


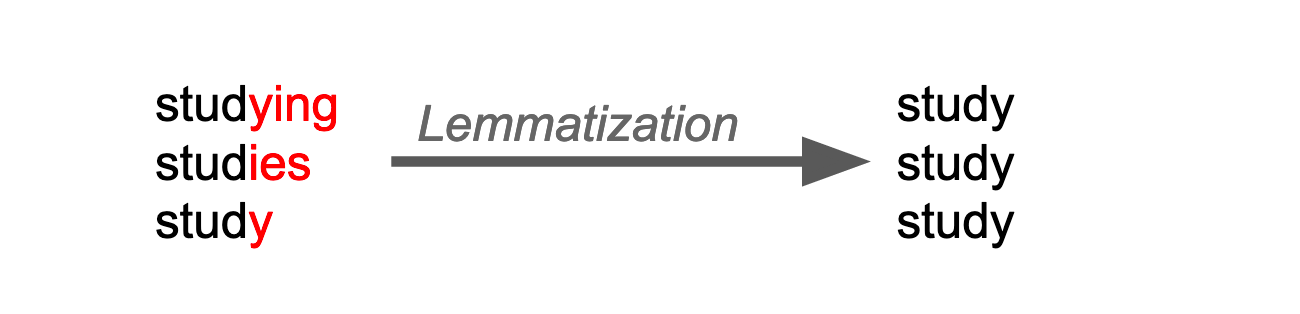










Karl Ho
Data Generation datageneration.io
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
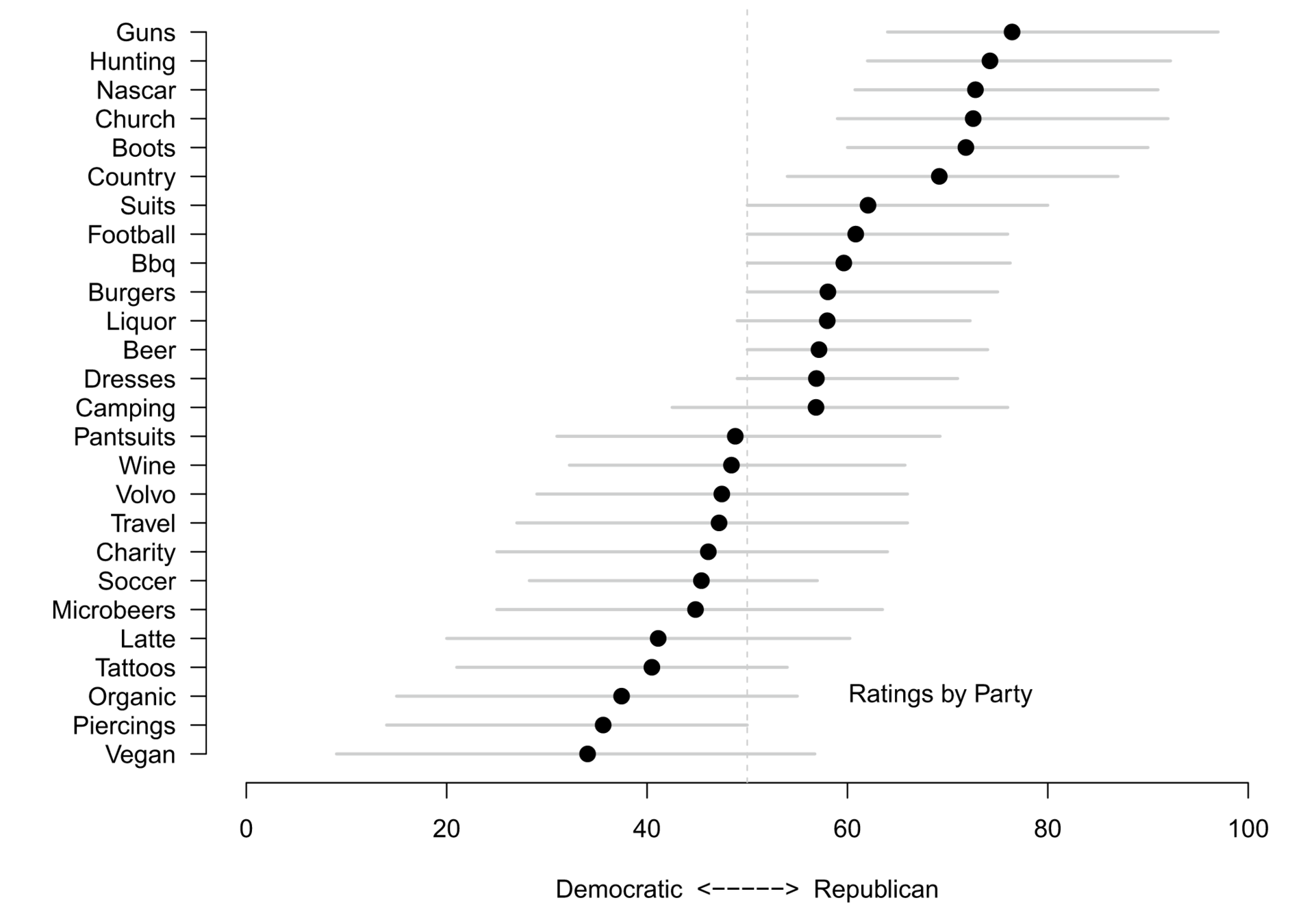
Why is it important?
Source: BusinessWire
Grimmer, Justin, and Brandon M. Stewart. 2013. “Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts.” Political Analysis 21(3): 267–97.
Grimmer, Justin, and Brandon M. Stewart. 2013. “Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts.” Political Analysis 21(3): 267–97.
Grimmer, Justin, and Brandon M. Stewart. 2013. “Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts.” Political Analysis 21(3): 267–97.
Supervised
Unsupervised
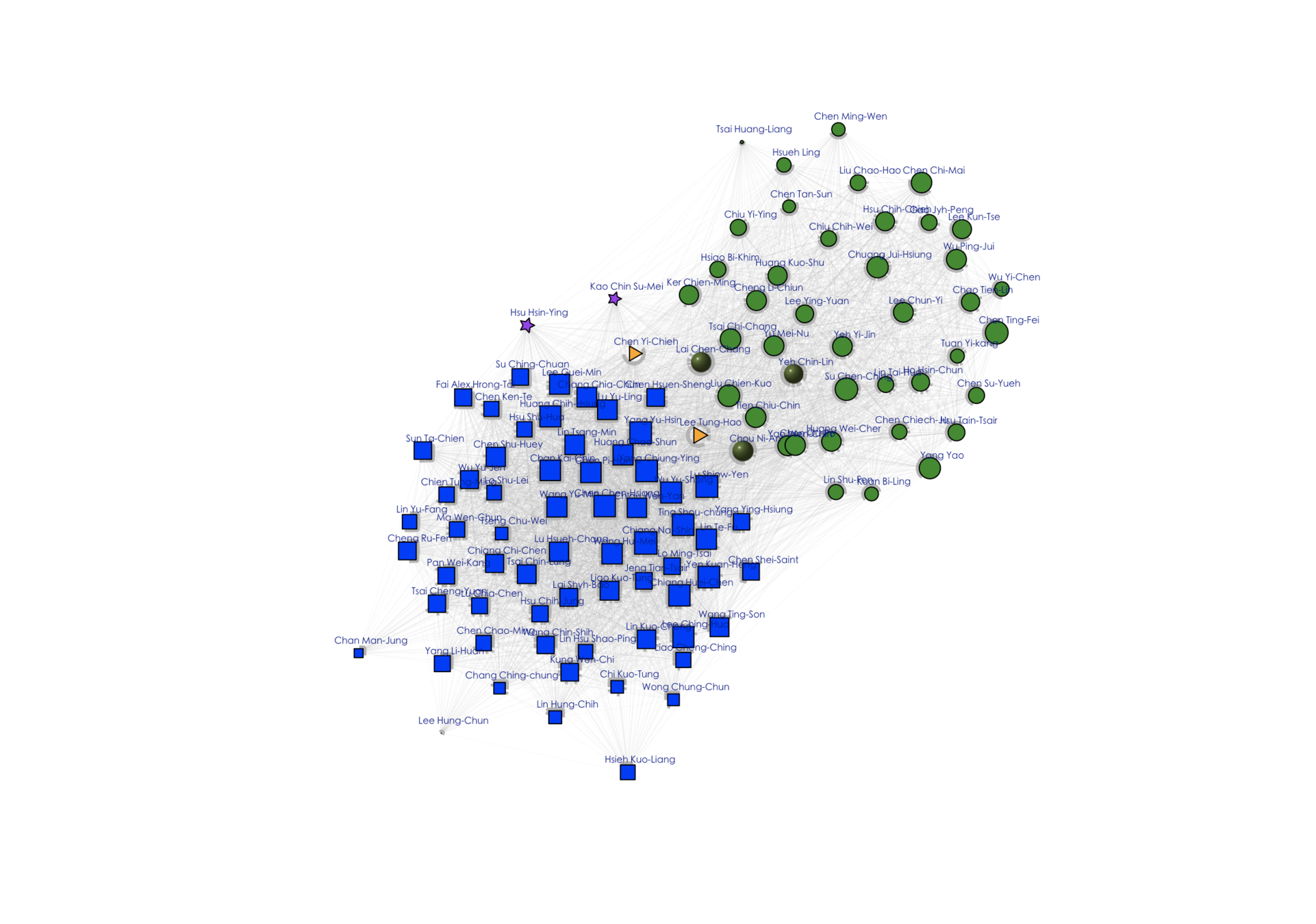
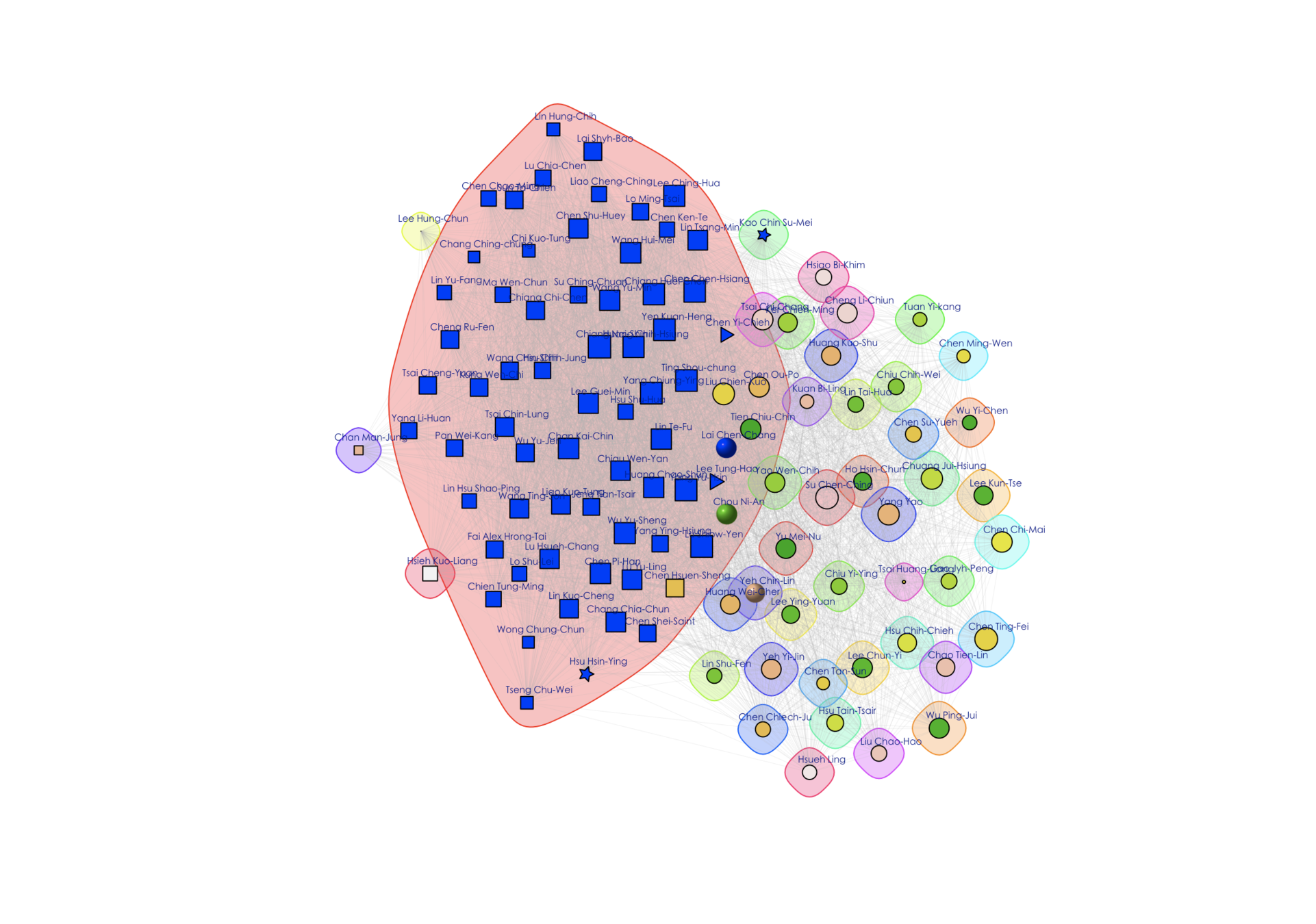
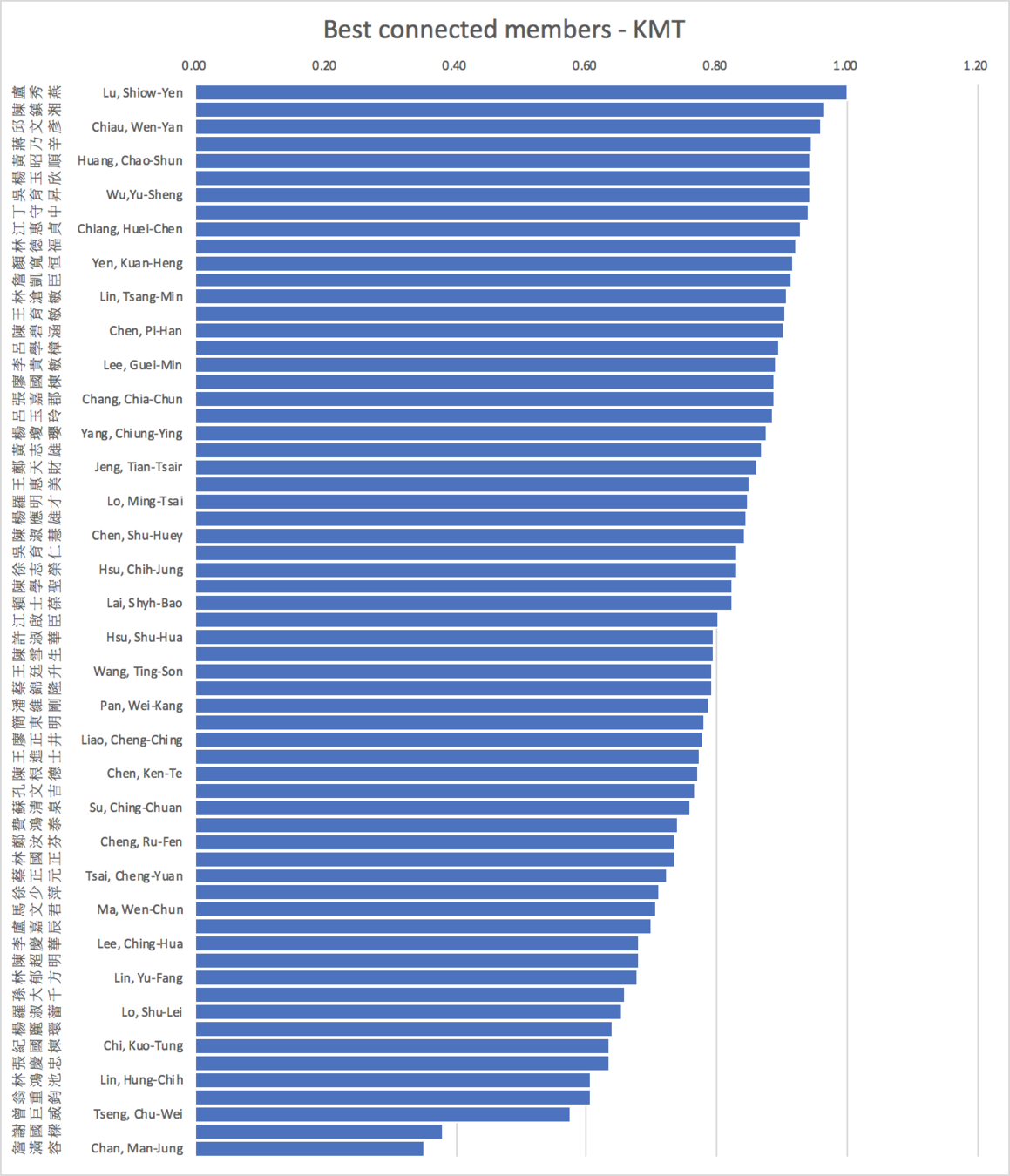
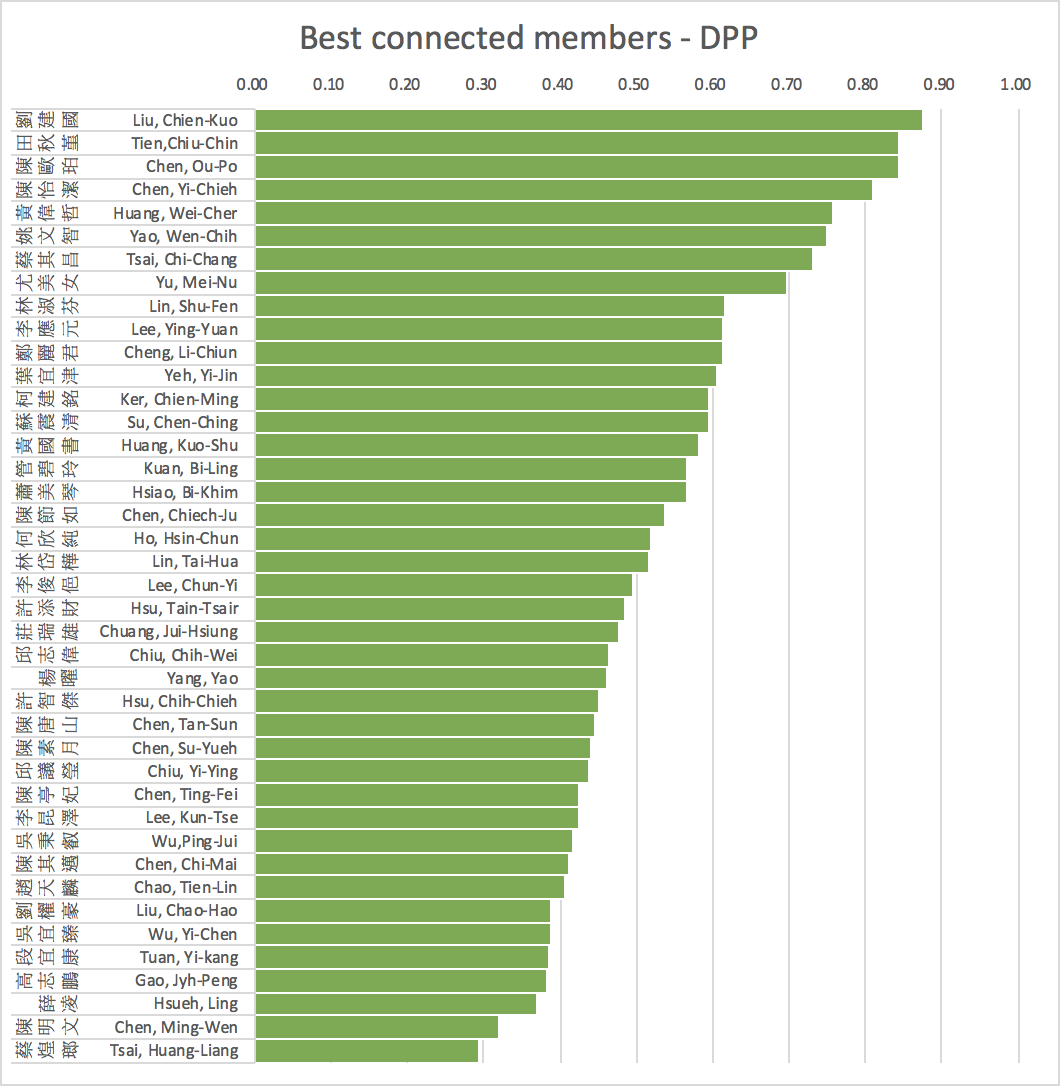
Source: Taiwan Legislative Yuan API
average=0.79 s.d.=0.13 skewness= -1.12
average=0.54 s.d.=0.15 skewness=0.72
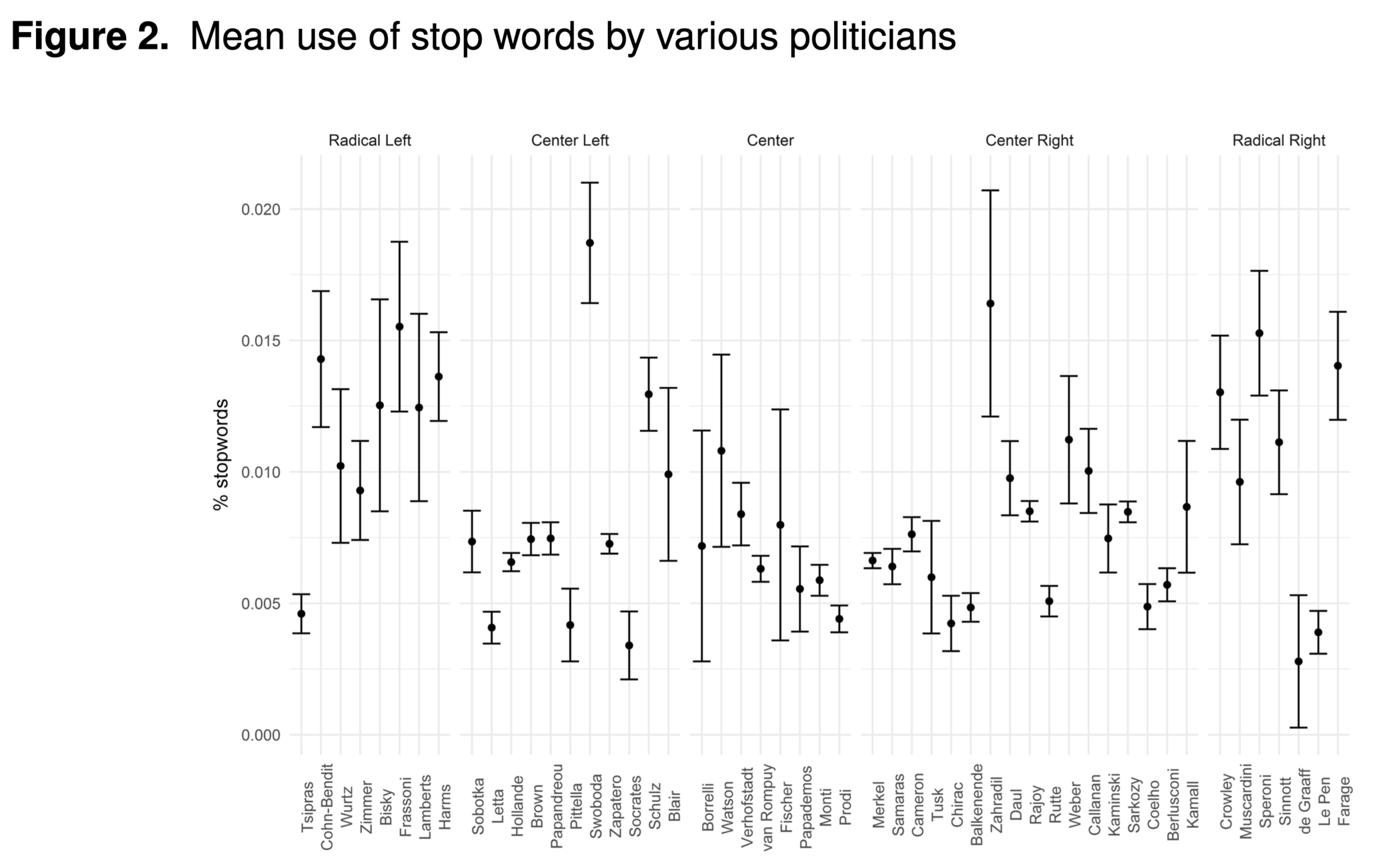
Schoonvelde et al. 2019: taking out stop words is not an ideologically neutral step.
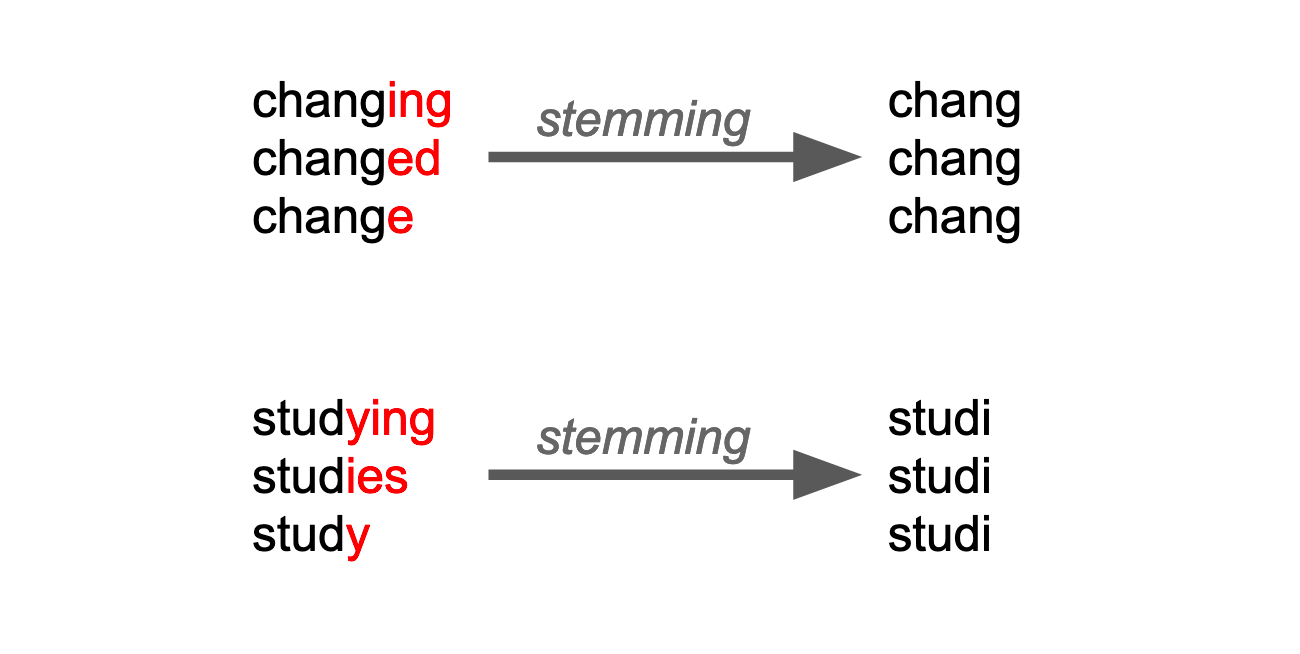
Source: Openclassrooms.com
Source: Openclassrooms.com
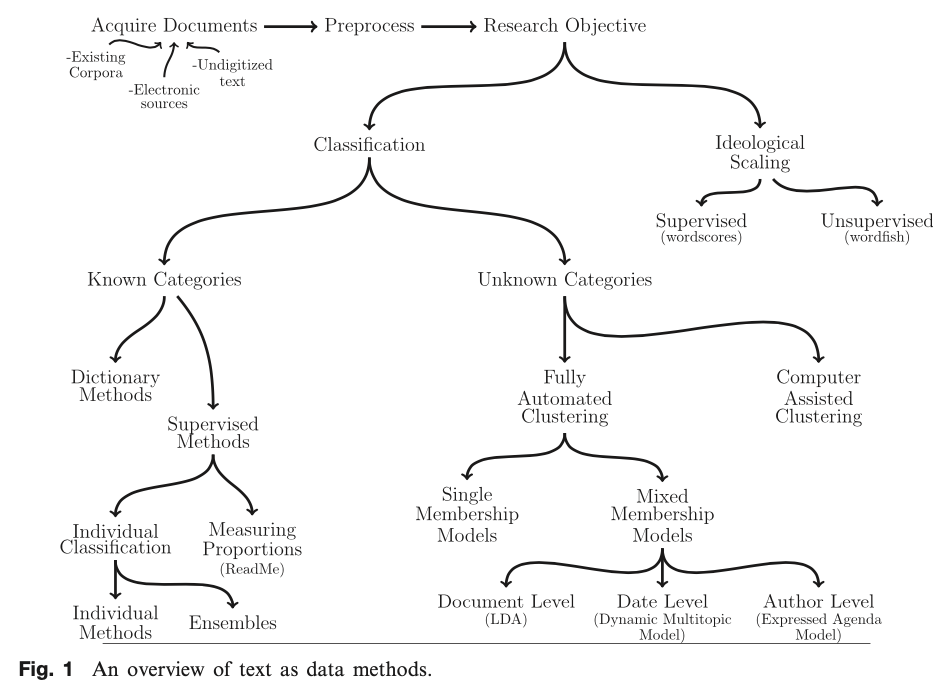
Topic modeling
Latent Dirichlet Allocation (LDA)
Structural Topic Modeling (STM)
Positional scaling
Wordfish
Dictionary-based
Sentiment Analysis
Lexicon
Dictionary
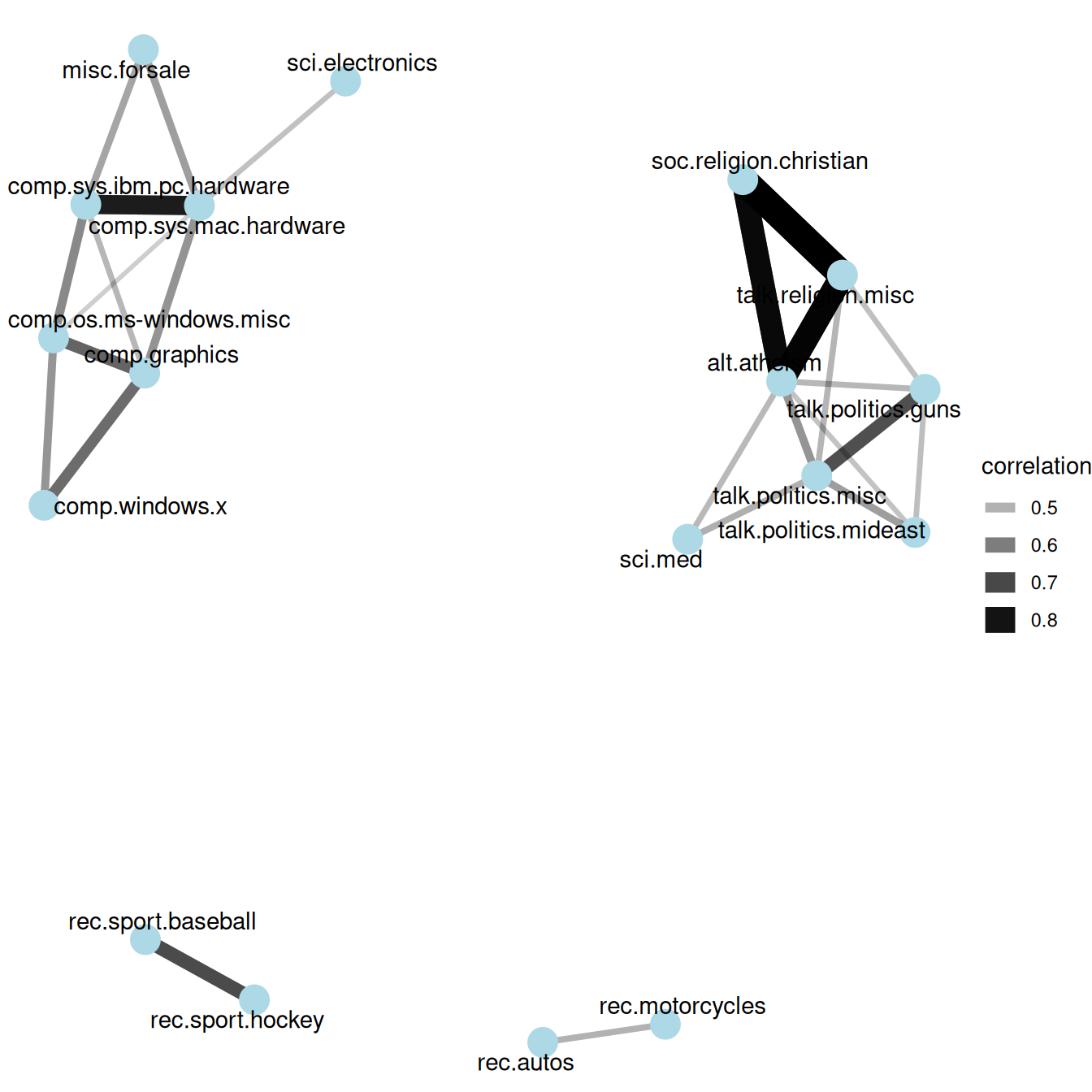
A network of Usenet groups based on the correlation of word counts between them
Silge, Julia. 2019. Text Mining in R
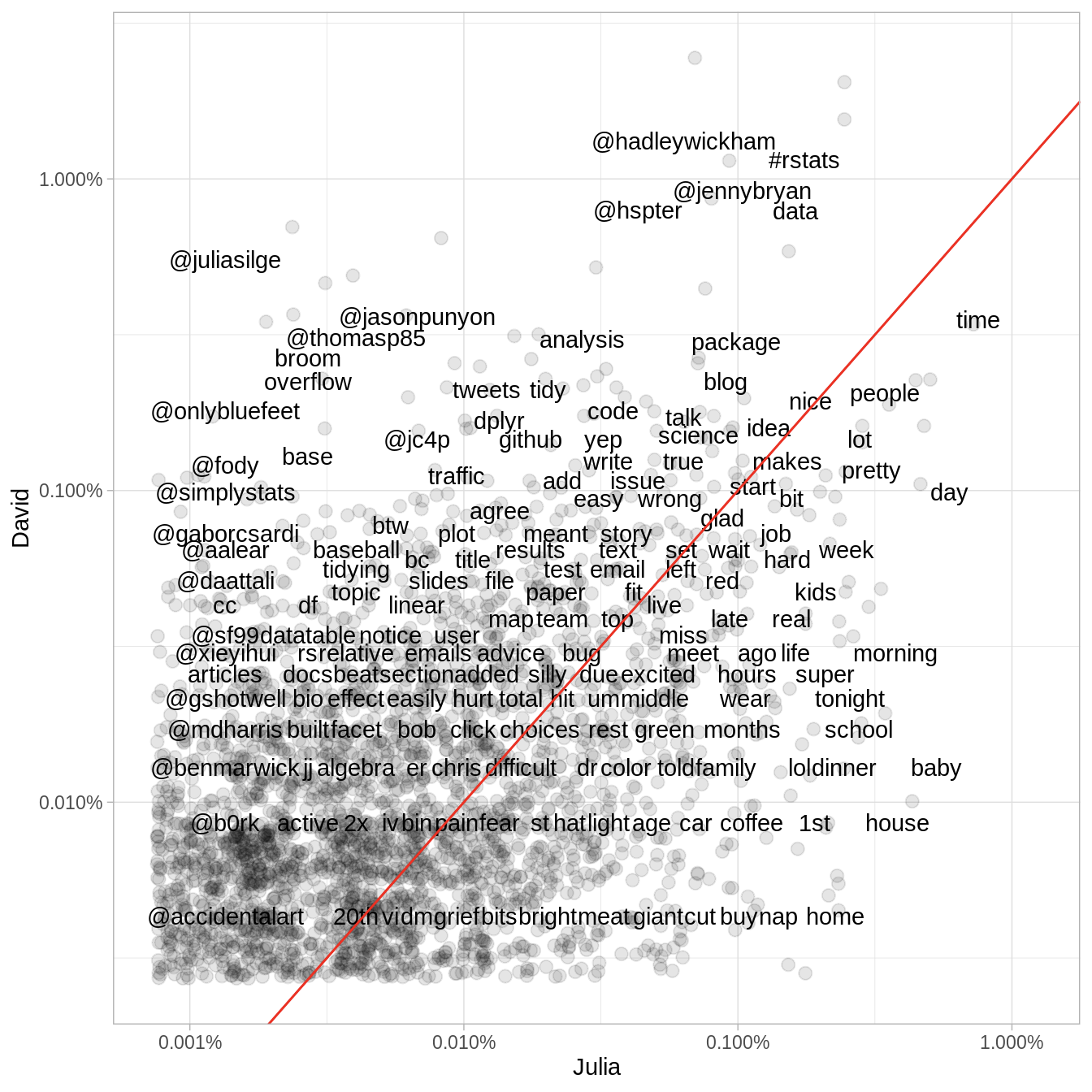
Comparing the frequency of words used by Twitter users
Silge, Julia. 2019. Text Mining in R
beta: per-topic-per-word probabilities
beta: per-topic-per-word probabilities
beta: per-topic-per-word probabilities
beta: per-topic-per-word probabilities
Hu, Minqing, and Bing Liu. "Mining opinion features in customer reviews." In AAAI, vol. 4, no. 4, pp. 755-760. 2004.
Liu, Bing. 2012. Sentiment analysis and opinion mining. Synthesis lectures on human language technologies, 5(1), pp.1-167.
get_sentiments("nrc")
# A tibble: 13,901 x 2
word sentiment
<chr> <chr>
1 abacus trust
2 abandon fear
3 abandon negative
4 abandon sadness
5 abandoned anger
6 abandoned fear
7 abandoned negative
8 abandoned sadness
9 abandonment anger
10 abandonment fear
# … with 13,891 more rows get_sentiments("bing")
# A tibble: 6,786 x 2
word sentiment
<chr> <chr>
1 2-faces negative
2 abnormal negative
3 abolish negative
4 abominable negative
5 abominably negative
6 abominate negative
7 abomination negative
8 abort negative
9 aborted negative
10 aborts negative
# … with 6,776 more rows get_sentiments("afinn")
# A tibble: 2,477 x 2
word value
<chr> <dbl>
1 abandon -2
2 abandoned -2
3 abandons -2
4 abducted -2
5 abduction -2
6 abductions -2
7 abhor -3
8 abhorred -3
9 abhorrent -3
10 abhors -3
# … with 2,467 more rowsTrump is afraid of democracy. Following the G7 meeting I can tell you that we're all united against autocrats and that they should be afraid. No collusion like with the old psychotic man you are supporting.
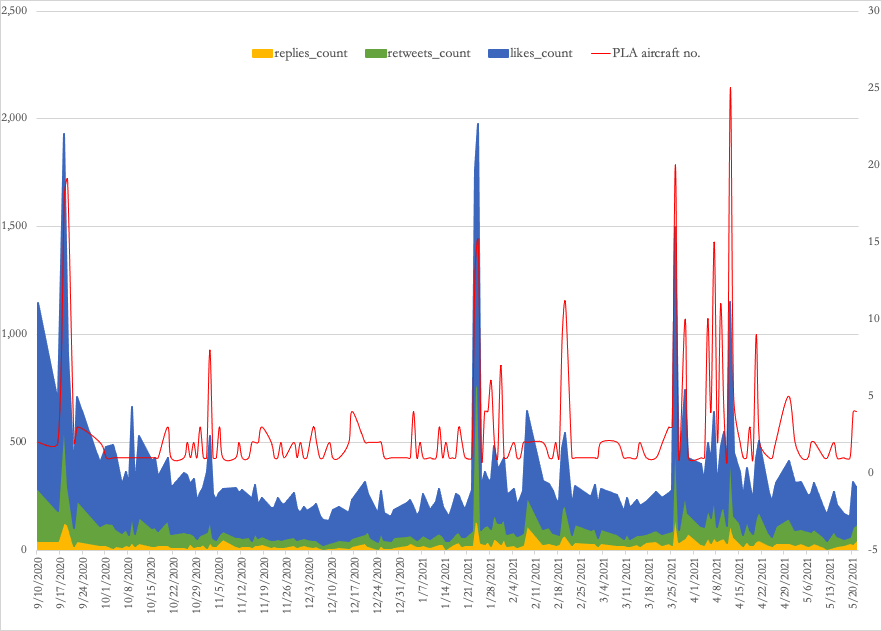
@G7 leaders have failed to rise above national interests and tackle the global crises of COVID19 and Climate Change. They have simply repeated old promises (unfulfilled) for Climate Finance and inadequate supplies of vaccine without allowing patents for manufacture. @SaleemulHuq https://t.co/hkyTGKZvTW en [{'screen_name': 'saleemulhuq'
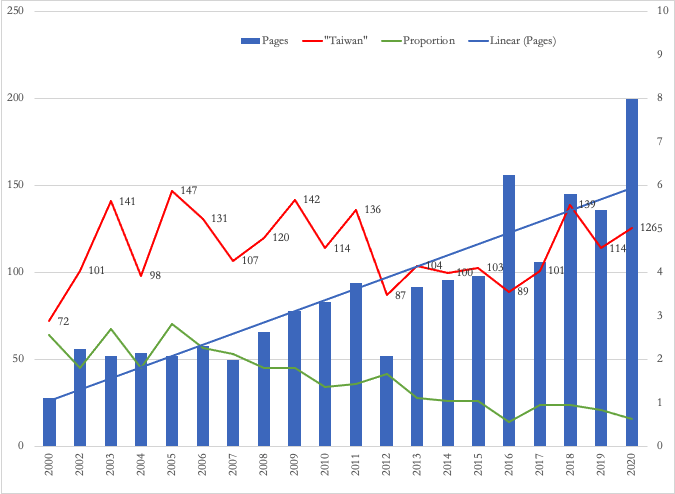
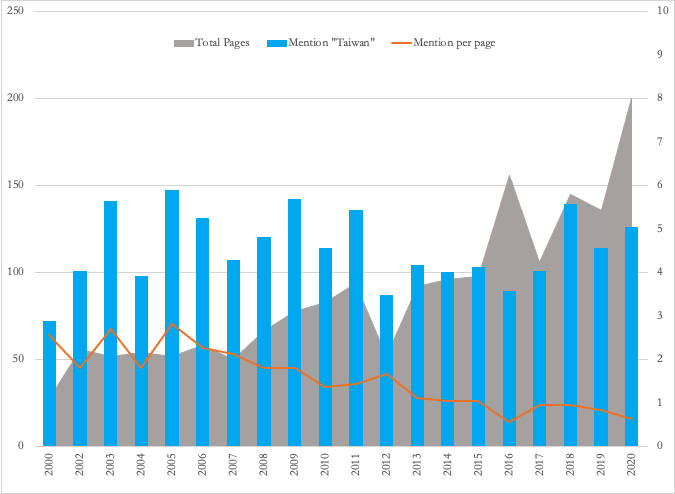
Figure 5. US Department of Defense Report on China’s Military Force: Mentions of “Taiwan”
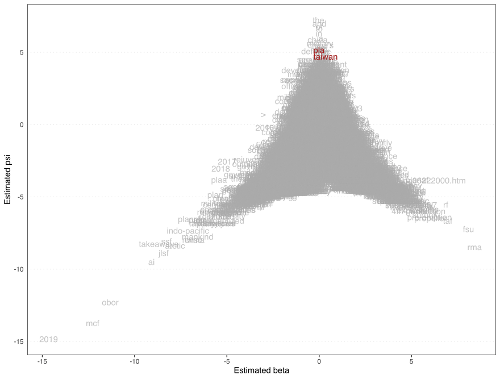
Figure 6. US Department of Defense Report on China’s Military Force: Keyword position of “Taiwan”
Figure 7. DOD Report: Poisson Scaling of favorability and position clarity on evaluating China’s military, 2000-2020
Aggarwal, C.C. and Zhai, C. eds., 2012. Mining text data. Springer Science & Business Media.
Chang, Jonathan, Jordan Boyd-Graber, Chong Wang, Sean Gerrish, and David M. Blei. 2009. Reading Tea Leaves: How Humans Interpret Topic Models. Neural Information Processing Systems.
Jockers, Matthew L. 2017. Syuzhet: An R package for the extraction of sentiment and sentiment-based plot arcs from text (GitHub).
Silge, Julia and Robinson, David. 2017. Text mining with R: A tidy approach. " O'Reilly Media, Inc." (https://www.tidytextmining.com/)
Cosima Meyer and Cornelius Puschmann: Advancing Text Mining with R and quanteda
Dan Jurafsky and James H. Martin: Speech and Language Processing
Ignatow, G. and Mihalcea, R., 2016. Text Mining: A Guidebook for the Social Sciences. Sage Publications.
By Karl Ho



