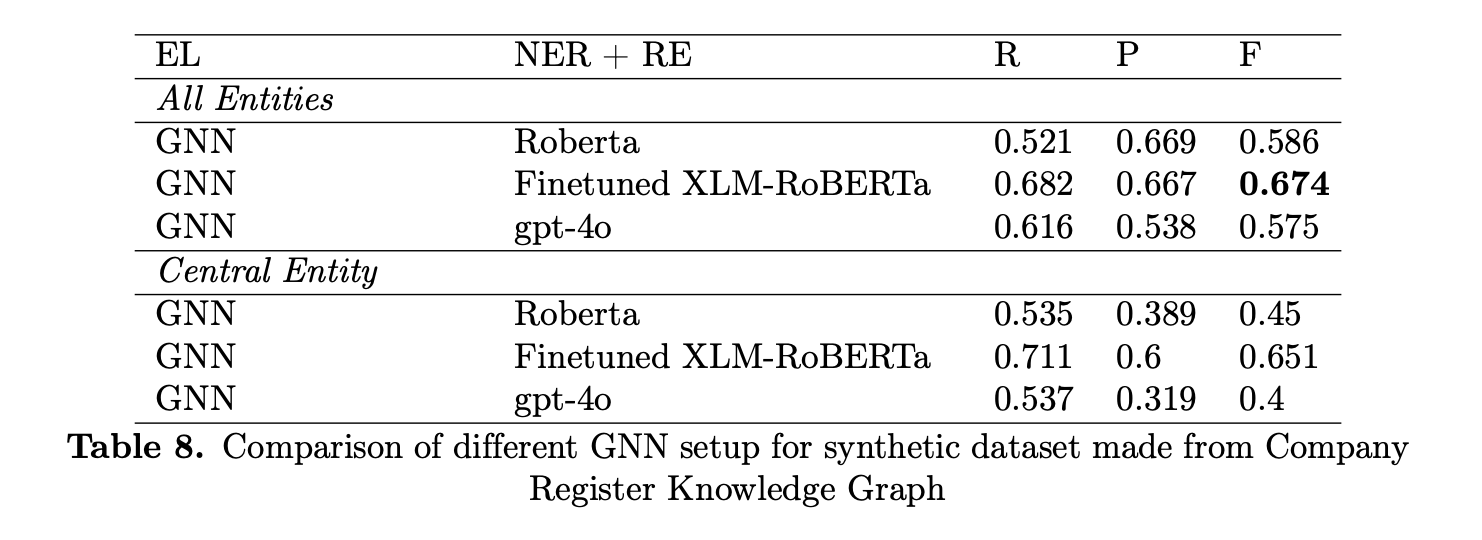
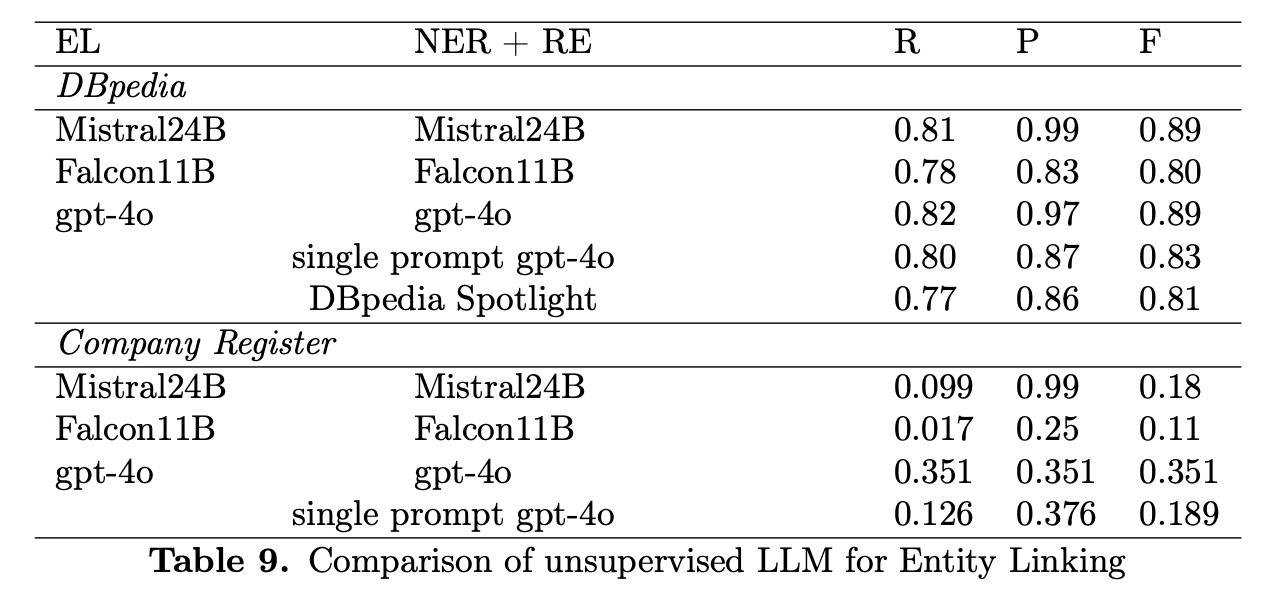
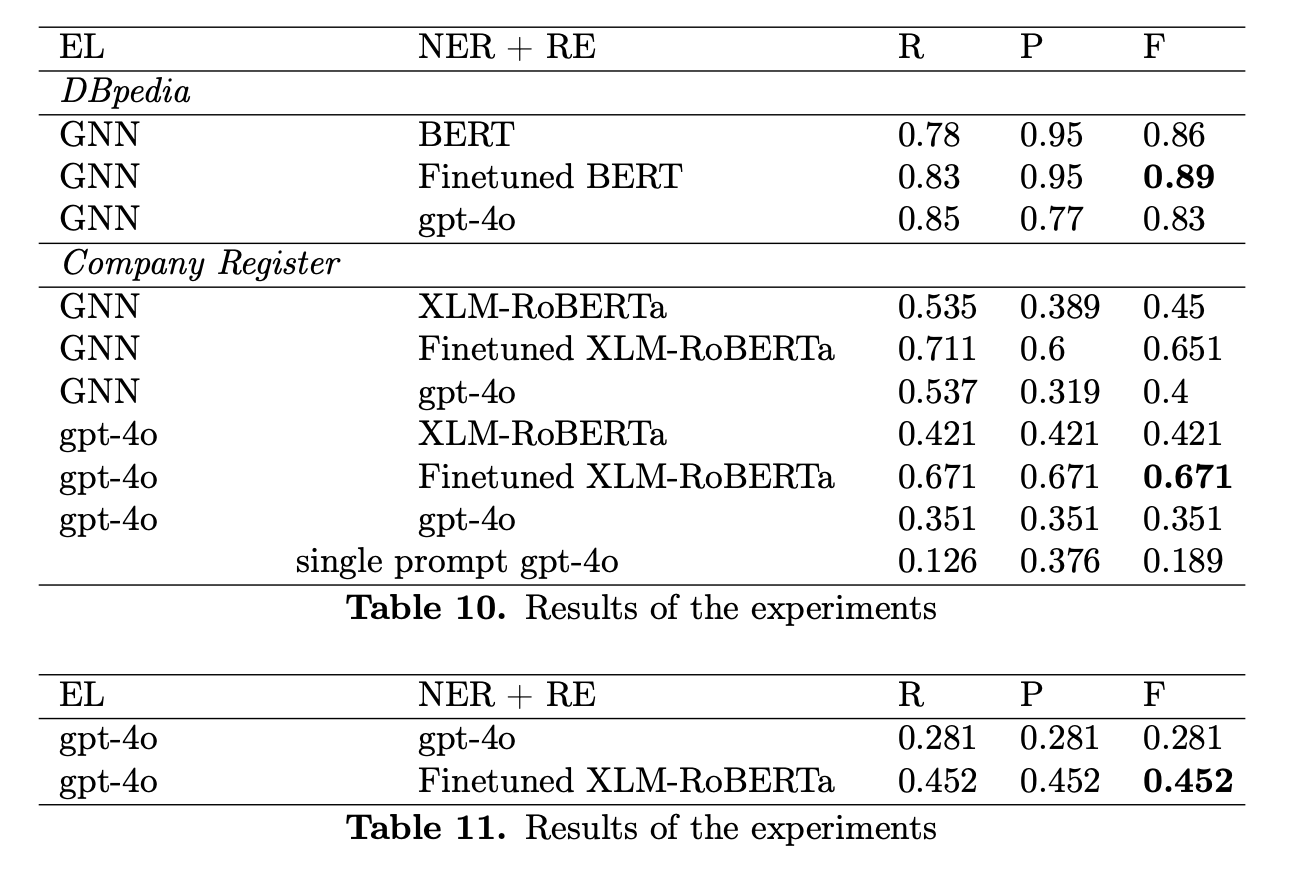
Knowledge graphs
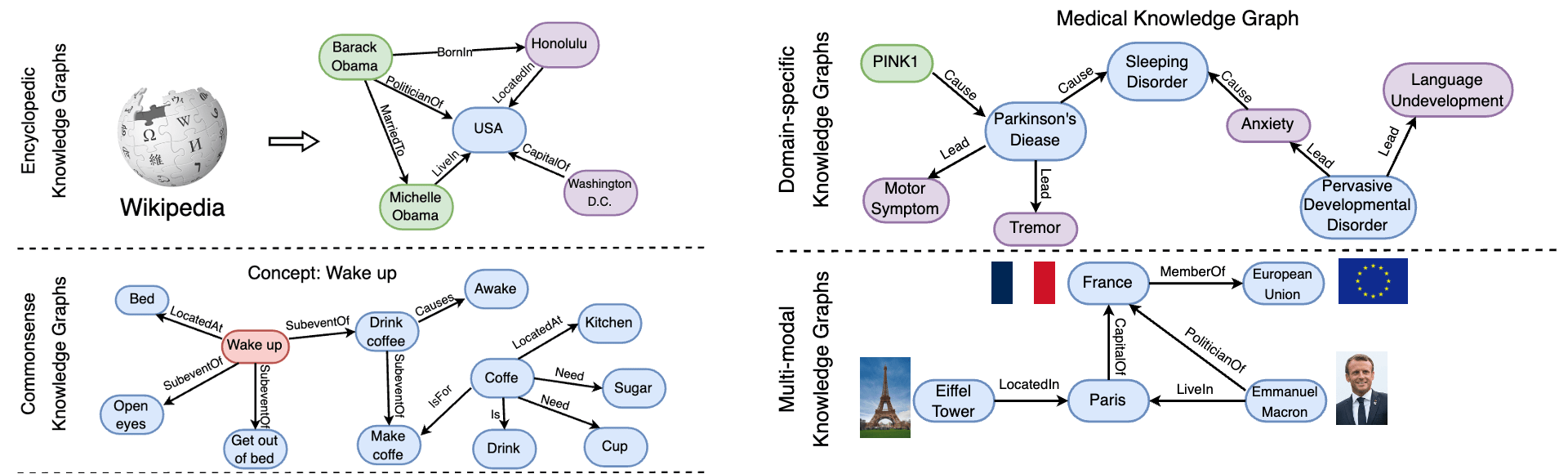
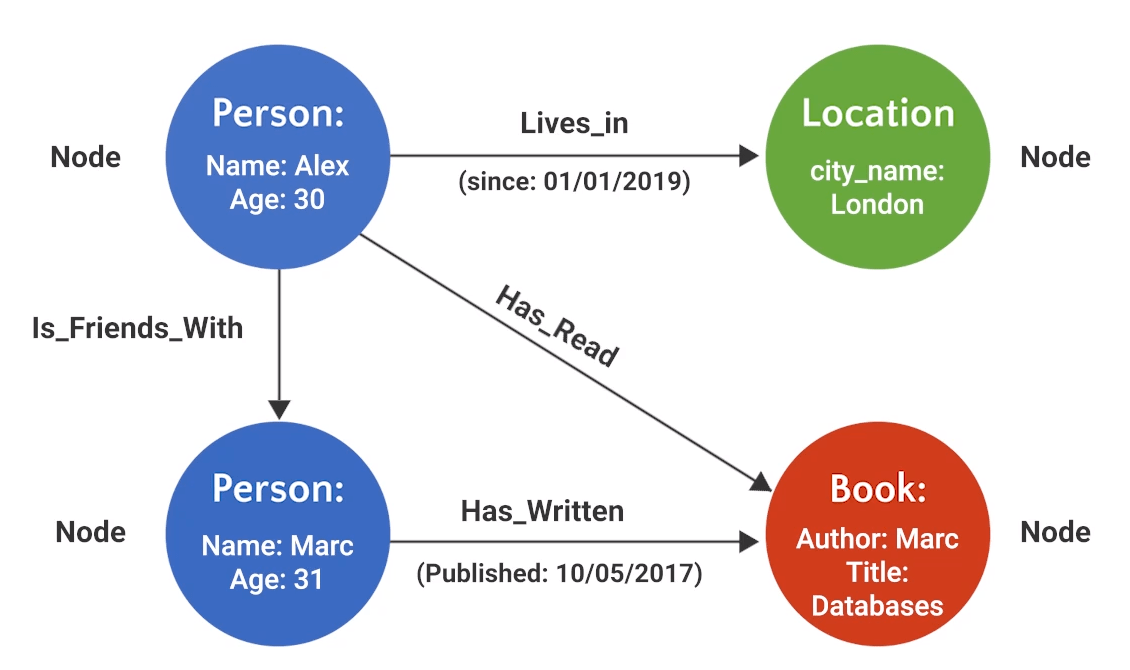
Introduction to KGs
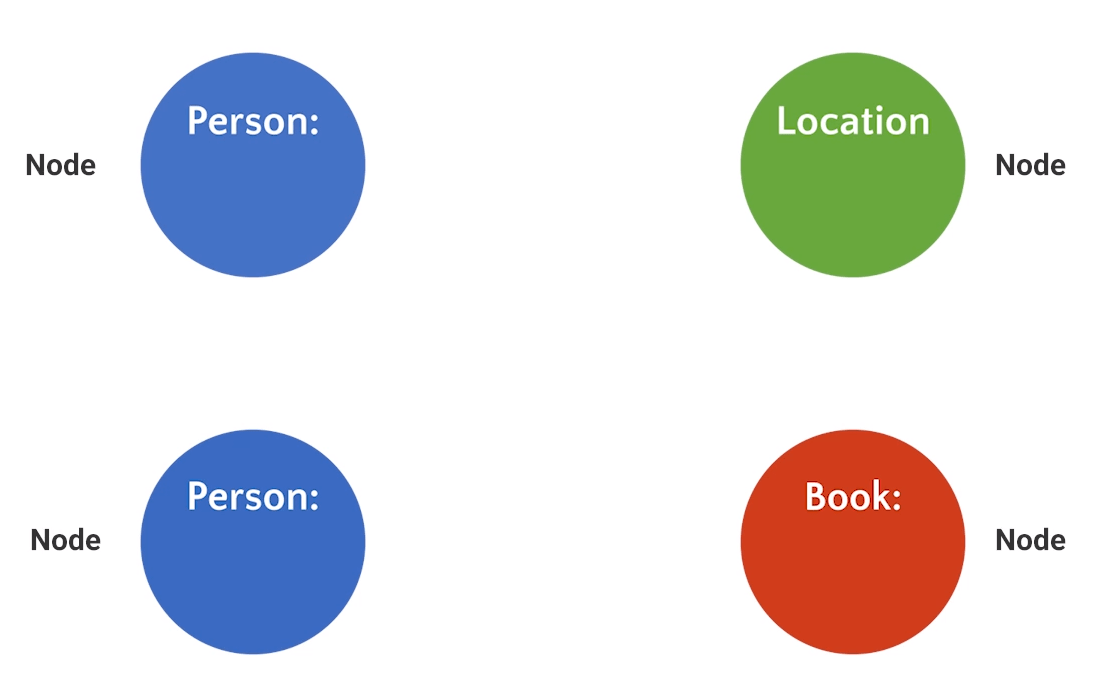
Introduction to KGs
Industry Applications of KGs
1. Banking and Finance
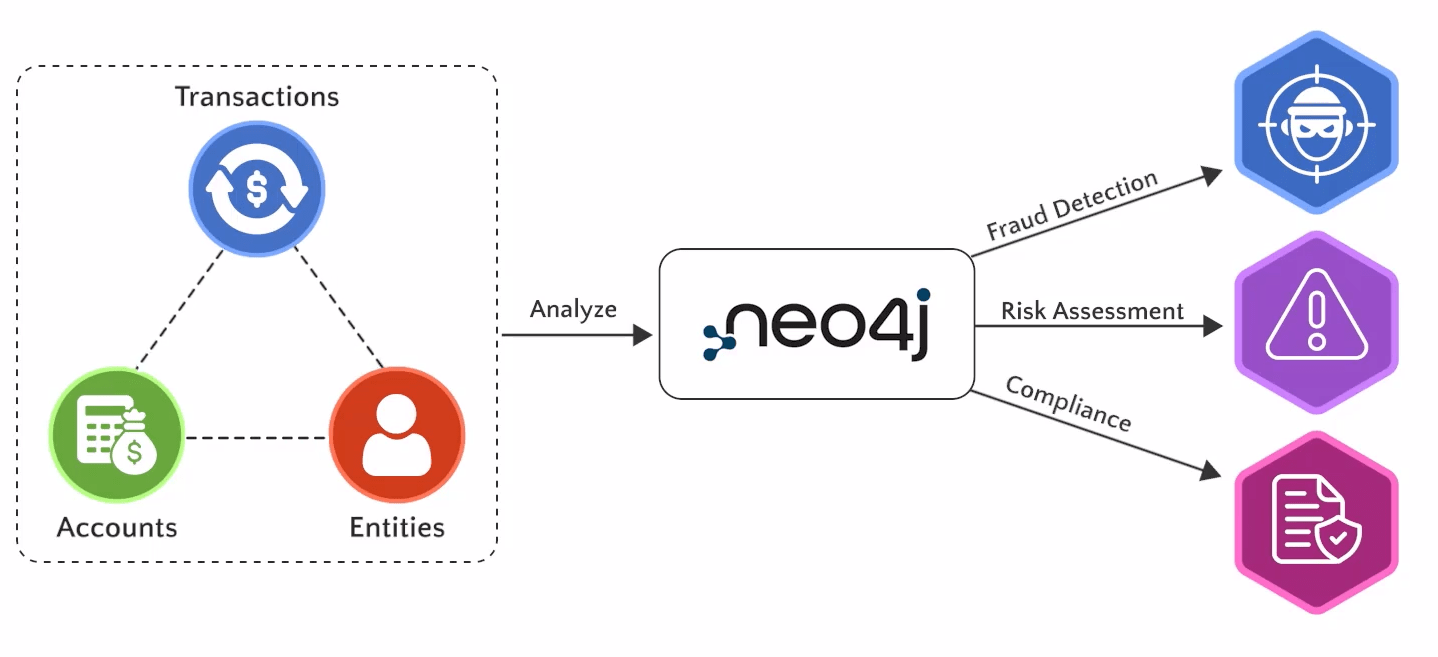
Industry Applications of KGs
2. Retail and E-commerce
Industry Applications of KGs
3. Telecommunications
Industry Applications of KGs
4. Healthcare and Life Sciences
Industry Applications KGs
5. Supply Chain and Logistics

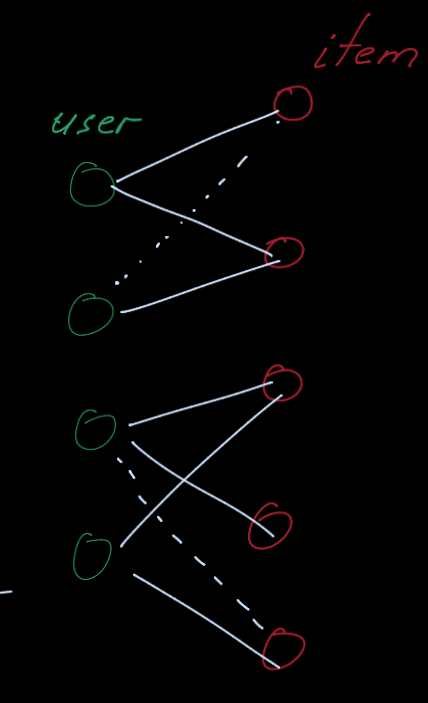
Recommender system can
modeled as a bipartite graph with two node types: users and items.
- Edges connect users and items and indicate user-item interaction
(e.g., click, purchase, review etc.)
- Often edge has timestamp of the interaction.
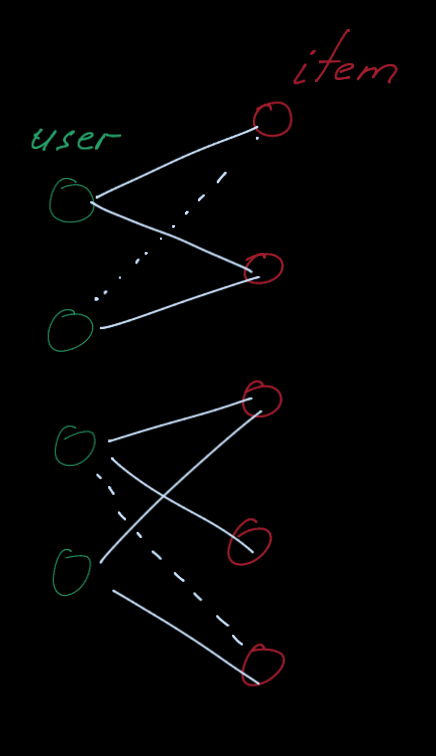
Given past user-item interactions we want to predict new items, the user will
interact in the future
- link prediction task
We need three functions:
- an encoder to generate user embeddings 𝒖
- an encoder to generate item embeddings 𝒗
- Score - a scalar function score(u, v), that returns a real-valued score
link prediction
Graph Collaborative Filtering
Neural Graph Collaborative Filtering (NGCF) explicitly incorporates high-order graph structure when generating user/item embeddings.
Key idea: Use a GNN to generate graph-aware user/item embeddings
Initial shallow embeddings
(not graph-aware)
Use a GNN to propagate
embeddings
NGCF's graph-aware
embeddings
Graph Collaborative Filtering
\boldsymbol{h}_v^{(k+1)}=\operatorname{COMBINE}\left(\boldsymbol{h}_v^{(k)}, \operatorname{AGGR}\left(\left\{\boldsymbol{h}_u^{(k)}\right\}_{u \in N(v)}\right)\right)
Forall \( u \in U \) , \( v \in V \), we set
\( \boldsymbol{u} \leftarrow \boldsymbol{h}_u^{(K)}, \boldsymbol{v} \leftarrow \boldsymbol{h}_v^{(K)} \)
\boldsymbol{h}_u^{(k+1)}=\operatorname{COMBINE}\left(\boldsymbol{h}_u^{(k)}, \operatorname{AGGR}\left(\left\{\boldsymbol{h}_v^{(k)}\right\}_{v \in N(u)}\right)\right)
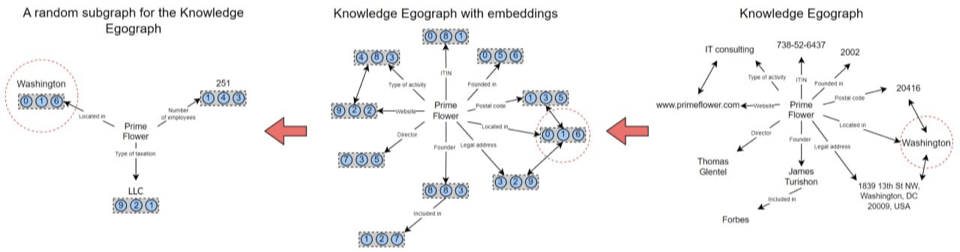
Knowledge Graph Construction

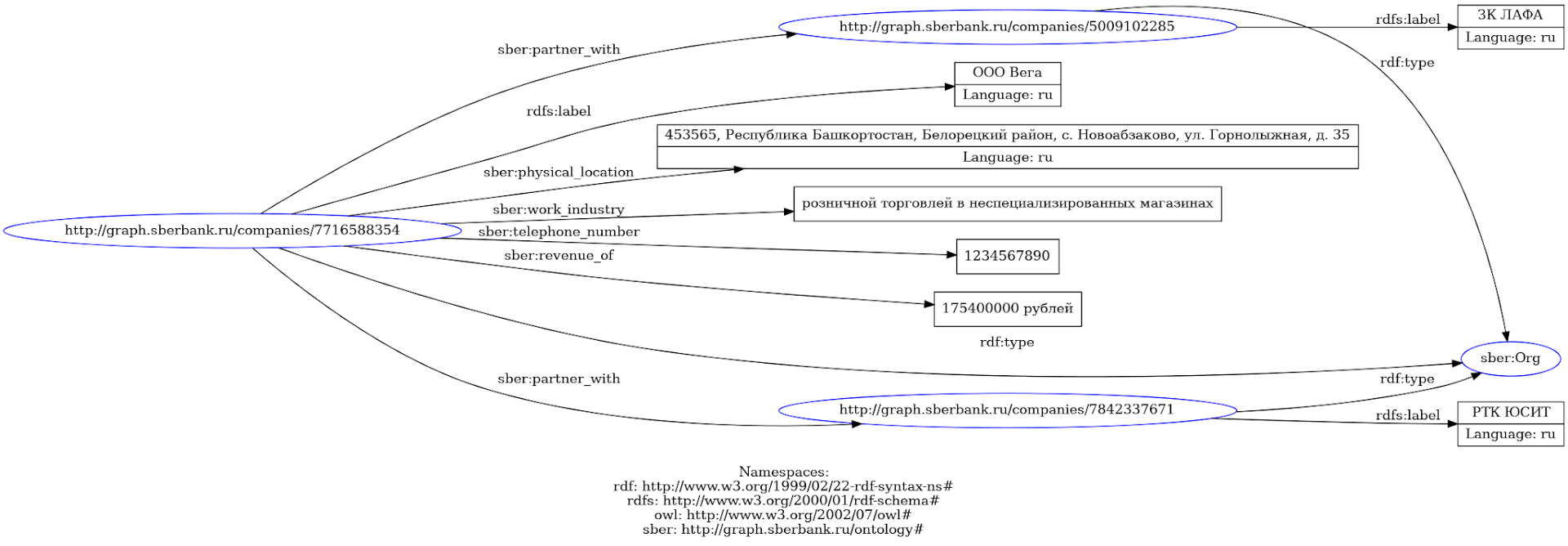
Представитель компании: Добрый день, я являюсь представителем ООО "ВЛАДИСЛАВ" и хотел бы узнать подробности о настройке онлайн-банкинга для нашей компании.
Служба поддержки банка: Здравствуйте! Конечно, я помогу вам с настройкой. Для начала мне понадобятся ваши реквизиты и информация о вашей компании.
Представитель компании: Наша компания занимается торговлей розничными непродовольственными товарами, не включенными в другие группировки, в специализированных магазинах. Мы расположены по адресу 352900, Краснодарский край, г. Армавир, ул. Кропоткина, д. 242, помещение 2. Наш капитал составляет 4 300 000 рублей.
Служба поддержки банка: Спасибо за предоставленную информацию. Для настройки онлайн-банкинга нам потребуется ваше юридическое название, ИНН и реквизиты счета.
Представитель компании: Наше юридическое название - ООО "ВЛАДИСЛАВ", наш ИНН - 1234567890, а реквизиты счета предоставлю вам сейчас. Мы также сотрудничаем с несколькими компаниями, такими как ПЕНЗААГРОПРОМСАД, ТКП ЭЛЗА и ВСЁ ВКУСНОЕ. Это партнеры, с которыми мы часто проводим финансовые операции.
<...>

Subtitle
GraphRAG
G-retriever

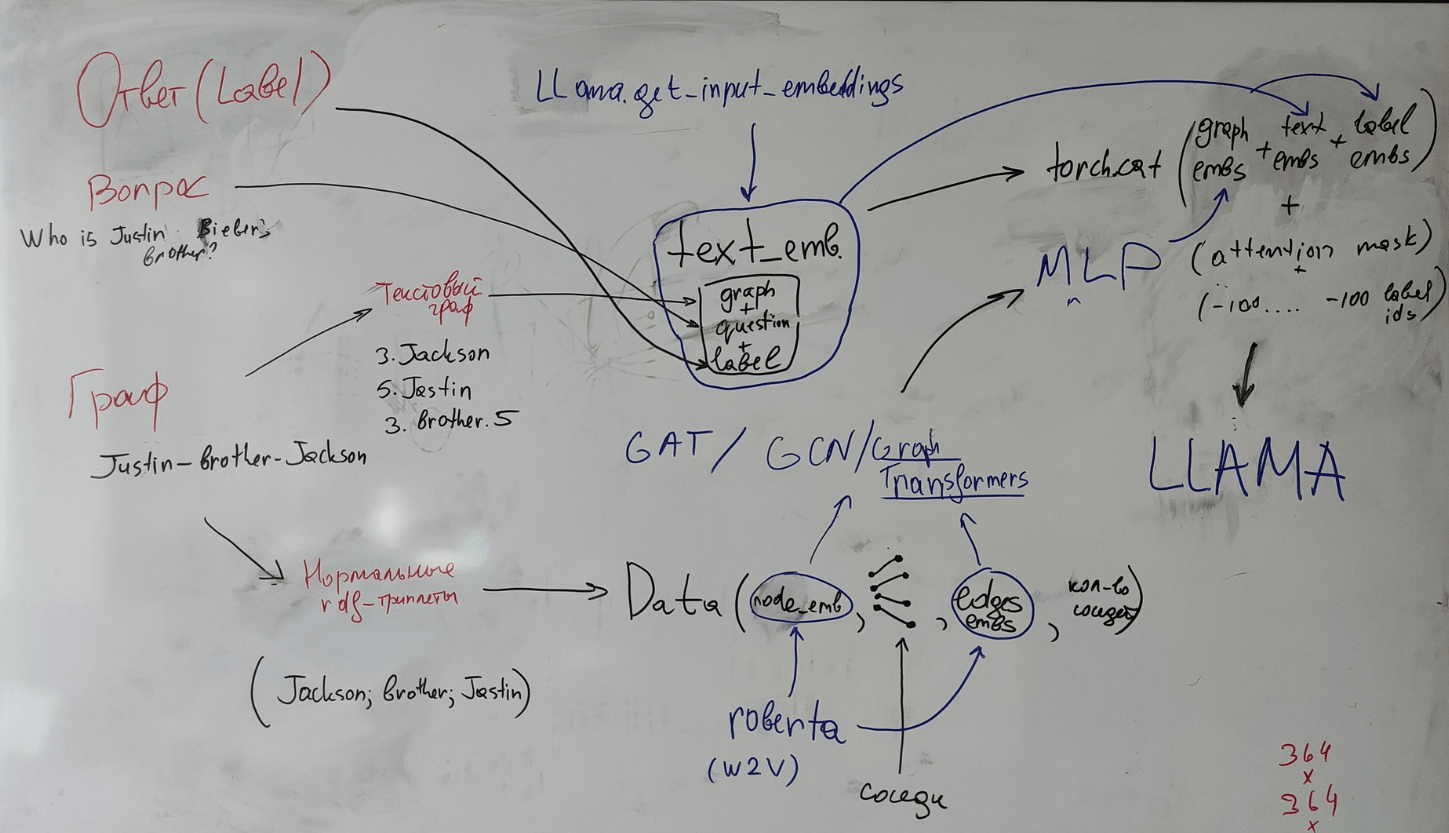
GraphRAG (Graph Retrieval-Augmented Generation)
Subtitle
Актуальность GraphRAG
GraphRAG направлен на преодоление этих ограничений путем интеграции графовых структур, которые позволяют эффективно моделировать и использовать сложные взаимосвязи между данными. Это способствует улучшению как качества поиска релевантной информации, так и процесса генерации текстов, делая их более точными и контекстуально обоснованными.
— методика, объединяющая преимущества графовых структур данных и подходов Retrieval-Augmented Generation (RAG) для улучшения качества и точности генерируемого текста.
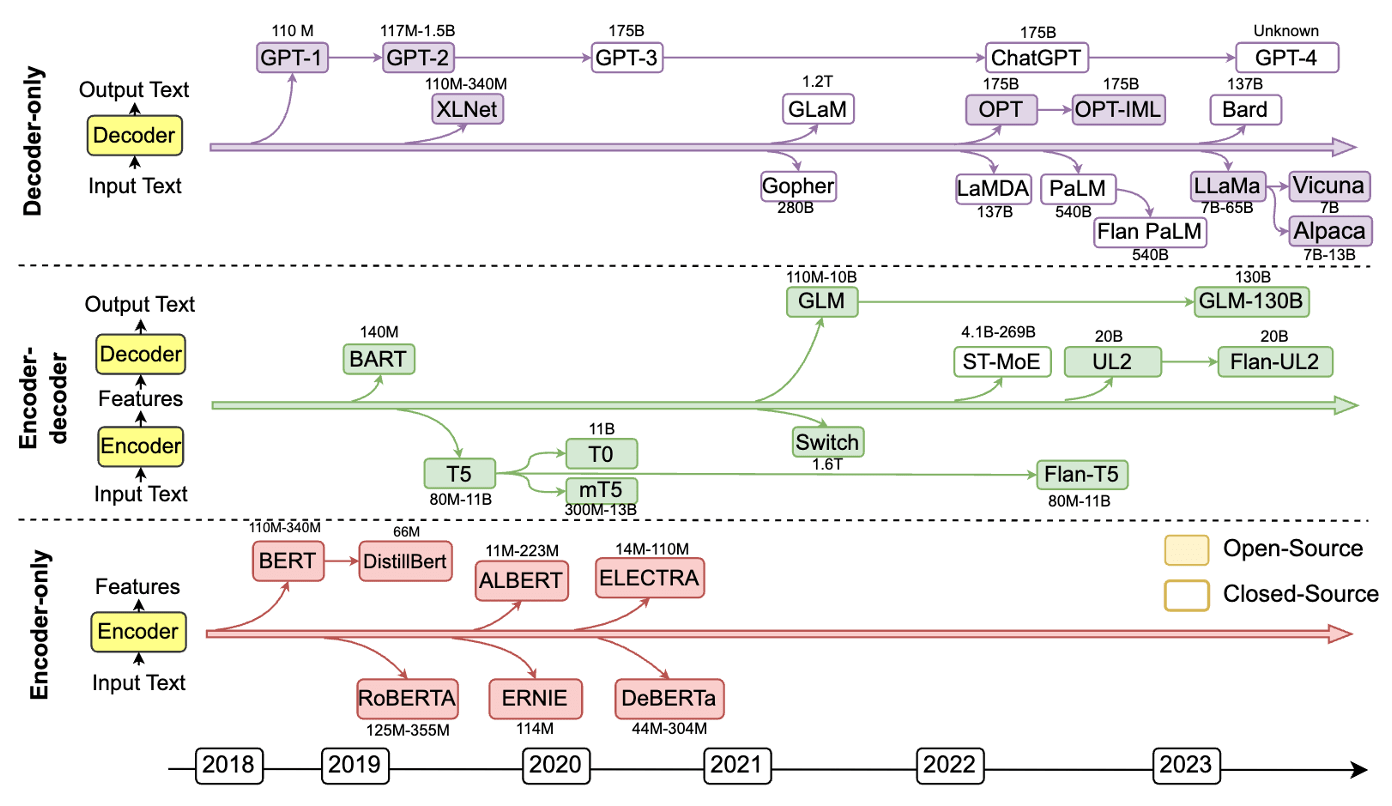
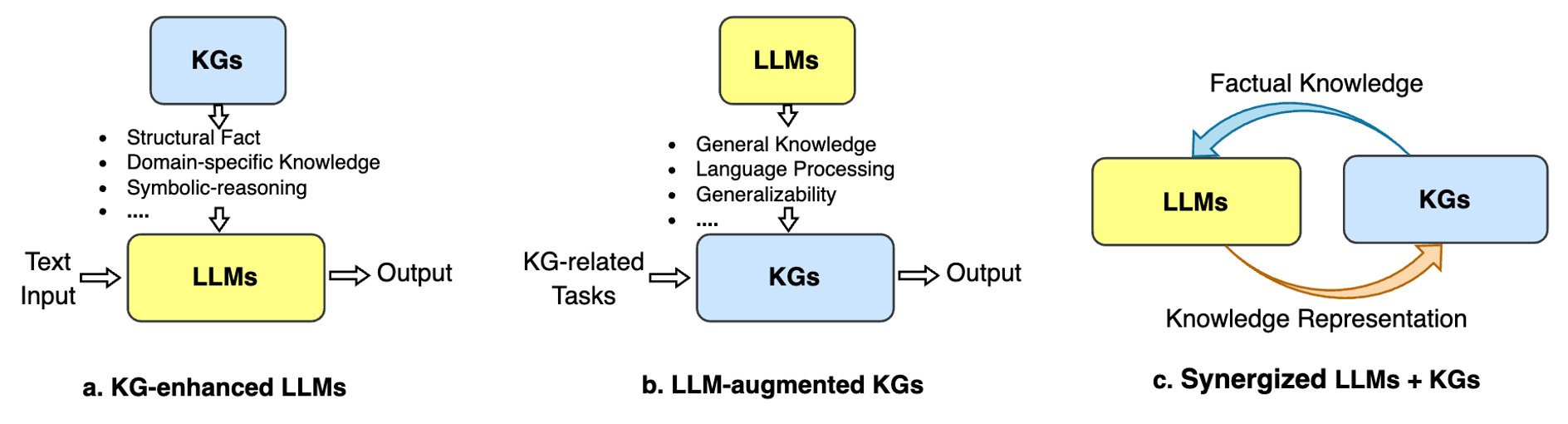
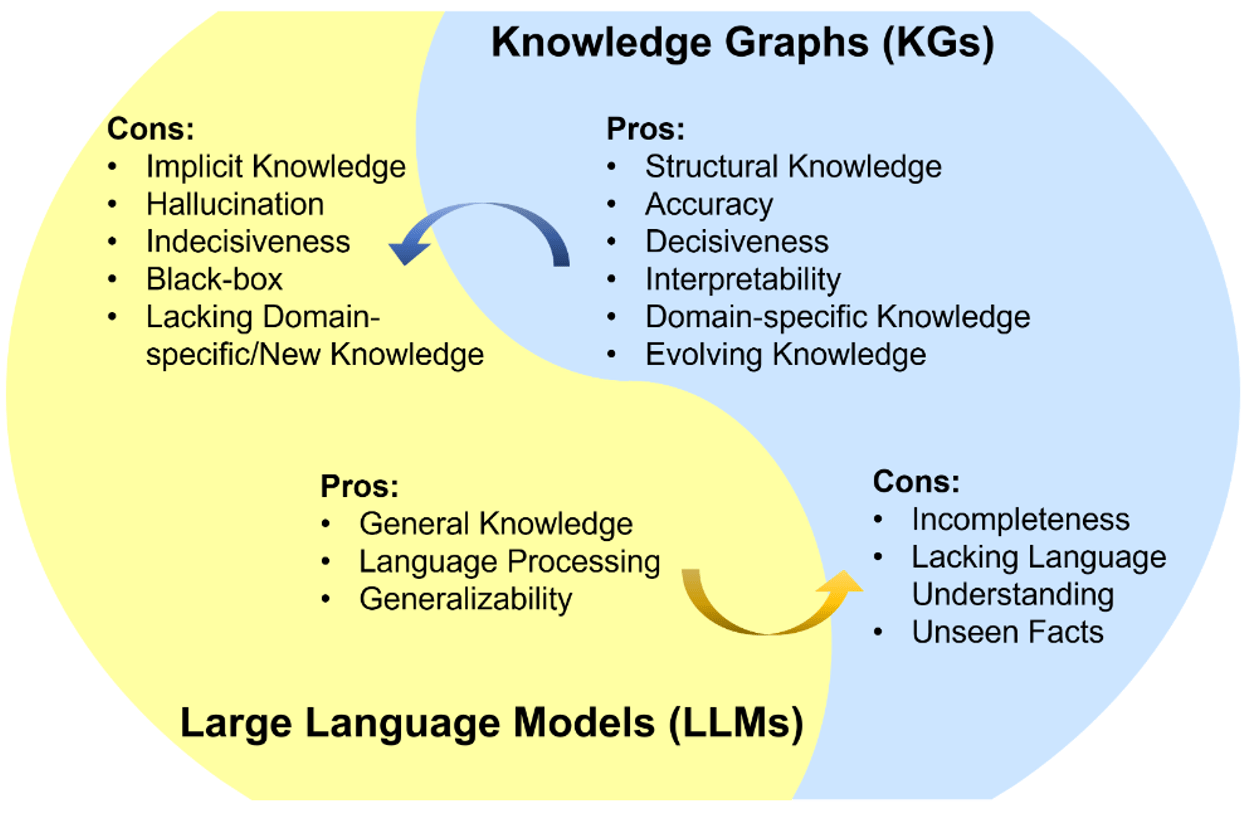
В (Pan et al., 2023) был предложен роудмап развития LLM и графов знаний (KG), включающий три основных направления:
1. KG-enhanced LLMs: Интеграция графов знаний в процессы предобучения и инференса LLM для углубления понимания моделей приобретённых знаний.
2. LLM-enhanced KGs: Использование LLM для различных задач графов знаний, таких как встраивание, дополнение, построение, генерация текста из графов и ответ на вопросы.
3. Совместные подходы LLMs+KGs: Взаимное усиление LLM и графов знаний через двунаправленный вывод, основанный на данных и знаниях.
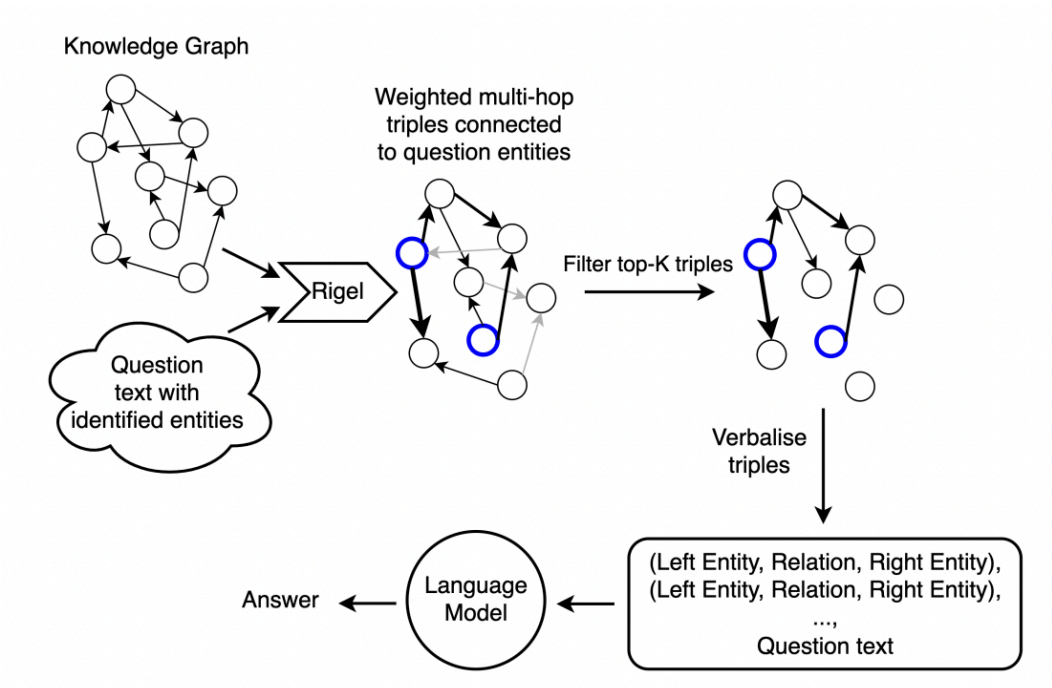
THINK-ON-GRAPH
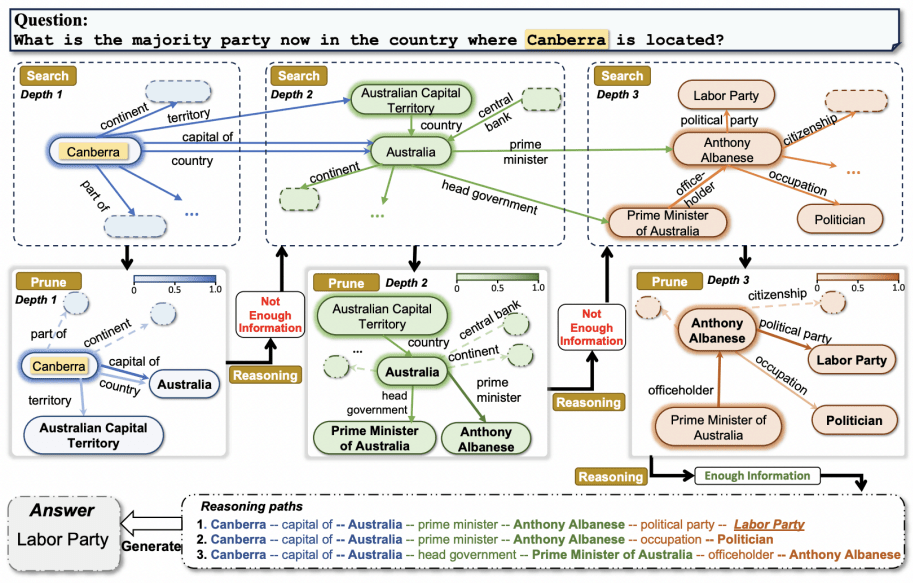
Метод ToG состоит из трёх основных фаз: инициализация, исследование (exploration) и рассуждение (reasoning). В рамках каждой фазы используются механизмы beam search для итеративного исследования возможных путей рассуждения на графе знаний до тех пор, пока LLM не определит, что на вопрос может быть получен ответ на основе текущих путей рассуждения.
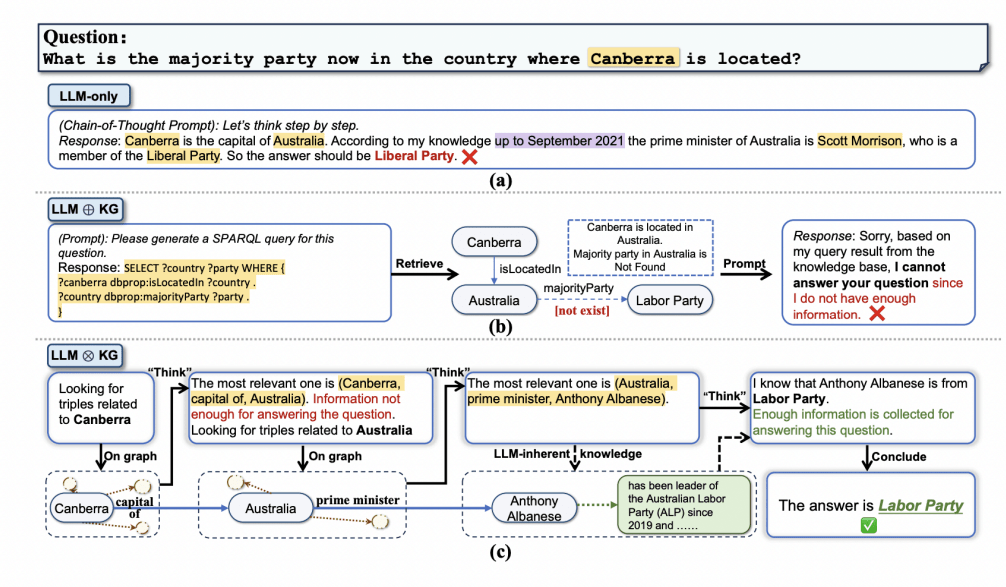
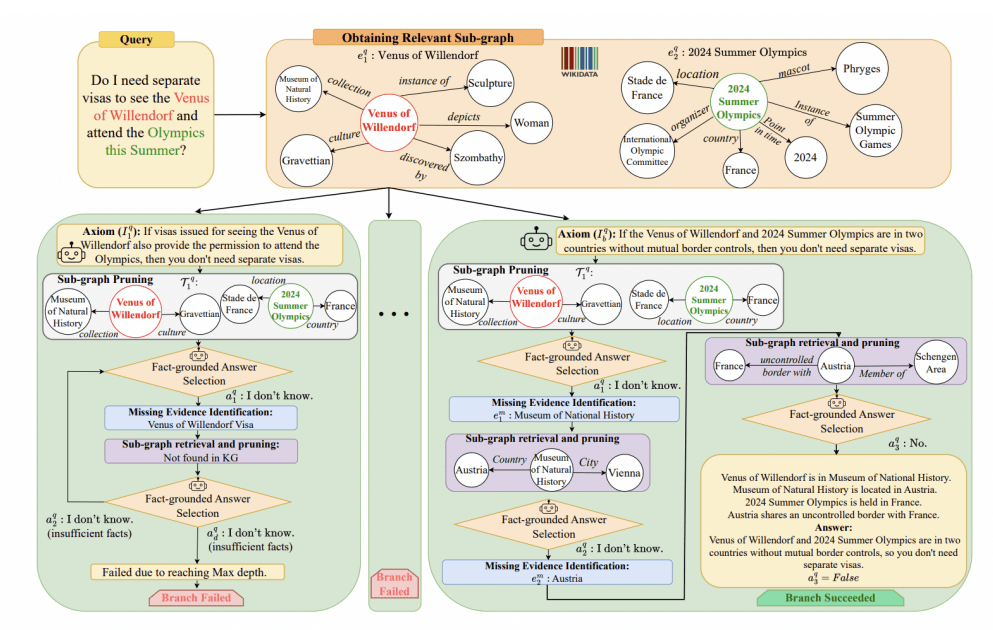
В работе (Toroghi et al., 2024) рассматривается другой метод улучшения рассуждений в процессе ризонинга посредством аксиом здравого смысла. Авторы делают акцент на сложностях подобных гибридных моделей в ответах на общие вопросы. Commonsense reasoning является одной из ключевых возможностей, предоставляемых LLMs (Shen and Kejriwal, 2021; Zhao et al., 2024). В теории, использование LLMs для рассуждения над набором извлечённых фактов из графов знаний может показаться простым и эффективным способом выполнения задач Commonsense Knowledge Graph Question Answering (KGQA). Однако на практике LLMs склонны вводить необоснованную или некорректную информацию в процесс рассуждения, что называется галлюцинацией (Ye et al., 2023; Tonmoy et al., 2024).
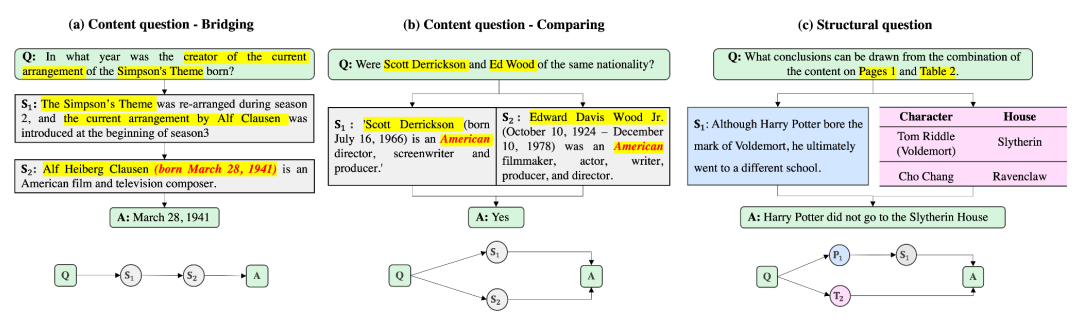
Промптинг, TF-IDF, KNN и иерархии документов
MoGG
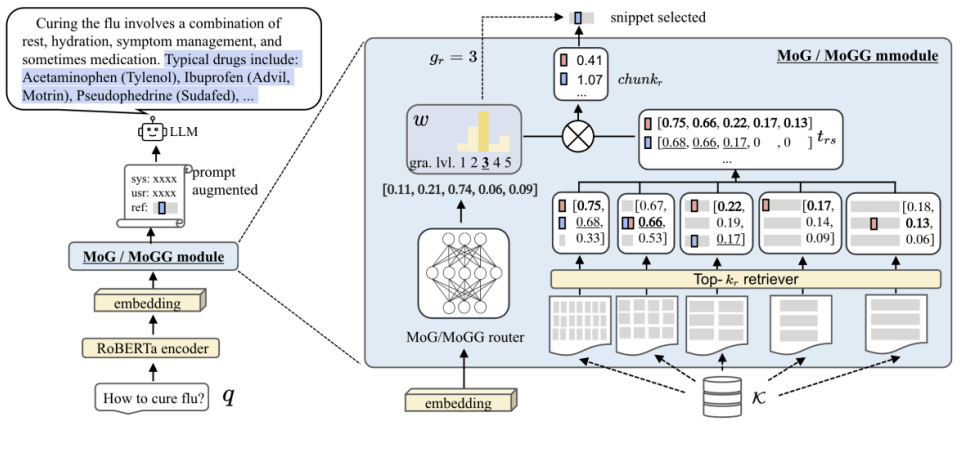
RAPTOP
Процесс построения дерева:
1. Сегментация текста: текст разделяется на короткие сегменты длиной до 100 токенов. Если предложение выходит за этот предел, оно переносится целиком в следующий сегмент, чтобы сохранить смысловую цельность.
2. Создание эмбеддингов сегментов с помощью SBERT (BERT-based encoder).
3. Кластеризация сегментов с использованием алгоритма кластеризации, основанного на Gaussian Mixture Models (GMM). Кластеризация подразумевает мягкое разбиение, где сегменты могут принадлежать нескольким кластерам. Для снижения размерности векторов используется метод UMAP.
4. Саммаризация: сегменты внутри кластеров обобщаются с помощью языковой модели (в экспериментах используется gpt-3.5-turbo). Далее итоговые резюме преобразовываются в эмбеддинги, после чего процесс кластеризации и резюмирования повторяется, пока не получится окончательное дерево.
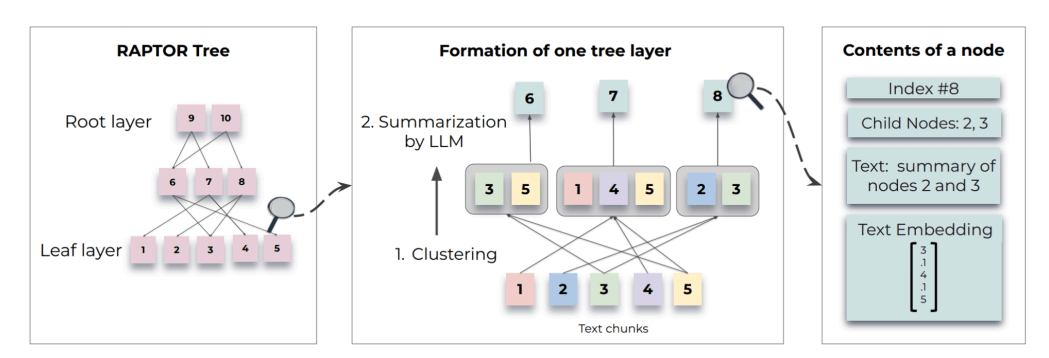
GraphRAG pipeline
1. Исходные документы → Текстовые чанки
2. Текстовые чанки → Графовые элементы
3. Графовые элементы → Саммари графовых объектов
4. Саммари объектов → Графовые сообщества
5. Графовые сообщества → Саммари сообществ
6. Саммари сообществ → Community Answers → Global Answer
Global Answer:
- Ответы сортируются по убыванию их полезности.
- Наиболее полезные ответы по порядку добавляются в новое контекстное окно LLM до тех пор, пока не достигнут лимит токенов.
- Итоговое контекстное окно используется для формирования глобального ответа, который возвращается пользователю.
1. Методы на основе вероятностных графовых моделей:
○ Эти методы используют вероятностные графы для моделирования сообществ. Например, методы на основе скрытых Марковских моделей или стохастических блоковых моделей.
○ Они традиционно применяют различные типы предварительных знаний, таких как вероятностные распределения или связи между узлами, для определения структуры сообществ.
2. Методы глубокого обучения: ○ В последние годы растёт интерес к использованию глубоких нейронных сетей для обнаружения сообществ. Эти подходы часто преобразуют данные сети в низкоразмерные представления, которые затем анализируются для выявления скрытых структур. ○ Одним из популярных направлений является использование графовых нейронных сетей (GNN), которые обучаются на графах и могут эффективно выявлять сообщества на основе связности узлов.
Алгоритмы обнаружения сообществ
Neo4j among Various DB Types
Neo4j among Various DB Types

- Organize data into tables.
- Ideal for structured data and
complex transactions.

- Designed for flexibility, scalability, and handling unstructured or semi-structured data.
Neo4j among Various DB Types
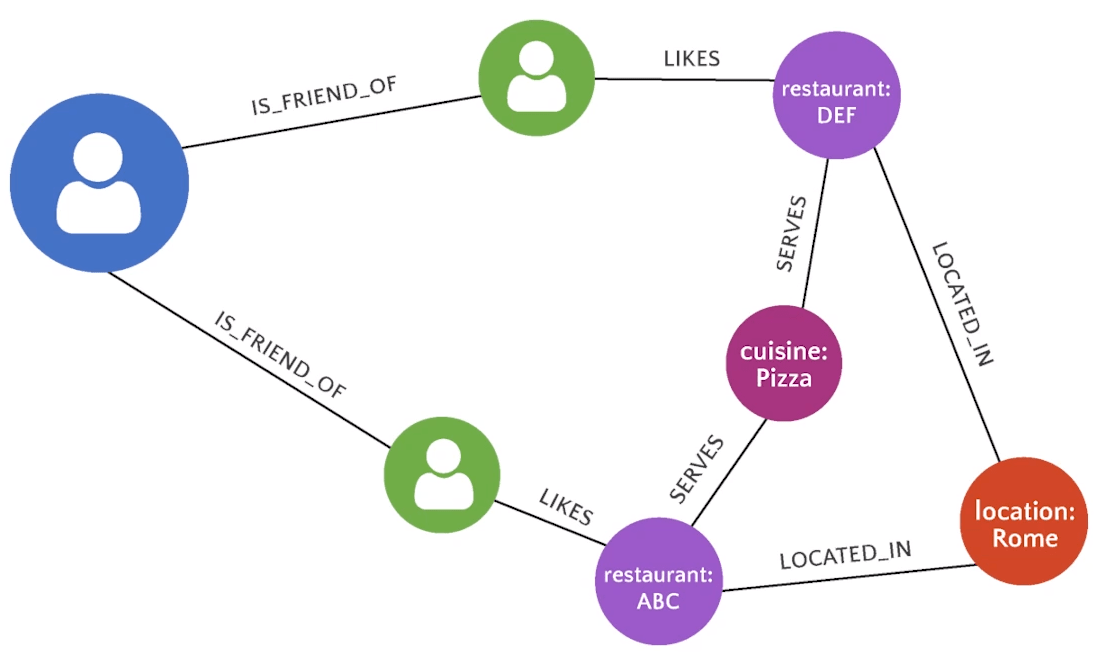
Data Connectivity
Interconnected Data
Copy of deck
By karpovilia




