Machine Learning
Going Deeper






Machine Learning - Training


Courtesy: Keelin Murphy
@MurphyKeelin
Machine Learning - Testing

Courtesy: Keelin Murphy
@MurphyKeelin

Hand-Crafted Features
What's in the Box?
Courtesy: Keelin Murphy
@MurphyKeelin
Hand-crafting Features





Texture
Curvature
Courtesy: Keelin Murphy
@MurphyKeelin
Deep Learning
Neural Networks. Lots of hidden layers (deep)
The network determines what features are useful

Source: Alexander Del Toro Barba : https://www.linkedin.com/pulse/how-artificial-intelligence-revolutionizing-finance-del-toro-barba
Courtesy: Keelin Murphy
@MurphyKeelin
Neural Network - Training





Dog
Dog
Cat
Cat
Penguin
Penguin
0.3
0.4
0.3
0.0
1.0
0.0
Input
Layer
Hidden Layers
(3)
Output
Layer
Neuron / Perceptron
= Array of Weights
ERROR
ERROR
ERROR
TRUTH
Back-Propagation
Update weights to minimize errors

Courtesy: Keelin Murphy
@MurphyKeelin
Neural Network - Testing
Dog
Cat
Penguin
0.08
0.02
0.9
Input
Layer
Hidden Layers
(3)
Output
Layer
Neuron / Perceptron
= Array of Weights

Courtesy: Keelin Murphy
@MurphyKeelin
Inside a Neural Network
x1
x2
x3
x4
Input
Layer
w11
w12
w13
w14
w21
w23
w24
b1
b2
Hidden Layer
2 neurons
(w11)(x1) + (w12)(x2)
+ (w13)(x3) + (w14)(x4) + b1
(w21)(x1) + (w22)(x2) +
(w23)(x3) + (w24)(x4) + b2
Output of hidden layer
w22
Further Layers
Courtesy: Keelin Murphy
@MurphyKeelin
Inside a Neural Network
Matrix Notation
Input
Layer
b1
b2
Hidden Layer
2 neurons
x
(4x1)
Output of hidden layer
W2 (1x4)
W1 (1x4)
(W1)(X) + b1
(W2)(X) + b2
W
(2x4)
b
(2x1)
Wx + b
(2x1)
Courtesy: Keelin Murphy
@MurphyKeelin
The Activation Function
Input
Layer
Hidden Layer
3 neurons
x
Output of hidden layer
Wx + b
Hidden Layer
2 neurons
f(Wx + b)
Courtesy: Keelin Murphy
@MurphyKeelin
The Activation Function
g()

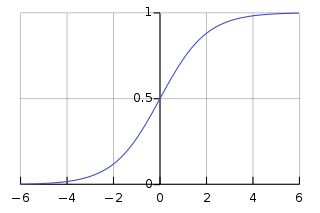
ReLU
Rectified Linear Unit
Most popular option
Sigmoid
No longer recommended
Courtesy: Keelin Murphy
@MurphyKeelin
Softmax
Input
Layer
Hidden Layer
3 neurons
x
Hidden Layer
2 neurons
g(Wx + b)
Dog
Cat
Penguin
Output Layer
0.3
0.4
0.3
Softmax Function
5
9
5
\sigma(z)_i=\frac{e^{z_i}}{\sum_{k=1}^{K}{e^{z_k}}}
Courtesy: Keelin Murphy
@MurphyKeelin
Back-Propagation
Input
Layer
Hidden Layer
3 neurons
x
Hidden Layer
2 neurons
g(Wx + b)
Dog
Cat
Penguin
Output Layer
0.3
0.4
0.3
Softmax Function
Dog
Cat
Penguin
0.0
1.0
0.0
ERROR
ERROR
ERROR
TRUTH
Back-Propagation
Update weights to minimize errors
Courtesy: Keelin Murphy
@MurphyKeelin
Back-Propagation
ERROR
Error is measured by the "Loss" (Cost) function
Want to update each weight to reduce the Loss
W_{1} = W_{1} -\alpha\frac{\partial L}{\partial W_{1}}

The Loss is a function of the network outputs, which are in turn functions of W and b values
W1
Loss (L)
Learning-Rate
Slope
Gradient Descent
Courtesy: Keelin Murphy
@MurphyKeelin
Back-Propagation

W1
W2
The "optimizer" decides how to move to reduce loss.
Optimizers are variants of basic gradient descent
"ADAM"
"Momentum"
"RMSprop"
Courtesy: Keelin Murphy
@MurphyKeelin
Tensorflow Tutorial

MNIST data

28
28
flatten
1
784
Output Layer
10 Neurons (classes)
Input Layer
batch-size =100
X (100 x 784)
W (784 x 10)
b (1 x 10)
XW + b
Softmax
(100 x 10)
(100 x 10)
Probabalistic Output
Truth
(100 x 10)
Error (Loss, Cost)
(Cross-Entropy)





Courtesy: Keelin Murphy
@MurphyKeelin
DeepLearning1
By keelinm

