ETL With Apache Spark
Jowanza Joseph
@jowanza
About Me
- Software Engineer at One Click Retail
- Java Virtual Machine (Scala, Java)
- Distributed Systems
- Husband and Father

Agenda
- A Brief History of ETL
- A Brief History of Large Data
- The Value of Scala In This Ecosystem
- The Lambda Architecture
- The Kappa Architecture
- Spark For ETL (Code + Demo)
- Questions
A Brief History of ETL
Extract
Transform
Load
Slow Data
Why?
Data Is more valuable when it's mixed with other data.
A Brief History Of Large Data

How do you store petabyte scale data?
Glaciers

Distributed File System
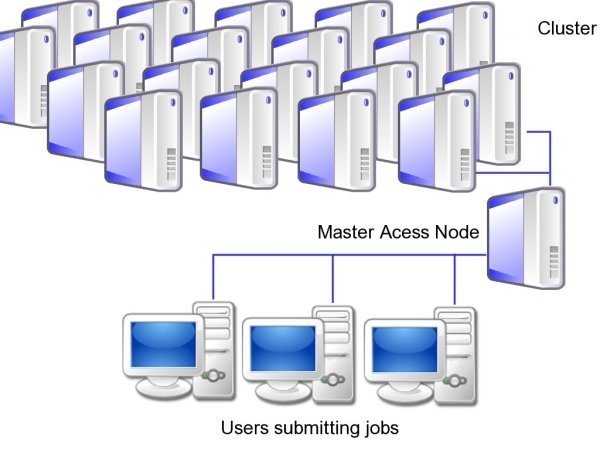
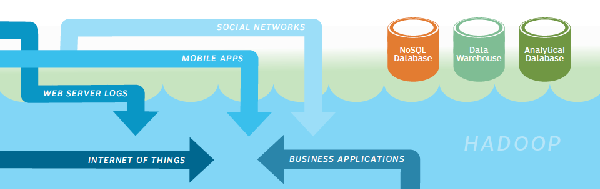
The Data Lake
Why Scala?

Types
case class Datum(product: String, category: String, revenue: Int)
val data = sc.textFile("./data.txt")
.map(_.split(","))
.map(r=> Datum(r(0), r(1), r(2).toInt))
.toDF()
Functional Programming
JVM
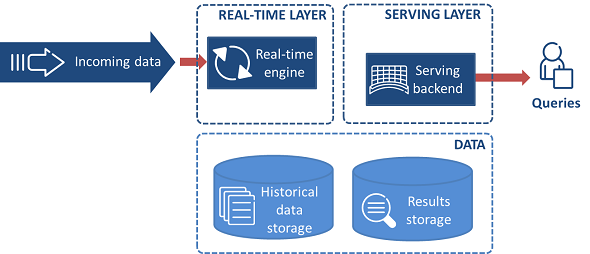
Big Data Architecture
Lambda Architecture
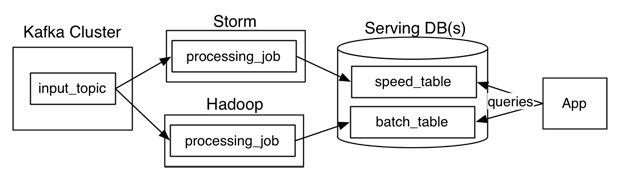
Kappa Architecture
Apache Spark™ is a fast and general engine for large-scale data processing.
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3
val conf = new SparkConf().setAppName("")
.setMaster("local[8]").set("spark.executor.memory", "10g")
.set("spark.driver.memory", "10g")
val sc = new SparkContext(conf)
val conf = new SparkConf().setAppName("MY_APP_NAME").setMaster("MASTER")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val data = sqlContext.read
.format("jdbc")
.option("url", "jdbc:mysql://<HOST>:3306/<database>")
.option("user", <USERNAME>)
.option("password", <PASSWORD>)
.option("dbtable", "MYSQL_QUERY")
.load()Dataframe
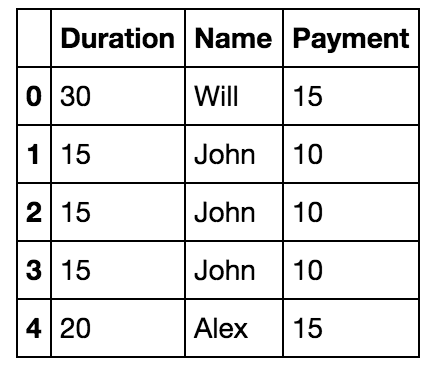
Fix Ugly Data

val conf = new SparkConf().setAppName("")
.setMaster("local[8]").set("spark.executor.memory", "10g")
.set("spark.driver.memory", "10g")
.set("com.couchbase.bucket.<>", "password")
.set("com.couchbase.nodes", "node_ip")
val query1 = "SELECT search_upid as search_upid, brandName, categoryNamePath as categoryName,
title, upcs[0] as upc from `indix-items_staging` where search_upid is NOT NULL and upcs[0] IS NOT NULL"
val dats = sc.couchbaseQuery(N1qlQuery.simple(query1))
.collect()
.map(x => x.value.toString)
case class NewInterpret(categoryName: String, upc: String, brandName: String, title: String, search_upid: String)
object NewInterpretProtocol extends DefaultJsonProtocol {
implicit val interpretformat = jsonFormat5(NewInterpret)
}
import NewInterpretProtocol._
val testValue = dats.map(x => x.parseJson.convertTo[NewInterpret])
val endGame = sc.parallelize(testValue).toDF()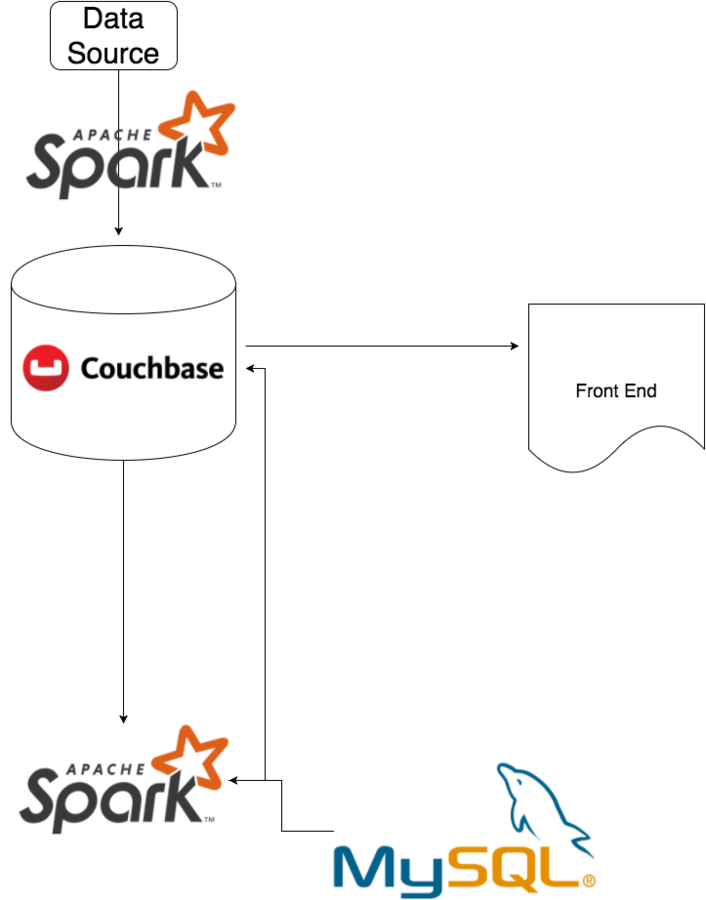
val rawData = sqlContext.read
.format("com.databricks.spark.redshift")
.option("url", "jdbc:redshift://<>")
.option("tempdir", "s3n://<>")
.option("query", "select...")
.load()Handy For ETL
UDF
val dataset = Seq((0, "hello"), (1, "world")).toDF("id", "text")
// Define a regular Scala function
val upper: String => String = _.toUpperCase
// Define a UDF that wraps the upper Scala function defined above
// You could also define the function in place, i.e. inside udf
// but separating Scala functions from Spark SQL's UDFs allows for easier testing
import org.apache.spark.sql.functions.udf
val upperUDF = udf(upper)
// Apply the UDF to change the source dataset
scala> dataset.withColumn("upper", upperUDF('text)).show
+---+-----+-----+
| id| text|upper|
+---+-----+-----+
| 0|hello|HELLO|
| 1|world|WORLD|
+---+-----+-----+Pattern Matching
def getRegressionReturns(data: DataFrame): RegressionReturns = {
Try(new LinearRegression().setMaxIter(100).setRegParam(0.3).fit(data)) match {
case Success(x) => RegressionReturns(x.intercept, x.coefficients(0))
case Failure(y) => RegressionReturns(0, 0)
}
}Spark Streaming

Questions?
ETL With Apache Spark
By Jowanza Joseph
ETL With Apache Spark
Transforming and moving data with Apache Spark



