





Karl Ho
Data Generation datageneration.io
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Photo credit: Shane Rounce on Unsplash
Photo credit: Nagara Oyodoon Unsplash
Photo credit: Tim Mossholder on Unsplash
- Hadley Wickham
Source: Joe Cheng "Running Shiny without a server"
Source: Rami Krispin GitHub
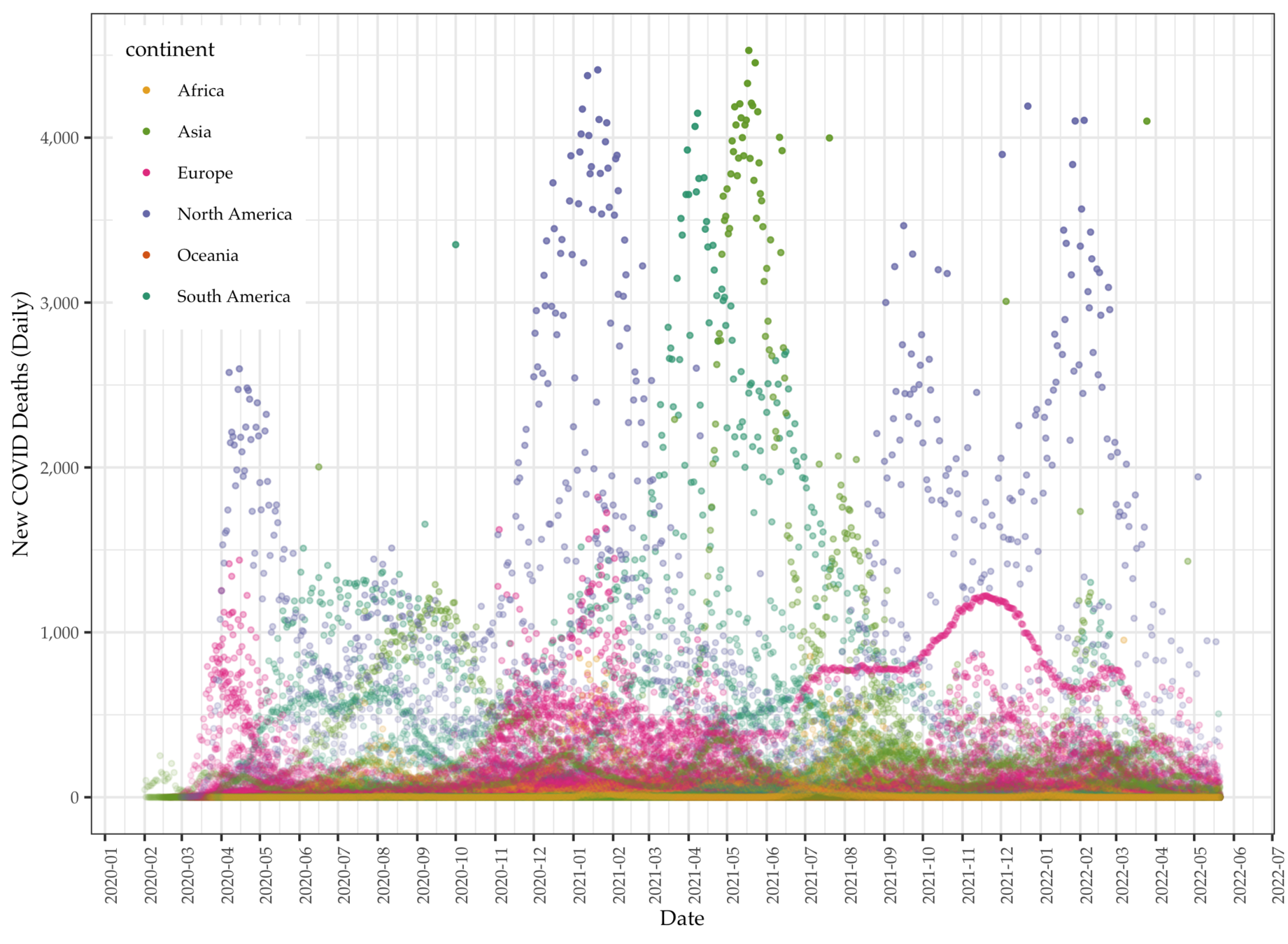
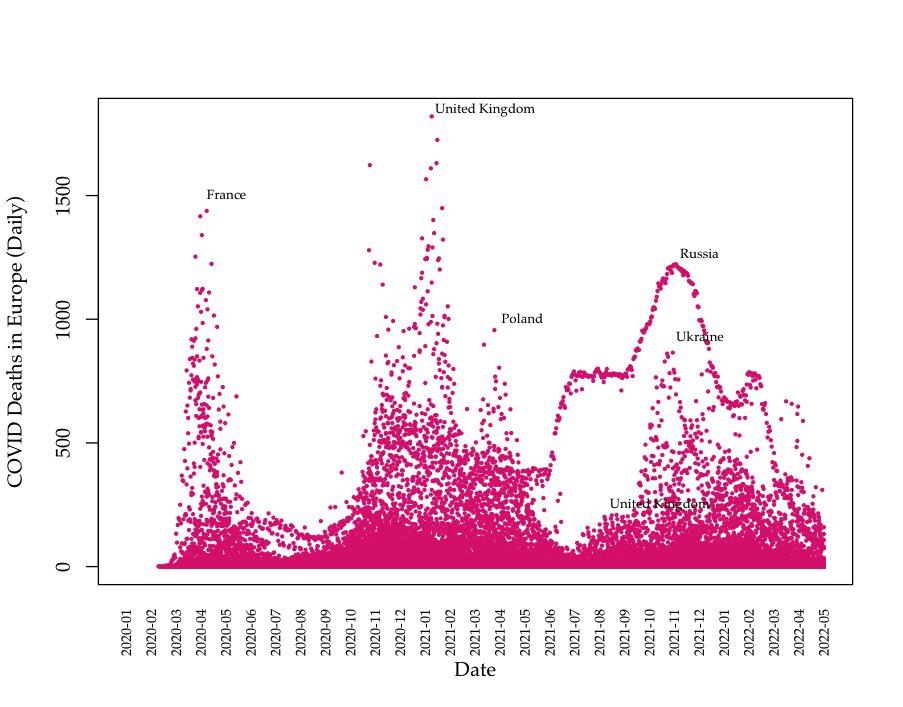
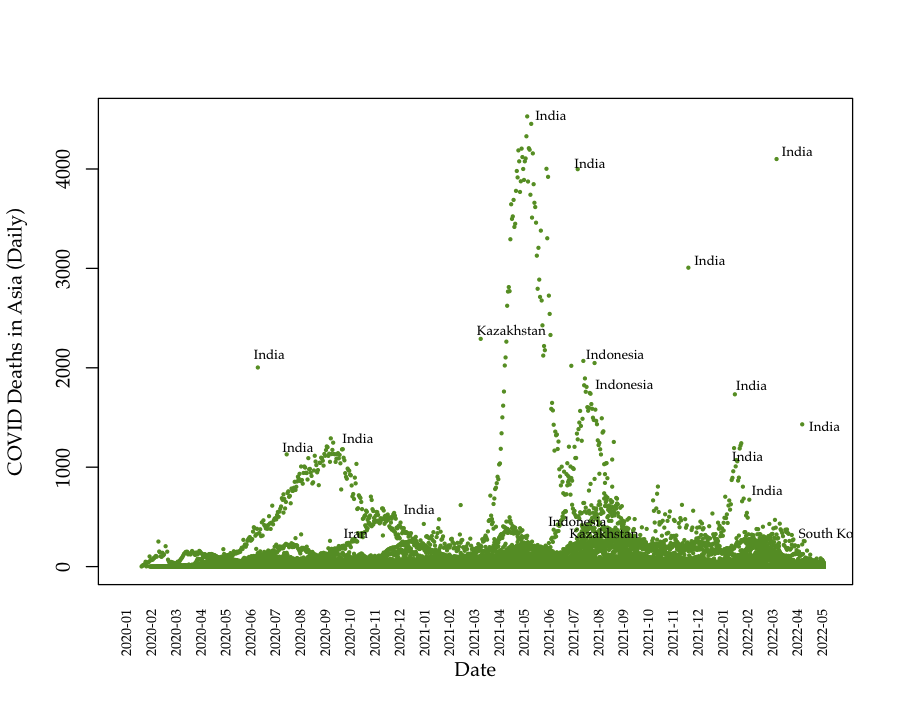
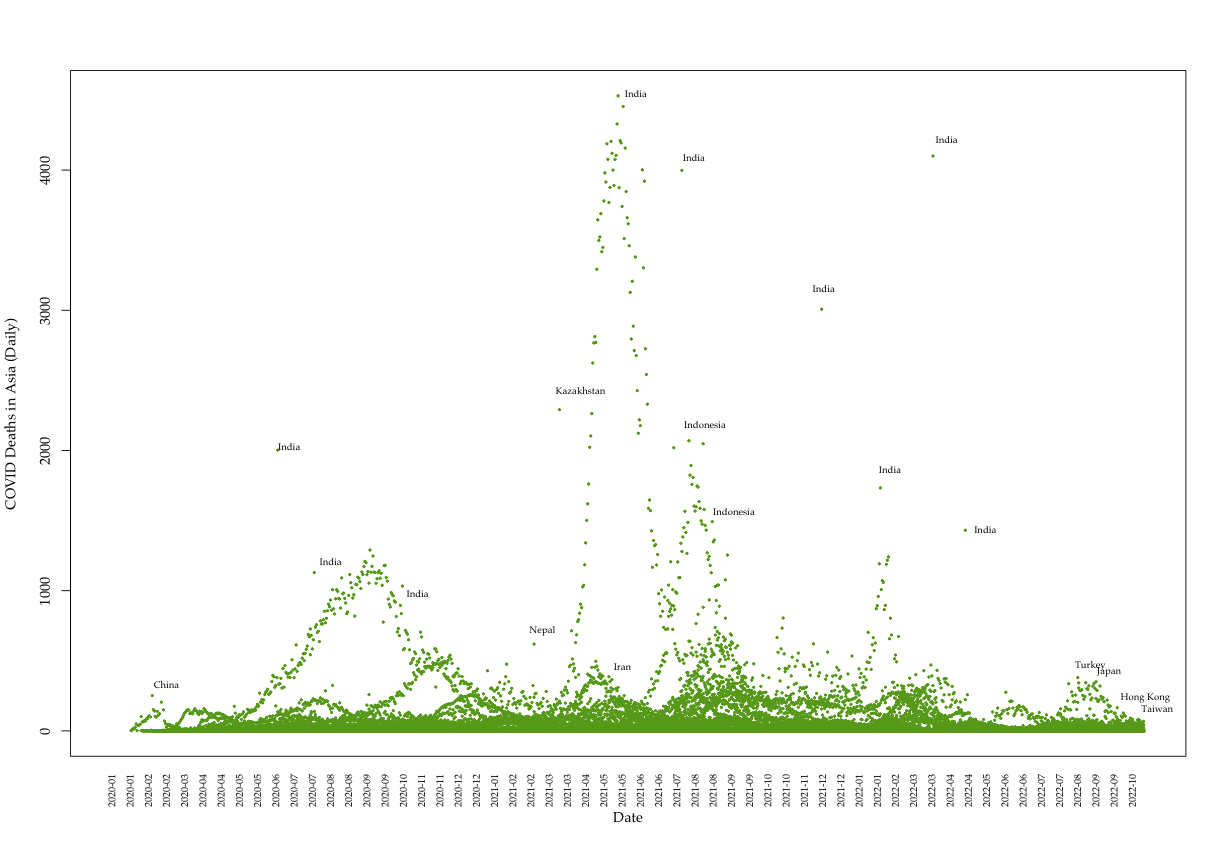
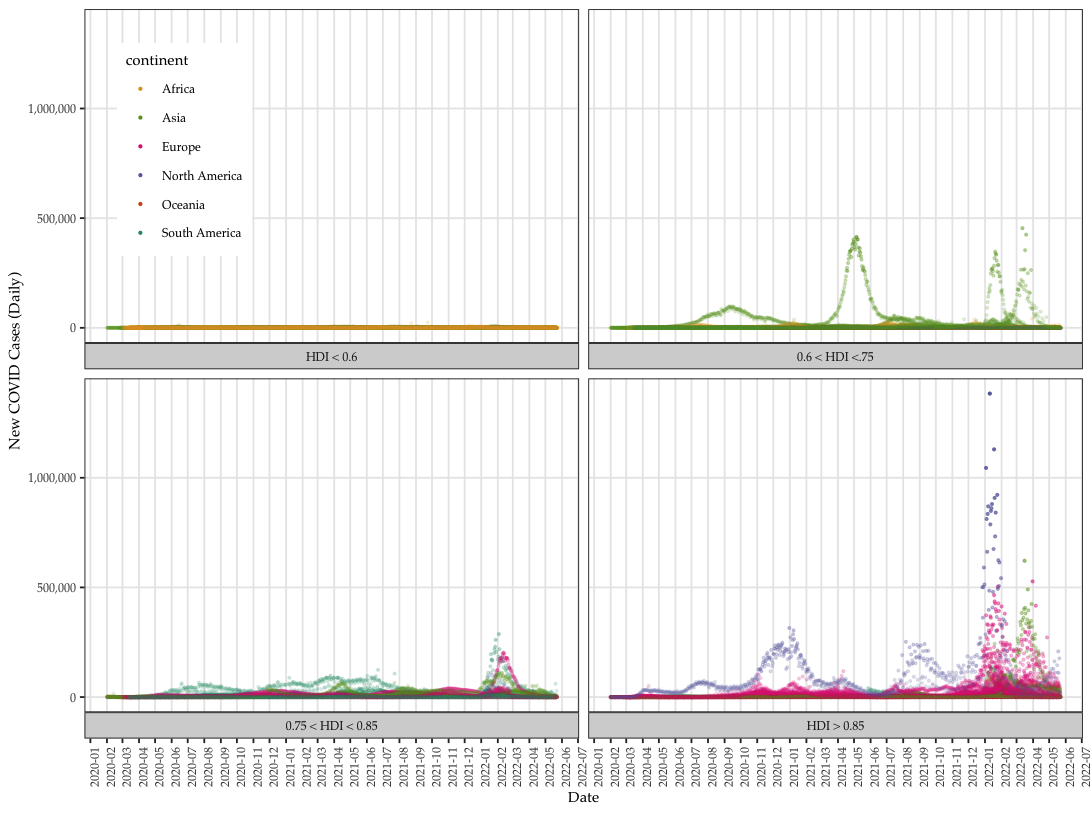
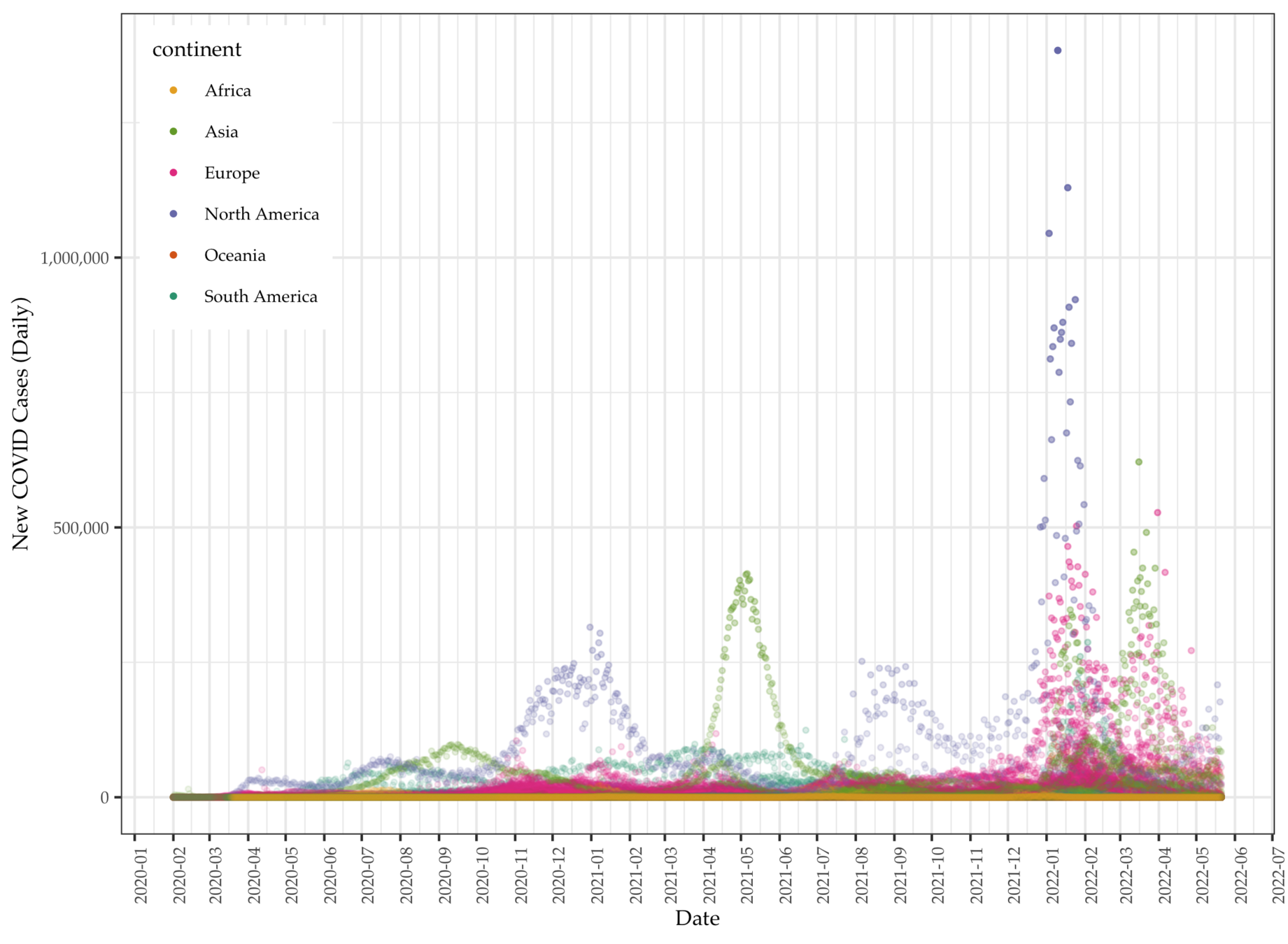
We collect global COVID data from the Our World in Data project, which makes available daily pandemic data from all countries available in real time.
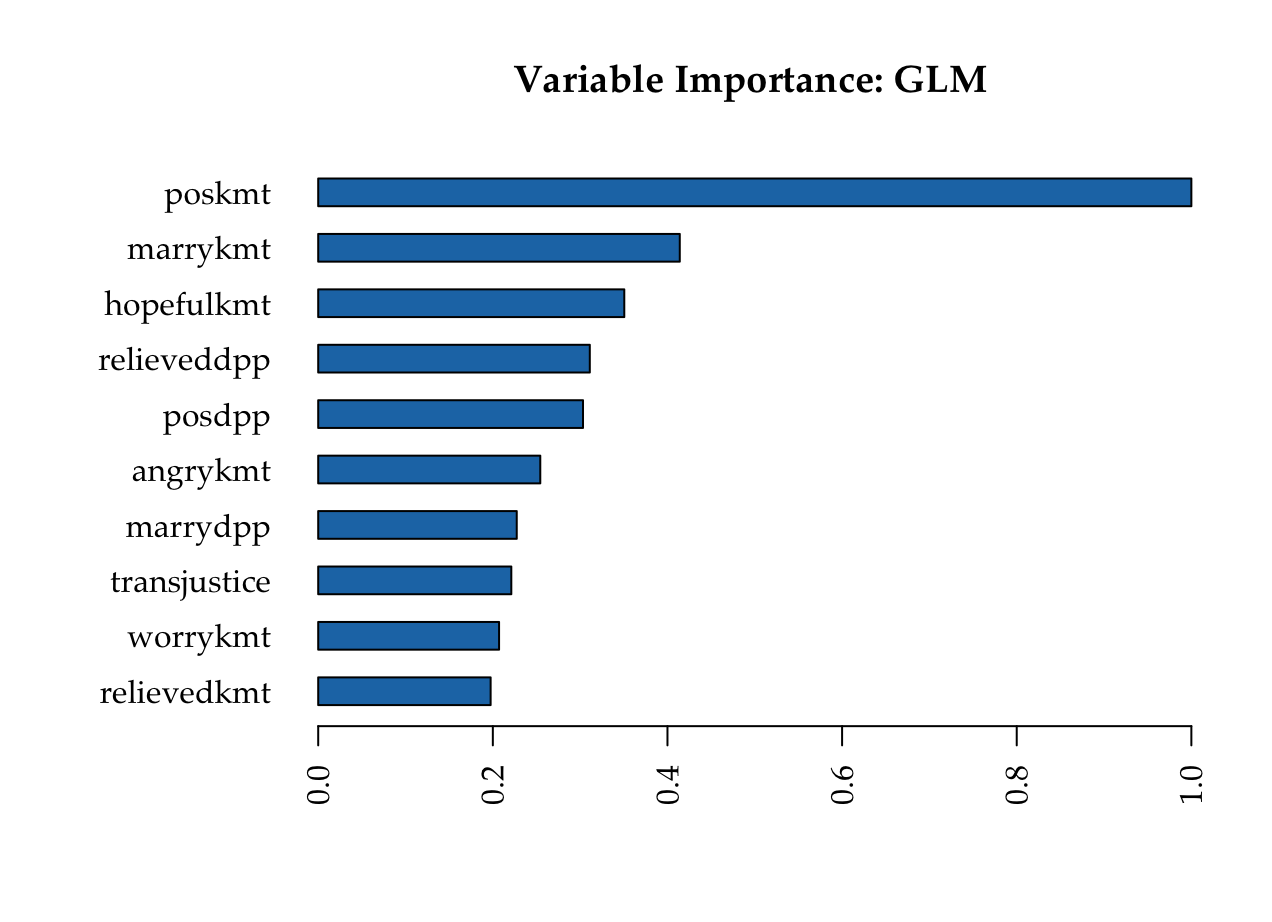
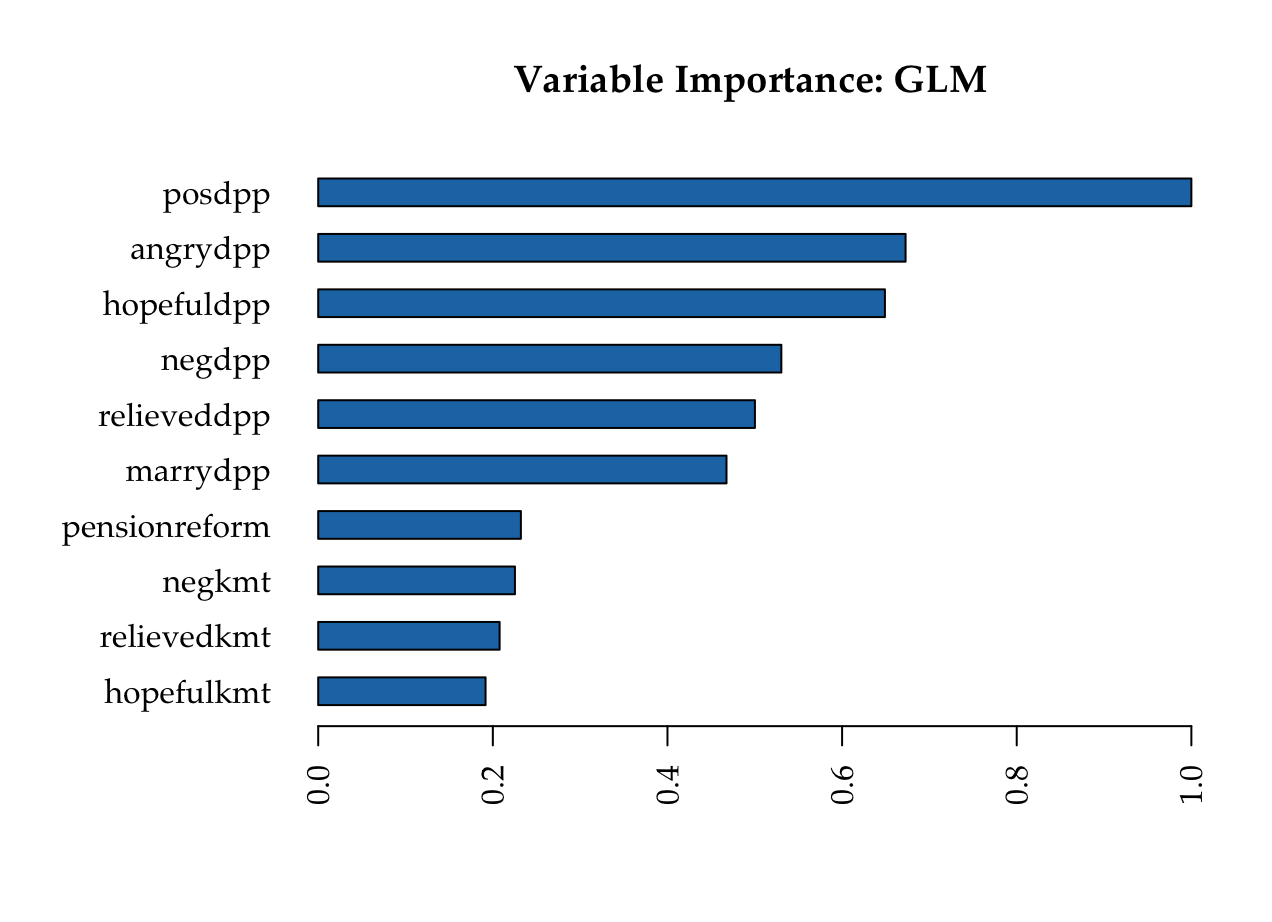
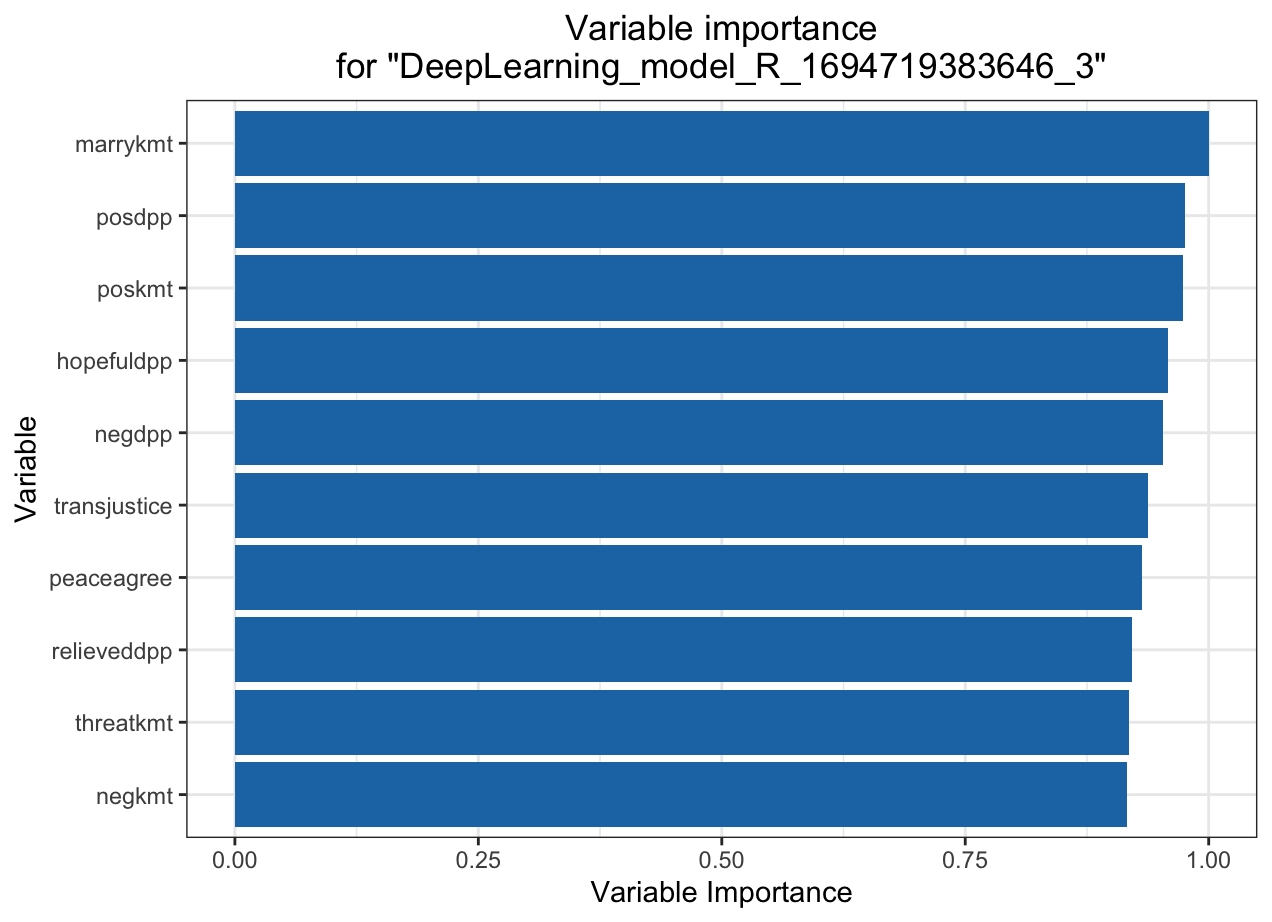
KMT
DPP
KMT
DPP
MSE: 0.05650798
RMSE: 0.2377141
LogLoss: 0.190111
Mean Per-Class Error: 0.07756352
AUC: 0.9773588
AUCPR: 0.9645369
Gini: 0.9547177
MSE: 0.05053361
RMSE: 0.2247968
LogLoss: 0.1659664
Mean Per-Class Error: 0.08273317 AUC: 0.9781768
AUCPR: 0.9399842
Gini: 0.9563536
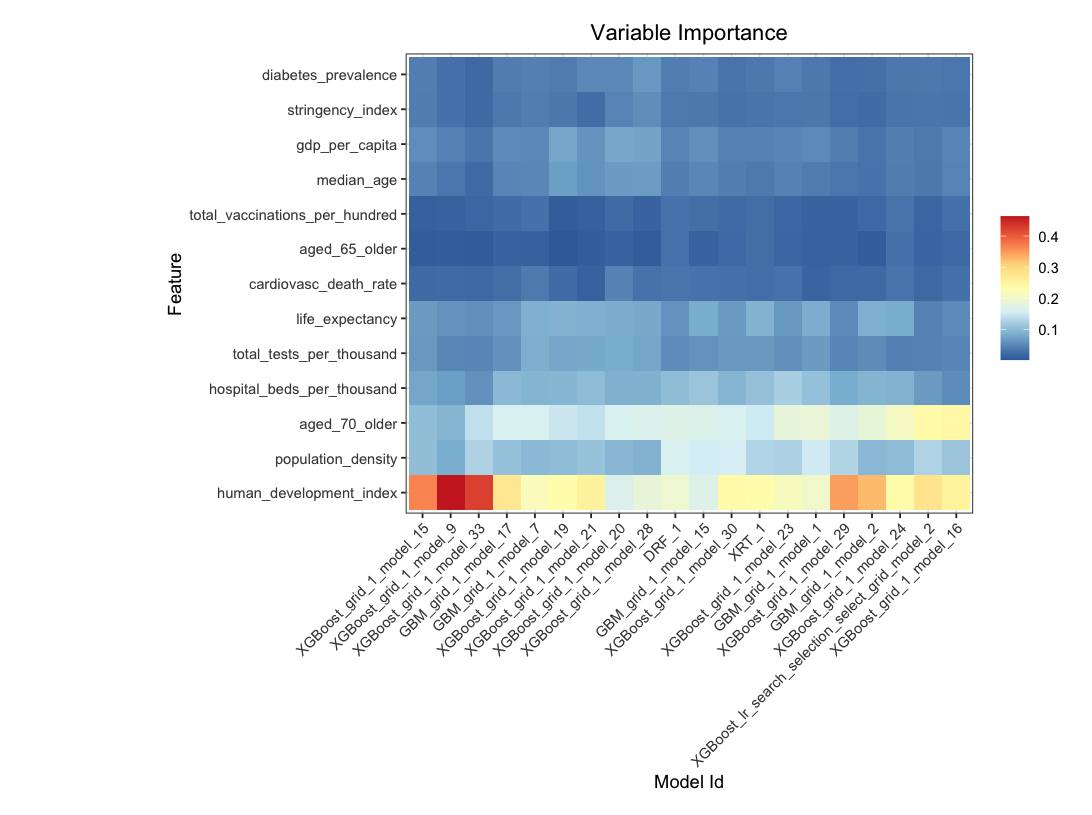
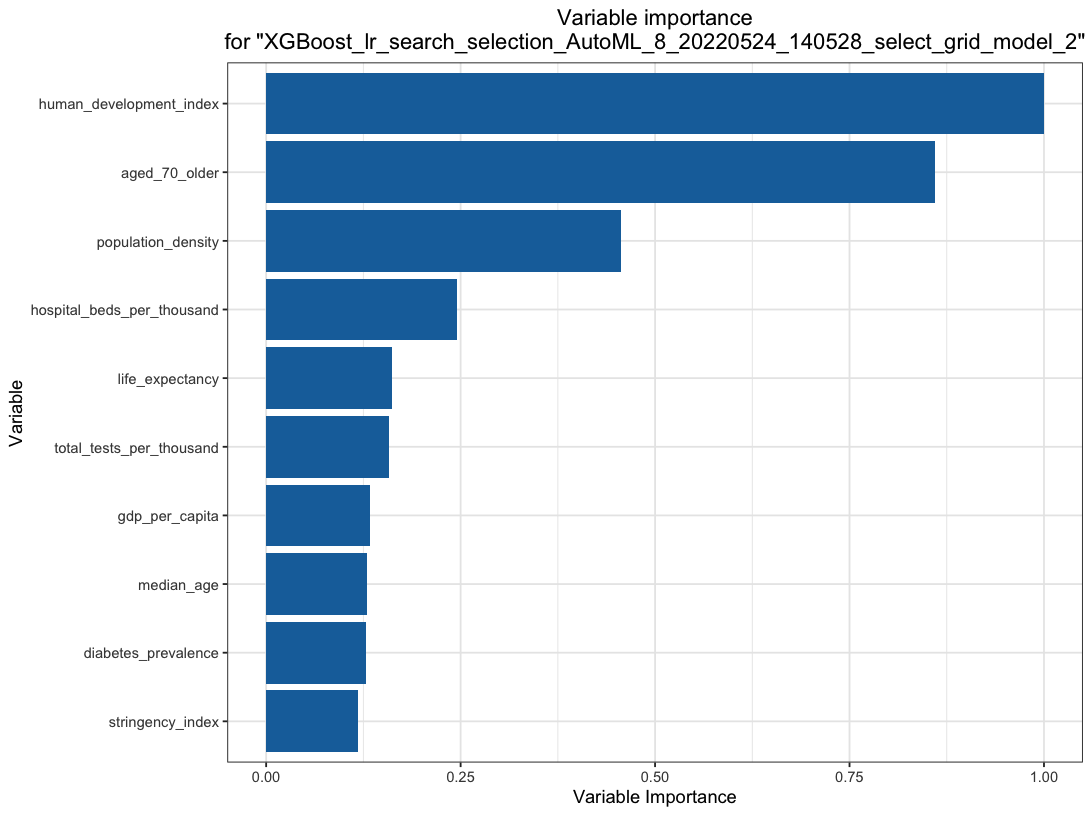
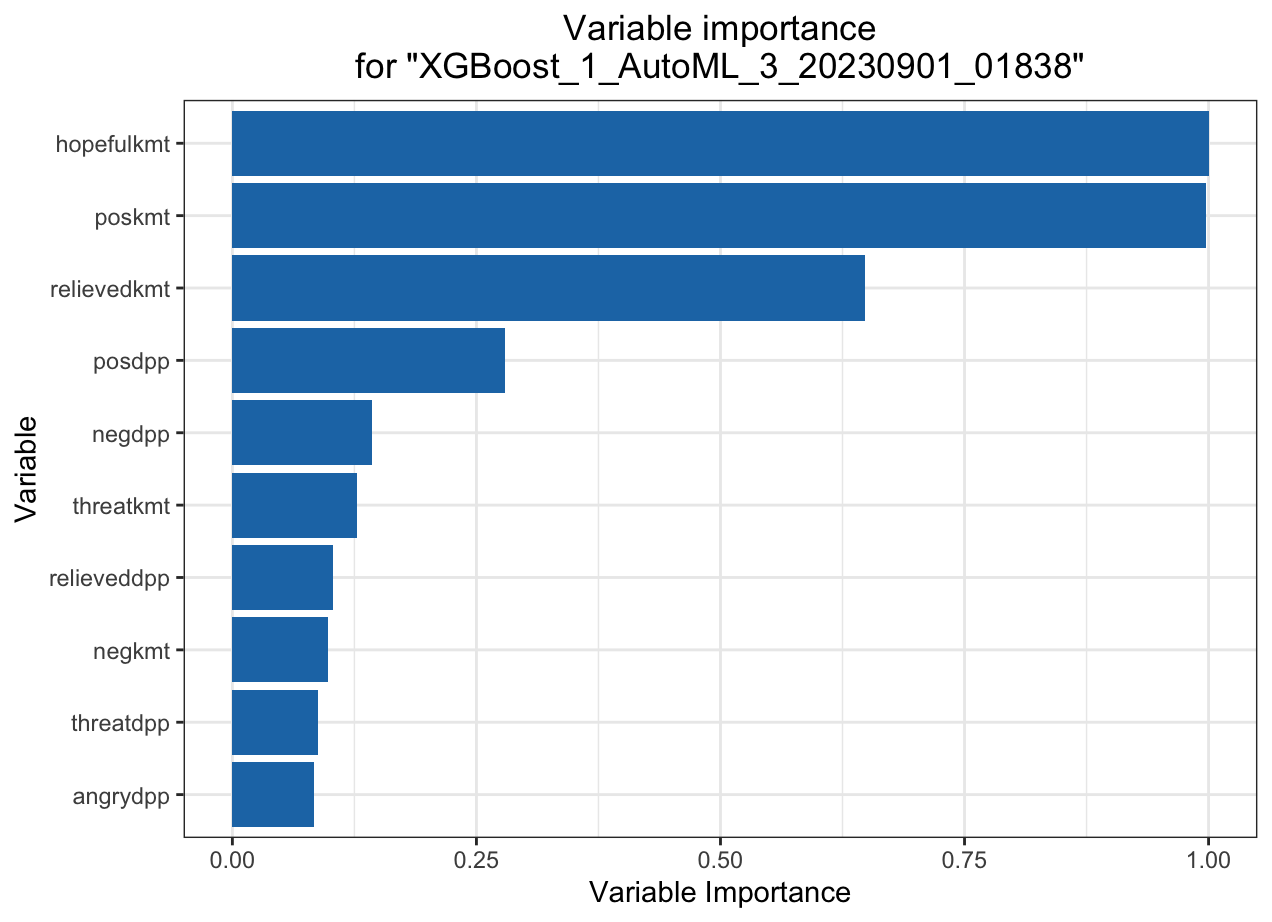
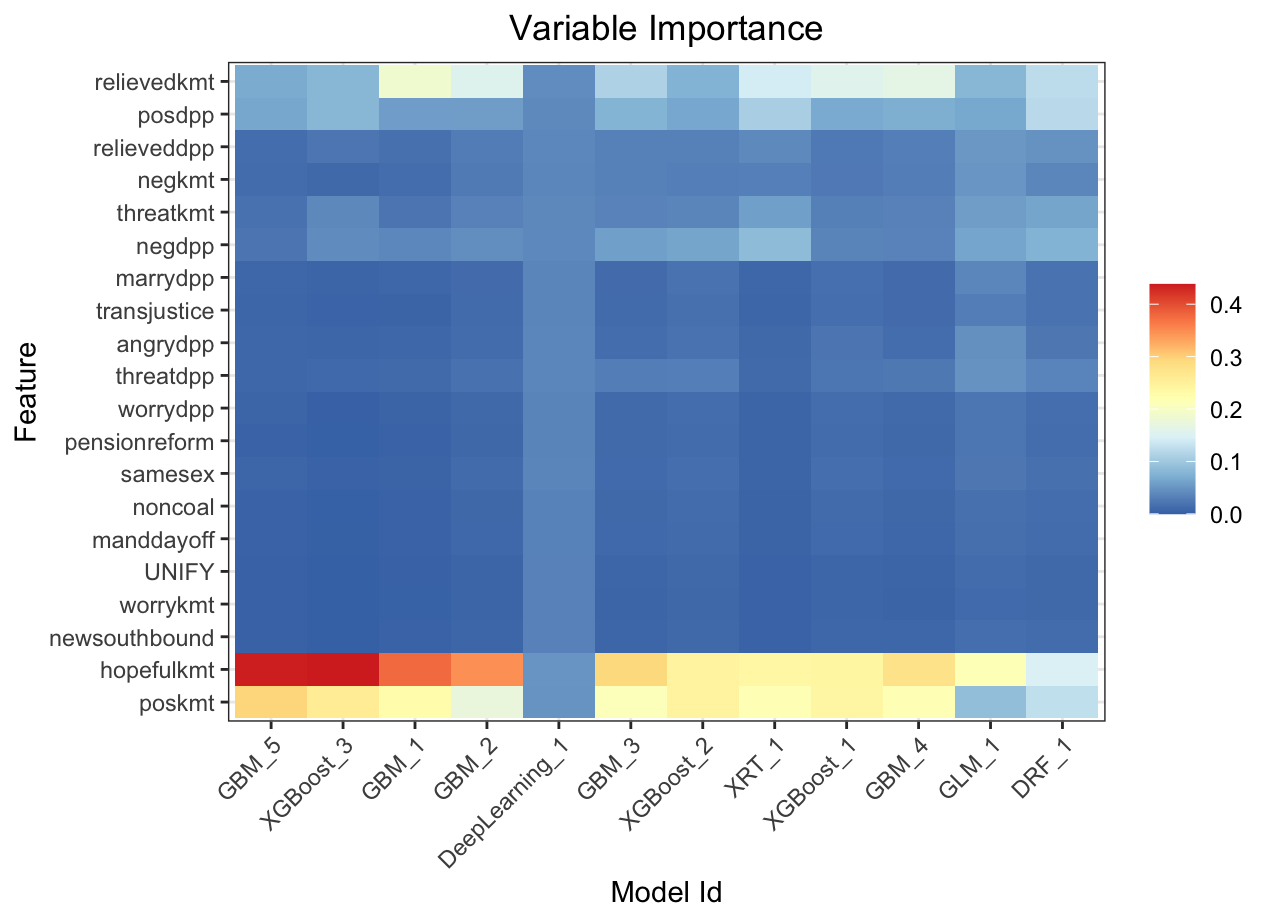
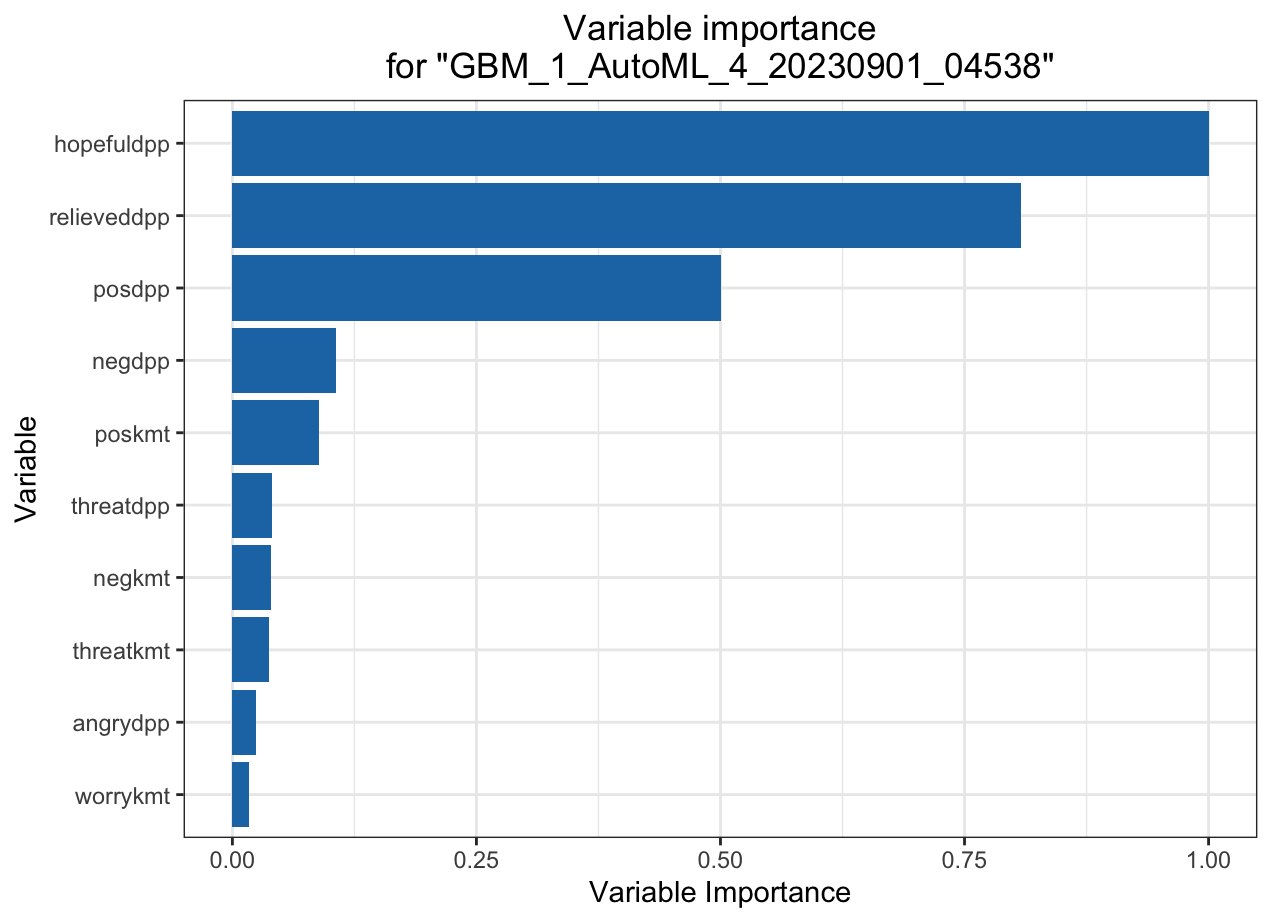
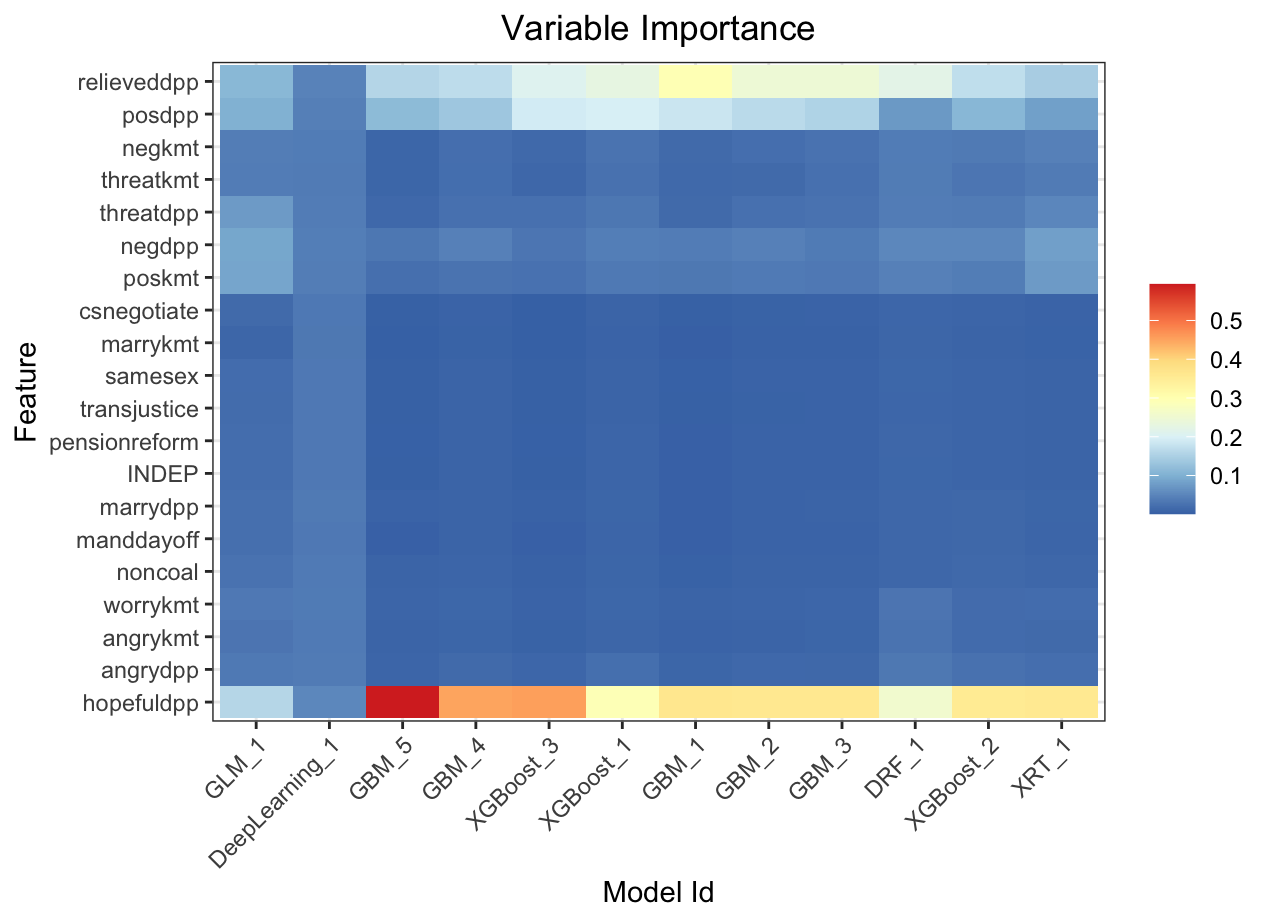
Variable importance heatmap shows variable importance across multiple models. Some models return variable importance for one-hot (binary indicator) encoded versions of categorical columns (e.g. Deep Learning, XGBoost). In order for the variable importance of categorical columns to be compared across all model types we compute a summarization of the the variable importance across all one-hot encoded features and return a single variable importance for the original categorical feature. By default, the models and variables are ordered by their similarity.
Variable importance heatmap shows variable importance across multiple models. Some models return variable importance for one-hot (binary indicator) encoded versions of categorical columns (e.g. Deep Learning, XGBoost). In order for the variable importance of categorical columns to be compared across all model types we compute a summarization of the the variable importance across all one-hot encoded features and return a single variable importance for the original categorical feature. By default, the models and variables are ordered by their similarity.
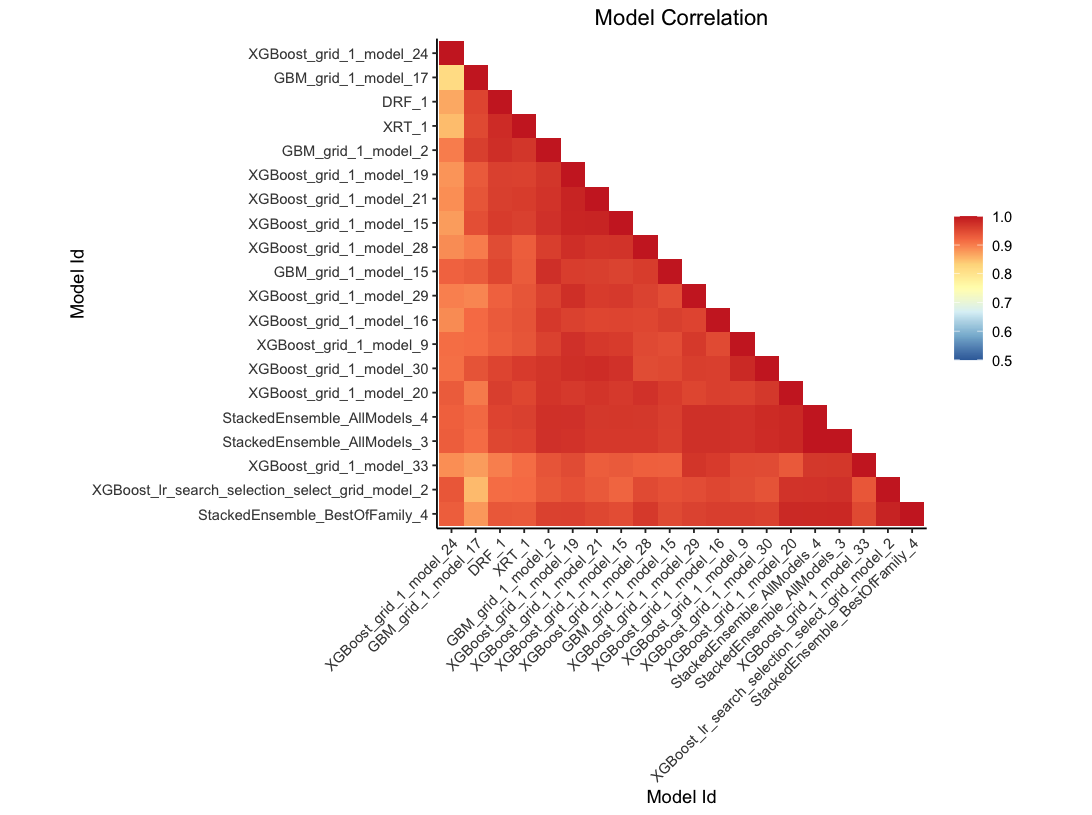
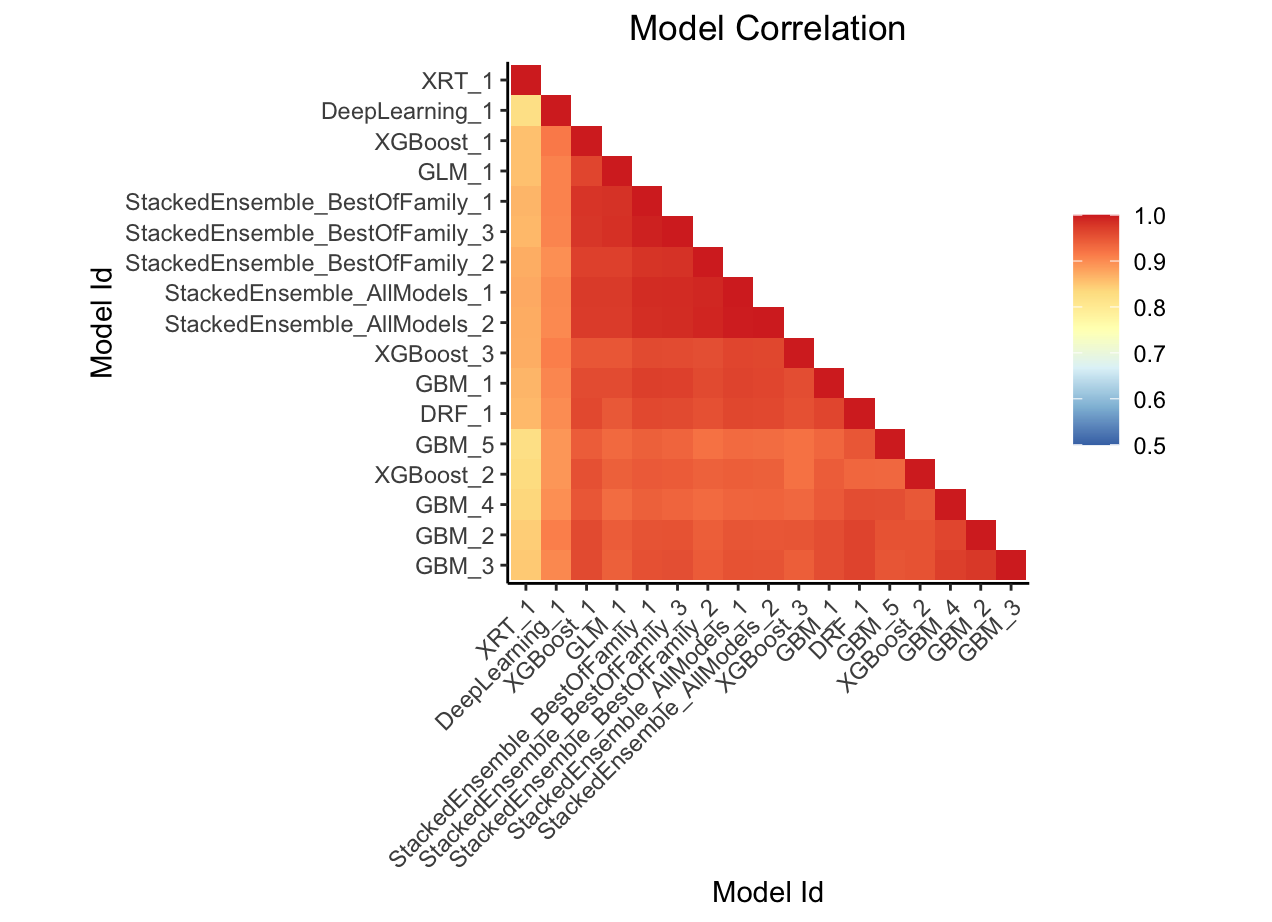
This plot shows the correlation between the predictions of the models. For classification, frequency of identical predictions is used. By default, models are ordered by their similarity (as computed by hierarchical clustering).
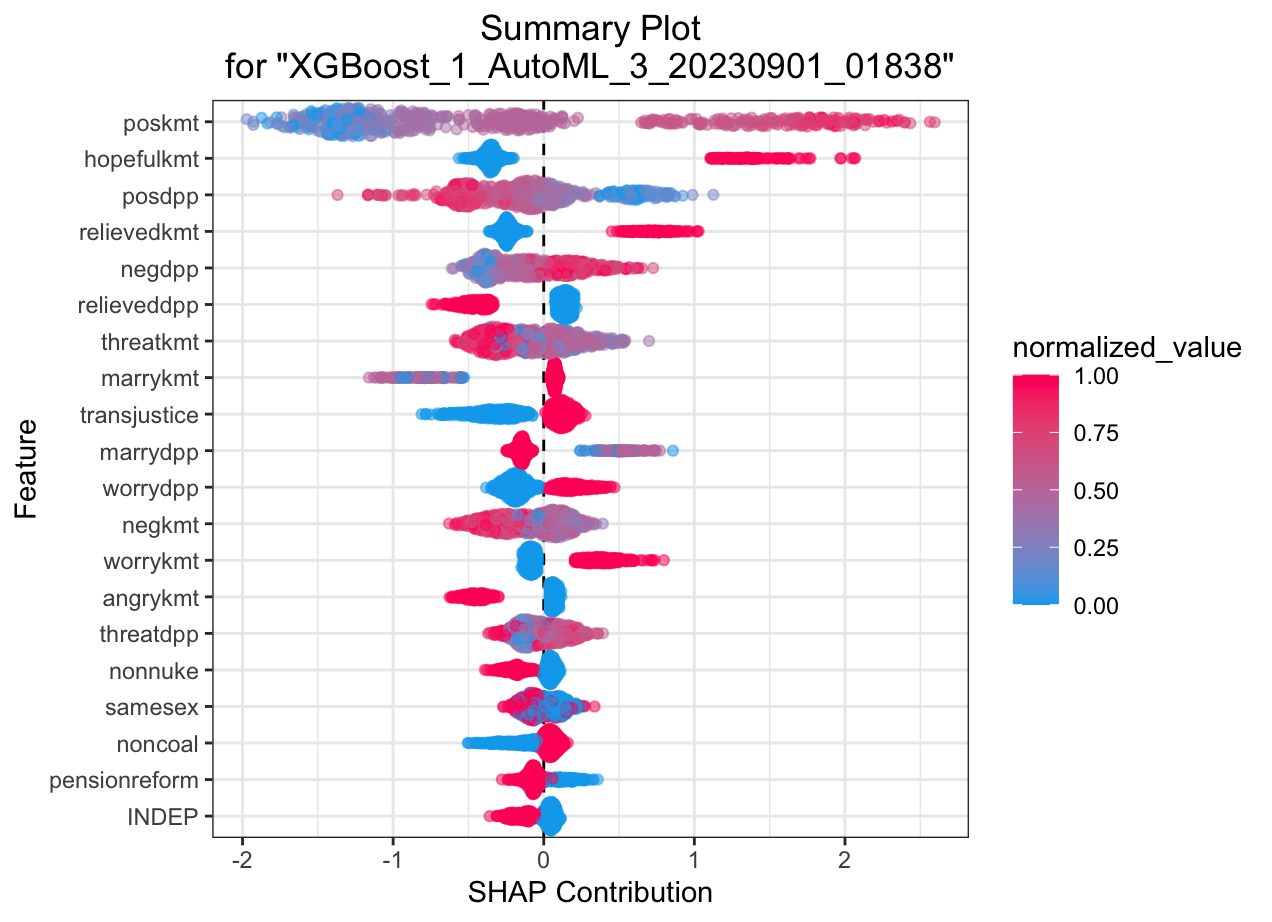
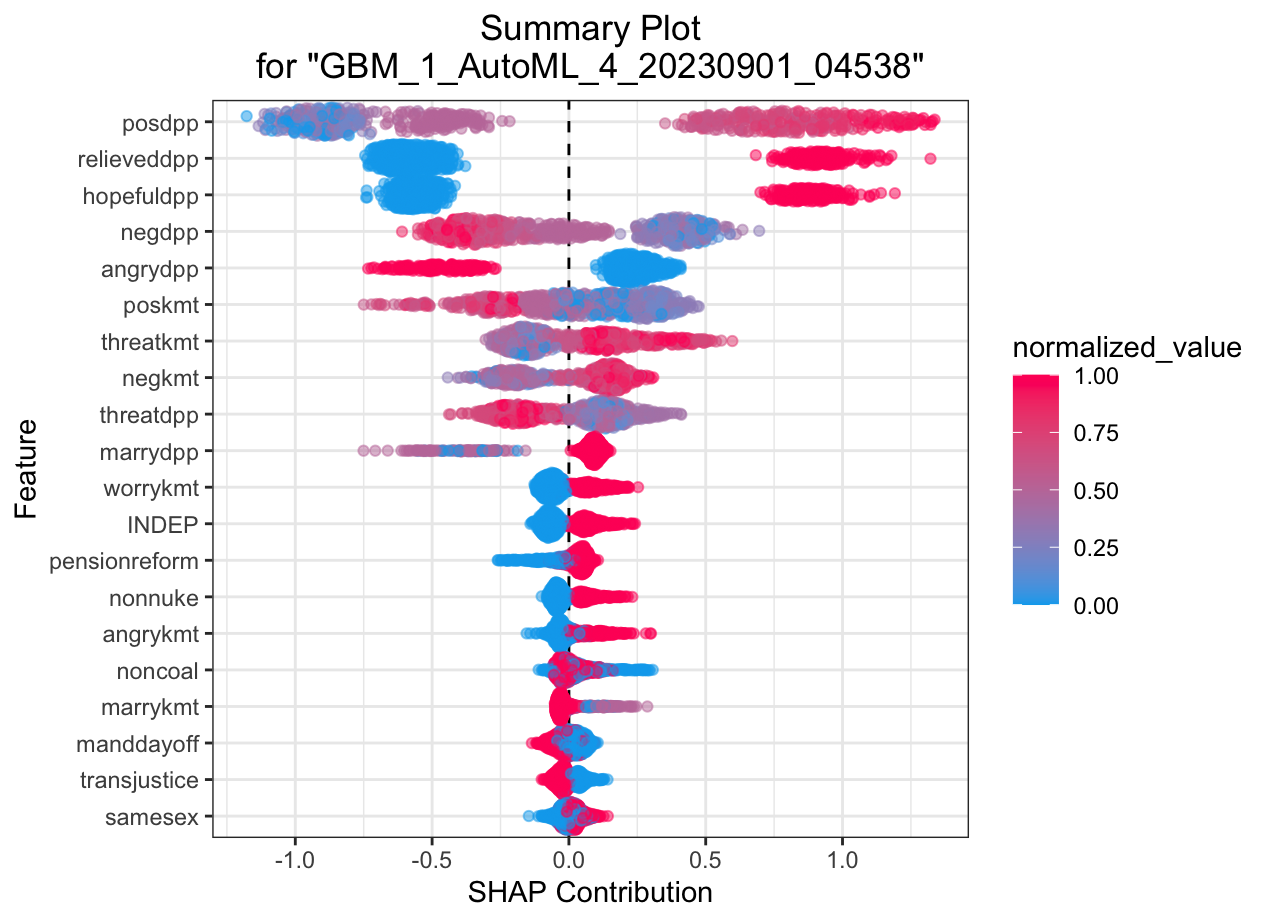
SHAP summary plot shows the contribution of the features for each instance (row of data). The sum of the feature contributions and the bias term is equal to the raw prediction of the model, i.e., prediction before applying inverse link function
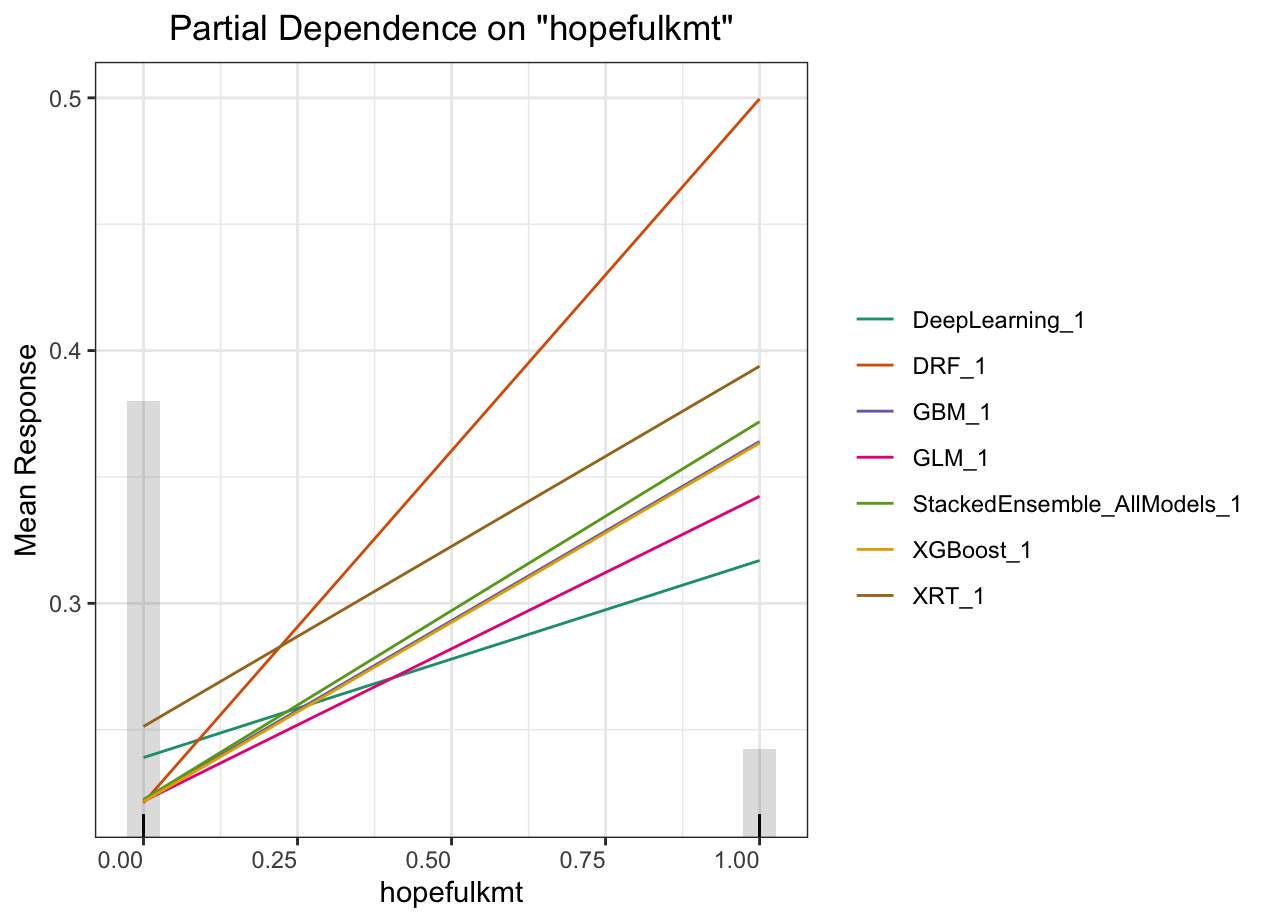
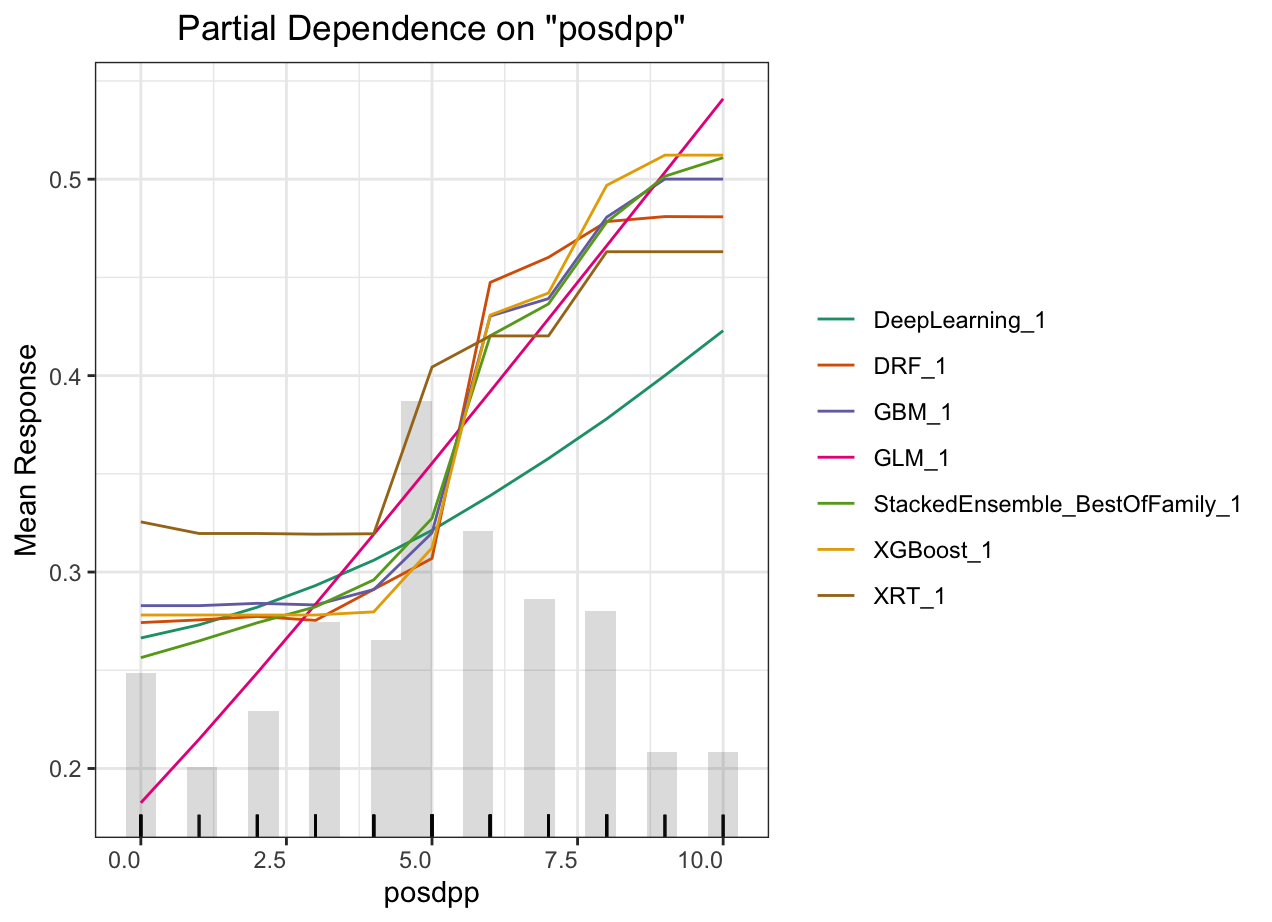
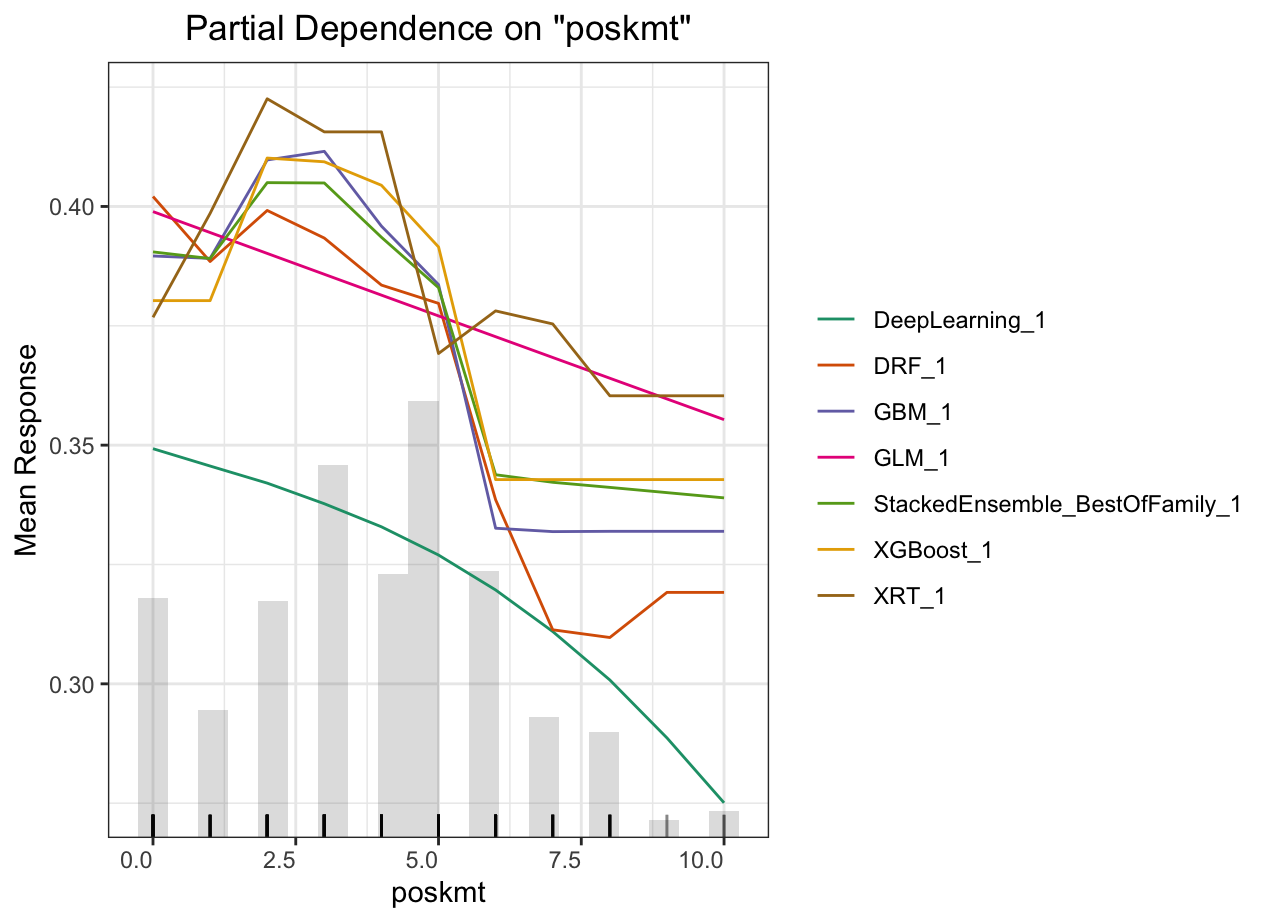
Partial dependence plot (PDP) gives a graphical depiction of the marginal effect of a variable on the response. The effect of a variable is measured in change in the mean response. PDP assumes independence between the feature for which is the PDP computed and the rest.
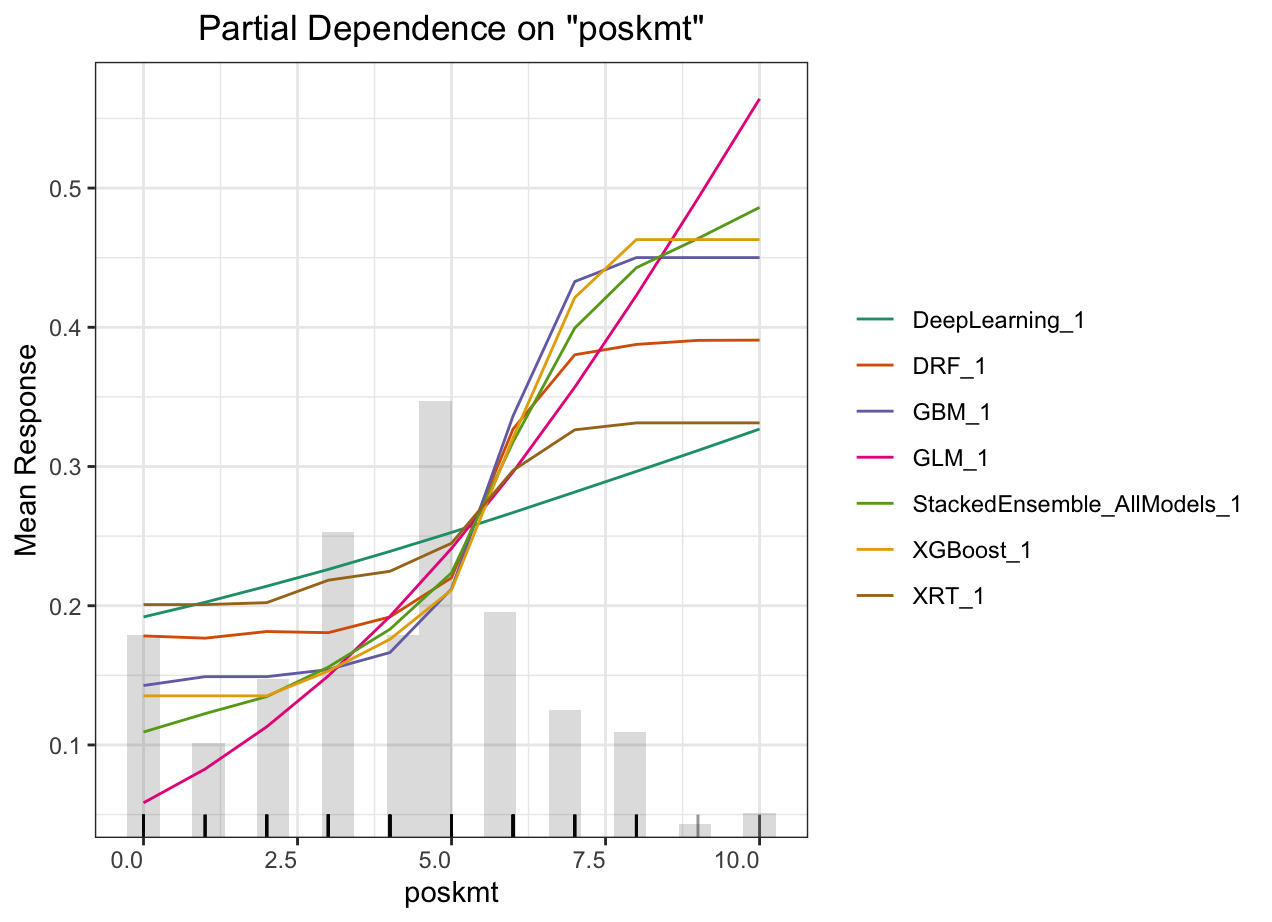
Partial dependence plot (PDP) gives a graphical depiction of the marginal effect of a variable on the response. The effect of a variable is measured in change in the mean response. PDP assumes independence between the feature for which is the PDP computed and the rest.
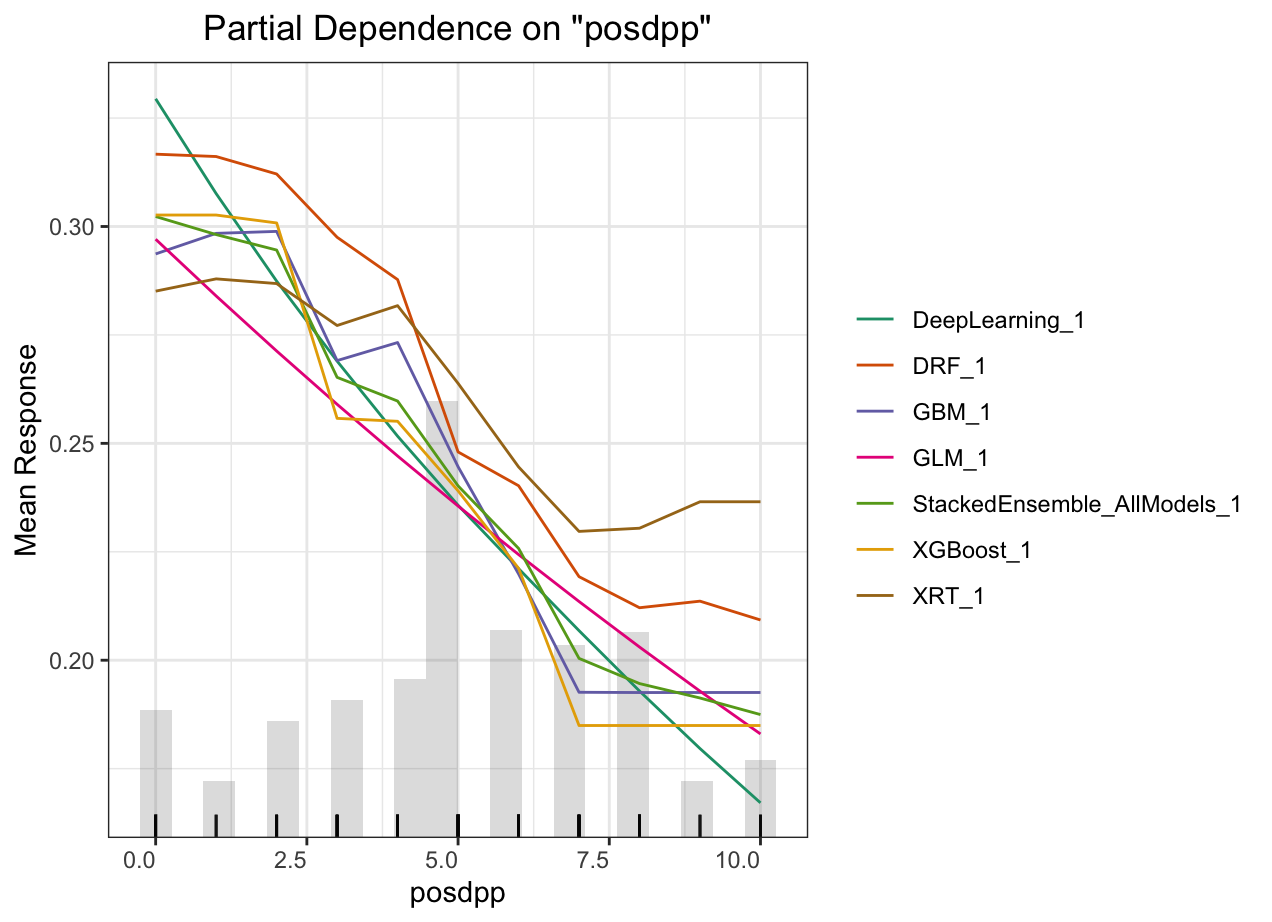
Partial dependence plot (PDP) gives a graphical depiction of the marginal effect of a variable on the response. The effect of a variable is measured in change in the mean response. PDP assumes independence between the feature for which is the PDP computed and the rest.
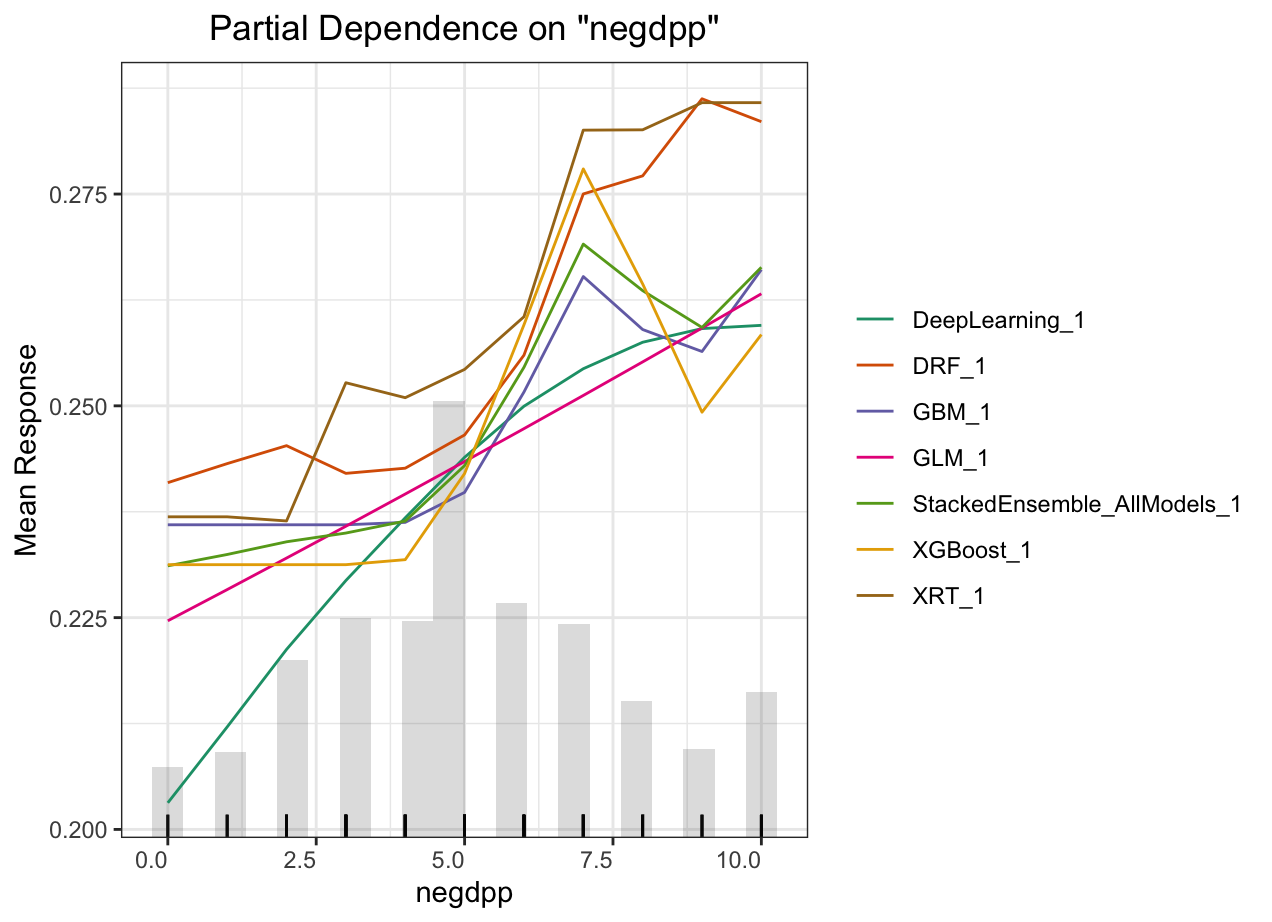
Partial dependence plot (PDP) gives a graphical depiction of the marginal effect of a variable on the response. The effect of a variable is measured in change in the mean response. PDP assumes independence between the feature for which is the PDP computed and the rest.
By Karl Ho



