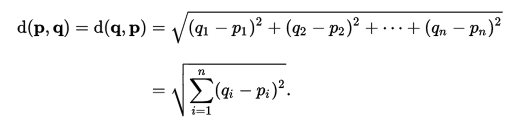

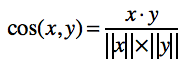

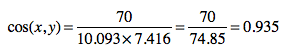

Jung Han
맨날 공부중
강추조
이강호(14), 한정(11)
> 사용자 혹은 상품의 내용을 이용
ex> 아이언맨(마블, 미국, 히어로물 등등..)
> 사용자의 평가 내용을 이용
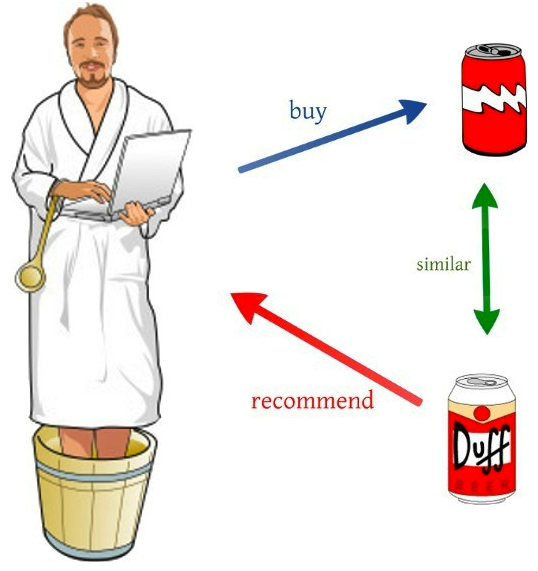
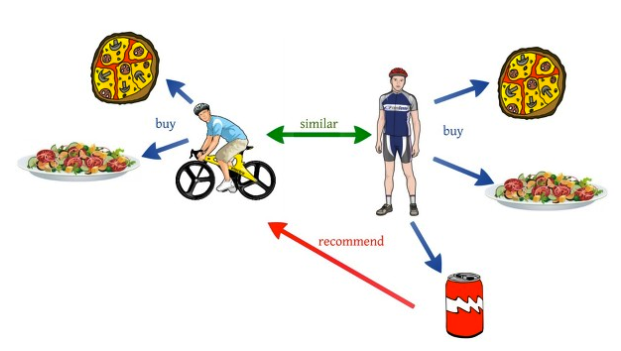
> User-based : 비슷한 사용자를 찾는다.
> Item-based : 비슷한 아이템을 찾는다.
과거 입력해 놓은 아이템을 기반으로 미래 아이템을 예측
> 적은 정보만으로 만족도 높은 추천을 나타낸다.
> 모델링 방식에 따라 추천의 정확도가 크게 달라진다.
> 비슷한 아이템끼리 추천을 하게 되는 단점이 있다.
> 데이터가 많아질 수록 높은 만족도를 나타낸다.
> 데이터가 적을 경우 Cold start가 있다.
1. Content-based에서 추천해줄 Item을 어떻게 모델링 하느냐에 따라
추천의 질이 크게 달라 지는데 개인의 임의대로 카테고리를 나눠 분석하는 것이 만족성이 높은 추천을 하기 어려울 것 이라 생각
2. 4학년 학생이 들은 과목은 많아야 35~40개 내외. 많아야 40개의 점수를
사용자들이 입력하는데 크게 어려움이 없을 것이라 예상
+ 졸업자들의 데이터가 강력하게 사용 될 수 있을 것이라 생각.(빠른수집또한 가능)
+ 빠른 완성후 데이터를 충분히 수집할 수 있을것이라 자신감을 가졌었음
3. Content-based를 사용했을 때 결과 예측이 쉬웠다. 실제로 이 프로그램을
사용했을 때 만족도 있는 추천을 할 지 궁금했다.
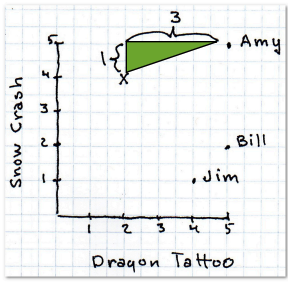
> missing value가 없을 때 유리함
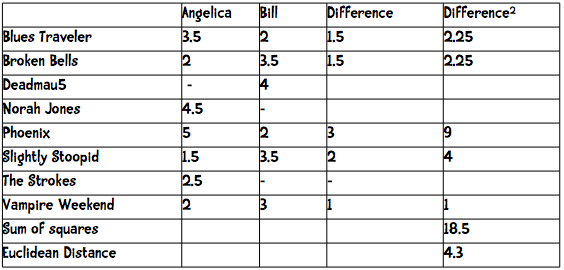
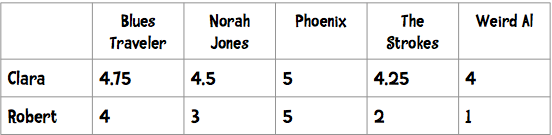
> Pearson은 grade-inflation 이 있는 곳에 적합하다.
> 가장 많이 Collaborative filtering에서 사용하는 방식
> 데이터가 sparse하게 퍼져 있을 때 유리
> 현재 사이트에서 유사도 측정 방법으로 사용
25일 현재
1번
2번
3번
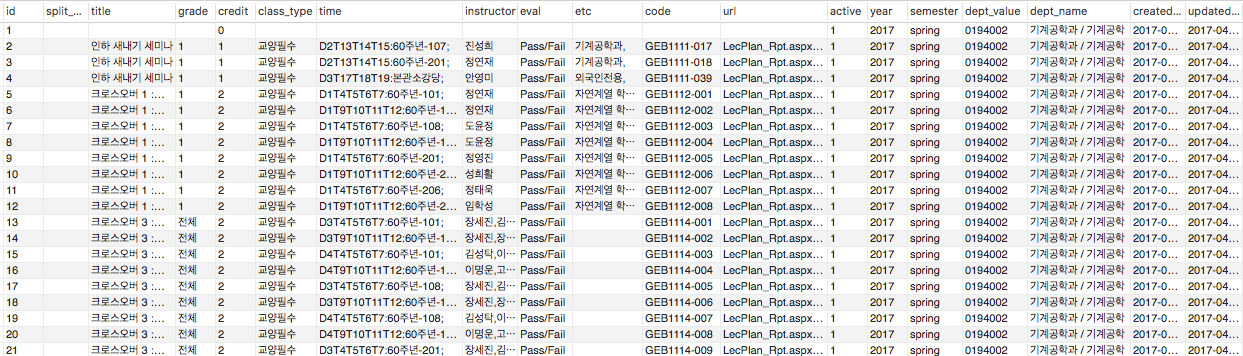
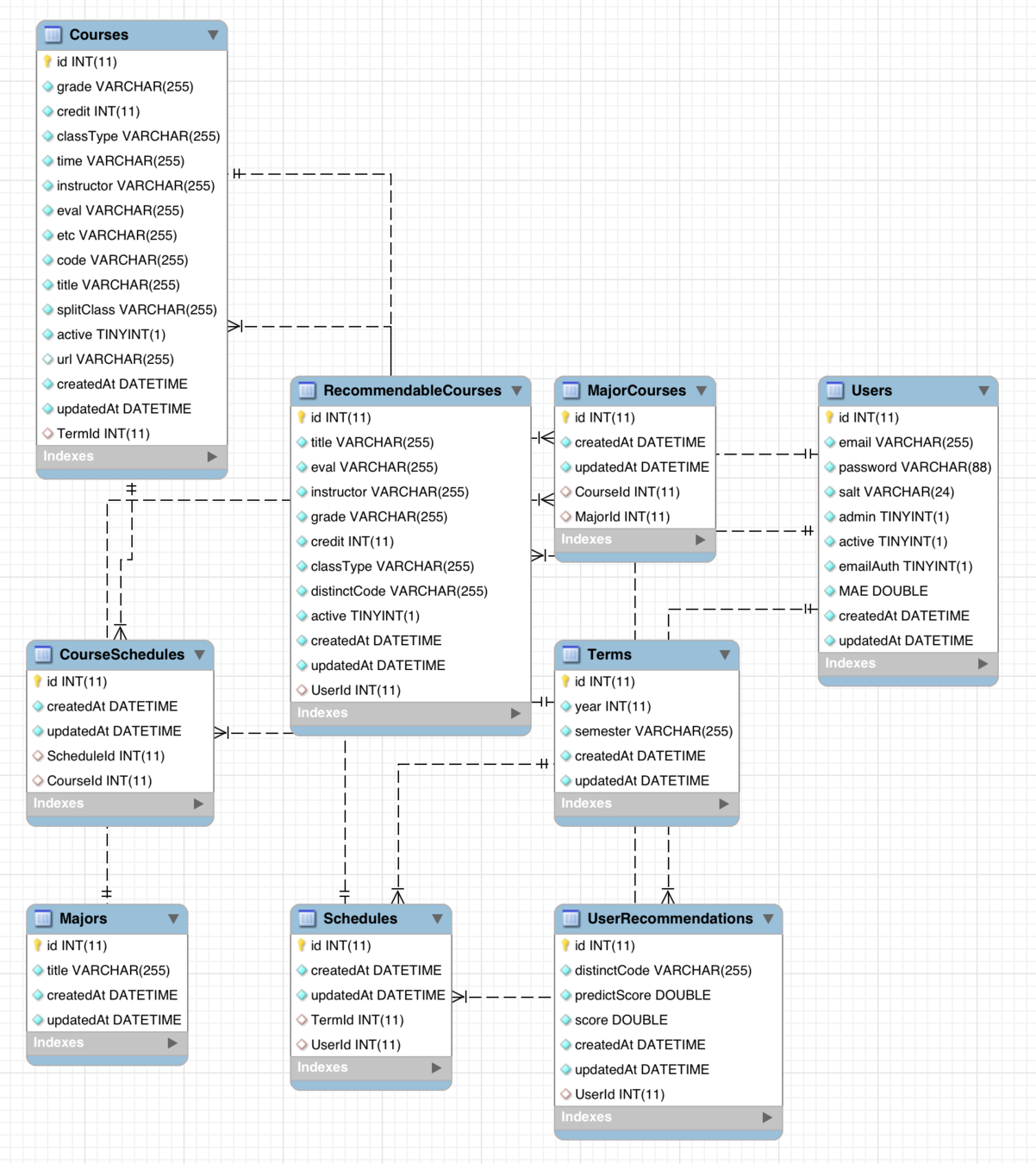
현재는 계속해서 데이터를 쓸 수 있게 테이블을 만들고 가공중에 있습니다.
By Jung Han




