以 gensim 實現 Word2Vec
講者: 王婕瑜
日期: 2020/11/29
OUTLINE
- Word2Vec 簡介
- 實作
- Reference
Word2Vec 簡介
Why Word2Vec?
文字型態的資料難以運算
將文字轉換成向量
Python 的 Gensim 實現
Word2Vec
- Word to vector
- Google 於 2013 年提出
- 將字詞用向量的方式代表語意
計算方式
CBOW (Continuous Bag of Words)
給定上下文,來預測輸入的字詞
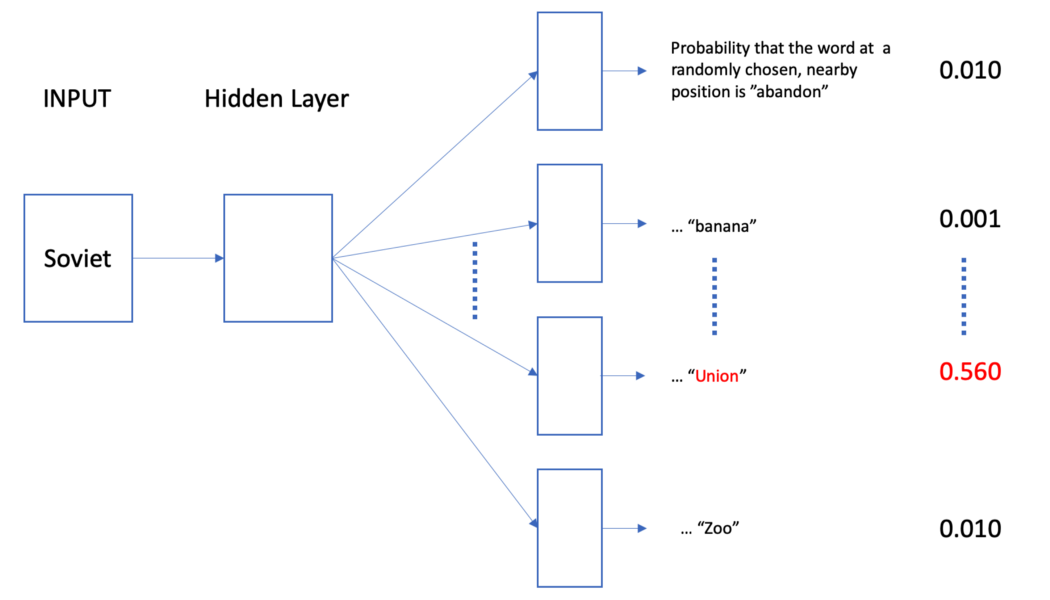
Skip-gram
給定輸入字詞後,來預測上下文
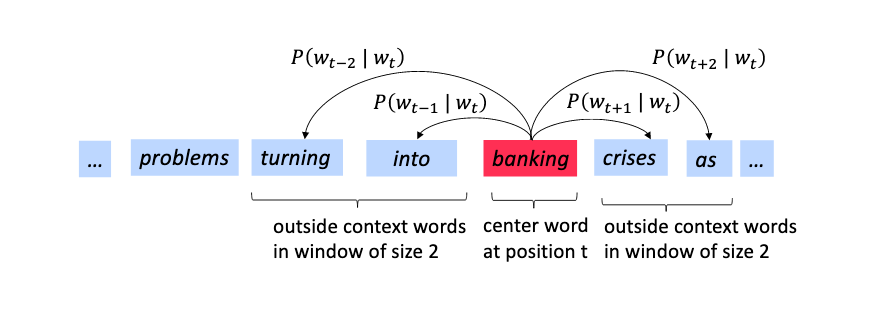
Skip-gram
實作
流程說明
- 資料準備
- 函式庫安裝
- 分詞
- 訓練模型
資料準備
import logging
import sys
from gensim.corpora import WikiCorpus
def main():
if len(sys.argv) != 2:
print("Usage: python " + sys.argv[0] + " wiki_data_path")
exit()
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
wiki_corpus = WikiCorpus(sys.argv[1], dictionary={})
text_num = 0
with open("wiki_texts.txt", 'w', encoding='utf-8') as output:
for text in wiki_corpus.get_texts():
output.write(' '.join(text) + '\n')
text_num += 1
#如果要抓完整的不用加
if text_num == 1000:
break
if text_num % 10000 == 0:
logging.info("已處理 %d 篇文章" % text_num)
if __name__ == "__main__":
main()將 xml 的 wiki 資料轉化成 text 格式
挑選以 pages-articles.xml.bz2 結尾的備份
pip install gensim函式庫安裝
分詞
使用 jieba 進行中文分詞
pip install jiebapip install opencc-python-reimplemented簡體轉繁體 (OpenCC)
# coding: utf-8
import jieba
from opencc import OpenCC
# Initial
cc = OpenCC('s2t')
# Tokenize
with open('wiki_text_seg.txt', 'w', encoding='utf-8') as new_f:
with open('wiki_texts.txt', 'r', encoding='utf-8') as f:
for times, data in enumerate(f, 1):
print('data num:', times)
data = cc.convert(data)
data = jieba.cut(data)
data = [word for word in data if word != ' ']
data = ' '.join(data)
new_f.write(data)訓練模型
from gensim.models import word2vec
# Settings
seed = 666 #亂數種子
sg = 0 #CBOW
window_size = 10 #周圍詞彙要看多少範圍
vector_size = 300 #轉成向量的維度
min_count = 50 #詞頻少於 min_count 則不會參與訓練
workers = 8 #訓練的並行數量
epochs = 5 #訓練的迭代次數
batch_words = 10000 #每次給予多少詞彙量訓練#接續上面的settinig
#可以加上limit限制數量
train_data = word2vec.LineSentence('wiki_text_seg.txt')
model = word2vec.Word2Vec(
train_data,
min_count=min_count,
size=vector_size,
workers=workers,
iter=epochs,
window=window_size,
sg=sg,
seed=seed,
batch_words=batch_words,
)
model.save('word2vec.model')
print("done")測試
from gensim.models import word2vec
model = word2vec.Word2Vec.load('word2vec.model')
print(model['生物'].shape)
for item in model.most_similar('生物'):
print(item)Reference
- Clay (2020). 在 Python 中使用 Gensim 將文字轉成向量. Retrieved from: https://bit.ly/3lkjUne
- Kai Chou Yang (2016). 以 gensim 訓練中文詞向量. Retrieved from: https://bit.ly/379njA2
Thanks for listening.
以 gensim 實現 Word2Vec
By juliewah
以 gensim 實現 Word2Vec
SIRLA 109-1 This 15 Speech



