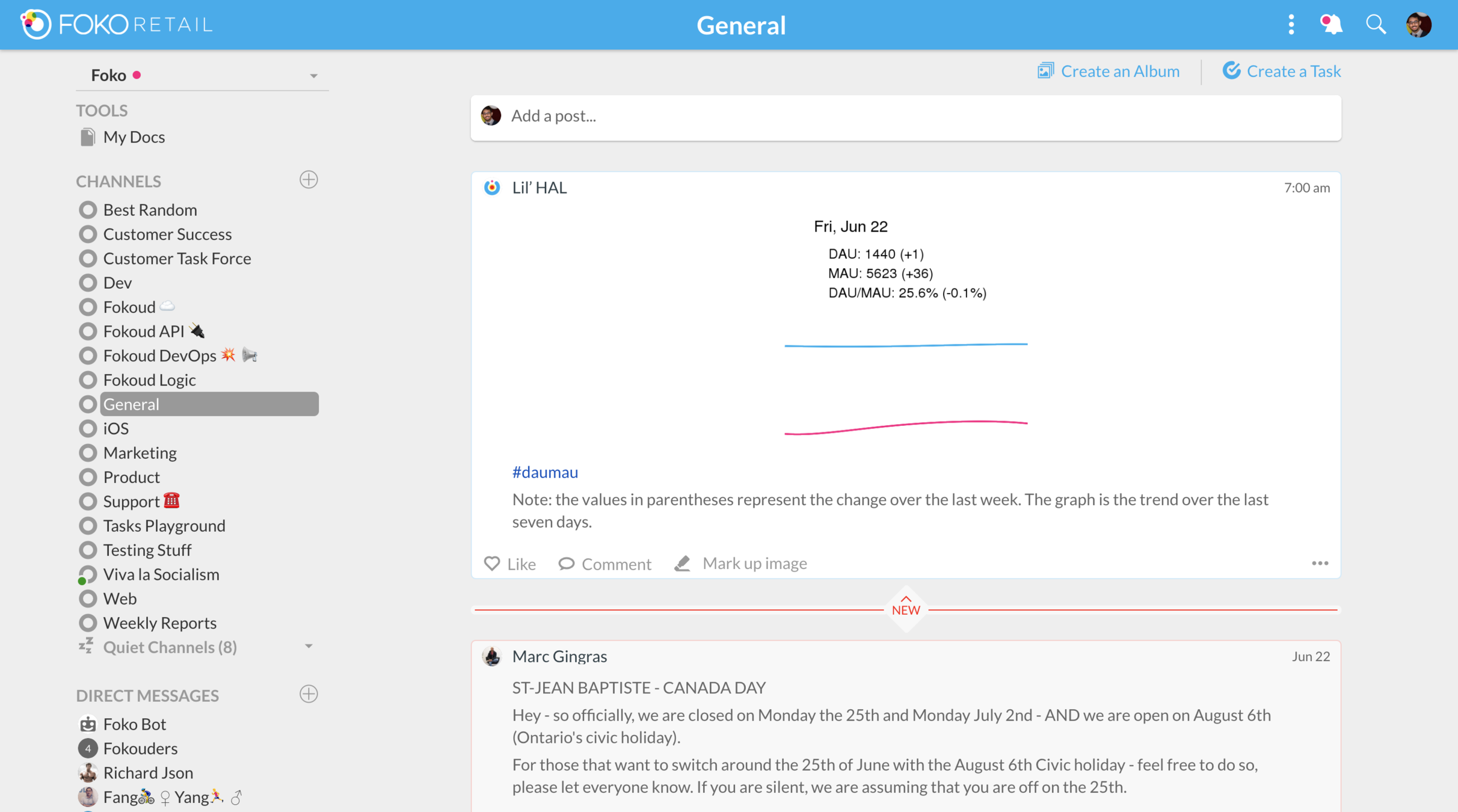
Building More Resilient Applications
Karim Alibhai
github.com/karimsa | npm install karimsa

I will drastically oversimplify some things!
DISCLAIMER:
Delivering the art & science of retail execution
Pst! We're hiring @ fokoretail.com
HQ
Observers / Managers
Assignees
Highly async
pipeline
Sub-par handling due to how fast the features were built
800
10
1
* 5 events per assignee = 40 000 events
HQ
Observers / Managers
Assignees
Worked beautifully
Still sub-par
800
800
1
* 5 events per assignee = 3 200 000 events
(80x)
How we think of failures
Problem: Evil butterflies are rare. Stupid butterflies are common.
How do we aim for high availability?
Availability =
Time to Failure
Time to Failure + Time to Recovery
* "Patterns for fault tolerant cloud software" by Robert Hanmer
The CAP Theorem
-
Consistency
-
Availability
-
Partition tolerance
*
* Required for distributed systems.
HTTP blah
blah
Server
Client
Unavoidable network partition
-
Consistency
-
Availability
-
Partition tolerance
*
* Required for distributed systems.
CP System
- Prefers consistency over availability (where possible).
- CAP defines consistency in terms of reads.
- In reality, we design in terms of writes.
- For example:
- Database transactions
- REST APIs (?)
AP System
- Prefers availability over consistency (where possible).
- Key phrase: is eventually consistent.
- For example:
- A `POST` / `PUT` during database downtime is still successful.
- The `User` microservice is down, so the recommender system provides general recommendations.
- Your `ES` cluster is down, so your API uses mongodb / cache.
Considerations
- When mechanics are involved
- When the user is orchestrating
Use AP where possible, otherwise fallback to CP.
Building More Resilient Applications (Part 1)
By Karim Alibhai
Building More Resilient Applications (Part 1)
A story about when all hell breaks loose & lessons learned from it.




