Improving the Categorizer
Overview
-
More robust data from crawler
-
DMOZ common word exclusion
-
Next steps
More Data Categories
-
Song titles
-
Restaurants
-
Movies
-
Cities
-
TV Shows
DMOZ
- categories.txt from DMOZ (802287)
- "common" words are removed from TopN list

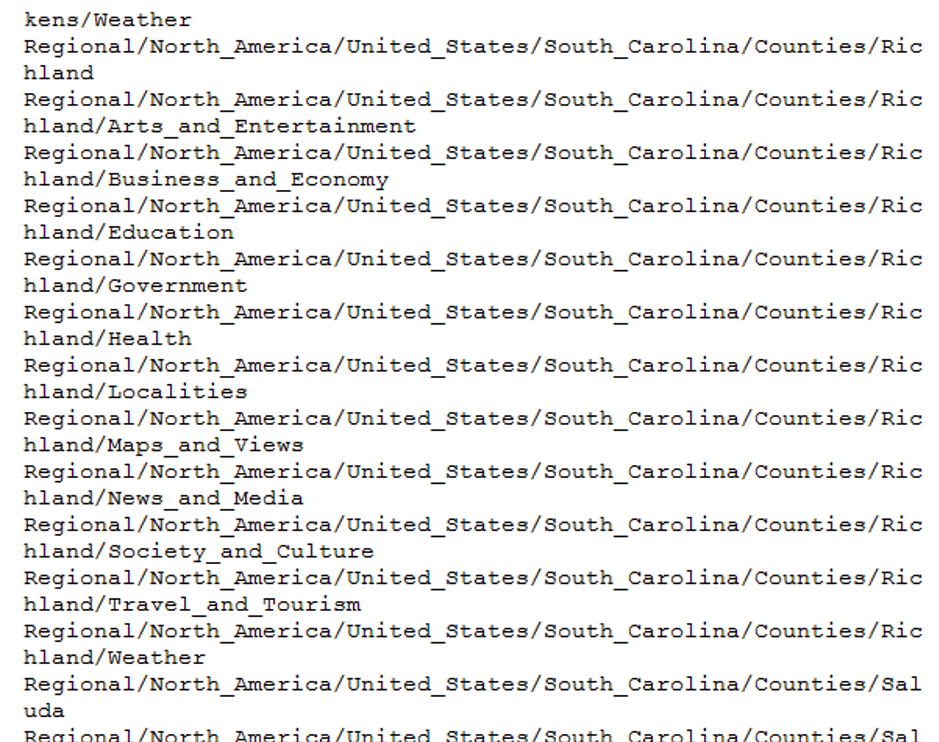
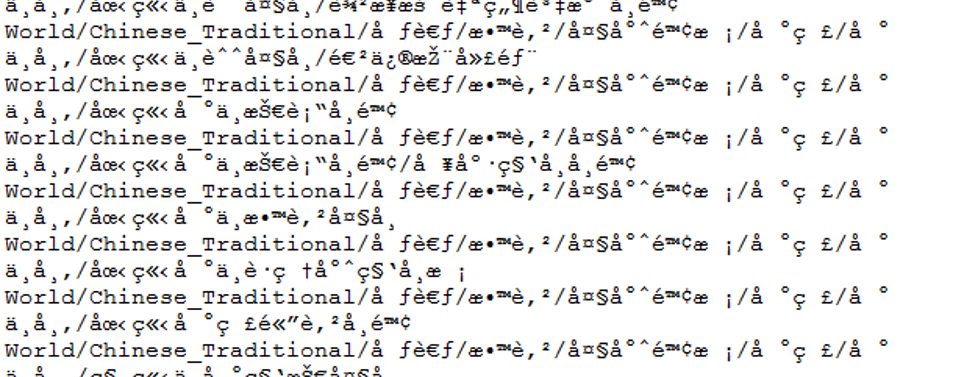
Point: Categories spelled in non-English characters
Not included in list of common words
Final Category List
[removed from TopN list]
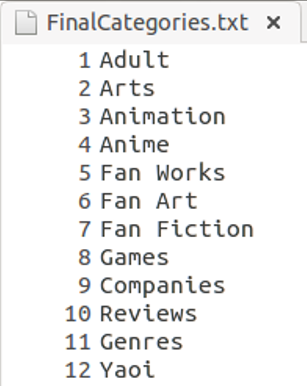
After removing non-English character categories: 568219
After removing repeated categories: 156160
...

...
Results
Restaurant TopN file:
[Given N = 10]
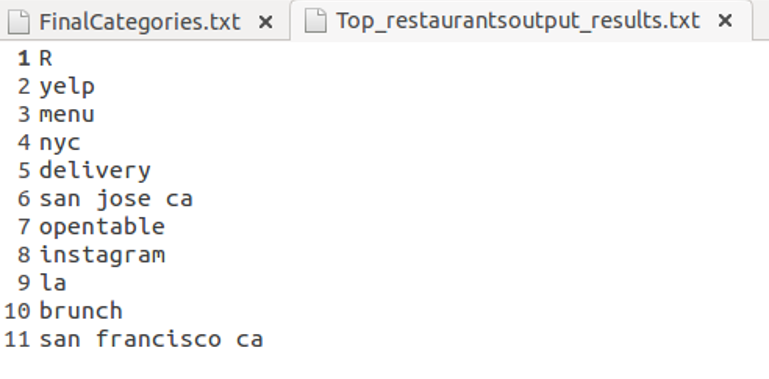
RunThrough
- Get data from multiple sources for different categories
- Autocomplete the data for all categories
- For each category, generate the topN terms.
- Compare the TopN terms with the autocomplete phrases on the testing data.
- Get results (APR)
- Major division: Calculation of TopN
- Method 1: Use TF-IDF to calculate the rate of a word being useful.
- Method 2: Use TF-IDF+DMOZ to remove the commonalities and recalculate the topN.
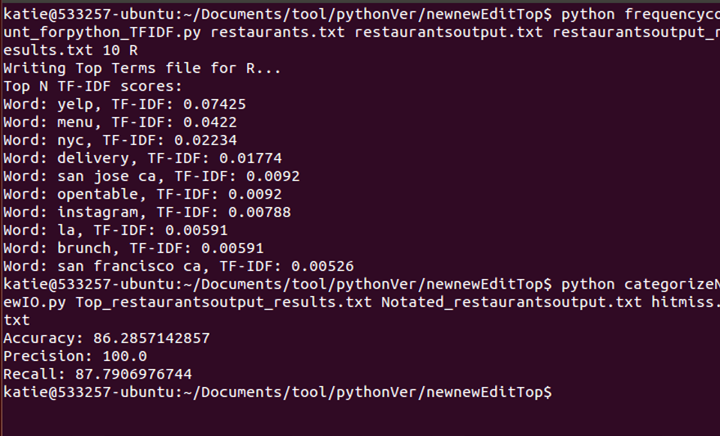
Previously
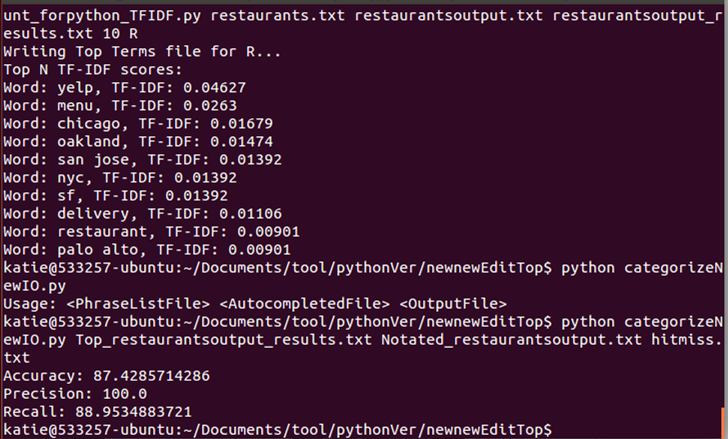
After DMOZ
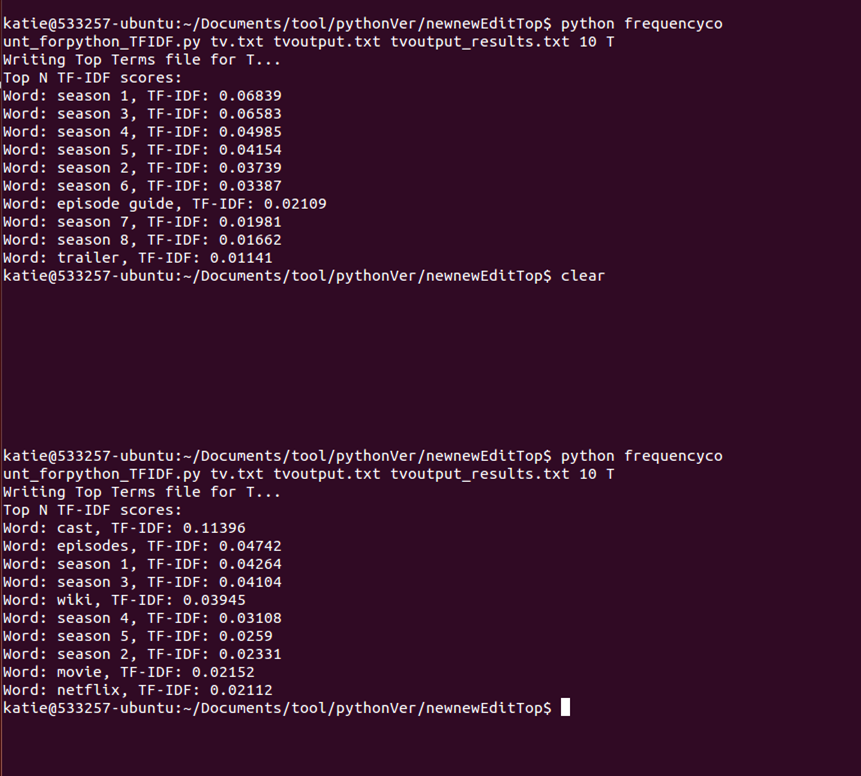
TV Anomalies - DMOZ
Next
- Improving the categorizer even more with Machine Learning / Neural Networks
- Vectorizing TopN key terms
Improving the Categorizer
By katiec089



