Semi-Supervised Sequence Modeling with Cross-View Training
Kevin Clark, Minh-Thang Luong, Christopher D. Manning, Quoc V. Le
Outline
- Problem and Motivation
- Cross-View Training
- Cross-View Training Models
- Experiments
- Results
- Takeaways
Focus: sequence modeling tasks attached to a shared Bi-LSTM sentence encoder
Aim: improves the representations of a Bi-LSTM sentence encoder using a mix of labeled and unlabeled data
Problem and Motivation
Semi-supervise learning
Overview
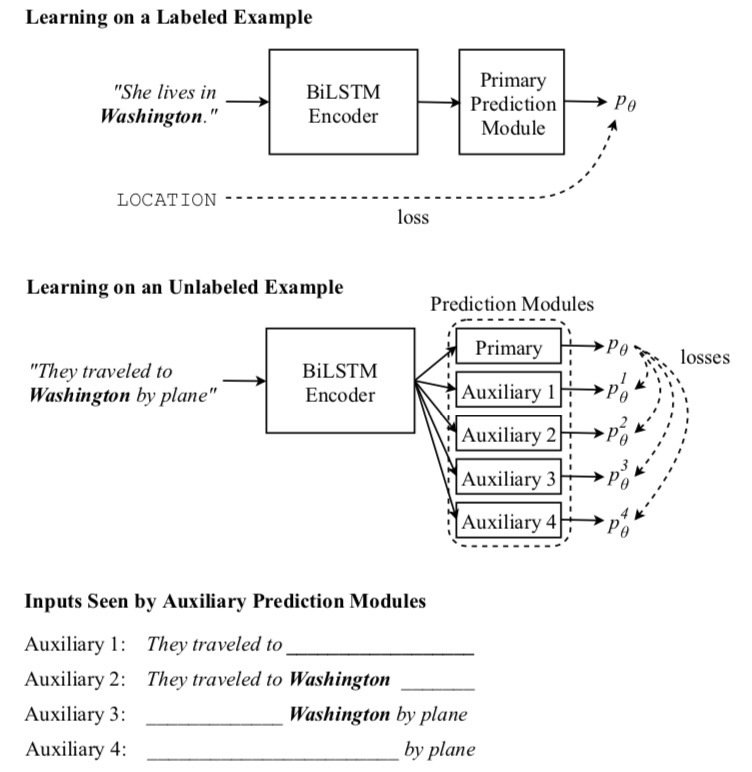
[Labeled examples] standard supervised learning.
[Unlabeled examples] train auxiliary prediction modules with different views of the input to agree with the primary prediction module.
view 1:
view 2:
view 4:
view 3:
Method
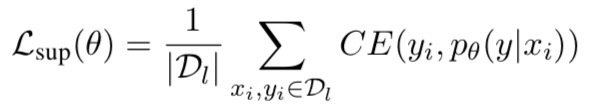
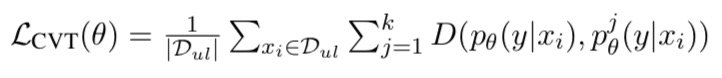
CVT trains the modules to match the primary prediction module on the unlabeled data by minimizing:
The module is trained on labeled examples by minimizing standard cross entropy loss:
primary prediction
auxiliary prediction
\mathcal{L} = \mathcal{L}_{sup} + \mathcal{L}_{CVT}
Method
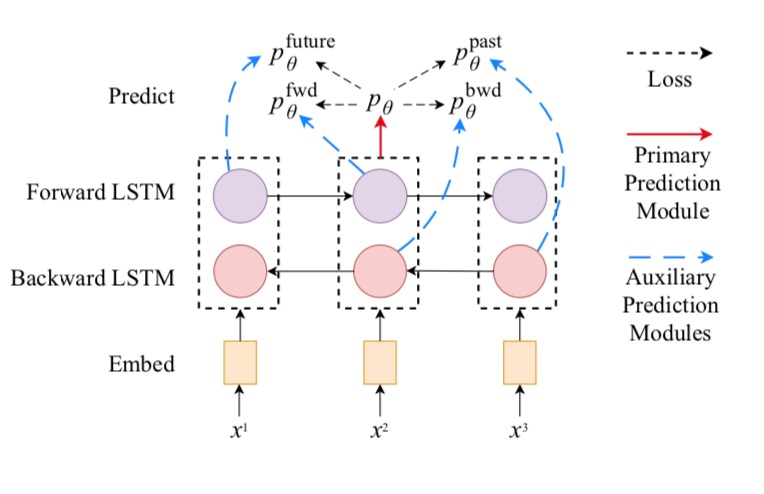
\mathcal{L}_{CVT} = \mathcal{L}^{future} + \mathcal{L}^{past} + \mathcal{L}^{fwd} + \mathcal{L}^{bwd}
Cross-View Training Models
- Sequence Tagging
- Dependency Parsing
- Sequence-to-sequence learning
Sequence Tagging
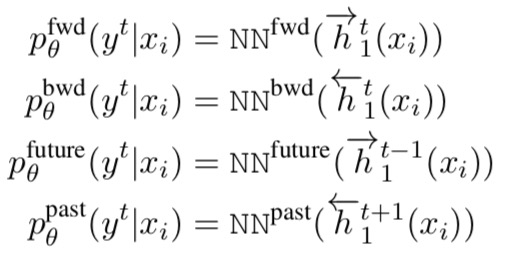
Primary module:
Auxiliary modules
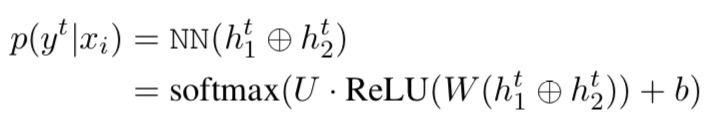
Dependency Parsing
"head"
Words in a sentence are
treated as nodes in a graph.
x_i = x_i^1,...x_i^T
x_i^t \to (u,t,r) \to x_i^u
"relation"
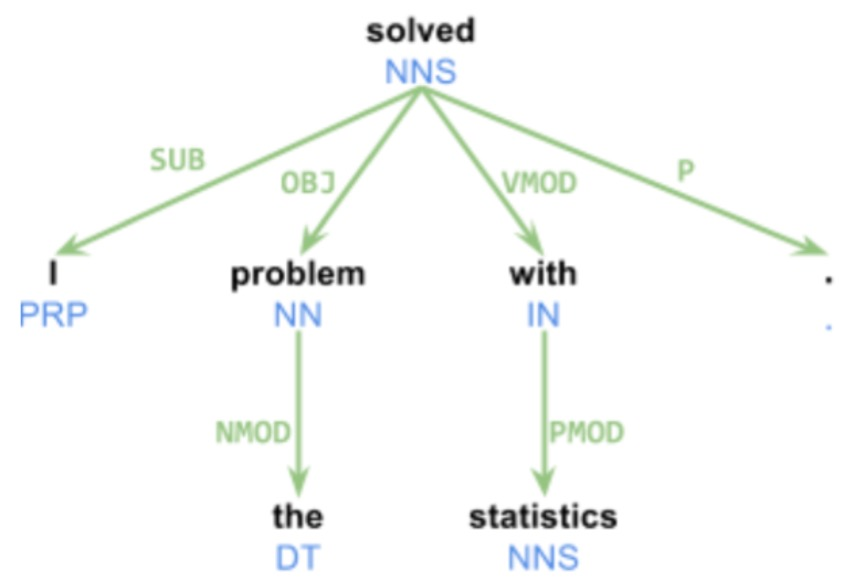
(solved, I, SUB)
Dependency Parsing
x_i = x_i^1,...x_i^T
x_i^t \to (u,t,r) \to x_i^u

Words in a sentence are
treated as nodes in a graph.
The probability of an edge (u,t,r) is given as:
h_1^u
: encoder hidden unit on word
h_2^u
: decoder hidden unit on word
u
u
The bilinear classifier uses a weight matrix Wr specific to the candidate relation as well as a weight matrix W shared across all relations.
Dependency Parsing
x_i = x_i^1,...x_i^T
x_i^t \to (u,t,r) \to x_i^u
Words in a sentence are
treated as nodes in a graph.
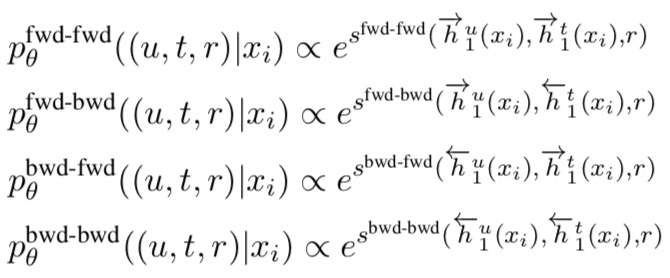
Auxiliary modules:
Sequence to Sequence Learning
Model: encoder-decoder with attention
\alpha_j \propto e^{h^jW_\alpha \overline{h}^t}
Attention
context
c_t=\sum_j \alpha_j h^j
p(y_i^t | y_i^{1:t},x_i)=softmax(W_s a_t)
a_t=tanh(W_a[c_t,h_t])
\overline{h}^t
\overline{h}^{1}
h^{1}
h^t
...
...
encoder
decoder
Sequence to Sequence Learning
p(y_i^t | y_i^{1:t},x_i)=softmax(W_s a_t)
a_t=tanh(W_a[c_t,h_t])
\overline{h}^t
\overline{h}^{1}
h^{1}
h^t
Two auxiliary decoders share embedding and LSTM parameters but maintain independent parameters for attention and softmax
dropout(a_t)
p^{future}_\theta(y_i^t|y_i^{1:t},x_i)=softmax(W_s^{future},a_{t-1}^{future})
auxiliary1:
auxiliary 2:
encoder
decoder
...
...
Sequence to Sequence Learning
\overline{h}^t
\overline{h}^{1}
h^{1}
h^t
encoder
decoder
No target sequence for unlabeled examples.
Teacher forcing to get an output distribution over the vocabulary from the primary decoder at each time step?
...
...
?
Sequence to Sequence Learning
\overline{h}^t
\overline{h}^{1}
h^{1}
h^t
encoder
decoder
produce hard targets for the auxiliary modules by running the primary decoder with beam search on the input sequence.
...
...
Beam search for sequence to sequence learning
[Step 1] select 2 words with max probability, i.e. a, c
Example: beam size = 2, vocab={a,b,c}
[Step 2] all combination {aa,ab,ac,ca,cb,cc}, select 2 sequences with max probability, i.e. aa, ca
[Step 3] repeat, until encounter <END>, output 2 sequences with max probability
Ref: https://www.zhihu.com/question/54356960
Experiments
Compare Cross-View Training on 7 tasks:
- CCG: Combinatory Categorical Grammar Supertagging
- Chunk: Text Chunking
- NER: Name Entity Recognition
- FGN: Fine-Grained NER
- POS: Part-of-Speech Tagging
- Dep. Parse: Dependency Parsing
- Translate: Machine Translation
Results
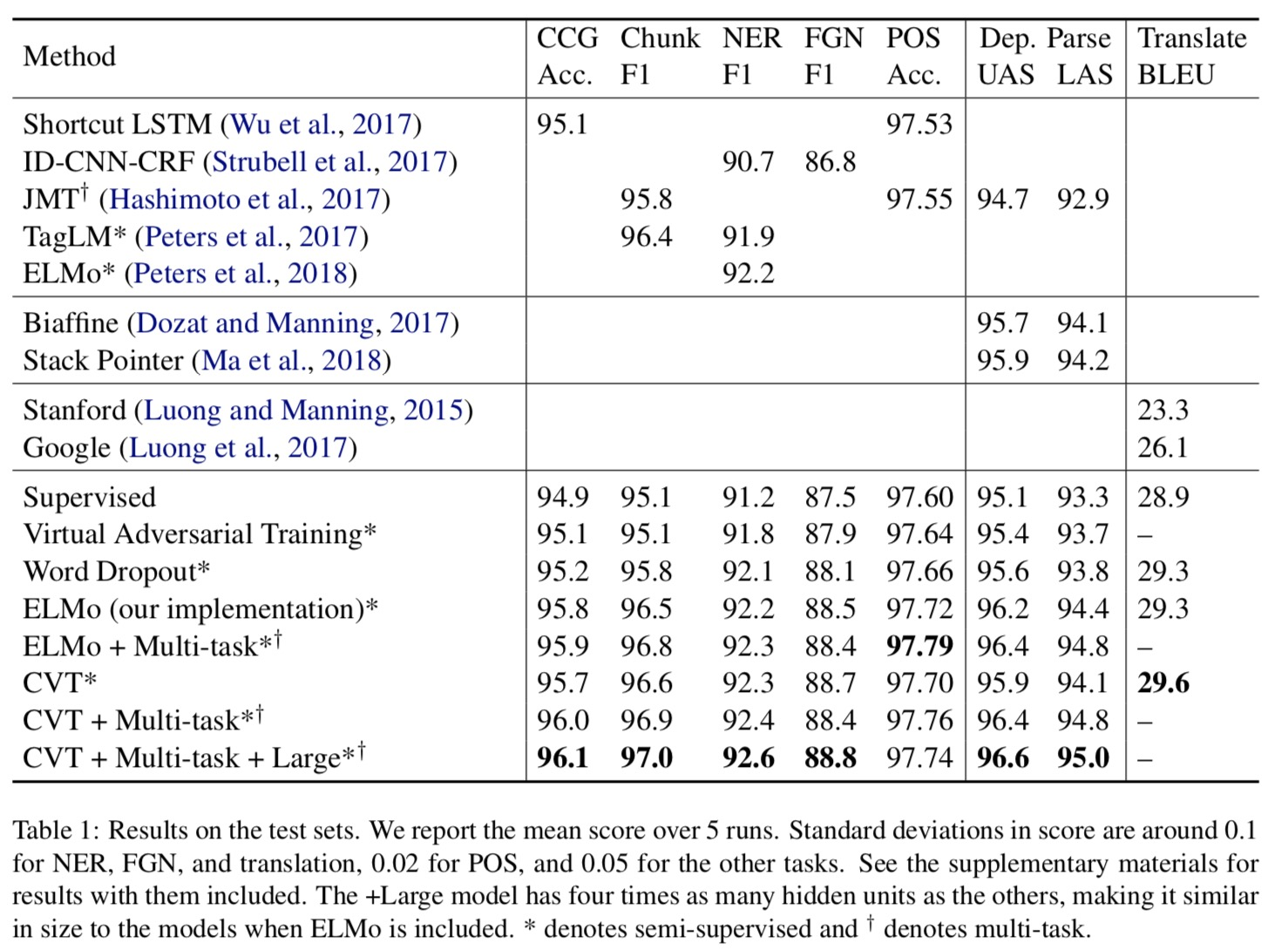
Case study: NER example

Takeways
Semi-supervised learning is an interesting method to address label deficiency in deep learning
About elegance: general to many tasks, succinct mathematical expression
What's more?
Semi-Supervised Sequence Modeling with Cross-View Training
By Jing Liao


