" Data for all and
all for Data "
Seminario de Big Data
IDE-CESEM
Diciembre 2016
Dr. Jose María Alvarez-Rodríguez
Madrid, España
¡Explosión de datos!

... NO todo es social media!
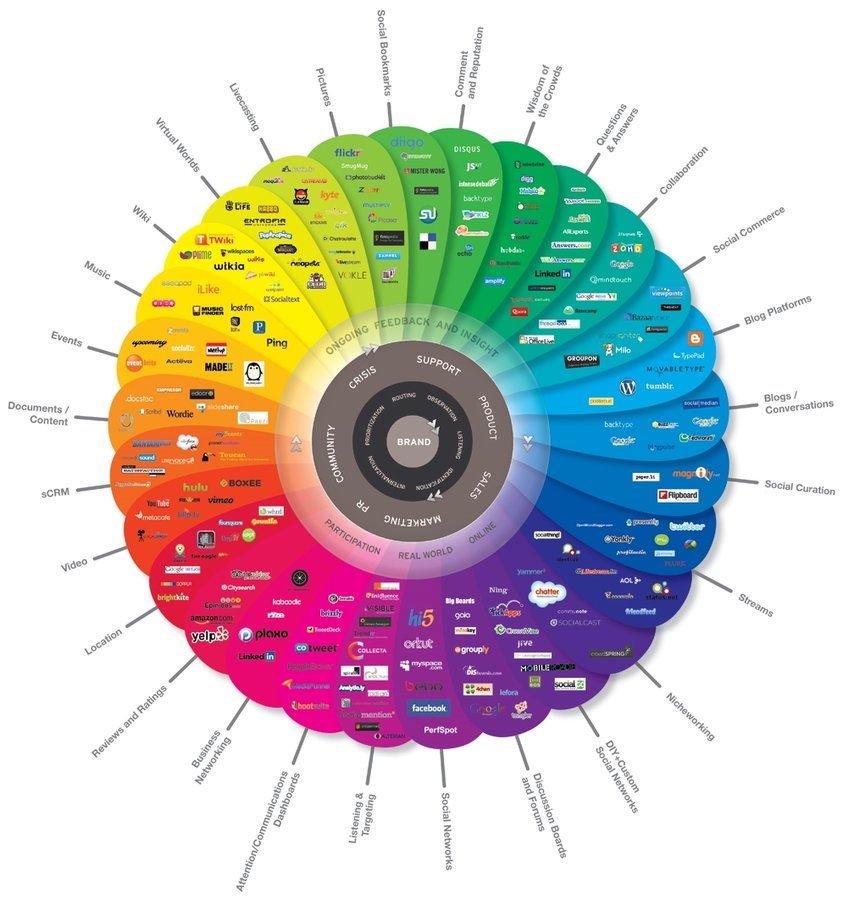
¿En qué era estamos viviendo?
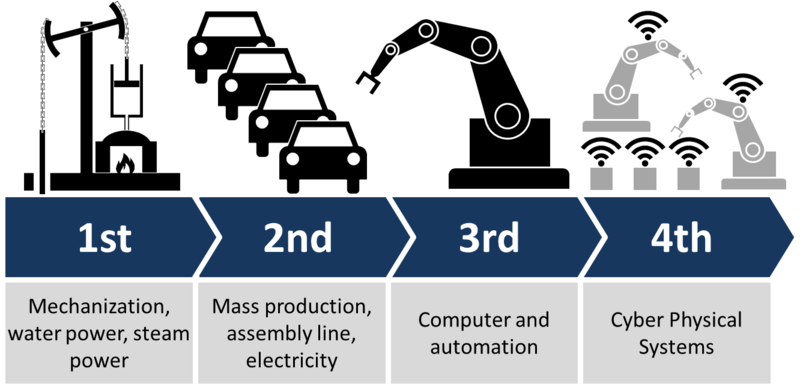
4ª Revolución Industrial
Fuente: https://goo.gl/images/8dsnlW
Transformación Digital
aplicada a la
Industria
Cyber-Physical Systems
Software
"alma" de los sistemas
Datos
"alimento" de los sistemas
Un ejemplo...
- " driven by exponential increases in computing power and by the availability of vast amounts of data "
- "...growing transparency, consumer engagement, and new patterns of consumer behavior (increasingly built upon access to mobile networks and data )..."
- These technology platforms, rendered easy to use by the smartphone, convene people, assets, and data —thus creating entirely new ways of consuming goods and services.
- New technologies make assets more durable and resilient, while data and analytics are transforming how they are maintained . A world of customer experiences, data-based services, and asset performance through analytics,
- ...
The 4th Industrial Revolution
...algunas preguntas..
¿La compañía de taxis más grande?
¿La gran tienda del mundo?
¿La cadena de hoteles con más habitaciones?
¿La universidad más grande?
¿El medio de noticias con más información?


...y la industria del automóvil?
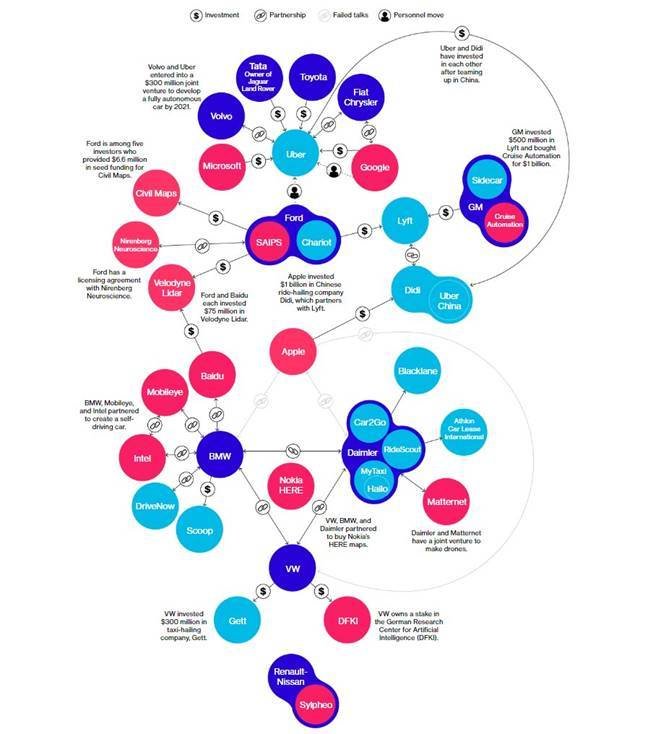
- Renault/Nissan
- Fiat/Chrysler
- Volkswagen
- Ford
- Daimler
- BMW
- TATA
- GM
- Toyota
- Volvo
- …
-
Intel
-
Microsoft
-
Google
-
Apple
-
Uber
-
Baidu
-
Nokia
-
…
This graphic originally published June 28, 2016. It has since been updated with additional reporting. SOURCE: Data compiled by Bloomberg
ADDITIONAL WORK: John Lippert, Keith Naughton and Cedric Sam
Software
"alma" de los sistemas
Datos
"alimento" de los sistemas

¿Seguro?
Según Forbes (2012)...
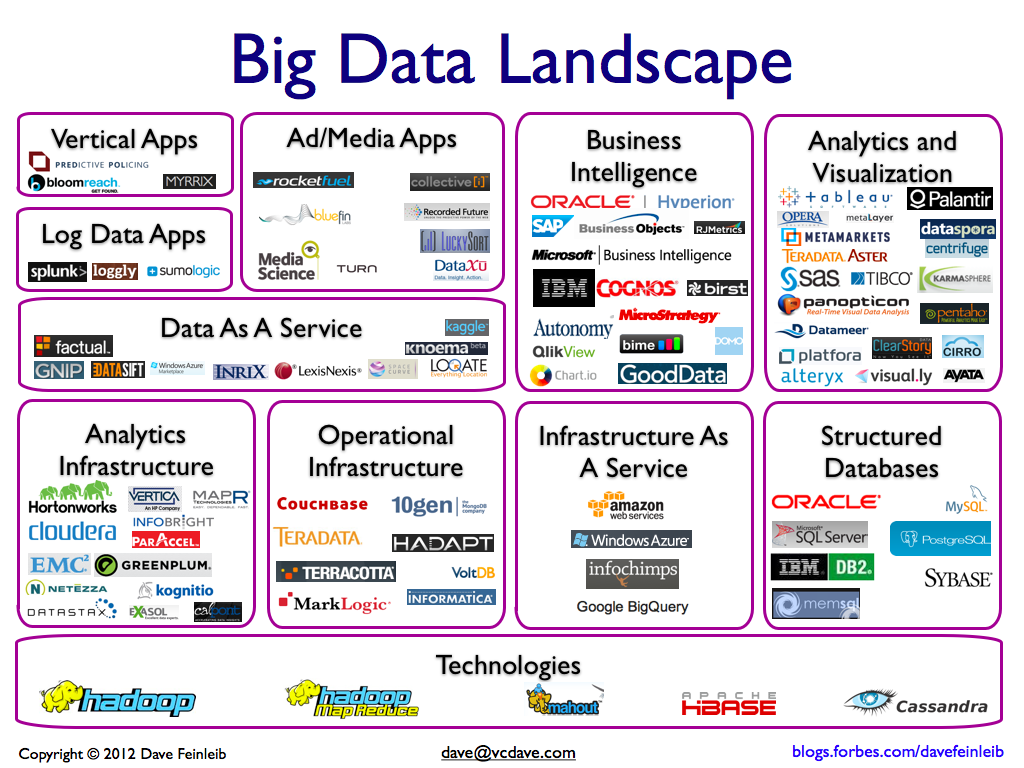
Según UX-Sears (2012)...
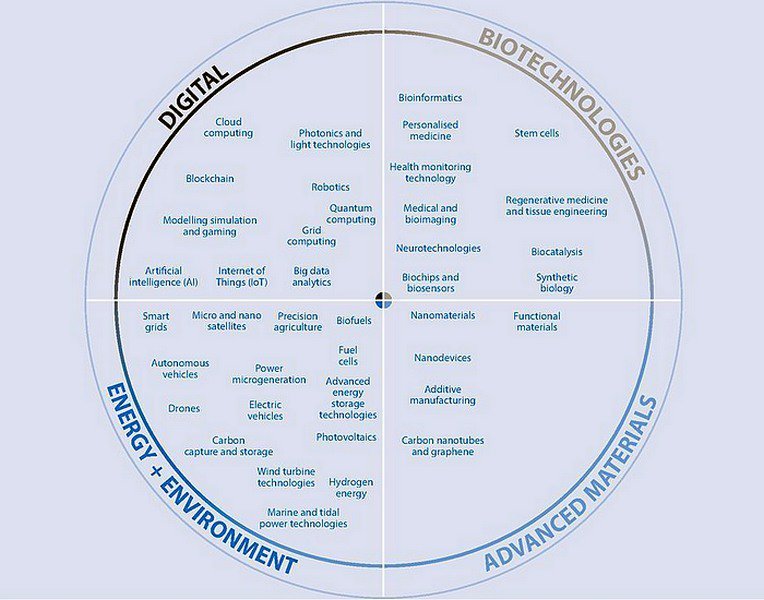
Según Matt Turck (2014)
Según BigDataLandscape...

Según Matt Turck 2016

...Gartner 2015 Hype Cycle...
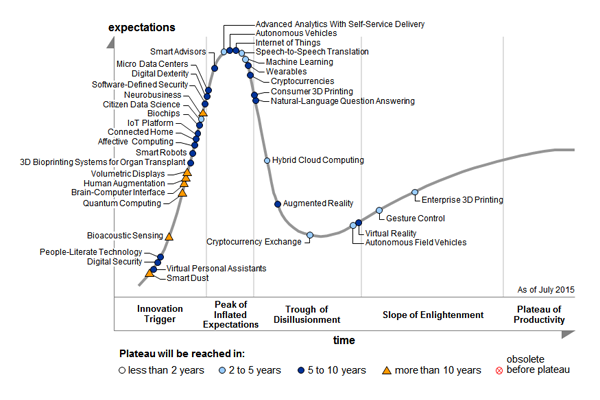
Big Data is out!
...Gartner 2016 Hype Cycle...
Big Data is still out!
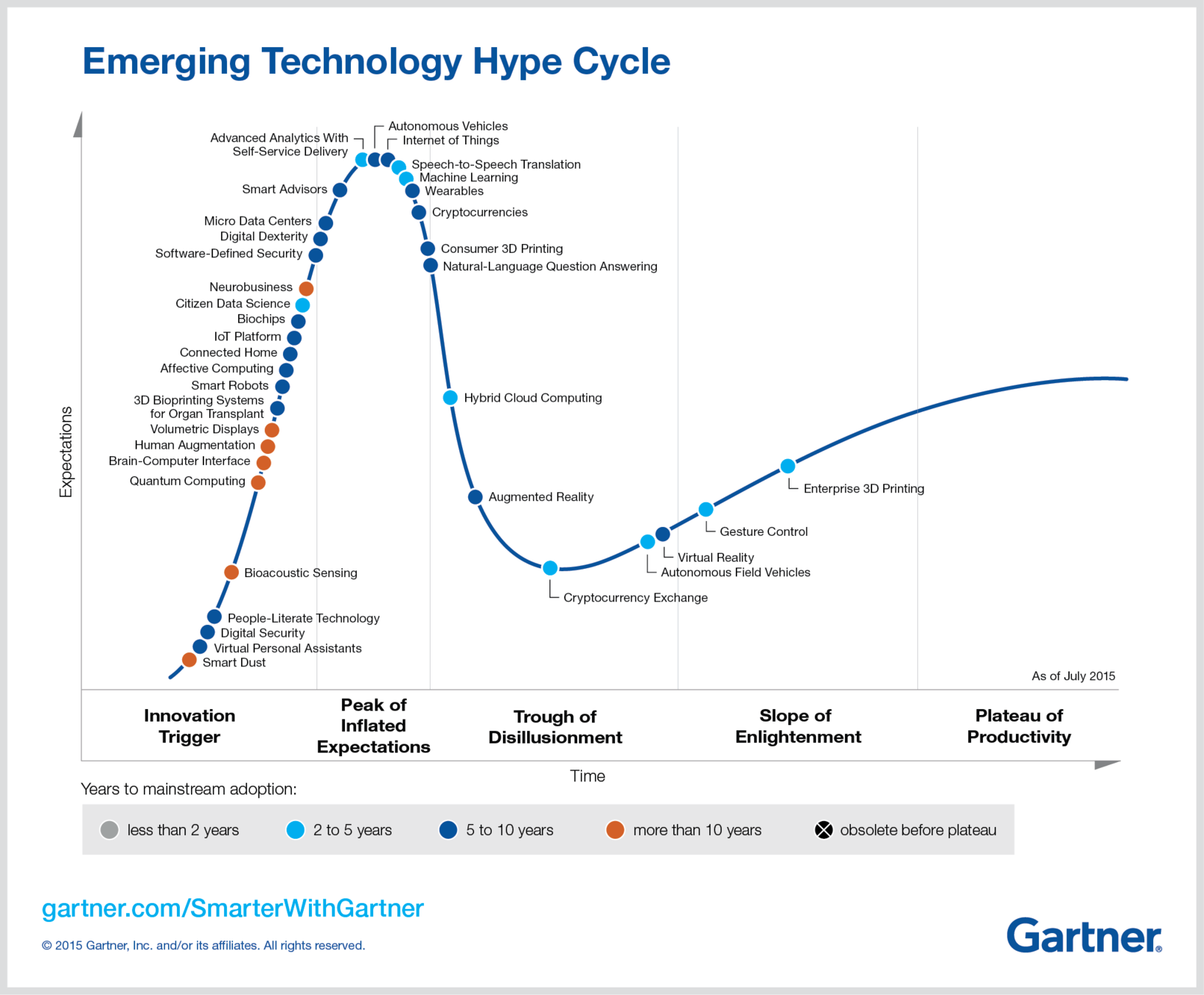

IoT Platform Citizen Data Scientist Machine Learning NLP & Question Answering
...
¡Big Data ya está en uso!
¿Por ejemplo?

Sofisticación de métodos para:
- Proceso de fabricación
- Servicios post-venta
- Engine Health Management
- ¿IoT en el futuro?

- Localización anónima de viajeros
- Predicción de carga de viajeros
- Manejo de situaciones excepcionales

- Predicción de problemas en la red (predictive analytics)










...De la empresa Teradata...
Supply Chain
Supply Chain
Policía
Crímenes
Eficiencia energética
...
Telefónica
TV+Audiencia
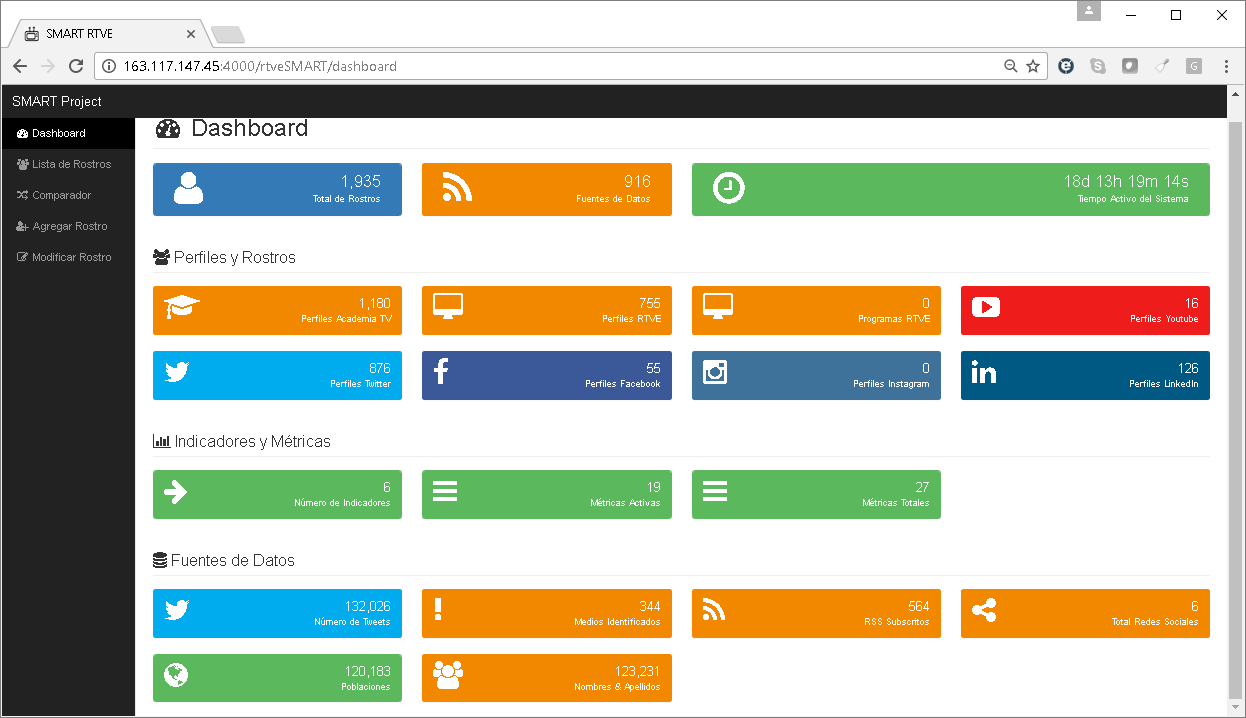
- +29M Observaciones
- +26 Métricas
- +350K relaciones
- 6 redes sociales
- +2000 perfiles
- +130K Tweets...
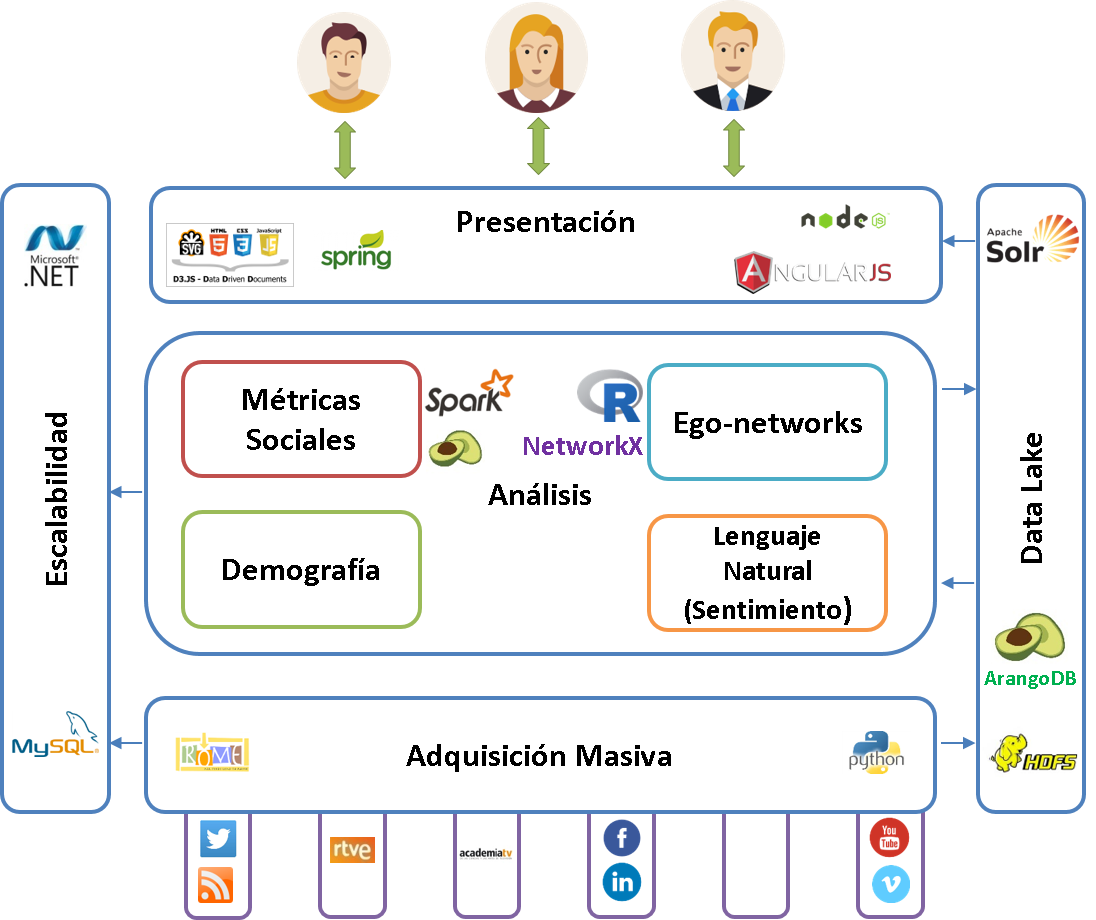
¿Algunas conclusiones iniciales?
Problemas de negocio
Monitorización
Batch vs Tiempo real vs Stream
Eficiencia y mejora
Análisis predictivo
Tecnología
...y en España...
Grandes Empresas
EBTs
Formación
Investigación
Eventos
Sectores













Varios másteres impulsados por empresas
Conceptos Clave
¿Qué es
Big Data?
3v's
vs
8v's
(n+1 v's)
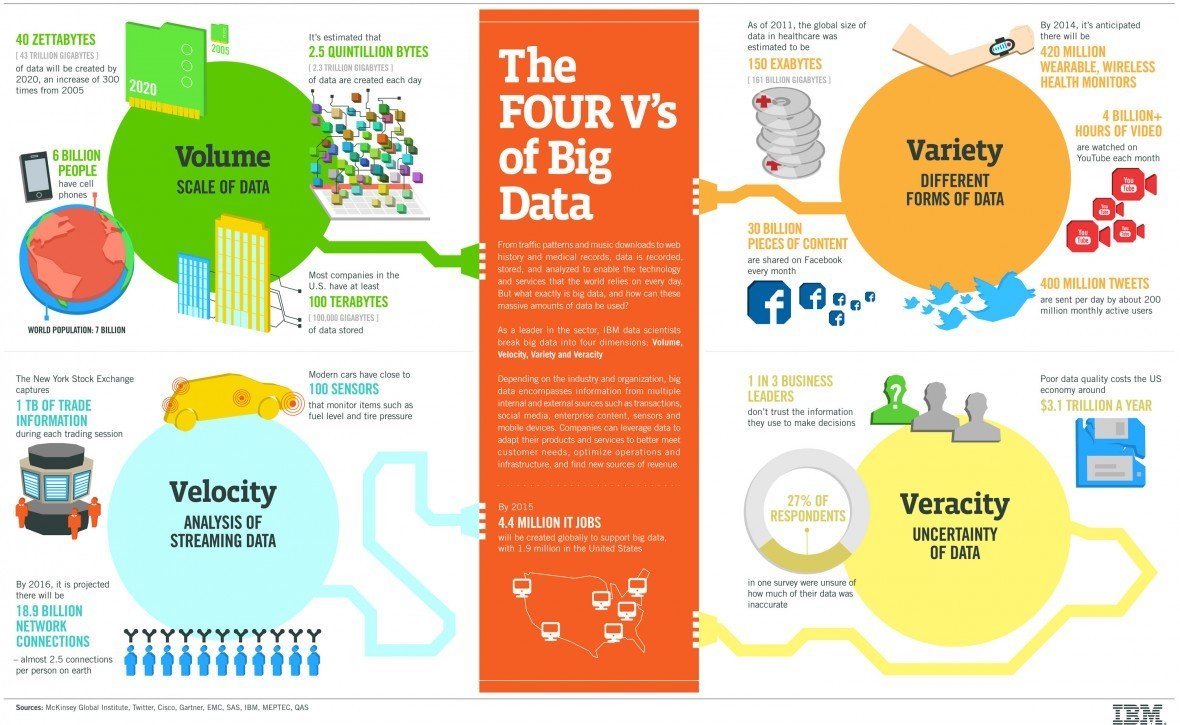
VOLUMEN

VOLUMEN
- Cantidad de datos que se han de procesar
- Crecimiento Continuo
¿Cuál es el tamaño para ser considerado Big Data?
- Al menos 1 TB hasta el orden de PB (en el futuro EB)
- ...pero también dependerá de la calidad
Ejemplo
Otro ejemplo
VARIEDAD

Tipos
- Documentos
- Imágenes
- Vídeos
- Posts en redes sociales
- Datos científicos, geográficos, etc.
Formatos
Estructurado vs
Semi-estructurado
No estructurado
- CSV, TSV, MSExcel
- PNG, JPG, MPEG, etc.
- PDF, HTML, etc.
Acceso
- Ficheros
- Lenguajes de consulta
- Streams
- BBDD
- ...
McKinsey
Tipos de Datos por Sector
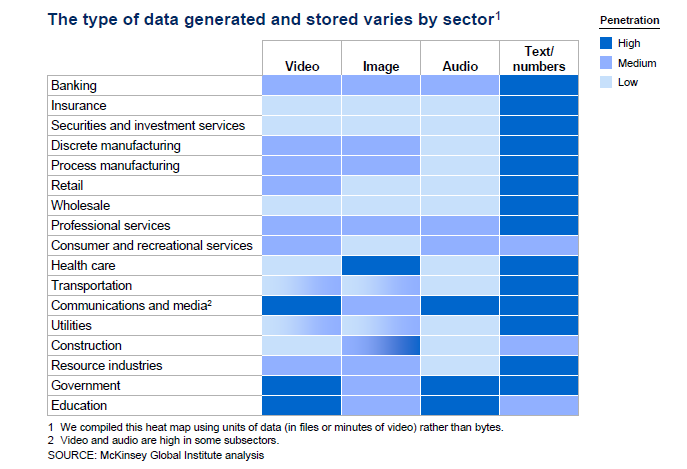
VELOCIDAD

Velocidad
Actualización y tipo de procesamiento
-
Batch -
Periódico -
Eventos -
Cercano a tiempo real -
Tiempo real
Ejemplo
500M de Tweets por día
6000 por segundo de media
VERACIDAD

Veracidad
- Calidad
- Limpieza
- Fuente de datos confiable
- ...
VISCOSIDAD

Viscosidad
- Resistencia a formar parte del flujo de datos
- Capacidad de integración de los datos
- Tipos de procesamiento:
- Stream
- Bus de integración
- Procesamiento de eventos complejos (CEP)
VIRALIDAD

Viralidad
PROPAGACIÓN DE LA INFORMACIÓN
VELOCIDAD Y TIEMPO
VALOR

Valor
Datos estadísticos
Eventos
Hipótesis (estimaciones)
Correlaciones
Variabilidad

Variabilidad
¿Cuán de dinámicos son los datos?
Atomicidad
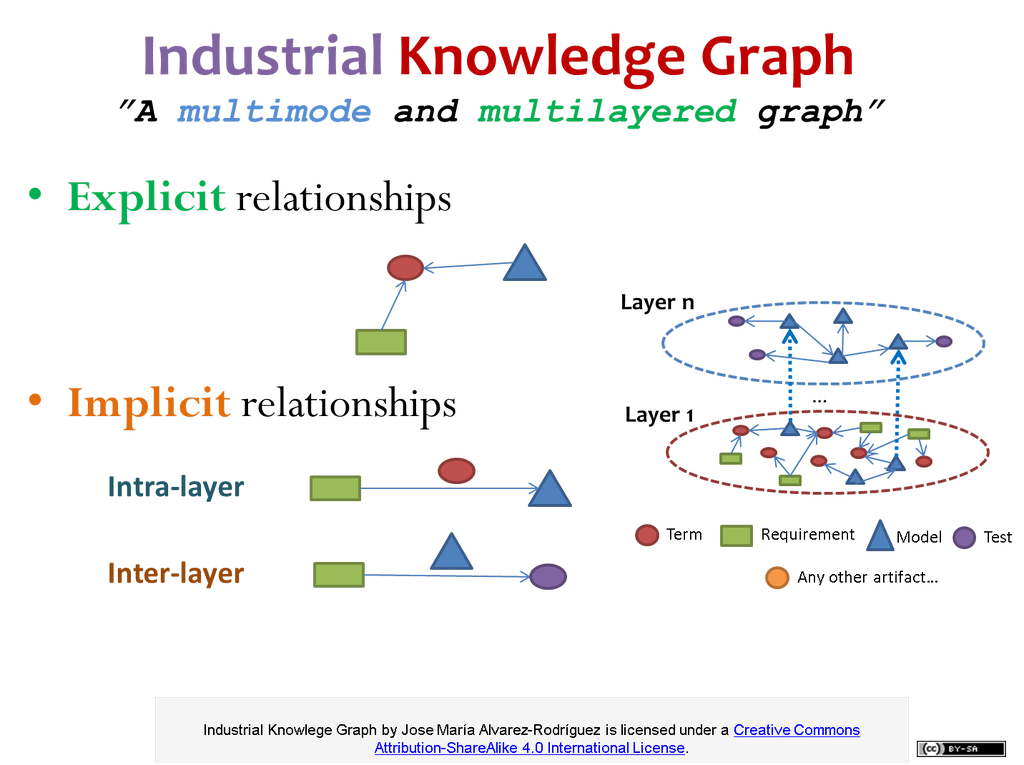
COMPLEJIDAD

COMPLEJIDAD
¿Cómo conectar?
¿Cómo correlar?
¿Capas?
¿Modos?
...
Ejemplo:
Red multimodo y multicapa
(Casi)
Todo en uno...
Big Data es...
- Es lo mismo que resolver problemas "Small Data"
- ...pero el disponer de muchos datos implica...
- Nuevas arquitecturas (distribuidas)
- Necesidades de almacenamiento
- Diferentes tipos de procesamiento
- ...
- para resolver problemas existentes con un mejor/nuevo enfoque
Old wine in new bottles!
Referencia oficial
Big Data Working Group en el NIST
NIST SP 1500-1 -- Volume 1: Definitions
NIST SP 1500-2 -- Volume 2: Taxonomies
(Instituto de Estandarización Americano)
¿Por qué
Big Data?
MEJORA EN LAS CAPACIDADES DE ALMACENAMIENTO
MAYOR CAPACIDAD DE PROCESAMIENTO
DISPONIBILIDAD DE DATOS
...para resolver problemas...
Otro caso de éxito: Walmart
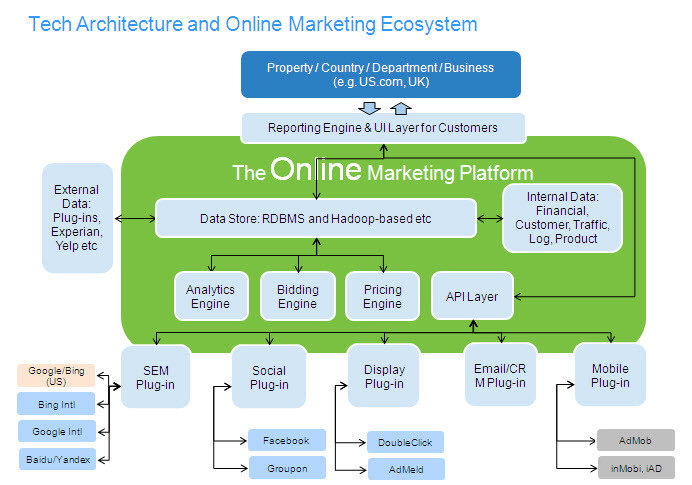
Arquitectura
Necesidades
-
Almacenar grandes cantidades de datos
- Caducidad en el tiempo
- Integrar fuentes de datos
-
(Re) Procesar y consultar en
- Batch
- Tiempo real
- ...para proporcionar servicios de
- Toma de decisiones
- Informes, etc.
- ....y con capacidades de...
- Escalabilidad
- Tolerancia a fallos
- Replicación
¿Alguna idea?
¿Una BBDD relacional tradicional?
¿Un sistema de procesamiento off-line?
¿Un sistema de Inteligencia de Negocio?
¿OLAP y variantes?
...
Sistemas NoSQL
- Key /Value (Tablas)
- Documentos
- Grafos
Database Landscape

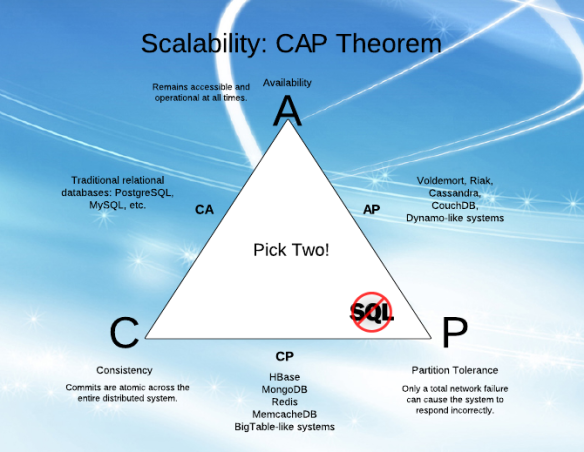
Teorema CAP
"Es imposible para un sistema de computación distribuida garantizar al mismo tiempo":
- Consistencia (Consistency)
- Disponibilidad (Availability)
- Tolerancia a fallos (Partition tolerance)
Ejemplos
AP: Cassandra y CouchDB
CP: HBase y PAXOS
CA: BBDD relacionales
CAP y Big data
Superando el teorema CAP
Las propiedades ACID de las bases de datos relacionales no encajan demasiado bien con las necesidades de un sistema Big Data (almacenar y procesar en ~tiempo real).
¿Factores Clave?
¿Arquitecturas?
¿Patrones?
Clasificación de IBM
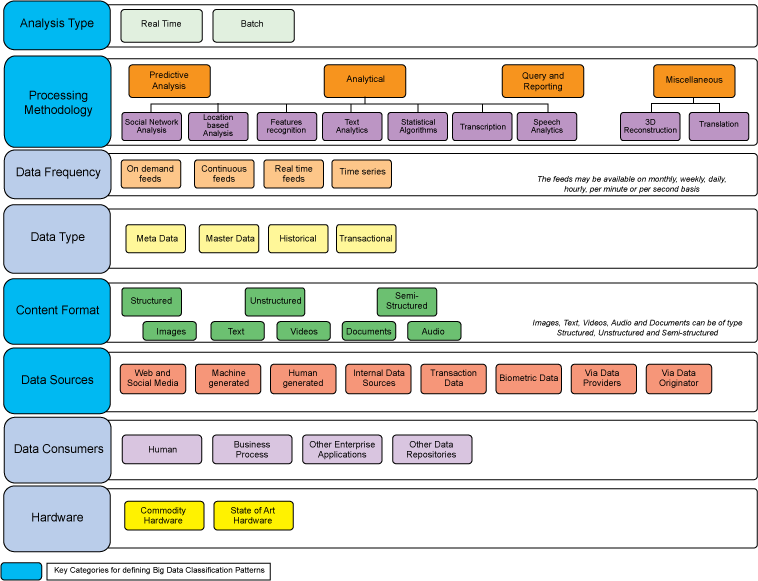
Diferentes Arquitecturas
-
Lambda -
Kappa -
Zetta -
IoT-a -
Polyglot Processing
...dependiendo de las necesidades...
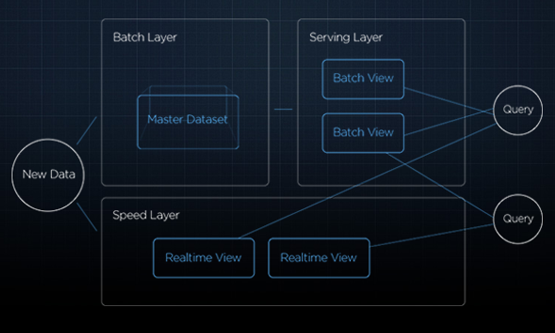
Arquitectura Lambda
Nathan Marz
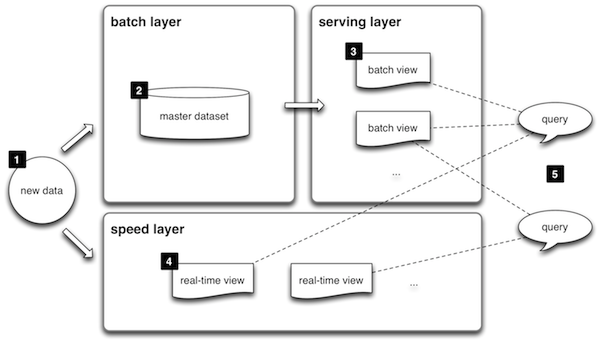
BATCH Layer
Procesamiento off-line
Todos los datos
Almacenamiento distribuido
Alta latencia
Implementación
Basado en Apache Hadoop
Cloudera Impala
...
SERVING Layer
Indexar y exponer los datos de las distintas vistas
Consultas en tiempo real
Baja-latencia
Implementación
Flink, Spark, Storm, Impala Cloudera, Dremel (Apache Drill), Hortonworks, etc.
Lenguaje de consulta sobre los datos: Pig, SploutSQL, etc.
SPEED Layer
Compensar la latencia de Batch layer (hasta que procese los datos y se pueden eliminar de esta vista)
Procesamiento de streams
Tolerancia a fallos
Diseño modular
Computación continua y distribuida
Implementación
Storm y similares
Ejemplo arquitectura Lambda
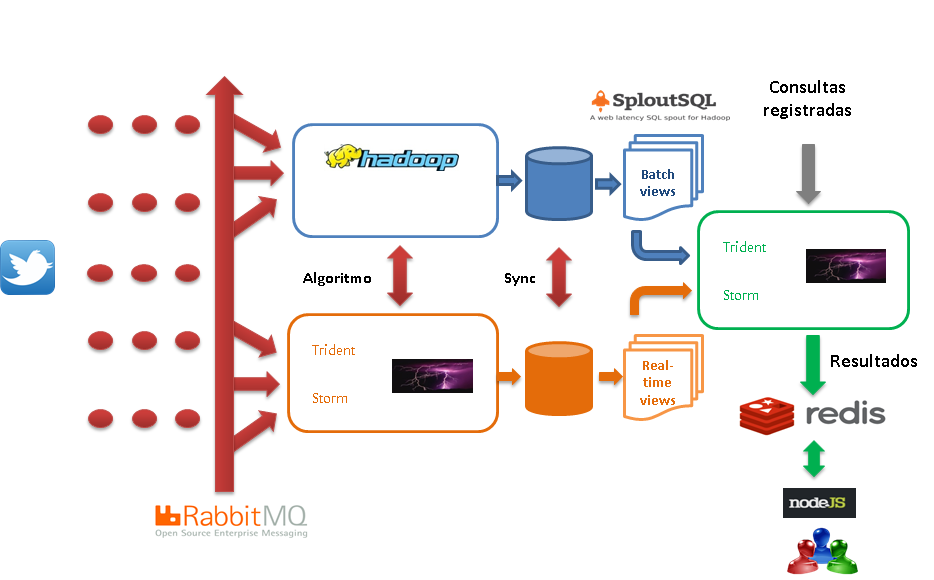
Arquitectura Kappa
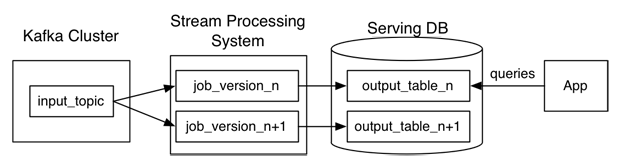
Arquitectura Zetta
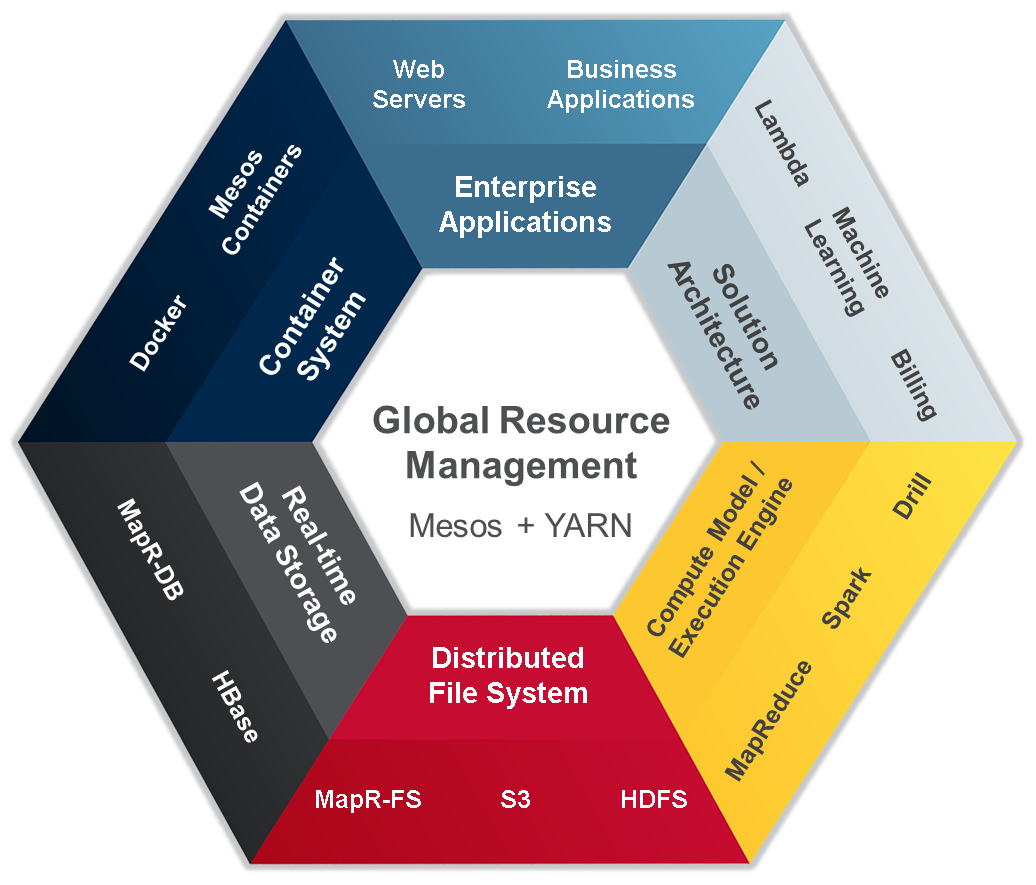
Arquitectura Zetta en Google
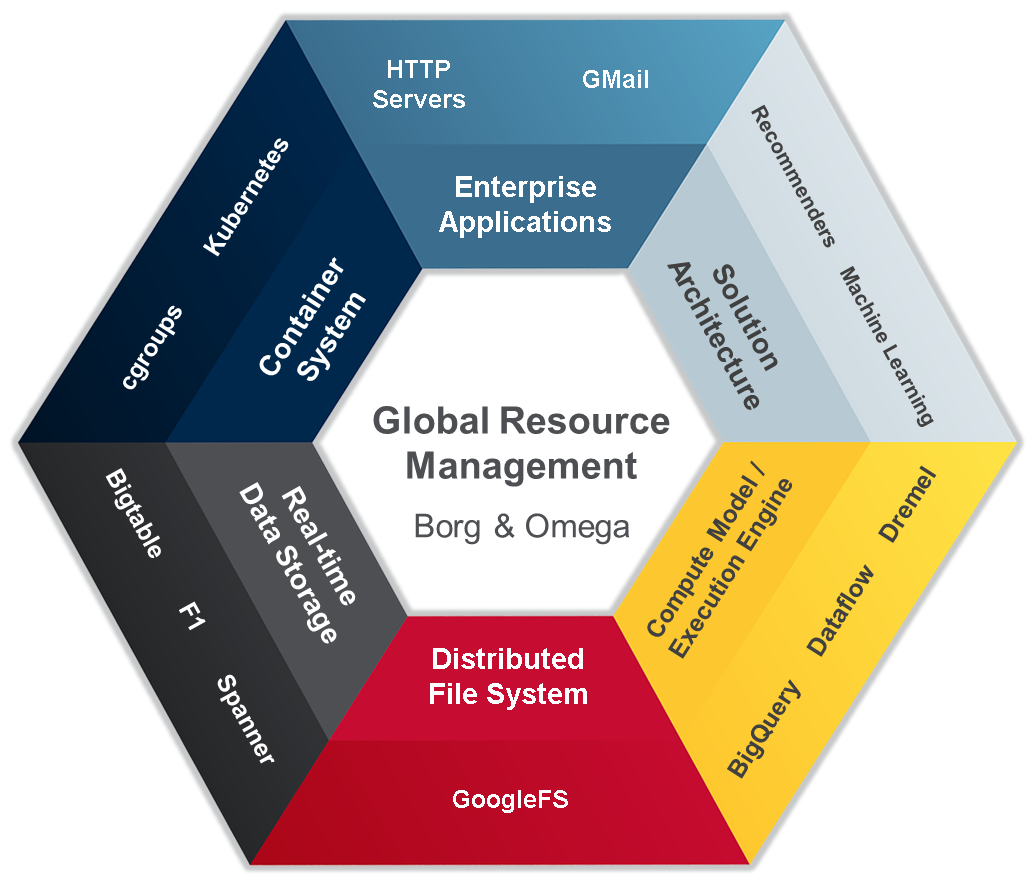
Arquitectura IoT-A
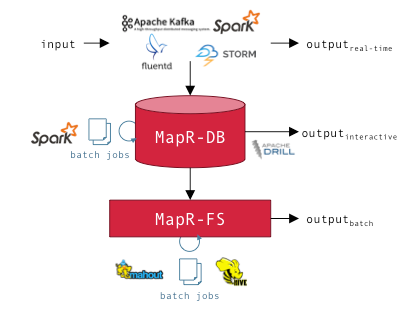
Arquitectura Polyglot Processing
Referencia oficial del NIST
| NIST Big Data Reference Architecture Subgroup |
| 5. NIST SP 1500-5 -- Volume 5: Architectures White Paper Survey |
| 6. NIST SP 1500-6 -- Volume 6: Reference Architecture |
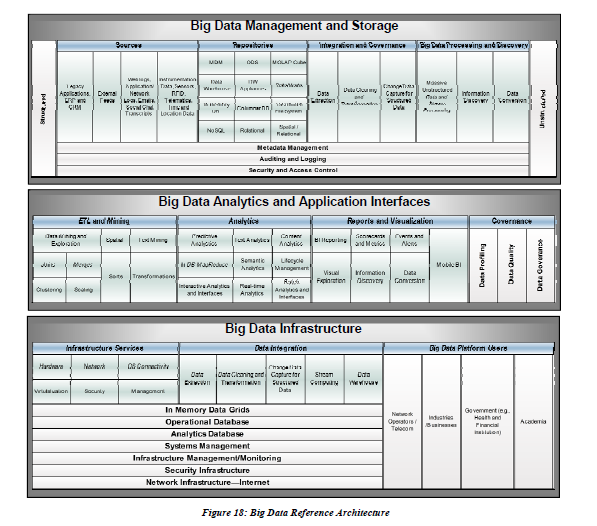
¿Big Data Management Platforms?
¿Revisamos arquitecturas de redes sociales ?
¿Facebook sólo "compró" a los usuarios?
Text
- 450 millones de usuarios
- 32 ingenieros (1 ingeniero para cada 14 millones de usuarios)
- 50 billones de mensajes al día
- 1+ millón de usuarios activos al día
- > 8000 nodos
- > 70 M mensajes en Erlang
- El 31 de diciembre de 2011-> 18 billones de mensajes
Infraestructura
-
Backend
- Erlang
- FreeBSD
- Yaws, lighttpd
- PHP
- Personalización BEAM (VM de Erlang) (BEAM is like Java’s JVM, but for Erlang)
- Personalización de XMPP
-
Hardware
- SDual Westmere Hex-core (24 logical CPUs);
- 100GB RAM, SSD;
- Dual NIC (public user-facing network, private back-end/distribution);
Lecciones Aprendidas
-
Erlang Rocks!
-
Mantener el d iseño simple y evolucionar (personalizar)
-
Mantener el servidor con carga baja
-
...
- + 150 M de usuarios activos
- ...
-
+500 M de tweets por día
- ¿Cuánto cuesta entregar un tweet de Lady Gaga ( +31 millones de seguidores)?-> 5 mins
- http://www.infoq.com/presentations/Real-Time-Delivery-Twitter
- http://highscalability.com/blog/2013/7/8/the-architecture-twitter-uses-to-deal-with-150m-active-users.html
- http://highscalability.com/blog/2009/10/13/why-are-facebook-digg-and-twitter-so-hard-to-scale.html
- http://www.infoq.com/presentations/Real-Time-Delivery-Twitter
- http://www.slideshare.net/caniszczyk/twitter-opensourcestacklinuxcon2013
- https://engineering.twitter.com/research/publication/fast-data-in-the-era-of-big-data-twitters-real-time-related-query-suggestion-0
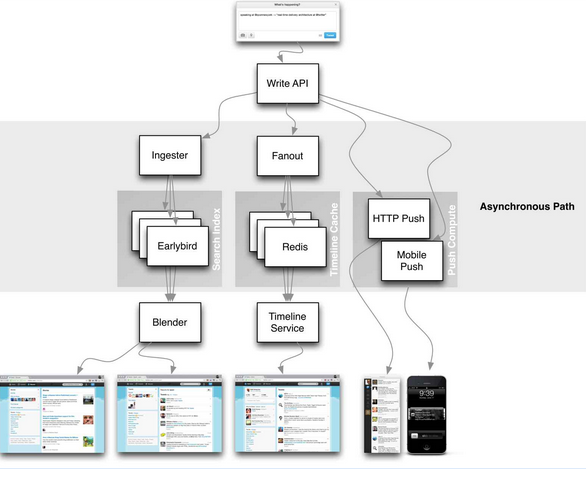
Twitter (2008)
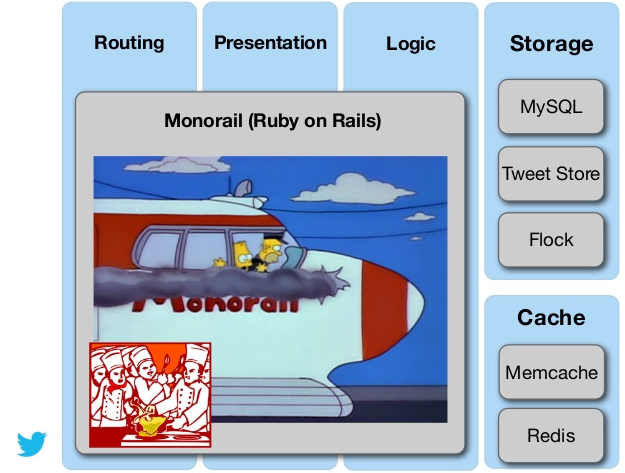
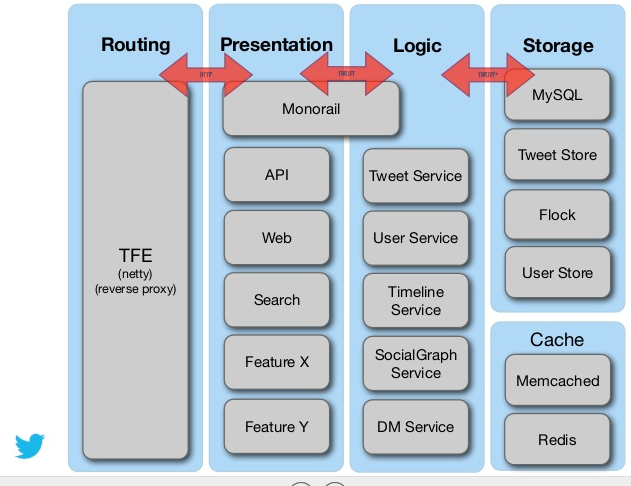
Twitter (¿actual?)
Arquitectura Lambda
Linkedin (2003-2005)
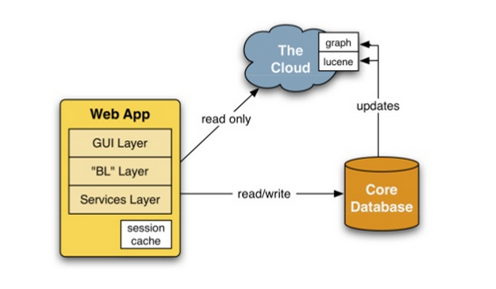
Text
Linkedin (2006)
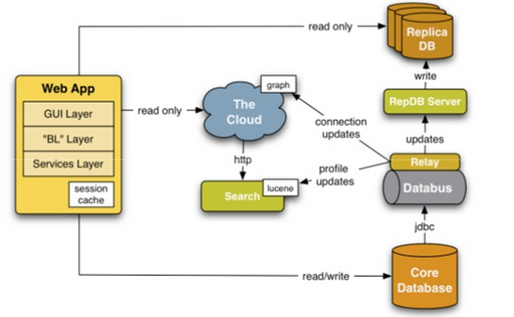
Linkedin (2008)
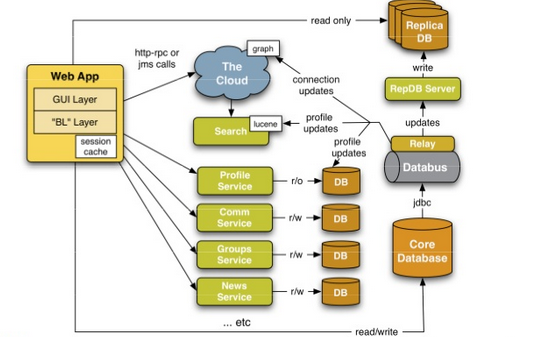
Recursos interesantes
Caso de Estudio I
Análisis del grafo social y eventos (extracción de estadísticas)
Caso de Estudio II
Sistema de Recomendación en tiempo real
¿Qué hay que hacer?
- Explicar y debatir una arquitectura para estos casos de estudio
- Criterios de selección de tecnología
- Tipo de procesamiento
- Almacenamiento de datos
- Latencia
- Actualización de los datos
- Caducidad
- Re-procesamiento
- Cambios en el código de los algoritmos
- Otros QoS: SMI framework
- ...
- Inspirarse en algún ejemplo real presente en redes sociales, etc.
Tecnología
Map/Reduce (M/R)
Un modelo de programación...
- Procesamiento de datos a gran escala y distribuido
- Simple pero restringido
- Programación paralela
- Extensible
- ...
Antecedentes
Programación Funcional
- Inspirado pero no equivalente
Ejemplo en Python
"Dada una lista de números entre 1 y 50 mostrar sólo los pares"
print filter(lambda x: x % 2 == 0, range(1, 50)) - Datos (una lista de números)
- Condición (ser par)
- Función de filtro
- ...
Otro ejemplo...
"Calcular la suma de los cuadrados de los números entre 1 y 50"
import operator
reduce(operator.add, map((lambda x: x **2), range(1,50)) , 0)- reduce es equivalente a foldl en otros lenguajes como Haskell
- se deben considerar otros aspectos matemáticos (tipo de operador)
Modelo Básico de M/R
MapReduce: The Programming Model and Practice,
SIGMETRICS, Tutorials 2009, Google.
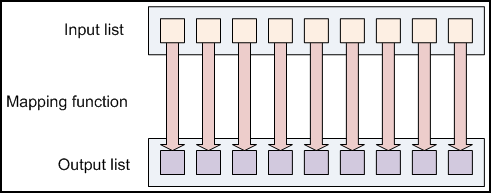
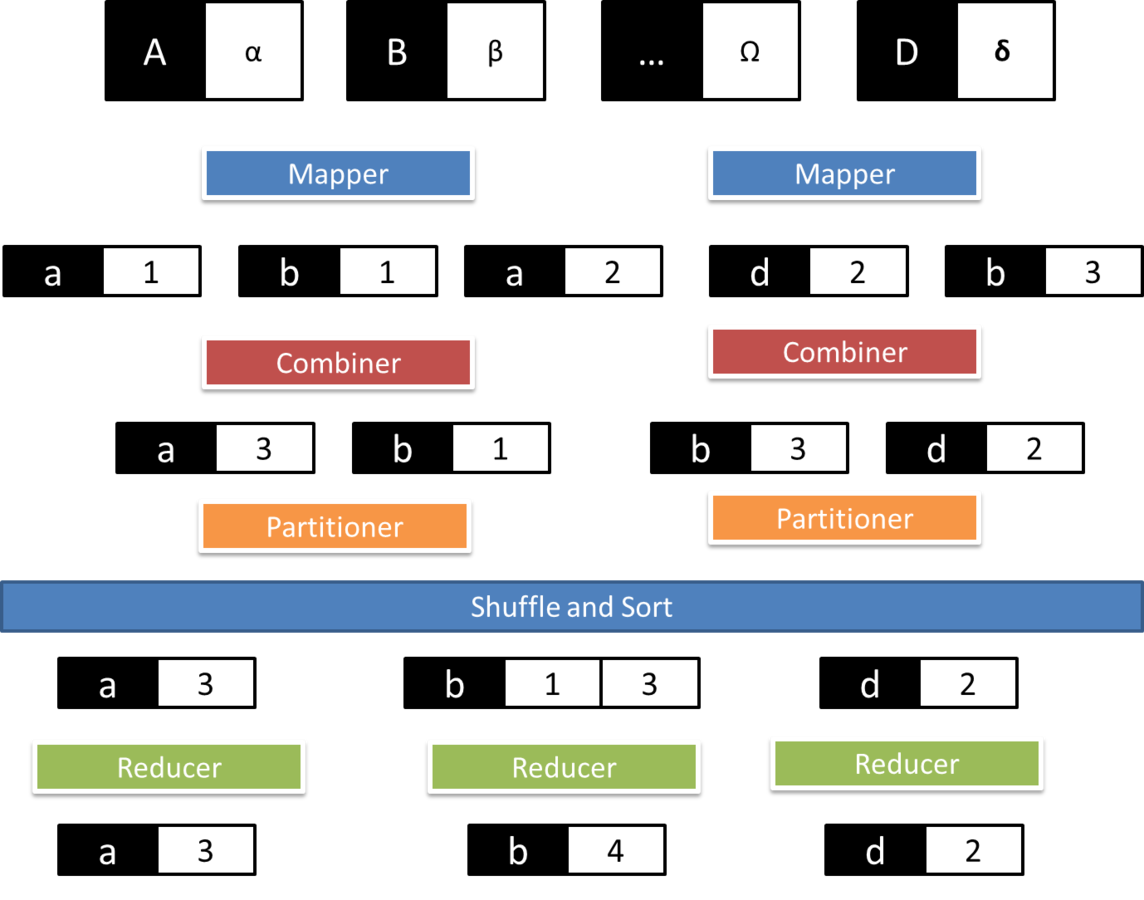
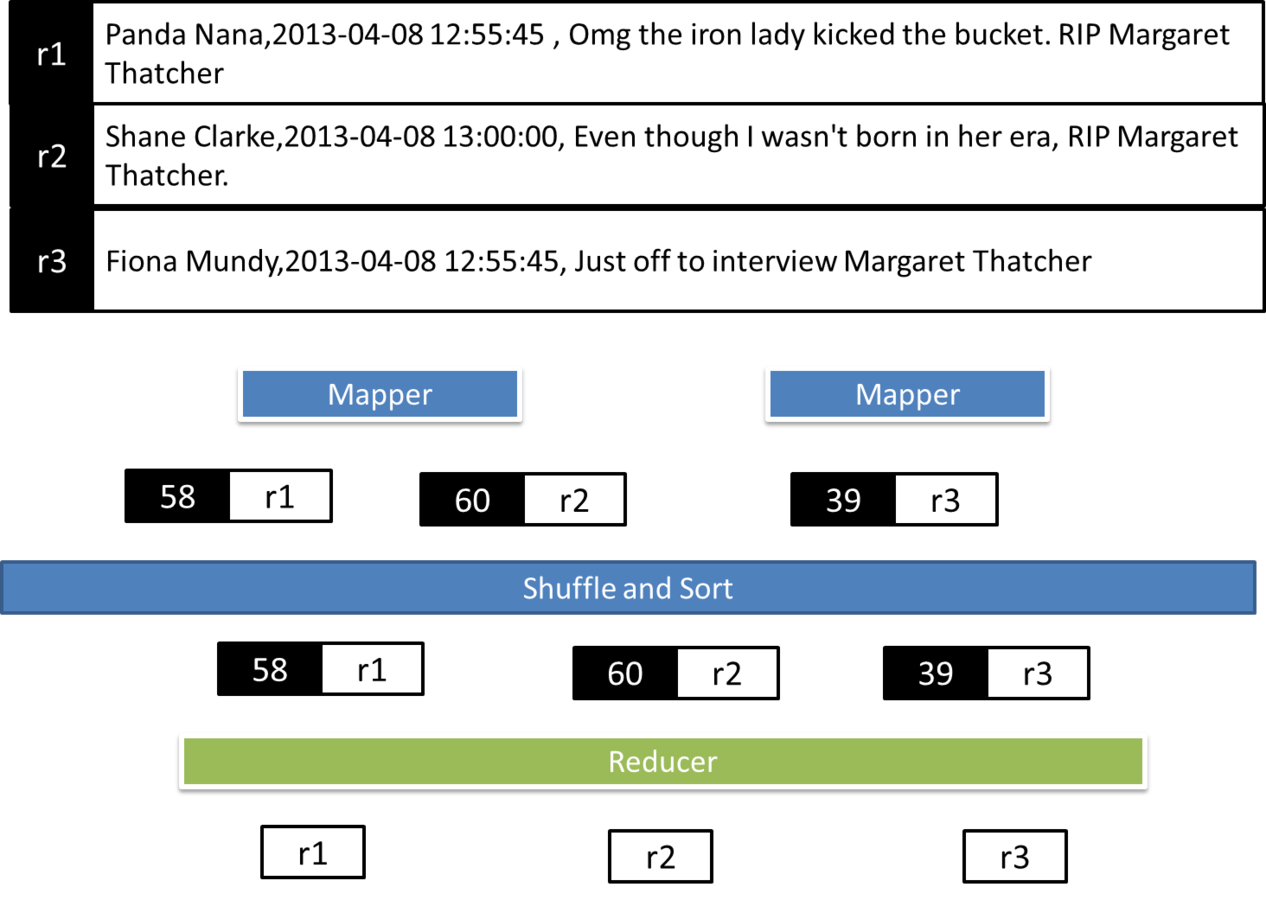
Mapping en M/R
Mapping es una función que crea una lista de salida tras la aplicación de un función a cada elemento de la lista de entrada.
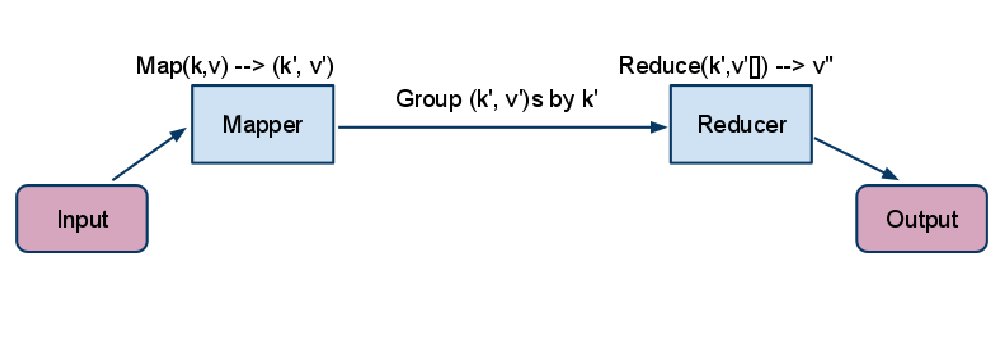
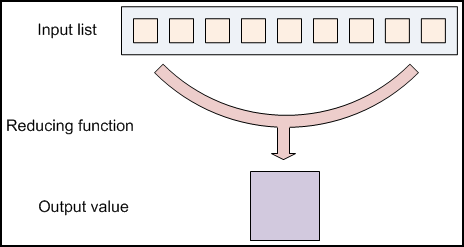
Reduce en M/R
Reduce es una función que itera sobre los elementos de entrada para agregarlos en un sólo valor.
¿Qué es M/R?
Es un modelo de programación inspirado en programación funcional para resolver problemas mediante un enfoque "divide y vencerás" con procesamiento distribuido y paralelo.
¿Cuándo utilizar M/R?
- Indexado y búsqueda (índices inversos)
- Filtrado
- Clasificación
- Recomendación (clustering o filtrado colaborativo)
- Resumen y estadística
- Ordenación y "merging"
- Distribución de frecuencia
- Consultas tipo SQL (group-by, having, etc.)
- Procesamiento y generación de gráficos (histogramas)
- Algoritmos tipo : Búsqueda en anchura o PageRank,
Consulta
Análisis
Otros
¿Cómo lo utiliza Google?
- Indexado y búsqueda a escala web (pre-caché de consultas y resultados)
- Clustering para recomendación en Google News
- Informes para Google Trends
- Procesamiento de imágenes de satélites
- Machine translation
- Aprendizaje automático
- ...
Comparación M/R y otros enfoques
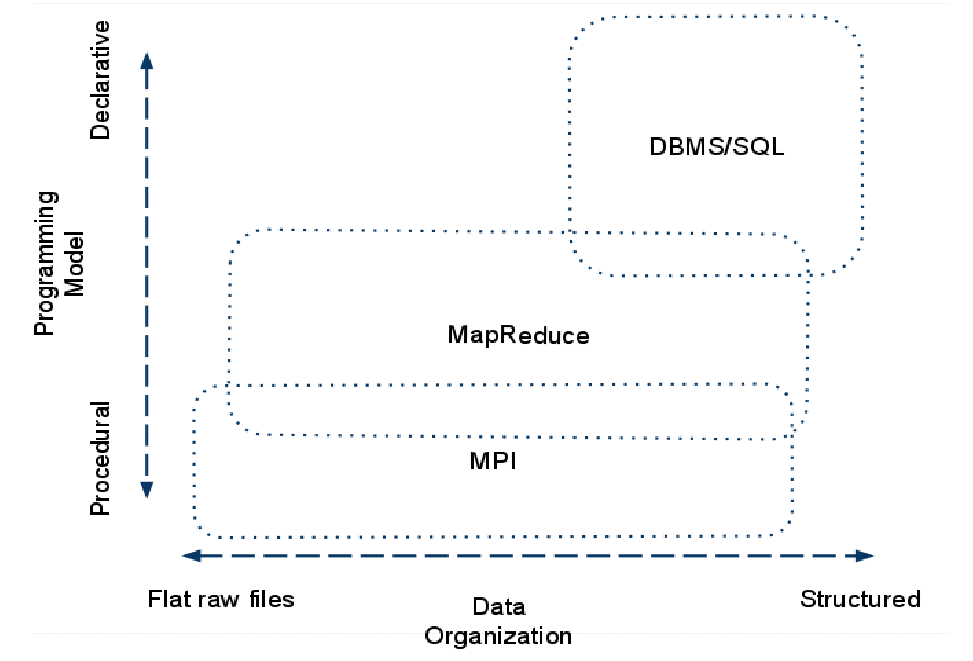
MapReduce: The Programming Model and Practice, SIGMETRICS, Turorials 2009, Google.
Evaluación y características M/R
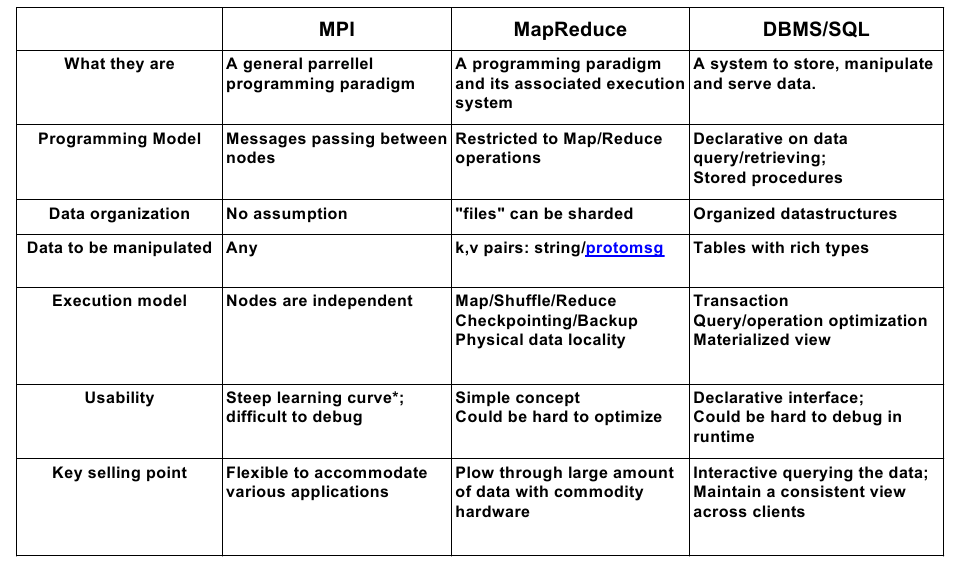
MapReduce: The Programming Model and Practice, SIGMETRICS, Turorials 2009, Google.
Apache Hadoop

The Apache Hadoop software library is a framework that allows for the
distributed processing of large data sets across clusters of computers
using simple programming models.
Hadoop Ecosystem
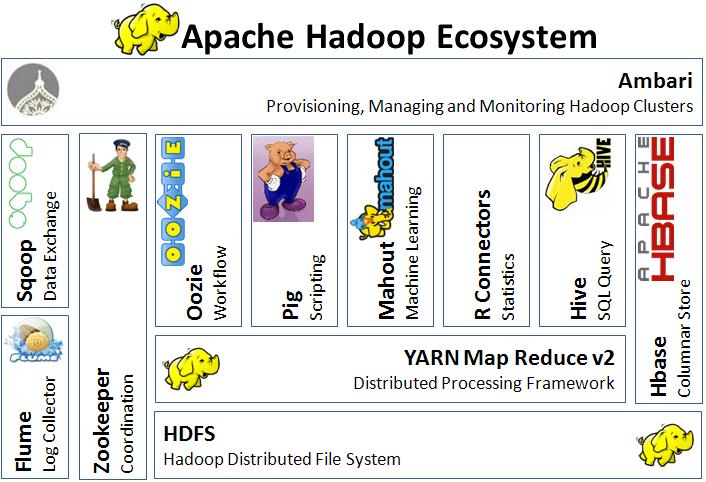
Otro listado: https://hadoopecosystemtable.github.io/
M/R Ejemplos
Apache Hadoop
Resumen M/R

Escenarios
- Resumen e informes agregados
- Filtros
- Organización de datos (sort, merging, etc.)
- Operadores relacionales (join, select, proyección, etc.)
- Paso de mensajes iterativos (procesamiento de grafos)
- Otros (según la implementación):
- Simulación de sistemas distribuidos
- Cross-correlation
- Metapatrones
- Input/output
- ...
-
algunos ejemplos con un dump de Twitter...
Contando letras...
Resumen Numérico
- Descripción:
- Agregar varios valores numéricos mediante alguna función estadística
- Objetivo:
- Procesar una lista de valores de entrada (números) para obtener un sólo valor y disponer de una medida de alto nivel de un conjunto de datos
- Aplicabilidad:
- Gestión de datos numéricos
- Agrupar datos por un campo determinado
- Ejemplos:
- Contar, Min/Max, media, desviación típica, etc.
Pseudo-código
class Mapper
method Map(recordid id, record r)
for all term t in record r do
Emit(term t, count 1)
class Reducer
method Reduce(term t, counts [c1, c2,...])
sum = 0
for all count c in [c1, c2,...] do
sum = sum + c
Emit(term t, count sum)
Ejemplo-Contar Palabras
...y en Java...
public void map(LongWritable key, Text value, Context context)
throws Exception {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
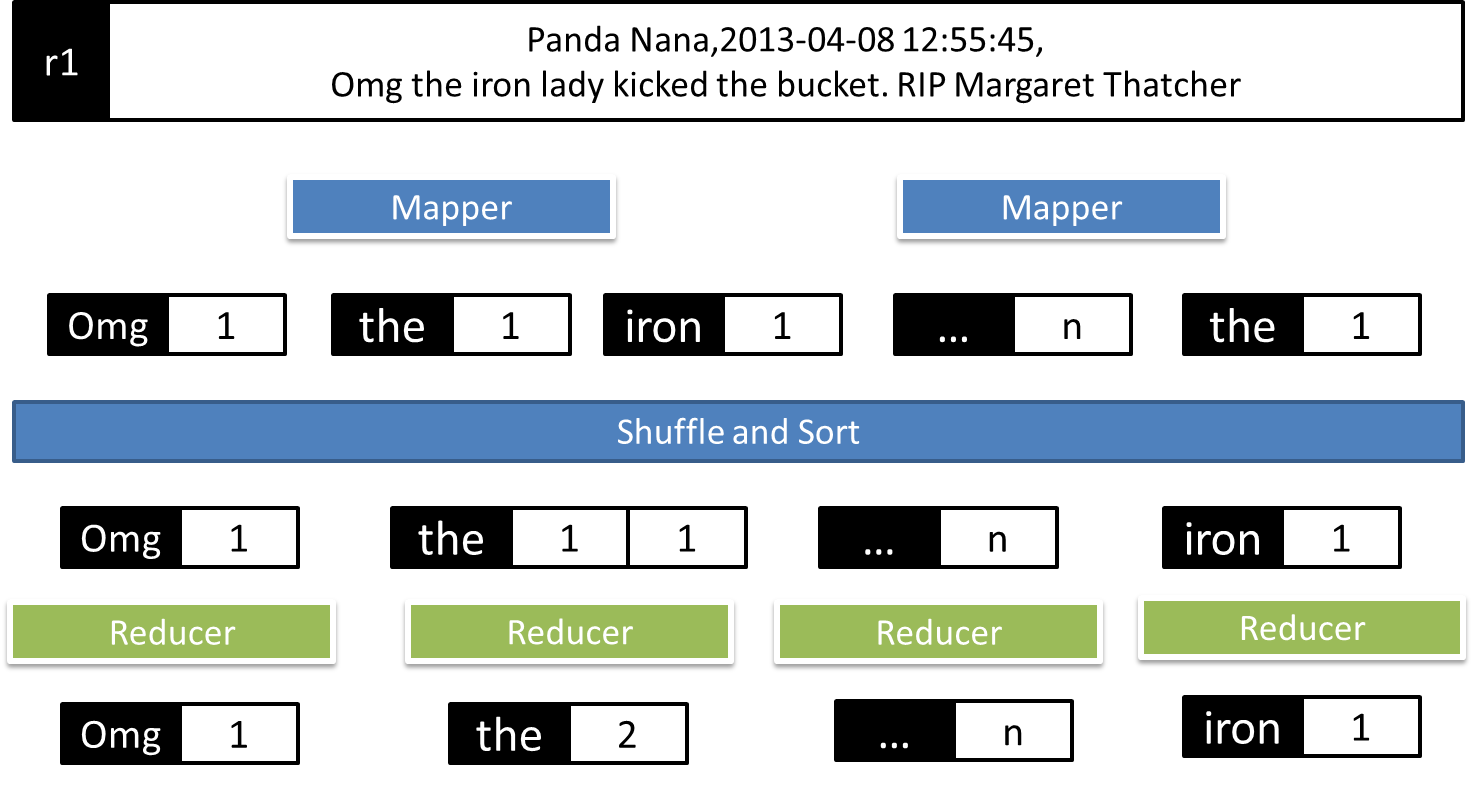
Min/Max
"Dada una lista de tweets en la forma (usuario, fecha y texto) determinar el primer y último comentario de un usuario"
Ejemplo gráfico
Map en Min/Max
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException, ParseException {
Map parsed = MRDPUtils.parse(value.toString());
String strDate = parsed.get(MRDPUtils.CREATION_DATE);
String userId = parsed.get(MRDPUtils.USER_ID);
if (strDate == null || userId == null) {
return;
}
Date creationDate = MRDPUtils.frmt.parse(strDate);
outTuple.setMin(creationDate);
outTuple.setMax(creationDate);
outTuple.setCount(1);
outUserId.set(userId);
context.write(outUserId, outTuple);
} Reduce en Min/Max
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
result.setMin(null);
result.setMax(null);
int sum = 0;
for (MinMaxCountTuple val : values) {
if (result.getMin() == null
|| val.getMin().compareTo(result.getMin()) < 0) {
result.setMin(val.getMin());
}
if (result.getMax() == null
|| val.getMax().compareTo(result.getMax()) > 0) {
result.setMax(val.getMax());
}
sum += val.getCount();}
result.setCount(sum);
context.write(key, result);
}
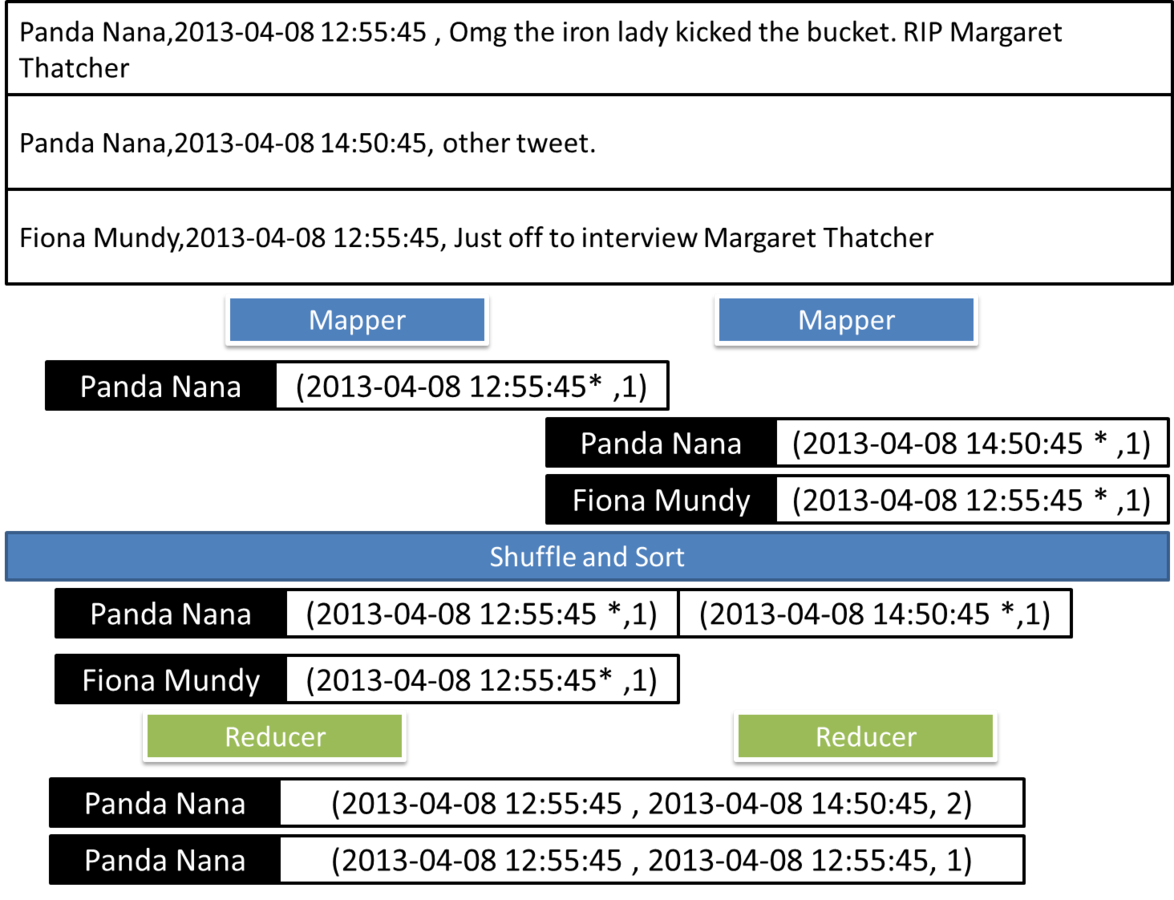
Media
Dada una lista de tweets en la forma (usuario, fecha y texto) determinar la media del tamaño del comentario por hora del día
Ejemplo

Map para media
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException,ParseException {
Map parsed =
MRDPUtils.parse(value.toString());
String strDate = parsed.get(MRDPUtils.CREATION_DATE);
String text = parsed.get(MRDPUtils.TEXT);
if (strDate == null || text == null) {
return;
}
Date creationDate = MRDPUtils.frmt.parse(strDate);
outHour.set(creationDate.getHours());
outCountAverage.setCount(1);
outCountAverage.setAverage(text.length());
context.write(outHour, outCountAverage);
}Reduce para media
public void reduce(IntWritable key, Iterable values,
Context context) throws IOException, InterruptedException {
float sum = 0;
float count = 0;
for (CountAverageTuple val : values) {
sum += val.getCount() * val.getAverage();
count += val.getCount();
}
result.setCount(count);
result.setAverage(sum / count);
context.write(key, result);
} Resumen Numérico Avanzado
Utilizando PIG
SELECT MIN(numcol1), MAX(numcol1),
COUNT(*) FROM table GROUP BY groupcol2;
b = GROUP a BY groupcol2;
c = FOREACH b GENERATE group, MIN(a.numcol1),
MAX(a.numcol1), COUNT_STAR(a);Filtrado
- Descripción:
- Evaluar una condición en cada registro de datos para decidir que se hace con él
- Objetivo:
- Filtrar registros de datos que no cumplen alguna condición
- Aplicabilidad:
- Filtrar
- Ejemplos:
- Vista parcial del dataset, limpieza de datos, monitorización de determinados eventos, selección de muestras, grep distribuido, análisis de registros, consulta y validación de datos, etc.
Pseudo-código
class Mapper
method Map(recordid id, record r)
field f = extract(r)
if predicate (f)
Emit(recordid id, value(r))
class Reducer
method Reduce(recordid id, values [r1, r2,...])
//Whatever
Emit(recordid id, aggregate (values)) Grep distribuido
Dada una lista de tweets en la forma (usuario, fecha y texto) determinar los tweets que contienen una determinada palabra.
Ejemplo
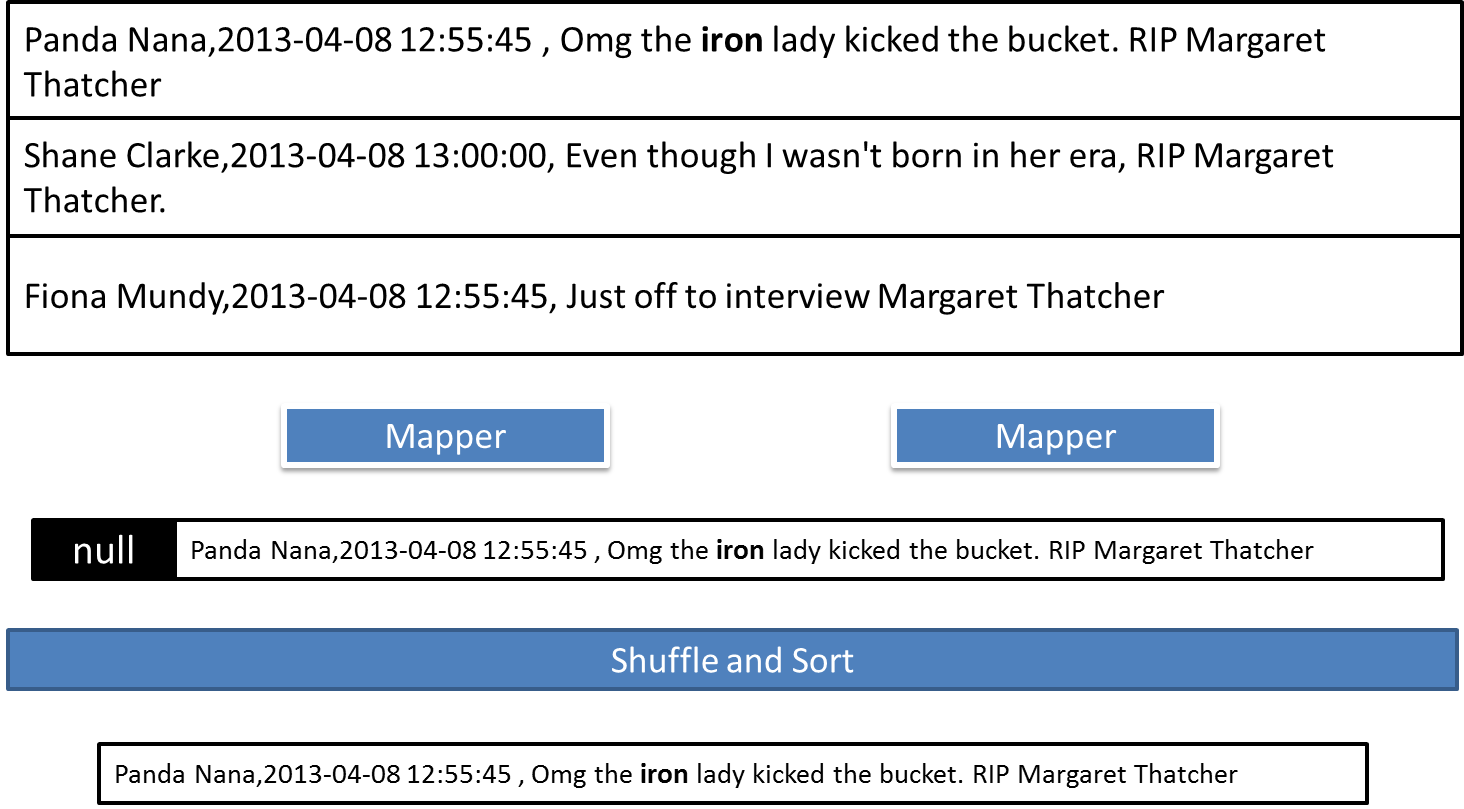
Map Grep distribuido
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed =
MRDPUtils.parse(value.toString());
String txt = parsed.get(MRDPUtils.TEXT);
String mapRegex = ".*\\b"+context.getConfiguration()
.get("mapregex")+"(.)*\\b.*";
if (txt.matches(mapRegex)) {
context.write(NullWritable.get(), value);
}
} Usuarios y tweets más largos
Dada una lista de tweets en la forma (usuario, fecha y texto) determinar los 5 usuarios que escriben los tweets más largos.
Ejemplo
Map Tweets más largos
private TreeMap repToRecordMap = new TreeMap();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map parsed =
MRDPUtils.parse(value.toString());
if (parsed == null) {return;}
String userId = parsed.get(MRDPUtils.USER_ID);
String reputation = String.valueOf(parsed.get(MRDPUtils.TEXT).length());
//Max reputation if you write tweets longer
if (userId == null || reputation == null) {return;}
repToRecordMap.put(Integer.parseInt(reputation), new Text(value));
if (repToRecordMap.size() > MAX_TOP) {
repToRecordMap.remove(repToRecordMap.firstKey());
}
} Reduce Tweets más largos
public void reduce(NullWritable key, Iterable values,
Context context) throws IOException, InterruptedException {
for (Text value : values) {
Map parsed = MRDPUtils.parse(value.toString());
repToRecordMap.put(parsed.get(MRDPUtils.TEXT).length(),new Text(value));
if (repToRecordMap.size() > MAX_TOP) {
repToRecordMap.remove(repToRecordMap.firstKey());
}
}
for (Text t : repToRecordMap.descendingMap().values()) {
context.write(NullWritable.get(), t);
}
} Filtrado con PIG
SELECT * FROM table WHERE colvalue < VALUE;
b = FILTER a BY colvalue < VALUE;< VALUE;Conclusiones
- M/R es un modelo de programación
- ...para manejar grandes cantidades de datos off-line
- ...escalabilidad, replicación, tolerancia a fallos, etc.
- Apache Hadoop no es una base de datos
- Existen muchos proyectos basados en Hadoop
- Existen enfoques similares:
- Apache Storm
- Apache Spark
- Apache Flink
- Signal/Collect
- ...
¿Qué hay después?
-
Concatenación de trabajos M/R
-
En otros frameworks ya superado (ej: Flink)
-
-
Optimización de los parámetros del algoritmo
-
Pipelining con otros lenguajes de programación
-
Patrones más avanzados
-
Procesamiento en tiempo real
-
Problemas actuales: imágenes, etc.
- ...
Ejemplo completo de
arquitectura Lambda
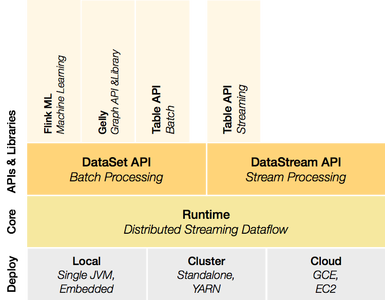
Apache Spark
Apache Flink
vs


Apache Spark
Apache Flink
Apache Flink
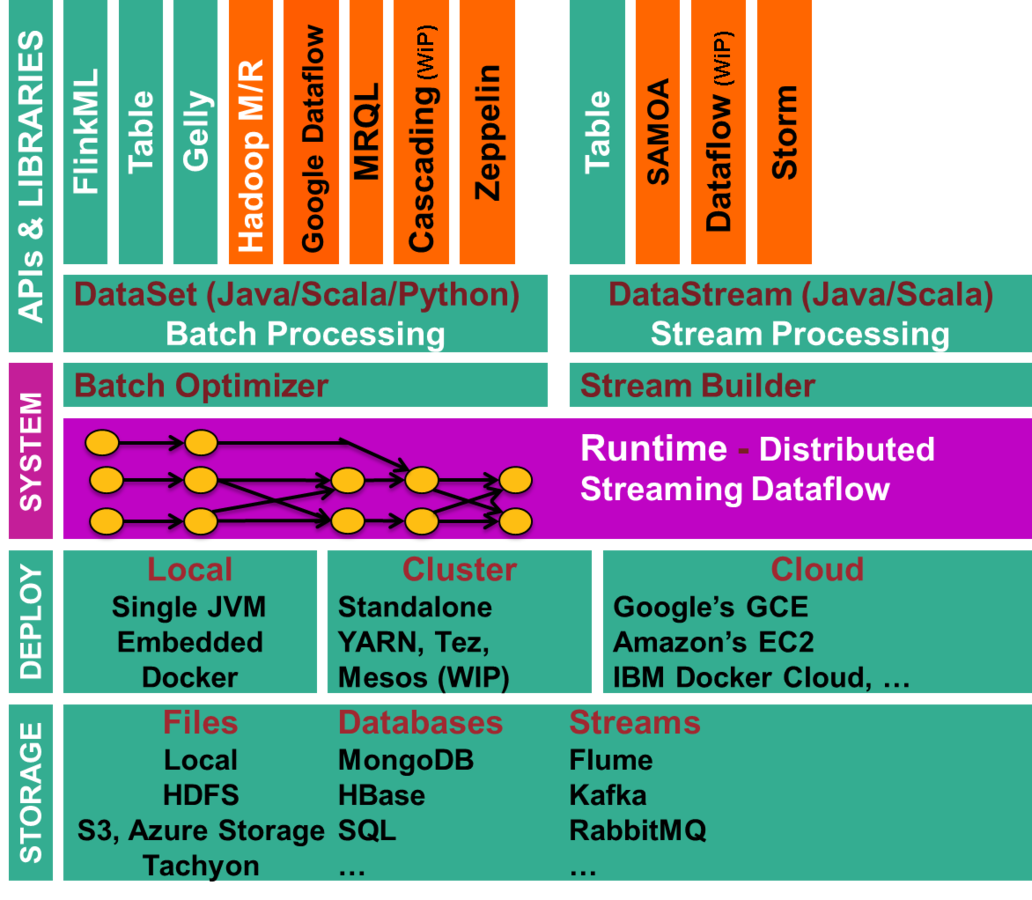
Resumen
¿Qué es Big Data?
Arquitectura
M/R y Hadoop
Tecnología y frameworks
FAQ
¿Tengo un problema Big Data?
- Evaluar de acuerdo a las 3-8 V's
- Definir necesidades
-
Procesamiento
- ¿Batch? ¿Tiempo real ? ¿Ambas?
- Almacenamiento
- Tablas, documentos, grafos, etc.
- Frecuencia de actualización
-
Consulta
- Lenguaje de consulta
- Infraestructura
- ¿Local? ¿Cloud Computing?
- Seleccionar tecnología
¿Cuál es el coste?
- Se puede empezar con las herramientas ya disponibles como código abierto
- La clave está en el conocimiento y el modelado del problema
- Los datos ya están disponibles
- Gratuitos
- Otros de pago
-
Se pueden crear
- Infraestructura para procesamiento y "crawling" (http://commoncrawl.org/)
- La implementación es cuestión de tiempo y de la tecnología seleccionada
¿Existe alguna suite completa?
- Cloudera Impala
- Pentaho (ETL)
- RapidMiner
- MapR
- Hortonworks
- IBM Watson Analytics
- Palantir
- Presto
- Lambdoop
- ...
¿Existen oportunidades de negocios?
¿Existen temas abiertos?
- Privacidad
- Salto entre modelo matemático y despliegue en arquitectura Big Data
- Big Data Governance (¿Semántica?)
- Acercar o facilitar Big Data para usuarios finales
- Aplicaciones
- Recomendación
- Análisis de sentimiento, etc.
- Visualización (D3.js, Highlights.js, etc.
- ...
¿Cuál es la diferencia con BI?
No es sencillo de hacer una gran diferenciación pero caería en los siguientes puntos:
- Big Data: estadística inferencial y low-density información
- BI: estadística descriptiva y high-density información
¿Big Data vs HPC?
- Big Data trata sobre datos
- HPC trata sobre poder computacional
...pero destinados a encontrarse...
http://www.hpcuserforum.com/presentations/tuscon2013/IDCHPDABigDataHPC.pdf

¿Cómo se forma un equipo?
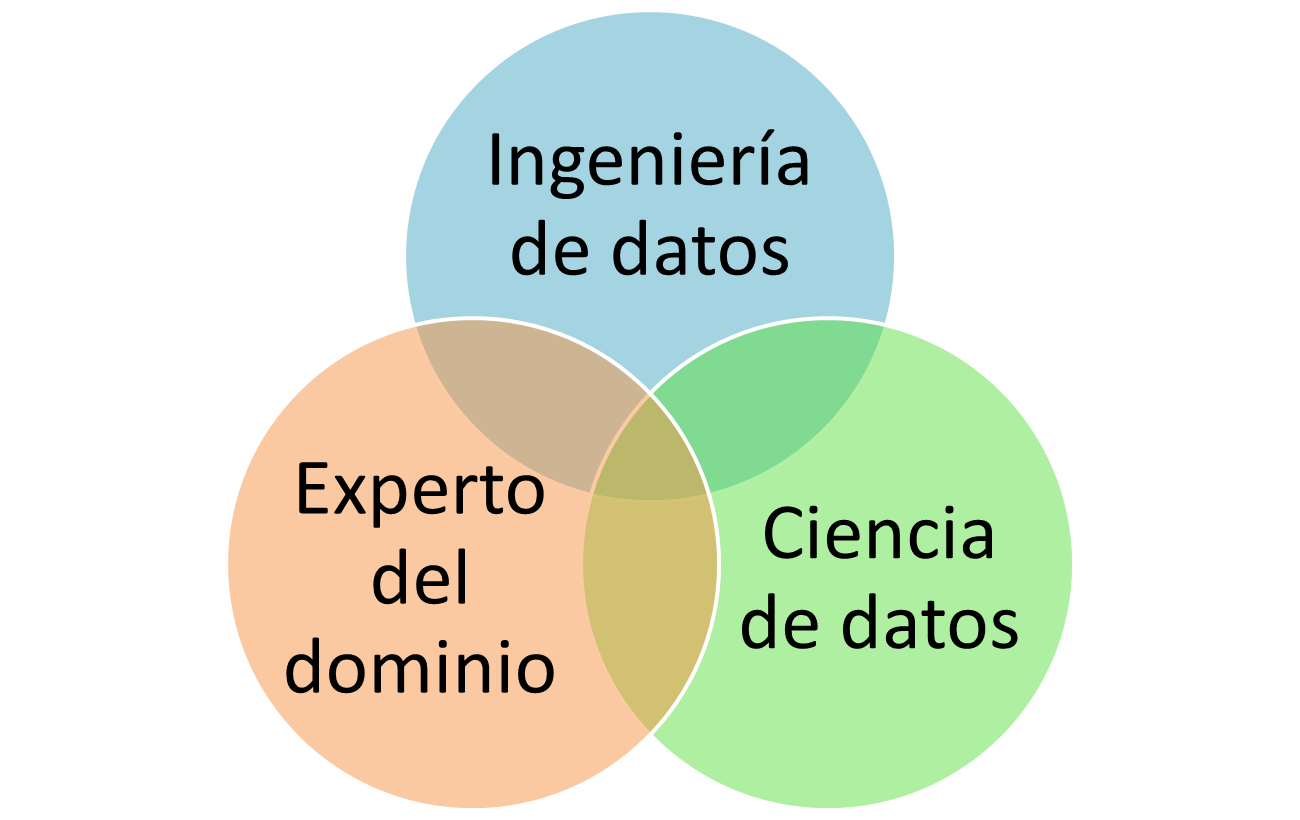
¿Por dónde continuar?
Entender los fundamentos de Big Data (ej: Hadoop, etc.)
Probar y ascender en el conocimiento de herramientas de mayor nivel de abstracción
- http://spark.apache.org/docs/latest/quick-start.htm
- https://ci.apache.org/projects/flink/flink-docs-release-0.10/quickstart/setup_quickstart.html
- http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/ciiu_tutorial.html
-
https://www.mapr.com/services/mapr-academy/course-pricing (estos son caros)
¿Cursos on-line específicos?
- Big Data
- Data Science
¿Algún libro?

Top libros...
Tendencias
(además de las de Gartner 2016)
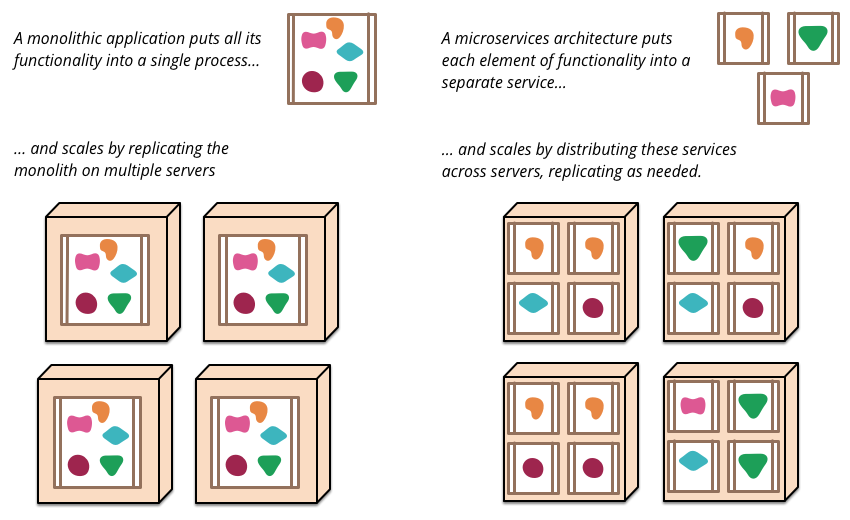
Microservicios y similares
Deep Learning-
Google Tensor Flow
Data Lake

Almacén de datos "en crudo" y en sus formatos nativos hasta que son procesados.
Sistemas interactivos para ciencia de Datos
Ej: Jupyter

Mitos
"Yo también quiero Big Data"
Dependiendo del problema se podrán aplicar las técnicas de forma más exitosa.
La selección debería basarse en innovación tecnológica para un proceso en negocio y no en marketing.
"Es sólo un problema técnico(IT)"
Realmente se debe buscar el problema de negocio y de ahí descender a la solución técnica. Ej: Walmart
"No se puede aplicar a grandes empresas por su diversidad"
Realmente el problema reside en la integración de datos y no en la aplicabilidad de las técnicas
"El coste de las herramientas y expertos es muy alto"
Sobre las herramientas e infraestructura ya se ha comentado y sobre los expertos el problema reside en seleccionar el perfil correcto: estadístic@, ingenier@, etc.
y más mitos...
- http://www.slideshare.net/ProphetBrandStrategy/the-myths-of-big-data
- http://www.v3.co.uk/v3-uk/analysis/2302685/top-10-big-data-myths-and-misconceptions/page/2
- Big data is new
- Big data is a commodity
- Big data is a problem
- Your data is useful only to you
- The government isn't interested in your social media data
- Big data won't land you in jail
- ...
Si con un "SMARTPHONE" no eres más "SMART"
Con"BIG DATA" no eres más "BIG"
Es muy importante contextualizar el problema de negocio tanto en necesidades como en nuestras capacidades
No es necesario diseñar/implementar una arquitectura desde el inicio, existen muchas herramientas ya disponibles
...pero...
IBM BIG DATA (Predicción)
4x more digital data than all the grains of sand on earth by 2020 #bigdata
https://twitter.com/IBMAnalytics/status/417748100217061377/photo/1

¡Explotemos Big Data!


- Ponente: Dr. Jose María Alvarez-Rodríguez
- Profesor Visitante
- Co-Director Cátedra RTVE-UC3M en Big Data
- Universidad Carlos III de Madrid
- E-mail: josemaria.alvarez@uc3m.es
- WWW:
Créditos
Data for all and all for Data 2016
By Jose María Alvarez
Data for all and all for Data 2016
Data for all and all for Data: Perspectivas y Oportunidades en la Web de Dato




