how
browser
work
(上)
目录
- 简介
- 渲染引擎
- 解析与DOM树的构建
简介
- 主流浏览器
- 浏览器的主要功能
- 浏览器的主要构成
主流浏览器

浏览器的主要功能
1. 展示用户选择的web资源
- 格式包括HTML/PDF/IMG等等
- 由URI来定位资源位置

浏览器的主要功能
2. 基于浏览器的用户界面元素
-
用来输入URI的地址栏
-
前进后退按钮
-
书签选项
-
用于刷新及暂停当前加载文档的刷新、暂停按钮
-
用来到达主页的按钮
浏览器的主要构成

渲染引擎
- 简介
- 渲染的主要流程
- 渲染流程实例
简介
-
渲染,即是把请求的内容显示在浏览器的窗口中
-
渲染引擎可以显示html、xml文档及图片,它也可以借助插件(一种浏览器扩展)显示其他类型数据
渲染的主要流程
解析html以构建dom树 -> 构建render树 -> 布局render树 -> 绘制render树

-
渲染引擎首先通过网络获得所请求文档的内容,通常以8K分块的方式完成
-
下面是渲染引擎在取得内容之后的基本流程:

Figure: Webkit Main Flow

Figure: Gecko Main Flow
解析和DOM树的构建
- 基本概念
- 解析
- DOM 树的构建
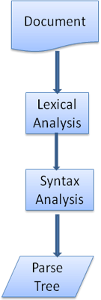
Parsing-general(解析)
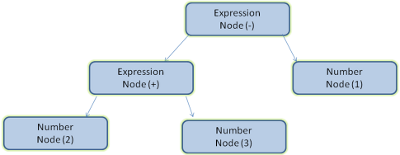
Figure: mathematical expression tree node
- 解析一个文档即将其转换为具有一定意义的结构——编码可以理解和使用的东西
- 解析的结果通常是表达文档结构的节点树,称为解析树或语法树
Grammars(文法)
-
解析基于文档依据的语法规则——文档的语言或格式
-
每种可被解析的格式必须具有由词汇及语法规则组成的特定的文法,称为上下文无关文法context free grammar
-
W3C组织制定规范定义了HTML的词汇表和语法,
Parser-Lexer combination(解析器-词法分析器)
-
词法分析 就是将输入分解为符号,符号是语言的词汇表——基本有效单元的集合
-
语法分析 指对语言应用语法规则
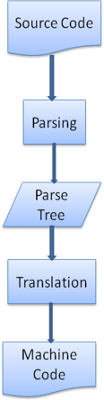
Translation(翻译)
-
解析一般在翻译中使用——将输入文档转换为另一种格式
Parsing example(解析实例2+3-1)
词汇:我们用的语言可包括证书、加号和减号
语法:
-
构成语言的语法单位是表达式、项和运算符
-
我们用的语言可以包含任意数量的表达式
- 表达式的定义是:一个“项”接一个“运算符”,然后再接一个“项”
-
运算符是加号或减号
- 项是一个整数或一个表达式
DOM
-
输出的树,也就是解析树,是由DOM元素及属性节点组成的
-
DOM是文档对象模型的缩写,它是html文档的对象表示,作为html元素的外部接口供js等调用
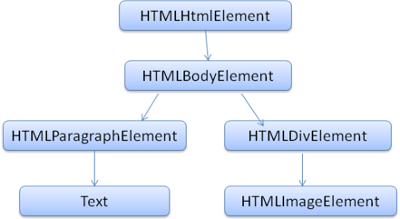
DOM
<html>
<body>
<p>
Hello!
</p>
<div>
<img src="example.png"/>
</div>
</body>
</html>
-
DOM和标签基本是一一对应的关系
The parsing algorithm(解析器算法)
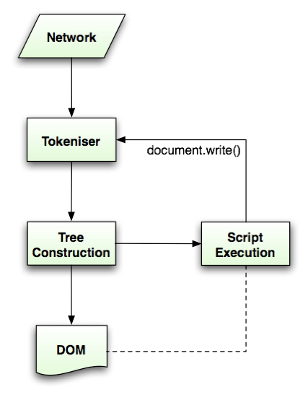
-
符号化
-
输⼊解析为符号
-
开始结束标签
-
属性名,属性值
-
构建树
-
符号识别器
-
树构建器
- 输⼊解析为符号
- 开始结束标签
- 属性名,属性值
- 符号识别器
- 树构建器
The tokenization algorithm (符号识别算法)

Parsing algorithm
(树的构建算法)
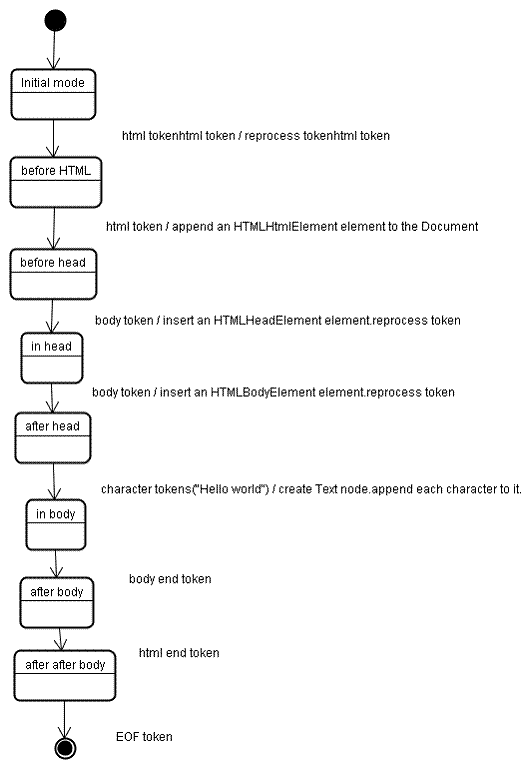
<html>
<body>
Hello world!
</body>
</html>
CSS解析
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
词法语法(词汇)是针对各个标记用正则表达式定义的
CSS解析
<symbol> ::= __expression__example: FOR_STATEMENT ::= "for" "(" ( variable_declaration | ( expression ";" ) | ";" ) [ expression ] ";" [ expression ] ";" ")" statement
语法是采用 BNF(Backus-Naur Form)格式描述的
1. 在双引号中的字("word")代表着这些字符本身2.double_quote用来代表双引号
3.在双引号外的字代表着语法部分
4.尖括号( < > )内包含为必选项。
5.方括号( [ ] )内包含为可选项
6.大括号( { } )内包含为可重复0至无数次的项
7.竖线( | )表示在其左右两边任选一项,相当于"OR"
8.::= 是“被定义为”
CSS解析
ruleset : selector [ ',' S* selector ]* '{' S* declaration [ ';' S* declaration ]* '}' S* ; selector : simple_selector [ combinator selector | S+ [ combinator? selector ]? ]? ;simple_selector : element_name [ HASH | class | attrib | pseudo ]* | [ HASH | class | attrib | pseudo ]+ ; class : '.' IDENT ; element_name : IDENT | '*' ; attrib : '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S* [ IDENT | STRING ] S* ] ']' ; pseudo : ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ] ;
CSS解析
div.error , a.error {
color:red;
font-weight:bold;
}
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S* ;
## S表示空格
CSS解析
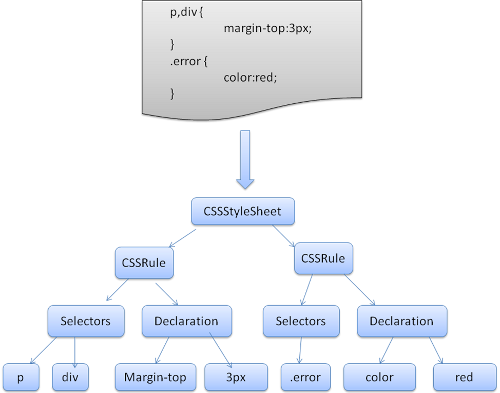
每个css文件解析为样式表对象,每个对象包含css规则,css规则对象包含选择器和声明对象,以及其他一些符合css语法的对象
处理脚本及样式表的顺序
-
脚本(script)
-
默认同步
-
HTML4/HTML5 defer 异步
-
预解析(Speculative parsing)
-
主解析器、预解析器
-
在执行脚本时,其他线程会解析文档的其余部分
-
找出并加载需要通过网络加载的其他资源
-
样式表(Style sheets)
-
Firefox 在样式表加载和解析的过程中,会禁止所有脚本
-
仅当脚本尝试访问的样式属性可能受尚未加载的样式表影响时
-
它才会禁止该脚本
- 默认同步
- HTML4/HTML5 defer 异步
- 主解析器、预解析器
- 在执行脚本时,其他线程会解析文档的其余部分
- 找出并加载需要通过网络加载的其他资源
- Firefox 在样式表加载和解析的过程中,会禁止所有脚本
- 仅当脚本尝试访问的样式属性可能受尚未加载的样式表影响时
-
它才会禁止该脚本
end
how-browser-work
By kangxiaojun
how-browser-work
test



