Python and binary data
Denis Kataev
Tinkoff.ru
О чем я расскажу
list.append — O(?)
Что быстрей?
In [1]: test = lambda s, n: list(range(s)) .extend(range(n))
In [2]: %timeit test(20_000, 100)
? µs ± ? µs per loop
(mean ± std. dev. of 7 runs, 1000 loops each)
In [3]: %timeit test(10_000, 200)
? µs ± ? µs per loop
(mean ± std. dev. of 7 runs, 1000 loops each)Что быстрей?
In [1]: test = lambda s, n: list(range(s)) .extend(range(n))
In [2]: %timeit test(20_000, 100)
644 µs ± 2.24 µs per loop
(mean ± std. dev. of 7 runs, 1000 loops each)
In [3]: %timeit test(10_000, 200)
211 µs ± 1.63 µs per loop
(mean ± std. dev. of 7 runs, 1000 loops each)list — linked list?
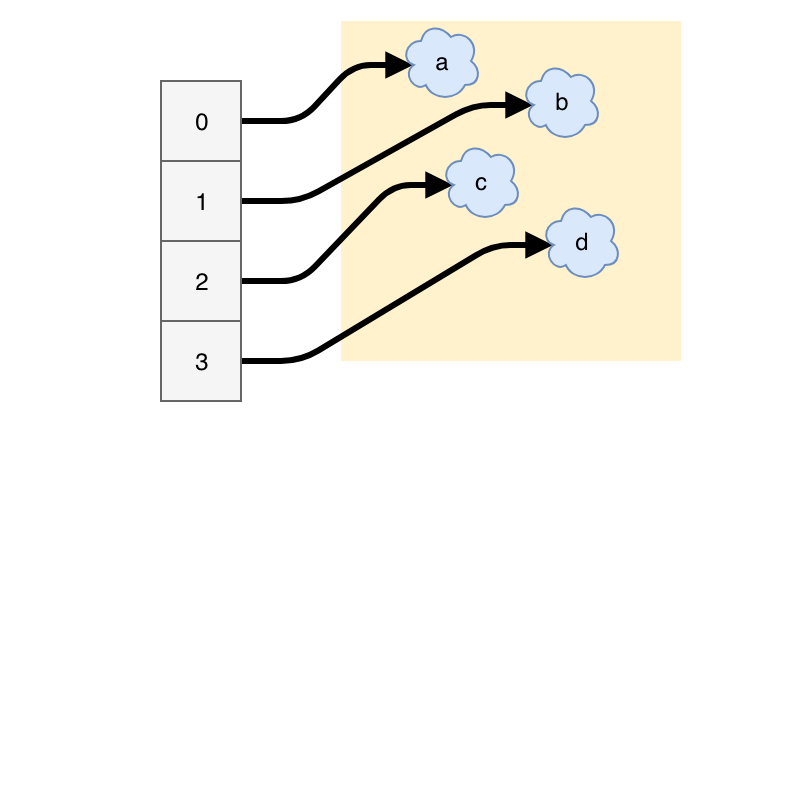
a = ['a', 'b', 'c', 'd']
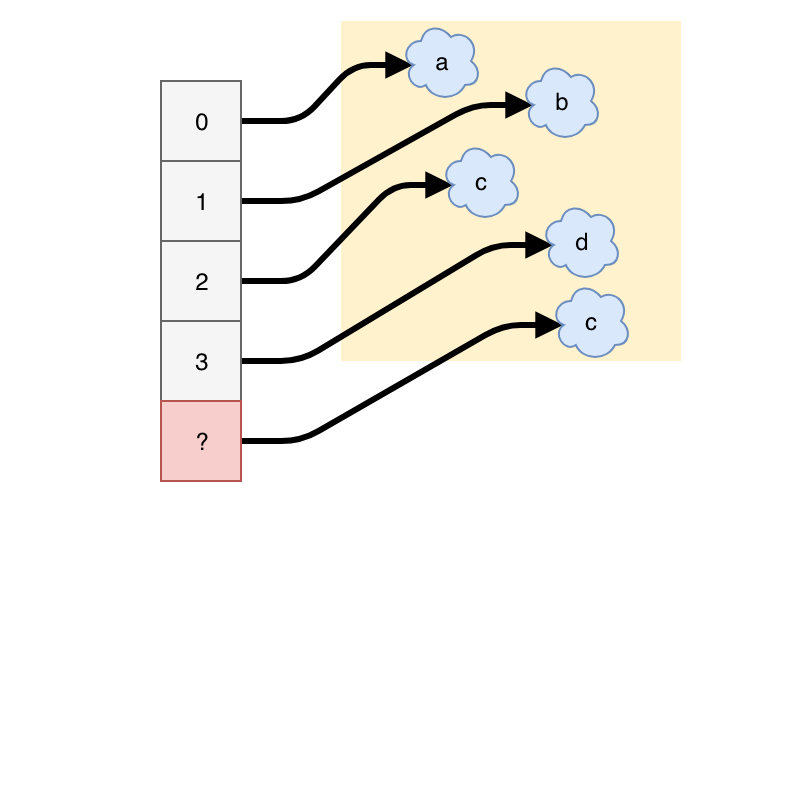
a = ['a', 'b', 'c', 'd']
a.append('c')How does it work?
n_allc = (size_t)newsize +
(newsize >> 3) +
(newsize < 9 ? 3 : 6);
# 0,4,8,16,25,35,46,58,72,88,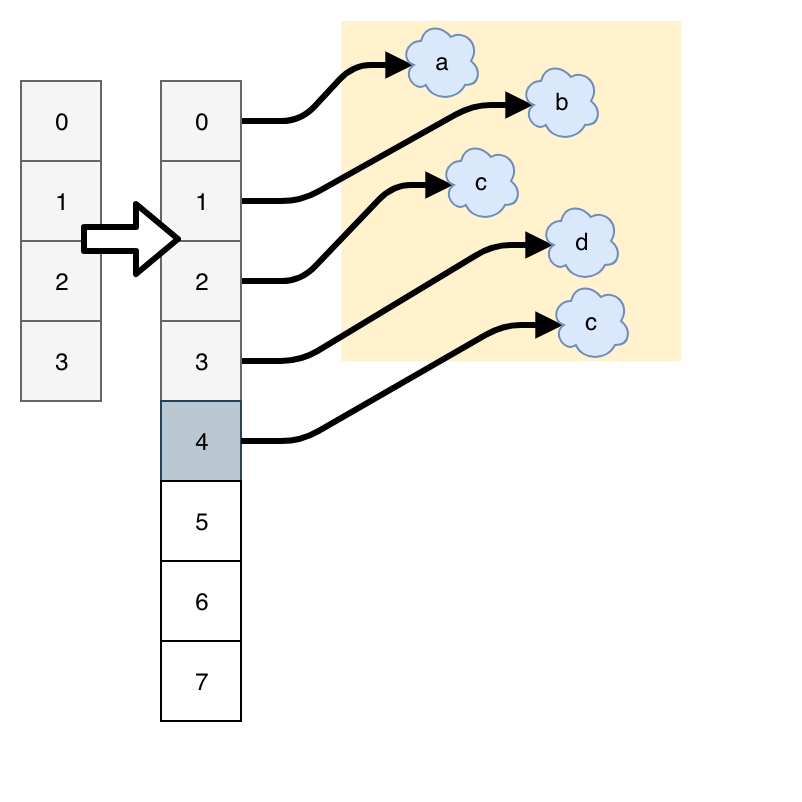
O(?)
In [1]: lst = []
In [2]: for x in range(100):
...: lst.append(x)O(352) 😱
In [1]: lst = []
In [2]: for x in range(100):
...: lst.append(x)In [1]: import sys
...: lst = []
...: size = sys.getsizeof(lst)
...: o = 0
...:
...: for x in range(100):
...: lst.append(x)
...: if size != sys.getsizeof(lst):
...: o += len(lst) - 1
...: print(len(lst) - 1, end=',')
...: size = sys.getsizeof(lst)
0,4,8,16,25,35,46,58,72,88,
In [2]: o
Out[2]: 352
fix: replace elements
lst = [None] * 100
for x in range(100):
lst[x] = xList elements — links
import array
List for fixed length elements
Limited set of element types
- Integer
- Float
- Char
- Unicode Char
- Signed
- Unsigned
array('L', [1, 2, 3, 4])
array('i', [1, 2, 3, 4])

Appending is like list
In [1]: import sys
...: lst = array.array('I')
...: size = sys.getsizeof(lst)
...: o = 0
...:
...: for x in range(100):
...: lst.append(x)
...: if size != sys.getsizeof(lst):
...: o += len(lst) - 1
...: print(len(lst) - 1, end=',')
...: size = sys.getsizeof(lst)
0,4,8,16,25,34,44,54,65,77,89,Work with bytes
- array.frombytes
- array.tobytes
- ...
- array.tofile
No custom types
Why do we need it?
Read only db
- Minimal overhead
- Fast search
- One file — one table
- Without gaps
- All elements one type
- Write once, read many
- Minimal size
- No dependencies
Пример
- Two fields (user id, password hash)
- Sorted by user id
- Binary search algorithm
- Write from Python
- Read from Python, C, etc ...
Implementation
- User id — unsigned int
- Password hash — unsigned int
- Limit user id to 2^32 values
- Sort in memory NLog(N)
- Write in one file
- Read making Log(N) ops
Unsigned int?
In [1]: bin(7)
Out[1]: '0b111'
In [2]: bin(10)
Out[2]: '0b1010'Don't keep the money in float
More
In [1]: struct.pack('f', 1)
Out[1]: b'\x00\x00\x80?'
In [2]: struct.pack('f', float('inf'))
Out[2]: b'\x00\x00\x80\x7f'
In [3]: struct.pack('f', float('-inf'))
Out[3]: b'\x00\x00\x80\xff'
In [4]: struct.pack('f', float('nan'))
Out[4]: b'\x00\x00\xc0\x7f'import struct
Unpack bytes to values
In [1]: struct.pack('II', 459, 2123)
Out[1]: b'\xcb\x01\x00\x00K\x08\x00\x00'
In [2]: b = (b'\xff\xff\xff\xff'
...: b'\xff\xff\xff\xff')
In [3]: struct.unpack('II', b)
Out[3]: (4294967295 , 4294967295 )
In [4]: struct.unpack('ff', b)
Out[4]: (nan, nan)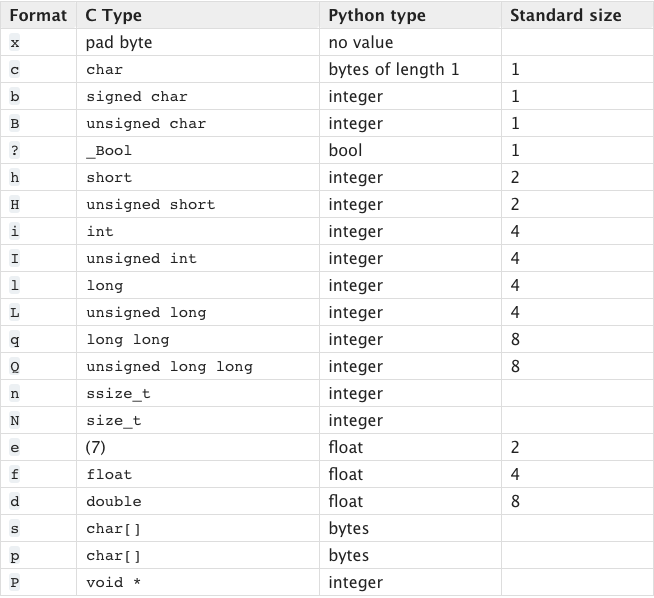
This is copying memory
In [1]: import struct
In [2]: b = b'asde'
In [3]: r = struct.unpack('i', b)
In [4]: id(r), id(r[0]), id(b)
Out[4]: (4513840992 , 4513694160 , 4513841760 )
In [5]: id(b) == id(r[0])
Out[5]: False
In [6]: id(b) == id(r)
Out[6]: False
Conversion without additional memory
In [1]: bytes(1)
Out[1]: b'\x00'
In [2]: bytes(1.0)
-----------------------------------------------------------
TypeError Traceback (most recent call last)
----> 1 bytes(1.0)
TypeError: cannot convert 'float' object to bytes
In [3]: bytes({})
Out[3]: b''
In [4]: bytes({1:2})
Out[4]: b'\x01'
In [5]: bytes(object())
------------------------------------------------------------
TypeError Traceback (most recent call last)
----> 1 bytes(object())
TypeError: cannot convert 'object' object to bytesBuffer protocol
- bytes()
- bytearray()
- memoryview()
buffer()
Classes with buffer protocol support
import ctypes
Numeric types
- с_bool
- c_uint[16,32,64]
- c_int[16,32,64]
- c_long
Other types
- ctypes.c_char
- ctypes.c_ssize_t
- ctypes.c_void_p # указатели
- ctypes.c_void_p * 10 # массив указателей
Structs
- ctypes.Union
- ctypes.Struct
- структуры из структур 😎
- массивы из структур
In [1]: class UserPassword(ctypes.Structure):
...: _fields_ = ('id', ctypes.c_uint32),
...: ('hash', ctypes.c_uint32)
In [2]: UserPassword()
Out[2]: <__main__.Test at 0x10d20fea0>
In [3]: t = UserPassword()
In [4]: t.id, t.hash
Out[4]: (0, 0)
In [5]: t.id, t.hash = (1,2)How is it stored
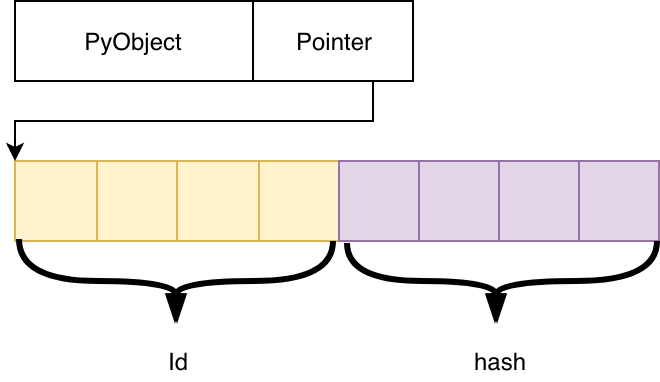
Real arrays
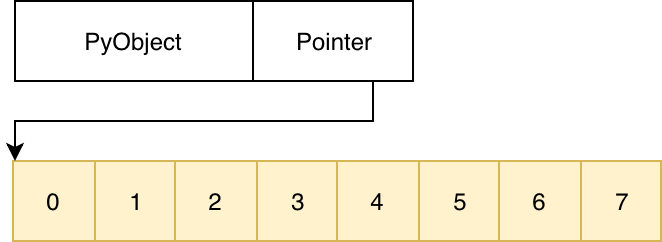
Real array
In [1]: import ctypes
In [2]: array_t = ctypes.c_uint16 * 4
In [3]: array = array_t()
In [4]: array[0], array[3]
Out[4]: (0, 0)Two objects and one memory area
In [7]: l = ctypes.c_uint64.from_buffer(array)
In [8]: l.value
Out[8]: 0
In [9]: l.value = 123
In [10]: array[0], array[1]
Out[10]: (123, 0)
Memory?
Shoot yourself in the foot!
All is object
import ctypes
class PyObject(ctypes.Structure):
_fields_ = [
('ref_count', ctypes.c_ssize_t),
('type_pnt', ctypes.c_void_p),
]
In [2]: s = 'asd'
In [3]: o = PyObject.from_address(id(s))
In [4]: o.type_pnt
Out[4]: 4416726352
In [5]: o.type_pnt == id(str)
Out[5]: True
In [6]: o.ref_count
Out[6]: 1In [2]: s = 'asd'
In [3]: o = PyObject.from_address(id(s))
In [4]: l = [s,s,s]
In [5]: o.ref_count
Out[5]: 4
In [6]: del s
In [7]: o.ref_count
Out[7]: 3Mutable string
class PyVarObject(ctypes.Structure):
_fields_ = PyObject._fields_ + [
('size', ctypes.c_ssize_t),
]
class PyBytesObject(ctypes.Structure):
_fields_ = PyVarObject._fields_ + [
('hash', ctypes.c_ssize_t),
('data', ctypes.c_char)
]
In [11]: s = b'123'
In [12]: o = PyBytesObject.from_address(id(s))
In [13]: o.data = b'0'
In [14]: s
Out[14]: b'023'
In [16]: o.hash == hash(s) == hash(b'123')
Out[16]: True
In [17]: s == b'123'
Out[17]: FalseIn [18]: s = b'123'
In [19]: o = PyBytesObject.from_address(id(s))
In [20]: o.hash += 1
In [21]: d = {s:1, b'123':2}
In [22]: d
Out[22]: {b'123': 1, b'123': 2}
In [23]: d[b'123'], d[s]
Out[23]: (2, 1)
In [24]: s == b'123'
Out[24]: TrueFinal implementation Read only db
import ctypes
class UserPassword(ctypes.Structure):
_fields_ = [
('id', ctypes.c_uint32),
('hash', ctypes.c_uint32)
]
@classmethod
def from_id_and_password(cls, user_id, password):
pwd = hashlib.sha256(password.encode()).digest()
record = cls()
record.id = user_id
record.hash = ctypes.c_uint32.from_buffer_copy(pwd)
return recordfrom random import randint, choices
def fill():
data = []
for x in range(10_000):
pwd = ''.join(choices(string.ascii_letters, k=10))
user_id = randint(0, 100_000) * randint(x, x + 100)
record = UserPassword.from_id_and_password(user_id, pwd)
data.append(record)
return data
db = fill()
test = UserPassword.from_id_and_password(1_234_567, '1234567 ')
db.append(test)
Search
In [4]: test in db
Out[4]: True@functools.total_ordering
class UserPassword(ctypes.Structure):
...
def __eq__(self, other: 'UserPassword'):
return (self.id, self.hash) == (other.id, other.hash)
def __lt__(self, other: 'UserPassword'):
return (self.id, self.hash) < (other.id, other.hash)
Binary search
import bisect
db.sort()
index = bisect.bisect_left(db, test)
assert db[index] == test
Read/Write file
import pathlib
db_path = pathlib.Path('output.db')
with db_path.open('wb') as f:
for record in db:
f.write(record)
with db_path.open('rb') as f:
size = ctypes.sizeof(UserPassword)
file_size = db_path.stat().st_size
array = (UserPassword * int(file_size / size))()
f.readinto(array)
index = bisect.bisect_left(array, test)
assert array[index] == test
Multiprocessing
And the memory copying
In [1]: import ctypes
...: import os
...: import time
...:
...: from concurrent.futures import ProcessPoolExecutor
...:
...: array = (ctypes.c_uint64 * 10)()
...:
...: pool = ProcessPoolExecutor(2)
...:
...:
...: def test(val):
...: array[0] = val
...: time.sleep(1)
...:
...: return id(array), os.getpid()
...:
...: with pool as p:
...: result = list(p.map(test, [1,2]))
In [2]: result
Out[2]: [(4361349320 , 13216), (4361349320 , 13217)]import mmap
Memory map — solution
How it works
- OS map the file in virtual memory
- By requesting memory, reading a piece of file
- When memory is changed, the OS writes changes to a file
- If desired, you can see changes in the file from other processes.
- Can run without a file (share fd at fork)
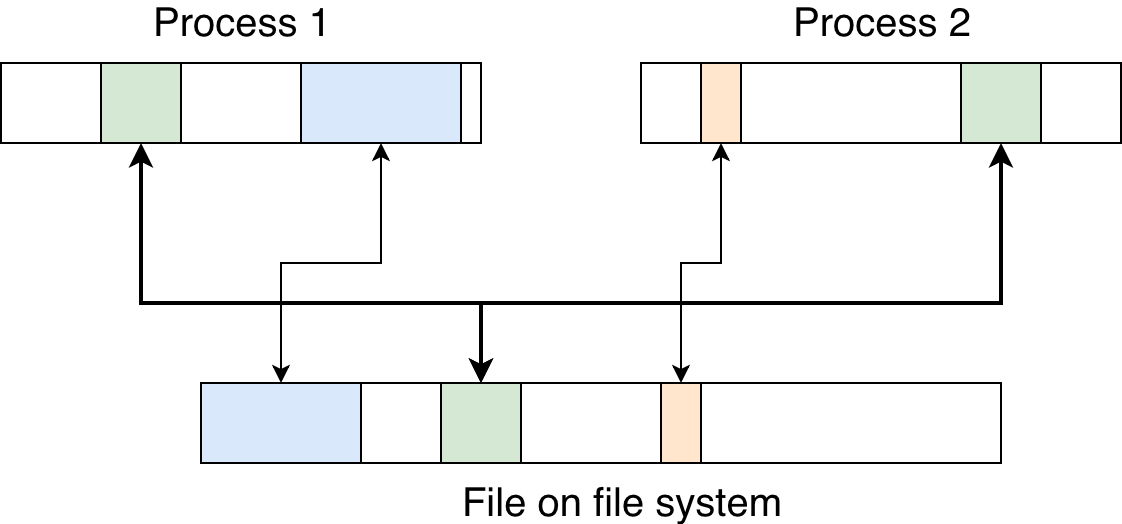
import mmap
file = db_path.open('rb+')
mem = mmap.mmap(file.fileno(), 0)
size = ctypes.sizeof(UserPassword)
file_size = db_path.stat().st_size
array_t = (UserPassword * int(file_size / size))
array = array_t.from_buffer(mem)
index = bisect.bisect_left(array, test)
assert array[index] == test
Example mmap
Understand when memory is being copied
Thank
kataev

Доклад Катаев Денис
By Denis Kataev




