


Kristoffer Brabrand
Senior developer @ Behalf
GraphQL: A graph oriented way to think about and explore data
[without the data actually having to be in
a graph database any particular structure,
database or format at all]
....real fast
(frontend requirements leaking into the API code)
(overfetching)
(latency and potentially a soft DDOS by your own clients/frontends)
Used for validation of data from the users
and
for validating data returned by the resolvers
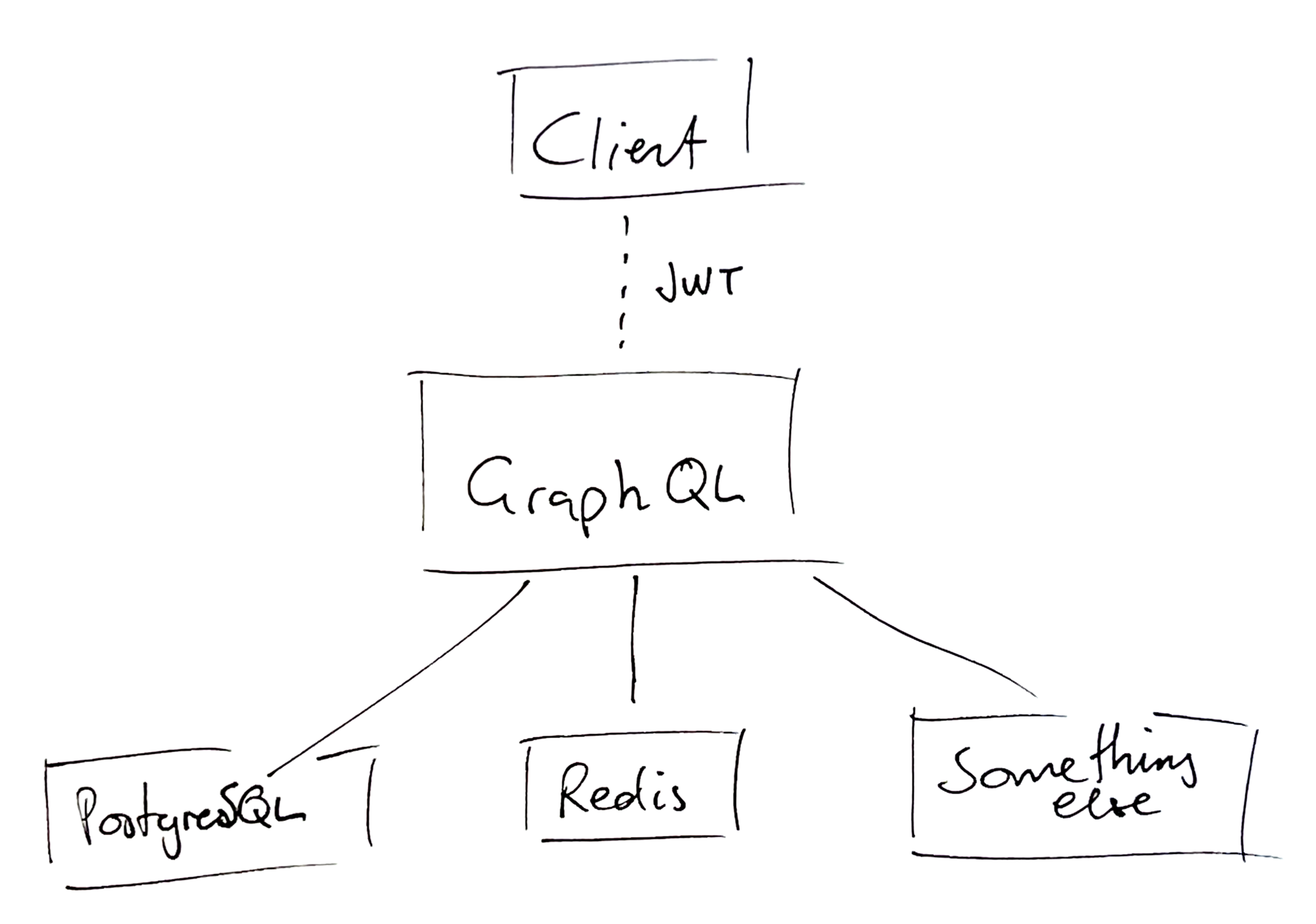
Functions that fetch information for a field in the graph based on the parent object, arguments and context.
Easy to start out, but hard to work with in a larger company since the single codebase has to be concerned with a lot of different things
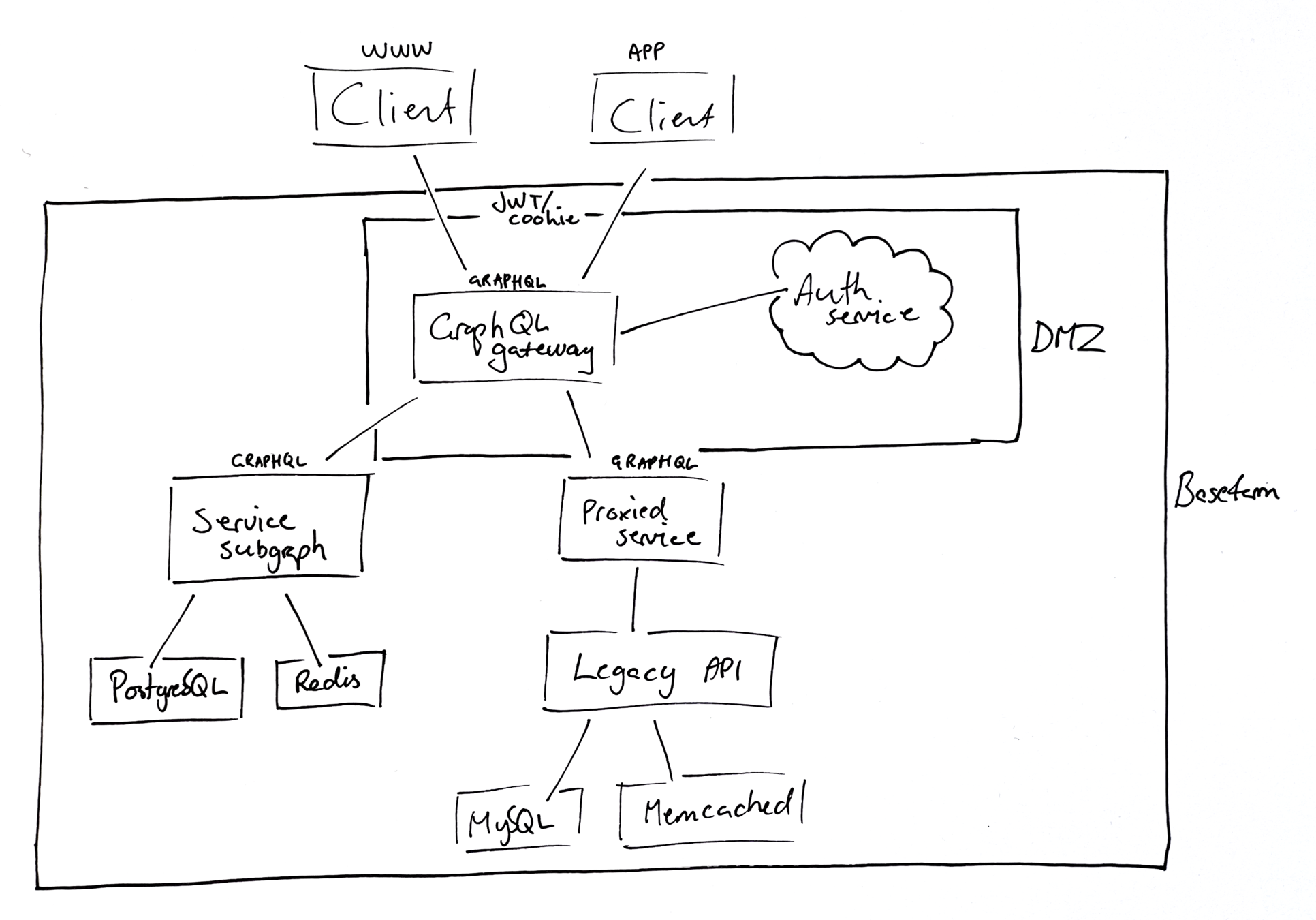
using Apollo federation
(formerly known as schema stiching)
...more work when getting started, but with each part of the graph knowing less about the whole picture. The advantage being better separation of concerns and that it's typically a lot easier to test.
(login)
You don't want abuse. There's a few ways around it.
Upload allowed queries to the registry build-time and allow only those queries uploaded to the registry to be performed.
Note: requires a an active team subscription for Apollo
A correlation ID is generated for all operations and is passed to subgraphs and [will be] returned if an error is returned. This way we can present the user with the correlation ID and they can give it to us when they get in touch
Apollo Gateway supports the Open TELemetry (OTEL) standard for app telemetry that can be consumed and presented by tools such as Zipkin or Jaeger.
...the Strawberry Python GraphQL library also has a plugin for OTEL.
By Kristoffer Brabrand


