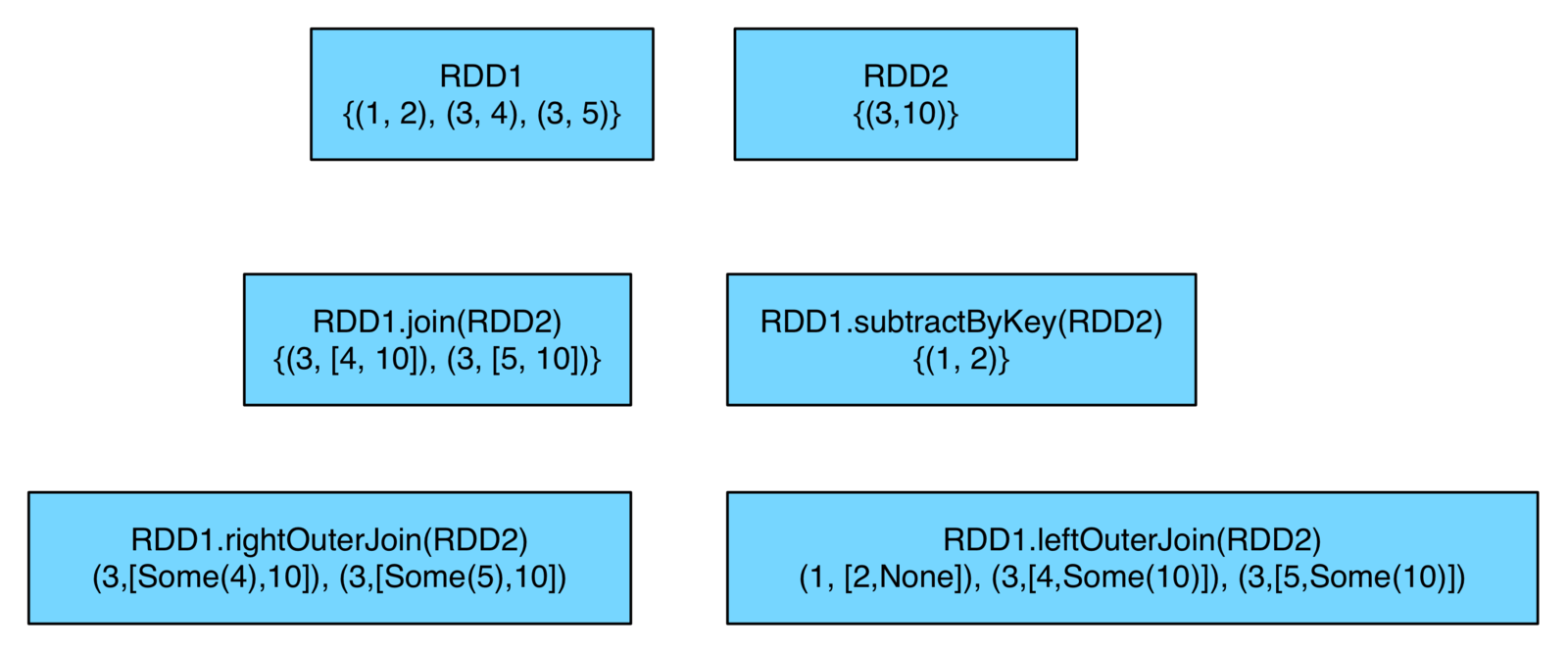
- join() - performs an inner join between two RDDs (also a rightOuterJoin() and leftOuterJoin())
- subtractByKey() - removes elements with a key present in the other RDD
Use Case - Readmission Risk
As part of the Affordable Care Act, the Centers for Medicare & Medicaid Services (CMS) began the the Bundled Payments for Care Improvement initiative (BPCI) and introduced several models to be tested in the US.
In BPCI Model 2, the selected episodes of care will include the inpatient stay in the acute care hospital and all related services during the episode. The episode will end either 30, 60, or 90 days after hospital discharge.
Research has shown that bundled payments can align incentives for providers – hospitals, post-acute care providers, doctors, and other practitioners – to partner closely across all specialties and settings that a patient may encounter to improve the patient’s experience of care during a hospital stay in an acute care hospital, and during post-discharge recovery.
- Instead of being paid per procedure, hospitals now are reimbursed once for the entire episode of care.
- Forces hospitals, and all those involved in the episode, during and after a procedure, to focus on outcomes
Use Case - Readmission Risk
- One measure that hospitals could assess in this model is the risk of re-admission after a procedure
- The goal would be to identify patients who are highes-risk to help control costs and achieve better outcomes
Use Case - Readmission Risk
- Hemoglobin < 12 g/Dl = 1 point
- Sodium level < 135 mEq/l = 1 point
- Non-elective admission = 1 point
- Length of stay >= 5 days = 2 points
- 1-5 Admissions last 12 months = 2 points
- > 5 Admissions last 12 months = 5 points
Readmission Risk Scoring
Cassandra Source Schema

Get abnormal lab results
val results = sc.cassandraTable("pjug", "pat_results").cache()
val abnormalHGB = results
.filter(x => x.getString("test_name") == "HGB")
.filter(y => y.getDouble("test_value") < 12)
val abnormalNA = results
.filter(x => x.getString("test_name") == "NA")
.filter(y => y.getDouble("test_value") < 135)JavaRDD<CassandraRow> abnormalHGB = patients.filter(new Function<CassandraRow, Boolean>() {
@Override
public Boolean call(CassandraRow row) throws Exception {
return ((row.getString("test_name") == "HGB") &&
(row.getDouble("test_value") < 12));
}
});
JavaRDD<CassandraRow> abnormalNA = patients.filter(new Function<CassandraRow, Boolean>() {
@Override
public Boolean call(CassandraRow row) throws Exception {
return ((row.getString("test_name") == "NA") &&
(row.getDouble("test_value") < 135));
}
});Java
Scala
Find Admissions (1 - 5 times)
val admit1to5 = encounters
.select("patient_id")
.map(row => (row.getString("patient_id"), 1))
.reduceByKey((x,y) => x + y)
.filter(row => (row._2 >= 1 && row._2 <= 5))
.map(x => (x._1, 2))JavaPairRDD<String, Integer> admit1to5 = encounters
.select("patient_id")
.mapToPair(new PairFunction<CassandraRow, String, Integer>() {
@Override
public Tuple2<String, Integer> call(CassandraRow arg0) throws Exception {
return new Tuple2<String, Integer>(arg0.getString("patient_id"), 1);
}}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer arg0, Integer arg1) throws Exception {
return (arg0 + arg1);
}}).filter(new Function<Tuple2<String,Integer>, Boolean>() {
@Override
public Boolean call(Tuple2<String, Integer> arg0) throws Exception {
return ((arg0._2>=1) && (arg0._2 <=5));
}}).mapToPair(new PairFunction<Tuple2<String,Integer>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<String, Integer> arg0) throws Exception {
return new Tuple2<String, Integer>(arg0._1, 2);
}
});Java
Scala
Calculating Total Score
val scoring = patients
.union(abnormals)
.union(longStay)
.union(nonElective)
.union(admit1to5)
.union(admit5orGt)
.reduceByKey((x,y) => x + y)JavaRDD<Score> scoresRDD = allPatients
.union(abnormals)
.union(longStay)
.union(nonElective)
.union(admit1to5)
.union(admit5orGt)
.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer arg0, Integer arg1) throws Exception {
return arg0 + arg1;
}}).map(new Function<Tuple2<String, Integer>, Score>() {
@Override
public Score call(Tuple2<String, Integer> input) throws Exception {
return new Score(input._1(), input._2());
}
});Java
Scala
Readmission Risk
Code Walkthrough and Demo
Q & A
Thank You!

Introduction to Apache Spark
By Jason R. Foster
Introduction to Apache Spark
In this session we will introduce Apache Spark, its origins, installation, architecture, tooling, programming constructs and how it addresses specific problems in Big Data applications. A specific use case will be presented as a demonstration of some of Spark's key concepts and core capabilities.


