Swin-Transformer
講師 Eating
- 啥都學一點
- React 熱愛
- vibe coding 中度使用者(?

目錄
- Transformer 概述
- Self-attention 概述
- Vision-Transformer 概述
- Swin Transformer 關鍵 Solution
Transformer 概述
Transformer 模型最初被用來做自然語言處理,他透過自注意力的機制取代傳統的 RNN 實現上下文接龍
自然語言處理 NLP
自然語言處理 (NLP) 是一種機器學習技術,讓電腦能夠解譯、操縱及理解人類語言。
1. 能夠理解同一 詞彙在不同上下文的不同意思
2. 能夠以人類一般說話的方式輸入輸出資訊
實現的方法大部分都是透過
1. 透過高維向量編碼實現以單詞為單位的向關性
2. 透過神經網路實現整個句子的上下文關係理解
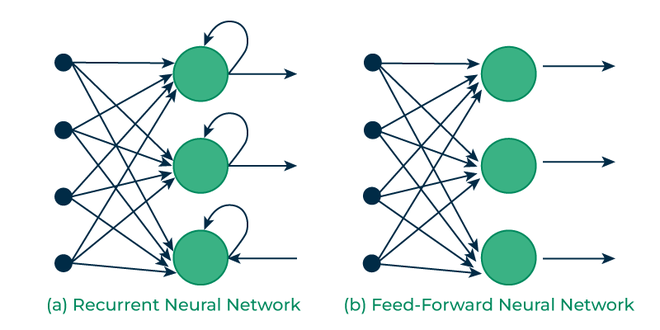
遞歸神經網路 RNN
RNN 會把同一層針對前一個字以及前前個字前前前個字處理的結果一起當作輸入處理當前的字,當然越久之前的權重就越小。
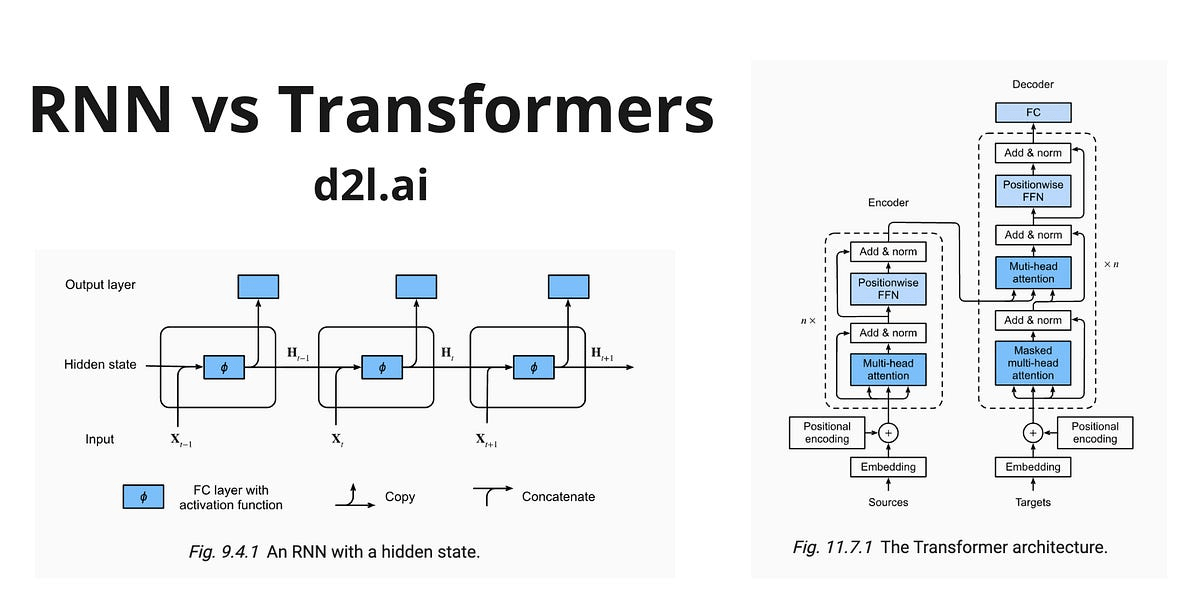
Transformer 概述
自注意力的機制可以想成在把每個字丟進神經網路前就先用另一個方法算出他和前面幾個字的關係,讓神經網路可以直接考慮,可以並行計算。
Self-attention 概述
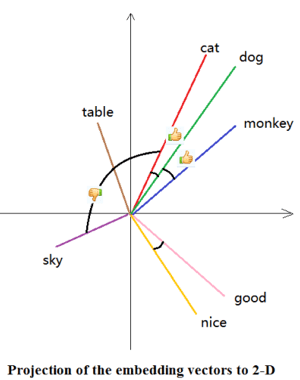
Self-attention 就是把每個字針對其餘的字做一些數學運算(例如dot-product 在向量的空間下可以計算出他們的相關性)
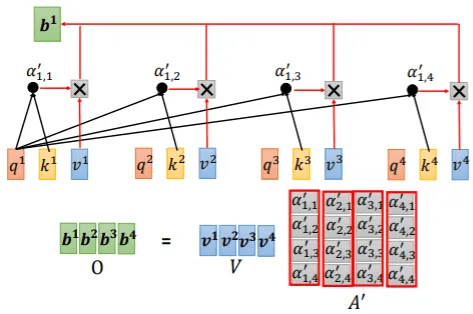
Self-attention 概述
但你可以看到它的複雜度看起來就很高是 <math xmlns="http://www.w3.org/1998/Math/MathML"><semantics><mrow><mi>O</mi><mo stretchy="false">(</mo><msup><mi>n</mi><mn>2</mn></msup><mo stretchy="false">)</mo></mrow><annotation encoding="application/x-tex">O(n^2)</annotation></semantics></math>是
n 是序列的長度
O(n^2)
Vision-Transformer 概述
Vision-Transformer 就是想要讓 Transformer 可以來處理圖片,用了下面這些方法。
- Patch Partition
- Linear Embedding
- Position Encoding
- Transformer
Patch Partition
Patch Partition:將輸入圖像分割為固定大小的 Patch(例如 16x16 像素),每個 Patch 被展平為一維向量。

Linear Embedding
Linear Embedding:將 Patch 向量通過線性層映射到固定維度,作為 Transformer 的輸入。
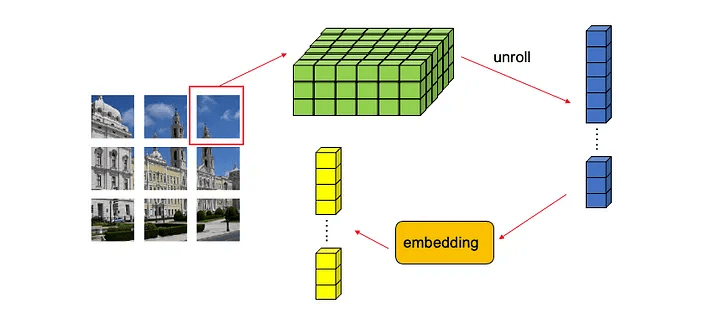
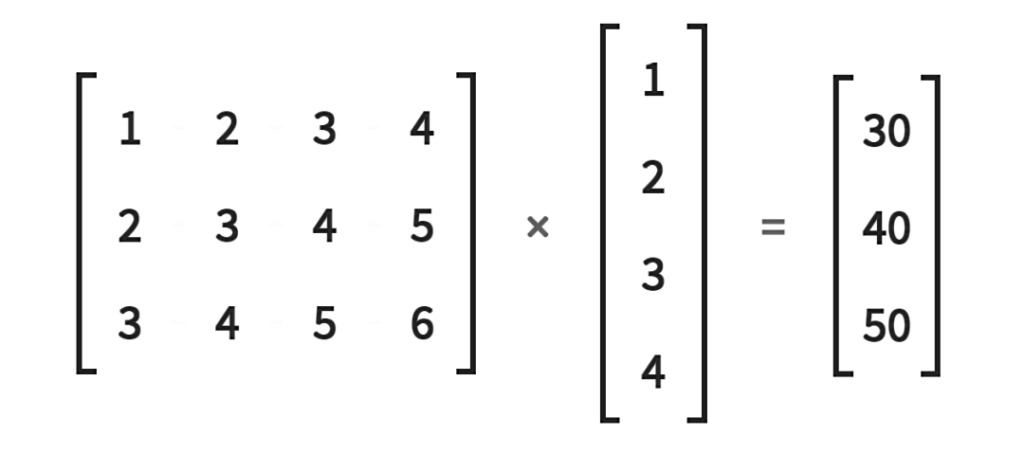
可以感性理解一下他就是3維的矩陣乘法
透過特定大小的矩陣讓他維度變高
就有點像自然語言處理一樣把單字轉成高維向量
但最後會把它攤平因為要丟到神經網路裡面
Position Encoding
Position Encoding:添加可學習的位置嵌入,保留 Patch 的空間資訊。

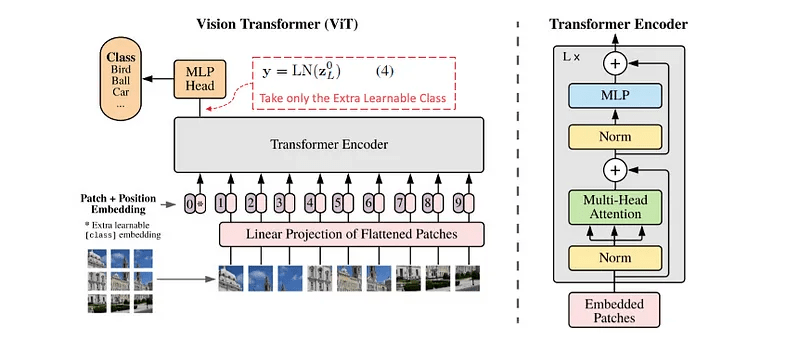
那個0號的是 class token ,可以想像成空白的向量,之後被丟到Transformer 時會因為自注意力公平的取得到其他圖塊的資訊,所以能代表圖片整體。會用在分類任務中。
Transformer 會針對每個輸入輸出對應的值(並行處理)分類任務時就可以看模型針對 class token 的輸出就好。
Transformer
Transformer 處理:將 Patch 序列輸入標準 Transformer,通過多層自注意力層和前饋神經網絡(MLP)進行處理。但圖片一變大他計算量就會爆掉
Swin Transformer 關鍵 Solution
Swin Transformer 的設計目標:
解決 ViT 的計算複雜度問題,使其適用於高分辨率圖像和密集預測任務。
模擬 CNN 的層次化特徵提取能力,生成多尺度特徵圖。
核心創新:
- 層次化架構(Hierarchical Architecture)
- 基於窗口的自注意力(Window-based Self-Attention, W-MSA)
- 移位窗口(Shifted Window, SW-MSA)
層次化架構Hierarchical Architecture
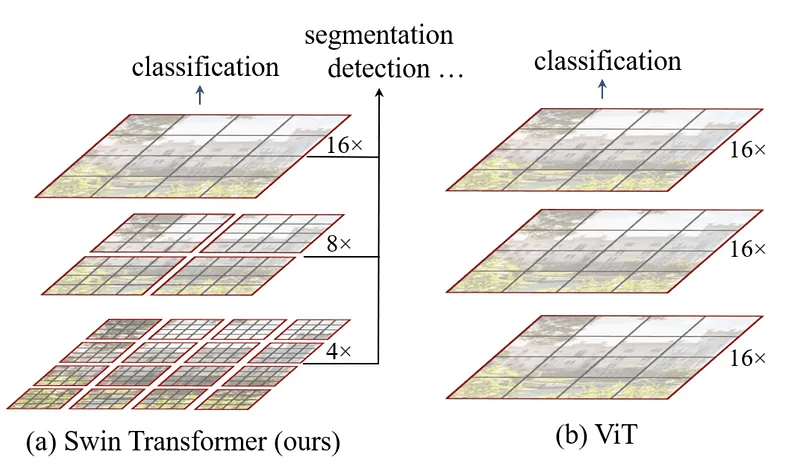
從 CNN 那邊偷過來的。可以看到他會把圖片拆成更小的小圖片,提高精度。
本來是用16個像量代表16*16的區塊,後來變成1個向量去代表那個區塊。
這個是CNN的架構
Patch Merging
他把圖片弄小不是單純裁切是這樣子把周圍的圖片切下來然後做線性變換
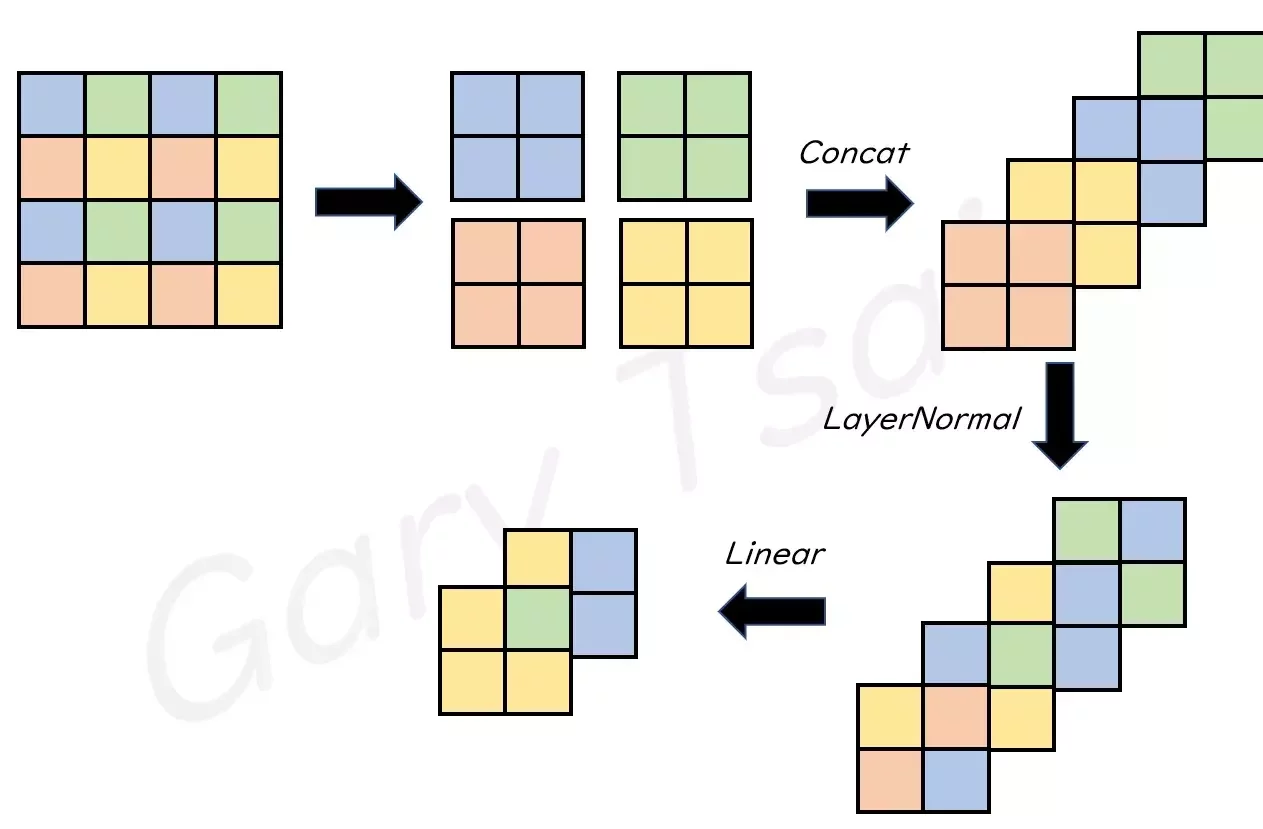
所以說隨著時間進行,會有越來越多向量被合併,模型會轉而根據過去濃縮的資訊來提取整體的訊息
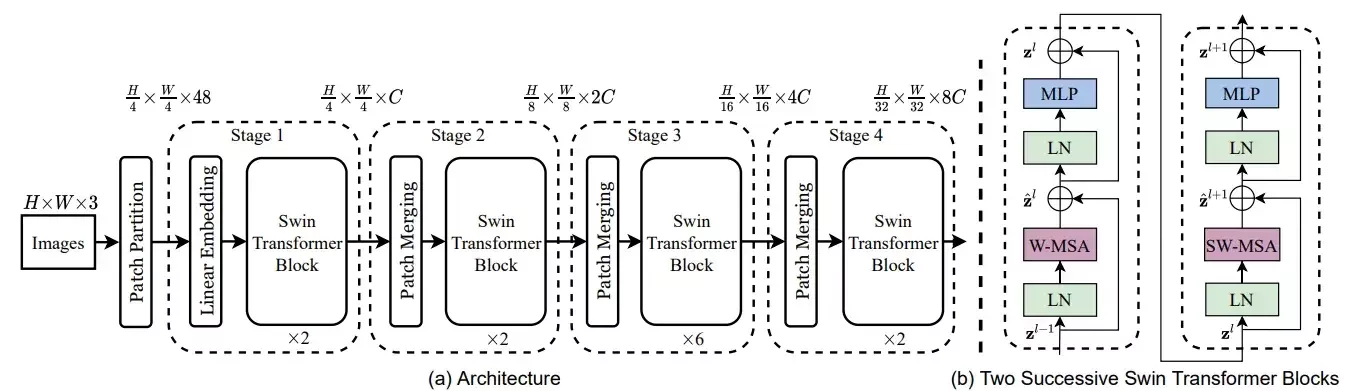
窗口自注意力 Window-based Self-Attention
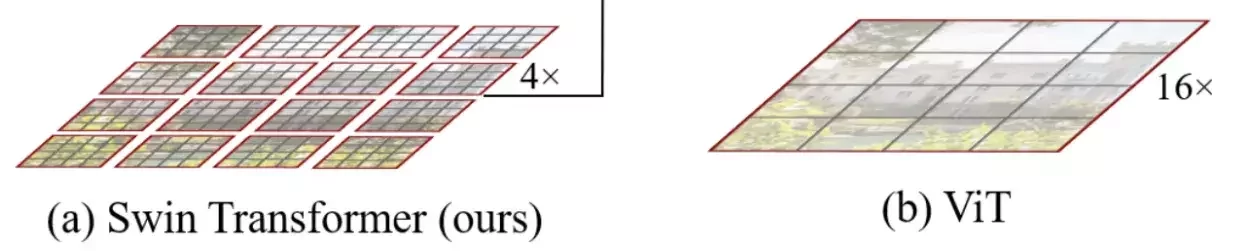
舉例來說本來切成一塊一塊16*16下去做自注意力,複雜度是
O\left(\left(\frac{WH}{16 ^2}\right)^2\right)
現在切成4*4的小塊,每16個自己做一次自注意力,複雜度是
O\left(\left(\frac{WH}{16 ^2}\right)\times 16^2 \right)=O({WH})
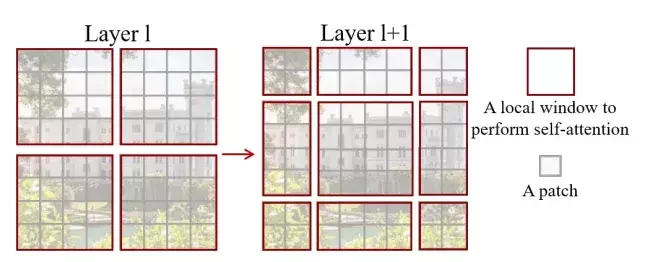
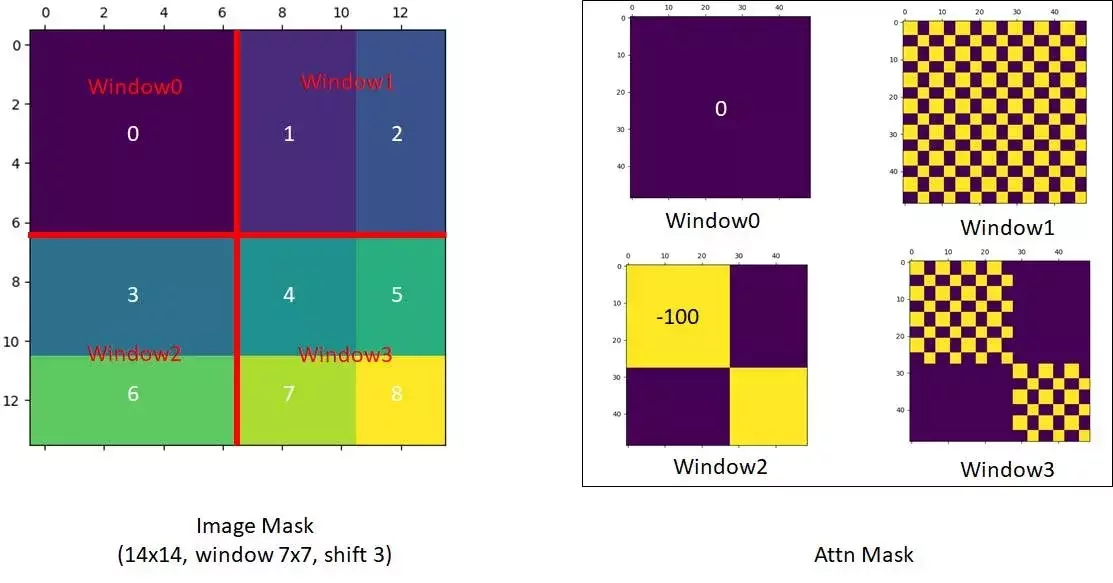
移位窗口Shifted Window
剛剛那樣暴力切會讓不同窗口之間的資訊完全無法共享,所以換另一種切法將剛剛被分割的部分弄到同一塊裡面,但這樣變成九塊所以作者把左上的東西移動到右下角。
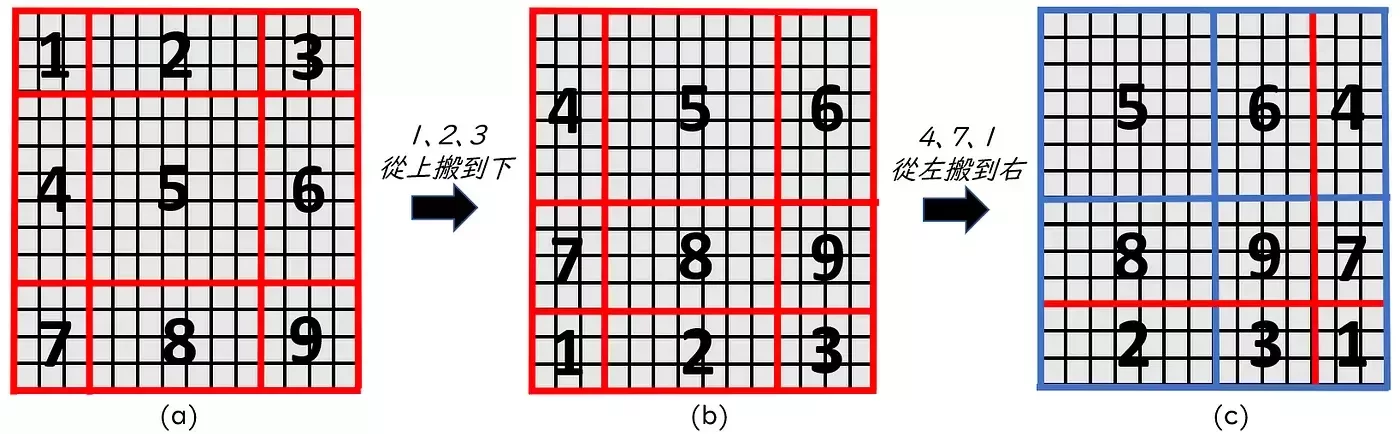
移位窗口Shifted Window
但這樣會出現天空被移動到地面的情況,所以作者決定在自注意力計算時將本來不相連的部分去除。還記得自注意力就是每一個人都對其他人做運算,所以可以用一個方形的表格表示。
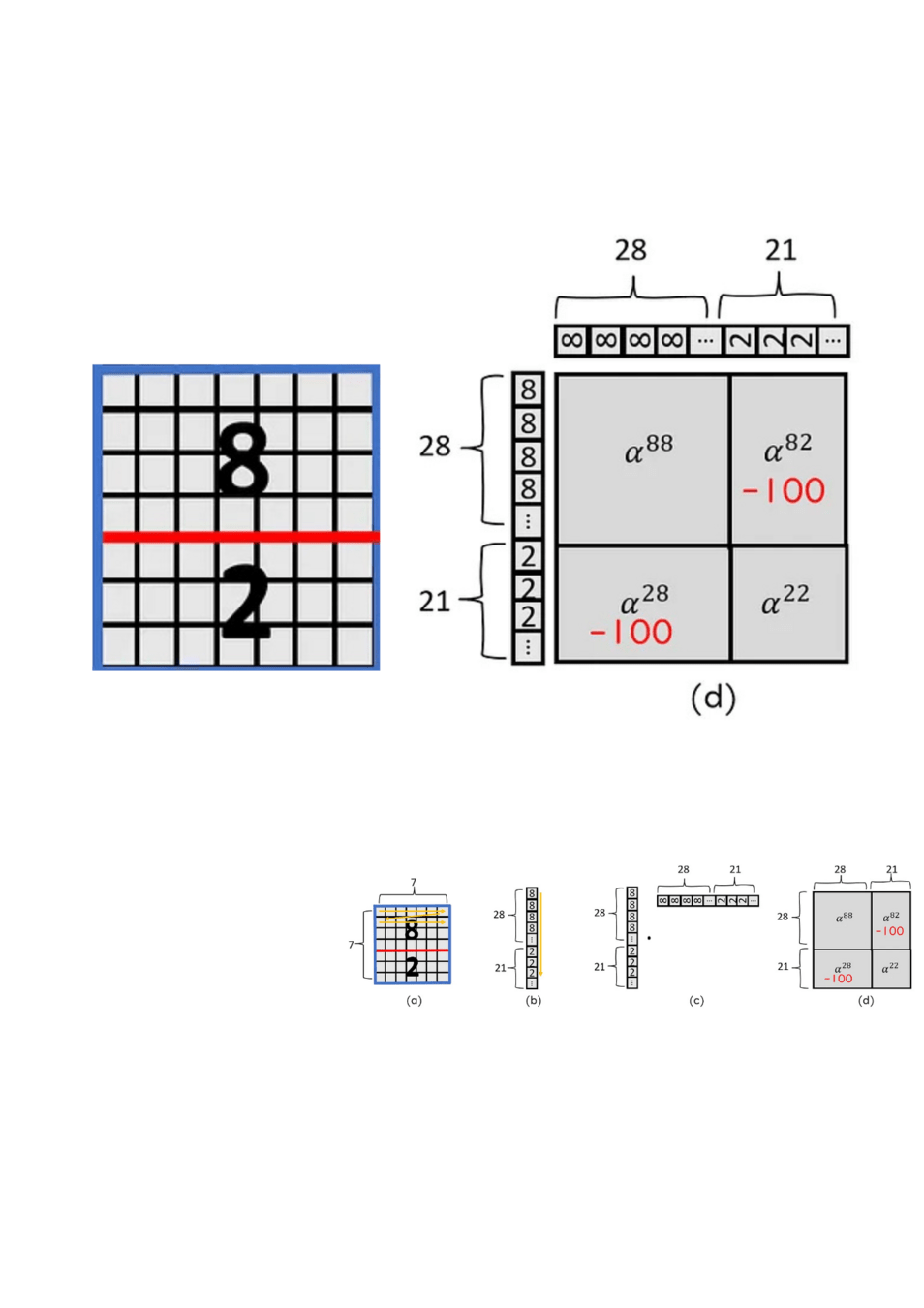
如右圖,將本來屬於不同塊的8和2相乘的部分扣掉 100 後續經過激活函數他就變成 0 了
移位窗口Shifted Window
上圖是原作者用的遮罩,黃色部分是需要扣除的。
deck
By 翊庭jx06 T


