データ指向プログラミングの真実を
お話しします

JJUG CCC 2023 Fall
kawasima
データ指向プログラミング
Project Amberの文脈
-
サイズの小さいアプリケーションも扱うようになった。
-
システム全部をJavaで作る訳じゃなくなった
-
オブジェクトではなく、データをやり取りするようになった。
-
そこでプレーンデータをモデル化し、処理するより良い方法が必要
-
代数データ型 (Record, switch式, sealed)
-
https://www.youtube.com/watch?v=eXCx2hW_xNI
Java 21 By Brian Goetz @Devoxx
データ指向プログラミング
書籍『データ指向プログラミング』の文脈
-
コードとデータを分離する
-
汎用データ構造でデータエンティティを表現する
-
データはイミュータブルである
-
データ表現からデータスキーマを切り離す
関数型プログラミングっぽいことを言ってそうだが、
2が決定的に異なる
この両者のアプローチがどれくらい異なるか?

その真実をお話します。
データとは何か
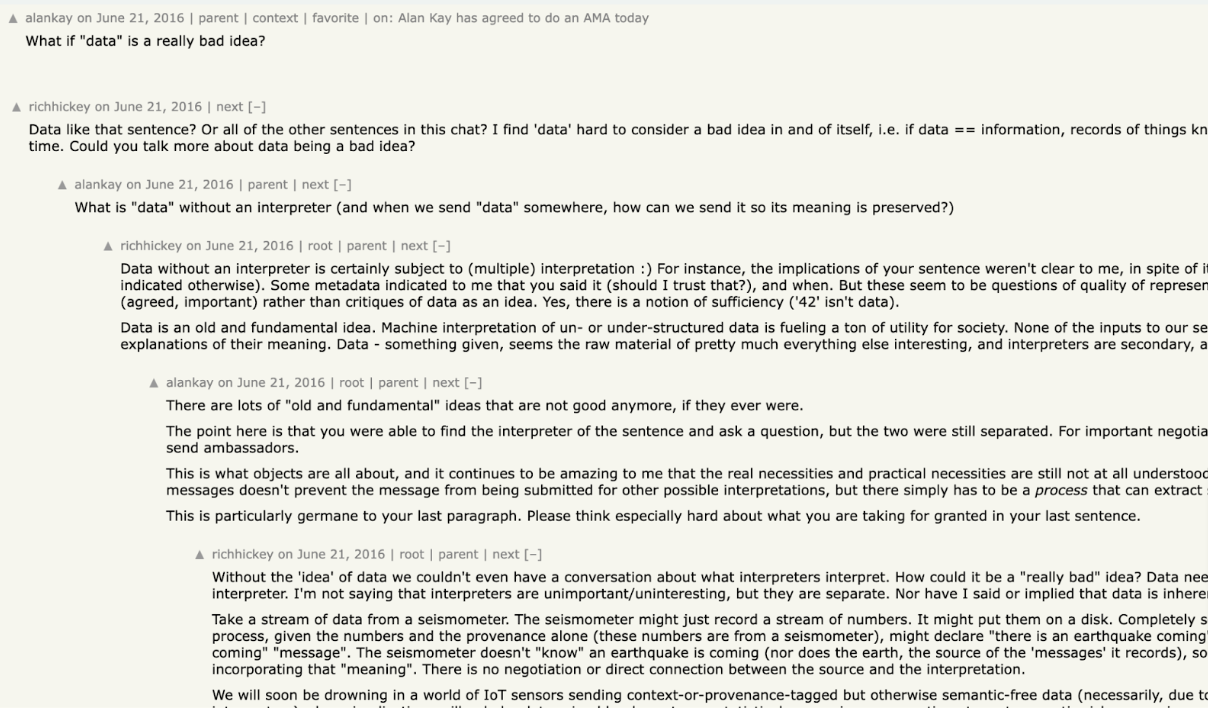
https://news.ycombinator.com/item?id=11945722
Rich HickeyとAlan Kayの議論
データおよび情報の認識のすれ違いまくっている。
データと情報(および知識)の違い


観測、収集したもの
データ
データを利用するために解釈を加えたもの
情報を元に判断したり、別の情報に変換したりする
情報
知識
DIKWフレームワーク
Data, Information, Knowledge, and Wisdom
http://www.systems-thinking.org/dikw/dikw.htm
データと情報は構造の違いではない
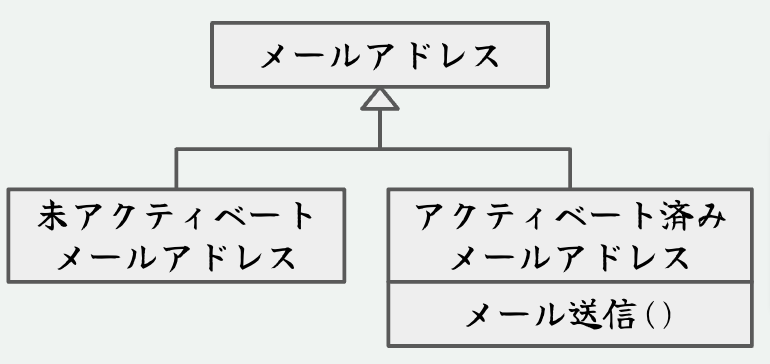
例えばメールアドレス"kawasima@wolfchief.jp" はデータであるが、アプリケーションでは解釈によって別の意味を持たせることがある
アクティベーションされているかによってメール送るかどうかが決まる、など。
未アクティベート
メールアドレス
アクティベート済
メールアドレス
また別のコンテキストでは別の解釈がされるかもしれない。
法人
メールアドレス
個人
メールアドレス
区別するにはいくつかのやり方がある
① 構造を変える
② 名前を変える
record EmailAddress(String address, boolean isActivated){}sealed interface EmailAddress(String address)
permits ActivatedEmailAddress, UnActivatedEmailAddress {
String value();
}
Perspective
データ
情報
情報
情報
解釈
知識
ドメインモデル
Parse
ドメインロジック
ドメインモデル
ドメインモデル
ドメインの外
からの入力
ソフトウェア版
DIKW
DIKW
つまり
-
データに解釈を加えて知識として利用する。
-
解釈の結果を情報と呼ぶことにする。
-
データは一般に多様な解釈がされうる。
これで、2つの「データ指向プログラミング」を読み解く準備が整った
解釈をどこで実装するか?
書籍『データ指向プログラミング』の場合
functionの中でデータを解釈しながら使う
データ
function
書籍『データ指向プログラミング』(DOP)でのやり方
class SendMail {
private final MailSender mailSender;
private final JsonValidator validator;
void send(ImMap<String, Object> data) {
if (!validator.validateEmail(data).isEmpty()) {
throw new IllegalArgumentException("Invalid email address");
}
if (data.getOrDefault("isActivated", false).equals(true)) {
mailSender.send(data.get("emailAddress").toString());
}
}
}「アクティベート済みの場合だけメールを送信する」は、アクティベートフラグがtrueの場合のみ、メールを送ることである、という解釈をメソッドの中で行っている。
このスタイルのPros/Cons
- データの解釈のやり方を選べる
Pros
Cons
-
データの解釈がfunctionごとに散らばってしまいがち
-
データをどう解釈するかは、コードの詳細を読む必要がある。
(ドキュメントとそのメンテナンスが命)
→ 残念ながらこのConsの対策まではDOPの書籍には書かれていない。
情報設計をせずにDOPを実践するやり方をNaive DOPと
呼ぶ(ことにする)
Naive DOP
Naive DOPは、レガシー基幹システムに多くみられる。
-
電文をPrimitive型に置き換えただけのDTO
-
このDTOをインプットとして「ビジネスロジック」を呼び出す
-
したがって、解釈は個別の「ビジネスロジック」毎に行われる
※イミュータビリティはたいてい持たないので、その点は異なる
では、なぜ今さらそういうことを言い出しているのか?
Clojureにおけるデータ指向プログラミング

そもそも書籍は「Clojureの思想を他言語でもやってみよう」という話。
だがClojureでは、specを使ってデータの解釈を表明する。
-
データの解釈をspecという形で残せる
-
functionの中で個別に解釈されるのではなく、同じ解釈ならば、それはspecとして共有できる
(s/def :email-address/address string?)
(s/def :email-address/is-activated boolean?)
(s/def ::activated-email-address
(and
(s/keys :req [:email-address/address :email-address/is-activated])
#(:email-address/is-activated %)))
(defn send-mail [email-address]
(if (:email-address/is-activated email-address)
(send (:email-address/address email-address))
(throw (Exception. "Email address is not activated"))))
(s/fdef send-mail
:args ::activated-email-address)
つまりClojureのデータ指向プログラミングは…
-
データの解釈をfunctionの事前条件、事後条件で表明する。
-
同じデータの解釈が重複して散らばるのを防ぐためにspecを定義できる。
単なるバリデーションとは違う、
単なるバリデーションとは!
ホンモノのデータ指向プログラミングをやりたきゃClojureを使おう
解釈をどこで実装するか?
Project Amberの場合
データの解釈を型で表現する
データ
メソッド
※ ここからの話はProject Amberの公式見解ではなく、これまでのJavaのオブジェクト指向の方針と、Project Amberで提供された機能から私が考察を加えたものです。
ドメインモデル
(情報)
これまでと何が違うの?
class EmailAddress {
private final String address;
private final boolean isActivated;
EmailAddress(String address, boolean isActivated) {
this.address = address;
this.isActivated = isActivated;
// validate address
}
void send(MailSender mailSender) {
if (isActivated) {
mailSender.send(address);
} else {
throw new NotActivatedException(address);
}
}
}データの解釈のためにアクティベートされているかどうかを持つ。が、これはこのクラスの利用者が知っておく必要はない
メールアドレスの実装の詳細を知らなくても、「アクティベート済みの場合だけメールを送信する」を実現してくれる
実装の詳細を隠す
Usecase
が、目論見どおり行かないことも多い。
テーブルにマッピングするために、Repository(の実装)がEmailAddressがaddressとisActivatedから構成されていることを知らなければならない。
このあたりからカプセル化が破綻していくことになりがち…
ドメインモデル
Repository
class EmailAddress {
private final String address;
private final boolean isActivated;
EmailAddress(String address, boolean isActivated) {
this.address = address;
this.isActivated = isActivated;
// validate address
}
String getAddress() {
return address;
}
boolean isActivated() {
return isActivated;
}
実装の詳細を露出させることに繋がる
そうなると利用側でActivateされているかどうかの判定ができる
class UserController {
private UserRepository userRepository;
String showProfile(Model model, String userId) {
User user = userRepository.load(userId);
model.addAttribute("isActivated",
user.email().isActivated());
return "profile";
}
}
例えばメールアドレスがアクティベートされているか?がフラグだけでなく、「休会会員でないこと」も条件に追加しなきゃいけなくなったとしたら…
カプセル化の破れ
(注意深く設計すれば、実装の詳細を隠しておけるかもしれないが)
データの解釈をクラスの中に閉じ込めておくのは難しいこともある。
そもそも、ドメインモデルに実装の詳細を持つのがどうなの?
データの解釈を型として表現する
public class SendMail {
private final MailSender mailSender;
public SendMail(MailSender mailSender) {
this.mailSender = mailSender;
}
public void send(ActivatedEmailAddress emailAddress) {
mailSender.send(emailAddress.value());
}
}
sealed interface EmailAddress
permits ActivatedEmailAddress, UnactivatedEmailAddress {
String value();
}
record ActivatedEmailAddress(String value) implements EmailAddress {}
record UnactivatedEmailAddress(String value) implements EmailAddress {}
Eメールアドレスは、未アクティベートとアクティベート済みに分類でき、アクティベート済みの場合だけ、メール送信できる
Project Amberにそこまでの想いが込められているかは分からないが…
実装の詳細をもたないドメインモデルは実現しやすくなる。
- Record
- Sealed interface/class
- switchによるパターンマッチ
結論: 同じ言葉を使っているが方向性はかなり異なる

| 書籍「データ指向プログラミング」 | Project Amberのデータ指向プログラミング |
|---|---|
|
型をデータから切り離す。 切り離した「型」はバリデーション用のスキーマ(書籍の中ではJSONスキーマ)として表現する。 データの解釈をどこで実装するかは言及されていない…が、Naive DOPの力学に支配されそう。 |
型でデータの解釈を表す。 Domain Modeling Made FunctionalやGrokking Functional Programming(なっとく!関数型プログラミング)の7章参照 |
データの解釈を型で表現する方向性をもう少し…
そもそもの
「メールアドレス」は「未アクティベート」と「アクティベート済み」が存在し、扱いがことなることがある。
という要求をストレートにモデリングすることが、どう実装するかうんぬん以前に重要
アクティベートフラグは業務の用語(ユビキタス言語)ではない
最終的に「アクティベートフラグ」を実装の詳細として持ち込むとしても、概念のモデル、ユビキタス言語を残しておかないと、仕様理解が難しくなる。
本書のコンテキストでは、複雑とは理解するのが難しい、という意味である
書籍「データ指向プログラミング」より
データの解釈をどこに残すか言及していないのに、「複雑とは理解するのが難しい」という意味というのは…

複雑さの分類
書籍『データ指向プログラミング』が参照しているOut of the Tar Pitに書いてあること
状態
本質的複雑さ
偶有的複雑さ
状態から直接計算する
ロジック
コントロール
導出できる
状態
偶有的複雑さは取り除けることもあるが、
本質的複雑さはソフトウェアの設計の工夫ではどうにもならない
https://tech.uzabase.com/entry/2021/05/20/141950
偶有的複雑さは究極理想環境では無くなるもの
(と考えると良い)
-
どんな検索も一瞬で返すマシンや無限のメモリ空間など
-
絶対に判断ミスをしない設計者
現実にはそういうものが存在しないので、トレードオフを考えつつ意思決定(偶有的複雑さを抱える)ことを決めていく。
偶有的複雑さの例①
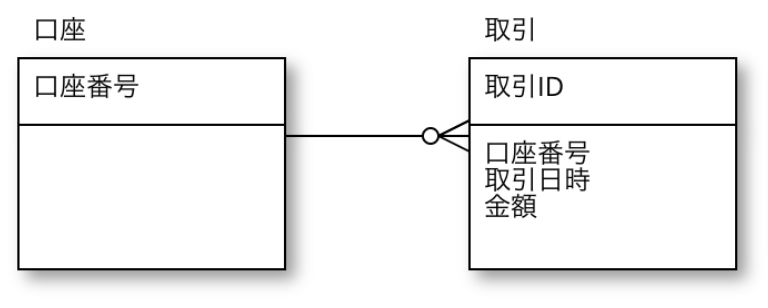
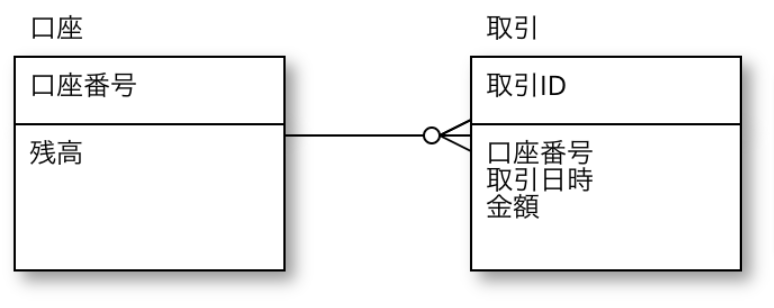
取引を集計しさえすれば、現在の残高は求まるので、口座エンティティには「残高」は不要。
…なのだが、実際はその算出にそれなりの計算量が必要なので、口座に「残高」を持たせる。
そうした途端に付随して、
-
残高更新時の排他制御
-
取引の集計と残高のズレのチェック(リコンサイル)
など、発生しさらなる複雑さを生む要因になる。
偶有的複雑さの例②
https://twitter.com/t__keshi/status/1635267214008897537
コントロールフロー
手続き型のプログラミングスタイルだとコード順に依存するので、要求仕様外の思わぬ動作に繋がる。
偶有的複雑さの例③
https://www.slideshare.net/kawasima/ss-255489610

偶有的複雑さの例④
プログラミング言語の制約、慣習、Syntax Sugarが無いことなどによっても発生する。
public class Person {
private final String name;
private final String address;
public Person(String name, String address) {
this.name = name;
this.address = address;
}
@Override
public int hashCode() {
return Objects.hash(name, address);
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
} else if (!(obj instanceof Person)) {
return false;
} else {
Person other = (Person) obj;
return Objects.equals(name, other.name)
&& Objects.equals(address, other.address);
}
}
@Override
public String toString() {
return "Person [name=" + name + ", address=" + address + "]";
}
// standard getters
}public record Person (
String name,
String address
) {}=
recordがない時代のJavaで小さなデータをクラスで表現しようとするのは、コード量が増えすぎて偶有的複雑性が増す
本質的複雑さ、とは何か?
シンプル
複雑
-
1つの役割
-
1つのタスク
-
1つの概念
-
複数の役割
-
複数のタスク
-
複数の概念

https://github.com/matthiasn/talk-transcripts/blob/master/Hickey_Rich/SimpleMadeEasy.md
要素数が多いのも「複雑」

要素数が多く、それらが相互作用しあう。
2種類の複雑さ
-
単一のコンポーネントに内包される複雑さ
-
1つのエンティティ、1つのクラス、1つのfunctionに複数の責務・概念が混ざっている。単一責任原則(SRP)に違反した状態
-
Unknown Unknowns (理解困難) [A Philosophy of Software Design]
-
-
コンポーネント数が多いことによる複雑さ
-
エンティティやクラス、functionの数が多く、それぞれの役割や関係性を理解するのが厄介。
-
認知負荷が高い (把握難しい) [A Philosophy of Software Design]
-
これらは相互に変換可能
本質的複雑さ保存の法則
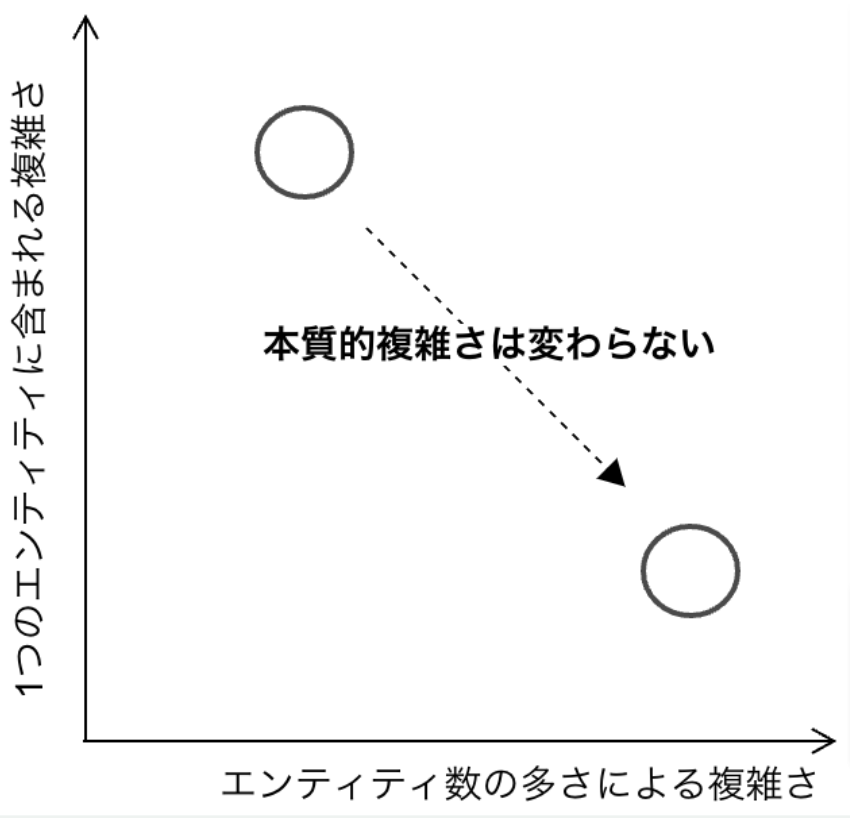
巨大なエンティティや巨大なクラスを、1つの責務・概念に分解しても、本質的複雑さの総量が変わるわけではない。
これが「銀の弾丸はない」の本質!
だが理解可能性の非対称
❶の注文には、どういう概念が含まれるか分からない。
【PR】本質的複雑さとうまく付き合う
ためのデータモデリング【宣伝】

複雑とは理解するのが難しいの対策は、
- 複数の概念が含まれないようにデータの解釈、振る舞いを分解する
- 数が多くなったデータの解釈、振る舞いを分割統治する
(Bounded Contextなどがこれに相当する)
ことが必要であり、データと振る舞いを分離したら理解しやすくなるわけではない
ただし、シンプル化し把握したデータの解釈と振る舞いを、どう実装するかは、型や関数を分けることによって生じる偶有的複雑さとのトレードオフを考慮する。
まとめ
つまりコードの詳細を読まずに仕様を理解できるためには、
モデルに含まれる概念(データの解釈)が明らかになっていること
が必要である。
そのためには
-
データの解釈ごとにエンティティや型を分ける
-
それができない場合は、ドキュメントなり何なりに明示しておく
のいずれかが必要
どちらのデータ指向プログラミングを実践するとしても注意しましょう
データ指向プログラミングの真実をお話しします
By kawasima
データ指向プログラミングの真実をお話しします
書籍『データ指向プログラミング』とJavaのProject Amberのデータ指向プログラミングの違いについて真実をお話しします。JJUG CCC 2023 Fallの発表資料です。