













Julián Duque
Developer and Educator
with Node.js
Principal Developer Advocate at Heroku
JSConf/NodeConf Colombia Organizer
Node.js Collaborator Emeritus
🦋 @julianduque.co
/in/juliandavidduque
X @julian_duque
💡 For the purposes of this session: AI ~ Agentic AI
Uses one or more Large Language Model (LLMs) to reason, plan, and execute tasks.
Runs inference across different modalities (text, code, audio, etc)
Integrates with tools, data sources, user input, and other AI agents
Large Language Model (LLM): A type of AI model trained on massive text data to understand and generate human-like language.
Inference vs Training: Inference is using a trained model to make predictions. Training is the process of teaching a model with data.
Model Size (7B / 13B / 70B): Number of parameters in a model. Larger often means better performance, but slower and more expensive.
Context Window: The amount of input (in tokens) an LLM can consider at once. Limits the scope of reasoning.
Fine-tuning vs Prompt Engineering: Prompting adapts output using input design. Fine-tuning customizes the model weights using new data.
Evaluation: Factuality, Reasoning, Safety. Testing models and systems across multiple axes like correctness, bias, and robustness. For agents, this extends to tool use accuracy, task completion rate, and communication efficiency in multi-agent setups.
Chat: Conversational assistants (foundational).
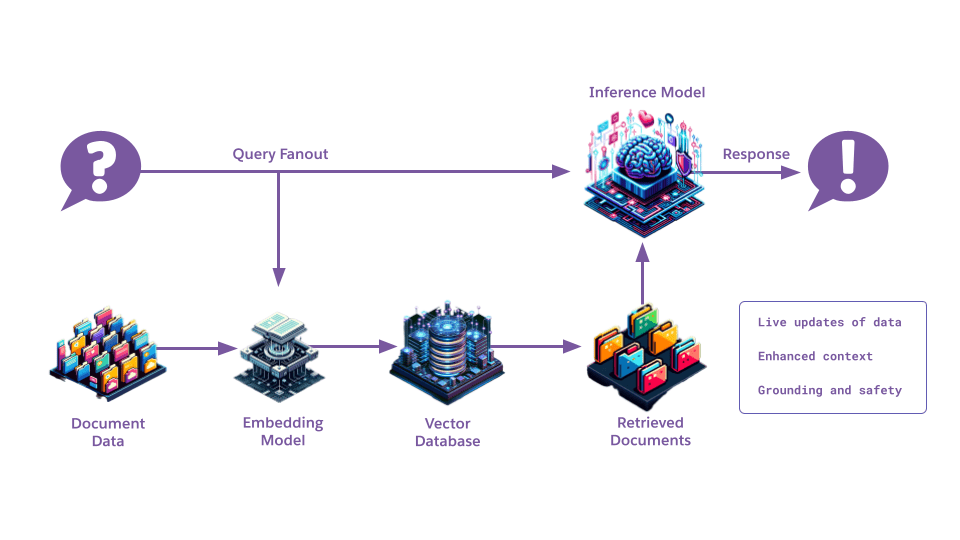
Retrieval Augmented Generation (RAG): Grounding responses with external data (foundational).
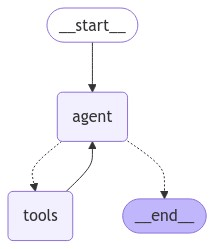
Single-Agent (ReAct): uses the "reasoning and acting" (ReAct) framework to combine chain of thought (CoT) reasoning with external tool use.
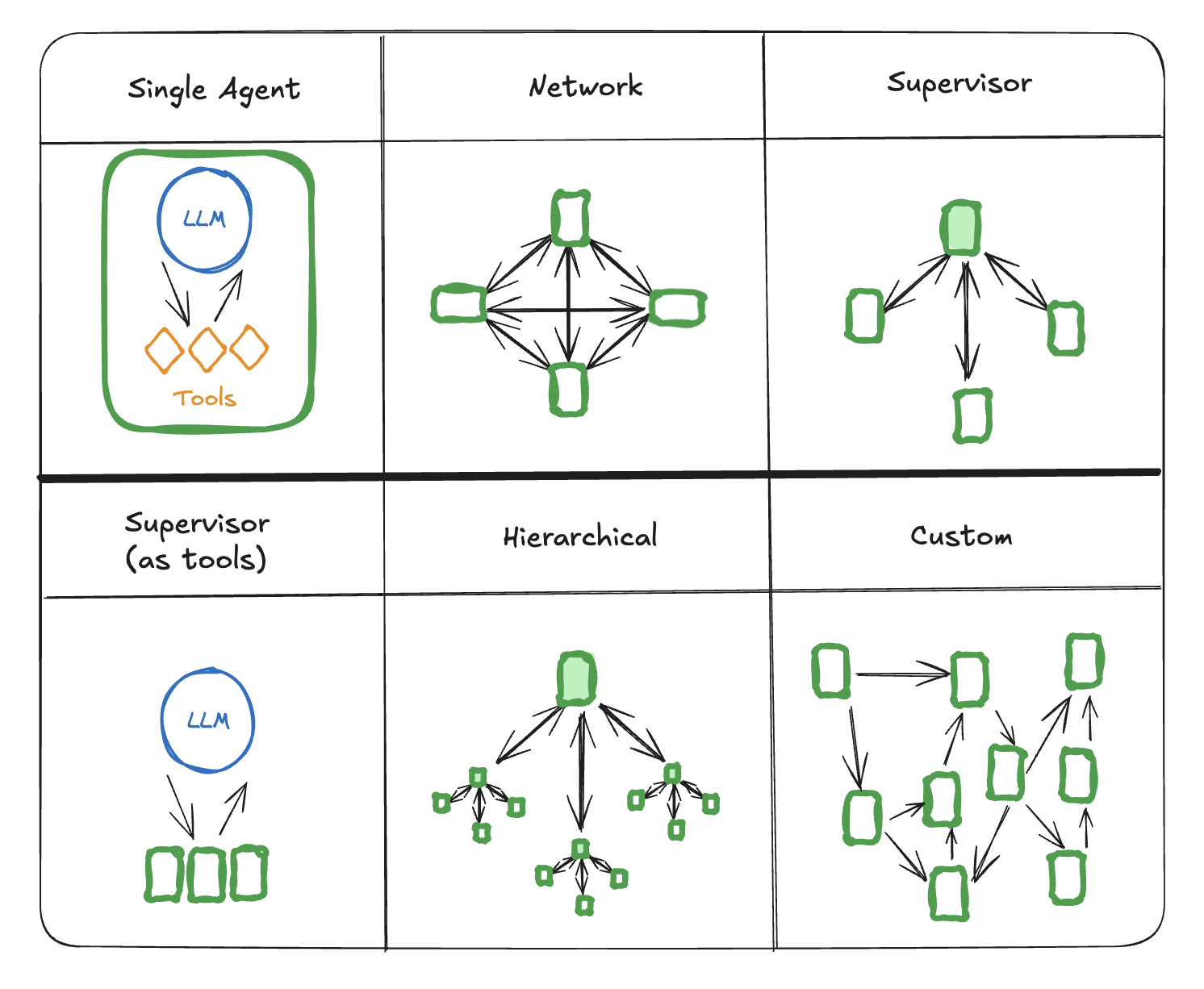
Multi-Agent Systems (MAS): Systems of multiple, specialized agents collaborating to solve complex problems that are beyond the scope of a single agent. This is the focus of modern agentic development.
| Capability | Single-Agent Architecture | Multi-Agent Architecture |
|---|---|---|
| Input | User queries, tasks, goals | Complex, multi-domain goals |
| Behavior | Single reasoning loop, selects from a pool of tools | Task decomposition, delegation to specialized agents, collaborative problem-solving |
| Output | Final answer or series of actions | Synthesized result from multiple agent contributions |
| Best For | Focused, single-domain tasks (e.g., customer support bot) |
End-to-end workflows, complex problem-solving (e.g., automated software development) |
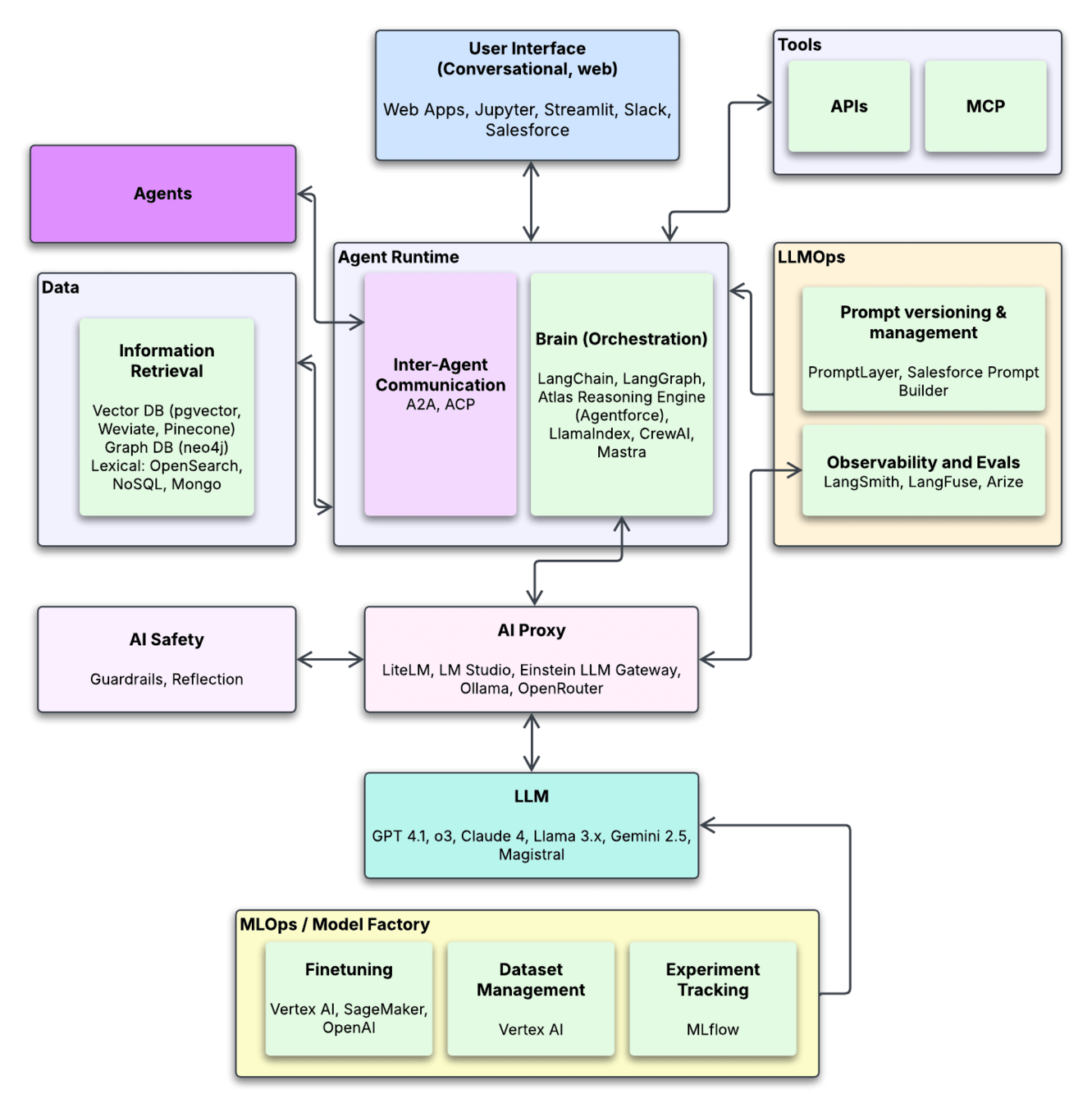
LLMs: OpenAI, Anthropic, Cohere, Google, Mistral, etc.
Vector Store: pgvector (via PostgreSQL), Weviate, Pinecone, etc.
Orchestration: LangChain, LangGraph, CrewAI, Mastra
Embedding: OpenAI, Cohere, HuggingFace APIs
Observability: LangSmith, LangFuse, Arize
Frontend: Your choice!
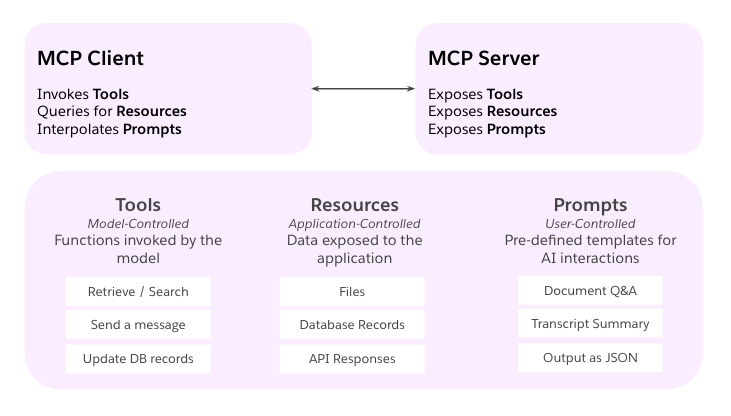
MCP provides the standard for a single agent to discover and use tools and resources. It is the foundational 'plugin' layer upon which multi-agent communication protocols like A2A are built.
Think of MCP as a
"USB-C for AI applications"
An open, application-level protocol, initiated by Google and supported by over 50 industry partners. It enables AI agents to discover, communicate, and collaborate across different systems, frameworks, and organizations.
Agent Card: A discoverable JSON manifest describing an agent's identity, capabilities (e.g., streaming support), skills, and authentication requirements. It's an agent's business card.
Task: The primary unit of work. A stateful, long-running operation with a defined lifecycle (e.g., submitted, working, completed, failed). This allows for asynchronous collaboration.
Message & Parts: Communication occurs via Messages, which contain one or more Parts (e.g., TextPart, FilePart, DataPart). This structure supports rich, multi-modal information exchange.
GPT o4-mini
Claude 4 Sonnet
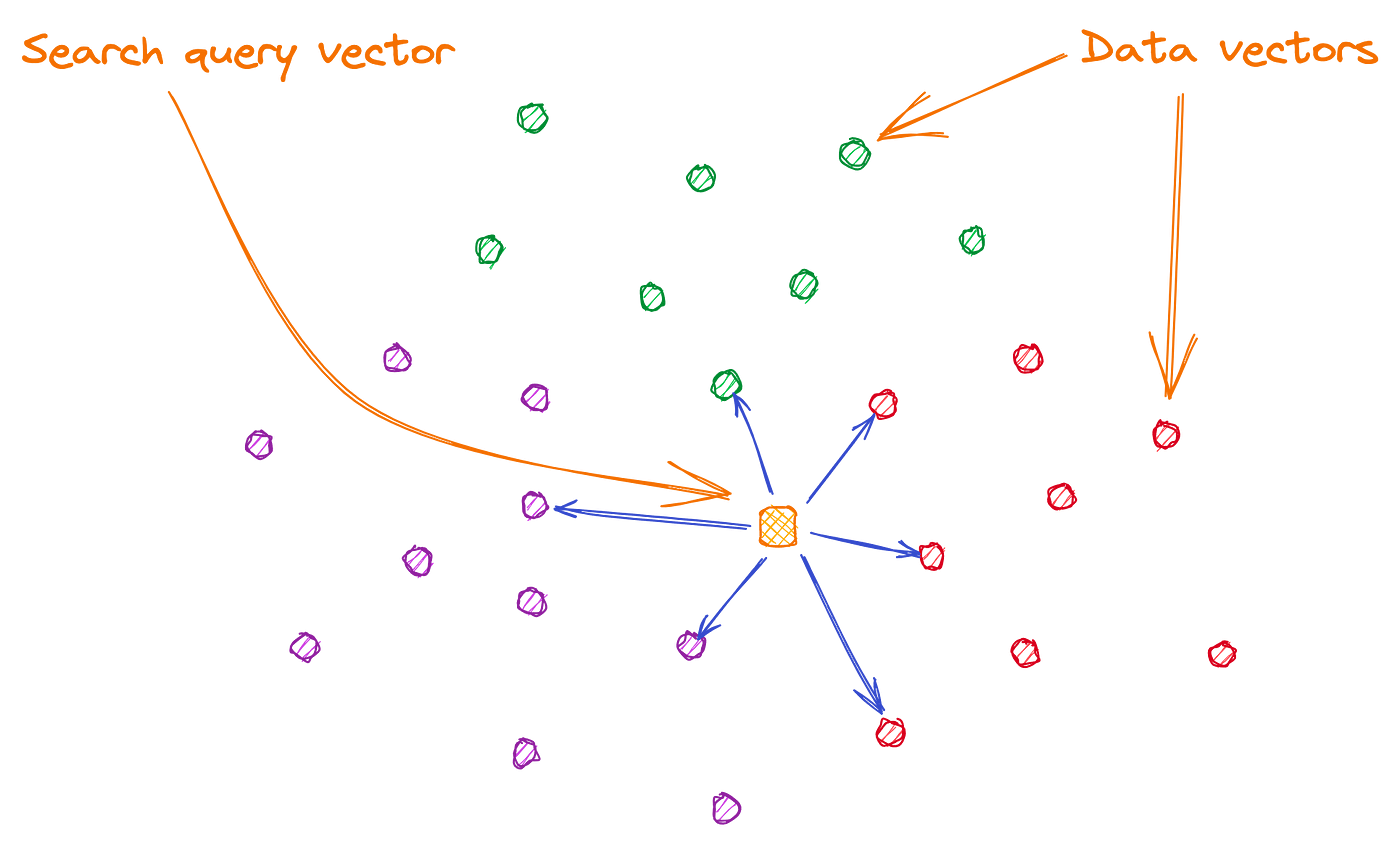
A type of database designed to store and search for data represented as vectors, enabling efficient semantic similarity searches.
-- Enable pgvector
CREATE EXTENSION IF NOT EXISTS vector;
-- Create a table with the VECTOR type
CREATE TABLE animals(id serial PRIMARY KEY, name VARCHAR(100), embedding VECTOR(100));
-- Insert embeddings
INSERT INTO animals(name, embedding) VALUES ('llama', '[-0.15647223591804504,
…
-0.7506130933761597, 0.1427040845155716]');-- Query Data using the euclidean distance operator
=> SELECT name FROM animals WHERE name != 'shark' ORDER BY embedding <-> (SELECT embedding FROM animals WHERE name = 'shark') LIMIT 5;
name
-----------
crocodile
dolphin
whale
turtle
alligator
(5 rows)Image source: Understanding similarity or semantic search and vector databases
Sudhir Yelikar
LangChain is a framework for developing applications powered by large language models (LLMs).
@langchain/core
Base abstractions and LangChain Expression Language (LCEL)
@langchain/community
3rd party integrations, document loaders, tools
@langchain/mcp-adapters
Official adapters to easily connect to MCP-compliant tools and servers.
Partner packages
@langchain/openai, @langchain/anthropic, @langchain/mistralai
LangGraph is a low-level orchestration framework for building controllable agents. It can be used standalone but integrates seamlessly with LangChain.
@langchain/langraph
Stateful: Maintains memory across steps
Graph-based flow: Define control logic as nodes and edges
Concurrent branches: Supports parallel reasoning paths
Node Level Caching: Avoids redundant computations by caching node outputs based on inputs
Retry, Resume & fallback logic: Handle failures with control flows and resumable streams
Agent loops: Enables Think → Act → Observe cycles
| Use Case | Use LangChain.js | Use LangGraph.js |
|---|---|---|
| Simple chains / pipelines | ✅ Yes | ❌ Overkill |
| RAG apps (chat + search) | ✅ Yes | ✅ Yes |
| Agent tool use (basic) | ✅ Yes | ✅ Yes |
| Complex logic / branching flows | ❌ Hard to manage | ✅ Graph-based control |
| Stateful agents | ⚠️ Requires manual state management | ✅ Built-in persistent state |
| Retry / fallback mechanisms | ❌ Manual | ✅ First-class feature |
| Concurrency / parallel branches | ⚠️ Limited (via Runnable.batch) | ✅ Native support for parallel branches and deferred nodes |
| Developer Experience | ✅ Simple, fluent LCEL. | ✅ Fully type-safe .stream() method |
Use LangChain.js for quick LLM integrations, chains, and simple agents.
Use LangGraph.js when your agent needs memory, branching logic, retries, or complex flows.
import { OpenAI } from "@langchain/openai";
// Create an instance of a LLM
const llm = new OpenAI({
modelName: "gpt-4o-mini",
temperature: 0,
});
const result = llm.invoke("What is the meaning of life?");Single prompt → LLM → Completion
A declarative way to compose chains together.
Source: LangChain documentation
Chain: A sequence of operations or steps hat link together different components or modules to accomplish a specific task.
const chain = prompt
.pipe(llm)
.pipe(parser);
const result =
await chain.invoke({ input });import { ChatOpenAI } from "@langchain/openai";
import { RunnableSequence } from "@langchain/core/runnables";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { StringOutputParser } from "@langchain/core/output_parsers";
// Create an instance of a chat model
const llm = new ChatOpenAI({
modelName: "gpt-4o-mini",
temperature: 0,
});
// Create a chat prompt
const promptTemplate = ChatPromptTemplate.fromMessages([
[
"system",`You are a professional software developer who knows about {language}.
Return just the code without any explanations, and not enclosed in markdown.
You can add inline comments if necessary.`,
],
["human", "Generate code for the following use case: {problem}"],
]);
// Example of composing Runnables with pipe
const chain = promptTemplate.pipe(llm).pipe(new StringOutputParser());
// Execute the chain
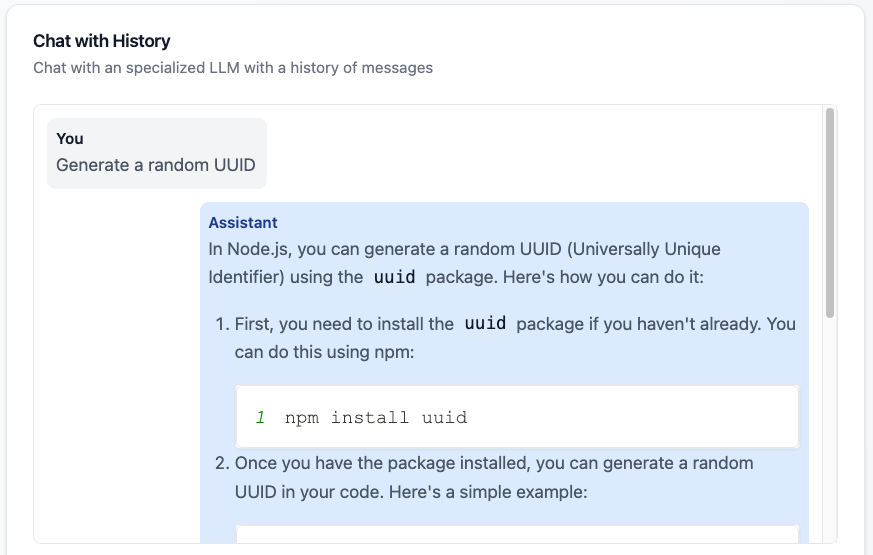
const result = await chain.invoke({ language: "Python", problem: "Reverse a string" });Stateless or Stateful (memory-enabled)
Useful for assistants, support bots, simple UX
const chain = prompt.pipe(llm).pipe(new StringOutputParser());
// Create an in-memory store for the chat history
const messageHistory = new ChatMessageHistory();
// Create a runnable with the chain and the chat history
const chainWithHistory = new RunnableWithMessageHistory({
runnable: chain,
getMessageHistory: () => messageHistory,
inputMessagesKey: "message",
historyMessagesKey: "history",
});
Single prompt → LLM → Response
Embed documents into vector store using an embedding model
Retrieves relevant content
LLM uses context to generate accurate response
Query vectors → Retrieve relevant context → Ground prompt
Can mantain memory, make decisions, and use tools
Useful for automation, APIs, multi-step reasoning
// Create a tool to query Wikipedia
const wikipediaTool = new WikipediaQueryRun({...});
// Create a custom tool
const weatherTool = new DynamicTool({...});
// // Create a list of tools
const tools = [weatherTool, wikipediaTool];
// // Create an agent with the LLM, tools, and prompt
const agent = createToolCallingAgent({
llm,
tools,
prompt,
});
// Create an agent executor with the agent and tools
const executor = new AgentExecutor({
agent,
tools,
});LLM plans → selects tools → executes → repeats
Single agents, even powerful ones, struggle with complex, multi-domain tasks. A single context can become overloaded with too many tools and instructions.
MAS employs a 'divide and conquer' strategy, assigning sub-tasks to specialized agents. This improves modularity, specialization, scalability, and fault tolerance.
Source: LangGraph documentation
| Patterns | Example | Description |
|---|---|---|
| Chat + RAG | Smart FAQ Assistant | Conversational UI with grounded answers from documents |
| Agent + RAG | Context-Rich Research Assistant | Retrieves and reasons over documents step by step |
| Agent + Planning + APIs | Autonomous Task Runner | Executes plans using external tools and APIs |
| RAG + Tool Use | Data-Aware Agent | Fetches docs and uses tools for real-time data |
| Agent + Planning | Task Executor | Breaks tasks into steps and completes them with tools |
| Chat + Agent + Tools | AI Concierge | Conversational system that plans, books, and responds with tools |
| Function Calling + Planner | DevOps Agent | Plans and calls structured DevOps functions |
Latency: RAG, tool use, multi-step and multi-agent workflows can slow response times
Security: Agentic systems introduce new attack surfaces. Developers must be aware of the OWASP Top 10 for LLMs
Prompt Injection: A successful injection attack on one agent could cause it to deceive another agent in the system, leading to cascading failures. Input and output sanitization must be implemented at each agent node
Cost Management: Autonomous, multi-step agents can lead to unpredictable and escalating LLM costs
Evaluation Complexity: Measuring factuality, reasoning, and safety isn't straightforward.
Model Limits: Context window size, token cost, and hallucinations affect reliability
Fast-Moving Ecosystem: Tools, models, and APIs evolve quickly. Stability and long-term support can be uncertain
Orchestration is the Core Task: The power of modern AI applications lies not in the LLM alone, but in how you orchestrate the interactions between LLMs, tools, data, and other agents.
Think in Architectures, Not Just Patterns: Move beyond building single agents. Choose the right multi-agent architecture (e.g., Supervisor, Hierarchical) that matches the complexity of your use case.
Embrace the Protocol Layer: Standardized protocols like MCP (for tools) and A2A (for inter-agent collaboration) are the future of interoperable AI. Design systems with these standards in mind.
Evaluate, Monitor, Secure: Production agentic systems are not 'fire-and-forget.' They demand a rigorous, continuous process of evaluation, deep observability (with tools like LangSmith), and proactive security management.
Node.js is Production-Ready for Agents: With LangChain.js and LangGraph.js, the Node.js ecosystem has the robust, stateful orchestration capabilities required for building and deploying complex agentic systems.
Always Bet on JS
Brendan Eich
sforce.co/build-ai-apps-heroku
build-ai-apps.ukoreh.com
By Julián Duque




