Recommendation System
2013.10.01(tue)
Jongho Kim
python korea study
Tip! - Python
list comprehension
[expression for variable in list]
or
[expression for variable in list if condition]
>> list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
>> print [v * 10 for v in list if v > 4 ]
[50, 60, 70, 80, 90] Recommendation is Important!
Netflix : 대여되는 영화의 2/3이 추천
Google News : 38%이상의 조회가 추천으로 발생
Amazon : 판매의 35%가 추천으로 발생
Collaborative filtering
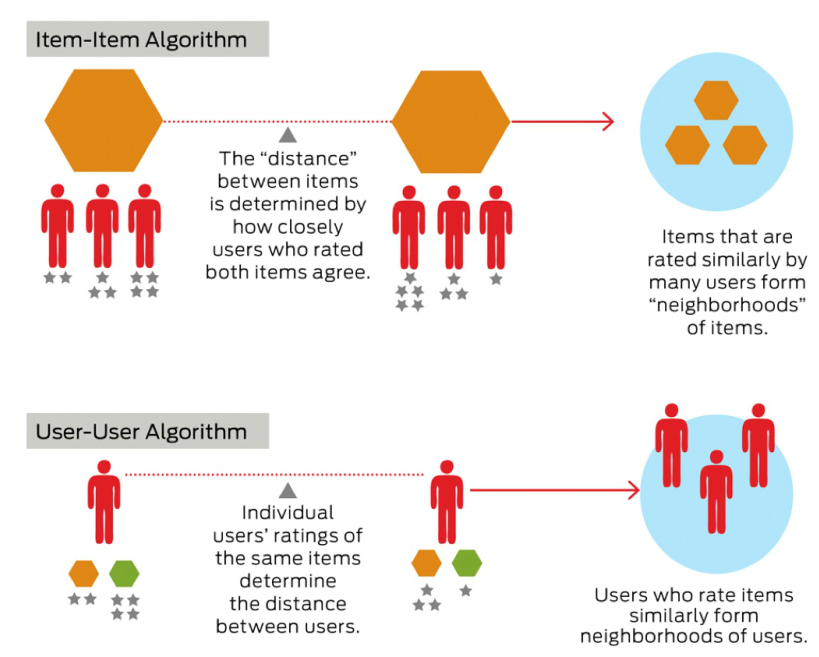
[출처 :Deconstructing Recommender Systems by JOSEPH A. KONSTAN, JOHN RIEDL / OCTOBER 2012]
Data set - 1~5 rating of items from "집단지성프로그래밍"책

Similarity Score = "distance"
- Euclidean distance score
- Pearson correlation score
- Jaccard coefficient
- Manhattan distance
- Cosine similarity
-
etc....

Euclidean distance score


Pearson correlation score


Euclidean vs Pearson (사진 : "집단지성프로그래밍" p.34 [그림 2-3])

Lisa Rose : 평점을 대체로 3점 대에서 준다.
Jack Matthews : 평점을 1-5까지 골고루 준다.
경향성이 비슷하다 !
Euclidean : 0.340542 vs Pearson : 0.747018 #어떤 유사도 측정 방법을 쓰느냐가 중요하다! 나와 비슷한 평론가 찾기

similarity 인자에 원하는 유사도 측정 방식을 선택
나와 비슷한 평론가를 찾는 것도 좋지만
내가 좋아할만한 영화를 찾고 싶다!
영화 추천(1) (사진:"집단지성프로그래밍" p.37 [표 2-2])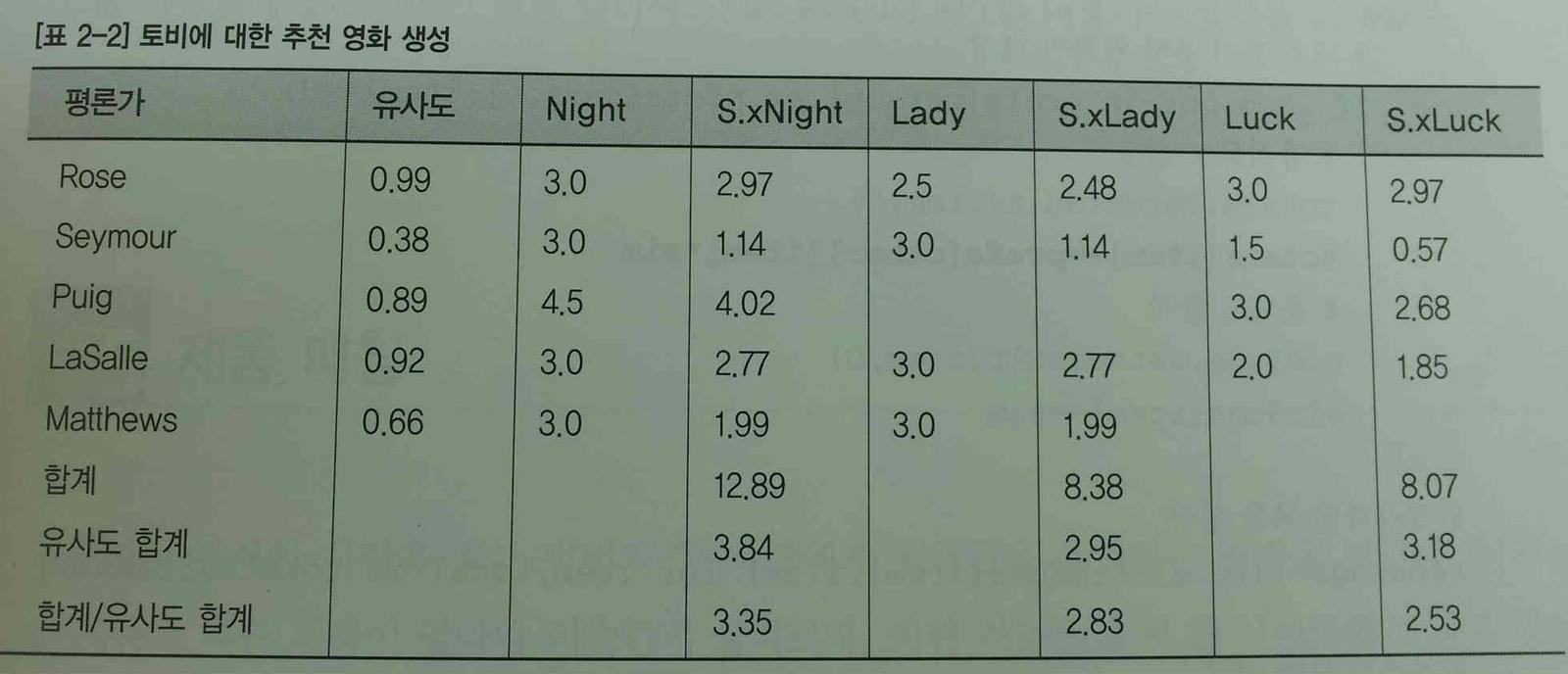
유사도 = sim_pearson()의 결과
S.xNight = Night * 유사도
유사도 합계 = 영화 평가가 겹치는 평론가들의 유사도 합
합계/유사도 합계 = "나의 예상 평점"
영화 추천(2)

user-based collarborative filtering - 단점
- Spare matrix : 두 사용자가 공통된 영화를 평가한 데이터는 드물다.
- Long time : 수천만의 사용자가 있으면 모든 사용자를 비교하고 제품들과 모두 비교를 해야되므로 느리다.
- Frequency Change : 사용자 데이터가 빈번히 바뀌므로 유사도 값을 계속 다시 측정해야 한다.

We need the item-based collaborative filtering!!
item-based collaborative filtering - 데이터 구조 변형
Dataset을 그대로 쓰기 위해 matrix 구조를 바꾸자
# 변경 전
{'Lisa Rose' : {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5},
'Gene Seymour': {'Lady in the Water': 3.0, Snakes on a Plane': 3.5}}
#변경 후
{'Lady in the Water': {'Lisa Rose': 2.5, 'Gene Seymour': 3.0},
'Snakes on a Plane': {'Lisa Rose': 3.5, 'Gene Seymour': 3.5}} item-based collaborative filtering - 유사도 계산
항목 간의 유사도 구하기!
기존에 사용했던 함수들을 그대로 사용한다.

item-based collaborative filtering - 영화추천(1)

(사진: "집단지성프로그래밍" p.47 [표 2-3])
평론가가 포함되어 있지 않다.
"내가 평가한 영화"와 "내가 평가하지 않은 영화"간의 비교
item-based collaborative filtering - 영화추천(2)

item-based collaborative filtering - 영화추천(3)
항목간의 유사도 매트릭스(itemMatch)를 인자로 받는다.
추천을 해줄 때 마다 새로 유사도 값을 계산할 필요 없다.
속도의 향상
참고하면 좋은 자료들
- 슬라이드 예제 코드
(https://gist.github.com/jonghokim/6774482)
- MapReduce 기반 대용량 추천 알고리즘 - SKplanet블로그
(http://readme.skplanet.com/?p=2509)
- 추천 시스템 분석 - KTH블로그
(https://github.com/muricoca/crab)
- 파이썬 추천 엔진 - 오픈소스
(https://github.com/muricoca/crab)
Recommendation System
By JongHo Kim
Recommendation System
python korea study. topic : recommendation System



