0 to 100 with
Jowanza Joseph
@jowanza
Origins

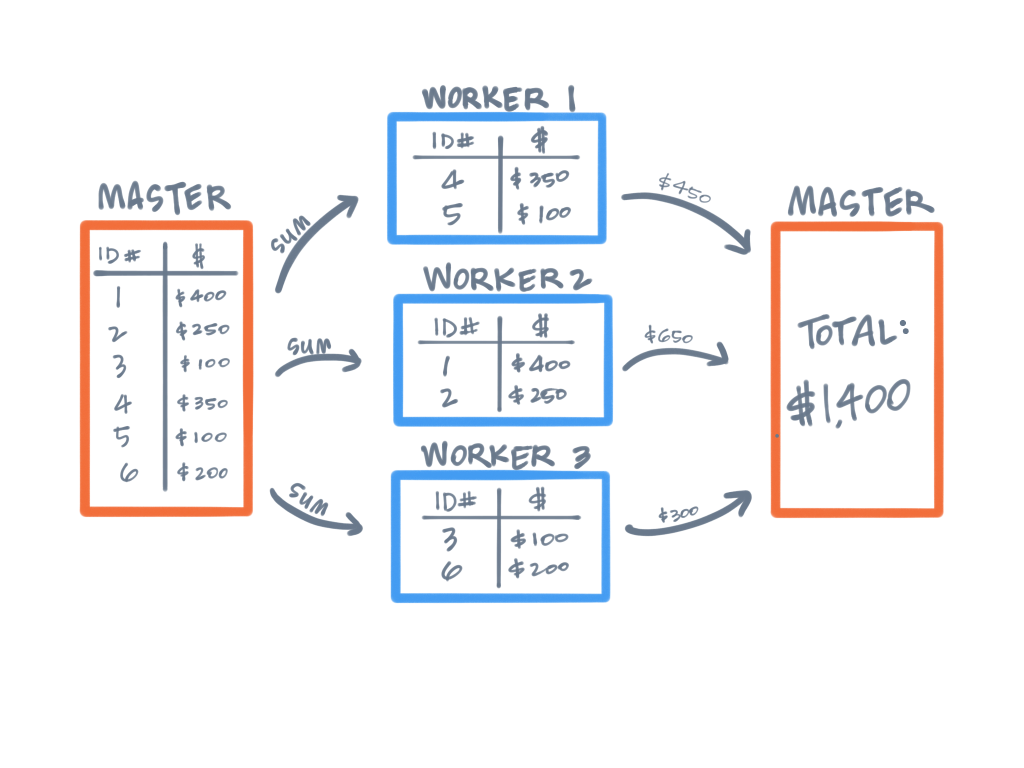
Basic Design
- Inspired by the MapReduce paradigm
- Focused on in-memory processing
- Built primarily for batch jobs
- Streaming as a special case
- Written in Scala
Principles
- Memory Efficiency
- Parallelism
- Lazy Evaluation*

APIs
- Scala, Java, Python and R APIs
- Spark SQL
- Structured Streaming
- GraphX
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
import spark.implicits._
val df = spark.read.json("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
df.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+val spark: SparkSession = ...
// Read text from socket
val socketDF = spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
socketDF.isStreaming // Returns True for DataFrames that have streaming sources
socketDF.printSchema
// Read all the csv files written atomically in a directory
val userSchema = new StructType().add("name", "string").add("age", "integer")
val csvDF = spark
.readStream
.option("sep", ";")
.schema(userSchema) // Specify schema of the csv files
.csv("/path/to/directory") // Equivalent to format("csv").load("/path/to/directory")Jobs
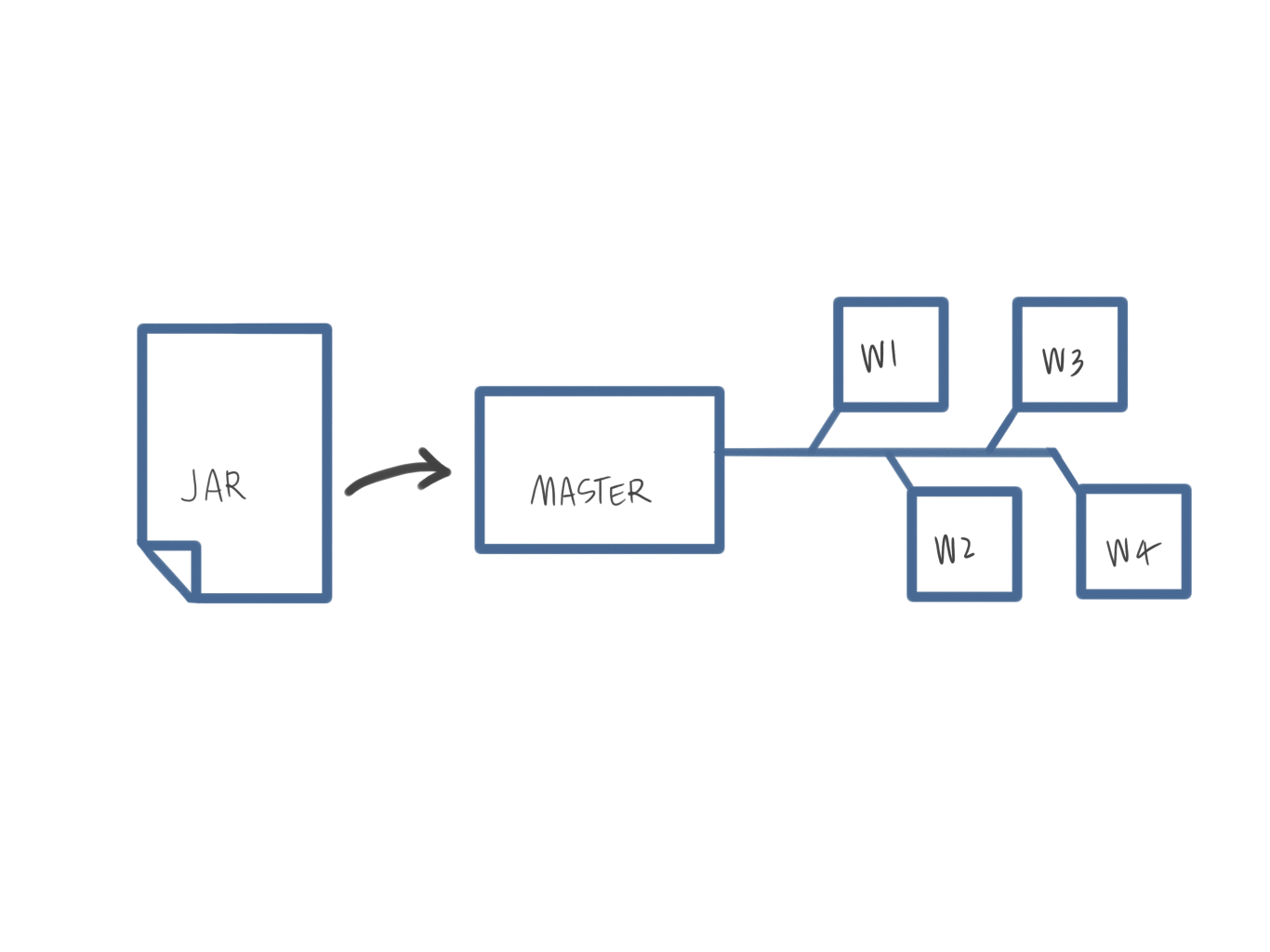
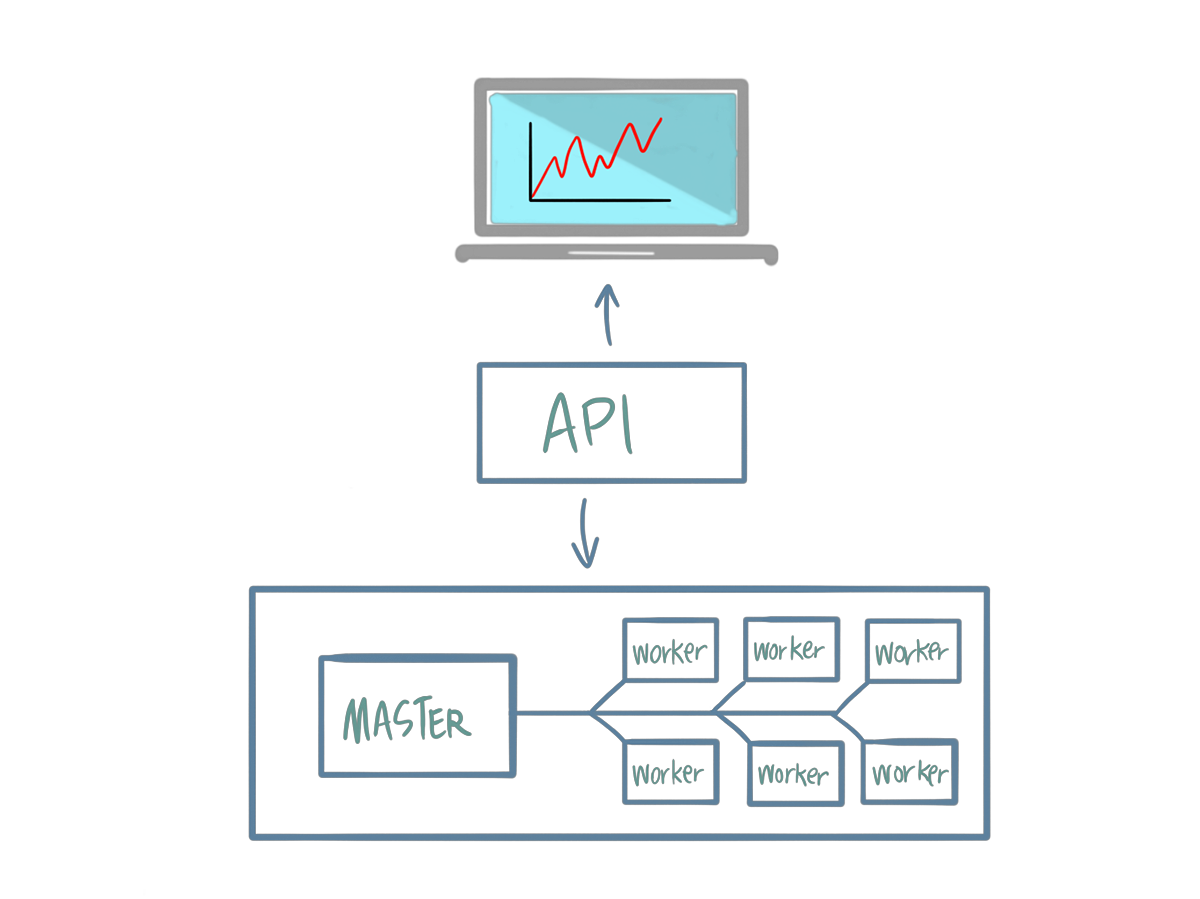
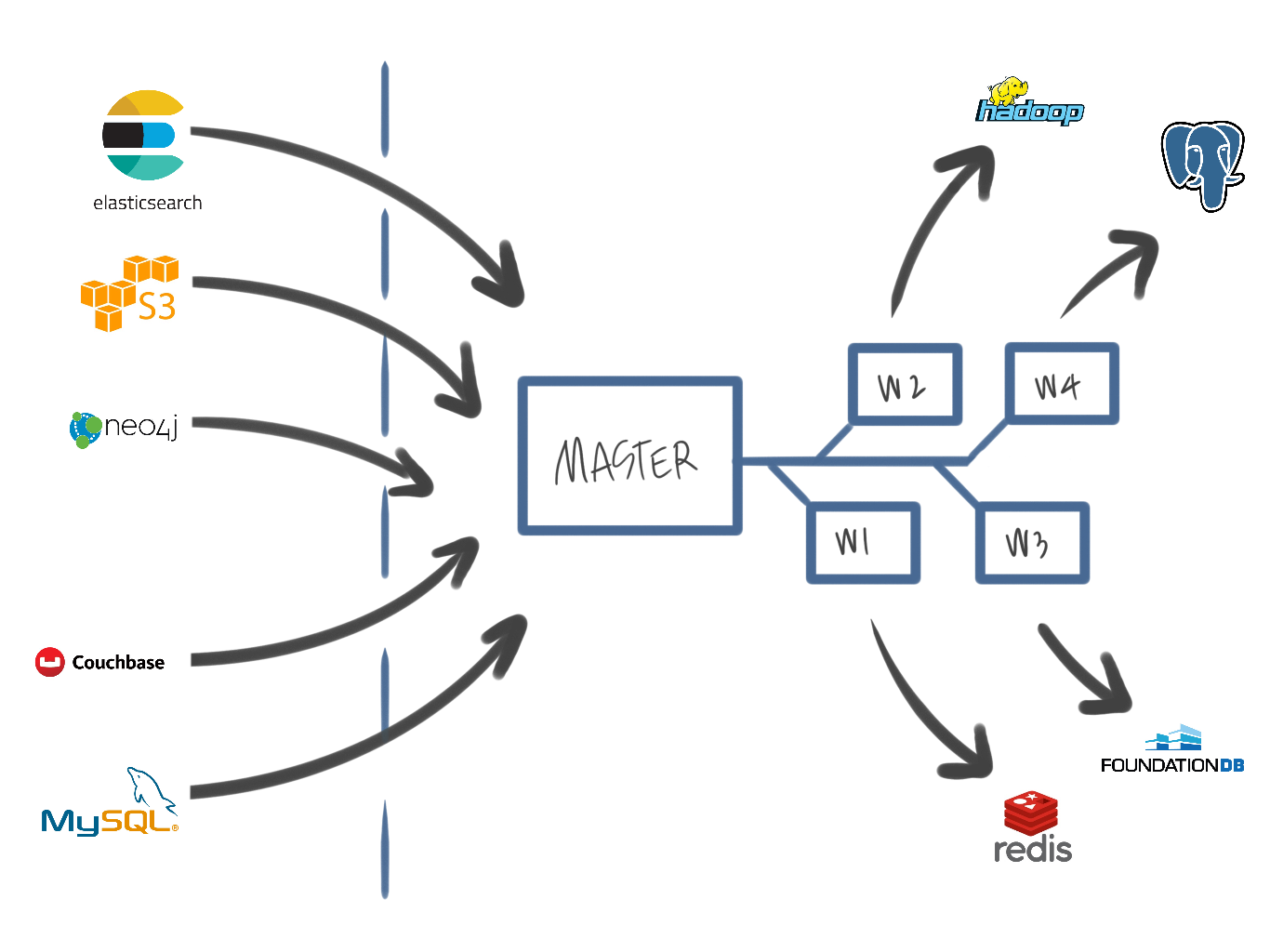
Ecosystem
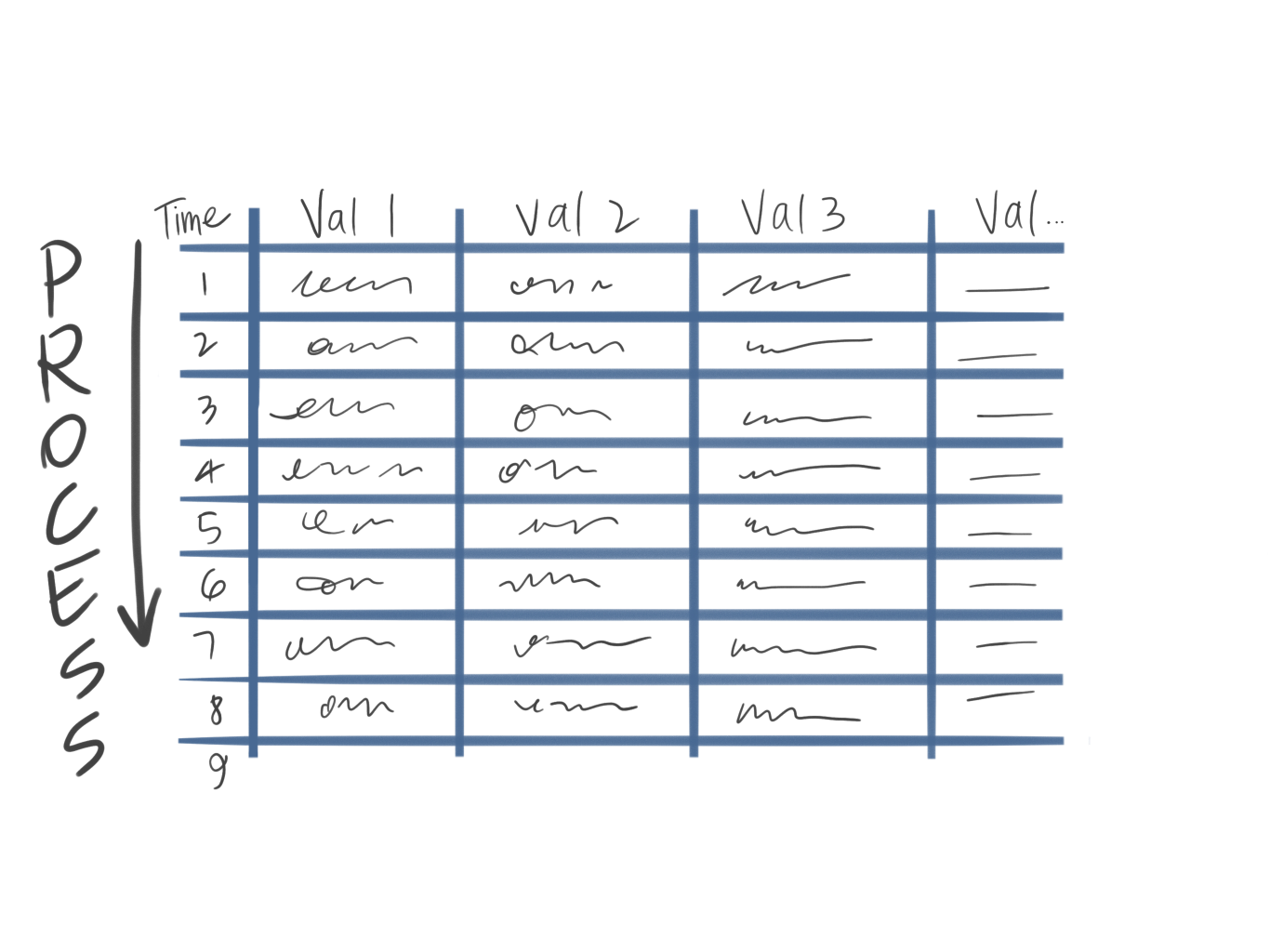
Stream Processing
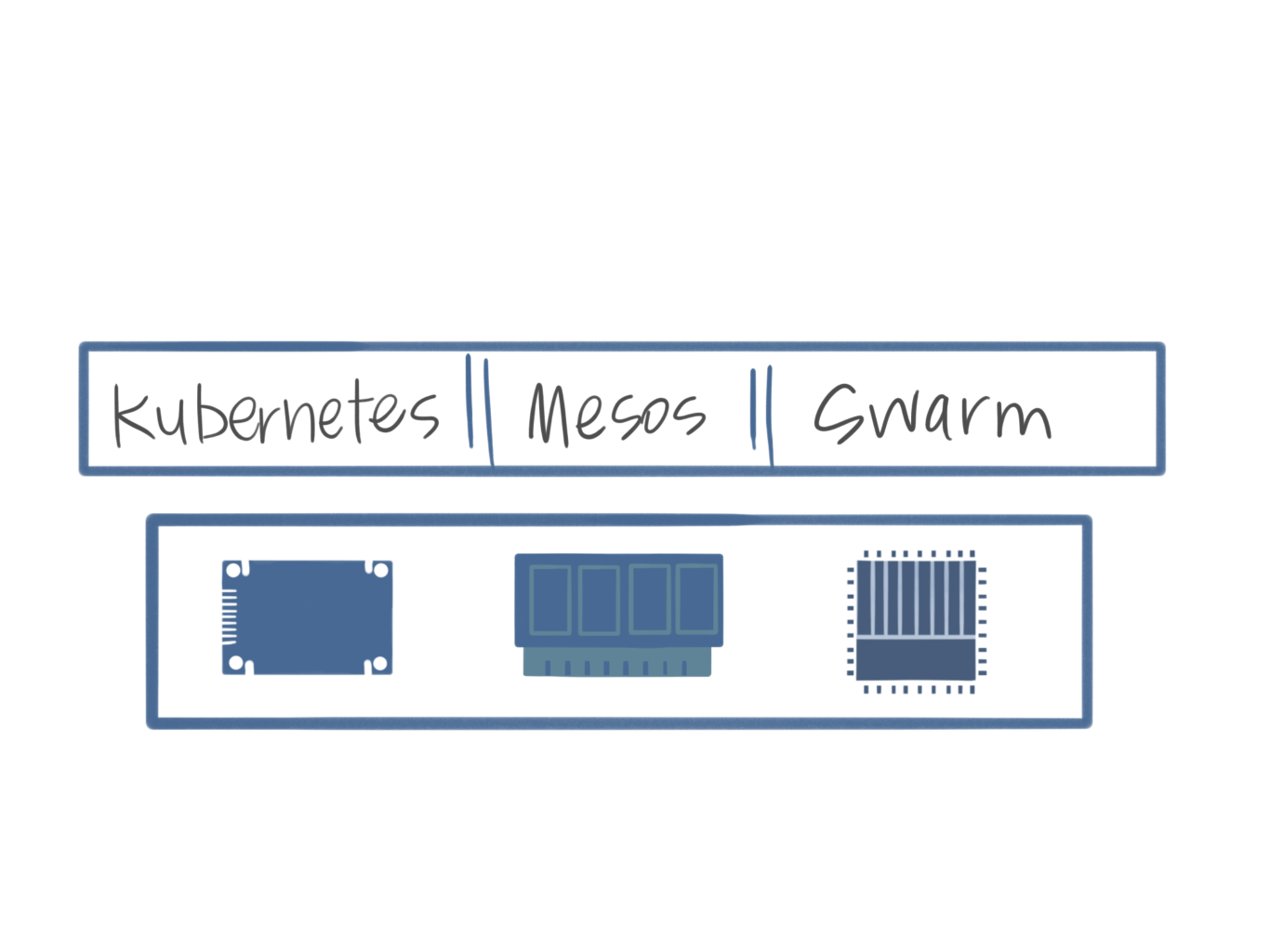
Deployment Options

Extras



Demo
Resources

Thanks
0 to 100 withApache Spark
By Jowanza Joseph




